西电【信息与内容安全】课程期末复习笔记

西电【信息与内容安全】课程期末复习笔记
来自2022年春的古早遗留档案,有人需要这个,我就再发一下吧。
- 平时成绩: 10%。
- 线上: 10% (线上学习内容, 共 100 分。)
- 实验: 10% (共 2 次实验, 每次实验按 50 分制评分,共 100 分。)
- 论文: 20% (以任何信息与内容安全相关技术撰写一篇学术报告,主题自拟,可适当结合自身研究方向,按所提供 word 模板不少于双栏 4 页。 注意,不允许综述型论文)
- 考试: 50%



重点
信息与内容安全简介
信息与内容安全概述
内容域与网络域

信息内容安全定义
-
信息内容安全是信息安全在法律、政治、道德层次上的要求,是语义层次的安全。我们要求信息内容是安全的,就是要求信息内容在政治上是健康的, 在法律上是符合国家法律法规的,在道德上是符合中华民族优良的道德规范的。
-
广义的信息内容安全既包括信息内容在政治、法律和道德方面的要求,也包括:
- 数据的获取,
- 信息内容的分析与识别,
- 数字图像视频内容安全,
- 多媒体信息隐藏,
- 隐私保护
- 等诸多方面。
信息内容安全的研究意义
- 随着大数据时代的到来以及科学技术的不断进步,数字资料的获取、存储、传输、编辑、转移和利用更加便利,然而人们也可以对其进行任意修改和伪造。
- 对互联网上数字媒体信息的真实性和完整性进行破坏,一方面侵犯个人隐私、版权保护问题,另一方面对社会公共秩序、军事和国家安全等方面均会产生不良影响。
- 虚假新闻的社会传播的往往产生严重后果, 暴力煽动语言的破坏性尤其巨大
- 随着密码和图像水印技术的普及,网上利用信息加密与内容隐藏等技术,隐秘传输非法信息的现象日益普遍
机器学习简介
了解
机器学习
假设用 𝑃 来评估计算机程序在某任务 𝑇 上的性能,若一个程序通过利用经验 𝐸 在 𝑇 中任务上获得了性能改善,则我们就说关于 𝑇 和 𝑃,该程序对 𝐸 进行了学习
机器学习的三个步骤:
- 一组方程
- 衡量方程的优劣
- 找出最好的方程
深度学习
深度学习的三个步骤:
- 神经网络
- 衡量方程的优劣
- 找出最好的方程
对抗样本攻击
机器学习算法以数字向量的形式接受输入。以一种特定的方式设计输入,从而从模型中得到一个错误的结果,这便被称为对抗性攻击
信息获取与表示
信息内容的获取
获取
网络信息内容的类型
- 网络媒体信息
- 网络通讯信息
网络媒体信息获取方法
- 网络媒体信息获取方法
- 基于自然人网络浏览行为模拟的信息获取
信息内容的表示
视觉信息特征

视觉信息的处理过程:
获取、压缩、传输、重建、处理
人眼两种细胞的区分
- 锥状细胞:高亮度、细节信息、快速变化、数量上
- 柱状细胞:低亮度、数量多
三原色
像素化
电脑中表示图像信息
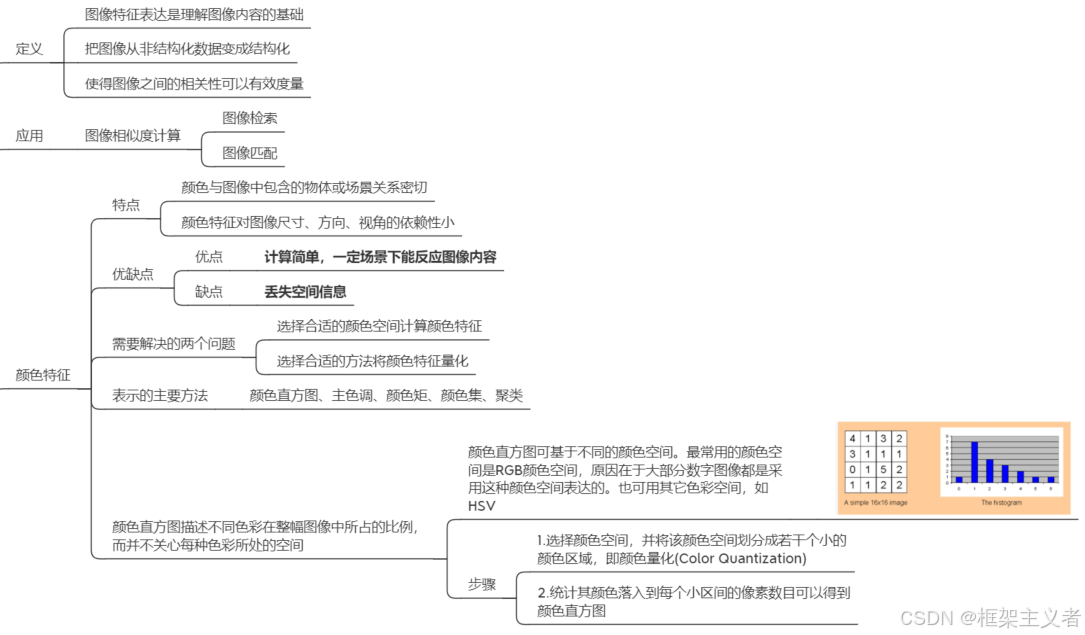
颜色特征
- 直方图
- 主色调……
纹理特征
-
LBP(考计算)

