销售预测的方法与模型(二)丨商品与库存分类——基于数据模型运营的本质和底层逻辑销售
在零售领域,通过商品分类来观察销售和库存的波动性是关键,不同商品具有不同的销售和库存模式,是对商品和库存进行有效分类与精细化管理的基础。此外,还要结合主观对商品画像的维度描述进行整合。根据商品的特性,不同的波动性模型可以帮助企业更精准地预测需求、制定补货计划,降低库存成本和缺货风险。
如何通过商品分类确定波动性模型?
商品可以根据其特性分为多种类型,如畅销商品、季节性商品、波动较大的商品等。针对不同商品的波动性,可以选择不同的模型来分析其销售和库存的波动。下面介绍几种常见的商品波动性分类及对应的模型,并举例说明如何使用这些模型。
一、ABC分析法
在零售行业中,产品分类是管理库存和优化供应链的基础。常见的分类方法之一是 ABC分析法,也称为 库存ABC模型,这是一种基于产品价值和消耗量的分类方法,可以帮助企业将不同的重要性和管理策略应用于不同的商品。
1. ABC模型的基本原理
ABC模型的核心理念是将产品分为三类:
A类商品:占库存中 较小的比例(如20%),但贡献了 较大的价值(如80%)。
B类商品:占库存和价值的 中等比例,通常是介于A类和C类之间的商品。
C类商品:占库存中 较大的比例(如50%或更多),但对总价值贡献 较小(如10%)。
这种分类方法遵循 帕累托原则(20% 的商品带来80%的收益),通过优先管理A类商品,可以实现有效的库存控制和资源分配。
2. ABC分类的步骤
(1)确定分类标准
ABC分类的标准通常基于 年度消耗量(或销售量)乘以 单价,以此来计算每个商品的 年度消耗价值。该值决定了商品的分类。
公式:
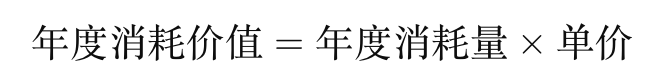
(2)计算各商品的年度消耗价值
假设一家零售企业 StarMart 的主要产品有以下数据:
| 产品名称 | 年度消耗量(件) | 单价(元) | 年度消耗价值(元) |
| 商品A | 1000 | 300 | 300,000 |
| 商品B | 1500 | 50 | 75,000 |
| 商品C | 500 | 10 | 5,000 |
| 商品D | 2000 | 5 | 10,000 |
| 商品E | 800 | 200 | 160,000 |
(3)按消耗价值排序并计算累积百分比
将各商品按年度消耗价值从高到低排序,然后计算累积百分比。
| 产品名称 | 年度消耗价值(元) | 累积消耗价值 | 类别 |
| 商品A | 300,000 | 50% | A类 |
| 商品E | 160,000 | 77% | A类 |
| 商品B | 75,000 | 90% | B类 |
| 商品D | 10,000 | 98% | C类 |
| 商品C | 5,000 | 100% | C类 |
在这个例子中,商品A和商品E由于年度消耗价值占比最高(前80%),被分类为A类;商品B处于中等消耗水平,属于B类;商品D和商品C的消耗价值较低,被划分为C类。
(4)根据分类调整管理策略
A类商品:需要密切关注,保证库存周转率高。通常采用 严格的库存管理,保证高供应链效率并避免缺货。
B类商品:次重点管理,定期监控,采用 平衡的补货策略。
C类商品:由于其贡献的总价值较低,可以采用 较宽松的库存管理,甚至适当减少库存量。
二、单一维度进行货品分类与预测(销量)
按照时间序列观察ABC分类,根据销售或库存的变化趋势调整库存策略。
基本思路
在传统的ABC分类中,产品是基于年度消耗量或年度消耗价值来进行分类的,具体来说,可以通过以下几个步骤来执行:
·收集历史销售数据:获取产品的历史销售或库存数据,形成时间序列数据集。
·根据时间序列趋势分类:通过时间序列模型(如简单移动平均、指数平滑等)对各类产品进行销量预测,从而动态地确定不同时间段的ABC分类。
·动态调整分类:定期或按需调整产品的ABC分类,根据产品的销量变化趋势(例如季节性波动、促销等)。
