ES集群的节点
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
-
海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
-
单点故障问题:将分片数据在不同节点备份(replica)
ES集群当中集群节点不同的职业划分
| 节点类型 | 配置参数 | 默认值 | 节点职责概述 |
|---|---|---|---|
| master eligible | node.master | true | 作为候选主节点,负责集群元数据管理(如集群状态、分片分配、索引库创建 / 删除等) |
| data | node.data | true | 存储实际数据,承担数据的读写、搜索、聚合以及增删改查(CRUD)操作 |
| ingest | node.ingest | true | 对即将存储到集群的数据,在写入前进行预处理(如格式转换、字段补充等) |
| coordinating | node.master、node.data、node.ingest 均为 false | 无 | 接收客户端请求,拆解并路由给其他节点,合并各节点返回结果后再响应给客户端 |
-
master eligible 节点: 集群核心 “大脑”,若被选为主节点(集群会从候选节点中选一个 ),掌控集群整体状态。日常要维护集群元数据(比如有新节点加入 / 退出、创建新索引时,更新集群状态 ),保障集群拓扑、分片分布等信息准确,若主节点故障,候选节点会参与重新选举,保证集群管理功能延续。
-
data 节点: 集群 “实干者”,数据实际存储在这些节点的分片上。不管是简单的根据 ID 查询文档,还是复杂的多条件搜索、聚合分析(像统计某城市酒店数量 ),都由数据节点执行,性能高低直接影响业务查询效率,数据量大或查询频繁时,需合理扩容数据节点。
-
