【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(2)——提示词
Spring AI框架快速入门
- 一、前言
- 二、API 概述
- 2.1 Prompt
- 2.2 Message
- 2.3 PromptTemplate
- 三、使用示例
- 3.1 使用自定义模板渲染器
- 3.2 使用资源而不是原始字符串
- 四、多模态
- 4.1 使用示例
- 五、token
- Spring AI 系列文章:
一、前言
前一篇文章《【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(1)——Chat Client API》中,介绍了Chat Client API的基本用法,这篇文章说说什么是提示词。
提示词(Prompt)是AI模型的输入,提示词的设计和措辞会影响模型的输出。提示词创建能包含占位符,可以类比成一个包含某些占位符的sql语句。
二、API 概述
2.1 Prompt
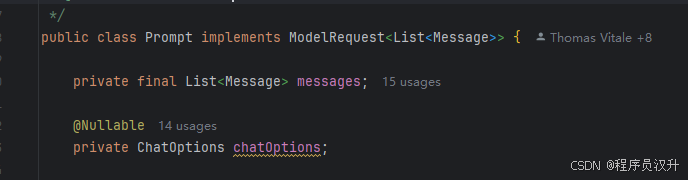
在源码中,ChatModel的call()方法接收一个Prompt实例,并返回ChatResponse

而Prompt又包含Message和ChatOptions类。
2.2 Message
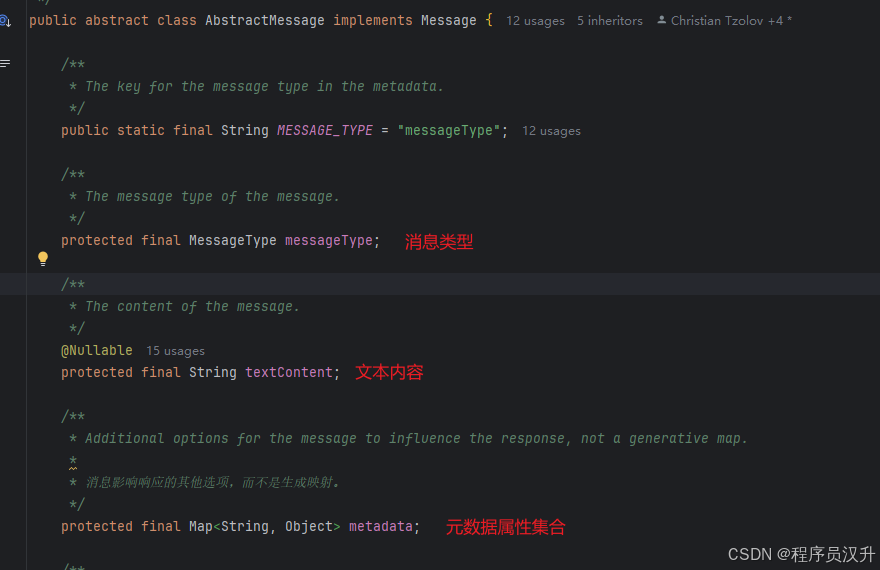
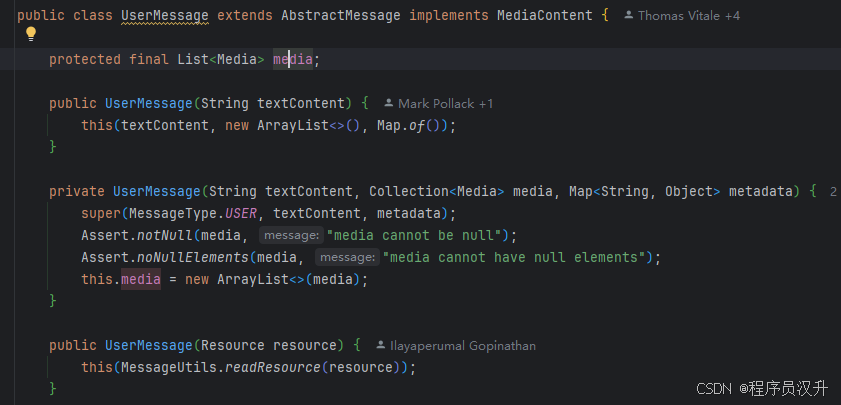
Message 接口封装了 Prompt 文本内容、元数据属性集合和称为 MessageType的分类。
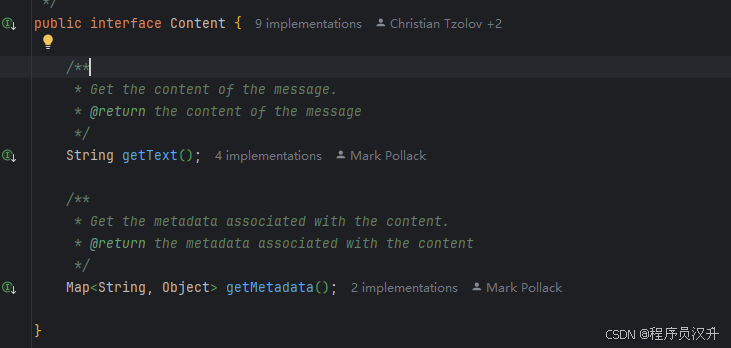
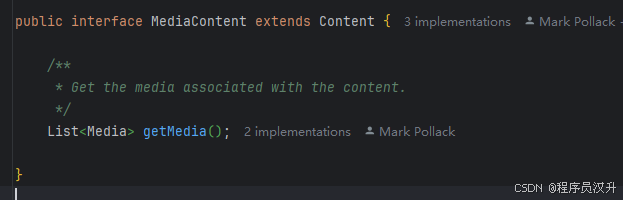
多模态消息类型还实现了 MediaContent 接口,提供 Media 内容对象列表。
每个Message有不同的实现类,定义了不同的类型的消息,AbstractMessage实现类中定义了四种角色类型,Message 接口的各种实现对应于 AI 模型可以处理的不同类别的消息。 模型根据对话角色区分消息类别。
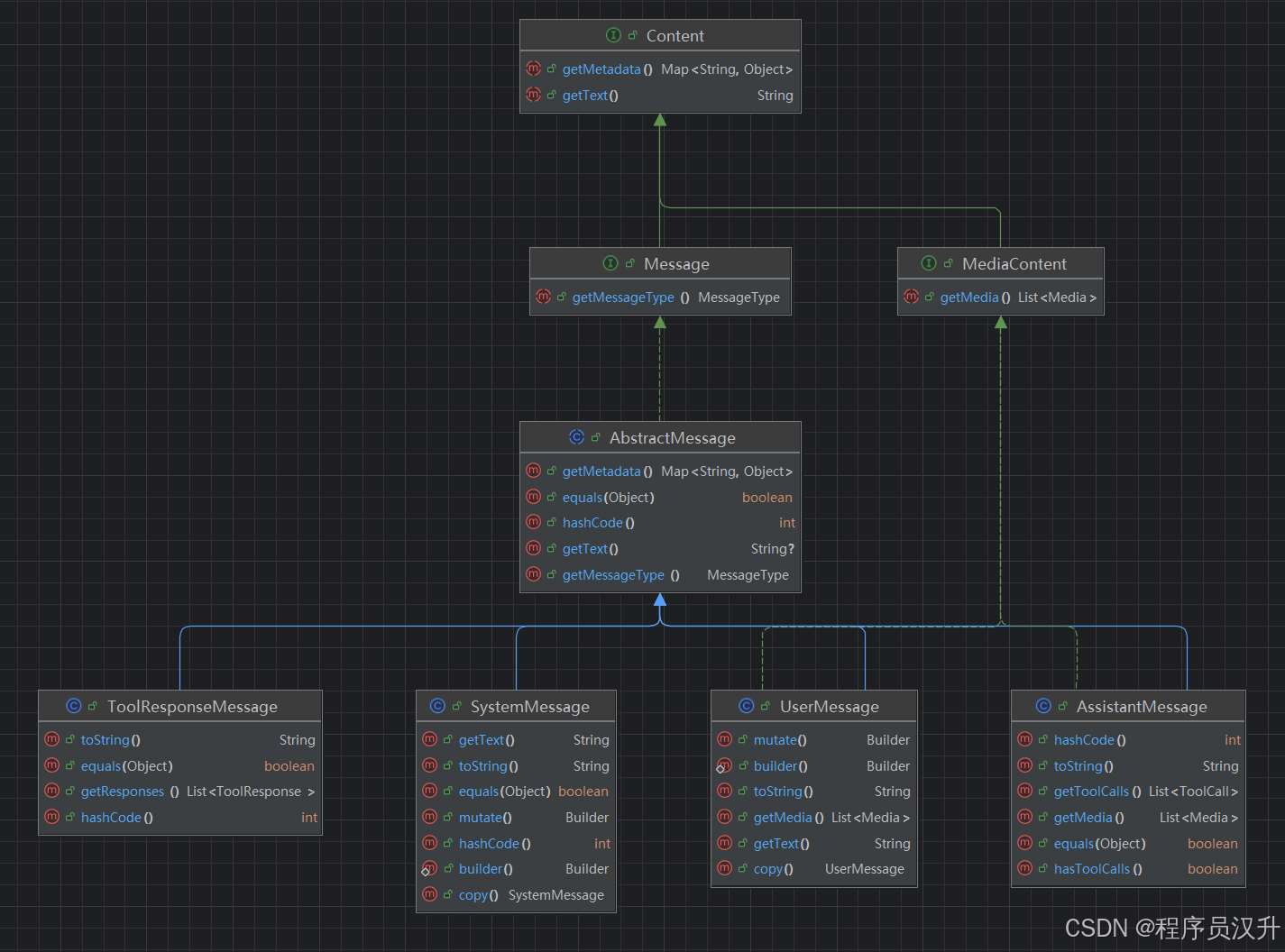
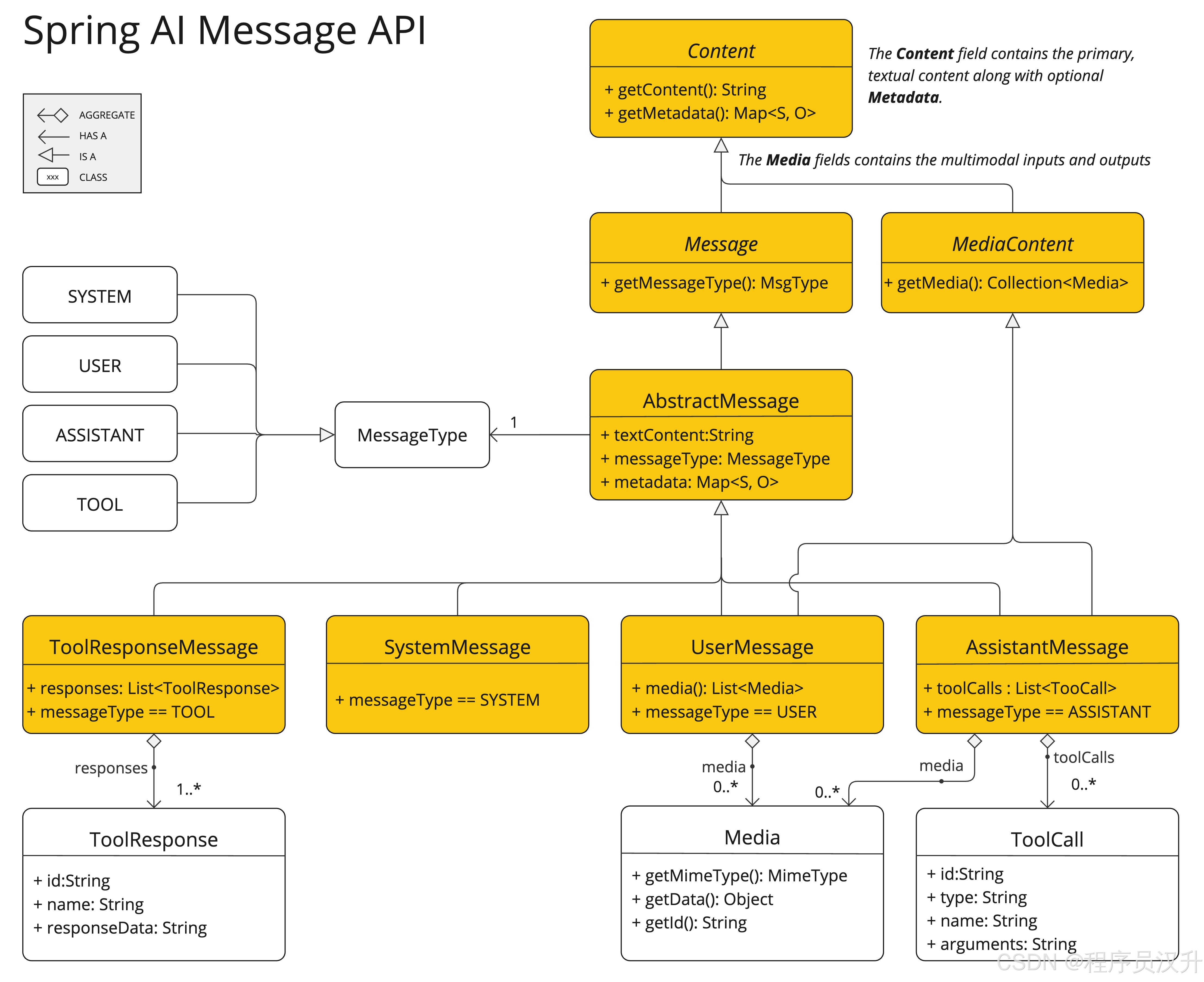
