C++开源协程库async_simple有栈协程源码分析
为什么需要使用协程
假设我们有一个任务T0,该任务需要开启一个线程来执行。在C++中,我们通常会写出如下的代码:
std::thread t0([](){// 任务T0的代码
});
t0.detach();来运行T0。
若是T0在运行的过程中,因为某些操作(比如:等待互斥锁、条件变量或者文件描述符没有可读事件)暂时不能够执行时。
你想啊,任务本身还不满足往下执行的条件,那还执行它干嘛,让它在线程中白白浪费CPU资源吗?
因此,为了不浪费CPU资源,线程一般都会自行陷入阻塞状态,让其他线程获得CPU以执行其他任务,等待T0一切就绪准备好执行后面的代码之后,才在此调度T0。
当任务的数量非常大的时候,取个极端的例子,比如有100万个任务的时候,我们需要并发地执行这些任务,那么就可能需要开启100万个线程,每个线程运行一个任务。
当这些任务线程发生阻塞或者任务执行完成之后,必然会发生线程的上下文切换,而线程的上下文切换要求程序陷入内核态才能完成。
因此,大量的任务线程也就意味着将会有非常频繁的线程上下文切换,程序需要频繁地陷入内核态。这样的开销会积少成多,减慢任务的完成效率。
因此,我们需要减少这种开销。可以考虑减少线程上下文切换来减少这种开销:
- 减少用于完成任务的线程的数量。线程少了那么必然就会导致线程的上下文切换的次数变少,但如果不采用额外的措施的话,少了线程也就意味着对于任务的吞吐量会有一定程度的减小。
- 引发线程上下文切换的原因是:任务阻塞和任务完成。可以在任务阻塞的时候,暂停该任务去执行其他任务,该任务准备好之后重新执行它;可以在任务完成之后,依旧不放弃CPU资源,继续去运行其他待运行的任务。通过减少任务阻塞/任务完成的事件,从而减少线程上下文切换的次数,以此来减少上下文切换的开销。
通过以上两种方式,若有100万个任务,那么我们就可以使用1万个线程,每个线程能调度100个任务的方式,达成减少线程上下文切换的开销的目的,并且不低于原本100万个线程时处理任务的效率。
我们仔细琢磨一下第2个点:“任务阻塞时,暂停该任务去执行其他任务;任务完成时,依旧不放弃CPU继续去运行其他待运行的任务”。对于我们使用线程时的:“线程阻塞时,陷入内核态进行线程上下文切换去执行其他线程;线程完成时,依旧不放弃CPU继续调度其他线程”。
可以发现,本来内核所扮演的角色,被线程取代了;本来由线程所扮演的角色则由任务取代了。这里所说的任务只是一个抽象概念,因为任务可暂停因此我们必然是需要存储该任务执行的状态的一些信息,这些信息就是其上下文。这里所说的“任务”其实就是协程。这也是协程被称为用户态线程的原因。
如何实现协程
单纯的函数调用
我们知道在C++在C++20标准之前标准库中是没有协程的,但这并不意味着我们无法自己实现协程。
先从函数调用说起吧,大家觉得能否通过单纯的函数调用(即我们不插手修改编译器实现,不使用汇编级代码的函数调用)实现协程。
我们就假设单纯的函数调用能够实现协程。下面假设我们只有一个线程T0,和一个要执行的任务队列[m1,m2,m3,m4]。
在线程T0中,我们首先会从任务队列中取出任务m1,然后调用该任务,此时该线程的运行栈的大致内存分布如下:
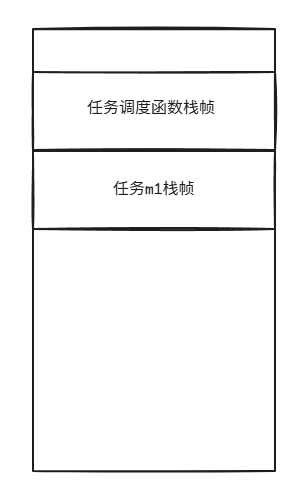
任务调度函数可能是这样的:
void schedule() {while(!task_queue.empty()) {auto task = std::move(task_queue.front());task_queue.pop_front();task();}
}若任务1能够直接完成,不带任何阻塞,那么这些任务能够完美地利用CPU资源。但如果这些任务在执行的过程中都有可能会因为某些原因无法继续往下执行(等待互斥锁、等待可读事件等),那么该如何暂停该任务的执行呢?
在暂停的地方先去执行其他任务,等待其他任务执行完之后再回来执行:
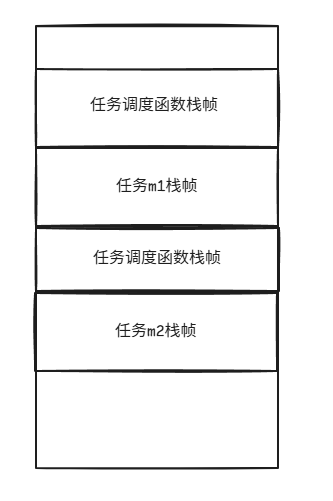
如果任务m2能够再阻塞,那么按照相同的做法它会等待完成m3执行完成。如果任务m2能够直接完成,然后回来执行任务m1并且刚好任务m1满足继续执行的条件,那么确实是很好的;但如果任务m1还没有处于可继续运行的状态,那么它可能需要继续调度其他任务。
但如果任务m2阻塞,它就会去调度新任务,但任务m2阻塞的时候,任务m1已经满足执行的条件了,能不能够去执行任务m1?不能够,因为这样的话表示任务m2的栈帧没了,也就意味着任务m2执行的上下文没了,那就无法恢复m2的执行了。因此,最终就会形成这样的调用链:

这条链上的任务数量可能远不止5个,可能会有几十个。当正在运行的那个任务遇到阻塞时,它会添加新任务,而不能够去运行之前的任务,因为会导致任务上下文的丢失,一些任务将无法被完成。我们确实没有浪费CPU资源,但这样的调用链使得原本应该得到及时处理的任务迟迟完成不了,从而降低任务的吞吐量。并且在任务量大的情况下,大量任务的压栈可能会导致栈溢出。
因此,用单纯的函数调用来实现协程,实现出来的机制不仅不能提高任务处理的效率,反而降低了任务处理的效率,这与我们的原本的目的相违背。
不单纯的函数调用
单纯函数调用出现问题的根本原因在于:后面的任务函数栈帧如果想要回到之前的函数栈帧(已经不阻塞了),那么就必然会导致任务函数栈帧的丢失。
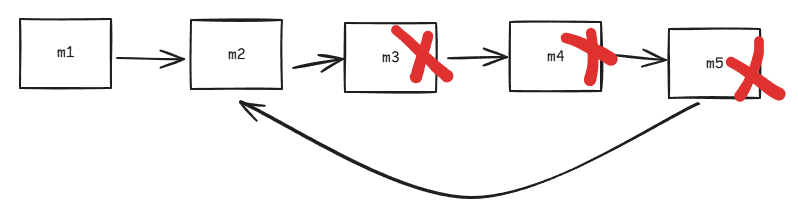
如果我们可以解开这种依赖关系,使得m5自身让出执行权给m2的前提下,m3、m4和m5的栈帧上下文不会因此丢失。
那么就可以避免单纯函数调用会出现的问题。
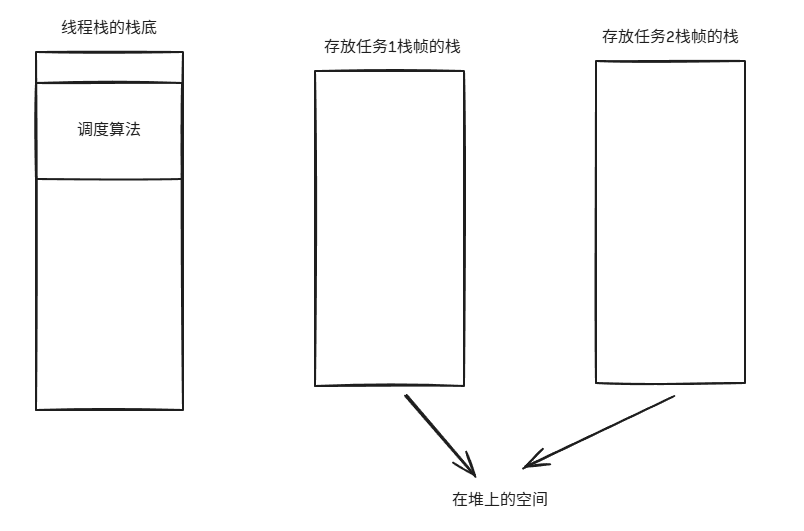
我来粗略地描述一下调度算法干了什么:
- 调度算法中会有一个循环,它从任务队列A中获取到任务1并为其申请独立的栈;
- 然后,会将当前调度算法的上下文信息压入栈中,将执行栈变为任务1的栈,然后弹出上下文信息,运行任务函数;
- 若任务1暂停,则会回到线程栈中,弹出之前压入栈中的上下文信息;
- 判断任务是否执行完成,若没有执行完成,则放入另外一个队列B中等待再次调度;
通过调度算法 + 每个任务拥有一个栈并存储于堆上的方式,解开了任务与任务之间的依赖关系,从而解决了单纯的函数调用的缺陷。
但是上述机制说起来容易,做起来难,涉及到的细节非常多并且不好理解。
请注意,上述说的是协程的实现思路,与async_simple中有栈协程的实现有一定相似性,但并非完全相同。
