leetcode-hot-100 (链表)
1. 相交链表
题目链接:相交链表
题目描述:给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
解答:
其实这道题目我一开始没太看懂题目给这个链表的定义是干啥用的,后面看了解析才知道为了让我们知道这个链表是如何创建的,以及如何进行链表数据的访问。
方法一:哈希集合
反正题目已经明确表示整个链式结构中没有环,因此直接使用一个集合,然后遍历链表A中的所有元素(链表B也可以),将链表A中的每个节点加入到哈希集合中去。然后遍历链表B,查询当前B中的结点元素是否在哈希集合中出现过。
- 要是如果当前节点不在哈希集合中,则继续遍历下一个节点;
- 如果当前节点在哈希集合中,则后面的节点都在哈希集合中,即从当前节点开始的所有节点都在两个链表的相交部分,因此在链表 headB 中遍历到的第一个在哈希集合中的节点就是两个链表相交的节点,返回该节点。
如果链表 headB 中的所有节点都不在哈希集合中,则两个链表不相交,返回 null。
因此代码编写如下(官方的代码):
class Solution {
public:ListNode* getIntersectionNode(ListNode* headA, ListNode* headB) {unordered_set<ListNode*> visited;ListNode* temp = headA;while (temp != nullptr) {visited.insert(temp);temp = temp->next;}temp = headB;while (temp != nullptr) {if (visited.count(temp)) {return temp;}temp = temp->next;}return nullptr;}
};
方法二:双指针
方法一中用到了哈希集合,因此空间复杂度是 O ( m ) O(m) O(m),双指针方法就是将空间复杂度降至 O ( 1 ) O(1) O(1)
双指针的解法如下:
上述官方的解法为啥是对的呢,可视化如下的图进行解释:
情况一:要是两个链表相交,则假设指针 P A P_A PA 从 p p p 出发,指针 P B P_B PB 从 q q q 出发,则指针 P A P_A PA 的运动轨迹如下图红色部分,指针 P B P_B PB 的运动轨迹如下图黄色部分,按照图中所表示的长度,可以发现,要是 a = b a = b a=b 这,两指针一定会在红色点处相遇,这样就找到了结果,要是 a ! = b a!=b a!=b 则两指针还是在红色点处相遇。因此,两指针最多遍历链表A和链表B即可判断出最终的结果。
情况二:要是两个链表不相交,则依旧可以遍历链表A和链表B即可判断出最终的结果。
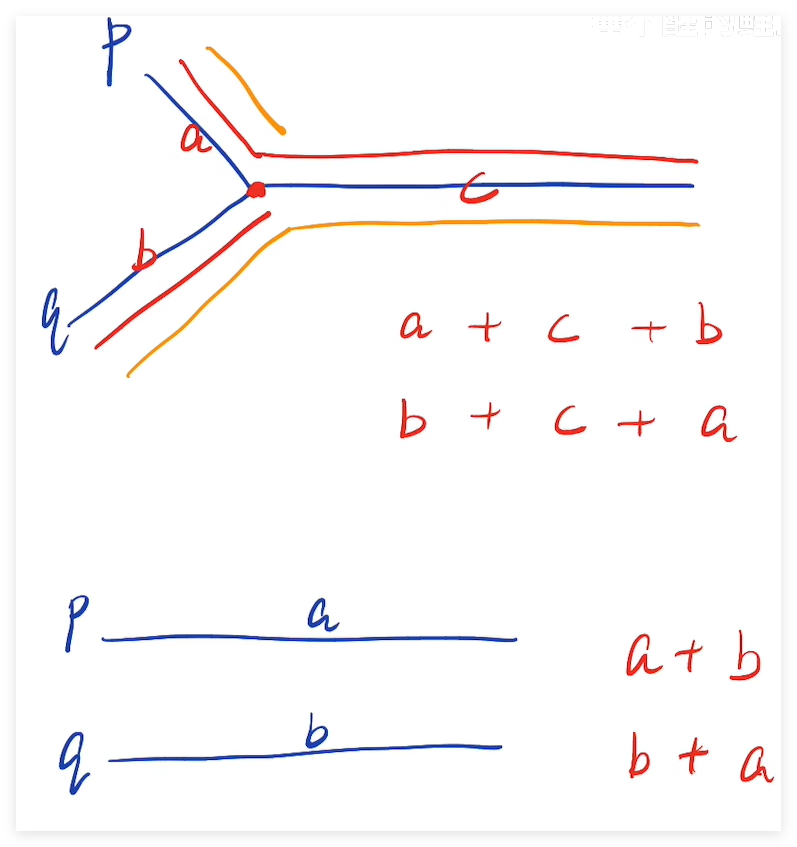
因此这样的话,时间复杂度就是两链表的长度 O ( m + n ) O(m+n) O(m+n) ,空间复杂度就是常数级别的了 O ( 1 ) O(1) O(1)。
于是代码编写如下:
class Solution {
public:ListNode* getIntersectionNode(ListNode* headA, ListNode* headB) {if (headA == nullptr || headB == nullptr) {return nullptr;}ListNode *pA = headA, *pB = headB;while (pA != pB) {pA = pA == nullptr ? headB : pA->next;pB = pB == nullptr ? headA : pB->next;}return pA;}
};
2. 反转链表
题目链接:反转链表
题目描述:给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
解答:
方法一:迭代法
示例:
输入: 1 -> 2 -> 3 -> 4 -> 5
输出: 5 -> 4 -> 3 -> 2 -> 1
使用三个指针进行链表的逐个反转:
p:表示当前节点,逐步向后移动。q:表示p的下一个节点,用于遍历原始链表。temp:临时保存q->next,防止链表断裂。
在每一步中:
- 将
q->next指向p,实现局部反转; - 向后移动
p和q; - 继续处理直到
q == nullptr,即整个链表反转完成; - 最后将原头节点指向
nullptr,避免循环引用; - 返回新的头节点
p。
C++ 实现代码
class Solution {
public:ListNode* reverseList(ListNode* head) {if (!head || !head->next)return head;ListNode *p = head, *q = p->next, *temp = nullptr;while (q) {temp = q->next; // 保存下一个节点q->next = p; // 反转当前节点的指针p = q; // 移动 p 到当前节点q = temp; // 移动 q 到下一个节点}head->next = nullptr; // 原头节点现在是尾节点,指向空return p; // 新的头节点是 p}
};
时间与空间复杂度分析
- 时间复杂度: O ( n ) O(n) O(n),其中 n n n 是链表的长度。我们只需要遍历一次链表。
- 空间复杂度: O ( 1 ) O(1) O(1),只使用了常数级别的额外空间。
示例解析
以链表 1 -> 2 -> 3 -> 4 -> 5 为例:
| 步骤 | p | q | temp | q->next | head->next |
|---|---|---|---|---|---|
| 初始 | 1 | 2 | - | - | 2 |
| 1 | 1 | 2 | 3 | 1 | 2 → 1 |
| 2 | 2 | 3 | 4 | 2 | 3 → 2 → 1 |
| 3 | 3 | 4 | 5 | 3 | 4 → 3 → 2 → 1 |
| 4 | 4 | 5 | null | 4 | 5 → 4 → 3 → 2 → 1 |
| 结束 | 5 | null | - | - | 1 → null |
最终返回 p = 5,链表成功反转为:5 -> 4 -> 3 -> 2 -> 1
注意
- 必须判断边界情况:
if (!head || !head->next) return head;,处理空链表或只有一个节点的情况。 - 不要忘记最后设置
head->next = nullptr,否则会导致循环链表或错误连接。
方法二:递归
我觉得递归主要还是不是很好想,但是代码还是很简洁的,具体的解释见:
官方解答
class Solution {
