@SchedulerLock处理Spring Task在分布式环境下的重复执行问题
本文大纲📖
- 1、背景🍂
- 2、@SchedulerLock注解
- 3、实现原理
1、背景🍂
Spring生态下,日常开发定时任务,使用Spring Task框架还是很常见的选择,但Spring Task并不是为分布式环境设计的,分布式环境下,服务被部署到多个节点,一个节点上运行着一个独立的Jvm,各个节点之间并不会协调通讯📞,因此,同一个定时任务会在每一个节点上都执行一次,导致任务重复执行,此时,可以考虑使用redis、zookeeper等中间件来实现分布式锁,保证一次只有一个节点执行任务,当然,也可以考虑支持分布式调度等框架,如Quartz、xxl-job
2、@SchedulerLock注解
在分布式场景下,可以使用@SchedulerLock注解来弥补Spring Task的缺点,注意⚠️,这个不是Spring的注解,是shedlock库的
package net.javacrumbs.shedlock.spring.annotation;import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface SchedulerLock {String name() default "";String lockAtMostFor() default "";String lockAtLeastFor() default "";
}@SchedulerLock
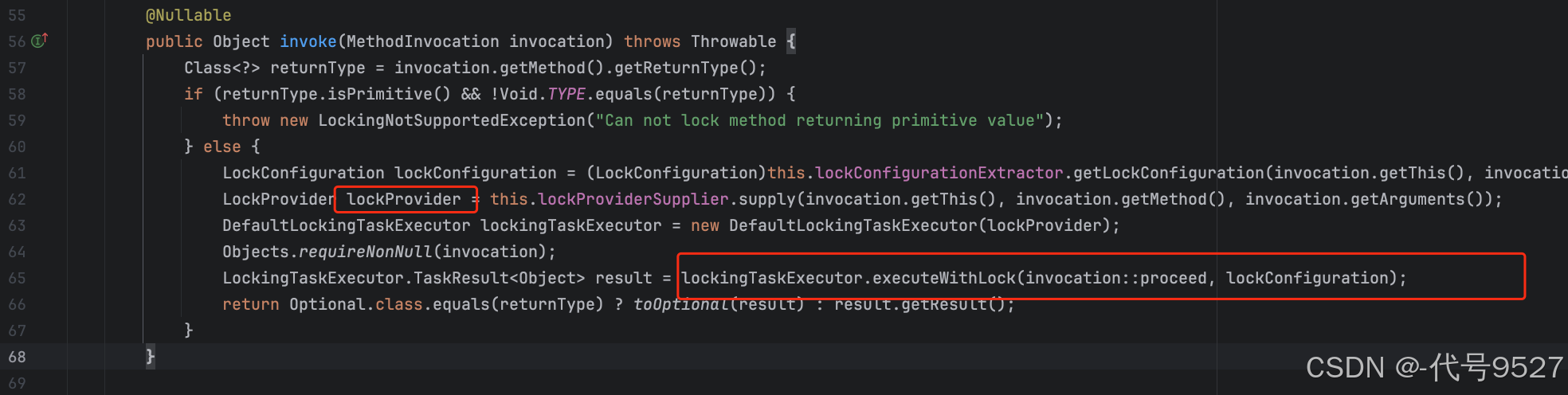
分布式锁的实现方式很多,官方也提供了不同中间件的实现示例:🎒https://github.com/lukas-krecan/ShedLock/blob/master/README.md,这里演示用mysql实现的过程
- 引入相关依赖,注意依赖版本的兼容性
<dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-spring</artifactId><version>4.42.0</version>
