ES集群的故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确 保数据安全,这个叫做故障转移。
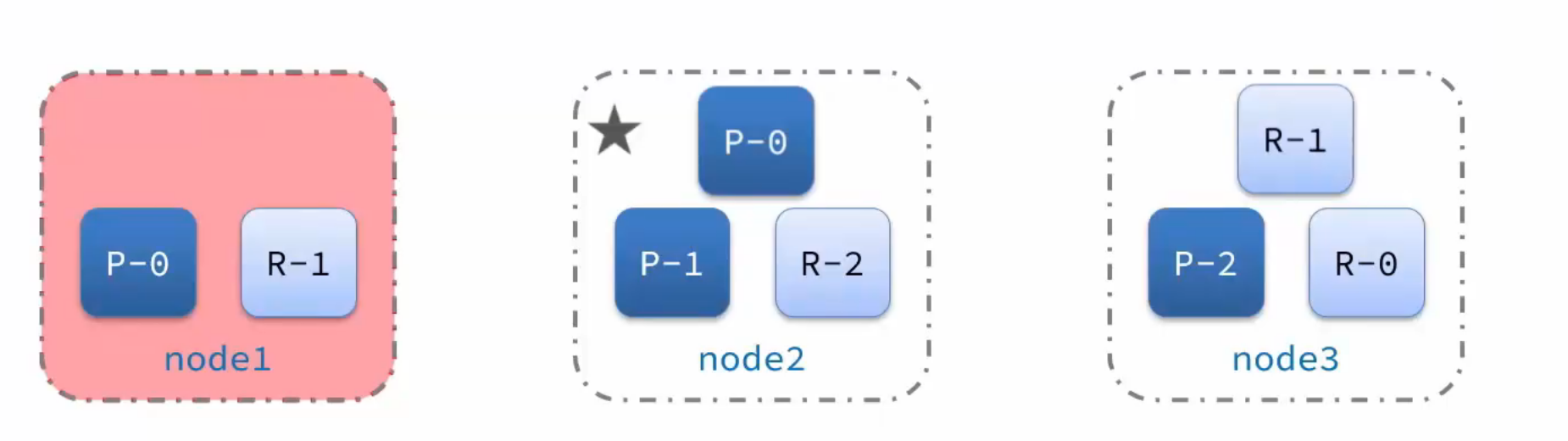
总结:
-
master容机后,Eligible Master选举为新的主节点
-
master节点监控分片、节点状态,将故障节点上的分片转移到正常节点,确保数据安全。
1.故障检测
- 心跳机制:节点间定期发送心跳(默认间隔 1 秒,超时 30 秒判定故障 )。Master 节点持续监控集群节点状态,若某节点心跳丢失超超时时间判定该节点故障。
2. 主节点故障转移(Master 节点宕机)
- 重新选举:剩余具备 Master 候选资格的节点,基于 Raft 协议发起选举,选出新主节点。
- 接管集群:新主节点从集群元数据中恢复分片分配等信息,接管集群状态管理,确保集群拓扑、分片分布等信息准确。
3. 数据节点故障转移(Data 节点宕机)
- 分片晋升:若故障节点包含主分片,其对应的副本分片自动晋升为新主分片,继续提供写入服务;若副本不足(如副本分片也故障 ),集群状态变为
yellow(部分分片未完全冗余 )。 - 恢复冗余:新主节点在健康数据节点上,为晋升后的主分片创建新副本分片,重建数据冗余,集群状态逐步恢复为
green(所有分片均有冗余 )。
简言之,ES 集群故障转移依靠自动检测(心跳)、分片冗余(副本)、动态选举(主节点) 实现高可用,合理配置节点角色、分片副本、跨可用区部署,并结合监控与手动干预,可最大程度保障集群在故障时持续服务,适配生产环境的高可靠需求。