【文献阅读】5%>100%: 打破视觉识别任务的完全微调的性能束缚
🧠 Mona: 打破视觉微调性能上限的多认知视觉适配器
📌 原文:Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks
📎 作者:Dongshuo Yin, Leiyi Hu, Bin Li, Youqun Zhang, Xue Yang
📚 arXiv:2408.08345 | 🔗 项目地址
🌟 目录
-
1. 背景与动机
-
2. Mona 方法详解
- 2.1 输入分布优化
- 2.2 多认知卷积滤波器
- 2.3 模块结构图
- 2.4 完整计算流程
-
3. 实验设置与结果
- 3.1 数据集
- 3.2 实验结果与关键图表
- 3.3 收敛性分析
-
4. 消融实验
-
5. 模型规模扩展性
-
6. 实验复现指南
- 6.1 环境配置
- 6.2 数据准备
- 6.3 训练配置文件结构(以COCO为例)
- 6.4 Mona模型注册与使用
-
7. 算法伪代码
-
8. 总结与讨论
-
9. 引用
1. 背景与动机
视觉模型调优长期以来依赖于全参数微调(Full Fine-tuning),其虽能最大化利用预训练特征,但带来:
- 参数更新多(100%),训练耗时长
- 存储与迁移成本高,尤其在大模型时代
而参数高效调优(PEFT / Delta-tuning)方法,如 LoRA、Adapter、BitFit,在CV任务(特别是检测与分割)中的性能仍落后于全参数微调。
Mona 提出新范式:
- 用视觉友好的多尺度卷积取代语言适配器中的线性变换
- 结合输入归一化与可学习缩放参数
- 实现更快训练、更强性能、更少参数
2. Mona 方法详解
2.1 输入分布优化
为稳定从冻结的主干网络传递到适配器的特征分布,Mona 引入如下形式的归一化:
x n o r m = s 1 ⋅ LayerNorm ( x 0 ) + s 2 ⋅ x 0 x_{norm} = s_1 \cdot \text{LayerNorm}(x_0) + s_2 \cdot x_0 xnorm=s1⋅LayerNorm(x0)+s2⋅x0
- s 1 , s 2 s_1, s_2 s1,s2:可学习缩放因子
- 有助于提升训练稳定性
2.2 多认知卷积滤波器
Mona引入3种DWConv卷积核(3×3, 5×5, 7×7),模拟人眼对不同尺度特征的敏感性:
f d w = x + avg ( ∑ i = 1 3 ω i d w ⊗ x ) f_{dw} = x + \text{avg}\left( \sum_{i=1}^3 \omega_i^{dw} \otimes^x \right) fdw=x+avg(i=1∑3ωidw⊗x)
f p w = x + ω p w ⊗ x f_{pw} = x + \omega^{pw} \otimes x fpw=x+ωpw⊗x
最终输出:
x = x 0 + U l ⋅ GeLU ( f p w ( f d w ( D l ( x n o r m ) ) ) ) x = x_0 + U^l \cdot \text{GeLU}\left( f_{pw}( f_{dw}( D^l(x_{norm}) ) ) \right) x=x0+Ul⋅GeLU(fpw(fdw(Dl(xnorm))))
2.3 模块结构图
2.4 完整计算流程公式
x = x 0 + U l ⋅ σ ( x + ω p w ⊗ ( x + avg ( ∑ i = 1 3 ω i d w ⊗ D ˆ l ( x n o r m ) ) ) ) x = x_0 + U^l \cdot \sigma\left( x + \omega^{pw} \otimes \left( x + \text{avg}\left( \sum_{i=1}^3 \omega_i^{dw} \otimes\^D^l(x_{norm}) \right) \right) \right) x=x0+Ul⋅σ(x+ωpw⊗(x+avg(i=1∑3ωidw⊗Dˆl(xnorm))))
3. 实验设置与结果
3.1 数据集
| 任务 | 数据集 | 模型 |
|---|---|---|
| 实例分割 | COCO | Swin-B + Cascade Mask RCNN |
| 语义分割 | ADE20K | Swin-L + UperNet |
| 检测 | Pascal VOC | Swin-L + RetinaNet |
| 定向检测 | DOTA, STAR | Swin-B + Oriented R-CNN |
| 分类 | Flowers102, OxfordPets, VOC2007 | Swin-L |
3.2 实验结果与关键图表
COCO 实例分割(表1)
| 方法 | APBox | APMask | 参数占比 |
|---|---|---|---|
| Full | 52.40% | 45.10% | 100% |
| Mona | 53.40% | 46.00% | 4.67% |
Pascal VOC + ADE20K(表2)
| 方法 | VOC APBox | ADE mIoU |
|---|---|---|
| Full | 83.70% | 51.18% |
| Mona | 87.30% | 51.36% |
