Go语言底层(四): 深入浅出Go语言的ants协程池
在 Go 语言中,goroutine 的轻量特性使得高并发编程变得异常简单。然而,随着并发量的增加,频繁创建对象和无限制启动 goroutine 也可能带来内存浪费、GC 压力和资源抢占等问题。为了解决这些隐患,协程池成为常用的优化手段。用于控制并发数量、避免系统过载。本文将简要介绍golang 中大名鼎鼎的 ants 协程池库的实现原理。
ants包仓库 : https://github.com/panjf2000/ants
为什么用协程池?
- 提升性能:主要面向一类场景:大批量轻量级并发任务,任务执行成本与协程创建/销毁成本量级接近;
- 动态调配并发资源 : 能够动态调整所需的协程数量以及各个模块的并发度上限;
- 协程生命周期控制:实时查看当前全局并发的协程数量;有一个统一的紧急入口释放全局协程.
1. 使用方法
安装ants库
go get -u github.com/panjf2000/ants/v2
1.1 创建协程池 NewPool(size int)
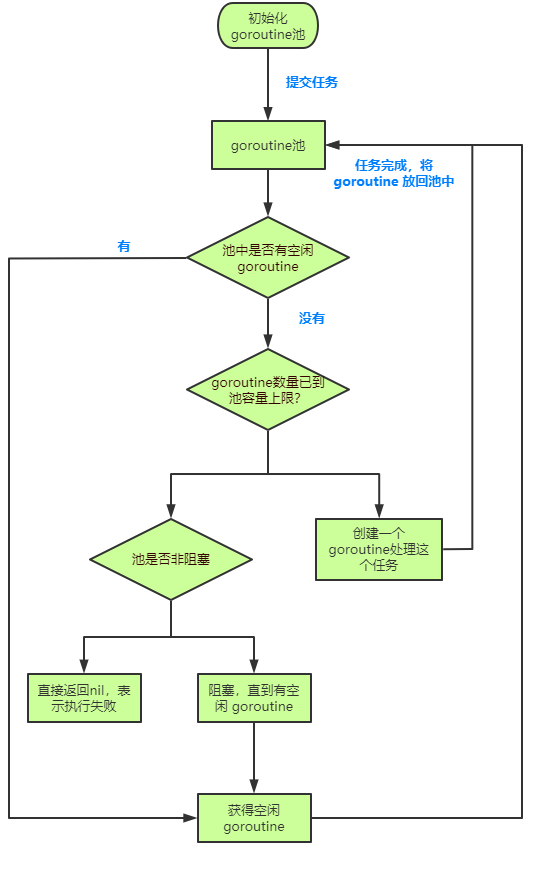
用于创建一个容量为 size 的协程池。默认情况下,协程池不会自动扩容,因此超出容量限制的任务会等待空闲 worker。
import "github.com/panjf2000/ants/v2"var pool *ants.Poolfunc init() {var err errorpool, err = ants.NewPool(10) // 创建容量为10的协程池if err != nil {log.Fatalf("Failed to create goroutine pool: %v", err)}
}
- NewPool() 返回的是一个可复用的固定容量协程池,内部通过任务队列与 worker 协同处理。
1.2 提交任务 Submit(task func())
协程池的核心方法
// Submit submits a task to the pool.
//
// Note that you are allowed to call Pool.Submit() from the current Pool.Submit(),
// but what calls for special attention is that you will get blocked with the last
// Pool.Submit() call once the current Pool runs out of its capacity, and to avoid this,
// you should instantiate a Pool with ants.WithNonblocking(true).
func (p *Pool) Submit(task func()) error
使用 Submit() 提交一个函数类型任务给协程池异步执行
示例 :
err := pool.Submit(func() {fmt.Println("Task executed by goroutine:", runtime.NumGoroutine())
})
if err != nil {log.Println("Failed to submit task:", err)
}
-
每次调用 Submit() 不会阻塞主线程。
-
如果当前运行的 goroutine 已达到上限,任务将等待空闲 worker。
1.3 释放协程池 Release()
释放协程池资源,释放后协程池不再接受新的任务提交。
pool.Release()
⚠️ 注意:一旦调用 Release(),协程池将被永久关闭,不能再次使用。再次提交任务将 panic。
1.4 查询当前运行数 Running()
适合用于实时监控协程池负载状态。
fmt.Printf("Running goroutines: %d\n", pool.Running())
适合用于实时监控协程池负载状态。
1.5 池容量
获取池容量 Cap()
返回协程池的最大容量(即最大 goroutine 数量)。可用于与 Running() 搭配分析使用率。
fmt.Printf("Pool capacity: %d\n", pool.Cap())
动态调整容量 Tune(newSize int)
在运行时动态调整协程池容量,适应系统负载变化。
pool.Tune(20) // 将容量调整为20
- 扩容会立即生效。
- 缩容后,多余的 worker 会在任务完成后自动回收。
- Tune() 不会中断正在执行的任务。
流程
2. 底层实现
原理篇前置知识
详细请看以往文章 : Go语言底层(三): sync 包锁与对象池
2.1 核心数据结构
2.1.1 goWorker
type goWorker struct {pool *Pooltask chan func()recycleTime time.Time
}
goWorker 就是我们协程池里的实例 , 简单理解为一个长时间运行而不回收的协程,用于反复处理用户提交的异步任务
-
pool:goWorker 所属的协程池;
-
task:goWorker 用于接收异步任务包的管道;
-
recycleTime:goWorker 回收到协程池的时间.