public:ListNode* reverseList(ListNode* head) {if (!head || !head->next) {return head;}ListNode* newnode = reverseList(head->next);head->next->next = head;head->next = nullptr;return newnode;}
};
3. 回文链表
题目链接:回文链表
题目描述:给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
解答:
方法一:直观
由于第二题是反转链表,因此我的第一想法就是深拷贝一个新的链表,然后反转此链表,然后在与原链表一个元素一个元素进行比较,这种方法比较的直观,因此直接展示代码:
class Solution {
public:// 主函数:判断是否是回文链表bool isPalindrome(ListNode* head) {// 1. 深拷贝原链表ListNode* copyHead = deepCopy(head);// 2. 反转拷贝链表ListNode* reversedCopy = reverseList(copyHead);// 3. 逐个比较原链表和反转后的拷贝链表while (head && reversedCopy) {if (head->val != reversedCopy->val) {return false;}head = head->next;reversedCopy = reversedCopy->next;}// 如果两个链表都走到了尽头,说明完全匹配return true;}private:// 辅助函数1:深拷贝链表ListNode* deepCopy(ListNode* head) {if (!head) return nullptr;ListNode* newHead = new ListNode(head->val);ListNode* currNew = newHead;ListNode* currOld = head->next;while (currOld) {currNew->next = new ListNode(currOld->val);currNew = currNew->next;currOld = currOld->next;}return newHead;}// 辅助函数2:反转链表(迭代法)ListNode* reverseList(ListNode* head) {ListNode* prev = nullptr;ListNode* curr = head;while (curr) {ListNode* nextTemp = curr->next;curr->next = prev;prev = curr;curr = nextTemp;}return prev;}
};
方法二:辅助数组
单向链表使用双指针比较直比较的麻烦,但是数组使用双指针比较值还是很快的,因此可以将链表中的值按照顺序存储在数组中,然后进行回文判断。
class Solution {
public:bool isPalindrome(ListNode* head) {vector<int> assist;while (head) {assist.emplace_back(head->val);head = head->next;}int len = assist.size();for (int i = 0, j = len - 1; i < j; i++, j--) {if (assist[i] != assist[j])return false;}return true;}
};
方法三:快慢指针
这部分主要是需要找到链表的中间位置,这个需要如何找呢?于是就使用快慢指针了,慢指针每次前进一个位置,快指针每次前进两个位置,这样当快指针到达链表末尾时候,慢指针就到达链表的中间位置。具体方法参考如下链接:官方解答
class Solution {
public:bool isPalindrome(ListNode* head) {if (head == nullptr) {return true;}// 找到前半部分链表的尾节点并反转后半部分链表ListNode* firstHalfEnd = endOfFirstHalf(head);ListNode* secondHalfStart = reverseList(firstHalfEnd->next);// 判断是否回文ListNode* p1 = head;ListNode* p2 = secondHalfStart;bool result = true;while (result && p2 != nullptr) {if (p1->val != p2->val) {result = false;}p1 = p1->next;p2 = p2->next;} // 还原链表并返回结果firstHalfEnd->next = reverseList(secondHalfStart);return result;}ListNode* reverseList(ListNode* head) {ListNode* prev = nullptr;ListNode* curr = head;while (curr != nullptr) {ListNode* nextTemp = curr->next;curr->next = prev;prev = curr;curr = nextTemp;}return prev;}ListNode* endOfFirstHalf(ListNode* head) {ListNode* fast = head;ListNode* slow = head;while (fast->next != nullptr && fast->next->next != nullptr) {fast = fast->next->next;slow = slow->next;}return slow;}
};
4. 环形链表
题目链接:环形链表
题目描述:给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
解答
方法一:快慢指针
这是我看到这道题目想到的第一个方法,就是使用快慢指针,快指针每次走两步,慢指针每次走一步,要是相遇了(即两指针指向链表中同一个位置),则该链表为环形链表,要是最终快指针指向空了,则该链表就不是环形链表了。
因此代码如下:
class Solution {
public:bool hasCycle(ListNode* head) {if (head == nullptr || head->next == nullptr)return false;ListNode* slow = head;ListNode* fast = head->next;while (slow != fast) {if (fast == nullptr || fast->next == nullptr) {return false;}slow = slow->next;fast = fast->next->next;}return true;}