ingest 节点: 数据 “预处理工厂”,在数据写入流程中 “插队” 干活。比如采集的日志数据格式杂乱,可通过 ingest 节点配置 pipeline,按规则解析成统一格式、添加自定义标记字段,让后续存储和查询更规整,减少下游处理负担。
-
coordinating 节点: 客户端请求 “调度员 + 结果汇总员”。收到查询、写入等请求后,它会判断需要哪些数据节点参与(比如搜索请求要涉及哪些分片 ),把任务拆分发下去,等各个节点返回部分结果,再汇总合并(如搜索结果排序、分页 ),最后返回给客户端,默认每个节点都可充当,也可专门配置纯协调节点应对高并发、复杂请求场景 。
实际上ES的集群在创建的时候都是默认的有这四个节点的功能。,但是在开发的过程当中,我们要在创建的时候,不需要使节点有过多的作用,只会让节点只有单个的功能进行部署。下图为一个健壮的集群。
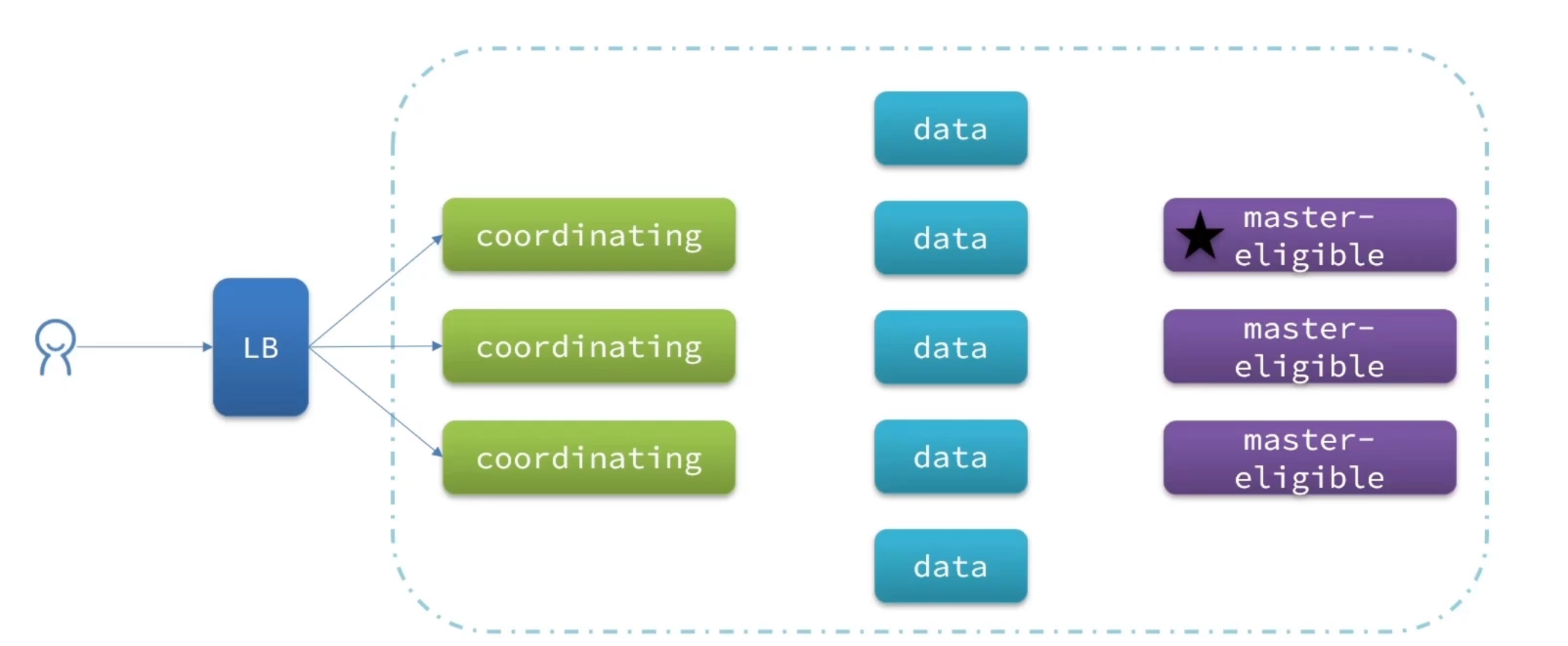
默认情况下,每个节点都是master eligible节点,因此一旦master节点宕机,其它候选节点会选举一个成为主节点。当主节 点与其他节点网络故障时,可能发生脑裂问题。
为了避免脑裂,需要要求选票超过(eligible节点数量+1)/2才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
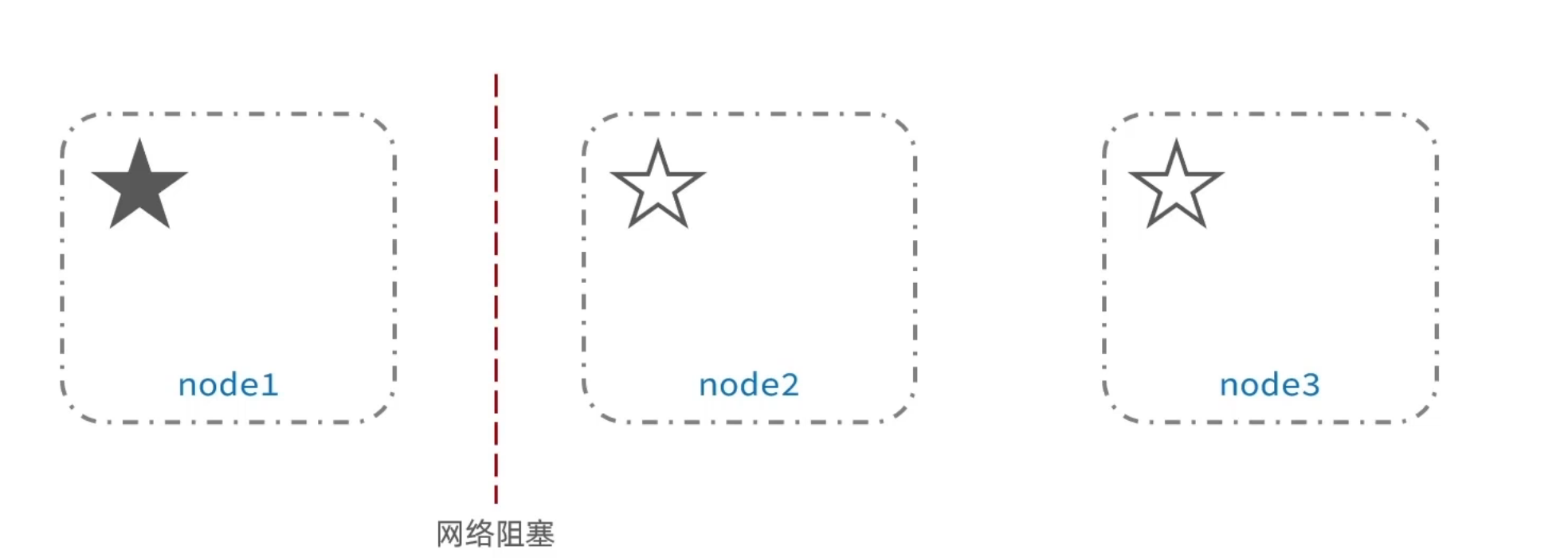 脑裂问题简单的来说就是由于网络的波动使得主节点的部分节点短暂连接不上主节点,但是主节点还是在正常工作的,但是连不上的节点之间又重新选举出了一个主节点,当网络阻塞消失之后,在一个集群当中就出现了两个主节点,都会进行数据的更新和存储操作,所以我们就称其为脑裂。
脑裂问题简单的来说就是由于网络的波动使得主节点的部分节点短暂连接不上主节点,但是主节点还是在正常工作的,但是连不上的节点之间又重新选举出了一个主节点,当网络阻塞消失之后,在一个集群当中就出现了两个主节点,都会进行数据的更新和存储操作,所以我们就称其为脑裂。