示例:StarMart的时间序列ABC分类
假设StarMart在过去3个月中有以下5个主要商品,且这些商品的日销量数据如下:
1. 数据收集
| 日期 | 商品A销量 | 商品B销量 | 商品C销量 | 商品D销量 | 商品E销量 |
| 2024-08-01 | 50 | 20 | 15 | 10 | 5 |
| 2024-08-02 | 48 | 22 | 14 | 12 | 5 |
| 2024-08-03 | 52 | 25 | 16 | 9 | 4 |
| 2024-08-04 | 49 | 21 | 15 | 11 | 5 |
| 2024-08-05 | 51 | 23 | 14 | 13 | 4 |
| 2024-08-06 | 53 | 24 | 15 | 10 | 6 |
| ... | ... | ... | ... | ... | ... |
| 2024-10-31 | 55 | 28 | 18 | 12 | 7 |
2. 计算每个商品的3个月销售总量
计算每个商品在3个月内的总销量(可以使用 简单移动平均 或其他平滑方法来减少日常波动的影响)。
| 商品名称 | 3个月总销量 |
| 商品A | 1,500 |
| 商品B | 600 |
| 商品C | 450 |
| 商品D | 300 |
| 商品E | 150 |
3. 按销售总量排序并计算累积百分比
将这些商品的销量按降序排列,并计算每个商品的累积销量百分比。
| 商品名称 | 3个月总销量 | 累积销量 | 累积百分比 | ABC分类 |
| 商品A | 1,500 | 1,500 | 50% | A类 |
| 商品B | 600 | 2,100 | 70% | A类 |
| 商品C | 450 | 2,550 | 85% | B类 |
| 商品D | 300 | 2,850 | 95% | B类 |
| 商品E | 150 | 3,000 | 100% | C类 |
4. 使用时间序列预测动态分类
假设我们希望基于 过去30天 的数据,动态地预测每个商品未来一个月的销量。我们可以使用 时间序列分析(如简单移动平均或指数平滑)来估算未来的销量,并根据这些预测结果来调整ABC分类。
4.1 应用时间序列模型(简单移动平均法)
对于商品A、B、C、D、E,我们可以计算过去30天的 简单移动平均,预测下个月的销量,并根据该销量重新评估它们的分类。
例如,商品A的过去30天日销量数据如下:
| 日期 | 商品A销量 |
| 2024-10-01 | 53 |
| 2024-10-02 | 54 |
| 2024-10-03 | 55 |
| 2024-10-04 | 53 |
| 2024-10-05 | 56 |
| ... | ... |
| 2024-10-30 | 58 |
我们可以计算过去30天的 简单移动平均(SMA):

假设商品A的过去30天销量的SMA为 54件/天。
那么,预计商品A的下个月销量为 54 * 30 = 1,620件。
4.2 根据预测调整ABC分类
使用同样的简单移动平均法计算其他商品的预测销量:
| 商品名称 | 预测销量(下个月) | 预测销量排名 | 累积销量 | 累积百分比 | ABC分类 |
| 商品A | 1,620 | 1 | 1,620 | 54% | A类 |
| 商品B | 700 | 2 | 2,320 | 77% | A类 |
| 商品C | 480 | 3 | 2,800 | 93% | B类 |
| 商品D | 320 | 4 | 3,120 | 98% | B类 |
| 商品E | 180 | 5 | 3,300 | 100% | C类 |
在这个例子中,虽然商品C在过去3个月是B类,但由于未来销量预计下降(预测销量为480件),它仍然是B类。商品A的销量预计继续增加,因此仍保持A类。
5. 总结评估
