【cv学习笔记】YOLO系列笔记
写在前面:本文主要介绍YOLO系列的整体框架,以及改进点的介绍。前面有型号的类型是经典,常被应用,YOLOv5,YOLOv8,和YOLOv11是ultralytics公司作品
*YOLOv5
Ultralytics YOLOv5 -Ultralytics YOLO 文档
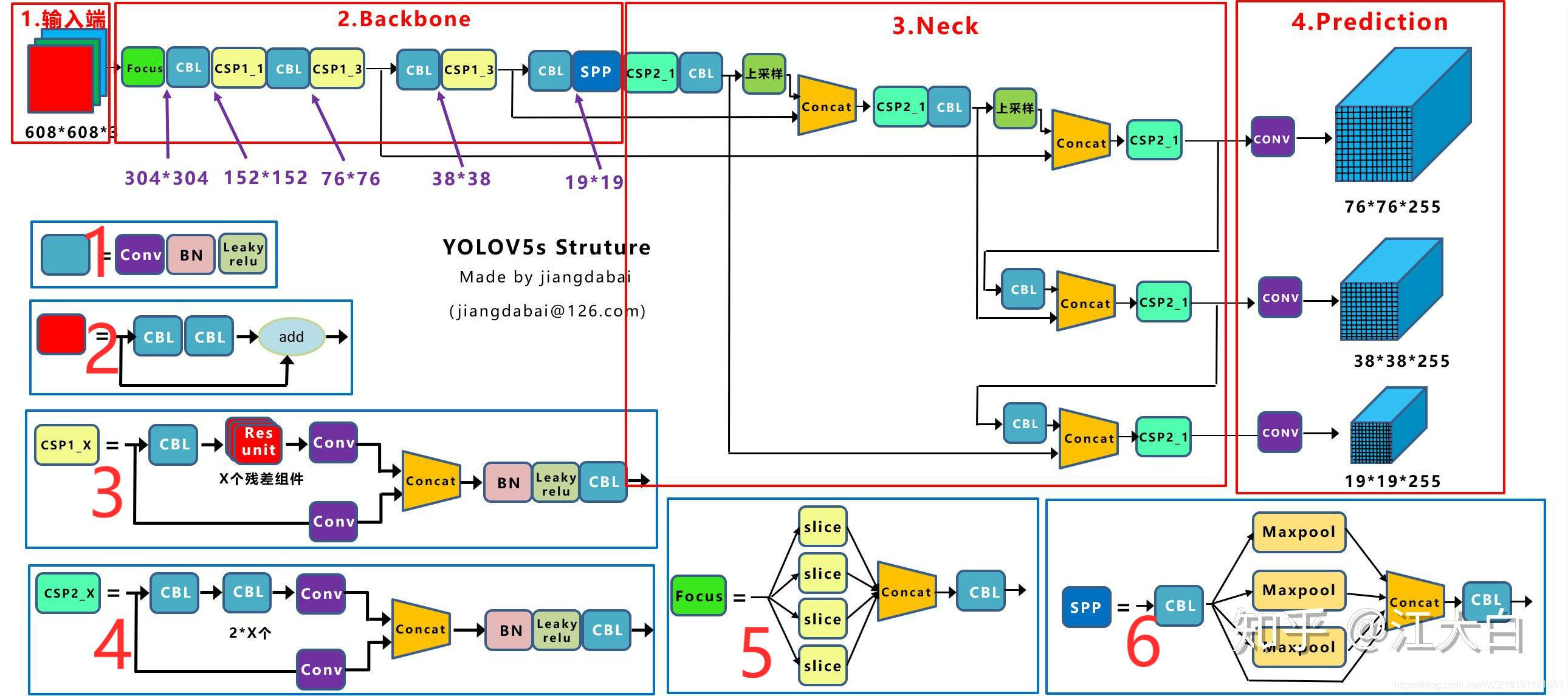
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
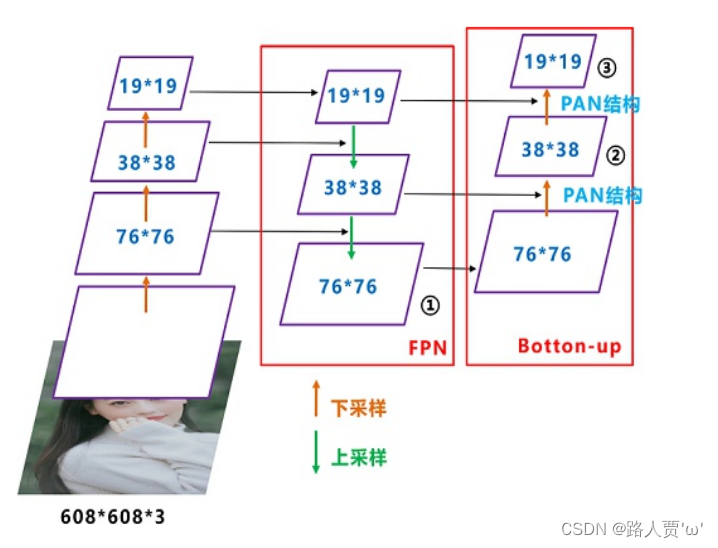
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
输入端细节详解
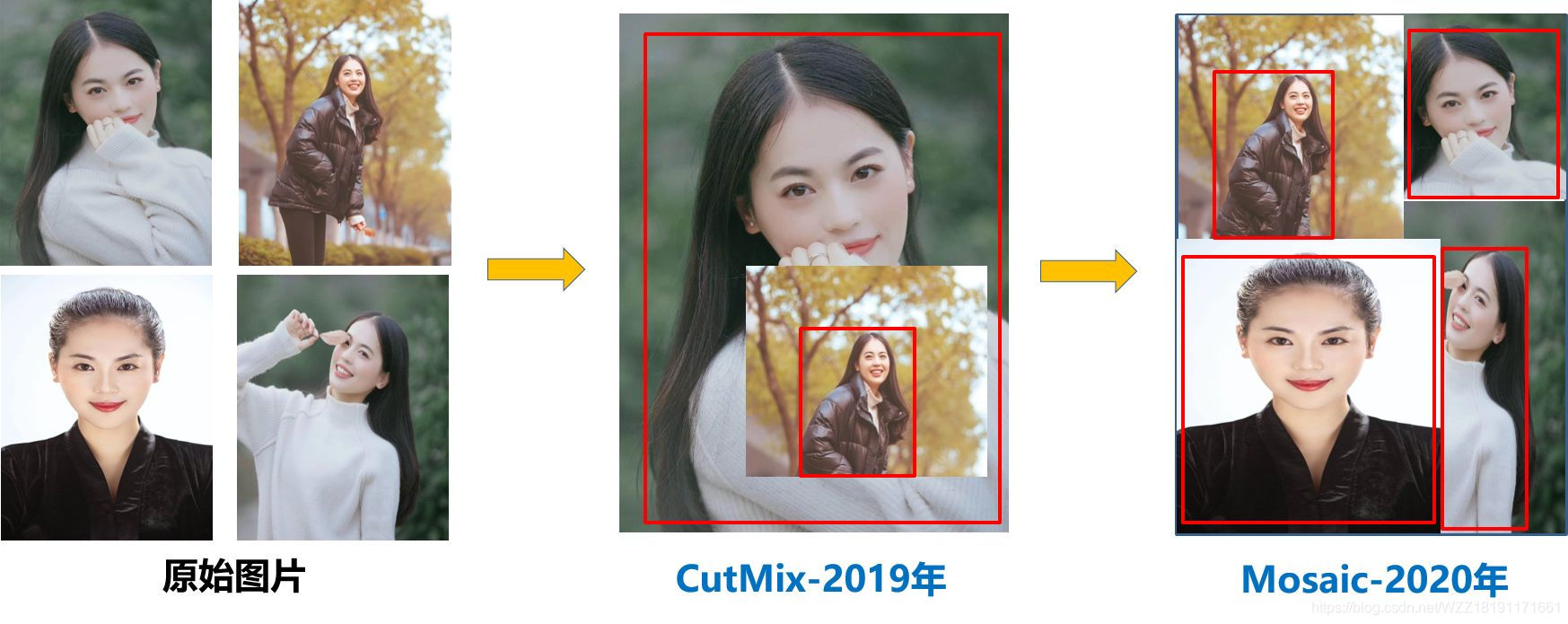
Mosaic数据增强:
YOLOv5中在训练模型阶段仍然使用了Mosaic数据增强方法,该算法是在CutMix数据增强方法的基础上改进而来的。CutMix仅仅利用了两张图片进行拼接,而Mosaic数据增强方法则采用了4张图片,并且按照随机缩放、随机裁剪和随机排布的方式进行拼接而成,具体的效果如下图所示。这种增强方法可以将几张图片组合成一张,这样不仅可以丰富数据集的同时极大的提升网络的训练速度,而且可以降低模型的内存需求。
自适应锚框计算:
在YOLO系列算法中,针对不同的数据集,都需要设定特定长宽的锚点框。在网络训练阶段,模型在初始锚点框的基础上输出对应的预测框,计算其与GT框之间的差距,并执行反向更新操作,从而更新整个网络的参数,因此设定初始锚点框也是比较关键的一环。在YOLOv3和YOLOv4检测算法中,训练不同的数据集时,都是通过单独的程序运行来获得初始锚点框。YOLOv5中将此功能嵌入到代码中,每次训练时,根据数据集的名称自适应的计算出最佳的锚点框,用户可以根据自己的需求将功能关闭或者打开,具体的指令为parser.add_argument(‘–noautoanchor’, action=‘store_ true’, help=‘disable autoanchor check’),如果需要打开,只需要在训练代码时增加–noautoanch or选项即可。
自适应图片缩放:
针对不同的目标检测算法而言,我们通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO系列算法中常用的尺寸包括416*416,608 *608等尺寸。原始的缩放方法存在着一些问题,由于在实际的使用中的很多图片的长宽比不同,因此缩放填充之后,两端的黑边大小都不相同,然而如果填充的过多,则会存在大量的信息冗余,从而影响整个算法的推理速度。为了进一步提升YOLOv5算法的推理速度,该算法提出一种方法能够自适应的添加最少的黑边到缩放之后的图片中。具体的实现步骤如下所述。
步骤1-根据原始图片大小与输入到网络图片大小计算缩放比例。

步骤2-根据原始图片大小与缩放比例计算缩放后的图片大小。

步骤3-计算黑边填充数值。

如上图所示,416表示YOLOv5网络所要求的图片宽度,312表示缩放后图片的宽度。首先执行相减操作来获得需要填充的黑边长度104;然后对该数值执行取余操作,即104%32=8,使用32是因为整个YOLOv5网络执行了5次下采样操作,即2 5 = 32 2^{5} =3225=32;最后对该数值除以2,即将填充的区域分散到两边。这样将416*416大小的图片缩小到416*320大小,因而极大的提升了算法的推理速度。
