【Python机器学习(一)】NumPy/Pandas手搓决策树+使用Graphviz可视化(以西瓜书数据集为例)
下题来源于笔者学校的《模式识别与机器学习》课程的作业题,本文将通过使用NumPy处理数学运算,Pandas处理数据集,Graphviz实现决策树可视化等Python库来实现决策树算法及其格式化。
导入用到的Python库:
import numpy as np
import pandas as pd
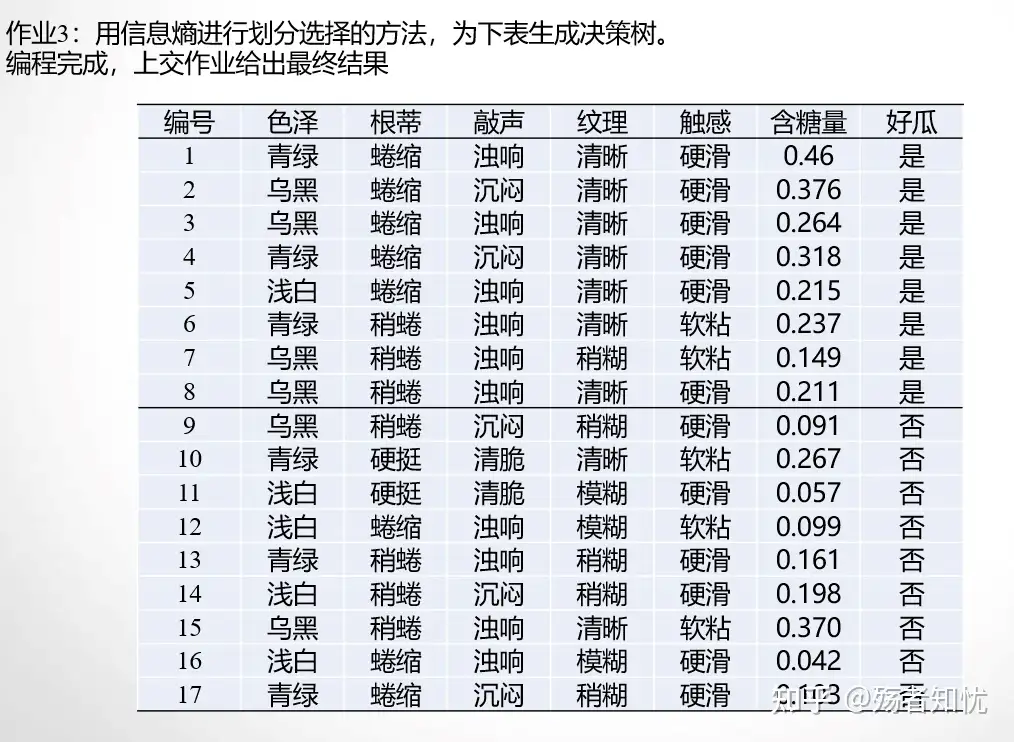
from graphviz import Digraph将数据集整理为DataFrame对象。数据集中除“好瓜”一栏表示类别外,其他栏均为属性和属性值:
data = pd.DataFrame({
"好瓜" : ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否'],
"色泽" : ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿', '浅白', '浅白', '青绿', '浅白', '乌黑', '浅白', '青绿'],
"根蒂" : ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺', '硬挺', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '蜷缩', '蜷缩'],
"敲声" : ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '浊响', '沉闷', '清脆', '清脆', '浊响', '浊响', '沉闷', '浊响', '浊响', '沉闷'],
"纹理" : ['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '清晰', '稍糊', '清晰', '模糊', '模糊', '稍糊', '稍糊', '清晰', '模糊', '稍糊'],
"触感" : ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '硬滑', '软粘', '硬滑', '硬滑'],
"含糖量" : [0.46, 0.376, 0.264, 0.318, 0.215, 0.237, 0.149, 0.211, 0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.37, 0.042, 0.103]
})创建节点类和边类:
class Node:def __init__(self, feature = None, cls = None, data = None):self.feature = feature #若为非叶节点,使用self.feature存储该节点的分类属性self.cls = cls #若为叶节点,使用self.cls存储该节点的分类结果self.data = data #储存分至该节点的样本class edge:def __init__(self, start = None, end = None):self.start = start #父节点self.end = end #子节点使用全局变量列表和字典分别存储决策树的各节点和边,其中边的存储格式为edge_dict[边的属性值]=边 。
由于数据集中含有属性值为连续值的属性,需使用二分法来处理。使用全局变量best_mid_point 来存储最佳二分点:
node_list = []
edge_dict = {} #属性值作为有向边字典的索引
best_mid_point = 0决策树学习基本算法如下图所示:

笔者使用信息增益作为划分标准,将其应用至决策树学习基本算法中,计算各属性的信息增益,取信息增益最大者为最优划分属性。
根据属性对数据集
划分后的信息增益的定义如下:
其中,表示经验熵:
表示