};
方法二:哈希表
分析题意可知,链表中的每个元素都是唯一的。因此,若在遍历过程中发现某个元素已经被访问过,则说明链表中存在环,此时可以直接返回结果。基于这一特性,我们可以采用哈希表来进行环的检测。
具体做法如下:初始化一个空的哈希表,然后从头开始遍历链表。对于每一个遍历到的节点,首先判断其是否为 null。若当前节点为空,则表示已到达链表末尾,说明链表无环,直接返回 false;若当前节点不为空,则检查该节点是否已经存在于哈希表中:
- 如果存在,说明链表中存在环,返回
true; - 如果不存在,则将该节点加入哈希表,并继续访问下一个节点。
通过这种方式可以有效地判断链表是否存在环,代码编写如下:
class Solution {
public:bool hasCycle(ListNode* head) {unordered_set<ListNode*> counts;ListNode* temp = head;while (temp != nullptr) {if (counts.count(temp)) {return true;}counts.insert(temp);temp = temp->next;}return false;}
};
5. 环形链表 II
题目链接:环形链表 II
题目描述:给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改链表。
解答
好像还是可以使用上一道题目的两种方法(快慢指针和哈希表),这道题目我看到的第一眼觉得哈希表更加的直观,快慢指针其实也能做。
方法一:哈希表
在判断链表中是否存在环并返回环的入口节点时,可以利用哈希表来记录已经访问过的节点。
具体思路如下:
遍历链表中的每一个节点,对于每个节点进行如下判断:
- 如果该节点 已经存在于哈希表中,说明我们再次访问到了之前已经出现过的节点,这表明链表中存在环,且该节点即为环的入口节点,直接返回该节点。
- 如果该节点 尚未被访问过,则将该节点加入哈希表中,然后继续访问下一个节点。
如果整个链表遍历完成都没有重复访问到任何节点,则说明链表中不存在环,最终返回 nullptr。
这种方法简单直观,适用于大多数链表环检测问题,尤其适合对空间效率要求不高的场景。若需进一步优化空间复杂度,可使用快慢指针法(Floyd 判圈算法)实现 O(1) 空间复杂度的解决方案。
class Solution {
public:ListNode* detectCycle(ListNode* head) {if (head == nullptr || head->next == nullptr)return nullptr;unordered_set<ListNode*> seen;ListNode* temp = head;while (temp != nullptr) {if (seen.count(temp)) {return temp;}seen.insert(temp);temp = temp->next;}return nullptr;}
};
方法二:快慢指针
这个方法涉及到一些数学公式的推导,具体的文字解释详见官方解答
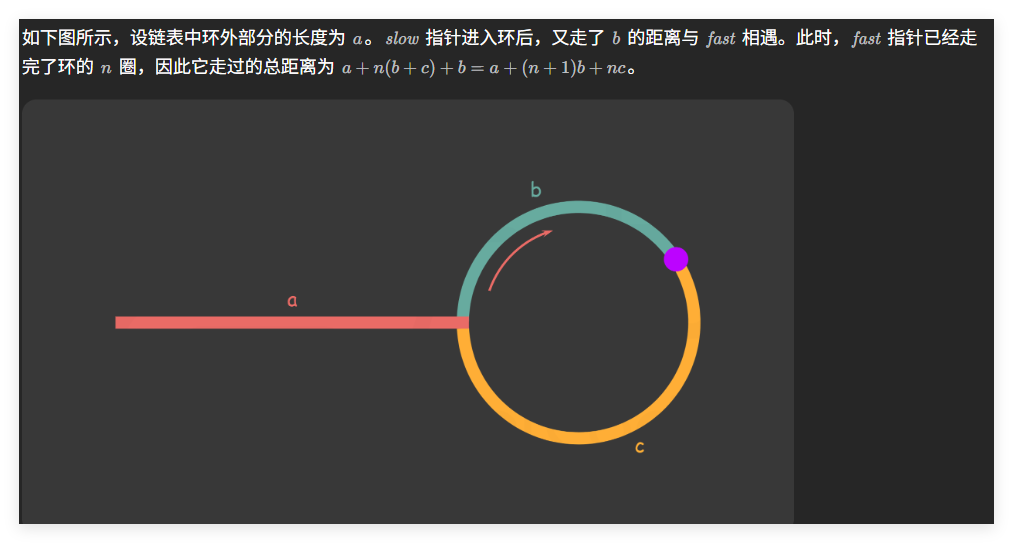
下面解释为什么在快慢指针相遇时,慢指针移动的距离 b b b 不会超过环的长度。
假设在相遇前,慢指针已经在环内绕行了一圈以上,那么快指针在这段时间内必然已经绕行了两圈以上。由于快指针的速度是慢指针的两倍,因此在慢指针进入环后、完成一圈之前,快指针就已经追上了它。
这就意味着,在慢指针绕完第一圈的过程中,快指针必定会在某一时刻从后面追上慢指针,两者相遇。因此,在快慢指针第一次相遇时,慢指针尚未走完整个环一圈,即移动距离 b b b 必然小于环的总长度。
class Solution {
public:ListNode* detectCycle(ListNode* head) {ListNode *slow = head, *fast = head;while (fast != nullptr) {slow = slow->next;if (fast->next == nullptr)return nullptr;fast = fast->next->next;if (slow == fast) {ListNode* ptr = head;while (ptr != slow) {ptr = ptr->next;slow = slow->next;}return ptr;}}return nullptr;}
};
6. 合并两个有序链表
题目链接:合并两个有序链表
题目描述:将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
解答
思路比较简单,但是编码需要注意的事项比较多
方法一:递归
递归嘛,就是选择两个链表头部值较小的一个节点与剩下元素的 merge 操作结果合并。对于边界情况特殊处理即可。
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if (list1 == nullptr)return list2;else if (list2 == nullptr)return list1;else if (list1->val < list2->val) {list1->next = mergeTwoLists(list1->next, list2);return list1;} else {list2->next = mergeTwoLists(list1, list2->next);return list2;}}
};
方法二:迭代
✅ 函数签名
ListNode* mergeTwoLists(ListNode* list1, ListNode* list2)
- 输入:两个指向
ListNode的指针,分别表示两个有序链表的头节点。 - 输出:一个指向合并后新链表头节点的指针。
🔁 主要逻辑步骤
-
边界处理:
- 如果其中一个链表为空,则直接返回另一个链表(即未空的那一个)。
-
使用虚拟头节点构建结果链表:
- 创建一个虚拟头节点
head(值为 0),用于简化插入操作。 - 使用指针
curr跟踪当前插入位置。
- 创建一个虚拟头节点
-
双指针遍历两个链表:
- 同时遍历
list1和list2,每次比较当前节点的值:- 取较小值创建新节点,并将其连接到
curr->next。 - 移动对应链表的指针(
list1或list2)和curr指针。
- 取较小值创建新节点,并将其连接到
- 同时遍历
-
处理剩余部分:
- 当其中一个链表遍历完成后,将另一个链表剩余的部分直接接在
