如何轻松实现多源混算报表
报表作为综合业务,数据来源多种多样。传统实现多源混合查询报表要通过 ETL 将数据同库,但这种方式数据时效性太差使用场景受限。通过逻辑数仓能获得较强的数据实时性,但体系又过于沉重,为报表业务搭建逻辑数仓有点得不偿失。需要一种更为简单轻量的多源报表实现方式。
SPL 能很好解决这个问题。作为轻量级计算引擎,SPL 具备天然多源混算能力,可以嵌入到报表中快速实现多源混算报表。
SPL 之所以具备天然混算能力,除了丰富的多样性数据源支持,更重要的是所有数据源接入后都会转换成统一数据对象:序表或游标,任何数据源只要能访问到就能混算。
目前主流报表工具润乾报表已经集成了 SPL,可以直接获得多源混合查询能力。
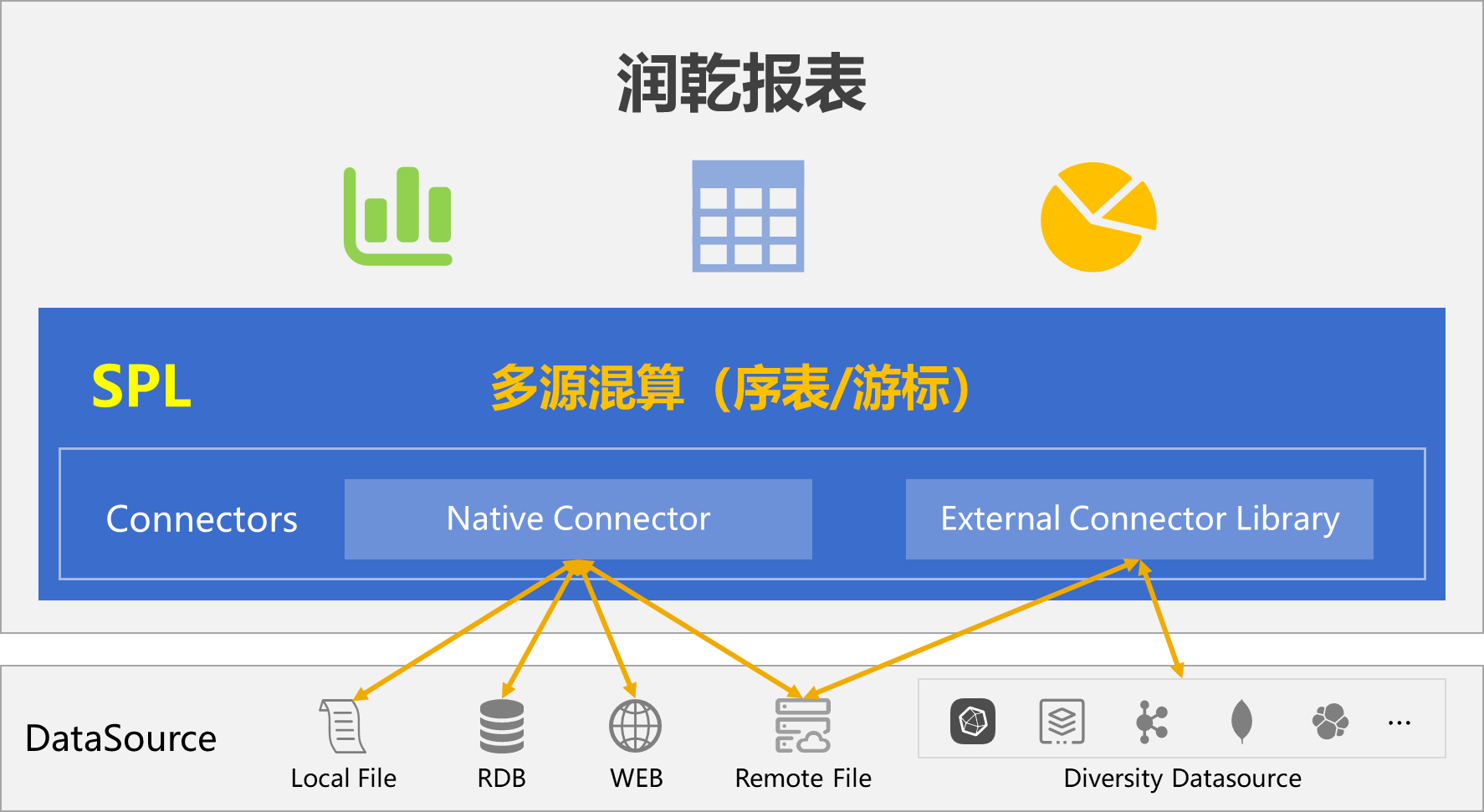
SPL 为多源计算设计了两种 Connector,最常见的 RDB,文本、Excel、JSON 等本地文件,以及 HTTP 数据源等属于原生 Connector 内置在 SPL 核心体系中。而对于一些没那么常用的数据源,像 MongoDB、Kafka、ES 这些,SPL 基于数据源的原生接口进行了简单封装,以外部 Connector 的形式提供,用到时单独引入即可。采用这种轻封装(相对逻辑数仓要深度定制开发)的模式可以让报表对数据源的支持更容易扩展,同时还能保留数据源的原生语法充分发挥数据源自身的能力。