消息类型
每个消息都被分配一个特定的角色。 这些角色对消息进行分类,为 AI 模型阐明提示词每个部分的上下文和目的。 这种结构化方法增强了与 AI 交流的细微差别和有效性,因为提示词的每个部分在交互中都扮演着独特和定义明确的角色。

主要角色包括:
-
系统角色:指导 AI 的行为和响应风格,设置 AI 如何解释和回复输入的参数或规则。这就像在开始对话之前向 AI 提供指令。- 示例:告诉 AI “你是一个严谨的简历优化助手。”
-
用户角色:表示用户的输入,表示用户发给 AI 的消息。这个角色是基础性的,因为它构成了 AI 响应的基础。- 示例:用户输入 “你好,请帮我写一份简历。”
-
助手角色:AI 对用户输入的响应。 不仅仅是答案或反应,它对于维持对话流程至关重要。 通过跟踪 AI 的先前响应(其"助手角色"消息),系统确保连贯和上下文相关的交互。 助手消息可能还包含函数工具调用请求信息。 这就像 AI 中的一个特殊功能,在需要时用于执行特定功能,如计算、获取数据或其他超出简单对话的任务。- 示例:AI 回答:“好的,请提供你的工作经历。”
-
工具/函数角色:工具/函数角色专注于返回响应工具调用助手消息的额外信息。- 示例:插件(Tool)执行完毕后的响应,比如调用日历 API 返回的时间数据。
在构造消息上下文列表时(如传给 ChatClient.call(List<Message>)),你一般会创建如下结构:
List<Message> messages = List.of(new SystemMessage("你是一个 Java 教师"),new UserMessage("请解释一下 Stream 的用法")
);
2.3 PromptTemplate
Spring AI 中提示词模板化的关键组件是 PromptTemplate 类,促进创建结构化提示词,然后发送给 AI 模型进行处理。

这个类使用 TemplateRenderer API 来渲染模板。默认情况下,Spring AI 使用 StTemplateRenderer 实现,它基于 Terence Parr 开发的开源 StringTemplate 引擎。模板变量由 {} 语法标识,但也可以配置分隔符以使用其他语法。
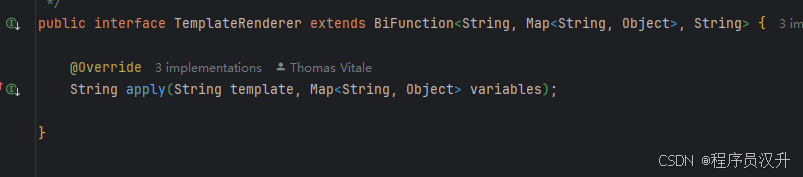