</dependency>
<dependency><groupId>net.javacrumbs.shedlock</groupId><artifactId>shedlock-provider-jdbc-template</artifactId><version>4.42.0</version>
</dependency>
- 配置锁🔒提供者,这里是mysql
import net.javacrumbs.shedlock.core.LockProvider;
import net.javacrumbs.shedlock.provider.jdbctemplate.JdbcTemplateLockProvider;
import net.javacrumbs.shedlock.spring.annotation.EnableSchedulerLock;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.scheduling.annotation.EnableScheduling;import javax.sql.DataSource;@Configuration
@EnableScheduling //这个是Spring注解,开启Spring task功能的
@EnableSchedulerLock(defaultLockAtMostFor = "30m", defaultLockAtLeastFor = "1m")
public class LockConfig {@Beanpublic LockProvider lockProvider(@Qualifier("primaryDataSource") DataSource dataSource) {return new JdbcTemplateLockProvider(JdbcTemplateLockProvider.Configuration.builder()// 使用primaryDataSource这个自定义的数据源,和业务接口用一个数据源就行 .withJdbcTemplate(new JdbcTemplate(dataSource)).usingDbTime().build());}
}
- 对应的库里建表
CREATE TABLE shedlock(name VARCHAR(64) NOT NULL, lock_until TIMESTAMP(3) NOT NULL,locked_at TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3), locked_by VARCHAR(255) NOT NULL, PRIMARY KEY (name));
- 使用
import net.javacrumbs.shedlock.spring.annotation.SchedulerLock;...@Scheduled(cron = "0 0 * * * *")
@SchedulerLock(name = "your.task.schedule.lockName") //锁名称自定义,可以驼峰,可以点点点
public void scheduledTask() {// do something
}
- 补充下,上面配置类里写了默认的锁持有的最长时间和最短时间,对于特定任务,可以自定义锁持有时间
@SchedulerLock(name = "TaskScheduler_CommonWhiteRisksReport", lockAtMostFor = "${task.schedulerLock.lockAtMost}", lockAtLeastFor = "${task.schedulerLock.lockAtLeast}")
task:schedulerLock:lockAtMost: "PT8M"lockAtLeast: "PT8M"# Duration的格式是ISO-8601,例如:
# "PT8M" 表示8分钟
# "PT30S" 表示30秒
# "PT1H" 表示1小时
3、实现原理