定向检测(表3)
| 数据集 | Full | Mona |
|---|---|---|
| DOTA | 78.31% | 78.44% |
| STAR | 38.63% | 39.45% |
图像分类(表4)
| 数据集 | Full Top-1 | Mona Top-1 |
|---|---|---|
| Flowers102 | 99.57% | 99.68% |
| OxfordPets | 94.65% | 95.48% |
3.3 收敛性分析
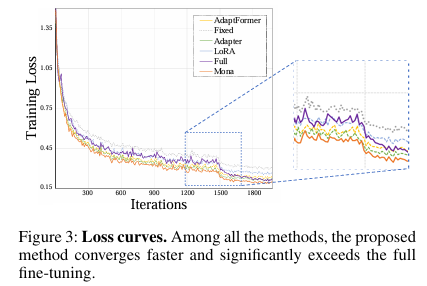
图3:Pascal VOC上训练损失对比
- Mona收敛更快,曲线更平滑
- 显示其训练稳定性和优化能力远优于其他方法
4. 消融实验
表5:中间维度影响
| 中间维度 | 参数比例 | VOC APBox |
|---|---|---|
| 32 | 1.35% | 86.8% |
| 64 | 2.56% | 87.3% |
| 128 | 5.22% | 87.1% |
5. 模型规模扩展性
| Backbone | Full | Mona | Mona参数占比 |
|---|---|---|---|
| Swin-T | 80.1% | 83.5% | 4.87% |
| Swin-B | 81.6% | 86.5% | 4.06% |
| Swin-L | 83.7% | 87.3% | 2.56% |
结论:
- 模型越大,Mona参数占比越低,性能提升越明显
6. 实验复现指南
6.1 环境配置
conda create -n mona_env python=3.9
conda activate mona_env
pip install mmcv-full mmdet mmsegmentation mmrotate
git clone https://github.com/Leiyi-Hu/mona.git
cd mona
pip install -r requirements.txt
6.2 数据准备
# 示例:COCO数据集准备
mkdir data && cd data
# 下载并解压COCO2017数据集
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
unzip train2017.zip && unzip val2017.zip
6.3 训练配置文件结构(以COCO为例)
配置文件目录:configs/mona/cascade_mask_rcnn_swin-b_fpn_1x_coco.py
关键字段说明:
model = dict(type='CascadeRCNN',backbone=dict(type='SwinTransformer',pretrained='path/to/swin_base.pth',mona_cfg=dict(enabled=True,dim=64,kernel_sizes=[3,5,7],)),adapter=dict(type='MonaAdapter',use_scaled_norm=True,use_skip=True),
)
6.4 Mona模型注册与使用
在 mona/models/backbones/swin.py 中注册:
from .mona_adapter import MonaAdapterclass SwinTransformerWithMona(SwinTransformer):def forward(self, x):x = super().forward(x)x = self.mona(x)return x
启动训练:
python tools/train.py configs/mona/cascade_mask_rcnn_swin-b_fpn_1x_coco.py
7. 算法伪代码
def MonaAdapter(x0, down_proj, up_proj, convs, pw_conv, s1, s2):# 1. 归一化输入x_norm = s1 * LayerNorm(x0) + s2 * x0x = down_proj(x_norm)# 2. 多尺度深度卷积f_dw = x + sum([conv(x) for conv in convs]) / len(convs)# 3. 点卷积 + 非线性f_pw = x + pw_conv(f_dw)output = x0 + up_proj(GeLU(f_pw))return output
8. 总结与讨论
- Mona是目前唯一能在多个视觉任务中超越全参数微调的PEFT方法。
- 显著降低训练参数量(<5%),提升迁移效率,适应多尺度视觉感知。
- 其结构简单易实现,适合集成进现有ViT类结构。
- 可扩展性强:大模型越大,收益越高。
9. 引用
@article{yin2024mona,title={Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks},author={Yin, Dongshuo and Hu, Leiyi and Li, Bin and Zhang, Youqun and Yang, Xue},journal={arXiv preprint arXiv:2408.08345},year={2024}
}