比如,在实际的电商业务中,MySQL 存储订单相关信息。同时,由于商品信息会根据类型动态变化,比如电子产品有品牌、型号和规格,而服装则包括品牌、尺寸和颜色,因此使用 MongoDB 来存储商品信息。
现在基于订单销售统计报表,查询指定时间段内不同类型('Tablets', 'Wearables', 'Audio')、品牌、商品的销售总额,这需要跨 MySQL 和 MongoDB 混合查询。
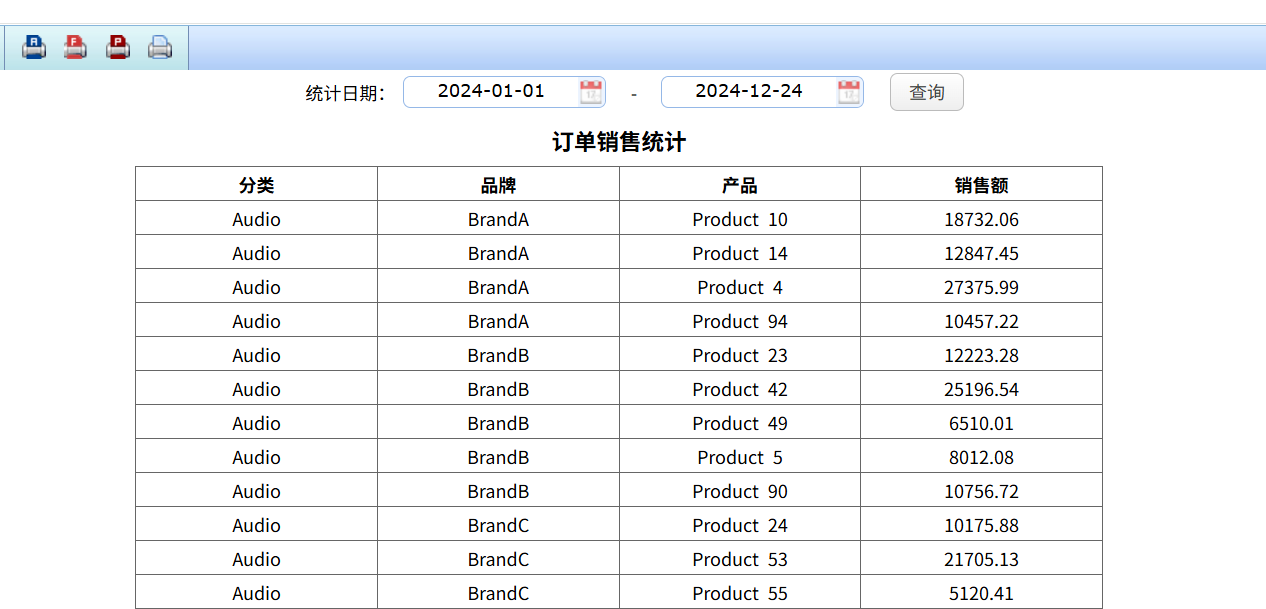
先通过 SPL 做跨库查询准备数据,编写 MySQL+Mongo.splx 脚本:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x ("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date>=? and o.order_date<=?",begin,end) |