我们自己实现一套这样的机制我感觉还是有点困难的。但只是学习别人的实现,难度就降低了不止一个档次了。本篇文章主要是研究async_simple协程库是如何实现有栈协程的。
async_simple的Uthread模块
他们自己对该模块的描述是:
async_simple作为C++协程库,不仅支持基于C++20标准的无栈协程,还支持基于上下文交换的有栈协程uthread。 uthread类似于业界其他有栈协程,通过保存当前A协程上下文寄存器和栈,恢复B协程寄存器和栈等信息实现多任务协作式运行。
uthread 来自于 boost 库。
他们所给的Uthread文档中只描述了Uthread的用法,并没有提到具体是如何实现的。那么我只要自动动手查看了。
Uthread的核心我认为是位于async_simple/uthread/internal/thread_impl.h文件中的两个函数:
extern "C" __attribute__((__visibility__("default")))
transfer_t _fl_jump_fcontext(fcontext_t const to, void* vp);extern "C" __attribute__((__visibility__("default")))
fcontext_t _fl_make_fcontext(void* sp, std::size_t size, void (*fn)(transfer_t));这两个函数不是来自什么第三方库,也不是Linux的系统调用,也不是C/C++的函数。因为它是使用纯汇编来实现的,它拥有不同CPU架构的实现
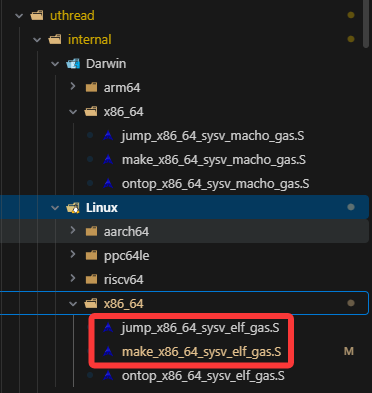
红色框中,jump开头的是_fl_jump_fcontext的实现;make开头的是_fl_make_fcontext的实现。
我这里以研究Linux/x86_64的汇编实现为例,其他的虽然代码不一样但思路应该都是一致的。
_fl_make_fcontext
typedef void* fcontext_t;struct transfer_t {fcontext_t fctx;void* data;
};fcontext_t _fl_make_fcontext(void* sp, std::size_t size, void (*fn)(transfer_t));源码中使用到_fl_make_fcontext函数的只有一个地方:
void thread_context::setup() {context_.fcontext = _fl_make_fcontext(stack_.get() + stack_size_,stack_size_, thread_context::s_main);...
}这里的stack_你可以理解为一个unique_ptr它是一个char*类型的指针。而stack_size_是stack_指向的内存空间的大小
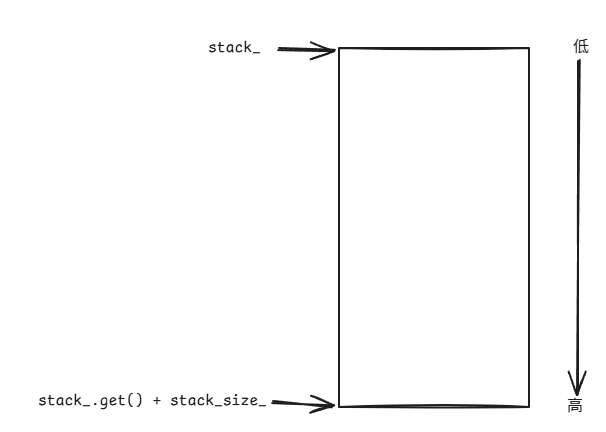
因此,我们可以确定_fl_make_fcontext接收的参数应该是:
void* sp,指向一片内存空间的尾部地址。std::size_t size,内存空间的大小。void (*fn)(transfer_t),一个函数指针。后面会说这个函数指针将会被怎样使用。
但返回值是什么我们暂且不知道。接下来我们就需要研究其汇编实现。
/*Copyright Oliver Kowalke 2009.Distributed under the Boost Software License, Version 1.0.(See accompanying file LICENSE_1_0.txt or copy athttp://www.boost.org/LICENSE_1_0.txt)
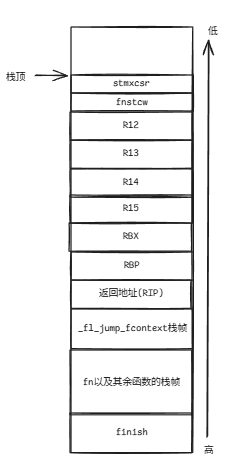
*//***************************************************************************************** ** ---------------------------------------------------------------------------------- ** | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ** ---------------------------------------------------------------------------------- ** | 0x0 | 0x4 | 0x8 | 0xc | 0x10 | 0x14 | 0x18 | 0x1c | ** ---------------------------------------------------------------------------------- ** | fc_mxcsr|fc_x87_cw| R12 | R13 | R14 | ** ---------------------------------------------------------------------------------- ** ---------------------------------------------------------------------------------- ** | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | ** ---------------------------------------------------------------------------------- ** | 0x20 | 0x24 | 0x28 | 0x2c | 0x30 | 0x34 | 0x38 | 0x3c | ** ---------------------------------------------------------------------------------- ** | R15 | RBX | RBP | RIP | ** ---------------------------------------------------------------------------------- ** *****************************************************************************************/.text
