大模型技术30讲-5-利用数据来减少过拟合现象
利用数据来减少过拟合现象
- Question
- 定义
- 常用方法
- 采集更多数据
- 数据增强
- 预训练
- 其他方法
- 参考文献
Question
假如用监督学习训练了一个神经网络分类器,但发现它出现了过拟合现象。从数据层面入手,有哪些常用方法来减少过拟合现象呢?
定义
过拟合是机器学习中经常遇到的问题,它是指模型对训练数据拟合得过于紧密,导致学习到了数据的噪声和异常值。而并非数据背后的真实规律。结果造成模型在训练数据上表现良好(甚至可能达到100%准确率),但在未见过的数据或测试数据上都表现不佳。虽然有办法减少过拟合,但很难将其彻底消除,因此,我们的目标是尽可能将过拟合最小化。
减少过拟合现象最有效的方式是采集更多高质量的有标签数据。但如果我们无法得到更多有标签数据,也可以通过增强现有数据或利用无标签数据进行预训练等方法来对付过拟合。
常用方法
在这里,主要介绍三种经历了时间考验的方法:采集更多数据、数据增强和预训练。
采集更多数据
减少过拟合现象最好的方式之一是采集更多质量更高的数据。通过绘制学习曲线来判断模型是否会从更多数据中收益。为了构建学习曲线,让模型在不同大小的训练集(如完整数据集的10%,20%等)上进行训练,并在大小不变的验证集或测试集上对训练后的模型进行评估。如果所示,随着训练集大小的增加,模型在验证集上的准确性也会提高。这表明,通过采集更多数据能够提升模型性能。
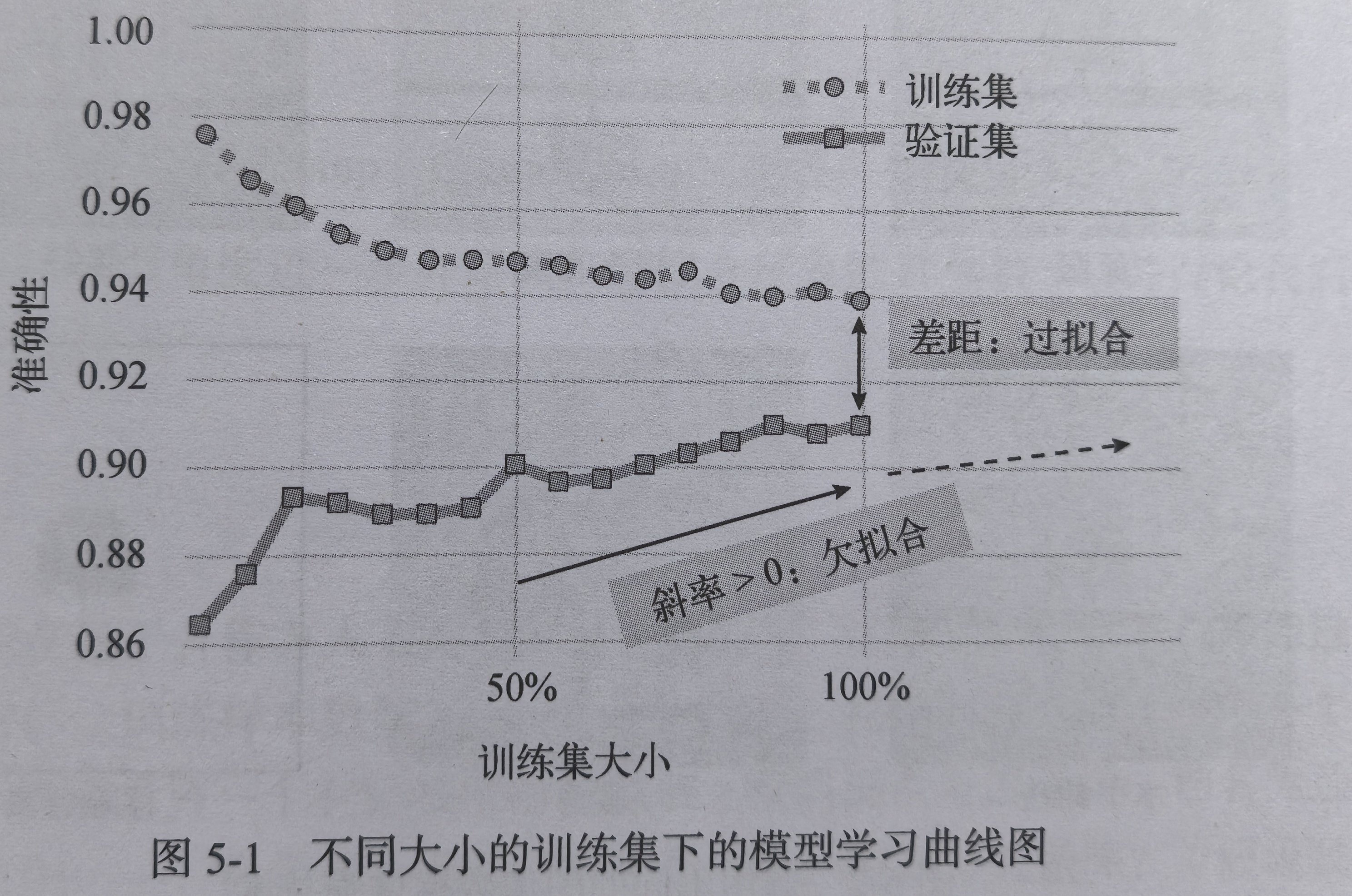
模型在训练集和验证集上表现的差距,反应了过拟合的程度——差距越大,表明过拟合越严重。反之,如果验证集上的正确率随着训练集的增大而提高,说明模型存在欠拟合问题,投喂更多数据可能会有帮助。通常来说,采集更多的数据能够缓解模型的欠拟合和过拟合问题。
