北航自由指令驱动的多模态导航最新研究:OctoNav:开启通用智能体具身导航


-
作者: Chen Gao, Liankai Jin, Xingyu Peng, Jiazhao Zhang, Yue Deng, Annan Li, He Wang, Si Liu
-
单位:北京航空航天大学,新加坡国立大学,北京大学,北京中关村学院
-
论文标题:OctoNav: Towards Generalist Embodied Navigation
-
论文链接:https://arxiv.org/pdf/2506.09839
-
项目主页:https://buaa-colalab.github.io/OctoNav/
-
代码链接:https://github.com/buaa-colalab/OctoNav-R1
主要贡献
-
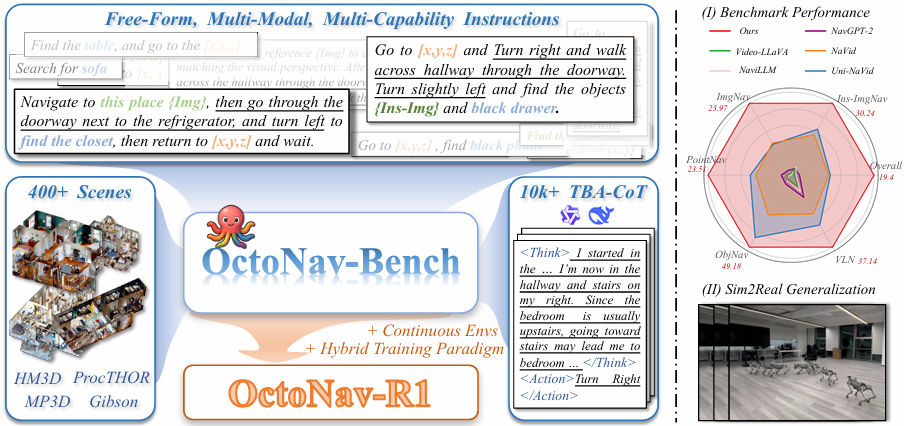
提出了一个大规模基准测试平台 OctoNav-Bench 和一种基于视觉语言动作(VLA)的方法 OctoNav-R1,旨在构建能够遵循自由形式指令的通用导航智能体(generalist navigation agents)。
-
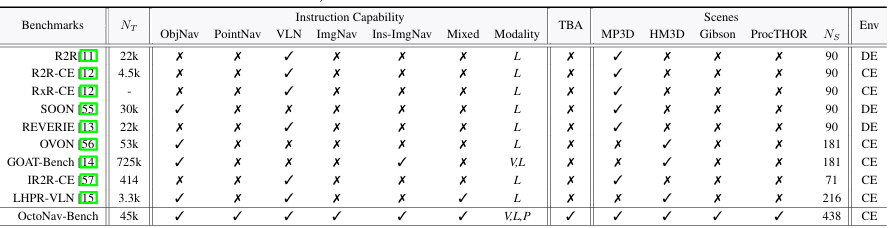
OctoNav-Bench 包含 400 多个 3D 场景和 45k+ 指令-轨迹对,支持大规模训练。这些指令是自由形式的,融合了多种模态(视觉、文本、坐标)和多种能力(如 ObjNav、PointNav、ImgNav 等),并构建了一个包含 10k+ 指令-思考-动作对的 Think-Before-Action Chain-of-Thought(TBA-CoT)数据集,用于捕捉行动背后的思考过程。
-
OctoNav-R1 基于 MLLMs 构建,能够直接从 2D 视觉观测生成低级动作,并通过提出的混合训练范式(Hybrid Training Paradigm, HTP)进行训练,该范式包括三个阶段:Action/TBA-SFT、Nav-GPRO 和在线强化学习(Online RL)。该方法强调“思考后再行动”,通过 TBA-CoT 数据集训练模型,使其具备生成思考过程和行动序列的能力。
-
在模拟环境中展示了 OctoNav-R1 的优越性能,并在真实世界中进行了初步的 sim2real 泛化实验,验证了其在现实场景中的适用性。
研究背景
-
传统的导航研究被划分为不同的任务,如目标导航(ObjNav)、点导航(PointNav)、图像导航(ImgNav)、实例图像导航(Ins-ImgNav)和视觉语言导航(VLN)。这些任务在设置、输入模态和目标上存在差异,导致数据集和方法都是针对特定任务设计的。