.globl _fl_make_fcontext
.type _fl_make_fcontext,@function
.align 16
_fl_make_fcontext:/* first arg of make_fcontext() == top of context-stack */movq %rdi, %rax/* shift address in RAX to lower 16 byte boundary */andq $-16, %rax/* reserve space for context-data on context-stack *//* on context-function entry: (RSP -0x8) % 16 == 0 */leaq -0x40(%rax), %rax/* third arg of make_fcontext() == address of context-function *//* stored in RBX */movq %rdx, 0x28(%rax)/* save MMX control- and status-word */stmxcsr (%rax)/* save x87 control-word */fnstcw 0x4(%rax)/* compute abs address of label trampoline */leaq trampoline(%rip), %rcx/* save address of trampoline as return-address for context-function *//* will be entered after calling jump_fcontext() first time */movq %rcx, 0x38(%rax)/* compute abs address of label finish */leaq finish(%rip), %rcx/* save address of finish as return-address for context-function *//* will be entered after context-function returns */movq %rcx, 0x30(%rax)ret /* return pointer to context-data */trampoline:/* store return address on stack *//* fix stack alignment */push %rbp/* jump to context-function */jmp *%rbxfinish:/* exit code is zero */xorq %rdi, %rdi/* exit application */call _exit@PLThlt
.size _fl_make_fcontext,.-_fl_make_fcontext/* Mark that we don't need executable stack. */
.section .note.GNU-stack,"",%progbits以上就是make_x86_64_sysv_elf_gas.S文件的内容,虽然我本身不是很懂汇编,但我从:
.text
.globl _fl_make_fcontext
.type _fl_make_fcontext,@function
.align 16大概了解到它声明一个函数,并猜测.globl应该是为了C语言中可以使用extern可以引入该函数。而.align 16则是声明了内存对齐的方式16字节对齐,即64位对齐。
接下来我们正式研究_fl_make_fcontext的代码段:
/* first arg of make_fcontext() == top of context-stack */movq %rdi, %rax由于_fl_make_fcontext在C语言程序中会以函数的形式被调用,而默认情况下,参数的传递遵循以下规则:
- 第一个参数存储在
%rdi寄存器中。 - 第二个参数存储在
%rsi寄存器中。 - 第三个参数存储在
%rdx寄存器中。 - 第四个参数存储在
%rcx寄存器中。 - 第五个参数存储在
%r8寄存器中。 - 第六个参数存储在
%r9寄存器中。
如果函数有超过6个参数,从第7个参数开始,这些参数会通过栈来传递。具体来说第7个参数会被压入栈中,第8个参数会紧接着压入栈中,以此类推。
因此,void* sp会存储在%rdi中,std::size_t size会存储在%rsi中,void (*fn)(transfer_t)会存储在%rdx中。
movq %rdi, %rax则是将第一个参数sp(即指向内存区域的尾部地址的指针),传递给了寄存器%rax。
/* shift address in RAX to lower 16 byte boundary */andq $-16, %rax这里将低4位置0,保证后面存储信息时16字节对齐。用图像表示为:
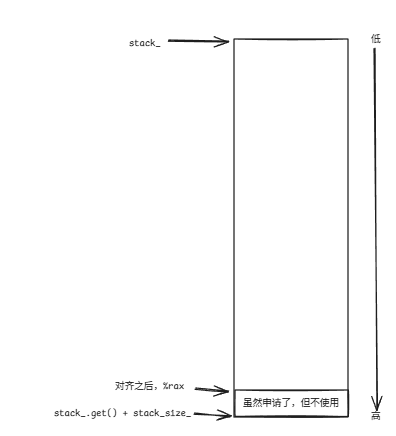
此时%rax即指向栈底,也指向栈顶。但主要目的是让%rax指向栈顶
/* reserve space for context-data on context-stack *//* on context-function entry: (RSP -0x8) % 16 == 0 */leaq -0x40(%rax), %rax这一步操作让栈顶下降0x40个字节,对于栈来说,它是从高地址往低地址增长的,因此这一步是增长了0x40个字节。
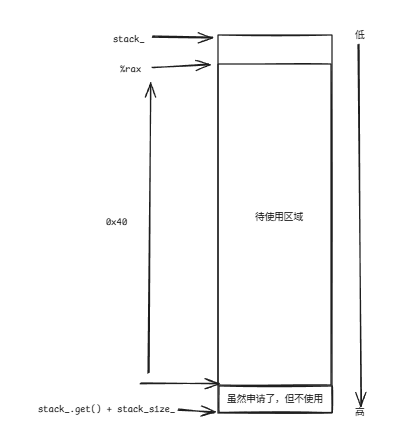
/* third arg of make_fcontext() == address of context-function *//* stored in RBX */movq %rdx, 0x28(%rax)movq %rdx, 0x28(%rax)第三个参数函数指针fn存储在比%rax高0x28个字节的区域。它自身占用了16字节:
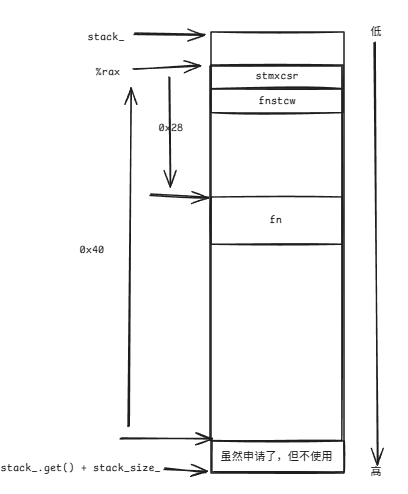
/* save MMX control- and status-word */stmxcsr (%rax)/* save x87 control-word */fnstcw 0x4(%rax)stmxcsr和fnstcw这两条命令存储一些寄存器信息。知道有这么个东西就行,因为这是为了符合原有的压栈和弹栈规则而存在的。