需要注意的是:(1)该操作仅在模型推理阶段执行,模型训练阶段仍然和传统的方法相同,将原始图片裁剪到416*416大小;(2)YOLOv3与YOLOv4中默认填充的数值是(0,0,0),而YOLOv5中默认填充的数值是(114,114,114);(3)该操作仅仅针对原始图片的短边而言,仍然将长边裁剪到416。
模型结构
Focus结构(开销很大)
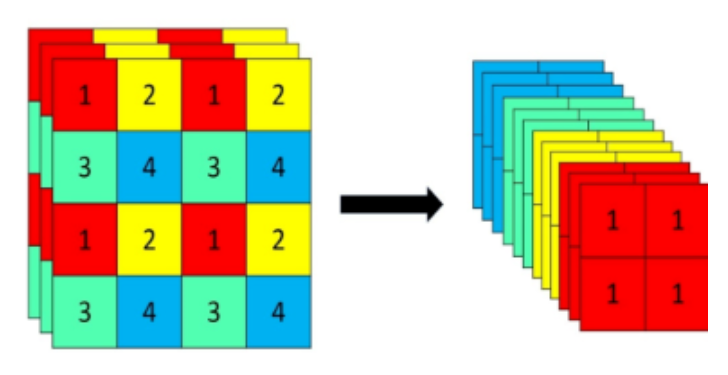
Focus模块在YOLOv5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以YOLOv5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。
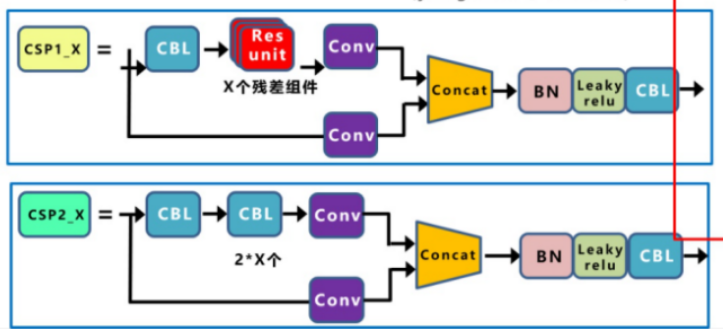
CSP结构
YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_ X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。 (没啥好说的)
Neck
YOLOv5现在的Neck和YOLOv4中一样,都采用FPN+PAN的结构。但是在它的基础上做了一些改进操作:YOLOV4的Neck结构中,采用的都是普通的卷积操作,而YOLOV5的Neck中,采用CSPNet设计的CSP2结构,从而加强了网络特征融合能力。
损失
Bounding box损失函数
YOLO v5采用CIOU_LOSS 作为bounding box 的损失函数。下面接扫一下不同iou损失:
经典IoU loss
IoU算法是使用最广泛的算法,大部分的检测算法都是使用的这个算法。
不足:没有相交则IOU=0无法梯度计算,相同的IOU却反映不出实际情况
GIOU(Generalized IoU)损失
GIoU考虑到,当检测框和真实框没有出现重叠的时候IoU的loss都是一样的,因此GIoU就引入了最小封闭形状C(C可以把A,B包含在内),在不重叠情况下能让预测框尽可能朝着真实框前进,这样就可以解决检测框和真实框没有重叠的问题。
公式:不足:但是在两个预测框完全重叠的情况下,不能反映出实际情况
DIOU(Distance IoU)损失
DIoU考虑到GIoU的缺点,也是增加了C检测框,将真实框和预测框都包含了进来,但是DIoU计算的不是框之间的交并,而是计算的每个检测框之间的欧氏距离,这样就可以解决GIoU包含出现的问题。
公式:其中分子计算预测框与真实框的中心点欧式距离d 分母是能覆盖预测框与真实框的最小BOX的对角线长度c
CIOU(Complete IoU)损失
CIoU就是在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框。
公式:损失函数必须考虑三个几何因素:重叠面积,中心点距离,长宽比 其中α可以当做权重参数
总结:
- IOU_Loss:主要考虑检测框和目标框重叠面积。
- GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
- DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
- CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。








NMS非极大值抑制
NMS 的本质是搜索局部极大值,抑制非极大值元素。
非极大值抑制,主要就是用来抑制检测时冗余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程:
1.对所有预测框的置信度降序排序
2.选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的 IOU
3.根据步骤2中计算的 IOU 去除重叠度高的,IOU > threshold 阈值就直接删除
4.剩下的预测框返回第1步,直到没有剩下的为止
SoftNMS:
当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个 BBox。为了解决这个问题,可以使用 softNMS。
它的基本思想是用稍低一点的分数来代替原有的分数,而不是像 NMS 一样直接置零。

训练策略
(1)多尺度训练(Multi-scale training)。 如果网络的输入是416 x 416。那么训练的时候就会从 0.5 x 416 到 1.5 x 416 中任意取值,但所取的值都是32的整数倍。
(2)训练开始前使用 warmup 进行训练。 在模型预训练阶段,先使用较小的学习率训练一些epochs或者steps (如4个 epoch 或10000个 step),再修改为预先设置的学习率进行训练。
(3)使用了 cosine 学习率下降策略(Cosine LR scheduler)。
(4)采用了 EMA 更新权重(Exponential Moving Average)。 相当于训练时给参数赋予一个动量,这样更新起来就会更加平滑。
(5)使用了 amp 进行混合精度训练(Mixed precision)。 能够减少显存的占用并且加快训练速度,但是需要 GPU 支持。
总结一下,YOLO v5和前YOLO系列相比的改进:
- (1) 增加了正样本:方法是邻域的正样本anchor匹配策略。
- (2) 通过灵活的配置参数,可以得到不同复杂度的模型
- (3) 通过一些内置的超参优化策略,提升整体性能
- (4) 和yolov4一样,都用了mosaic增强,提升小物体检测性能
YOLOv6
YOLOv6大量地吸收了最近的网络设计、训练策略、测试技术、量化和优化方法的想法。(也就是说没有吸睛创新点,主要做的也是缝合和堆砌)
主要改进点:
Backbone不再使用Cspdarknet,而是转为比Rep更高效的EfficientRep;它的Neck也是基于Rep和PAN搭建了Rep-PAN;而Head则和YOLOX一样,进行了解耦,并且加入了更为高效的结构。
值得一提的是,YOLOv6也是沿用anchor-free的方式,抛弃了以前基于anchor的方法。
除了模型的结构之外,它的数据增强和YOLOv5的保持一致;而标签分配上则是和YOLOX一样,采用了simOTA;并且引入了新的边框回归损失:SIOU。这样看来,YOLOv6可谓是结合了两者的优良点。
Anchor-free
我认为其最主要的改进是采用了 的方式。
传统的目标检测都是基于anchor的,如今,anchor-free的使用越来越广。因为使用anchor会存在以下几个问题:
1.需要在训练之前进行聚类分析以确定最佳anchor集合,但是这些anchor集合存在数据相关性,泛化性能较差。
2. anchor机制提升了检测头的复杂度。
SimOTA
SimOTA主要用于正样本的匹配,即为不同目标设定不同的正样本数量。我们知道检测模型推理的过程中会出现正负样本不均衡的现象,所以就需要进行正负样本的平均。
传统的anchor-free版本仅仅对每个目标赋予一个正样本,而忽视了其他高质量预测。因此这里为每个中心点赋予了多个正样本。并且为每个GT分配不同数量的anchor。所用的策略是参考FCOS,赋予中心3×3区域为正样本。落入其中区域的都为正样本。