通过对数据的分析,可以预判下一个行动周期的数据,然后对比预测的情况找到此类商品的波动性(需求、库存),验证模型的准确性(观察数据的波动性对比)。
三、多维度货品分类(ABC-XYZ),基于库存与销售数据(客观数据)
XYZ模型是一种基于需求波动性对库存进行分类的模型。与ABC分类法侧重于销售或消耗的金额或数量不同,XYZ模型侧重于产品需求的稳定性和波动性。具体来说,XYZ模型将产品根据其 需求波动性 分为三类:
·X类:需求非常稳定,波动性小,通常可以预测。
·Y类:需求有中等波动,受季节、促销等因素影响,适合使用中期预测模型。
·Z类:需求波动性大,需求难以预测,通常受到偶发事件或特殊情况(如促销、突发市场变化等)影响较大。
这种分类方法适用于多种行业,尤其是在零售、制造和供应链管理中,可以帮助企业更好地管理库存和补货策略。
1. XYZ模型的基本原理
X类产品:需求稳定,通常为基础产品或者长期销售的产品。对这些产品,企业可以使用长期的库存管理策略,较少需要调整库存水平。
Y类产品:需求有一定波动,通常与季节性、促销活动或趋势变化有关。对于这类产品,企业需要根据季节性、市场活动等因素做中期的预测与调整。
Z类产品:需求波动性大,不稳定,可能受到短期事件、市场波动等影响。对于这类产品,企业需要较高的灵活性和反应速度,采用灵活的库存管理策略和短期预测。
2. XYZ模型的应用流程
计算需求波动性:
需求波动性通常通过 标准差 或 变异系数(CV,Coefficient of Variation)来衡量。变异系数是需求标准差与平均需求的比值,变异系数越大,需求波动性越大。
公式:

分类标准:
·X类:需求波动性小,CV较低(通常小于0.5),产品的需求变化可预测。
·Y类:需求波动性中等,CV适中(0.5到1.0之间),需求受季节、促销等因素影响。
·Z类:需求波动性大,CV较高(大于1.0),产品的需求难以预测。
根据波动性制定策略:
·X类产品:采用 较低的安全库存,库存补充策略可以较为稳定,适合长期预测。
·Y类产品:采用 中期预测和灵活调整策略,根据季节变化或促销活动调整库存。
·Z类产品:需要 较高的安全库存 和 快速反应机制,并且采用短期预测,灵活应对突发需求。
3. XYZ模型的实际案例
以一个 零售商店(如StarMart)为例,假设其有五种产品,销售数据如下(按周销售量计算):
3.1 数据收集
| 产品名称 | 销售量(周1-4) | 销售量(周5-8) | 销售量(周9-12) | 销售量(周13-16) |
| 商品A | 50,52,51,53 | 52,51,53,50 | 51,50, 52, 53 | 53,52,51,50 |
| 商品B | 200,210,220,230 | 240,250,230,220 | 210,200,230,240 | 250,240,230,210 |
| 商品C | 10,12, 9,15 | 50,55,48,45 | 5,4,6,8 | 12,15,18,20 |
| 商品D | 5,5,5,5 | 4,4,5,6 | 10,12,13,14 | 20,25,30,35 |
| 商品E | 100,150,130,120 | 160,170,180,150 | 140,130,120, 110 | 100,90,95,110 |
3.2 计算需求波动性(CV)
我们先计算每个商品的 变异系数(CV),来评估它们的需求波动性。
商品A的需求:
销售量数据:50, 52, 51, 53, ...
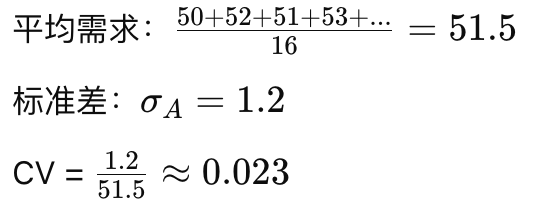
商品B的需求:
销售量数据:200, 210, 220, 230, ...

商品C的需求:
销售量数据:10, 12, 9, 15, ...
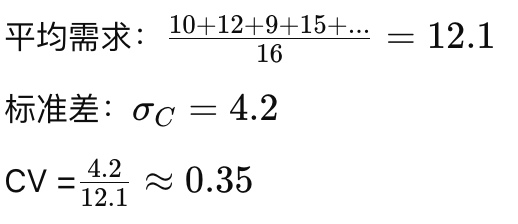
商品D的需求:
销售量数据:5, 5, 5, 5, ...