| 3 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 4 | =mongo_shell@d(A3, "{'find':'products', 'filter': { 'category': {'$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
| 5 | =A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
| 6 | =A5.groups(category,brand,name;sum(price*quantity):amount) |
| 7 | return ifn(A6,create(category,brand,name,amount)) |
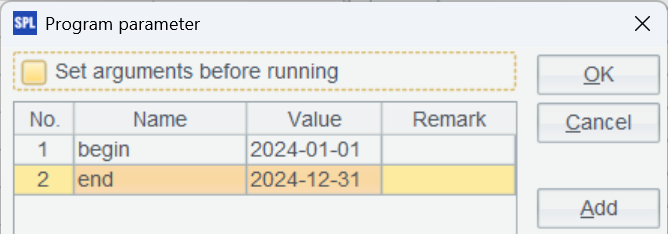
先连接 MySQL 并查询指定时间段的数据,begin 和 end 是报表中传递过来的参数,需要在脚本中增加相应的参数设置:
然后读取 MongoDB 数据,这里的语法都是 MongoDB 原生语法(在 Mongoshell 中可以直接执行)。
最后两部分数据进行关联计算并分组汇总返回计算结果。
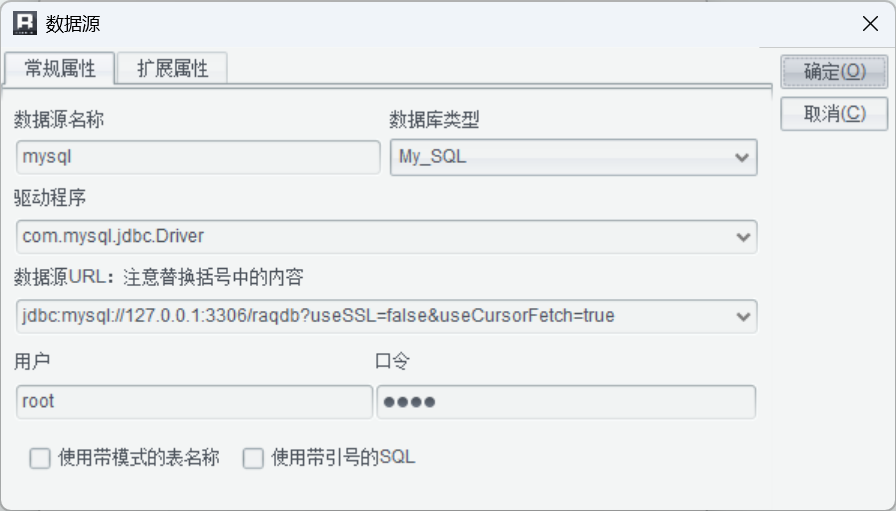
接下来设计报表展现模板。报表模板开发时需要先在润乾报表中需要配置 MySQL 数据连接:
MongoDB 要先引入外部库,在选项中选择外部库目录:
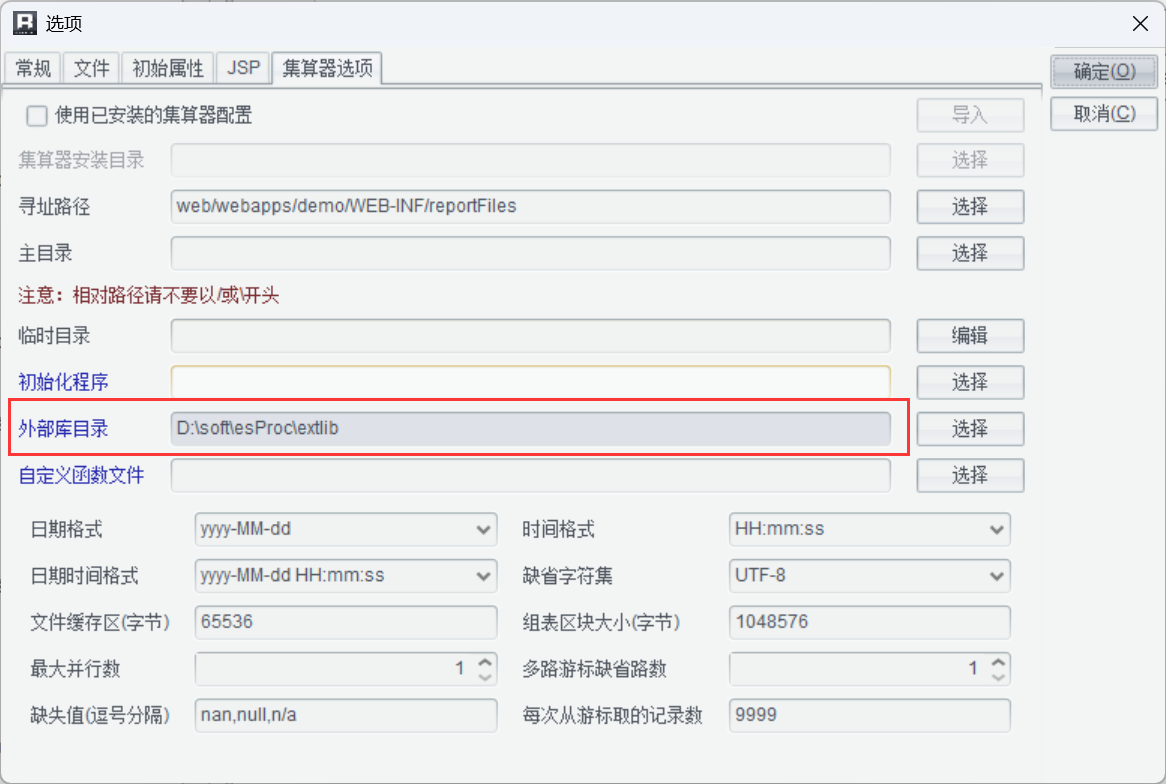
所有外部库接口到这下载: 集算器 (SPL) 最新版发布啦『发布日期 20250605』
然后勾选 MongoDB 就可以了:
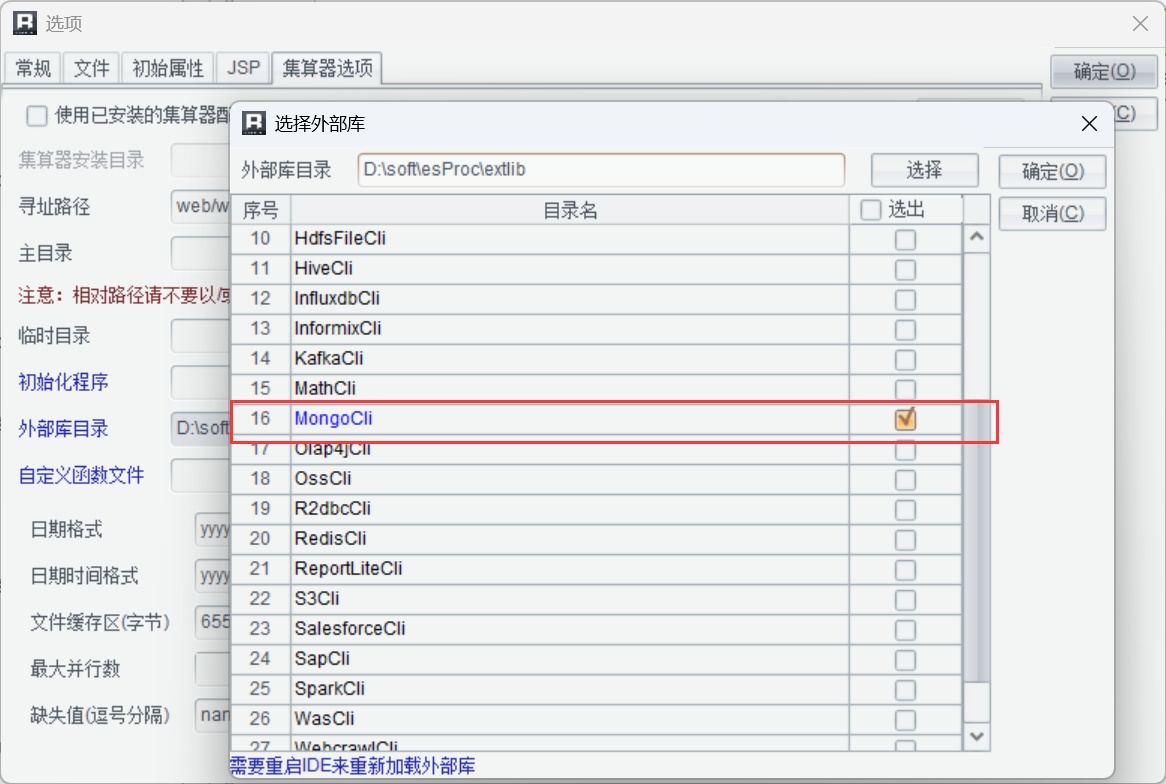
上面这些配置都是一次性的。
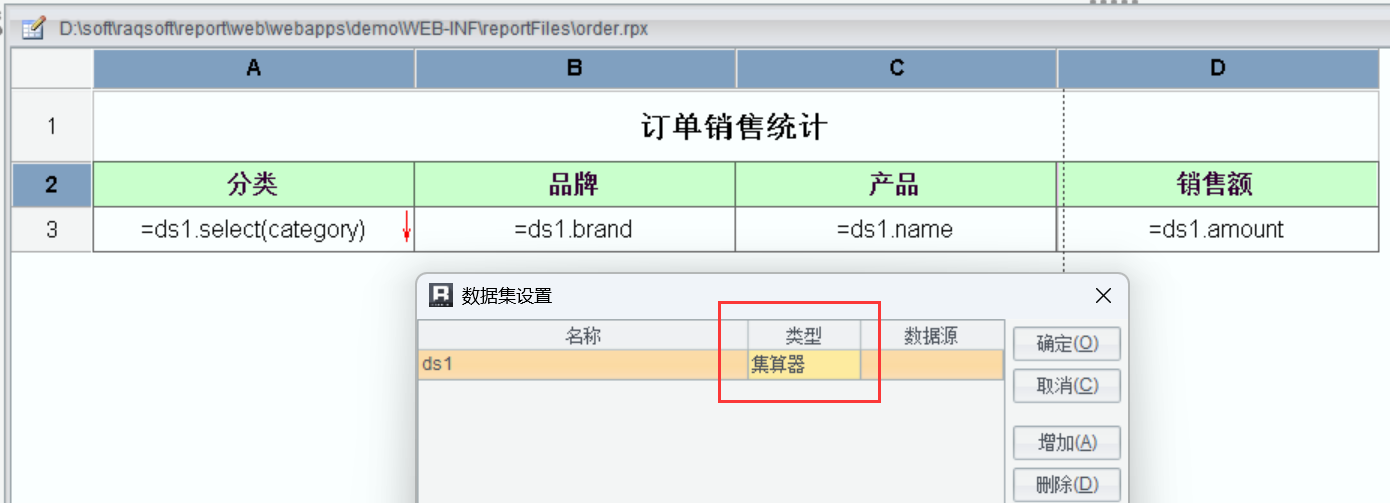
因为 SPL 已经内置到润乾报表中,开发报表模板的时候选择数据集为“集算器”,然后指定 SPL 脚本即可。
指定脚本并传递参数:
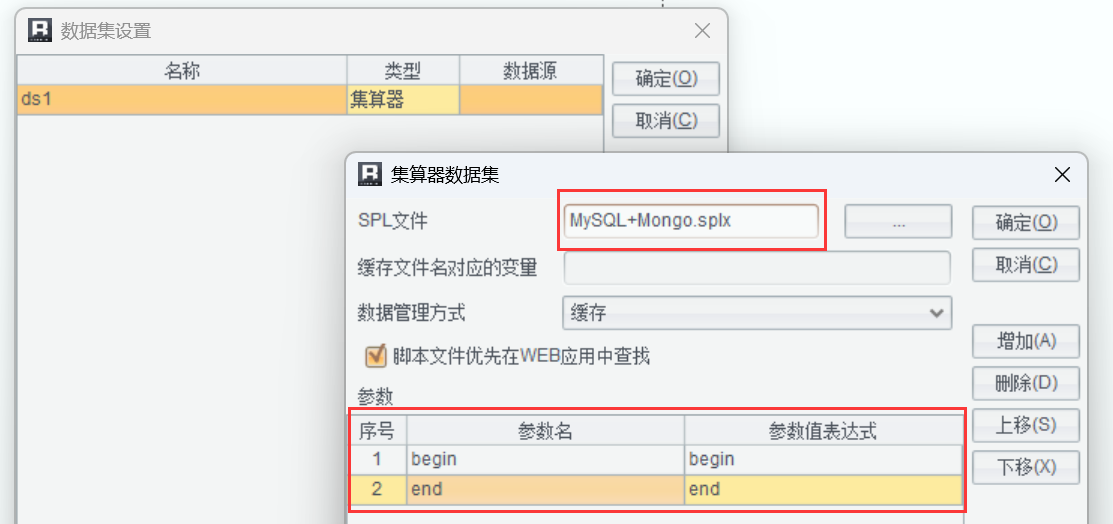
整个过程报表模板很简单,主要还是 SPL 完成数据混算部分。数据源都是直连混算,不涉及数据搬迁,也不需要做逻辑映射,任何数据源只要连上就能混算。比如 Kafka 和 MongoDB 混算也是类似的:
| A | |