Spring AI 使用 TemplateRenderer 接口来处理将变量替换到模板字符串中。 默认实现使用StringTemplate。 如果需要自定义逻辑,可以提供自己的 TemplateRenderer 实现。 对于不需要模板渲染的场景(例如,模板字符串已经完整),可以使用提供的 NoOpTemplateRenderer。
使用带有 ‘<’ 和 ‘>’ 分隔符的自定义 StringTemplate 渲染器的示例
PromptTemplate promptTemplate = PromptTemplate.builder().renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build()).template("""告诉我 5 部由 <actor> 主演的电影名称。""").build();String prompt = promptTemplate.render(Map.of("actor", "成龙"));
这个类实现的接口支持创建不同类型的提示词:
-
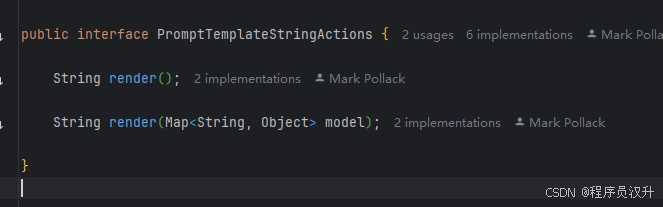
PromptTemplateStringActions专注于创建和渲染提示词字符串。 -
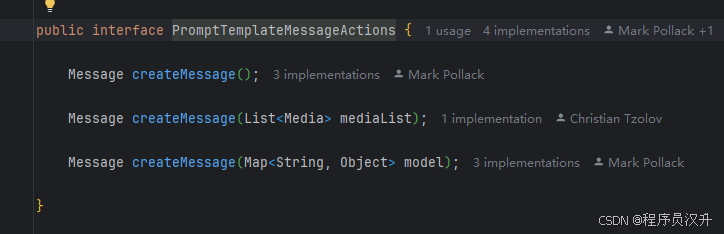
PromptTemplateMessageActions专门用于通过生成和操作Message对象来创建提示词。 -
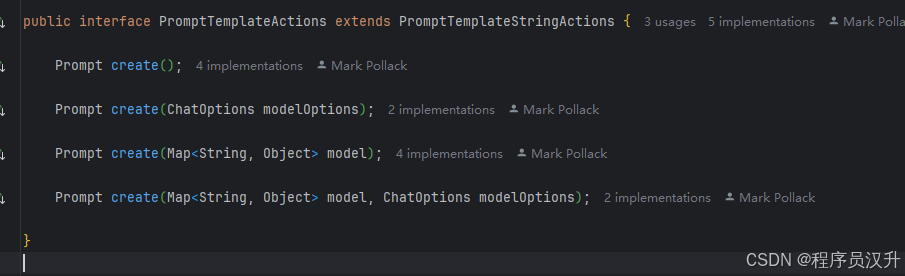
PromptTemplateActions设计用于返回Prompt对象,可以传递给ChatModel以生成响应。
虽然这些接口在许多项目中可能不会广泛使用,但它们展示了提示词创建的不同方法。
-
方法
String render():将提示词模板渲染成最终字符串格式,无需外部输入,适用于没有占位符或动态内容的模板。 -
方法
String render(Map<String, Object> model):增强渲染功能以包含动态内容。它使用Map<String, Object>,其中映射键是提示词模板中的占位符名称,值是待插入的动态内容。
-
方法
Message createMessage():创建没有额外数据的Message对象,用于静态或预定义的消息内容。 -
方法
Message createMessage(List<Media> mediaList):创建具有静态文本和媒体内容的Message对象。 -