SimOTA实际就是为各个GT框进行anchor的分配。分配策略可以理解为,根据不同anchor的模糊程度赋予不同的权重,从而得到分配的数量。因为在OTA中,将模糊的anchor分配给任何GT或背景都会对其他GT的梯度造成不利影响。所以,对模糊anchor样本的分配策略是特殊的。为此,需要进行更优的分配策略:除了考虑分类信息,还考虑了位置信息。也就是为图像中的所有GT对象找到全局的高置信度进行分配。
但是这里又引入了一个问题:最优运输问题优化会带来25%的额外训练耗时。所以在YOLOX中,又简化为动态的top-k策略进行分配,也就是得到一个近似解的策略:SimOTA。YOLOv6也沿用这个标签分配的方法。
SIOU
SIOU是2022年5月提出的。常用的IOU损失有IOU、GIOU、DIOU等,它们引入了框与框之间的重叠程度、中心点距离等等因素来进行匹配。而SIOU 损失函数是引入了所需回归之间的向量角度。这样就重新定义了距离损失,有效降低了回归的自由度,从而加速网络的收敛,进一步提升回归的准确性。
*YOLOv8
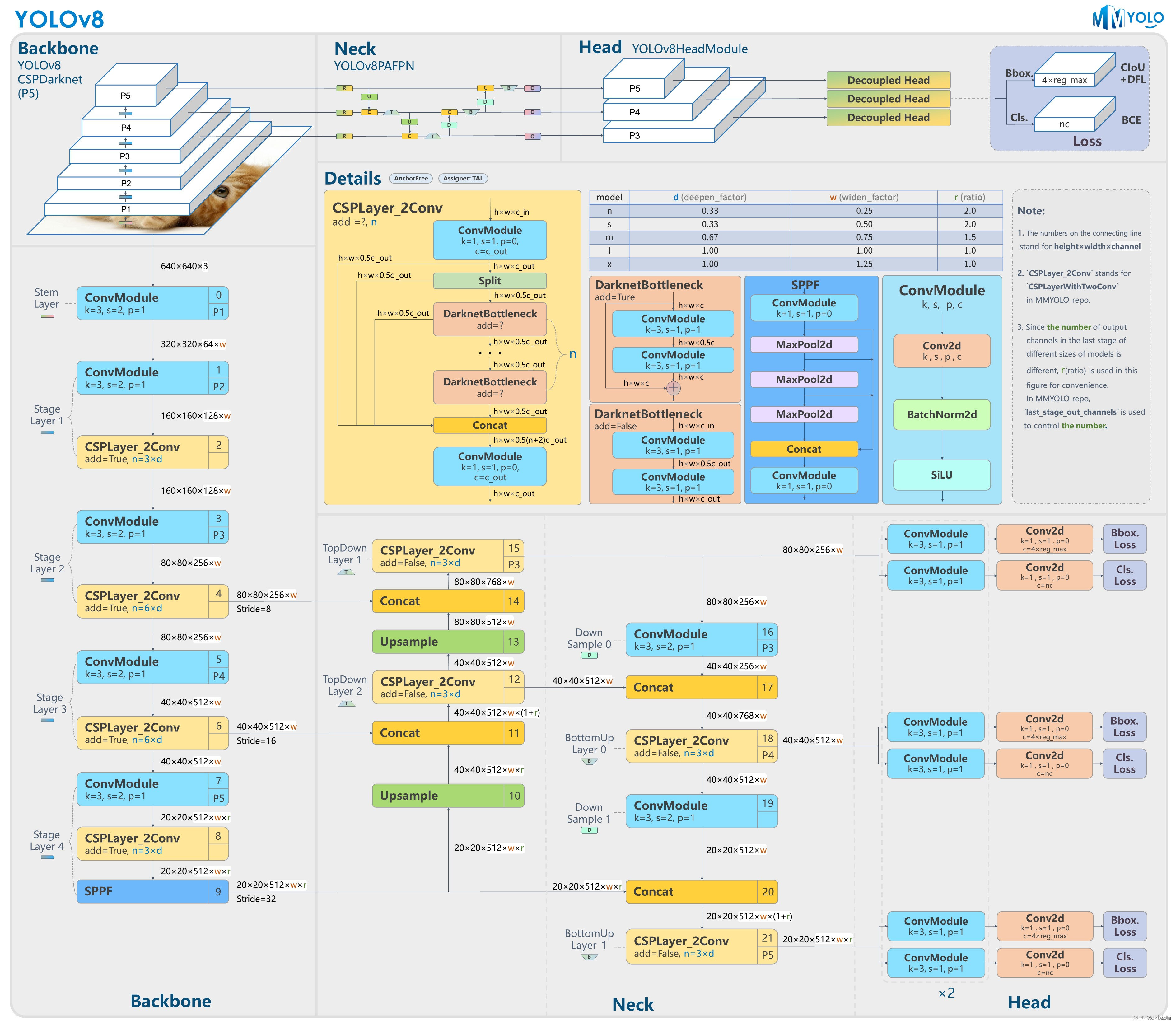
Anchor-Free思想:抛弃了Anchor-Base,采用了Anchor-Free的思想。
损失函数改进:分类使用BCEloss,回归使用DFL Loss+CIOU Loss。
样本匹配方式改进:采用了Task-Aligned Assigner匹配方式。
这些改进使得YOLOv8在保持了YOLOv5网络结构的优点的同时,进行了更加精细的调整和优化,提高了模型在不同场景下的性能。
Loss计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和Loss计算。
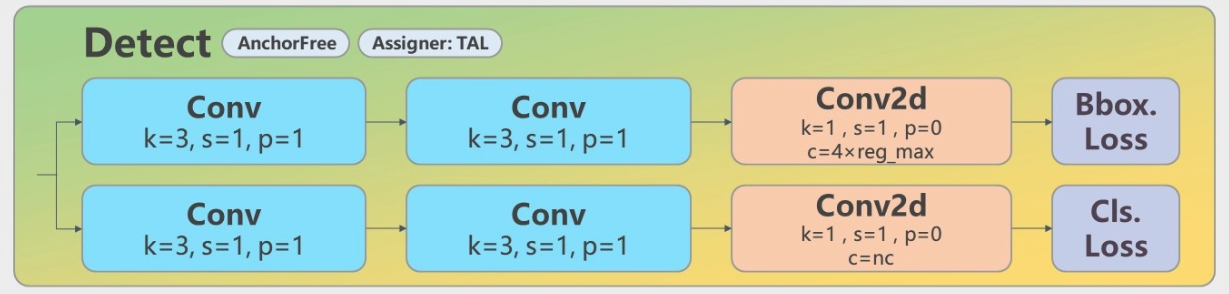
1. 正样本匹配
TaskAlignedAssigner样本分配:根据分类与回归的分数加权的分数选择正样本。
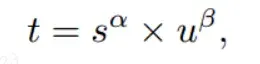
s是标注类别对应的预测分值,u是预测框和gt框的iou,两者相乘就可以衡量对齐程度。
TAL分配样本的具体流程:
①预处理:
对类别、边框、特征图各anchor中心点进行处理
类别:进行sigmoid处理
边框:还原到网络输入尺度
中心:还原到网络输入尺度
对标签数据也做同样处理,开始做正样筛选
②初筛:对所有中心点在GT框中的anchor作为初步正样本。
③精筛:计算上一步中anchor的对齐分数alignment_metrics(即t),选择分数最高的**topk个候选框(默认为10)**作为正样本。
④去除重复分配:通过mask矩阵与anchor求和,找出分给多个GT框的anchor,只留下CIOU值大的anchor。
⑤获得每样本对应的训练标签:通过上述步骤得到的掩码——anchor的正负样本、GT对应的正负样本、GT对应的正样本anchor索引,得到筛选出的正样本训练信息。
动态样本分配的策略能指导网络学习到更广泛的目标数据,而TAL通过使分类、回归加权指标来描述框的质量,更能指导模型在两种任务中薄弱那一方进行加强学习。通过提升正样本质量而非数量的策略,更能使网络的训练效率和质量有所提升。
值得指出的是,TAL官方论文中有提到,在对齐质量公式中的α、β是固定值,是由于团队对α、β的值做过学习性实验,将α、β也作为网络的一部分来优化数据。但发现随着α、β的更新,网络很容易进入局部最优状态,遂将α、β设置为固定值。
但团队也指出,α、β的值可以根据具体任务来做一些微调,能够取得一些优化。
Loss计算包括 2 个分支:分类和回归分支,没有了之前的objectness分支。
