Redis的list的底层原理
Redis的list的底层原理
今天我们来聊聊Redis中list数据结构的底层实现原理。想象一下我们日常生活中排队买奶茶的场景:
队伍可以不断有人加入(从队尾),也可以有人离开(从队头),甚至有时候会有VIP客户插队(从队头插入)。Redis的list就像这样一个灵活的队伍管理工具,它支持从两端快速插入和删除元素,这种特性使它在消息队列、最新消息排行等场景中非常有用。
在实际工作中,我们经常会使用Redis的list来实现简单的消息队列或者存储时间线数据。但你是否好奇过,为什么Redis的list能够如此高效地支持这些操作?今天,我们就一起来揭开它的神秘面纱。
一、Redis list的执行流程
理解了list的基本概念后,我们来看看Redis是如何实现list的各种操作的。Redis的list是一个双向链表结构,它支持从头部和尾部快速插入和删除元素,这种设计使得它的时间复杂度在大多数情况下都是O(1)。

当我们执行一个LPUSH命令向list头部插入元素时,Redis会经历以下步骤:
- 首先检查键是否存在,如果不存在则创建一个新的list
- 为新元素分配内存空间
- 将新元素链接到现有list的头部
- 更新list的长度计数器
类似地,RPUSH操作会在尾部插入元素,而LPOP和RPOP则分别从头部和尾部移除元素。Redis还提供了LRANGE命令来获取list的一个范围内的元素,这个操作的时间复杂度是O(N),其中N是返回的元素数量。
小贴士:Redis的list操作命令非常丰富,除了基本的LPUSH/RPUSH/LPOP/RPOP外,还有BLPOP/BRPOP等阻塞版本,以及LINDEX、LINSERT等实用命令,大家可以根据实际需求选择合适的命令。
二、Redis list的技术原理
了解了基本操作流程后,我们深入探讨一下Redis list的底层实现原理。Redis的list并不是简单地使用一种数据结构实现的,而是根据数据量的大小和元素的特性,采用了两种不同的内部编码方式:ziplist和linkedlist。
在Redis 3.2版本之后,list的实现又引入了一个更高效的结构——quicklist,它实际上是ziplist和linkedlist的结合体,既保留了ziplist的高内存利用率,又具备linkedlist的操作灵活性。
1. ziplist结构
当list中元素数量较少且元素较小时,Redis会使用ziplist(压缩列表)来存储数据。ziplist是一块连续的内存空间,它通过特殊的编码方式存储多个元素,从而节省内存。
ziplist的结构如下:
+--------+--------+--------+--------+--------+--------+--------+
| zlbytes | zltail | zllen | entry1 | entry2 | ... | zlend |
+--------+--------+--------+--------+--------+--------+--------+
上述代码说明了ziplist的基本结构:
- zlbytes:整个ziplist占用的内存字节数
- zltail:到最后一个entry的偏移量
- zllen:entry的数量
- entry1…entryN:实际的列表元素
- zlend:结束标记
ziplist的优点是内存利用率高,因为它是连续存储的,不需要额外的指针开销。但是它的缺点是插入和删除操作可能需要移动大量数据,时间复杂度是O(N)。
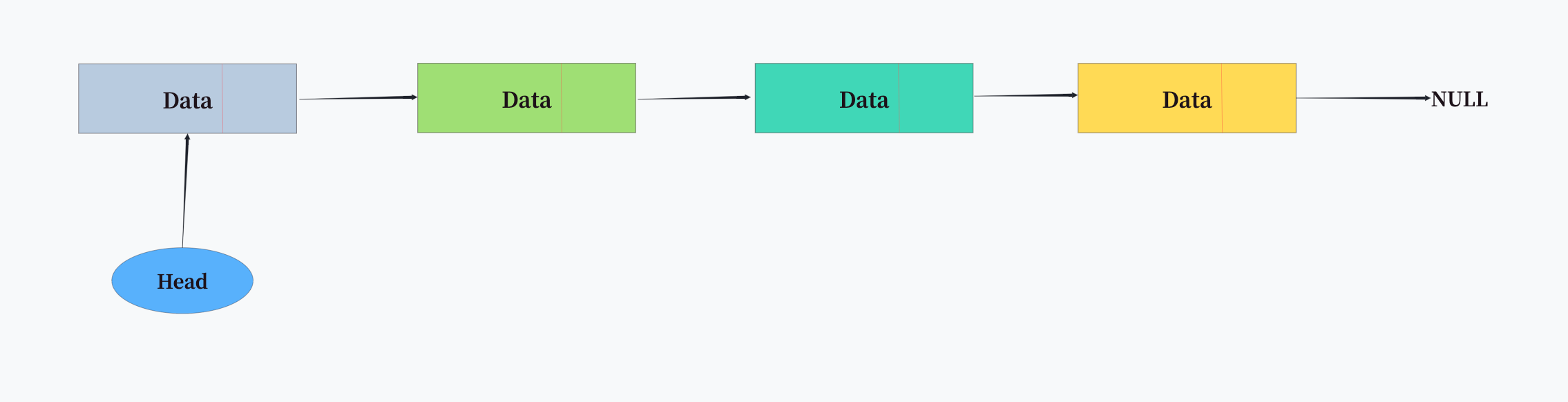
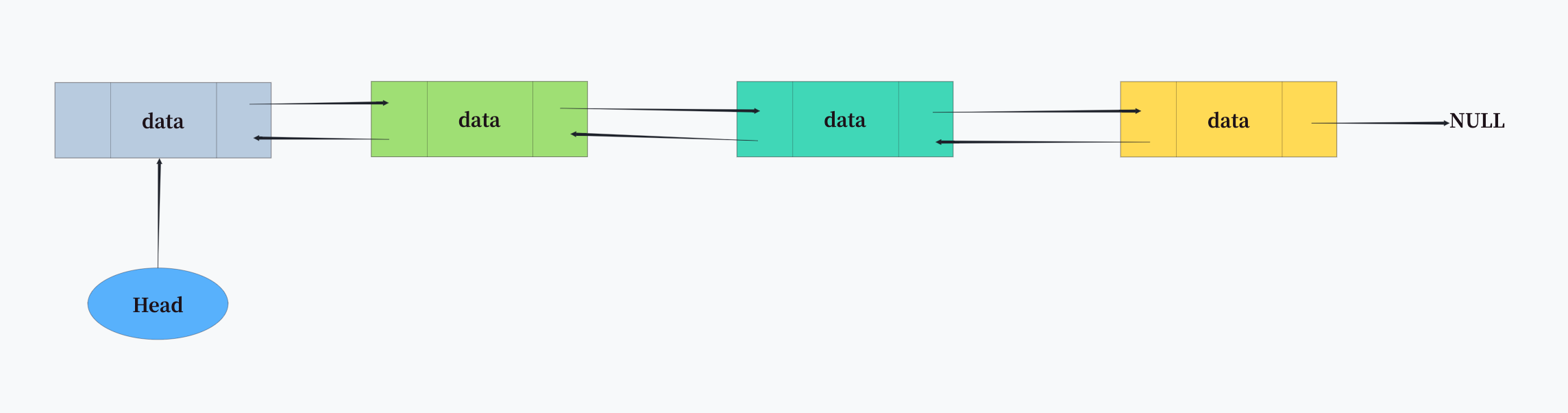
2. linkedlist结构
当list中的元素数量较多或者元素较大时,Redis会转换为linkedlist(双向链表)结构。linkedlist由多个listNode节点组成,每个节点包含指向前驱和后继的指针,以及存储实际值的指针。
linkedlist的结构如下:
typedef struct listNode {struct listNode *prev;struct listNode *next;void *value;
} listNode;typedef struct list {listNode *head;listNode *tail;unsigned long len;// ...其他字段省略
} list;
上述代码展示了Redis中linkedlist的实现方式。考虑到实际应用中需要频繁的头部和尾部操作,Redis使用了双向链表结构,因此能达到O(1)时间复杂度的头部和尾部插入删除操作。
3. quicklist结构
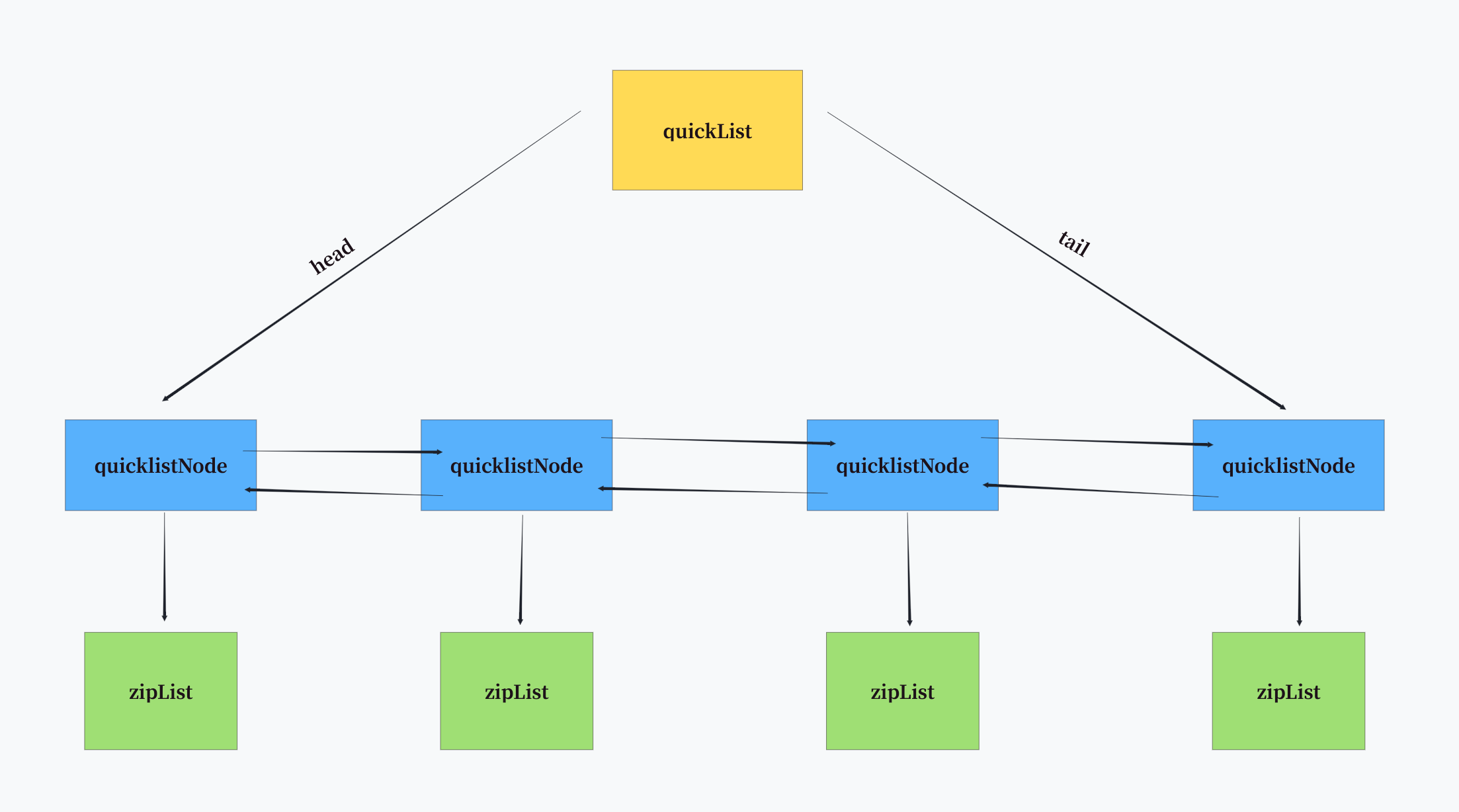
Redis 3.2版本引入了quicklist作为list的默认实现,它是对ziplist和linkedlist的折中方案。quicklist是一个由ziplist组成的双向链表,每个节点都是一个ziplist。
quicklist的结构如下:
typedef struct quicklistNode {struct quicklistNode *prev;struct quicklistNode *next;unsigned char *zl; // 指向ziplist的指针unsigned int sz; // ziplist的字节大小unsigned int count : 16; // ziplist中的元素个数// ...其他字段省略
} quicklistNode;typedef struct quicklist {quicklistNode *head;quicklistNode *tail;unsigned long count; // 所有ziplist中元素的总数unsigned long len; // quicklistNode的数量// ...其他字段省略
} quicklist;
上述代码说明了quicklist的基本结构。quicklist通过将多个ziplist用双向链表连接起来,既保留了ziplist的内存优势,又避免了单个ziplist过大导致的性能问题。
quicklistNode 是 quicklist 的节点,每个 quicklistNode 包含:一个 ziplist(压缩列表, 该 ziplist 的大小信息, 前后节点的指针
在实际应用中,我建议大家可以尝试使用Redis 3.2及以上版本,因为quicklist的实现通常能提供更好的性能和内存利用率。如果你真的遇到性能问题,不妨调整一下list-max-ziplist-size参数,找到最适合你应用场景的配置。
三、Redis list的编码转换
理解了各种底层结构后,我们来看看Redis是如何在不同编码之间进行转换的。Redis会根据list的当前状态和配置参数自动选择合适的编码方式。
Redis的配置文件中通常会有以下相关参数:
# list-max-ziplist-size -2
# list-compress-depth 0
list-max-ziplist-size参数决定了单个ziplist能存储的最大元素数量或字节大小。当超过这个限制时,Redis会将ziplist转换为linkedlist(在Redis 3.2之前)或创建新的quicklist节点(在Redis 3.2之后)。
list-compress-depth参数控制quicklist两端不被压缩的节点数。例如,设置为1表示头节点和尾节点不压缩,中间的节点会被压缩。
编码转换的触发条件主要包括:
- 向ziplist插入元素导致其大小超过list-max-ziplist-size限制
- 执行某些操作(如LINSERT)导致ziplist不再满足效率要求
- Redis在后台定期检查并优化数据结构
四、Redis list的应用场景
通过前面的讨论,相信大家对Redis list的底层实现有了清晰的认识。现在,我们来看看它在实际工作中的应用场景。