-
HOG(理解)


-
SIFT(深度学习之前最经典的特征,基本原理,尺度不变)


文本特征
文本特征表达(one-hot),另外三种方法的基本概念
1-of-N Encoding( One-hot Encoding)
如何将文本表达成向量?
- 词频: 词频是一个词在文档中出现的次数。通过词频进行特征选择就是将词频小于某一闭值或大于某一值的词删除,从而降低特征空间的维数。
- 文档频数: 文档频数(Document Frequency, DF)是最为简单的一种特征选择算法,它指的是在整个数据集中有多少个文本包含这个单词。
- TF-IDF:词频(TF)=某个词在文章中的出现次数 / 文章的总词数逆文档频率(IDF)=log(语料库的文档总数 / (包含该词的文档数+1))TF-IDF = TF * IDF
音频特征
音频特征表达(流程图,变成彩色图案)



增强、切片、DFT、频谱图、可视化、图像分析方法
IDFT、MFCC
- IDFT
MFCC
深度学习基础
选择、填空、计算
三个步骤
-
设计神经网络

-
评估网络好坏


-
选择最好的网络
神经元、神经网络
神经元的构造,激活函数,不要求计算,但要求掌握输入输出过程公式
神经网络-全连接层
神经网络基本概念,维度
全连接神经网络:全部连接
交叉熵损失的训练方法,梯度下降,反向传播


卷积神经网络

-
卷积:卷积的基本流程
-
卷积核
-
要求会计算卷积
-
优点
- 缩减参数
- 共享参数
-
-
池化:最大最小池化,输入输出位数
-
展平:
-
全连接:
(卷积、池化多次重复)

理解神经网络
神经网络可视化

经典神经网络结构
(了解)
LeNet-5
AlexNet 2012
- ReLU
- 标准化
- Dropout
- 数据增广
VGGNet
- 3x3 小卷积
- 16、19层
GoogLeNet
- 23层
- 不同尺度特征图串联
- 1x1 conv
ResNet
- 152层
- 残差学习:跳层连接,解决梯度消失问题
生成对抗网络 GAN

(偏概念)
生成器
判别器
GAN 步骤与原理




argmax/argmin的意思是在里面达到最大的时候,min/max下面那个变量的值
V(G,D)严格定义叫散度,但应该不要求掌握散度是啥,大概理解就是两个图像的差距
初始化生成器【输入随机向量】、判别器【输入为图像】,固定一个,更新一个【二者博弈得到生
成】
生成器原理【散度】
判别器原理【采样】


GAN 里的各种公式,最大最小

PPT 上的特别小的公式了解为主
参考:DCGAN Tutorial — PyTorch Tutorials 1.11.0+cu102 documentation

Conditional GAN
(了解,可用图像风格转换)
条件的意思:输入不是随机向量,而是一个图像
InfoGAN
主要区别:提供两个输入
普通的GAN存在无约束、不可控、噪声信号z很难解释等问题,2016年发表在NIPS顶会上的文章InfoGAN:Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets,提出了InfoGAN的生成对抗网络。InfoGAN 主要特点是对GAN进行了一些改动,成功地让网络学到了可解释的特征,网络训练完成之后,我们可以通过设定输入生成器的隐含编码来控制生成数据的特征。
作者将输入生成器的随机噪声分成了两部分:一部分是随机噪声Z, 另一部分是由若干隐变量拼接而成的latent code c。其中,c会有先验的概率分布,可以离散也可以连续,用来代表生成数据的不同特征。例如:对于MNIST数据集,c包含离散部分和连续部分,离散部分取值为0~9的离散随机变量(表示数字),连续部分有两个连续型随机变量(分别表示倾斜度和粗细度)。InfoGAN-无监督式GAN - 简书 (jianshu.com)
应用

了解即可
-
图像翻译
- Pix2Pix
- CycleGAN
- StarGAN:多合一
-
人脸属性编辑
-
图片质量增强
-
文本合成图像
- Text-conditional GAN
-
图像语义分割
-
人脸去遮挡任务
-
小物体检测
Attack ML Models
在线社交网络分析 与 舆情检测
在线社交网络分析
了解原理即可