加@EnableSchedulerLock注解后,会引入SchedulerLockConfigurationSelector类
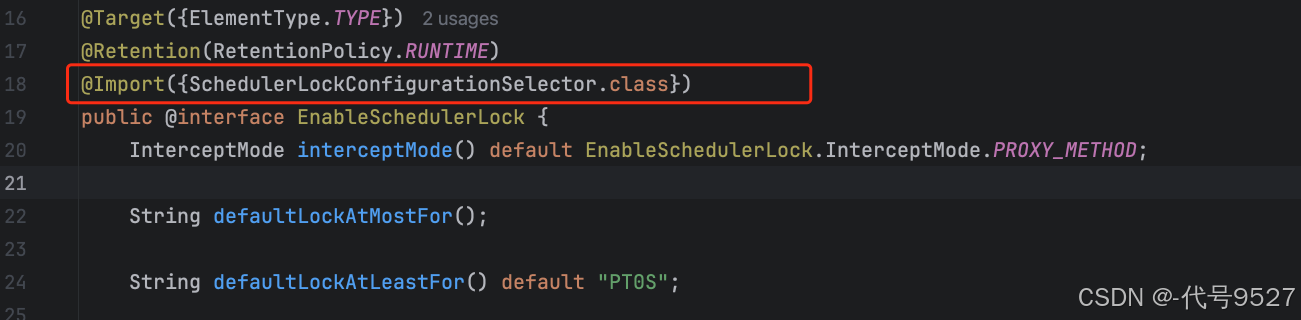
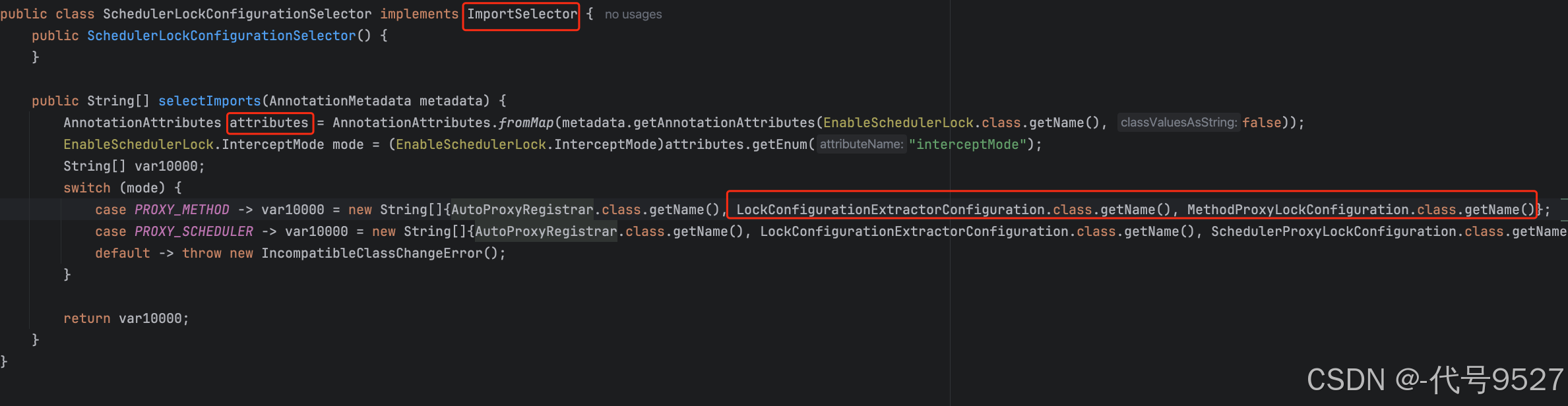
SchedulerLockConfigurationSelector类通过实现ImportSelector类,导入了两个Bean,LockConfigurationExtractorConfiguration 和 MethodProxyLockConfiguration, Sting数组里是要注册成Bean的类的全类名,这两步,就是ImportSelector接口搭配@Import注解声明Bean的方式一种使用
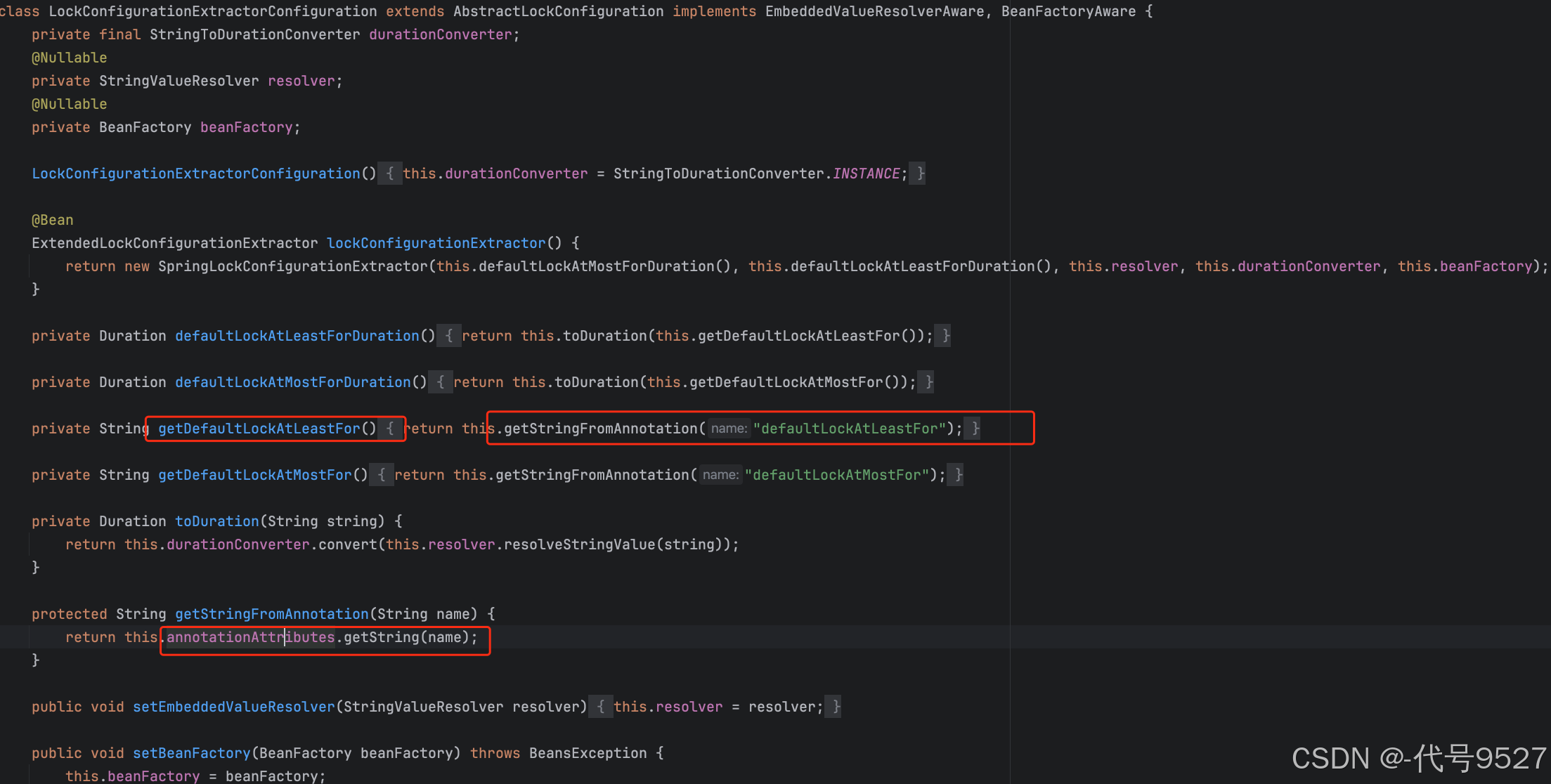
再往下,LockConfigurationExtractorConfiguration配置类声明了ExtendedLockConfigurationExtractor这个Bean,里面包含了锁的一些配置信息,如默认最大持有时间,这些配置是从注解的属性里拿到的,这回配置提取的Bean,会带着这些配置信息,给下面要提到的另一个Bean使用
另一个配置类,MethodProxyLockConfiguration,则是声明了MethodProxyScheduledLockAdvisor这个Bean,里面通过上面的lockConfigurationExtractor获取锁的一些配置
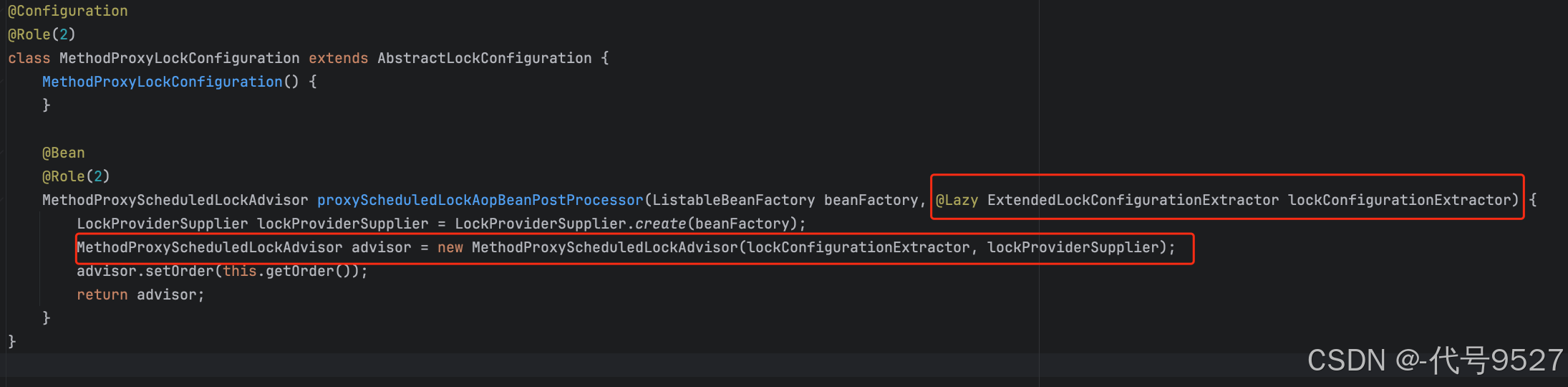
跟进MethodProxyLockConfiguration类,发现其获取了一个切面,切面就是包含@SchedulerLock注解的方法,切面拦截住以后,增强的部分是LockingInterceptor对象

而方法增强部分,就是根据我们提供的LockProvider来做加锁和释放锁的操作:比如mysql向库里写数据,Redis的setnx