-
然而,理想中的通用智能体应该能够遵循自由形式的指令,这些指令不仅包含单一任务指令,还可能融合多种模态和多种能力。例如,指令可能要求智能体先导航到某个位置(PointNav),然后找到某个物体(ObjNav),最后通过视觉匹配找到特定场景(ImgNav)。当前的研究方法在处理这种复杂指令时存在局限性。
相关工作
-
大型语言模型(LLMs)在导航中的应用:近年来,LLMs 和多模态语言模型(MLLMs)被引入导航领域,用于生成导航策略或直接预测低级动作。然而,这些方法大多针对单一任务或特定模态,无法处理自由形式的多模态、多能力指令。
-
强化学习(RL)在导航中的应用:强化学习被证明是提高模型推理能力的有力策略。例如,DeepSeek-R1 通过奖励机制引导 LLMs 进行推理,而 Vision-R1 和 Video-R1 则构建了多模态的 CoT 数据集。然而,这些研究主要集中在静态图像或受限任务上,尚未探索如何将类似方法应用于机器人导航场景。
OctoNav-Bench
大规模标注
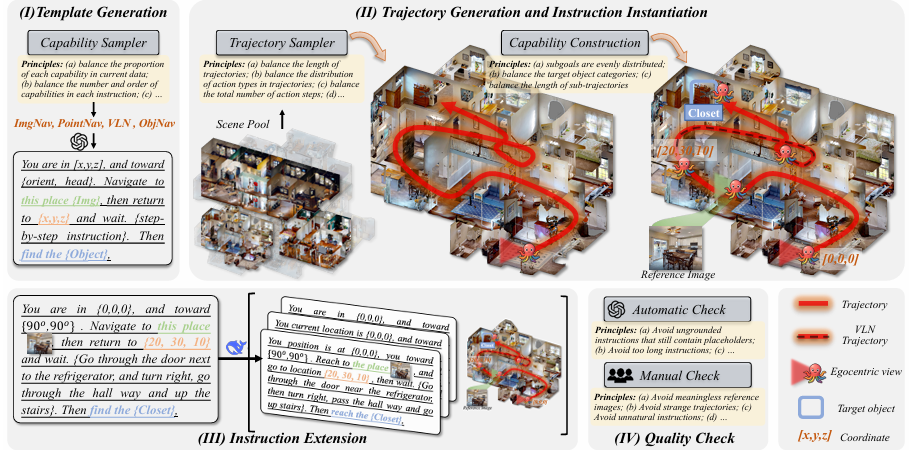
-
OctoNav-Bench 包含 400 多个 3D 场景,涵盖 MP3D、HM3D、Gibson 和 ProcTHOR 等常用数据集。
-
通过自动化标注流程,生成了 45k+ 指令-轨迹对,支持大规模训练。
自由形式、多模态和多能力指令
指令以自由形式生成,融合了文本、视觉(参考图像)和空间(坐标)描述,并且每个指令可能同时包含多种导航能力,如 ObjNav、PointNav、ImgNav、Ins-ImgNav 和 VLN。
TBA-CoT 数据集
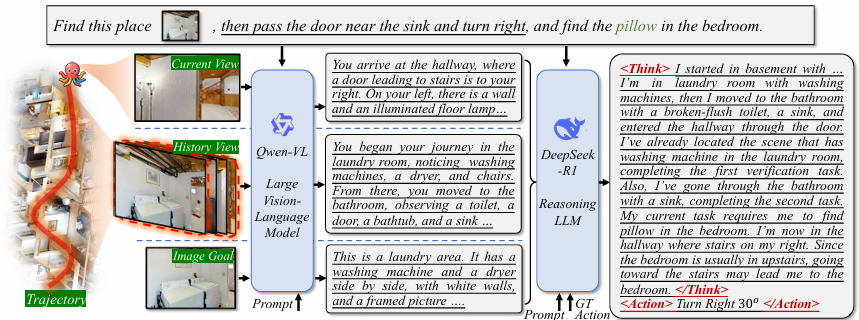
利用 Qwen-VL 和 DeepSeek-R1 构建了 TBA-CoT 数据集,捕捉每个行动背后的思考过程。该数据集可用于监督和增强智能体的推理能力。
连续环境与强化学习支持
与离散或基于图的设置不同,OctoNav-Bench 提供连续的模拟环境,允许智能体在任意位置自由移动并获取视觉观测,支持在线强化学习。
OctoNav-R1
架构设计
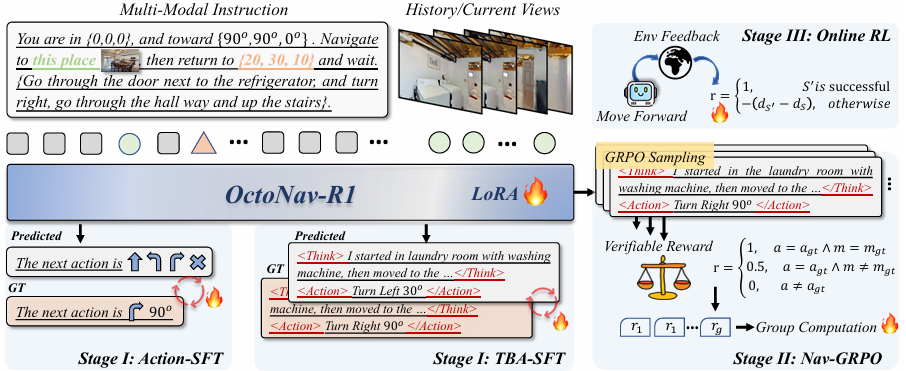
OctoNav-R1 基于 LLaMA-VID 构建,能够接收多模态指令并生成低级动作。模型架构包括视觉编码器、语言编码器、查询生成器等模块,通过交叉注意力和查询投影器将视觉和语言信息融合到 LLM 的嵌入空间中。