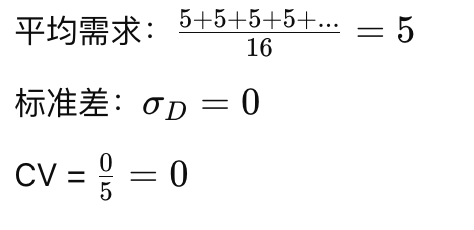
商品E的需求:
销售量数据:100, 150, 130, 120, ...
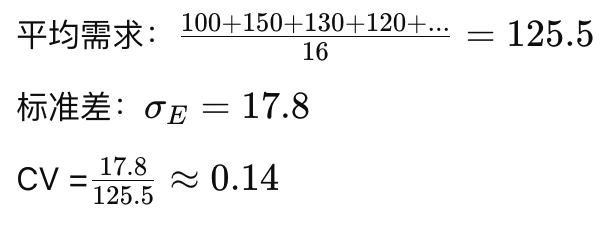
3.3 分类与分析
根据计算得到的CV值,我们可以对每个商品进行分类:
商品A:CV = 0.023 → X类(需求非常稳定)
商品B:CV = 0.041 → X类(需求稳定,适合长期预测)
商品C:CV = 0.35 → Y类(需求波动较大,适合季节性预测)
商品D:CV = 0 → X类(需求稳定,无需太多调整)
商品E:CV = 0.14 → Y类(需求略有波动,适合季节性调整)
3.4 结果总结
通过XYZ模型,能够根据不同商品的需求波动性,采取针对性的库存管理策略。对于需求稳定的商品,采用较为简单、稳定的库存管理方法;而对于需求波动较大的商品,则需灵活调整库存和补货策略,甚至进行短期预测和快速响应。
这种方式帮助企业提高了库存周转率,减少了积压,同时避免了缺货现象,提升了整体的供应链效率。
四、多维度货品分类(VED),主观数据(人为判断)
VED分类(Vital, Essential, and Desirable)是库存管理中常用的一种方法,它通过对产品的重要性进行分类,以帮助企业更好地管理库存和优化采购决策。VED分类主要关注每个产品对公司运营的影响程度,而非其销售频率或库存周转速度。
V类(Vital):对企业运营至关重要,缺货可能导致生产停滞或重大业务损失。
E类(Essential):对企业运营非常重要,但可以通过适度的库存调整和替代品管理来应对短期缺货。
D类(Desirable):对企业运营的影响较小,可以接受库存不足或偶尔缺货,通常是可选配件或非核心产品。
1. VED分类的基本原理
Vital (V类):
这些产品对于企业的日常运营和生产至关重要。如果这些产品断货,可能会直接导致生产线停工、销售停滞或客户流失。
对于V类产品,企业需要始终保持充足的库存,并确保及时补货,通常会采取保守的库存策略。
Essential (E类):
这些产品对企业运营也非常重要,但相对来说,它们的缺货影响不如V类产品严重。企业可以通过调整库存、延迟补货或使用替代品来应对短期缺货。
对于E类产品,库存管理更为灵活,可以通过优化补货周期来平衡成本和风险。
Desirable (D类):
这些产品对企业运营的影响较小。即使短期内缺货,也不会对公司造成重大影响。通常是一些配件、替代品或非关键产品。
对于D类产品,库存量可以保持较低,补货周期较长,甚至可以不做优先补货。
2. VED分类的实际案例
假设我们有一家制造企业,生产汽车零部件。企业需要管理大量的原材料和配件,并确保生产线的顺利运行。以下是根据产品重要性对一些原材料和配件进行VED分类的过程。
2.1 数据收集
我们从生产计划中获取到以下几种原材料及其库存需求:
| 产品名称 | 描述 | 库存使用频率 | 生产中的重要性 |
| 发动机芯片 | 关键电子组件,汽车发动机中不可缺少的部分 | 高频使用 | 极其重要(V类) |
| 轮胎 | 汽车的标准配件,必须保证足够库存 | 高频使用 | 重要(E类) |
| 后视镜 | 非核心配件,偶尔需要更换 | 中频使用 | 可有可无(D类) |
| 刹车片 | 汽车安全部件,必须确保供应 | 高频使用 | 重要(E类) |
| 座椅缝线 | 用于车座的缝制材料 | 低频使用 | 可有可无(D类) |