/* compute abs address of label trampoline */leaq trampoline(%rip), %rcx/* save address of trampoline as return-address for context-function *//* will be entered after calling jump_fcontext() first time */movq %rcx, 0x38(%rax)/* compute abs address of label finish */leaq finish(%rip), %rcx/* save address of finish as return-address for context-function *//* will be entered after context-function returns */movq %rcx, 0x30(%rax)trampoline和finish是此文件中定义的两个标签,如果想要使用标签来获得其地址,那么就需要使用leaq trampoline(%rip), %rcx的方式来获取标签所代表的绝对地址。将trampoline的绝对地址存储在%rcx后再转存到0x38(%rax)中。最终其内存分布将如下图所示:
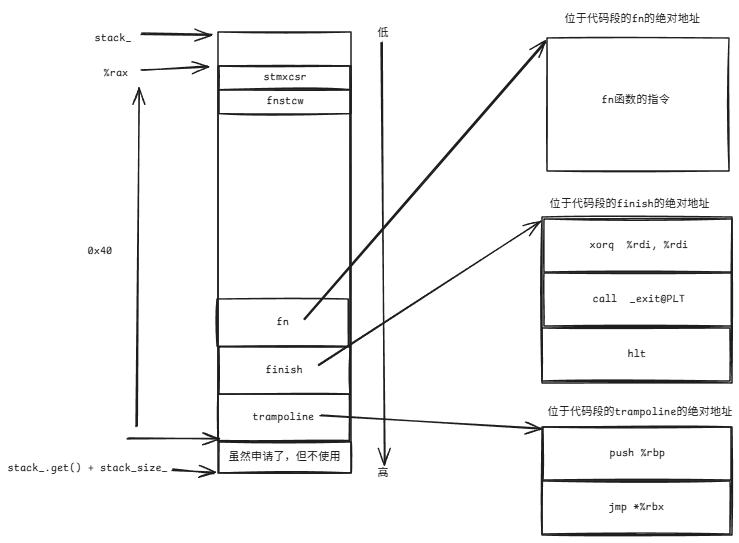
我们可以观察到文件开头的注释:
/***************************************************************************************** ** ---------------------------------------------------------------------------------- ** | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ** ---------------------------------------------------------------------------------- ** | 0x0 | 0x4 | 0x8 | 0xc | 0x10 | 0x14 | 0x18 | 0x1c | ** ---------------------------------------------------------------------------------- ** | fc_mxcsr|fc_x87_cw| R12 | R13 | R14 | ** ---------------------------------------------------------------------------------- ** ---------------------------------------------------------------------------------- ** | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | ** ---------------------------------------------------------------------------------- ** | 0x20 | 0x24 | 0x28 | 0x2c | 0x30 | 0x34 | 0x38 | 0x3c | ** ---------------------------------------------------------------------------------- ** | R15 | RBX | RBP | RIP | ** ---------------------------------------------------------------------------------- ** *****************************************************************************************/这里面说明的是什么我来解释一下:
- 栈顶 + 0x0地址开始的4个字节,在恢复时将会存储在
fc_mxcsr对应的寄存器中。 - 栈顶 + 0x4地址开始的4个字节,在恢复时将会存储在
fc_x87_cw对应的寄存器中。 - 栈顶 + 0x8地址开始的8个字节,在恢复时将会存储在
R12寄存器中。 - 栈顶 + 0x10地址开始的8个字节,在恢复时将会存储在
R13寄存器中。 - 栈顶 + 0x18地址开始的8个字节,在恢复时将会存储在
R14寄存器中。 - 栈顶 + 0x20地址开始的8个字节,在恢复时将会存储在
R15寄存器中。 - 栈顶 + 0x28地址开始的8个字节,在恢复时将会存储在
RBX寄存器中。 - 栈顶 + 0x30地址开始的8个字节,在恢复时将会存储在
RBP寄存器中。 - 栈顶 + 0x38地址开始的8个字节,在恢复时将会存储在
RIP寄存器中。
这里要说明的是,将一个值存储在RIP寄存器中,也就意味着发生跳转操作。
我们可以猜测到的是,若对一个刚刚构造好的栈执行一次恢复操作,首先会执行1-8操作,fn的地址会在%rbx中,而finish的地址会在%rbp中。
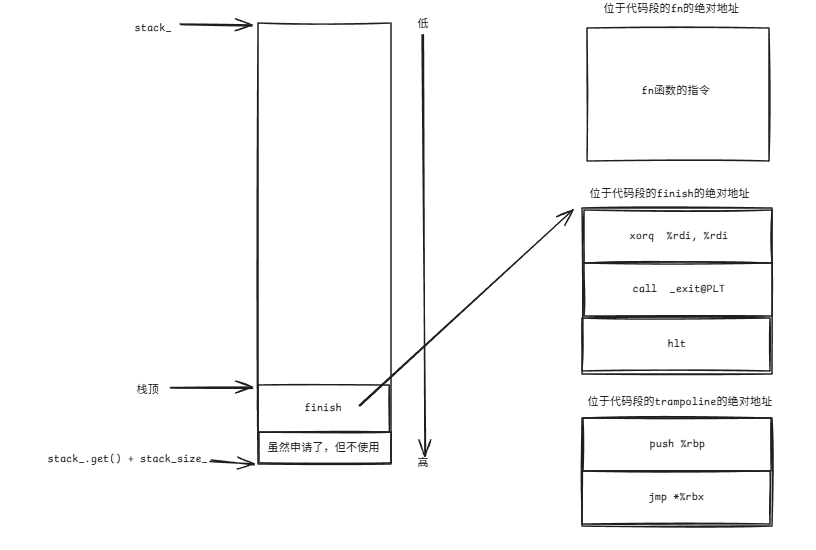
执行到9操作时,会跳转去执行trampoline的指令,即:
/* store return address on stack *//* fix stack alignment */push %rbp/* jump to context-function */jmp *%rbx此时%rbp内存储的是finish地址,因此栈的内容会变成:
由于%rbx存储的是fn的地址,因此会跳转去运行fn函数,之后函数调用就会引发新的内容压栈:
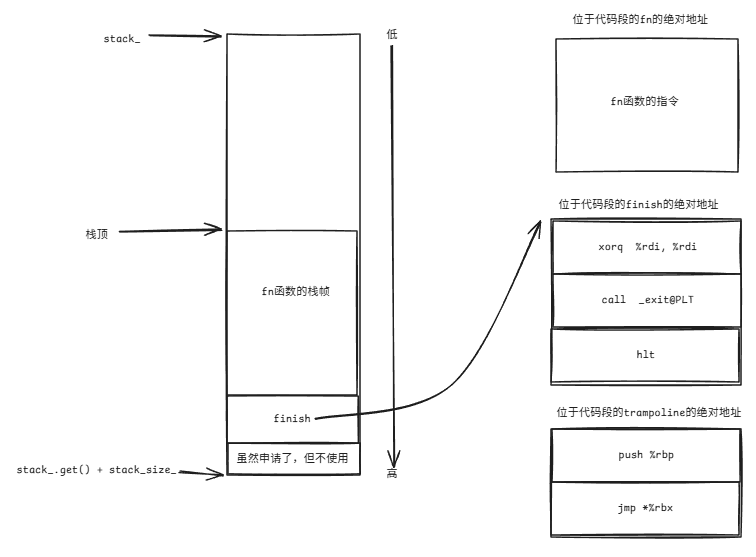
函数fn的参数是如何进行传递的需要去了解_fl_jump_fcontext的实现。
_fl_jump_fcontext
transfer_t _fl_jump_fcontext(fcontext_t const to, void* vp);to是要跳转到的协程的独立栈的栈顶。vp是要传递给void(*fn)(transfer_t)函数的transfert_t的data字段。