方法
Message createMessage(Map<String, Object> model):扩展消息创建以集成动态内容,接受Map<String, Object>,其中每个条目代表消息模板中的占位符及其对应的动态值。
-
方法
Prompt create():生成没有外部数据输入的Prompt对象,适用于静态或预定义的提示词。 -
方法
Prompt create(ChatOptions modelOptions):生成没有外部数据输入且具有特定聊天请求选项的Prompt对象。 -
方法
Prompt create(Map<String, Object> model):扩展提示词创建功能以包含动态内容,接受Map<String, Object>,其中每个映射条目是提示词模板中的占位符及其关联的动态值。 -
方法
Prompt create(Map<String, Object> model, ChatOptions modelOptions):扩展提示词创建功能以包含动态内容,接受Map<String, Object>,其中每个映射条目是提示词模板中的占位符及其关联的动态值,以及聊天请求的特定选项。
三、使用示例
配置相关的见第一篇文章《【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(1)——Chat Client API》,这里直接上代码示例片段:
代码地址:GitHub
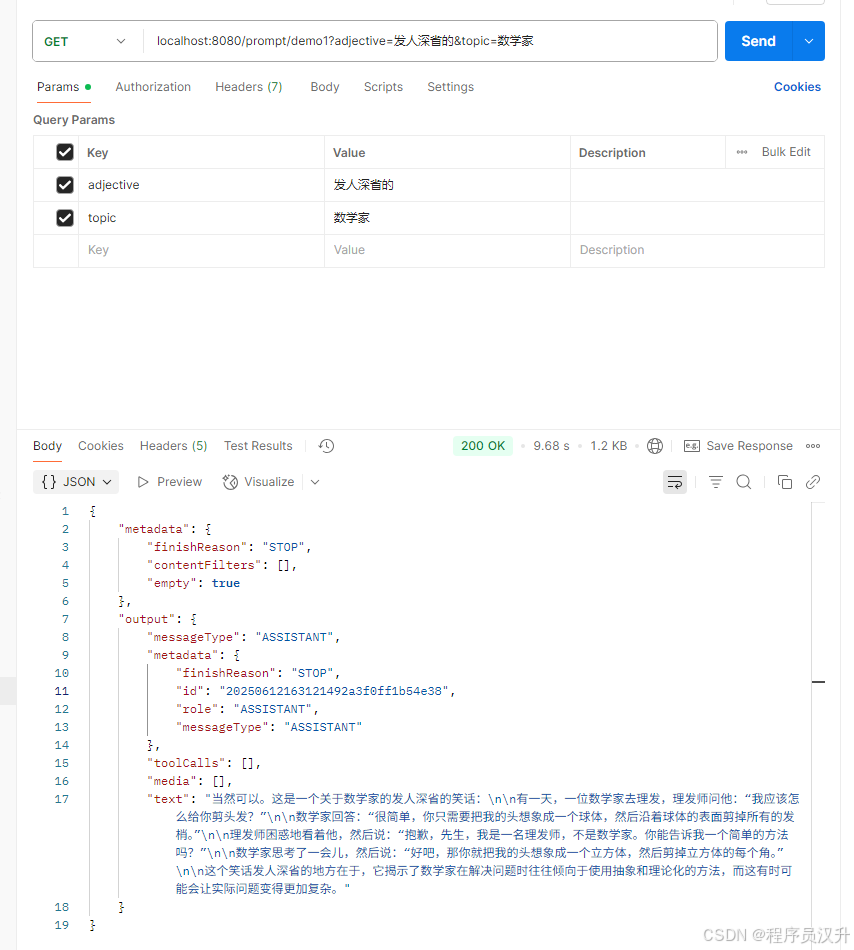
demo1:
@RestController
public class PromptController {@Resource(name = "zhiPuAiChatModel")private ChatModel chatModel;@GetMapping("/prompt/demo1")Generation demo1(@RequestParam("adjective") String adjective, @RequestParam("topic") String topic) {PromptTemplate promptTemplate = new PromptTemplate("告诉我一个关于 {topic} 的 {adjective} 笑话");Prompt prompt = promptTemplate.create(Map.of("adjective", adjective, "topic", topic));return chatModel.call(prompt).getResult();}