curr->next后面。
- 当其中一个链表遍历完成后,将另一个链表剩余的部分直接接在
-
返回结果:
- 返回
head->next,即合并后链表的第一个有效节点。
- 返回
⏱️ 时间与空间复杂度分析
| 类型 | 复杂度 | 说明 |
|---|---|---|
| 时间复杂度 | O(m + n) | 其中 m 和 n 分别是两个链表的长度,每个节点最多访问一次 |
| 空间复杂度 | O(m + n) | 新建了一个链表来保存合并后的结果 |
class Solution
{
public:ListNode *mergeTwoLists(ListNode *list1, ListNode *list2){if (list1 == nullptr)return list2;if (list2 == nullptr)return list1;ListNode *head = new ListNode(0);ListNode *curr = head;while (list1 != nullptr && list2 != nullptr){int val = 0;if (list1->val <= list2->val){val = list1->val;list1 = list1->next;}else{val = list2->val;list2 = list2->next;}curr->next = new ListNode(val);curr = curr->next;}if (list1 == nullptr)curr->next = list2;else if (list2 == nullptr)curr->next = list1;return head->next;}
};
或者 w h i l e while while 语句可以写成如下的形式:
while (list1 != nullptr && list2 != nullptr) {if (list1->val <= list2->val) {curr->next = new ListNode(list1->val);list1 = list1->next;} else {curr->next = new ListNode(list2->val);list2 = list2->next;}curr = curr->next;}
7. 两数相加
题目链接:两数相加
题目描述:给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
解答
反正这道题目我也不知道使用的是啥方法,我写的代码原本如下(又臭又长):
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {ListNode* head = new ListNode(0);ListNode* curr = head;int temp = 0;// 同时遍历两个链表的部分while (l1 != nullptr && l2 != nullptr) {int sum = l1->val + l2->val + temp;if (sum > 9) {curr->next = new ListNode(sum % 10);temp = 1;} else {curr->next = new ListNode(sum);temp = 0;}curr = curr->next;l1 = l1->next;l2 = l2->next;}// 处理 l2 剩余部分if (l1 == nullptr) {while (l2 != nullptr || temp > 0) {if (l2 == nullptr) {curr->next = new ListNode(temp);temp = 0;} else {int sum = l2->val + temp;if (sum > 9) {curr->next = new ListNode(sum % 10);temp = 1;} else {curr->next = new ListNode(sum);temp = 0;}l2 = l2->next;}curr = curr->next;}}// 处理 l1 剩余部分if (l2 == nullptr) {while (l1 != nullptr || temp > 0) {if (l1 == nullptr) {curr->next = new ListNode(temp);temp = 0;} else {int sum = l1->val + temp;if (sum > 9) {curr->next = new ListNode(sum % 10);temp = 1;} else {curr->next = new ListNode(sum);temp = 0;}l1 = l1->next;}curr = curr->next;}}return head->next;}
};
还是官方的代码简洁巧妙,学到了,官方认为:如果两个链表的长度不同,则可以认为长度短的链表的后面有若干个 0 ,这样的话,可以相当于两个链表是一样长的。
class Solution {
public:ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {ListNode* head = new ListNode(0);ListNode* curr = head;int carry = 0;while (l1 != nullptr || l2 != nullptr || carry > 0) {int x = (l1 != nullptr) ? l1->val : 0;int y = (l2 != nullptr) ? l2->val : 0;int sum = x + y + carry;carry = sum / 10;curr->next = new ListNode(sum % 10);curr = curr->next;if (l1 != nullptr)l1 = l1->next;if (l2 != nullptr)l2 = l2->next;}return head->next;}
};
8. 删除链表的倒数第 N 个结点
题目链接:删除链表的倒数第 N 个结点
题目描述:给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
解答
一开始我也不知道为啥会写出下面的代码,逻辑上没有问题,但是超时了(内存泄露等问题)。