2.1.2 Pool
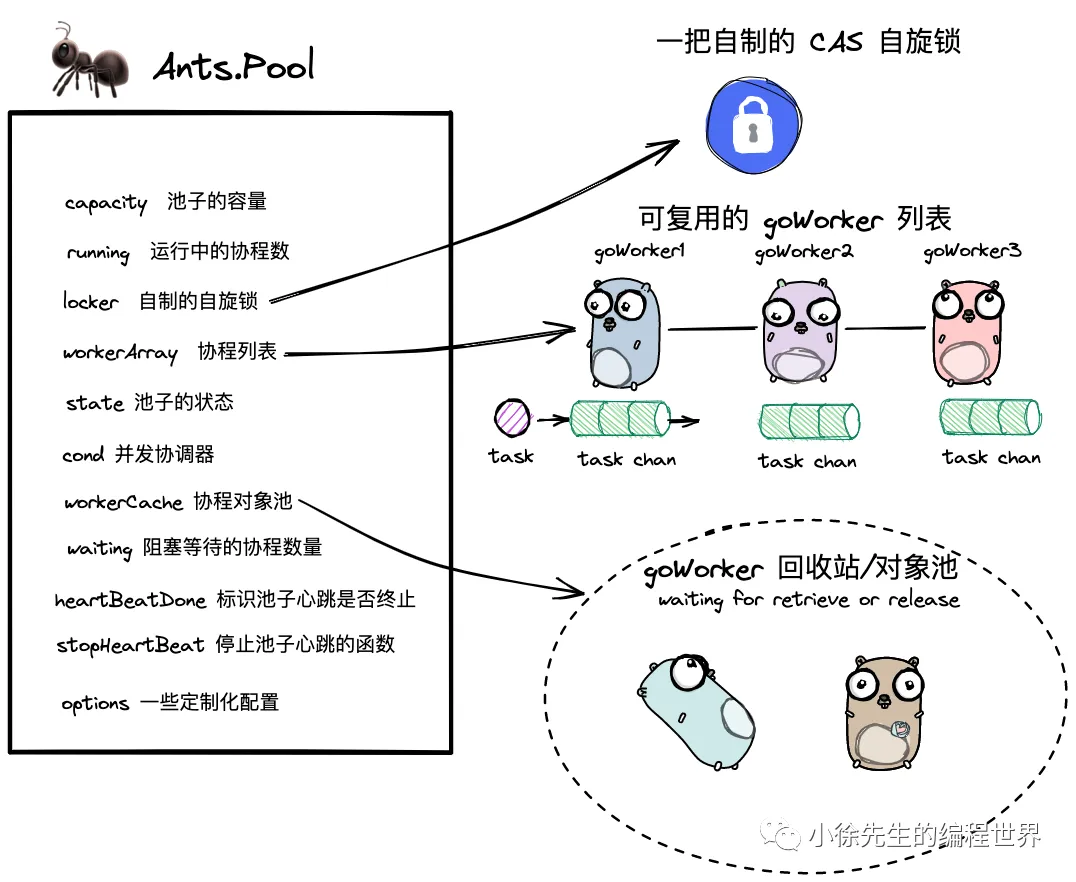
type Pool struct {capacity int32running int32lock sync.Lockerworkers workerArraystate int32cond *sync.CondworkerCache sync.Poolwaiting int32heartbeatDone int32stopHeartbeat context.CancelFuncoptions *Options
}
- capacity:池子的容量
- running:出于运行中的协程数量
- lock:自制的自旋锁,保证取 goWorker 时并发安全
- workers:goWorker 列表,即“真正意义上的协程池”
- state:池子状态标识,0-打开;1-关闭
- cond:并发协调器,用于阻塞模式下,挂起和唤醒等待资源的协程
- waiting:标识出于等待状态的协程数量;
- heartbeatDone:标识回收协程是否关闭;
- stopHeartbeat:用于关闭回收协程的控制器函数;
- options:一些定制化的配置.