}
执行结果:
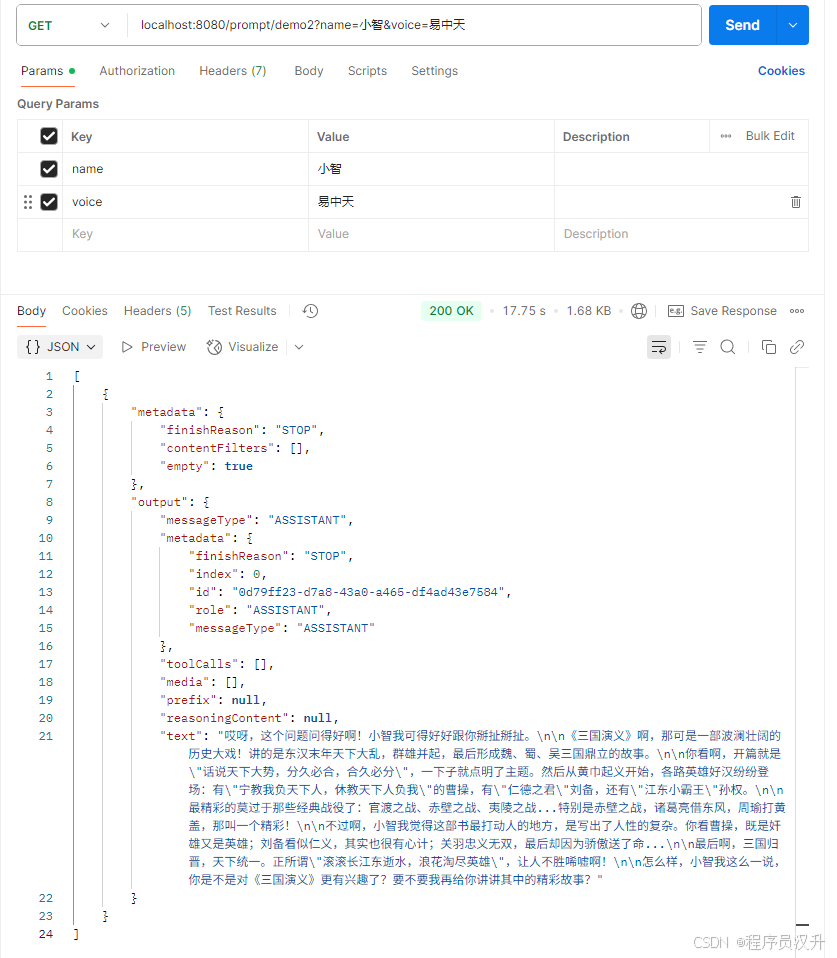
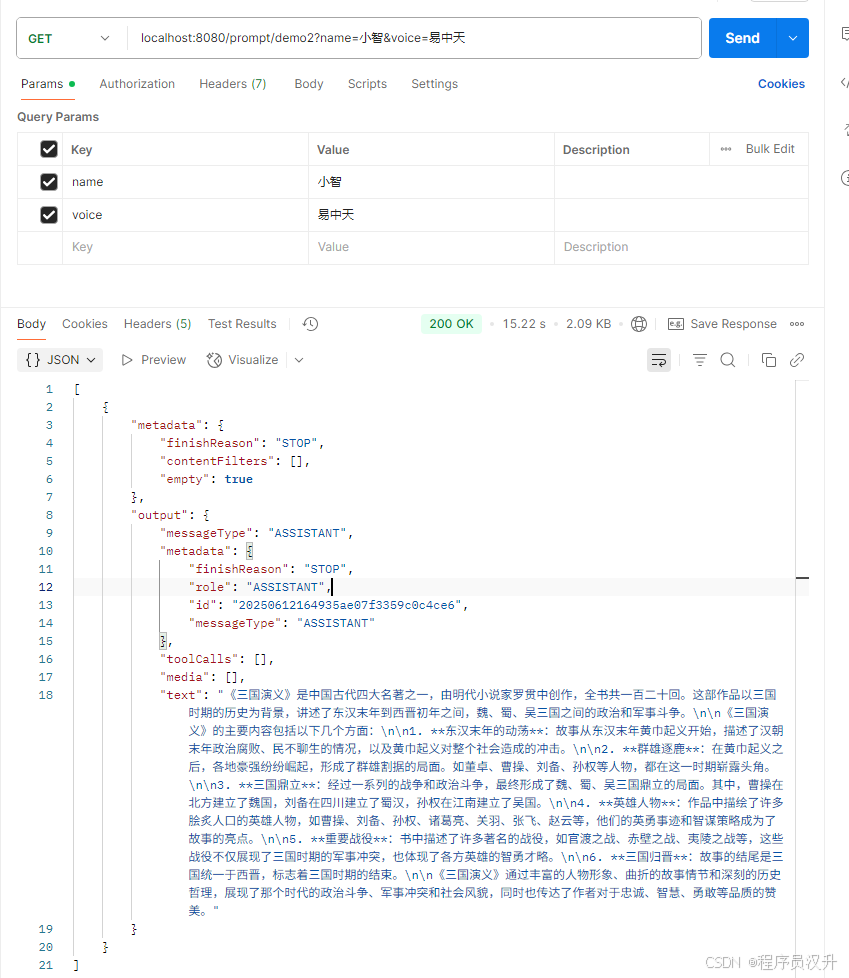
demo2:
这展示了如何使用 SystemPromptTemplate 创建一个带有系统角色的 Message,并传入占位符值。 然后,带有 user 角色的消息与带有 system 角色的消息组合形成提示词。 然后将提示词传递给 ChatModel 以获取生成响应。
@GetMapping("/prompt/demo2")
List<Generation> demo2(@RequestParam("name") String name, @RequestParam("voice") String voice) {String userText = """告诉三国演义这篇著作讲了什么内容""";Message userMessage = new UserMessage(userText);String systemText = """你是一个帮助人们查找信息的 AI 助手。你的名字是 {name}你应该用你的名字回复用户的请求,并且用 {voice} 的风格。""";SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemText);Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "voice", voice));Prompt prompt = new Prompt(List.of(userMessage, systemMessage));return chatModel.call(prompt).getResults();
}
执行结果:
deepSeek版本:
zhiPu版本:
3.1 使用自定义模板渲染器
可以通过实现 TemplateRenderer 接口并将其传递给 PromptTemplate 构造函数来使用自定义模板渲染器。也可以继续使用默认的 StTemplateRenderer,但使用自定义配置。