| 1 | =kafka_open("/mafia/my.properties","topic-order") |
| 2 | =kafka_poll(A1) |
| 3 | =json(A2.value) |
| 4 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 5 | =mongo_shell@d(A4,"{'find':'products'}") |
| 6 | =A3.join(product_id,A5:product_id,product_id,name,brand,category,attributes) |
| 7 | return A6.select(category== arg_category) |
不仅是小数据,大数据也能轻松支持。前面 MySQL 和 MongoDB 混算如果数据量比较大可以这样混算:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.cursor@x ("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date>=? and o.order_date<=? ORDER BY oi.product_id ASC ",begin,end) |
| 3 | =mongo_open("mongodb://127.0.0.1:27017/raqdb") |
| 4 | =mongo_shell@dc(A3,"{'find':'products','filter': {},'sort': {'product_id': 1}}") |
| 5 | =joinx(A2:o,product_id;A4:p,product_id) |
| 6 | =A5.groups(category,brand,name;sum(price*quantity):amount) |
| 7 | return ifn(A6,create(category,brand,name,amount)) |
A2 和 A4 的数据查询都改成游标分批加载数据,然后进行游标关联,最后进行分组汇总并返回结果。这里汇总后的结果集已经不大了,所以直接全部返回;如果结果集比较大,SPL 脚本可以直接返回游标,润乾报表提供了大报表功能可以直接基于游标分批呈现数据(具体参考论坛资料),因此可以满足任意数据源任意数据规模的报表查询。
具备如此强大多源混算能力的润乾报表只要极低成本就可以永久使用:一万一套,三万买断。