这个函数的返回值并不像普通函数的返回值那样。一些和_fl_make_fcontext类似的部分我就不介绍了,主要说它独有的。
如果我们在C程序中调用_fl_jump_fcontext函数,首先它会将要传递的参数存在寄存器中:
to ->%rdivp ->%rsi
然后执行call _fl_jump_fcontext指令,该指令会将其后面一条指令的地址入栈,然后跳转到_fl_jump_fcontext函数体中。
即此时,栈的内存分布将是:
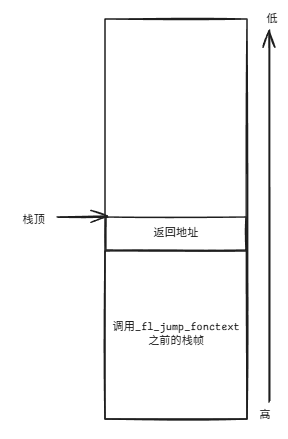
接下来才会执行:
leaq -0x38(%rsp), %rsp /* prepare stack */此时将会变成:
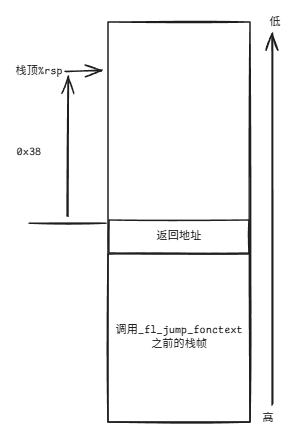
然后按照顺序存储寄存器信息:
#if !defined(ASYNC_SIMPLE_USE_TSX)stmxcsr (%rsp) /* save MMX control- and status-word */fnstcw 0x4(%rsp) /* save x87 control-word */
#endifmovq %r12, 0x8(%rsp) /* save R12 */movq %r13, 0x10(%rsp) /* save R13 */movq %r14, 0x18(%rsp) /* save R14 */movq %r15, 0x20(%rsp) /* save R15 */movq %rbx, 0x28(%rsp) /* save RBX */movq %rbp, 0x30(%rsp) /* save RBP */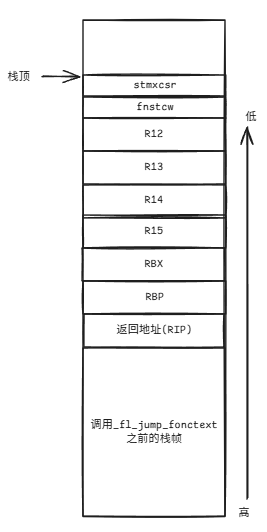
因此,如果我们在一个线程或者协程上调用_fl_jump_fcontext,它的栈首先会压入上下文信息。此时如果别人保存有这个栈的栈顶指针,那么就能够使用_fl_jump_fcontext(栈顶地址,vp)来恢复该线程或者协程的上下文,从而达成恢复执行的目的。
上面我们演示了调用了_fl_jump_fcontext的线程或者协程的变化情况,接下来就来演示对于_fl_jump_fcontext(to, vp);to所指向协程(即要恢复执行的协程的栈顶)是怎样恢复上下文的。
(1)启动协程。
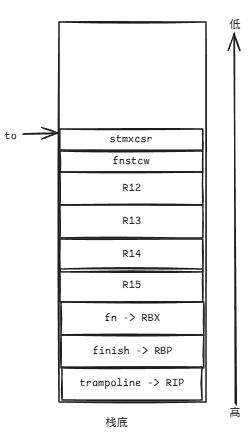
我忽略了因对齐而未使用的区域。
如果一个协程从未执行过,那么其栈的内存分布状况应该如上图所示。
/* store RSP (pointing to context-data) in RAX */movq %rsp, %rax此时,原本调用_fl_jump_fcontext的栈顶地址将会存储在%rax中。
/* restore RSP (pointing to context-data) from RDI */movq %rdi, %rsp然后%rdi内存储的to指针,即要恢复执行的协程的栈顶地址将会变成新的执行栈栈顶(因为%rsp所指即为执行栈栈顶)。
movq 0x38(%rsp), %r8 /* restore return-address */首先取出返回地址,即trampoline的地址,存储在%r8。
然后从栈中依次取出r12,r13,r14,r15,rbx,rbp:
movq 0x8(%rsp), %r12 /* restore R12 */movq 0x10(%rsp), %r13 /* restore R13 */movq 0x18(%rsp), %r14 /* restore R14 */movq 0x20(%rsp), %r15 /* restore R15 */movq 0x28(%rsp), %rbx /* restore RBX */movq 0x30(%rsp), %rbp /* restore RBP */最后完成弹栈操作:
leaq 0x40(%rsp), %rsp /* prepare stack */内存分布变为:

/* return transfer_t from jump *//* RAX == fctx, RDX == data */movq %rsi, %rdx/* pass transfer_t as first arg in context function *//* RDI == fctx, RSI == data */movq %rax, %rdi对于用_fl_jump_fcontext而言,我们只需要关注“参数传递”即可,因为这个时候返回值是用不上的。
%rax ->%rdi -> transfer_t.fctx,该fctx指向的是启动该协程的“协程”或者“线程”的栈的栈顶(最顶上的栈帧是暂停栈帧)。%rsi -> transfer_t.data,来自_fl_jump_fcontext(to,vp);
这两个参数将会传递给等下调用的void(*fn)(transfer_t)。
/* indirect jump to context */jmp *%r8此时%r8存储的是trampoline的绝对地址,因此会跳转去执行以下指令:
trampoline:/* store return address on stack *//* fix stack alignment */push %rbp/* jump to context-function */jmp *%rbx首先会将%rbp入栈,即finish的绝对地址将会入栈。然后跳转到%rbx指向的地址,即fn函数的地址。
这代表fn函数执行完之后的返回地址是finish指向的指令,也就是说如果协程执行完fn函数整个程序就会因为执行了finish而停止。但我们后面可以看到,async_simple在fn函数中编写的逻辑保证了fn函数在执行完之前就主动切换出去启动它的线程或者协程中,从而确保了finish永远不会执行。
由于%rdi和%rsi的内容未改变,因此参数会传递到fn函数中被使用。
(2)恢复协程。
首先会调用_fl_jump_fcontext的线程或者协程会像之前启动协程那样在栈中保存上下文。
但被恢复的协程的栈就不像启动协程那样,其大致内存分布应该是:
唯一不同的是,恢复协程时,参数传递将不再起作用,而由于暂停是由于_fl_jump_fcontext产生的,恢复之后必然是执行_fl_jump_fcontext的返回值赋值操作。因此这个时候返回就有效了。那么返回值是什么呢?
