前缀和:leetcode974--和可被K整除的子数组
前言
1.前缀和+哈希表(+排列组合思想)
2.同余定理

3.Cpp和Java修正【负数%正数】
(num%k + k)% k
题目解析
和可被K整除的子数组:
给定一个整数数组 nums 和一个整数 k ,返回其中元素之和可被 k 整除的非空 子数组 的数目。
子数组 是数组中 连续 的部分。

本题在leetcode560“和为K的子数组”这道题上进行了扩展,
但同样是--统计一段和满足某条件的连续区间(子数组)的数目。
算法原理
暴力解法
用两层循环遍历所有子数组的情况,求和看是否满足条件。
虽然容易想,但并非毫无意义:在想暴力解法的过程中,我们会发现题目所给数组包含负数和0,不具有单调性,因此不能用双指针“滑动窗口”进行优化。那怎么办?
前缀和+哈希表
在学完前缀和以后,每当看到题目要求连续区间的和时,都应该想到前缀和,毕竟在有了前缀和之后,求某段区间的和都只需要O(1)就能完成。
那么如何用前缀和优化又是个问题。
为了使用前缀和,首先要一改暴力解法的思想:以i位置为起点遍历所有子数组。、 这样我们只能求出后缀和,与前缀和完全不搭边。
这样我们只能求出后缀和,与前缀和完全不搭边。
那么反过来想,遍历以i位置为结尾的子数组,似乎就好起来了,既能考虑所有子数组的情况,又能使用前缀和。 当有了i位置的前缀和之和,其实就不需要再一个一个遍历子数组的情况了。
当有了i位置的前缀和之和,其实就不需要再一个一个遍历子数组的情况了。
因为sum[i,j] = prefix_sum[j] - prefix[i]。有了两个前缀和,就能够算出这两段前缀和之间的值。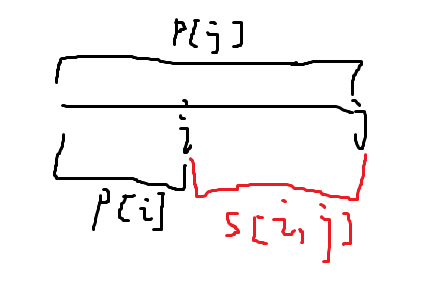 (图中抽象表示,未处理细节)
(图中抽象表示,未处理细节)
在知道要使用前缀和的情况下,再观察一下题目要求:和可被K整除的子数组。
子数组不就是sum[i,j] = prefix_sum[j] - prefix[i]这个嘛。且和能够用前缀和之差表示,再结合同余定理,就会发现找到 j 位置时,只要前面 j 前有 i 位置,满足二者的前缀和(mod)k相等,就能推出sum[i,j]这段子数组之和能被K整除,只需要把下面的逻辑逆着推上来即可。

这样,用哈希表记录下某位置之前的前缀和,结合哈希表快速查找的特性,
就可以在到 i 位置时, 查找之前满足条件的前缀和出现的次数,就是满足条件的子数组的个数。
(哈希中可以只存前缀和模K的余数及其出现的次数)
注意的细节就是,哈希表需要初始化map[0] = 1。这是因为可能某位置的前缀和就刚好满足条件,那么子数组就是该段前缀和减去一个0,需要在哈希表中找到一个为0的前缀和。换种理解就是,index在-1位置时,前缀和为0。
还有,数组中存在负数,对于取模操作,Cpp 和Java 的 [ 负数%正数 == 负数 ]
可是对K取模运算余数的范围是[0,K-1],是正数,就需要特殊处理。
对负数:(num % k)+ k ;但正数不需要啊
有一个正负取模统一表达式:(num%k + k)% k; 就行了。
代码实现
不需要真的创建一个数组存前缀和,都放到哈希表中即可。
int subarraysDivByK(vector<int>& nums, int k) {int n = nums.size(), sum = 0, ct = 0;unordered_map<int, int> m;m[0]++;for (int e : nums) {sum += e;ct += m[(sum % k + k) % k];m[(sum % k + k) % k]++;}return ct;}还有一种排列组合的思路,把前缀和模K都求出后放入哈希,相同的余数两两进行排列组合,也是满足条件的子数组。
int subarraysDivByK(vector<int>& nums, int k) {int n = nums.size(), sum = 0, ct = 0;unordered_map<int, int> m;m[0]++;for(int e : nums){sum+=e;m[(sum%k+k)%k]++;}for(auto [k,v] : m){ct += v*(v-1)/2;}return ct;}