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {vector<int> value;ListNode* curr = head;while (curr != nullptr) {value.push_back(curr->val);curr = curr->next;}int len = value.size();int del_pos = len - n;ListNode* new_head = new ListNode(0);curr = new_head;int i = 0;while (i < len) {int temp = value[i];if (i == del_pos)continue;i++;curr->next = new ListNode(temp);curr = curr->next;}return new_head->next;}
};
方法一:二次遍历
既然超时了,那我又有了以下的想法:
- 先遍历一遍链表,统计节点个数 num;
- 然后计算出要删除的是“正数第 del_pos = num - n” 个节点;
- 再次从头开始遍历,走到那个位置进行删除。
上述需要注意头节点的删除需要特殊处理
于是代码编写如下:
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {int num = 0;ListNode* curr = head;// 第一次遍历:统计节点个数while (curr != nullptr) {num++;curr = curr->next;}// 需要删除节点的位置int del_pos = num - n;// 特判:删除头节点if (del_pos == 0) {ListNode* newHead = head->next;delete head;return newHead;}// 第二次遍历:找到要删除节点的前一个节点curr = head;int count = 0;while (curr != nullptr && curr->next != nullptr) { // 防止空指针if (count == del_pos - 1) {// 找到前一个节点,删除后一个节点ListNode* toDelete = curr->next;curr->next = toDelete->next;delete toDelete;break;}curr = curr->next;count++;}return head;}
};
方法二:栈
这方法不错,利用栈的特性,将全部节点压入栈,然后弹栈时即可判断需要删除的节点。
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode* dummy = new ListNode(0, head);stack<ListNode*> stk;ListNode* curr = dummy;while (curr) {stk.push(curr);curr = curr->next;}for (int i = 0; i < n; i++)stk.pop();ListNode* prev = stk.top();prev->next = prev->next->next;ListNode* ans = dummy->next;delete dummy;return ans;}
};
方法三:双指针
这个方法比较的巧妙,不同于快慢指针的遍历速度不同,这个双指针遍历速度一样,只是中间需要隔一段距离,而这个距离是由题目需要删除节点的位置决定的。引入一个哑结点(dummy),这样通过上述方式即可找到需要删除节点的前驱节点,这样就能更好的删除了。
官方的可视化的一个例子很好的说明了这个方法:
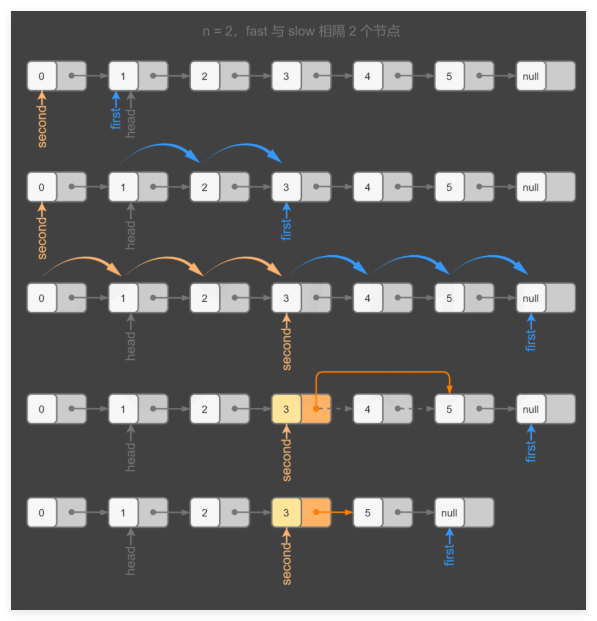
基于上述原理,可以编写代码如下:
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {// 创建一个虚拟头节点 dummy,并让它指向原始链表的头节点 head// dummy 的作用是简化边界情况(如删除头节点)ListNode* dummy = new ListNode(0, head);// 定义两个指针:ListNode* first = head; // 快指针ListNode* second = dummy; // 慢指针,初始时指向 dummy// 快指针先向前移动 n 步for (int i = 0; i < n; i++) {first = first->next;}// 然后快慢指针一起向前移动,直到快指针到达链表末尾while (first != nullptr) {first = first->next; // 快指针继续前移second = second->next; // 慢指针同步前移}// 此时,second 指向要删除节点的前一个节点// 删除目标节点(即 second->next)ListNode* nodeToDelete = second->next; // 保存要删除的节点second->next = second->next->next; // 跳过目标节点delete nodeToDelete; // 释放内存(C++ 中重要)// 保存结果头节点(可能不是原始 head,因为 dummy 是虚拟头节点)ListNode* ans = dummy->next;// 最后释放 dummy 节点的内存delete dummy;// 返回最终结果return ans;}
};
9. 两两交换链表中的节点
题目链接:两两交换链表中的节点
题目描述:给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
解答
这道题目主要是需要知道这个交换的节点是啥,我一开始没有看懂啥叫两两交换链表中的结点,询问 a i ai ai 发现就是每次处理两个节点,把它们的位置调换。例如:
原始顺序是:A → B → C → D
交换后是:B → A → D → C
每两个一组交换,直到链表末尾。
也就是说,这一组只在组内交换,不和其他的组进行交换,比如上述 A A A 交换后不与后面的 C C C 进行交换了。
再弄懂了题目的大致意思后,于是我就有了两种初始的想法,一种就是模拟,直接设置两个指针,然后逐渐遍历下去,直到交换完成,还有一种就是递归的方式(这种代码简单,但是不好想)。
方法一:模拟
我使用的模拟的思路大致如下:
- 使用一个虚拟头节点 d u m m y dummy dummy 来简化边界情况。
- 维护三个指针:
- p r e v prev prev :前一个节点(用来连接新的交换后的节点)
- f i r s t first first :当前组的第一个节点
- s e c o n d second second :当前组的第二个节点
- 每次循环中完成一次交换,并移动指针到下一组。
在有了上述的思路后,于是代码编写就不是很难了,
class Solution {
