python中的zip函数
最近刷leetcode,以及处理数据的时候,发现python中一个平时很少关注的函数zip,合理运用的话,可以规避很多算法层面上的逻辑流程结构,算是python搞算法部分一个合理偷懒的作弊函数吧!
zip() 函数基本概念
zip() 函数将多个可迭代对象(如列表、元组等)"打包"在一起,创建一个迭代器,返回元组的序列。
基本语法
zip(*iterables)*iterables: 一个或多个可迭代对象
举例来说:
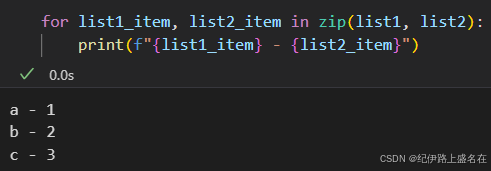
1,2个列表(或者2个可迭代基本元素的对齐打包):
list1 = ['a', 'b', 'c']
list2 = [1, 2, 3]result = zip(list1, list2)
# 结果: [('a', 1), ('b', 2), ('c', 3)]
注意到此时这里的zip已经是一个整合打包之后的迭代器了,
所以如果要访问元素的话
(1)需要进行迭代
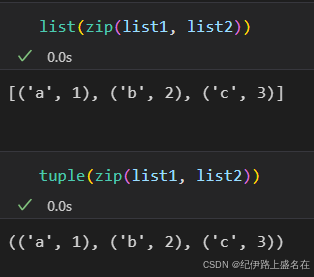
(2)或者直接将该迭代器显式转换为其他的基本可迭代数据格式:
比如说是list列表,或者是元组tuple之类,
2,多个列表(同上):
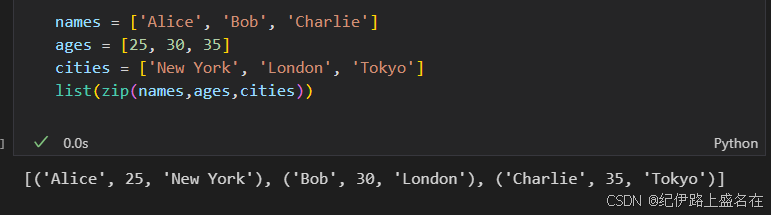
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
cities = ['New York', 'London', 'Tokyo']
list(zip(names,ages,cities))
如果是长度不同的列表进行对齐的话,注意!这里是不会广播的,有的学生很容易把这里的对齐和numpy等高维数组处理中的广播broadcast机制混淆在一起,
但是实际上合并的时候是以短的序列为主:
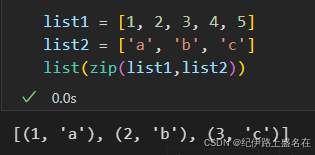
实际上,数据敏感的人,其实一眼就可以看出来zip处理数据的方式,可以很自然的和dict也就是key-value字典的映射/组织规则联系起来,
这个一般是在数据处理中非常常见,我们在处理比较复杂的生物序列数据,比如说是fasta格式的数据(header+content其实可以分离开来当作是不同的key、value向量,如果要进一步对header进行处理的话,其实是可以细分为多个元素级别的dict),或者是其他的问题。
我们一般是key、value分离来处理的,
所以这个时候可以使用zip来重新组织分离的key-value为新的dict格式数据,当然,我们其实可以继续保留这个zip打包对齐的数据,因为一般的dict都是key-value的二元对齐,但是我们在zip中其实是可以打包多个数据的,也就是达到多元对齐,然后我们就可以按照需求从里面按照数字下标索引index切出不同的复杂的字典格式数据。