2. 分类损失
BCE:v5/v8均使用BCE(二元交叉熵)作为分类损失,每类别判断“是否为此类”,并输出置信度。
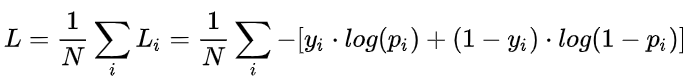
v8中,由于去掉了对象损失,在输出中也去掉了“对象置信度”,直接输出各个类别的“置信度分数”,再对其求最大值,将其作为此anchor框的“置信度”。
3. 回归损失
CIOU
IOU(Intersection over Union、交集-并集比例)是一种描述框之间的重合度的方式。在回归任务中,可通过“目标框”与“预测框”的比值来衡量框的回归程度
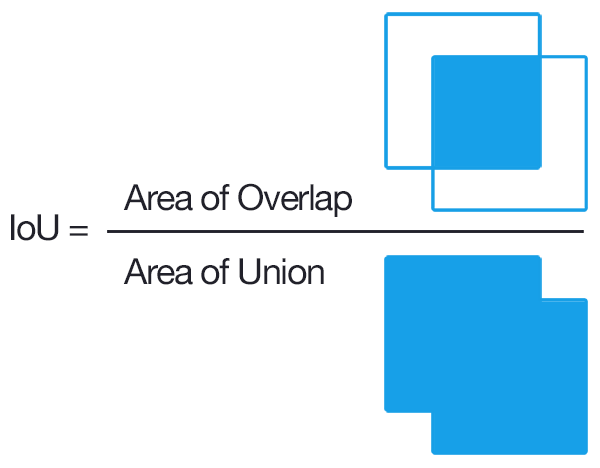
v5使用的CIOU loss用以令锚框更加接近标签值的损失,在(IOU)交并比损失上加上了宽高比的判据,从而更好在三种几何参数:重叠面积、中心点距离、长宽比上拟合目标框。
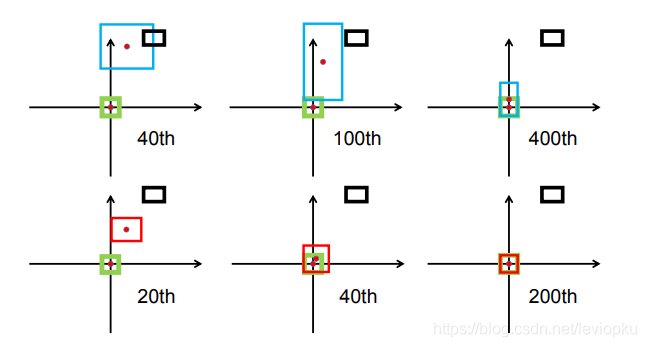
单独的CIOU loss的目标为“预测一个绝对正确的值(标签值)”,在数学上可以看做是一种“狄拉克分布”(一个点概率为无穷大,其他点概率为0)如下图。
如果把标签认为是"绝对正确的目标",那么学习出的就是狄拉克分布,概率密度是一条尖锐的竖线。然而真实场景,物体边界并非总是十分明确的。
我的理解,简单来说并不是非此即彼,相似的物体之间没有明显的边界,在预测的时候,相似物体预测概率不会是0
CIOU + DFL
虽然v8的CIOU使用方式与v5保持一致,但引入Anchor-Free的Center-based methods(基于中心点)后,模型从输出“锚框大小偏移量(offest)”变为"预测目标框左、上、右、下边框距目标中心点的距离(ltrb = left, top, right, bottom)"。

为配合Anchor-Free、以及提升泛化性,在v8中,增加了DFL损失。DFL以交叉熵的形式,去优化与标签y最接近的一左一右2个位置的概率,从而让网络更快的聚焦到目标位置及邻近区域的分布。
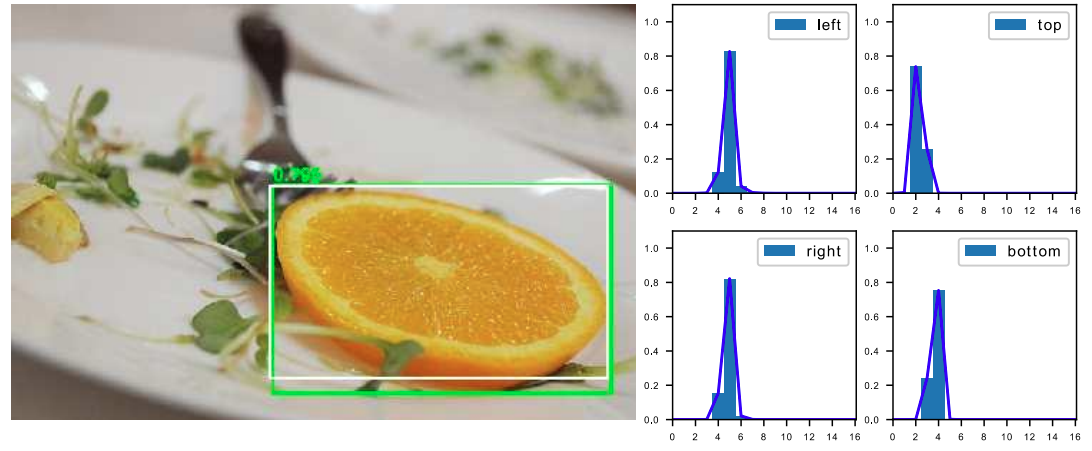
也就是说,学习的分布理论上是在真实浮点坐标的附近,并以线性插值的模式得到距离左右整数坐标的权重。

这种学习标签周围位置的损失,能够增强模型在复杂情况下,如遮挡、移动物体时的泛化性。
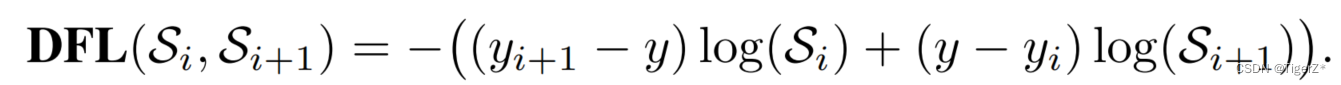
注:Si、Si+1的即为网络输出的“预测值”、“临近预测值”。y、yi、yi+1即为标签的“实际值”、“标签积分值”、“临近标签积分值”
将标签转换为DFL形式的具体过程为:
①将标签值从xywh转换为ltrb
②计算标签的ltrb四个值,并转换为DFL所需的积分形式(即标签值 + 临近标签值)
具体转换过程为:y = 中心距某条边的距离 / 当前的下采样倍数
例如:
某目标的中心点距离自身的上边界73 px(即ltrb的t = 73 px),在最大下采样32倍的特征图中,计算其在DFL中的映射值为73 / 32 = 2.3。
取整后得标签值yi = 2,
临近标签值yi+1 = 3
根据映射值与标签值、临近标签值的接近程度,计算各自的权重为
2.3 - 2 = 0.3,
3 - 2.3 = 0.7
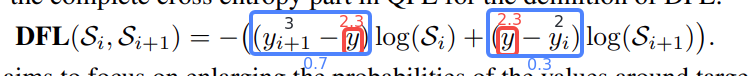
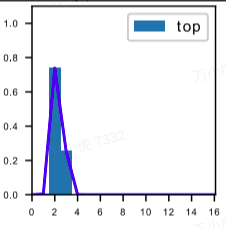
根据上述计算,其在DFL中的表达即为下图
在实际训练中,DFL将与CIOU损失结合使用。
