Oracle 逻辑结构与性能优化(上)
梁敬彬梁敬弘兄弟出品
摘要
逻辑结构与SQL优化之间的关系,是大部分开发者和初级DBA容易忽略的关键一环。我们常常埋头于SQL语句本身的调优,却很少思考其背后,数据在数据库中究竟是如何存放的。本章旨在打通这一知识壁垒,我们将从Oracle最基础的逻辑结构知识开始介绍,并对所有可能和SQL优化有关的逻辑结构细节,如块、段、行迁移、行链接等,做进一步的剖析。
在理论介绍之后,将通过一系列的案例剖析,让读者能真真切切地感知到,这些看似抽象的逻辑结构,无时无刻不在影响着我们工作中的各种真实场景。最后,我们会对本章内容进行思考回顾,形成一个完整的学习闭环。
关键词
逻辑结构、BLOCK、Segment、行迁移、行链接、rowid
1 逻辑结构
在深入细节之前,我们首先需要建立一个宏观的认识。Oracle的逻辑结构是一种清晰的层次结构,它定义了数据是如何被组织和管理的。这套结构是面向我们用户的,我们所有的开发工作,都是在与它打交道。
数据库存储层次结构及其构成关系,从微观到宏观,形成了不同层次的粒度关系,如下图所示:
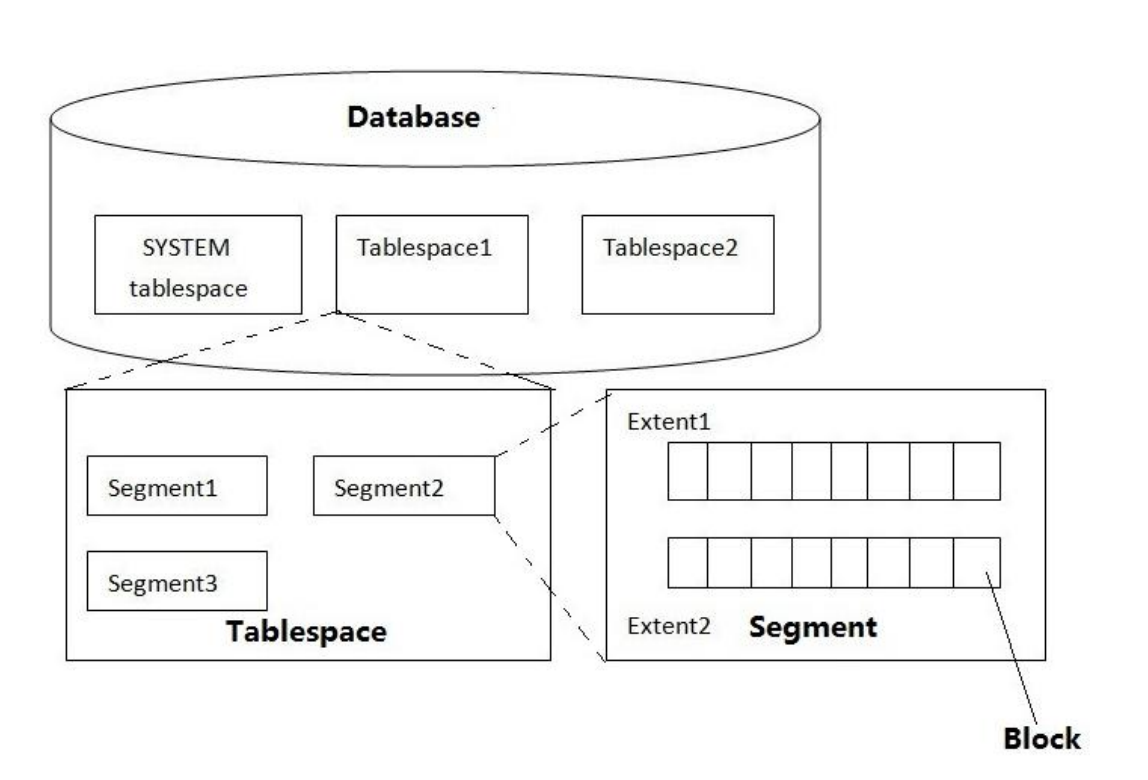
数据库(DATABASE)由若干表空间(TABLESPACE)组成, 表空间(TABLESPACE)由若
干段(SEGMENT)组成,段(SEGMENT)由若干区(EXTENT)组成,区(EXTENT)又由 Oracle
的最小单元块(BLOCK)组成。
理解这个从块 -> 区 -> 段 -> 表空间的层次,是理解后续所有性能问题的基础。
2 体系细节与 SQL 优化
有了宏观的层级概念,现在我们将带上放大镜,逐一审视这些逻辑体系的细节。我们将从块、段、表空间、rowid等维度来进行阐述,你会发现,每一个细节都与我们的SQL优化工作息息相关。
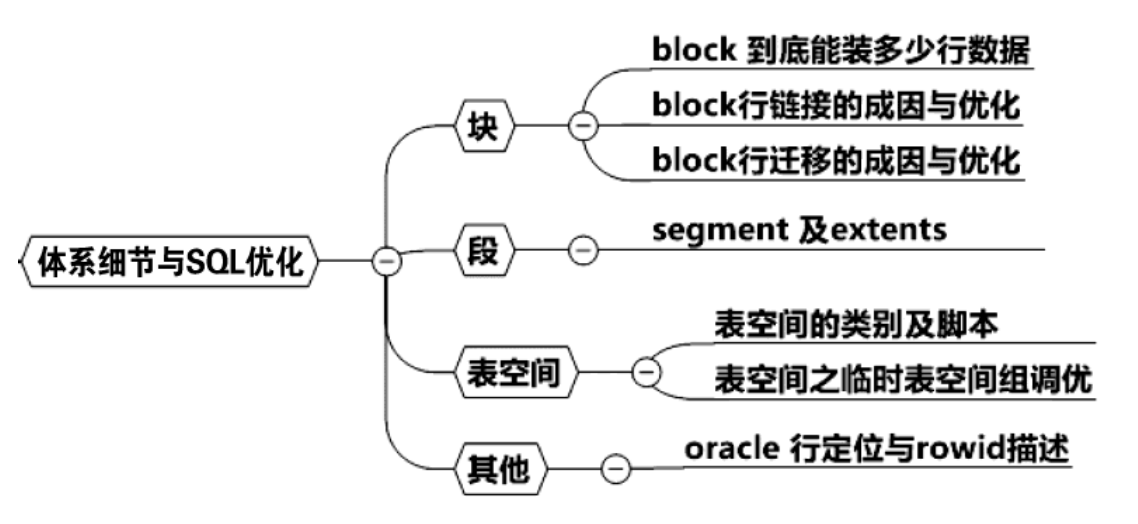
2.1 Block
1. Block 最多能装多少行
一个 8KB 的块其最大可用空间有 8096 字节,如果一个字节装一行的数据,能否插入 8000 行
呢?我们做些试验看看。首先是构造环境,如下:
drop table test_block_num purge;
create table test_block_num (id varchar2(1));
begin
for i in 1..8000 loopinsert into test_block_num values('a');
end loop;
commit;
end;
/
接下来我们通过调用 dbms_rowid 包来研究块到底能装下多少行数据。
SQL> select f, b, count(*)2 from (select dbms_rowid.rowid_relative_fno(rowid) f,3 dbms_rowid.rowid_block_number(rowid) b4 from test_block_num)5 group by f, b;F B COUNT(*)
--------------------------------4 433740 6604 481685 6604 433742 6604 433743 6604 481681 6604 481683 804 481684 6604 481688 6604 433744 6604 481682 6604 481687 6604 433741 6604 481686 660
