关于深度学习网络中的归一化BN
以这篇论文为例,GhostNet: More Features from Cheap Operations
论文中提出了一种新型的模型,Ghost Model,这种模型在构建的时候每次走完一个GhostModel都要进行一次归一化BN。
那么为什么模型中要经常进行归一化BN,它有什么作用?
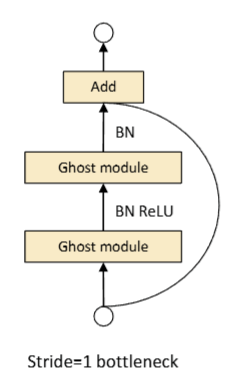
什么是BN?
BN--Batch Normalization--批量归一化,它有如下作用:
- 稳定训练:神经网络训练时,每层输入的分布会因为前面层参数更新而变化(叫 “内部协变量偏移”)。BN 会把每层输出的特征做归一化(均值 0、方差 1 ),让输入分布更稳定,这样模型训练更顺滑,不容易出现梯度消失、爆炸,也能加速收敛。
- 减少过拟合:相当于给训练加了 “小扰动”(归一化过程会引入少量噪声 ),让模型没那么 “死板”,泛化能力更强,测试集上表现更好。
- 缓解梯度依赖:让每层的更新不太受前面层的影响,梯度传递更稳定,深层网络也能好好训练。
有的小伙伴就要问了,为什么一定需要BN 会把每层输出的特征做归一化(均值 0、方差 1 ),这个均值 0、方差 1又是什么意思?
归一化(均值 0、方差 1 )
把一组数据处理成 平均值为 0,数据之间离散程度(方差)为 1 的新数据,在神经网络里,它主要是为了让模型训练更顺畅,
- 均值(平均值):就是把一堆数加起来,除以数的个数。比如数据是
[1, 3, 5],均值就是(1+3+5)/3 = 3,反映这组数据的 “中心位置” 。 - 方差:衡量数据有多 “散” 。计算方式是:先算每个数和均值的差的平方,再加起来求平均。还是
[1, 3, 5],和均值3的差分别是-2、0、2,平方后是4、0、4,方差就是(4+0+4)/3 ≈ 2.67,方差越大,数据越分散。
当我们说 “把数据归一化成均值 0、方差 1” ,实际是做这两步:
- 减均值:把每个数据都减去这组数据的均值,让新数据的均值变成 0 。
比如原数据均值是3,每个数减3,[1, 3, 5]就变成[-2, 0, 2],新均值就是0。 - 除以标准差(标准差是方差的平方根 ):把减均值后的数据,再除以原数据的标准差,让新数据的方差变成 1 。
原数据方差≈2.67,标准差≈1.63,[-2, 0, 2]每个数除以1.63,得到[-1.23, 0, 1.23],新方差就接近1(计算会有细微误差,因为是近似值 )。
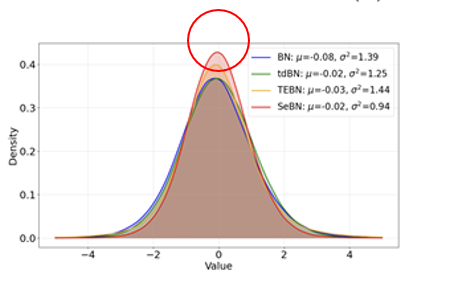
类似这种图,均值在0,且在正负一之间波动
为什么一定要归一化(均值 0、方差 1 )
把每层输入的数据归一化成均值 0、方差 1,本质是给模型打造 “稳定的训练环境” ,分两步实现稳定:
1. 均值 0:让数据 “居中”,避免整体偏移
假设某层输入数据原本均值是 100(比如图像像素值 ),经过计算后,输出可能整体偏大;如果下一层输入又因为参数更新,均值变成 50,数据分布就会剧烈波动。
归一化成均值 0 后,数据始终围绕 0 对称分布,相当于给每层输入定了个 “中心点”,避免因均值偏移导致输出整体飘移 ,让后续计算更可控。
2. 方差 1:让数据 “整齐”,限制波动幅度
方差衡量数据的 “离散程度”。如果方差太大(比如数据在 - 1000 到 1000 之间 ),经过多层网络计算后,数值会像 “滚雪球” 一样爆炸式增长;如果方差太小(比如数据都在 0.001 附近 ),数值会逐渐 “消失”,梯度也跟着消失。
归一化成方差 1 后,数据波动被限制在 **“以 0 为中心,±1 左右的范围”**(根据正态分布特性,大部分数据会落在 - 3 到 3 之间 )。这样:
- 每层计算时,数值不会因多层叠加 “失控”;
- 梯度反向传播时,也能保持合理的更新幅度(不会爆炸或消失 )。