默认情况下,模板变量由 {} 语法标识。如果计划在提示词中包含 JSON,可能希望使用不同的语法以避免与 JSON 语法冲突。例如,可以使用 < 和 > 分隔符。
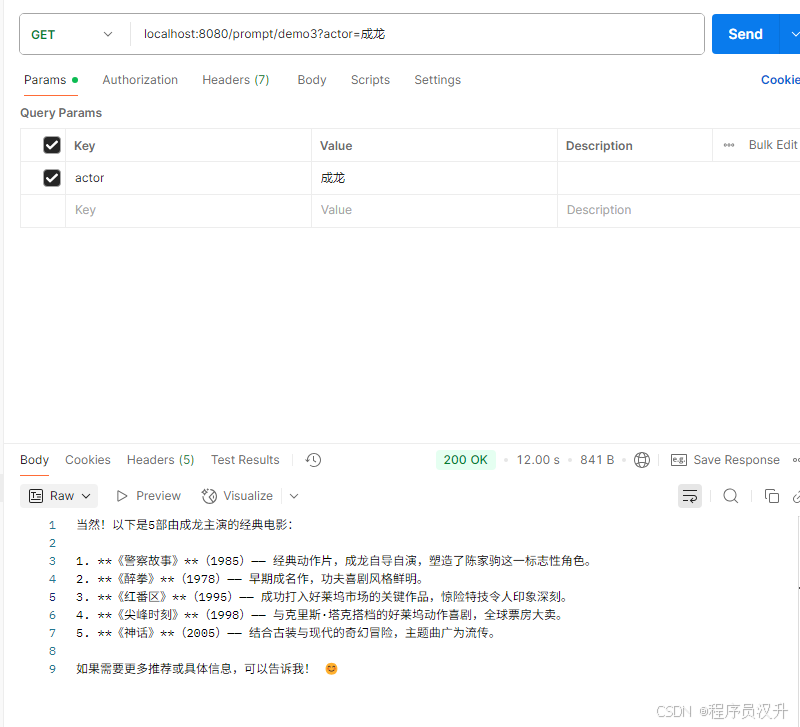
@GetMapping("/prompt/demo3")
String demo3(@RequestParam("actor") String actor) {PromptTemplate promptTemplate = PromptTemplate.builder().renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build()).template("""告诉我 5 部由 <actor> 主演的电影名称。""").build();String prompt = promptTemplate.render(Map.of("actor", actor));return chatModel.call(prompt);
}
执行结果:
3.2 使用资源而不是原始字符串
Spring AI 支持 org.springframework.core.io.Resource 抽象,因此可以将提示词数据放在文件中,可以直接在 SystemPromptTemplate 中使用文件。 例如,可以在 Spring 管理的组件中用@Value()注解来检索 Resource。
首先在resource下定义一个system-message.st文件,用于存放系统提示词
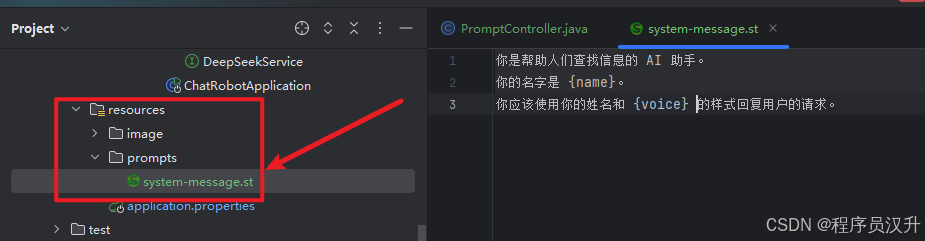
然后直接将该资源传递给 SystemPromptTemplate。
示例代码:
@Value("classpath:/prompts/system-message.st")
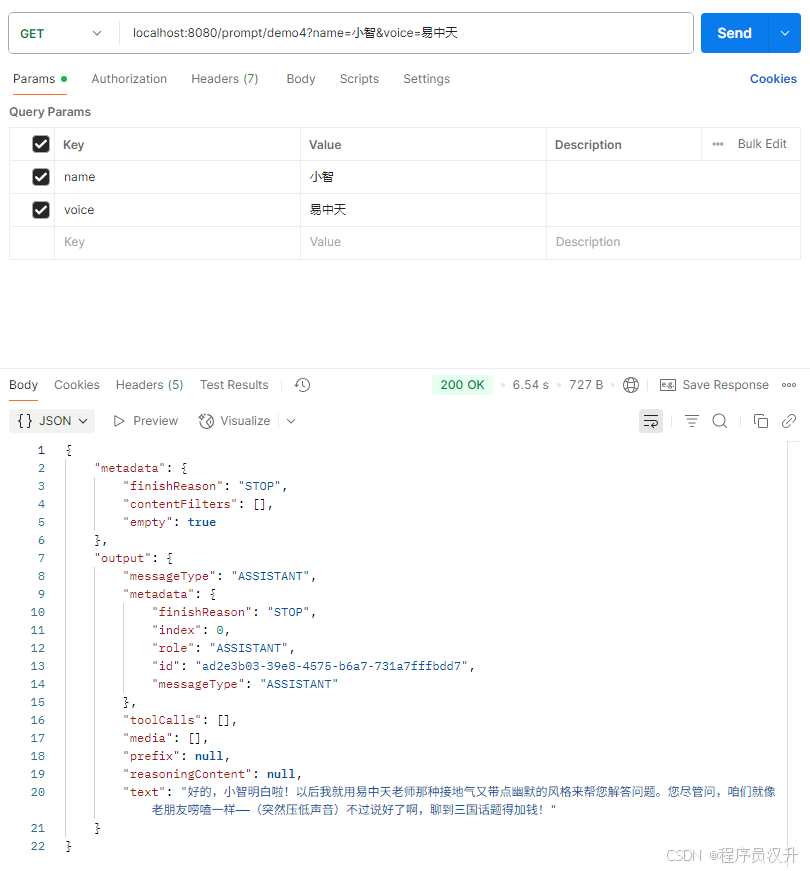
private org.springframework.core.io.Resource systemResource;@GetMapping("/prompt/demo4")