试验结论与启示:
原文结论指出,由于块头、行目录等各种内部开销的存在,每行数据即使自身很小,也需要约11个字节的“包装”成本。因此,一个8KB(可用空间约8096字节)的块,理论上最多存储不超过 8096 / 11 ≈ 736 行。实验结果也清晰地验证了这一点。
这对SQL优化的意义在于: 帮助我们理解单次I/O的“含金量”。即使是访问看似很小的数据行,其背后也伴随着对整个数据块的读取和处理开销。
2. Block 行迁移的成因与优化
理解了Block的容量限制后,我们来看一个常见的性能问题:行迁移(Row Migration)。当一行数据因UPDATE操作导致其长度增加,而当前块的剩余空间已无法容纳这“变胖”的行时,Oracle会被迫将这整行数据“搬家”到一个新的数据块中,并在原地址留下一个指向新地址的“指针”。
这种“搬家”行为对性能的损害是直接的:通过索引访问这行数据时,Oracle需要先读一次旧块找到指针,再读一次新块获取数据,使得单次逻辑读变成了两次,性能自然下降。
优化效果对比:
通过实验可以直观看到,消除行迁移后,查询的逻辑读(consistent gets)从219下降到了116,性能得到明显提升。
行迁移优化前:
SQL> select /*+index(EMPLOYEES,idx_emp_id)*/ * from EMPLOYEES where employee_id>0;
统计信息
--------0 recursive calls0 db block gets219 consistent gets0 physical reads0 redo size437664 bytes sent via SQL*Net to client492 bytes received via SQL*Net from client9 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)107 rows processed
行迁移优化后,再看看如下语句逻辑读情况:
SQL> select /*+index(EMPLOYEES,idx_emp_id)*/ * from EMPLOYEES where employee_id>0;
统计信息
--------0 recursive calls0 db block gets116 consistent gets0 physical reads0 redo size437034 bytes sent via SQL*Net to client492 bytes received via SQL*Net from client9 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)107 rows processed
逻辑读从原来的 219 下降到 116,性能明显提升。
具体试验步骤如下:
--- PCTFREE 试验准备之建表
DROP TABLE EMPLOYEES PURGE;
CREATE TABLE EMPLOYEES AS SELECT * FROM HR.EMPLOYEES ;
desc EMPLOYEES;
create index idx_emp_id on employees(employee_id);