public:ListNode* swapPairs(ListNode* head) {// 创建一个哑结点,指向头节点,简化返回ListNode* dummy = new ListNode(0, head);ListNode* prev = dummy;// ListNode* first = head;while (head != nullptr && head->next != nullptr) {ListNode* first = head;ListNode* second = head->next;prev->next = first->next;first->next = second->next;second->next = first;prev = first; // 此时的 first节点就类似于下一组的哑结点,按照循环直接处理即可head = first->next;}return dummy->next;}
};
方法二:迭代
在经过上述模拟的方法,可以知道,其实每次交换使用的方法几乎都是一样的,因此还可以使用迭代的方法进行交换,思路如下:
- 如果链表为空或只有一个节点,直接返回。
- 否则,先交换前两个节点。
- 然后让后面的部分递归地去交换。
- 最后返回新的头节点。
于是代码可以编写如下:
class Solution {
public:ListNode* swapPairs(ListNode* head) {// 边界判断:如果链表为空 或者 只剩一个节点,无法交换,直接返回原头节点if (head == nullptr || head->next == nullptr) return head;// 定义第一个节点ListNode* first = head;// 定义第二个节点(一定是 first 的下一个)ListNode* second = first->next;// 关键步骤1:// 把 first 的 next 指向「从 second 之后的节点开始交换后的结果」// 这里使用了递归,swapPairs(second->next) 表示对后面未处理的部分进行同样的操作。// 比如在 1 -> 2 -> 3 -> 4 中:// first 是 1,second 是 2,// swapPairs(3) 就是处理 3 -> 4 的结果(即 4 -> 3),// 所以现在 first(1)的 next 应该指向 4 -> 3 的头节点 4first->next = swapPairs(second->next);// 关键步骤2:// 把 second 的 next 指向 first,完成当前这对节点的交换// 原来是 first -> second,现在变成 second -> firstsecond->next = first;// 返回值是 second,因为交换后 second 成为了这一段的新头节点// 比如上面的例子中,交换 1 -> 2 后变成 2 -> 1,// 所以返回的是 second(即 2),作为这一层递归的新头节点return second;}
};
评论解答区看到一个有意思的解答
class Solution {
public:ListNode* swapPairs(ListNode* head) {vector<ListNode*> vec;ListNode *ans = new ListNode(0, nullptr), *pre = ans;while (head) {vec.emplace_back(head);head = head->next;}for (int i = 0, j = 1; j < vec.size(); i += 2, j += 2) {pre->next = vec[j];pre = pre->next;pre->next = vec[i];pre = pre->next;}if (vec.size() % 2) {pre->next = vec[vec.size() - 1];pre = pre->next;}pre->next = nullptr;return ans->next;}
};
上述代码就是直接将节点中的值存储起来了,然后新建一个链表,然后存储对应位置的值,返回即可,虽然不符合题目要求,但是也算是一种解题方法。
10. K 个一组翻转链表
题目链接:K 个一组翻转链表
题目描述:给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
解答
前面写过反转链表,因此这里就只需要将链表划分为 k k k 组,最后不足 k k k 组的直接不翻转,直接拼接即可。接着对于一些边界仔细处理,各组之间链表的连接仔细处理即可,然后就可以得到答案了。
class Solution {
private:// 翻转从 head 开始的 k 个节点,并返回新的头节点ListNode* reverseList(ListNode* head, int k) {ListNode* prev = nullptr;ListNode* curr = head;while (k--) {ListNode* next = curr->next;curr->next = prev;prev = curr;curr = next;}return prev; // 新的头节点是 prev}
public:// K 个一组翻转链表主函数ListNode* reverseKGroup(ListNode* head, int k) {// 边界情况:空链表或 k == 1(无需翻转)if (!head || k == 1)return head;// 创建一个虚拟头节点,简化头节点翻转时的处理ListNode* dummy = new ListNode(0, head);// prev 指向前一组的最后一个节点,用来连接下一组翻转后的头节点ListNode* prev = dummy;// curr 指向当前要处理的节点ListNode* curr = head;// 遍历整个链表while (curr) {// 检查是否有足够的节点进行翻转(至少 k 个)ListNode* tail = prev; // 尝试找到第 k 个节点for (int i = 0; i < k; ++i) {tail = tail->next;if (!tail) { // 不足 k 个节点,保留原样,直接返回结果return dummy->next;}}// 找到了可以翻转的 k 个节点,开始翻转ListNode* next_group = tail->next; // 记录下一组的起始点ListNode* group_head = curr; // 当前组的头节点// 翻转这 k 个节点ListNode* new_head = reverseList(group_head, k);// 连接翻转后的这一组和前一部分prev->next = new_head;// 把当前组翻转后的尾节点(即原来的头)指向下一组的开始group_head->next = next_group;// 更新指针,准备处理下一组prev = group_head; // 原来的头变成了尾curr = next_group; // 移动到下一组开始位置}// 返回最终结果(dummy 的下一个节点是新的头节点)return dummy->next;}