2.2 根据重要性进行VED分类
根据以上数据,企业可以根据产品对生产和运营的重要性进行VED分类。
发动机芯片:由于发动机芯片是汽车发动机中至关重要的部件,若短缺会导致生产停滞,因此它被归类为 V类(Vital)。
轮胎:轮胎是汽车的必需部件,缺少轮胎会导致产品无法出厂,因此它被归类为 E类(Essential)。
后视镜:后视镜虽然是汽车的标准配件,但它对汽车的正常运行影响较小,即使短期内缺货也不会对生产造成太大影响,因此它被归类为 D类(Desirable)。
刹车片:刹车片是确保汽车安全的重要部件,缺少刹车片会导致安全隐患,因此它被归类为 E类(Essential)。
座椅缝线:虽然座椅缝线对汽车外观和舒适性有影响,但它不是生产中不可缺少的部件,因此它被归类为 D类(Desirable)。
2.3 分类后的库存管理策略
根据VED分类,企业可以采取不同的库存管理策略:
V类(Vital)产品(如发动机芯片):
库存管理策略:这些产品对生产至关重要,企业需要始终保持充足的库存,并提前规划补货周期。为了避免缺货情况,可以考虑多渠道供应商、长期合同等保障措施。
补货策略:定期审查库存和销售数据,确保产品库存量能够满足生产需求。如果发现库存量低于安全库存线,必须及时补货。
E类(Essential)产品(如轮胎、刹车片):
库存管理策略:这些产品对生产仍然重要,但可以接受在短期内的供应调整。企业可以根据市场需求进行季节性调整,或适度减少库存水平以降低成本。
补货策略:合理规划补货周期,基于销售历史和季节性需求,灵活调整库存量。例如,轮胎的需求通常会在冬季或特定促销期增加。
D类(Desirable)产品(如后视镜、座椅缝线):
库存管理策略:这些产品的库存需求较低,可以减少库存量或延长补货周期。可以根据实际使用情况来确定是否继续保留库存。
补货策略:对于D类产品,可以采用较长的采购周期,定期检查是否需要替换或淘汰滞销产品。
通过VED分类,企业能够清晰地识别哪些产品是目前的主推款、形象款、陈列款等,作为客观条件的主观补充。
五、多维度整合(主观+客观)
将 XYZ、VED、FSN 等多维度的分类模型整合在一起,确实是一个复杂的任务,尤其当这些分类标准涉及到不同的变量和维度时。为了实现这个目标,通常可以采用 多维度权重分析 和 机器学习算法 来综合考虑各个分类维度。下面是一些方法,如何将这些多维度分类模型整合在一起:
1. 加权评分法(Weighted Scoring Method)
一种简单但有效的方法是采用 加权评分法,将不同分类维度(例如 XYZ、VED、FSN)的得分进行加权汇总。这种方法的基本思路是为每个维度(如 销售频率、重要性、需求波动性 等)设定一个权重,并根据每个产品在各个维度上的表现来计算一个综合得分。
步骤:
定义维度:确定哪些维度(例如:销售频率、重要性、需求波动性等)是用于分类的。
设定权重:为每个维度设定权重(根据企业需求,可以根据经验、业务目标、数据分析等)。
打分:根据每个维度对产品进行打分(例如:FSN分类中的F类=3分,S类=2分,N类=1分)。
计算综合得分:将各个维度的得分乘以相应的权重后求和,得到每个产品的综合得分。
排序或分类:根据综合得分进行排序或划分组别。
举个例子:
假设我们有一个产品(如轮胎)需要考虑以下三个维度:
XYZ分类(需求波动性):根据历史销售数据分为X类、Y类、Z类。
VED分类(重要性):分为V类、E类、D类。
FSN分类(流动速度):分为F类、S类、N类。