--- PCTFREE 试验准备之扩大字段
alter table EMPLOYEES modify FIRST_NAME VARCHAR2(1000);
alter table EMPLOYEES modify LAST_NAME VARCHAR2(1000);
alter table EMPLOYEES modify EMAIL VARCHAR2(1000);
alter table EMPLOYEES modify PHONE_NUMBER VARCHAR2(1000);
--- PCTFREE 试验准备之更新表
UPDATE EMPLOYEESSET FIRST_NAME = LPAD('1', 1000, '*'), LAST_NAME = LPAD('1', 1000, '*'), EMAIL = LPAD('1',
1000, '*'),PHONE_NUMBER = LPAD('1', 1000, '*');
COMMIT;
---行迁移优化前,先看看该语句逻辑读情况(执行计划及代价都一样,没必要展现了,就展现 statistics 即可)。
SET AUTOTRACE traceonly
set linesize 1000
select /*+index(EMPLOYEES,idx_emp_id)*/ * from EMPLOYEES where employee_id>0;
/
set autotrace off
----- 发现存在行迁移的方法。
--首先建 chaind_rows 相关表,这是必需的步骤。
--sqlplus "/ as sysdba"
sqlplus ljb/ljb
drop table chained_rows purge;
@?/rdbms/admin/utlchain.sql
----以下命令针对 EMPLOYEES 表和 EMPLOYEES_BK 做分析,将产生行迁移的记录插入到 chained_rows 表中
analyze table EMPLOYEES list chained rows into chained_rows;
select count(*) from chained_rows where table_name='EMPLOYEES';
---以下方法可以去除行迁移
drop table EMPLOYEES_TMP;
create table EMPLOYEES_TMP as select * from EMPLOYEES where rowid in (select head_rowid
from chained_rows);
Delete from EMPLOYEES where rowid in (select head_rowid from chained_rows);
Insert into EMPLOYEES select * from EMPLOYEES_TMP;
delete from chained_rows ;
commit;
analyze table EMPLOYEES list chained rows into chained_rows;
select count(*) from chained_rows where table_name='EMPLOYEES';
--这时的取值一定为 0,用这种方法做行迁移消除,肯定是没问题的!