%rax -> transfert_t.fctx,恢复本协程的其他协程/线程的栈顶地址。%rdx -> transfert_t.data,作为返回值时不会被使用。
总结_fl_make_fcontext和_fl_jump_fcontext
fcontext_t _fl_make_fcontext(void* sp, std::size_t size, void (*fn)(transfer_t));功能:使用给定的内存空间,构造一个用于协程启动的栈帧,fn函数是这个协程启动时执行的函数。
参数:
sp,内存空间的尾部地址。size,内存空间的大小。fn,函数指针。
返回值:构造完启动栈帧后,协程栈的栈顶。
transfer_t _fl_jump_fcontext(fcontext_t const to, void* vp);功能:to是某个协程的协程栈栈顶,若该协程还未正式启动,则会将vp作为data字段,而当前协程或线程暂停后的栈顶将会作为fctx字段传递给fn函数;若该写成已启动,则data和fctx将会作为_fl_jump_fcontext的返回值返回给被暂停的协程/线程。
参数:
to,要启动/恢复执行的协程。vp,启动协程时传递给fn函数的transfert_t的data指针。
返回值:
- 在当前协程调用
_fl_jump_fcontext会导致当前协程暂停,若其他协程恢复当前协程的运行,则返回值中的fctx字段会存储调用_fl_jump_fcontext恢复当前协程运行的其他协程的协程栈的栈顶。
_fl_make_fcontext还属于函数调用的范畴;但是_fl_jump_fcontext的返回值机制就比较抽象了,返回值是由恢复该协程的其他协程来决定。恢复者可能是任何协程。
Uthread
在前面的源码解析中,相信大家都对_fl_make_fcontext和_fl_jump_fcontext这两个函数都有一定的了解了。
以此为基础,我们完全可以自顶向下地了解Uthread是如何实现的。
Uthread的使用类似于std::thread的使用,比如说std::thread在构造的时候也就意味着线程开始执行。而Uthread在构造的时候也就意味着当前线程/协程暂停,去执行新的协程。
因此,我们来看Uhtread的构造函数,看看它是如何启动协程的:
Uthread(Attribute attr, Func&& func) : _attr(std::move(attr)) {_ctx = std::make_unique<internal::thread_context>(std::move(func),_attr.stack_size);}attr就是一个结构体:
struct Attribute {Executor* ex;size_t stack_size = 0;
};它和启动协程无关。因此,启动协程的关键应该在ctx_的创建上,从代码中我们可以看出来ctx_是一个internal::thread_context类对象,使用unique_ptr指向该对象。
因此,协程的启动应该和thread_context的构造有关:
thread_context::thread_context(std::function<void()> func, size_t stack_size): stack_size_(stack_size ? stack_size : get_base_stack_size()),func_(std::move(func)) {setup();
}thread_context的构造函数如上。它定义了协程栈的大小stack_size_以及回调函数func_。
看名字就可以猜测出来,协程的启动应该在setup()函数中:
void thread_context::setup() {context_.fcontext = _fl_make_fcontext(stack_.get() + stack_size_,stack_size_, thread_context::s_main);context_.thread = this;
#ifdef AS_INTERNAL_USE_ASANcontext_.asan_stack_bottom = stack_.get() + stack_size_;context_.asan_stack_size = stack_size_;
#endifcontext_.switch_in();
}可以看到,首先调用了_fl_make_fcontext函数构造协程栈,其启动函数为thread_context::s_main。
然后设置了几个变量,最后调用了context_.switch_in()函数:
inline void jmp_buf_link::switch_in() {link = std::exchange(g_current_context, this);if (!link)AS_UNLIKELY { link = &g_unthreaded_context; }void *stack_addr = nullptr;start_switch_fiber(this, &stack_addr);// `thread` is currently only used in `s_main`fcontext = _fl_jump_fcontext(fcontext, thread).fctx;finish_switch_fiber(link, stack_addr);
}这里的重点就在于_fl_jump_fonctext切换到新协程中。
通过观察我发现,协程的暂停和恢复,与jmp_buf_link中的switch_in和switch_out方法有着密切的联系。
分析switch_in和switch_out的功能
有下面这样一个场景:
- 主线程创建一个协程1,调用
switch_in启动协程1。 - 协程1运行一段时间,创建一个协程2,此时会调用
switch_in跳转到协程2执行。 - 协程2执行一段时间后,调用
switch_out恢复协程1的执行。 - 协程1运行一段时间后,调用
switch_in恢复了协程2的执行。 - 协程2执行完毕,调用
final_switch_out恢复协程1的执行。 - 协程1执行完毕,调用
final_switch_out恢复主线程的执行。
(1)主线程创建一个协程1。
这意味着在主线程的运行栈中,必然存在以下变量:
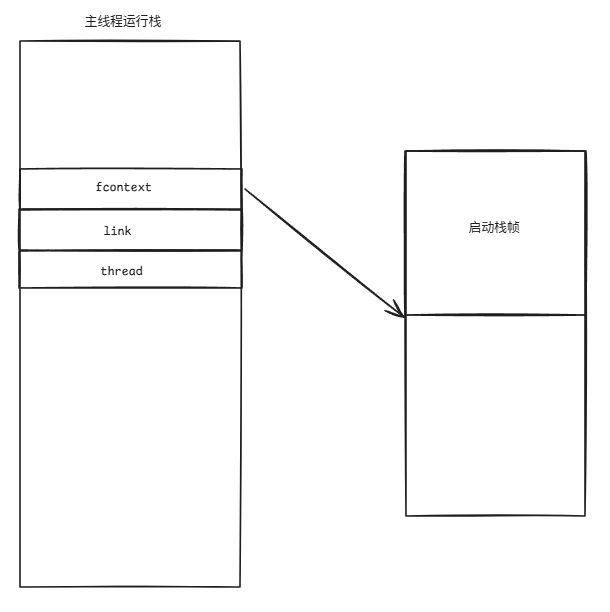
此时调用switch_in:
inline void jmp_buf_link::switch_in() {link = std::exchange(g_current_context, this);if (!link)AS_UNLIKELY { link = &g_unthreaded_context; }void *stack_addr = nullptr;start_switch_fiber(this, &stack_addr);// `thread` is currently only used in `s_main`fcontext = _fl_jump_fcontext(fcontext, thread).fctx;finish_switch_fiber(link, stack_addr);
}调用_fl_jump_fcontext(fcontext, thread)时,会暂停主线程,然后去运行协程1,此时主线程的switch_in()其实还没有对fcontext执行赋值操作。
因此,当协程1开始执行时,运行栈的内存状况应该是这样的:
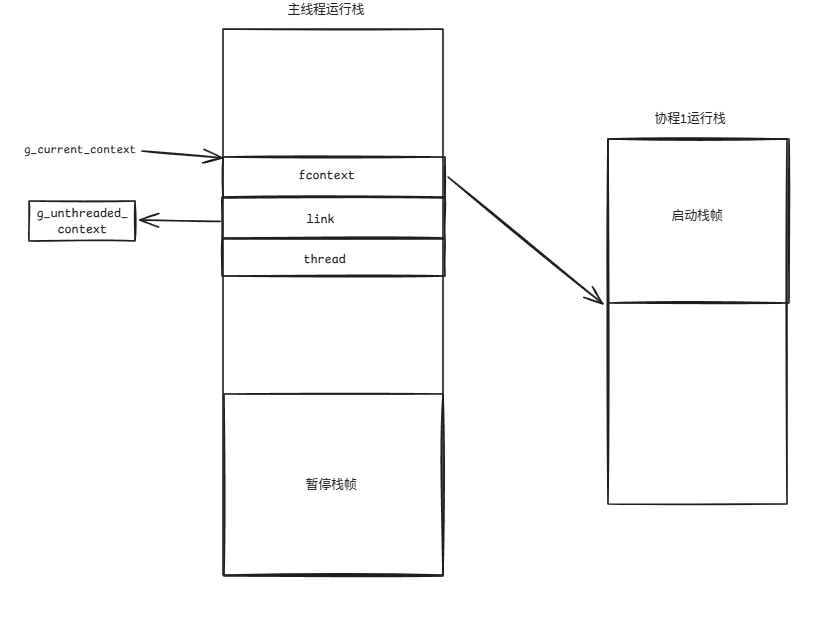
(2)协程1运行一段时间,创建一个协程2,此时会调用switch_in跳转到协程2执行。
同理,当协程2开始运行时,内存分布应为:
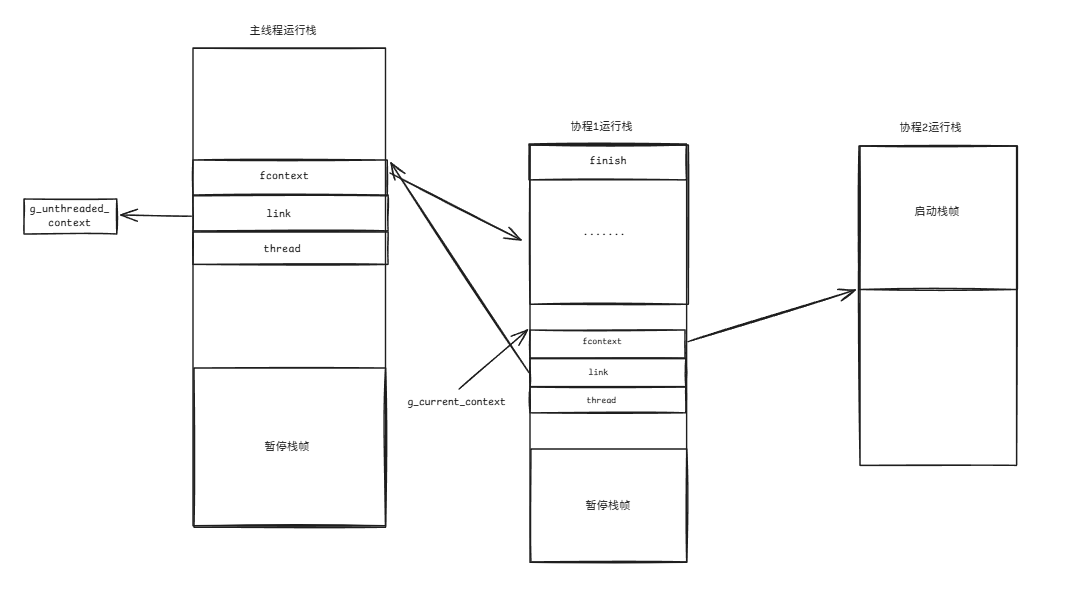
(3)协程2执行一段时间后,调用switch_out恢复协程1的执行。
inline void jmp_buf_link::switch_out() {g_current_context = link;void *stack_addr = nullptr;start_switch_fiber(link, &stack_addr);link->fcontext = _fl_jump_fcontext(link->fcontext, thread).fctx;finish_switch_fiber(this, stack_addr);
}此时,协程1原本被暂停的switch_in将会得到执行,因此对于其fcontext的更新将会得到兑现。
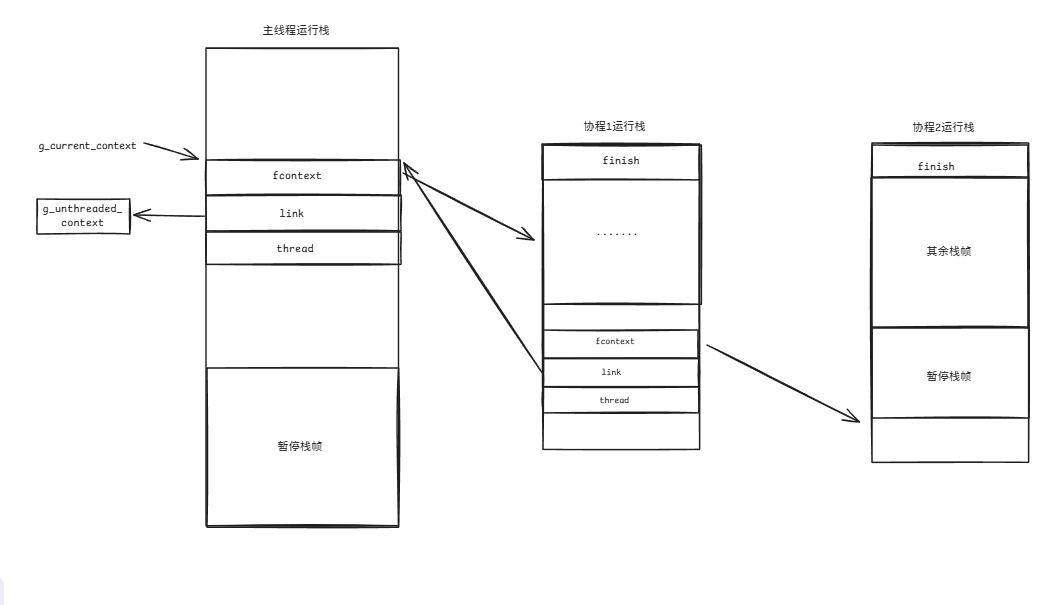
(4)协程1运行一段时间后,调用switch_in恢复了协程2的执行。
此时原本switch_out得到恢复link->fcontext将得到更新:
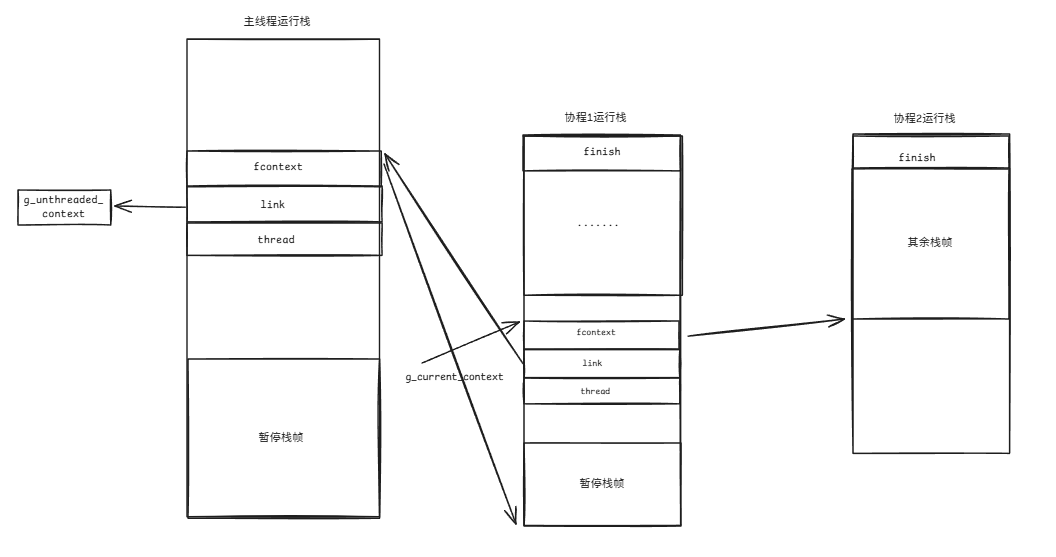
(5)协程2执行完毕,调用final_switch_out恢复协程1的执行。
此时,协程1将恢复执行,因此switch_in()的返回值将会被设置为发出跳转的协程的栈顶。
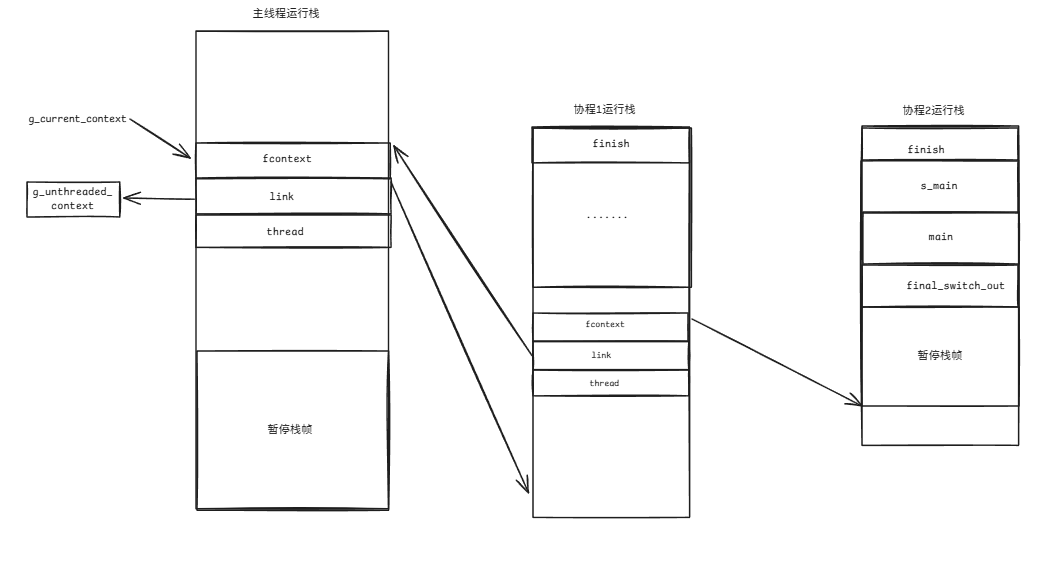
(6)协程1执行完毕,调用final_switch_out恢复主线程的执行。
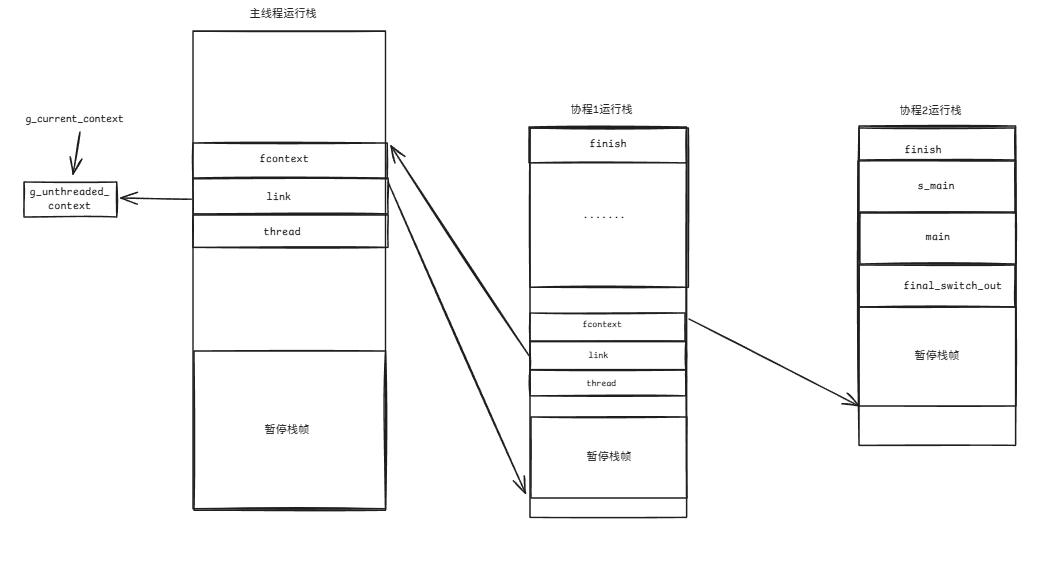
因此,我们可以得出结论:
switch_in()中的fcontext = _fl_jump_fcontext(fcontext, thread).fctx;是为了让_fl_jump_fcontext跳转到的fcontext在跳转回来后,fcontext能够正确指向暂停后的栈顶位置,以便后面再次调用switch_in()时能够正确地恢复。