混合训练范式(HTP)
-
Action/TBA-SFT:通过指令-轨迹对进行监督微调,使模型能够遵循指令执行动作。同时,利用 TBA-CoT 数据集进行 TBA-SFT,训练模型在行动前进行思考。
-
Nav-GPRO:通过组相对策略优化(GRPO)进一步增强模型的思考能力。该阶段通过定制化的奖励函数和提示模板,鼓励模型生成更高质量的思考过程。
-
在线强化学习:在模拟环境中进行在线强化学习,使模型能够通过试错和主动学习来优化导航策略。
思考能力
OctoNav-R1 强调“思考后再行动”,通过 TBA-CoT 数据集训练模型生成思考过程和行动序列,使其具备更强的推理能力。
实验
实验设置
在 Habitat 模拟器上进行实验,测试集包含 400 多个未在训练集中出现的场景。使用成功率达到(SR)、路径长度加权成功率(SPL)和最终目标成功率(OSR)等指标进行评估。
与其他方法的比较
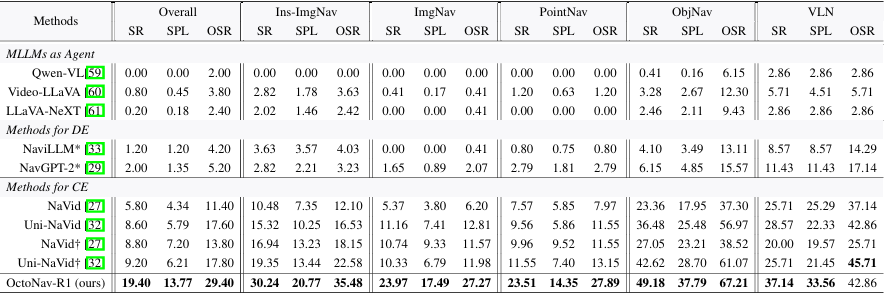
OctoNav-R1 在所有能力上均优于先前的方法,例如在 ImgNav 上的 SR 为 30.24%,在 VLN 上的 SR 为 49.18%,而其他方法如 Uni-NaVid、NavGPT-2 等在这些任务上的表现较低。
消融研究
-
Action-SFT:通过指令-轨迹对训练后,模型在多种能力上的表现得到提升,但 VLN 能力略有下降。
-
TBA-SFT:引入思考过程后,模型的整体性能显著提高,尤其在 PointNav 和 ObjNav 上的提升更为明显。
-
Nav-GPRO:进一步增强了模型的思考能力,提升了 VLN 任务的性能。
-
在线强化学习:通过在线 RL,模型在 ImgNav 和 VLN 任务上的表现进一步提升,同时整体路径效率也有所提高。
-
思考频率:实验表明,思考频率对性能的影响不敏感,但“何时思考”和“在何处思考”仍然是一个有价值的研究方向。
结论与未来工作
- 结论:
-
该研究通过构建 OctoNav-Bench 和 OctoNav-R1,展示了在自由形式、多模态和多能力指令下的通用导航智能体的潜力。
-
OctoNav-R1 在模拟环境中表现出色,并在真实世界中展示了初步的 sim2real 泛化能力。
-
- 未来工作:
-
未来的工作可以探索更复杂的思考机制,例如慢思考与快思考的协作、场景感知的自适应思考等,以进一步提高模型的推理能力和泛化能力。
-
此外,还可以研究如何减少视觉语言模型(VLMs)生成的幻觉,以提高导航性能。
-