- workerCache:存放 goWorker 的对象池,用于缓存释放的 goworker 资源用于复用. 对象池需要区别于协程池,协程池中的
goWorker 仍存活,进入对象池的 goWorker 逻辑意义已经销毁;
2.1.3 workerArray
type workerArray interface {len() intisEmpty() boolinsert(worker *goWorker) errordetach() *goWorkerretrieveExpiry(duration time.Duration) []*goWorkerreset()
}
该 interface 主要定义了作为数据集合的几个通用 api,以及用于回收过期 goWorker 的 api.
- insert 插入一个
goWorker - detach 取出一个
goWorker - retrieveExpiry 获取池中空闲时间超过 duration 的 已经过期的
goWorker集合 ,其中goWorker的回收时间与入栈先后顺序相关,因此可以借助binarySearch方法基于二分法快速获取到目标集合.
2.2 核心方法的实现
2.2.1 NewPool 创建协程池
func NewPool(size int, options ...Option) (*Pool, error) {// 读取用户配置,做一些前置校验,默认值赋值等前处理动作...opts := loadOptions(options...)// 构造好 Pool 数据结构;p := &Pool{capacity: int32(size),lock: internal.NewSpinLock(),options: opts,}// 构造对象池p.workerCache.New = func() interface{} {return &goWorker{pool: p,task: make(chan func(), workerChanCap),}}// 构造好 goWorker 对象池 workerCache,声明好工厂函数;p.workers = newWorkerArray(stackType, 0)// golang 标准库提供的并发协调器,用于实现指定条件下阻塞和唤醒协程的操作.p.cond = sync.NewCond(p.lock)// 异步启动 goWorker 过期销毁协程.var ctx context.Contextctx, p.stopHeartbeat = context.WithCancel(context.Background())go p.purgePeriodically(ctx)return p, nil
}
2.2.2 pool.Submit 提交任务
func (p *Pool) Submit(task func()) error {// 从 Pool 中取出一个可用的 goWorker;var w *goWorkerif w = p.retrieveWorker(); w == nil {return ErrPoolOverload}// 将用户提交的任务包添加到 goWorker 的 channel 中.w.task <- taskreturn nil
}
取出goWorker 的实现:
func (p *Pool) retrieveWorker() (w *goWorker) {// 声明了一个构造 goWorker 的函数 spawnWorker 用于兜底,从对象池 workerCache 中获取 goWorker;spawnWorker := func() {w = p.workerCache.Get().(*goWorker)w.run()}p.lock.Lock()// 尝试从池中取出一个空闲的 goWorker;w = p.workers.detach()if w != nil { p.lock.Unlock()// 倘若池子容量未超过上限, 从对象池中取出一个 goWorker } else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {p.lock.Unlock()spawnWorker()} else { // 倘若池子容量超限,且池子为非阻塞模式,直接抛回错误;if p.options.Nonblocking {p.lock.Unlock()return}// 倘若池子容量超限,且池子为阻塞模式,则基于并发协调器 cond 挂起等待有空闲 worker;retry:// 若阻塞任务已达最大限制,也直接返回;if p.options.MaxBlockingTasks != 0 && p.Waiting() >= p.options.MaxBlockingTasks {p.lock.Unlock()return}// 增加等待数并使用 cond 条件变量挂起当前协程;p.addWaiting(1)p.cond.Wait() // block and wait for an available workerp.addWaiting(-1)// 被唤醒后(可能是因为 scavenger 清理协程),判断是否还有运行中的 worker;var nw intif nw = p.Running(); nw == 0 { // awakened by the scavengerp.lock.Unlock()spawnWorker()return}// 再次尝试重新获取一个空闲 worker;if w = p.workers.detach(); w == nil {if nw < p.Cap() {p.lock.Unlock()spawnWorker()return}goto retry}// 获取到了可用 worker,解锁并返回;p.lock.Unlock()}return
}
2.2.3 goWorker 运行
func (w *goWorker) run() {w.pool.addRunning(1)go func() {defer func() {w.pool.addRunning(-1)w.pool.workerCache.Put(w)if p := recover(); p != nil {// panic 后处理}w.pool.cond.Signal()}()for f := range w.task {if f == nil {return}f()if ok := w.pool.revertWorker(w); !ok {return}}}()
- 循环 + 阻塞等待,直到获取到用户提交的异步任务包 task 并执行;
- 执行完成 task 后,会将自己交还给协程池;
- 倘若回归协程池失败,或者用户提交了一个空的任务包,则该 goWorker 会被销毁,销毁方式是将自身放回协程池的对象池 workerCache. 并且会调用协调器 cond 唤醒一个阻塞等待的协程.