在第一部分,通过DFL对“边界框分布概率”和标签的“分布概率”进行损失计算,从而对每条边进行优化。
在第二部分,将“边界框分布概率”还原为预测框,通过CIOU损失对预测框和标签的“实际框”进行损失计算,从而对预测框整体进行优化。
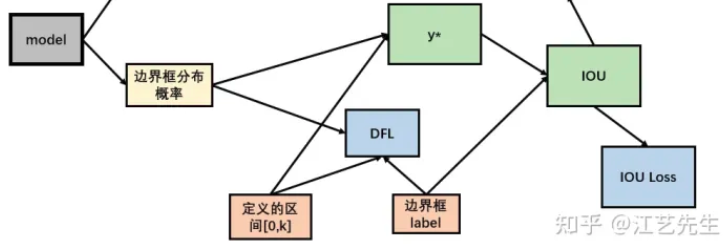
DFL的Reg_max
需要额外指出的是,DFL有一个隐藏的超参数——Reg_max。
这个参数代表了“输出特征图中,ltrb预测的最大范围”。默认值为16,即能表示16个特征图单元所映射的实际距离。
在v8中,最大下采样倍数为20。即在默认环境——640 x 360下,DFL能表达的最大单边距离为:320。能够覆盖此分辨率下的所有目标。

但此超参数Reg_max是固定值——16,如果你的输入是640,最大下采样到20 x 20的特征图,那么16是够用的。
如果输入没有resize或者超过了640则需设置这个Reg_max参数,否则如果目标尺寸还大,将无法拟合到这个偏移量。
如1280 x 1280的图片,目标1280 x 960,最大下采样32倍,1280/32/2=20 > 16(除以2是因为ltrb是一半的宽高),超过了DFL的reg_max范围。
同理,输入图像小于512 x 512,那下采样32倍后,特征图尺度就小于16,Reg_max就需要设定一个更小的值。
个人理解:检测大图大目标/小图小目标时,要调整Reg_max。
个人理解:DFL通过将回归问题改造为分类问题,一方面提升了模型对复杂情况的预测能力;另一方面,在结合了Anchor-Free的思想后,通过ltrb的形式,拓展了单个特征图单元的表达能力,提升了预测框输出的利用率。
AnchorFree
原理
训练中直接学习各种框形状。推理时不依靠聚类,而是根据学习到的边框距离/关键点位置,拟合物体尺寸。
v8中使用的方法是:Center-based methods——基于中心点的方法。先找中心/中心区域,再预测中心到四条边的距离。

模型的改进
Backbone改进:YOLOV5中的C3模块被替换成了C2f模块,实现了进一步的轻量化。同时保持了CSP的思想,保留了YOLOv5等架构中使用的SPPF(空间金字塔池化)模块。整个YOLOv8的Backbone由CBS、C2f、SPPF三种模块组成。让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。 具体并不细说。
检测头(head)
区别于YOLOV5的耦合头,YOLOV8使用了Decoupled-Head,将分类和检测头分离,使得网络的训练和推理更加高效。

YOLOv9
(1)提出了可编程梯度信息(PGI)的概念,以应对深度网络实现多个目标所需的各种变化。
(2)设计了一种新的基于梯度路径规划的轻量级网络结构——广义高效层聚合网络(GELAN)。
【YOLO系列】YOLOv9论文超详细解读(翻译 +学习笔记)-CSDN博客
YOLOv10
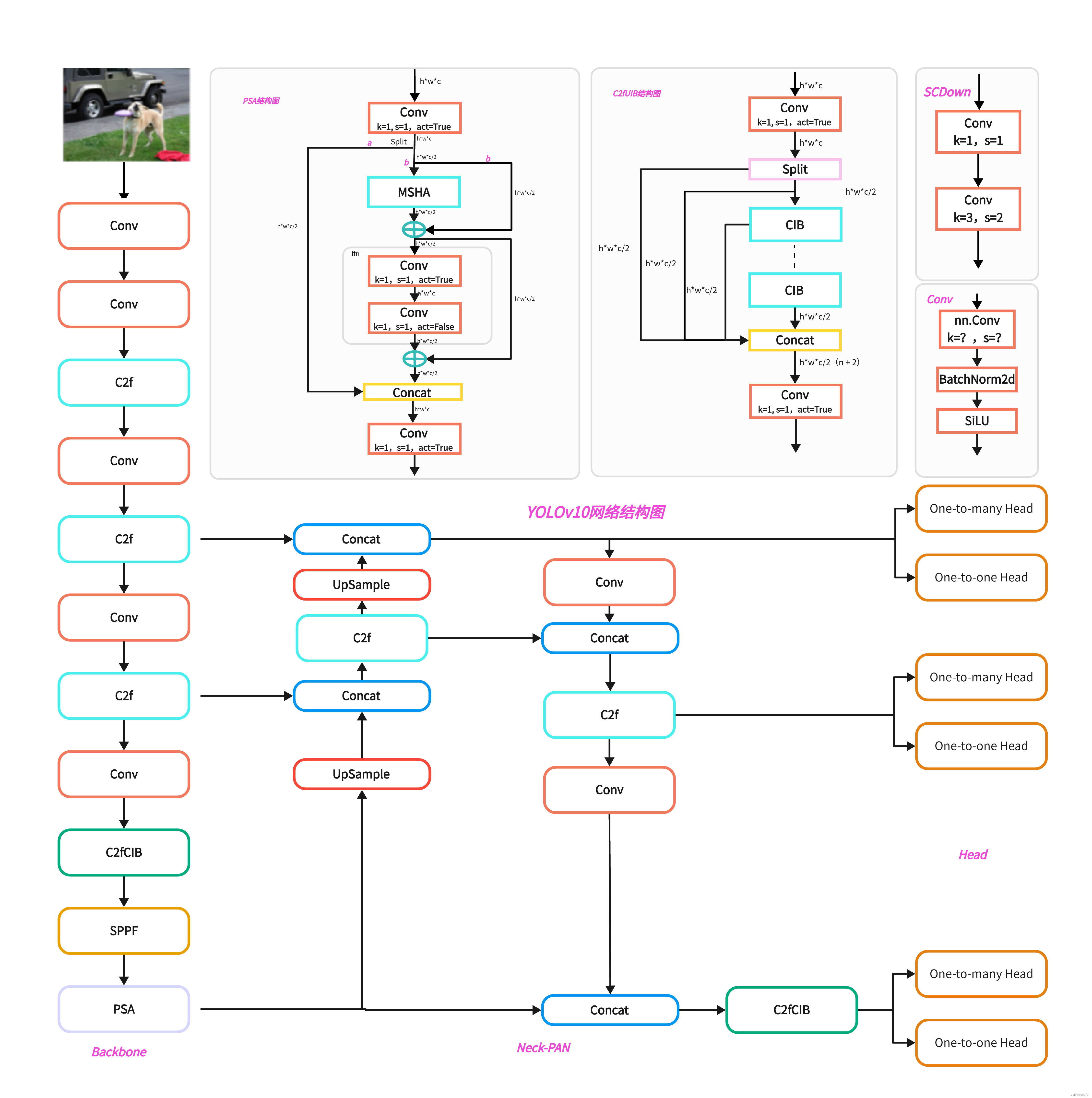
YOLOv10的主要创新点是取消后处理NMS,加速推理
具体而言,YOLO在训练期间通常采用一对多的标签分配策略,其中一个真实物体对应多个正样本。尽管这种方法能获得更好的性能,但需要在推理过程中使用NMS选择最佳正预测,这减慢了推理速度,并使性能对NMS的超参数敏感,阻碍了YOLO的端到端部署。
创新点:
- 引入一致的双重分配策略,消除NMS依赖。
- 提出整体效率-精度驱动的模型设计策略,包括轻量级分类头、空间-通道分离下采样和基于秩的块设计。
方法
无NMS训练的一致双重分配