switch_out()中的link->fcontext= _fl_jump_fcontext(link->fcontext, thread).fctx;是为了让退出到link->fcontext(即上一个协程的栈顶)之后,如果上一个协程再次调用switch_in()切换到子协程,此时我们就需要更新上一个协程的栈顶(就是link->fcontext)。
因此,switch_in()和switch_out()这两个函数的作用就是在切换协程的过程中正确地维护协程的运行栈的栈顶。
整个jmp_buf_link的作用就是:对_fl_jump_fcontext进行封装,提供协程切换的功能,同时保证fcontext在切换的过程中拥有指向栈顶。同时使用一些工具保证内存访问的正确性,防止协程使用过程中出现内存问题。
thread_context::s_main函数
thread_context::s_main函数作为协程的启动函数,它提供了一层对于来自Uthread构造函数的参数func的封装,保证了启动了协程的启动和切换符合需求。
void thread_context::s_main(transfer_t t) {auto q = reinterpret_cast<thread_context*>(t.data);assert(g_current_context->thread == q);q->context_.link->fcontext = t.fctx;q->main();
}当协程启动之后,启动当前协程的栈顶会被设置成暂停后的栈顶,保证jmp_buf_link的fcontext正确指向栈顶。这样在恢复该协程时才能正确地恢复。
而q->main()则是该协程真正要运行的函数:
void thread_context::main() {
#ifdef __x86_64__// There is no caller of main() in this context. We need to annotate this// frame like this so that unwinders don't try to trace back past this// frame. See https://github.com/scylladb/scylla/issues/1909.asm(".cfi_undefined rip");
#elif defined(__PPC__)asm(".cfi_undefined lr");
#elif defined(__aarch64__)asm(".cfi_undefined x30");
#elif defined(__riscv)asm(".cfi_undefined ra"); // The return address register in RISC-V is 'ra'
#else
#warning "Backtracing from uthreads may be broken"
#endifcontext_.initial_switch_in_completed();try {func_();done_.setValue(true);} catch (...) {done_.setException(std::current_exception());}context_.final_switch_out();
}func_()是协程真正想要运行的函数。而done_.setValue()和done_.setException()这两个东西让协程中的Promise/Future机制得以生效。Promise/Future机制在async_simple中非常重要,后面如果有时间我会去研究一下。
最后的context_.final_switch_out()保证了在执行完之前切换出协程,如果不这样做的话,结束main之后就会弹出s_main最后执行finish导致程序强制停止。
使用Uthread案例
在uthread/test/UtheadTest.cpp中有很多关于Uthread的使用示例,类似于:
_executor.schedule([ex, &running, &show, &ioJob]() mutable {Uthread task1(Attribute{ex}, [&show, &ioJob]() {show("task1 start");// 这里的await()函数其实是一种Promise/Future机制,暂停当前协程// 等待ioJob()任务完成时,通过Promise的回调机制,让该协程可以被重新调度,从而恢复协程执行auto value = await(ioJob());EXPECT_EQ(1024, value);show("task1 done");});task1.join([&running]() { running--; });});_executor.schedule([ex, &running, &show]() mutable {Uthread task2(Attribute{ex}, [&show]() {show("task2 start");show("task2 done");});task2.join([&running]() { running--; });});