};
思路还是挺好想到的,但是转化为代码就不是很好编写了,需要考虑众多因素。
11. 随机链表的复制
题目链接:随机链表的复制
题目描述:给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
解答
对于普通链表的复制,直接可以按照遍历的顺序创建链表节点,但是这道题目由于存在随机指针,可能当前结点的随机指针指向的节点还没有常见,因此我的想法是需要遍历两边,第一遍先创建出来所有的结点,第二便在确定 n e x t next next 指针和 r a n d o m random random 指向的节点。于是可以编写代码如下:
class Solution {
public:unordered_map<Node*, Node*> hmap;Node* copyRandomList(Node* head) {Node* p = head;while (p) {hmap.insert({p, new Node(p->val)});p = p->next;}p = head;while (p) {hmap[p]->next = (p->next != nullptr) ? hmap[p->next] : nullptr;hmap[p]->random =(p->random != nullptr) ? hmap[p->random] : nullptr;p = p->next;}return hmap[head];}
};
12. 排序链表
题目链接:排序链表
题目描述:给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
解答
方法一:辅助数组
看到这道题的第一反应是考虑排序。然而,直接对链表进行排序操作较为复杂,效率也不高。因此,我想到借助数组来简化这一过程。
具体思路如下:
- 遍历原始链表,将所有节点依次存入一个数组中;
- 对这个数组进行排序(根据节点的值);
- 然后将排好序的节点重新赋值给原始链表
- 返回原始链表的头节点
class Solution {
public:ListNode* sortList(ListNode* head) {vector<int> cache_val;ListNode* p = head;while (p) {cache_val.push_back(p->val);p = p->next;}sort(cache_val.begin(), cache_val.end());int len = cache_val.size();p = head;int i = 0;while (p && i < len) {p->val = cache_val[i];i++;p = p->next;}return head;}
};
方法二:递归实现的归并排序
归并排序是一种典型的 分治算法(Divide and Conquer),它适用于需要稳定排序的场景。链表结构天然适合归并排序的原因有:
- 不需要像数组那样频繁移动元素;
- 可以通过指针操作轻松拆分和合并链表。
整个算法分为三步:
| 步骤 | 描述 |
|---|---|
| 分 | 使用快慢指针将链表从中间断开为两个子链表 |
| 治 | 对每个子链表递归进行归并排序 |
| 合 | 将两个有序链表合并成一个有序链表 |
于是代码编写如下:
class Solution {
public:// 主函数:排序链表ListNode* sortList(ListNode* head) { return mergeSort(head); }
private:// 归并排序主函数ListNode* mergeSort(ListNode* head) {// 小于等于1个节点的话,直接返回if (!head || !head->next)return head;// 1. 快慢指针找中点ListNode *slow = head, *fast = head, *prev = nullptr;while (fast && fast->next) {prev = slow;slow = slow->next;fast = fast->next->next;}// 2. 断开链表,prev找到了链表中点的位置prev->next = nullptr;// 3. 分治ListNode* left = mergeSort(head);ListNode* right = mergeSort(slow);// 4. 合并return merge(left, right);}// 合并两个有序链表ListNode* merge(ListNode* l1, ListNode* l2) {// ListNode* dummy = new ListNode(0);// ListNode* curr = dummy;// 注释起来的写法也是可以的,但是返回的值需要写return dummy->next;ListNode dummy(0);ListNode* curr = &dummy;while (l1 != nullptr && l2 != nullptr) {if (l1->val < l2->val) {curr->next = l1;l1 = l1->next;} else {curr->next = l2;l2 = l2->next;}curr = curr->next;}curr->next = l1 ? l1 : l2;// 注释起来的写法也是可以的// if (l1 != nullptr)// curr->next = l1;// if (l2 != nullptr)// curr->next = l2;return dummy.next;}
};
方法三:自底向上归并排序
这个方法看官方解答吧,感觉原理还是很好懂的,但是编码可能需要注意的地方比较的多:
官方解答
class Solution {