每个维度的权重可以设定为:
XYZ:权重0.4
VED:权重0.3
FSN:权重0.3
假设:
XYZ分类为 X类(分数3)
VED分类为 E类(分数2)
FSN分类为 F类(分数3)
那么,综合得分计算如下:
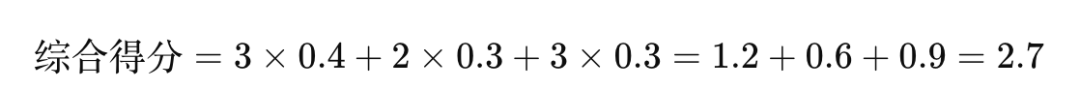
然后可以根据综合得分进行排序或分类。
2. 聚类分析(Clustering)
聚类算法是一种无监督学习方法,能够根据多个变量自动将对象(如产品)分成几个组别。通过聚类方法,我们可以将XYZ、VED、FSN等多个维度的数据结合起来,自动对产品进行分组。
K-means聚类:一种常见的聚类算法,适用于数值型数据。通过计算产品在多个维度上的均值,将其分为K个类别。你可以把 XYZ、VED、FSN 等分类的得分作为特征输入K-means算法,然后根据聚类结果对产品进行分类。
层次聚类(Hierarchical Clustering):这种方法基于距离度量来构建树状图,并且可以根据不同的阈值切割树状图来生成不同数量的类别。层次聚类适用于那些需要从多个维度中综合考虑产品特征的情境。
3. 多目标优化(Multi-Objective Optimization)
当涉及多个维度(如销售频率、需求波动性、重要性等)时,多目标优化方法是一个很好的选择。它可以帮助你在不同维度之间找到一个平衡点,并且综合考虑多个目标函数。
目标函数可以包括:
最大化销售效益(考虑需求波动性);
最小化库存持有成本(考虑库存波动);
优化产品的补货和存货策略(考虑产品重要性)。
这种方法通常通过优化算法(如线性规划、整数规划等)来实现。
4. 机器学习方法
如果分类任务的维度较多且关系较为复杂,机器学习可以更好地帮助我们自动识别不同维度之间的关系,并进行预测或分类。常用的机器学习方法包括:
决策树(Decision Trees):决策树是一种基于树形结构的分类方法,它能够很好地处理多维度的分类问题。通过构建树形模型,机器可以根据不同的特征(如销售频率、需求波动性、重要性等)自动进行分类。
随机森林(Random Forest):随机森林是多棵决策树的集合,可以提高预测的准确性。它可以处理高维度特征,并自动评估特征的重要性。
支持向量机(SVM):SVM是一种强大的分类算法,能够找到不同类别之间的最佳分隔超平面,适合用于处理复杂的多维度数据。
神经网络(Neural Networks):当数据量庞大,且维度非常复杂时,神经网络可以通过深度学习来自动提取特征并进行分类。神经网络特别适用于处理具有复杂模式的多维度数据。
5. 深度学习方法
当产品分类维度非常复杂(例如同时考虑销量、销售频率、需求波动性、产品重要性等多个因素),深度学习方法,尤其是多层感知器(MLP)网络或卷积神经网络(CNN),可以在多维度特征空间中学习复杂的模式和关系。
深度学习可以帮助从历史数据中自动学习出每个特征的权重和关系,从而更加精准地进行分类和预测。
6. 组合方法(Hybrid Approach)
你还可以将上述方法结合起来,形成一个多阶段的模型。例如,首先使用加权评分法对产品进行初步分类,然后通过聚类分析对产品进行精细化分组,最后使用机器学习模型进行进一步优化和预测。
进行销售预测,可以将各种算法分别使用,也可以分阶段使用,或者整合使用。虽然目前市场比较热衷于大模型解决所有问题,但对于全局最优和局部最优还是要慎重考虑,各有千秋。下面几期将会对每一种算法进行展开并附上实现的伪代码。