---行迁移优化后,先看看该语句逻辑读情况(执行计划及代价都一样,没必要展现了,就展现 statistics 即可)
SET AUTOTRACE traceonly statistics
set linesize 1000
select /*+index(EMPLOYEES,idx_emp_id)*/ * from EMPLOYEES where employee_id>0;
/
总结与启示:
行迁移是UPDATE密集型系统需要警惕的性能杀手。通过合理设置表的PCTFREE参数为更新操作预留空间,是预防行迁移的有效手段。对于已经存在的行迁移,则需要通过ALTER TABLE … MOVE或导出导入等方式进行整理。
3. Block 行链接的成因与优化
与行迁移的“后天长胖”不同,行链接(Row Chaining) 是“天生体型过大”。当你要插入的一行数据,其总长度本身就超过了一个数据块的最大可用空间时,Oracle只能将其“切分”成多段,存放在不同的数据块中,并用指针连接起来。
行链接对性能的影响是必然的,因为读取这一行数据,注定需要多次I/O。
SQL> analyze table EMPLOYEES list chained rows into chained_rows;
表已分析。
SQL> select count(*) from chained_rows where table_name='EMPLOYEES';COUNT(*)
----------107SQL> --行链接只有通过加大 BLOCK 块的方式才可以避免,如下:
SQL> DROP TABLE EMPLOYEES_BK PURGE;
表已删除。
SQL> CREATE TABLE EMPLOYEES_BK TABLESPACE TBS_LJB_16K AS SELECT * FROM EMPLOYEES;
表已创建。
SQL> delete from chained_rows ;
已删除 107 行。
SQL> commit;
提交完成。
SQL> analyze table EMPLOYEES_BK list chained rows into chained_rows;
表已分析。
SQL> select count(*) from chained_rows where table_name='EMPLOYEES_BK';COUNT(*)
----------0
总结与启示:
解决行链接问题的根本方法,是在数据库设计阶段就充分预估行的最大长度,并选择拥有足够大DB_BLOCK_SIZE的表空间来存储这类“超长行”的表。
2.2 Segment 与 extent
建一个 T 表就产生了表段、T 段(SEGMENT),请观察区(EXTENT)及块(BLOCK)的个数。建
一个索引 IDX_OBJ_ID 就产生了索引段,IDX_OBJ_ID 段(SEGMENT)和表的情况类似,试验如下:
SQL> drop table t purge;
表已删除。
SQL> create table t tablespace tbs_ljb as select * from dba_objects where rownum=1 ;
表已创建。
SQL> col segment_name format a15
SQL> col segment_type format a10
SQL> col tablespace_name format a20
SQL> col blocks format 9999
SQL> col extents format 9999
SQL> select segment_name,2 segment_type,3 tablespace_name,4 blocks,extents,5 bytes/1024/10246 from user_segments where segment_name = 'T';
SEGMENT_NAME SEGMENT_TY TABLESPACE_NAME BLOCKS EXTENTS BYTES/1024/1024
--------------- ---------- -------------------- ------ ------- ---------------
T TABLE TBS_LJB 8 1 .0625
SQL> select count(*) from user_extents WHERE segment_name='T';COUNT(*)
----------1
SQL> ---建一个索引 IDX_OBJ_ID 就产生了索引段,IDX_OBJ_ID 段(SEGMENT)和表的情况类似,如下:
SQL> create index idx_obj_id on t(object_id);
索引已创建。
SQL> select segment_name,2 segment_type,3 tablespace_name,4 blocks,5 extents,6 bytes/1024/10247 from user_segments8 where segment_name = 'IDX_OBJ_ID';
SEGMENT_NAME SEGMENT_TY TABLESPACE_NAME BLOCKS EXTENTS BYTES/1024/1024
--------------- ---------- -------------------- ------ ------- ---------------
IDX_OBJ_ID INDEX USERS 8 1 .0625
SQL> select count(*) from user_extents WHERE segment_name='IDX_OBJ_ID';COUNT(*)
----------1
随着表记录的增加,表对应的 Extents 及 Blocks 的个数也不断增多。随着 Idx_obj_id 不断增
大,索引对应的 Extents 及 Blocks 的个数也不断增多。如下:
SQL> insert into t select * from dba_objects ;
已创建 72882 行。
SQL> commit;
提交完成。
SQL> ---随着 T 表数据不断增加,区(EXTENT)及块(BLOCK)的个数也不断增多。如下:
SQL> select segment_name,2 segment_type,3 tablespace_name,4 blocks,5 extents,bytes/1024/10246 from user_segments7 where segment_name = 'T';
SEGMENT_NAME SEGMENT_TY TABLESPACE_NAME BLOCKS EXTENTS BYTES/1024/1024
--------------- ---------- -------------------- ------ ------- ---------------
T TABLE TBS_LJB 1152 24 9