public:// 主函数:对链表进行排序ListNode* sortList(ListNode* head) {if (!head || !head->next)return head;// 1. 先遍历一次链表,获取总长度int length = getLength(head);// 创建一个虚拟头节点,方便操作整个链表ListNode dummy(0, head);ListNode* curr = head;ListNode* prev = &dummy;// 2. 开始 Bottom-Up 归并排序,从子段长度 1 开始,逐步翻倍for (int subLength = 1; subLength < length; subLength *= 2) {prev = &dummy;curr = dummy.next; // 从原始链表开头开始处理// 对当前链表按 subLength 分割成多个子段并两两合并while (curr != nullptr) {// 第一段 l1 的起点是 currListNode* l1 = curr;// 找到第一段的结尾,并断开它for (int i = 1; i < subLength && curr->next != nullptr; ++i) {curr = curr->next;}ListNode* l2 = curr->next;curr->next = nullptr; // 断开 l1// 移动 curr 到 l2 的位置curr = l2;// 找到第二段的结尾,并断开它for (int i = 1; i < subLength && curr != nullptr && curr->next != nullptr;++i) {curr = curr->next;}// 保存下一轮的起点ListNode* next = nullptr;if (curr != nullptr) {next = curr->next;curr->next = nullptr; // 断开 l2}// 合并两个有序子链表ListNode* merged = merge(l1, l2);// 把合并后的链表接到 prev 后面prev->next = merged;// 更新 prev 到合并后链表的末尾while (prev->next != nullptr) {prev = prev->next;}// 下一轮从这里继续处理curr = next;}}// 返回排序后的链表头节点return dummy.next;}private:// 获取链表长度int getLength(ListNode* head) {int len = 0;while (head) {++len;head = head->next;}return len;}// 合并两个有序链表(标准写法)ListNode* merge(ListNode* l1, ListNode* l2) {ListNode dummy(0); // 虚拟头节点ListNode* tail = &dummy;while (l1 && l2) {if (l1->val < l2->val) {tail->next = l1;l1 = l1->next;} else {tail->next = l2;l2 = l2->next;}tail = tail->next;}// 接上剩余部分tail->next = l1 ? l1 : l2;return dummy.next;}
};
13. 合并 K 个升序链表
题目链接:合并 K 个升序链表
题目描述:给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
解答
方法一:分治法
看到这道题目我就觉得首先肯定是需要用到之前的 合并两个有序链表 的思想,但是这里由于有 k k k 个链表,因此不能简单的进行排序处理,于是我就想到了分治的方法,每次合并后,链表的数量变成原来的两倍,一直重复下去,直到得到最终的有序链表,官方可视化解释如下: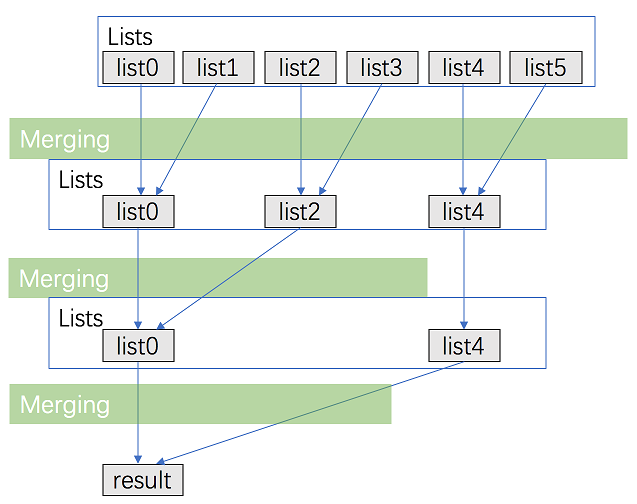
代码如下:
class Solution {
private:// 对两个有序链表进行排序,之前的题目中有对应的实现ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if (list1 == nullptr || list2 == nullptr)return list1 ? list1 : list2;ListNode* dummy = new ListNode(0);ListNode* head = dummy;while (list1 && list2) {if (list1->val < list2->val) {head->next = list1;list1 = list1->next;} else {head->next = list2;list2 = list2->next;}head = head->next;}head->next = list1 ? list1 : list2;return dummy->next;}// 分治法进行排序ListNode* merge(vector<ListNode*>& lists, int left, int right) {if (left == right)return lists[left];if (left > right)return nullptr;int mid = (left + right) >> 1;return mergeTwoLists(merge(lists, left, mid),merge(lists, mid + 1, right));}public:ListNode* mergeKLists(vector<ListNode*>& lists) {int len = lists.size();return merge(lists, 0, len - 1);}
};
方法二:顺序实现
也是需要自己编写两个有序链表的合并,然后直接遍历这 k k k 个列表,每次遍历一个调用合并函数即可。
class Solution {
private:// 合并两个有序链表ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {if (list1 == nullptr || list2 == nullptr)return list1 ? list1 : list2;ListNode* dummy = new ListNode(0);ListNode* head = dummy;while (list1 && list2) {if (list1->val < list2->val) {head->next = list1;list1 = list1->next;} else {head->next = list2;list2 = list2->next;}head = head->next;}head->next = list1 ? list1 : list2;return dummy->next;}
public:ListNode* mergeKLists(vector<ListNode*>& lists) {ListNode* ans = nullptr;for (size_t i = 0; i < lists.size(); ++i) {ans = mergeTwoLists(ans, lists[i]);}return ans;}
};
14. LRU 缓存
题目链接:LRU 缓存
题目描述:
解答
这题直接看题解吧,我感觉我要是研究生面试应该是不会问到这类的算法题的
官方解答