数据增强
数据增强是指基于现有数据生成新的数据样本或特征,它能在不采集额外数据的情况下扩充数据集。通过数据增强技术,能够生成原始输入数据的多个不同的版本,从而有助于提升模型的泛化性。因为数据增强后,模型不容易从训练样本或特征中记住虚假信息,以图像数据处理为例,模型将很难记住特定像素位置的精确像素值。下图展示了一些常见的图像数据增强技术,如提高亮度、翻转和裁剪等。

除了采集更多数据和增强现有数据,还可以创造全新的合成数据。尽管这种做法更多见于图像和文本数据,但对比表格型数据集来说也是可行的。
预训练
如技术2中所讲的,自监督学习允许我们通过大型无标签数据集对神经网络进行预训练,这也有助于减少在较小的目标数据集上发生的过拟合现象。
作为自监督学习的替代方案,也可以选择在大型有标签数据集上进行传统的迁移学习。如果有标签数据集与目标领域高度相关,迁移学习将特别有效。比如说,训练一个模型来识别不同的鸟类,可以先在一个包含多种动物的大型通用动物分类数据集上对网络进行预训练。但是,如果没有符合要求的大型数据集,也可以在范围相对较大的ImageNet数据集上进行预训练。
有时候数据集可能非常小,监督学习不适用,比如每个标签下只有几个样本。如果我们的分类器需要在无法获取更多有标签数据的情况下工作,可以考虑小样本学习。
其他方法
以上介绍了减少过拟合现象的主要方法,这些方法都面向数据集实现,但并不是全部策略,其他常见的技术还包括:
- 特征工程和标准化
- 假如对抗样本和标签或特征噪声
- 标签平滑
- 更小的训练批次
- 其他数据增强技术,如Mixup,Cutout和CutMix等。
参考文献
[1] 塞巴斯蒂安·拉施卡, 大模型技术30讲, 人民邮电出版社(北京), 2025, PP18-21.