1. 消息队列:使用LPUSH/RPOP组合可以实现简单的FIFO队列,而使用LPUSH/LPOP可以实现栈结构。
# 生产者
LPUSH message_queue "task1"
# 消费者
RPOP message_queue
2. 最新消息列表:使用LPUSH和LTRIM可以轻松实现固定长度的最新消息列表。
# 添加新消息
LPUSH latest_news "news1"
# 保持只保留100条最新消息
LTRIM latest_news 0 99
3. 阻塞队列:使用BLPOP/BRPOP可以实现阻塞式的消息队列,当队列为空时消费者会阻塞等待。
4. 分页查询:使用LRANGE命令可以方便地实现分页功能。
通过我的观察,我发现很多问题都可以通过Redis list解决。我通常是这样做的:对于需要保证顺序且需要快速访问两端的数据,优先考虑使用Redis list。但要注意,如果需要随机访问中间元素(通过LINDEX),性能会比较差,因为时间复杂度是O(N)。
五、总结与最佳实践
让我们总结一下今天讨论的内容:
- Redis的list支持高效的头部和尾部操作,时间复杂度通常是O(1)
- 底层实现经历了从ziplist/linkedlist到quicklist的演进
- quicklist结合了ziplist和linkedlist的优点,是Redis 3.2+的默认实现
- 编码转换由配置参数和实际使用情况自动触发
- 适用于消息队列、最新消息列表等场景
在实际使用中,我建议大家可以遵循以下最佳实践:
- 根据数据特点合理配置list-max-ziplist-size参数
- 避免频繁使用LINDEX等需要遍历list的操作
- 对于大型list,考虑使用LTRIM限制其大小
- 在需要严格顺序的场景下优先选择list
通过今天的分享,希望能帮助大家更好地理解和使用Redis的list数据结构。记住,理解底层原理不仅能帮助我们更好地使用工具,还能在遇到问题时更快地找到解决方案。
文章目录结构总结
为了方便大家回顾,以下是本文的目录结构:
- 开篇:通过生活场景引入Redis list的概念
- Redis list的执行流程:基本操作的时间复杂度分析
- Redis list的技术原理:详细讲解ziplist、linkedlist和quicklist三种实现
- Redis list的编码转换:自动转换机制和配置参数
- Redis list的应用场景:消息队列、最新消息列表等实际用例
- 总结与最佳实践:使用建议和性能考量
欢迎随时交流,一起分享使用Redis的经验。让我们共同进步,不断探索新技术!