SQL> ---随着 IDX_OBJ_ID 不断增大,区(EXTENT)及块(BLOCK)的个数也不断增多。如下:
SQL> select segment_name,2 segment_type,3 tablespace_name,4 blocks,5 extents,6 bytes/1024/10247 from user_segments8 where segment_name = 'IDX_OBJ_ID';
SEGMENT_NAME SEGMENT_TY TABLESPACE_NAME BLOCKS EXTENTS BYTES/1024/1024
--------------- ---------- -------------------- ------ ------- ---------------
IDX_OBJ_ID INDEX TBS_LJB 384 18 3
总结与启示:
段和区的增长是数据库的正常行为。但过多的区(Extents)分配,可能意味着段的存储空间是零散的,这会对全表扫描等需要大量连续读的操作性能产生一定影响。通过在建表时合理规划存储参数(如INITIAL, NEXT),可以优化空间分配的效率。
2.3 Tablespace
查看表空间的总体情况:
SQL> SELECT A.TABLESPACE_NAME "表空间名",2 A.TOTAL_SPACE "总空间(G)",3 NVL(B.FREE_SPACE, 0) "剩余空间(G)",4 A.TOTAL_SPACE - NVL(B.FREE_SPACE, 0) "使用空间(G)",5 CASE WHEN A.TOTAL_SPACE=0 THEN 0 ELSE trunc(NVL(B.FREE_SPACE, 0) / A.TOTAL_SPACE
* 100, 2) END "剩余百分比%" --避免分母为 06 FROM (SELECT TABLESPACE_NAME, trunc(SUM(BYTES) / 1024 / 1024/1024 ,2) TOTAL_SPACE7 FROM DBA_DATA_FILES8 GROUP BY TABLESPACE_NAME) A,9 (SELECT TABLESPACE_NAME, trunc(SUM(BYTES / 1024 / 1024/1024 ),2) FREE_SPACE
10 FROM DBA_FREE_SPACE
11 GROUP BY TABLESPACE_NAME) B
12 WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME(+)
13 ORDER BY 5;
表空间名 总空间(G) 剩余空间(G) 使用空间(G) 剩余百分比%
------------------------------ ---------- ----------- ----------- -----------
SYSTEM 1.04 0 1.04 0
SYSAUX .93 .05 .88 5.37
EXAMPLE .09 .02 .07 22.22
USERS 5.96 1.77 4.19 29.69
TBS_BOSSWG_PDM 16 7.98 8.02 49.87
UNDOTBS1 2.67 2.63 .04 98.5
TBS_LJB_B 8 7.99 .01 99.87
TBS_LJB_C 8 7.99 .01 99.87
TBS_LJB 8 7.99 .01 99.87
TBS_CS 16 15.99 .01 99.93
TBS_LJB_A .15 .15 0 100
已选择 11 行。
总结与启示:
表空间是物理存储和逻辑结构的连接点。合理的表空间规划(如将数据和索引分离、将高I/O对象分散到不同物理磁盘)和持续的容量监控,是整个数据库性能优化的前提和保障。
2.4 rowid
游览了所有逻辑结构之后,我们回到一个根本问题:Oracle是如何在亿万行数据中,瞬间定位到某一行数据的呢?答案就是rowid。
rowid的构成与解读:rowid可以被理解为一行数据的唯一物理地址。它本身是一串编码,包含了定位到这行数据所需的所有信息:对象ID、文件ID、块ID和块内行号。它虽然不作为列存储在数据块中,但却是索引结构的核心组成部分,是连接索引和表的关键桥梁。
drop table t purge;
create table t as select * from dba_objects;
select rowid from t where rownum=1;
ROWID
------------------
AAAYPJAAQAAATNDAAA
--以下可定位该行具体在哪个对象、文件、块、行(注:rowid 是 64 进制的)
data object number=AAAYPJ
file =AAQ
block =AAATND
row =AAA
select dbms_rowid.rowid_object('AAAYPJAAQAAATNDAAA') data_object_id#,dbms_rowid.rowid_relative_fno('AAAYPJAAQAAATNDAAA') rfile#,dbms_rowid.rowid_block_number('AAAYPJAAQAAATNDAAA') block#,dbms_rowid.rowid_row_number('AAAYPJAAQAAATNDAAA') row#
from dual;
DATA_OBJECT_ID# RFILE# BLOCK# ROW#
--------------- ---------- ---------- ----------99273 16 78659 0
set linesize 266
col owner format a10
col object_name format a20
col file_name format a40
col tablespace_name format a30
select owner,object_name from dba_objects where object_id=99273;
OWNER OBJECT_NAME
---------- -----------
LJB T
select file_name,tablespace_name from dba_data_files where file_id=16;
FILE_NAME TABLESPACE_NAME
---------------------------------------- ---------------
D:\ORACLE\ORADATA\TEST11G\TBS_LJB02.DBF TBS_LJB
总结与启示:
rowid是Oracle中访问单行数据最快的方式。所有我们熟知的索引扫描,其最终目的都是为了快速获取目标的rowid,然后通过这个“精确GPS”直接访问数据块,从而避免耗时的全表扫描。理解了rowid,就理解了索引能够极大提升查询效率的核心秘密。
未完待续…
系列回顾
“大白话人工智能” 系列
“数据库拍案惊奇” 系列
“世事洞明皆学问” 系列