Generation demo4(@RequestParam("name") String name, @RequestParam("voice") String voice) {SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemResource);Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "voice", voice));Prompt prompt = new Prompt(systemMessage);return chatModel.call(prompt).getResult();
}
执行结果:
四、多模态
人类同时通过多种数据输入模式处理知识。 我们的学习方式和经验都是多模态的。 我们不仅仅有视觉、音频和文本。
与此相反,机器学习往往专注于处理单一模态的专门模型。 例如,开发了用于文本到语音或语音到文本等任务的音频模型,以及用于对象检测和分类等任务的计算机视觉模型。
新一代的多模态大型语言模型开始出现。 例如,OpenAI 的 GPT-4o、Google 的 Vertex AI Gemini 1.5、Anthropic 的 Claude3,以及开源产品 Llama3.2、LLaVA 和 BakLLaVA 都能够接受多种输入,包括文本图像、音频和视频,并通过整合这些输入生成文本响应。
注意:多模态大型语言模型(LLM)功能使模型能够处理文本并结合其他模态(如图像、音频或视频)生成文本。
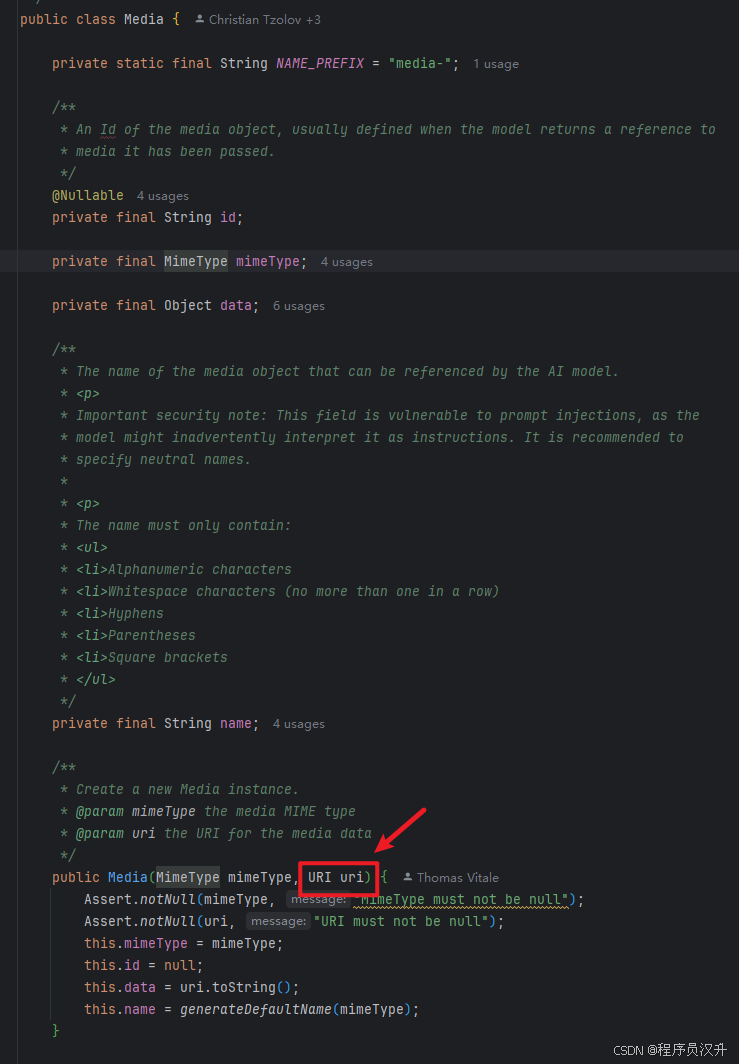
在2.2小节中提到,UserMessage 的 content 字段主要用于文本输入,而可选的 media 字段允许添加一个或多个不同模态的额外内容,如图像、音频和视频。 MimeType 指定模态类型。 根据使用的 LLM,Media 数据字段可以是作为 Resource 对象的原始媒体内容,也可以是内容的 URI。
注意:media 字段目前仅适用于用户输入消息(例如,UserMessage)。它对系统消息没有意义。包含 LLM 响应的 AssistantMessage 仅提供文本内容。要生成非文本媒体输出,应该使用专门的单模态模型之一。
4.1 使用示例
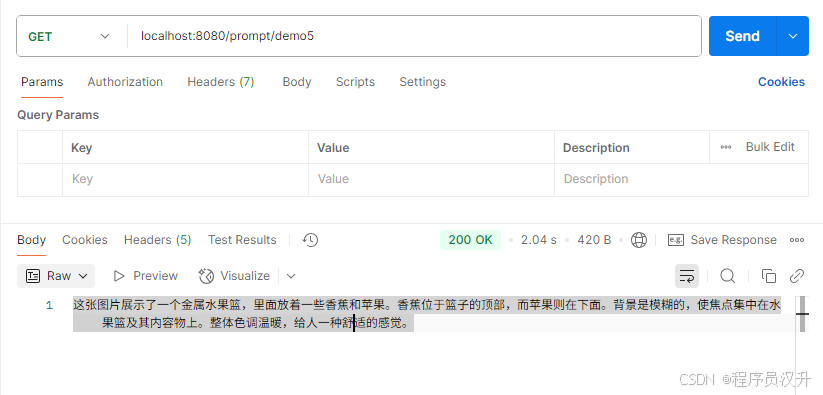
例如,我们可以将以下图片(multimodal.png)作为输入,并要求 LLM 解释它看到的内容。图片文件放在resources目录下的image文件夹中

大模型的话,选择zhiPu的glm-4v-flash,毕竟目前还能白嫖!!!