在训练过程中,YOLO通常使用TAL(标签分配策略)为每个实例分配多个正样本。一对多分配的采用提供了丰富的监督信号,有助于优化并实现优异的性能。然而,这需要YOLO依赖于NMS后处理,导致推理效率不佳。虽然先前的工作探索了一对一匹配(为每个实例分配一个正样本,避免NMS后处理。)以抑制冗余预测,但通常会引入额外的推理开销或导致次优性能。在这项工作中,我们提出了一种无NMS训练策略,通过双重标签分配和一致的匹配度量,实现了高效率和竞争性性能。
例子解释1
这里解释一下大家可能不懂的点,一对多分配策略的解释:
假设我们有一张图像,其中包含两个目标:一个狗和一个猫。每个目标都有一个对应的真实边界框。
标签分配:
- 在一对多分配策略下,对于每个真实边界框(例如,狗的边界框),会分配多个正样本。这些正样本是预测的边界框,它们与真实边界框的重叠度(通常用IoU表示)超过某个阈值。例如,对于狗的边界框,模型可能会生成10个候选边界框,其中有5个与真实边界框的IoU超过0.5,这5个候选边界框将被分配为正样本。
丰富的监督信号:
- 由于分配了多个正样本,模型在训练过程中能够从更多的边界框中学习到相关信息。这些正样本提供了丰富的监督信号,有助于模型更好地优化分类和定位能力。每个正样本都会计算一个损失(例如分类损失和定位损失),模型会根据这些损失来调整参数,从而提高检测精度。
依赖NMS后处理:
- 在推理阶段(即模型应用于新图像时,注意此处是在推理阶段!!!我注意到Github上有人对作者的计算量进行质疑说和论文中公布的参数量不一致,有人回复是说训练的时候没有用到NMS所以此处的计算量可以忽略不记,仅仅是在推理阶段生效 | 我理解的就是论文公布的计算量是在推理阶段的,我们实际训练的时候可能参数量要大一些,不知道对不对,如果不对欢迎大家在评论区指正!),由于一对多分配策略会产生多个重叠的正样本(即多个边界框可能检测到同一个目标),因此需要使用NMS(非极大值抑制)来选择最优的预测边界框。NMS会抑制重叠度高的非最佳边界框,只保留得分最高的边界框,以减少冗余检测。
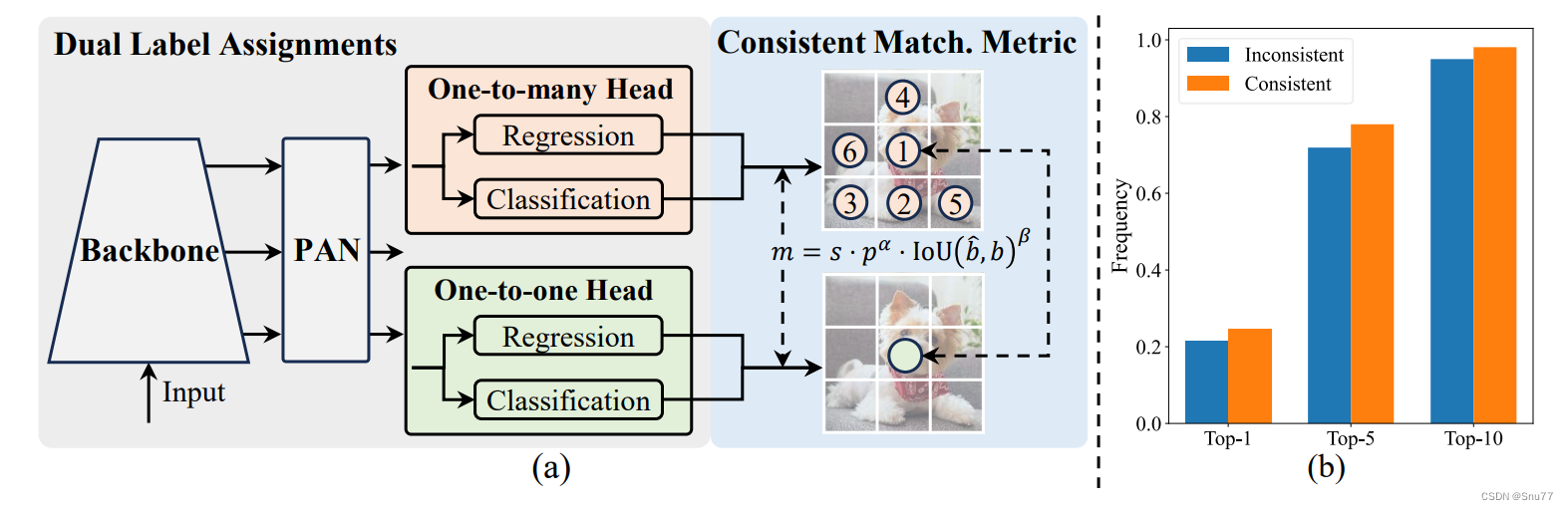 图片2描述:图展示了无NMS训练的一致双重分配策略以及YOLOv8-S模型在一对多结果中的一对一分配频率。
图片2描述:图展示了无NMS训练的一致双重分配策略以及YOLOv8-S模型在一对多结果中的一对一分配频率。
例子解释2
举例理解:大家看到这里可能还是晕头转向的对于这个一致双重分配策略不太理解,下面举个例子带大家理解下->
例子背景:
假设我们有一张包含三个目标(一个狗、一个猫和一个鸟)的图像。每个目标都有一个对应的真实边界框。在训练过程中,我们希望模型能够准确地预测这些边界框的位置和类别。一对多分配
在一对多分配策略中,模型会为每个真实边界框分配多个预测边界框作为正样本。假设对于狗的真实边界框,模型生成了10个候选边界框,其中有4个与真实边界框的IoU超过了设定的阈值(例如0.5),这4个边界框都会被视为正样本。这样做的目的是:
- 丰富监督信号:通过多个正样本,模型在训练过程中能够获得更多的反馈,帮助其更好地学习目标的特征。
- 优化效果更好:由于有更多的正样本参与优化,模型的性能通常会更好。
一对一分配(One-to-One Assignment)
在一对一分配策略中,每个真实边界框只分配一个预测边界框作为正样本。例如,对于狗的真实边界框,模型只选择与其IoU最高的一个预测边界框作为正样本。这种方法的优点是:
- 无需NMS后处理:因为每个目标只有一个正样本,避免了推理过程中使用非极大值抑制(NMS)来消除重复检测。
- 更高效的推理:省去了NMS步骤,推理速度更快。