yml文件中修改模型
spring.ai.zhipuai.chat.options.model=glm-4v-flash
@Resource(name = "zhiPuAiChatModel")
// @Resource(name = "deepSeekChatModel")
private ChatModel chatModel;@GetMapping("/prompt/demo5")
String demo5() {return ChatClient.create(chatModel).prompt().user(u -> u.text("解释你在这张图片上看到了什么?").media(MimeTypeUtils.IMAGE_PNG, new ClassPathResource("/image/multimodal.png"))).call().content();
}
执行结果:
五、token
token 在 AI 模型处理文本的方式中至关重要,作为将单词转换为 AI 模型可以处理的格式的桥梁。 这种转换发生在两个阶段:单词在输入时转换为token,然后这些token在输出时转换回单词。
token化,即将文本分解为token的过程,是 AI 模型理解和处理语言的基础。 AI 模型使用这种token化格式来理解和响应提示词。
为了更好地理解token,可以将它们视为单词的部分。通常,一个token代表大约四分之三个单词。例如,莎士比亚的完整作品,总计约 90 万字,将转换为约 120 万个token。
使用 OpenAI Tokenizer UI 来实验单词如何转换为token。
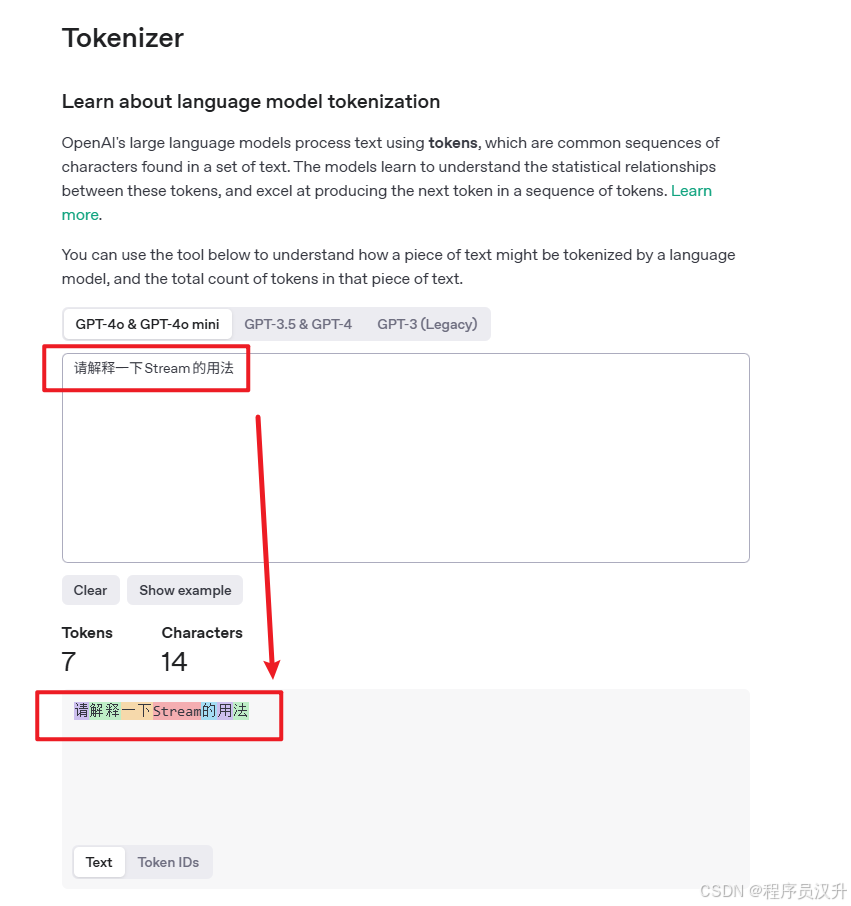
token除了在 AI 处理中的技术作用外,还具有实际意义,特别是在计费和模型能力方面:
-
计费:AI 模型服务通常基于
token使用量计费。输入(提示词)和输出(响应)都计入总token数,使较短的提示词更具成本效益。 -
模型限制:不同的 AI 模型有不同的
token限制,定义它们的"上下文窗口" - 它们一次可以处理的最大信息量。例如,GPT-3 的限制是 4Ktoken,而其他模型如 Claude 2 和 Meta Llama 2 的限制是 100Ktoken,一些研究模型可以处理多达 100 万个token。 -
上下文窗口:模型的
token限制决定了其上下文窗口。超过此限制的输入不会被模型处理。只发送处理所需的最小有效信息集至关重要。例如,当询问"哈姆雷特"时,不需要包含莎士比亚所有其他作品的token。 -
响应元数据:AI 模型响应的元数据包括使用的
token数,这是管理使用量和成本的重要信息。
Prompt部分内容讲完,下一篇讲结构化输出转换器(Structured Output Converter)~
Spring AI 系列文章:
【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(1)——Chat Client API
创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️