一致双重分配策略(重点)
一致双重分配策略结合了一对多和一对一分配的优点,在训练和推理过程中分别使用这两种方法。1. 训练阶段:
- 一对多头:利用一对多分配策略,为每个真实边界框分配多个正样本,提供丰富的监督信号,帮助模型更好地学习。
- 一对一头:同时,利用一对一分配策略,为每个真实边界框分配一个正样本,确保训练过程中模型能够学会选择最佳的预测边界框。
2. 推理阶段:
- 在推理阶段,只使用一对一头进行预测,因为一对一分配确保每个目标只有一个正样本,避免了冗余预测和NMS后处理。
一致匹配度量(重点)
为了使两个分支在训练过程中保持一致,采用了一致的匹配度量。匹配度量用于评估预测边界框与真实边界框之间的一致性,公式为:
其中,
是分类得分,
和
分别是预测边界框和真实边界框,
表示空间先验,
和
是超参数。
通过一致的匹配度量,可以确保一对一头和一对多头在优化方向上的一致性,进一步提升模型的性能。
希望能通过这个例子帮助大家理解一下这个策略,如果不对欢迎评论区指正!
“简单来说,v10在训练的时候使用one to one 和many to one 两个方式,在推理的时候只使用one to one方式,节省了NMS的时间 ”
YOLOv11
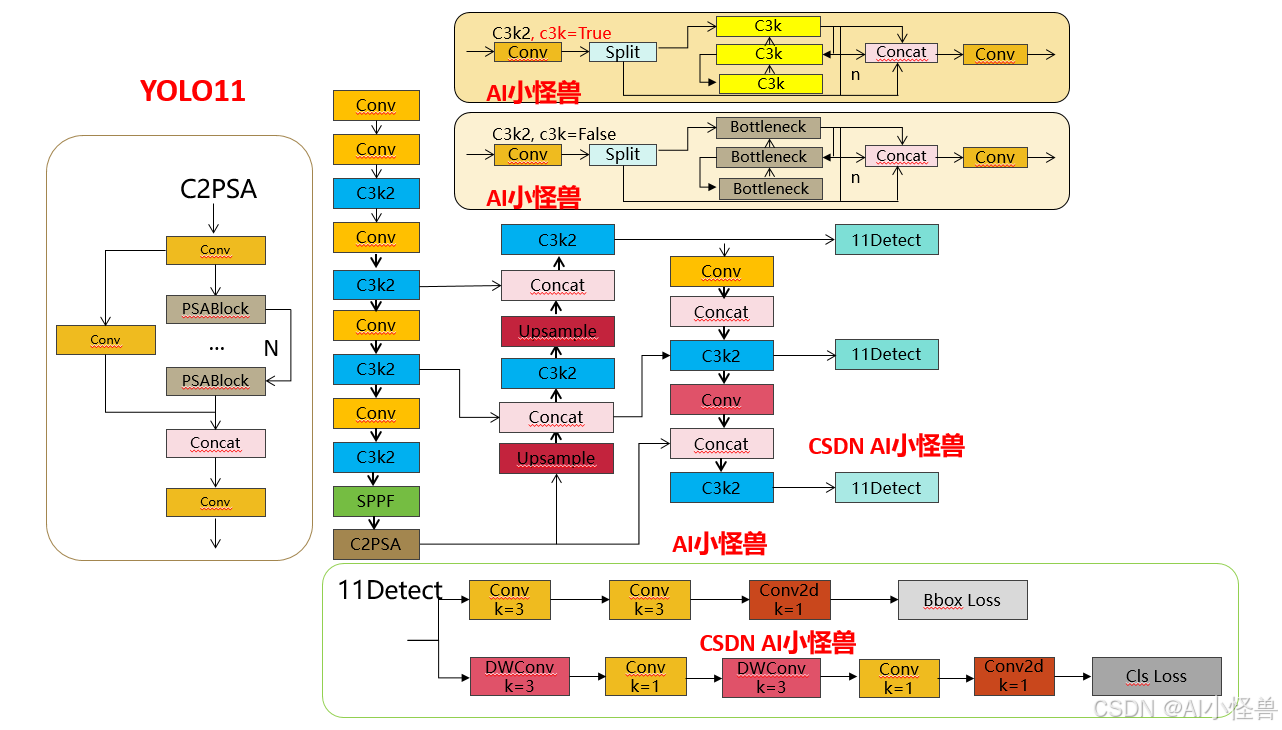
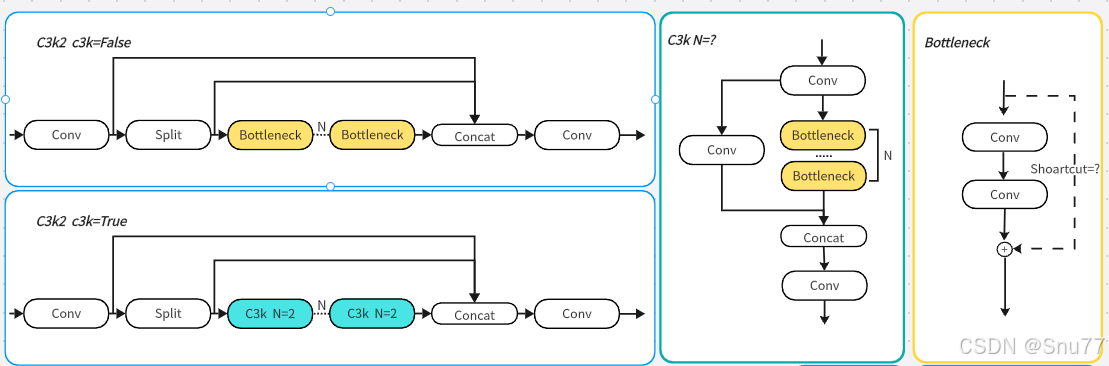
1. 提出C3k2机制,其中C3k2有参数为c3k,其中在网络的浅层c3k设置为False(下图中可以看到c3k2第二个参数被设置为False,就是对应的c3k参数)
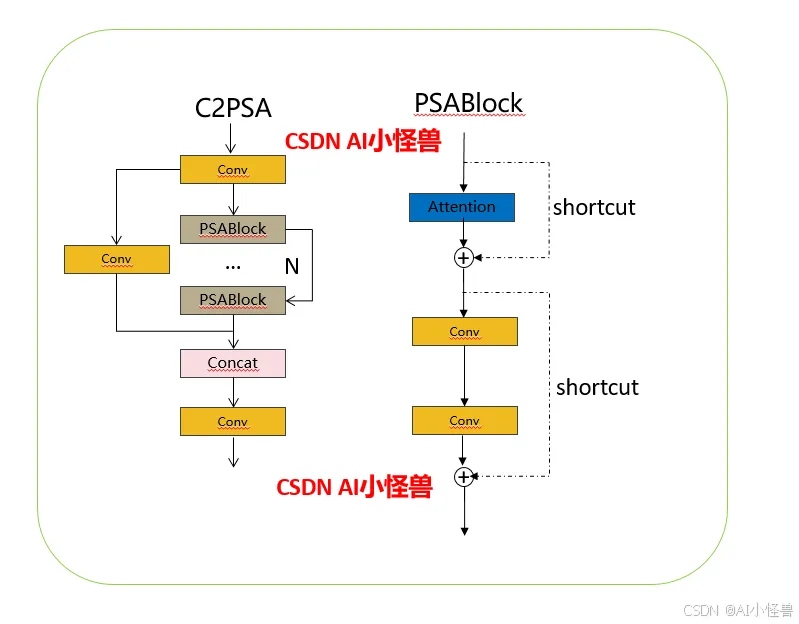
2. 提出C2PSA机制,这是一个C2(C2f的前身)机制内部嵌入了一个多头注意力机制,在这个过程中我还发现作者尝试了C2fPSA机制但是估计效果不如C2PSA,有的时候机制有没有效果理论上真的很难解释通,下图为C2PSA机制的原理图,仔细观察把Attention哪里去掉则C2PSA机制就变为了C2所以我上面说C2PSA就是C2里面嵌入了一个PSA机制。
3. 第三个创新点可以说是原先的解耦头中的分类检测头增加了两个DWConv,具体的对比大家可以看下面两个图下面的是YOLOv11的解耦头,上面的是YOLOv8的解耦头.
结构改进
c3k2
 C2PSA
C2PSA
 YOLOv12
YOLOv12
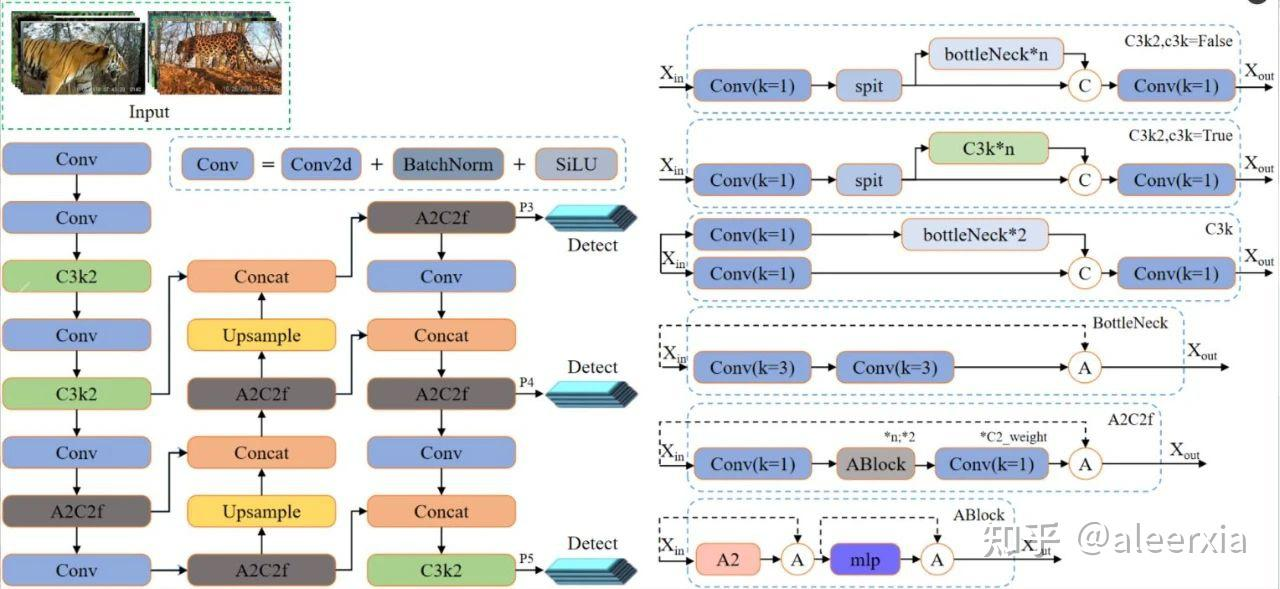
显著特点是摒弃了传统基于 CNN 的方法,引入注意力机制用于实时目标检测。主要创新:
(1) 区域注意力(Area Attention):
为了克服传统自注意力机制的高计算成本问题,YOLOv12 将特征图水平或垂直划分为大小相等的区域(默认分为 4 部分)。这种简单而有效的方法在保留大感受野的同时,显著降低了计算复杂度。
(2) 残差高效层聚合网络(Residual Efficient Layer Aggregation Networks,R-ELAN)
R-ELAN 是早期 ELAN 架构的演进版本,它通过引入块级残差连接和缩放技术,解决了训练过程中的不稳定性问题。这种重新设计的特征聚合方法,使得即使是更深更宽的模型版本也能稳定训练。(3)快速注意力(FlashAttention)的集成
YOLOv12 利用快速注意力(FlashAttention)技术来最小化内存访问瓶颈。该技术在现代支持 CUDA 的 GPU(如 Turing、Ampere、Ada Lovelace、Hopper 架构)上尤为有效,能显著减少注意力操作的计算时间,从而提升模型的整体效率。