在线社交网络是一种在信息网络上由社会个体集合及个体之间的连接关系构成的社会性结构,包含关系结构、 网络群体与网络信息三个要素。
在线社交网络的三个维度
- 结构
- 群体
- 信息
在线社交网络的地位和作用
- 政治
- 经济
- 文化
- 生活
在线社交网络分析定义
在线社交网络分析是指从网络结构、 群体互动、信息传播三个维度,基于信息学、数学、社会学、管理学、心理学等多学科的融合理论和方法,为理解人类各种社交关系的形成、行为特点分析以及信息传播的规律提供的一种可计算的分析方法。
信息传播模型
(掌握原理)
影响力模型
每个节点有两种状态: 活跃(active)和不活跃(inactive), 只有活跃状态的节点才具有影响力, 能够影响其他节点。
当一个节点被其他节点影响成功时, 则称该节点被激活, 不活跃状态的节点不能激活其他节点。
社会网络的影响力传播表现为节点状态由不活跃变激活为活跃, 状态转变是单向的, 即网络中不存在由活跃变为不活跃的情况。
Independent Cascade (IC) 独立级联模型

Linear Threshold (LT) 线性阈值模型

传染模型
传染模型也叫流行病模型, 用于描述个人传播传染病的方式
节点有三种状态
- S 易感人群:易感节点可能会感染疾病
- I 感染人群:感染节点有机会去感染易感人群
- R 免疫人群:感染节点被治愈后不会再得疾病的人群
Susceptible Infected Recovered (SIR)
设总人口为N(t), 则有N(t)=s(t)+i(t)+r(t)。
三个假设:
- 人口始终保持一个常数, 即N(t)≡K。
- 假设t时刻单位时间内, 一个病人能传染的易感者数目与此环境内易感者总数s(t)成正比, 比例系数为β, 从而在t时刻单位时间内被所有病人传染的人数为βs(t)i(t)。
- t时刻, 单位时间内从染病者中移出的人数与病人数量成正比, 比例系数为γ, 单位时间内移出者的数量为γi(t)



β: 易感节点被成功感染的概率
μ: 感染节点被治愈的概率
社交网络传播引导
如何投放信息使其传播影响力最大?
影响力计算方法
就是总体过程求平均

影响力最大化贪婪算法
原理:只保留最大影响力的节点

社交网络话题发现模型
概率潜在语义分析模型(PLSA) (了解为主)

舆情检测
记忆基本概念,特性,演化流程

网络舆情:是指以互联网为载体所表达的公众情绪,究其本质是社会情绪在互联网这个可见载体上的公共表达。
网络舆情特征
- 自发性
- 指向性
- 时效性
- 情绪性
- 片面性
网络舆情演化
- 形成期
- 高涨期
- 波动期
- 消退期
网络舆情监测系统

三个层
-
数据采集处理层
-
提供网络数据采集和预处理功能
- 网络爬虫(了解)
- PageRank(了解)
-
-
舆情分析处理层
- 主要提供话题检测、 话题跟踪、 倾向性分析、 自动摘要以及中文分词等功能
- 主要完成热点话题的检测、 跟踪以及情感倾向性分析, 并且对各类热点话题及倾向性进行自动摘要, 分析结果存入数据库, 以便为用户提供各种舆情分析服务。
- 舆情分析引擎的核心技术是文本聚类、 文本分类、 情感分析中所采用的模型与算法, 直接关系到系统的性能高低。
-
舆情分析服务层
- 主要提供突发事件分析、 舆情预警报警、 舆情趋势分析、 舆情统计报告以及舆情查询检索等各种舆情分析服务
信息过滤


信息过滤通常是在输入数据流中移除数据, 而不是在输入数据流中找到数据。
在信息内容安全领域, 信息过滤是提供信息的有效流动, 消除或者减少信息过量、信息混乱、信息滥用造成的危害。
信息过滤模型

过滤模型,各部分
例子
信息过滤与其他信息处理异同
| 信息处理方法 | 信息需要/需求 | 信息源 |
|---|---|---|
| 信息过滤 | 稳定的、特定的信息 | 动态的、非结构化的 |
| 信息检索 | 动态的、特定的信息 | 稳定的、非结构化的 |
| 数据访问 | 动态的、特定的信息 | 稳定的、结构化的 |
| 信息提取 | 特定的信息 | 非结构化的 |
信息检索

信息分类

信息抽取(信息提取)

信息过滤应用
- Internet搜索结果的过滤
- 用户电子邮件过滤(垃圾邮件过滤)
- 服务器/新闻组过滤
- 浏览器过滤
- 专为孩子的过滤(绿色上网)
- 为客户的过滤-用户爱好推荐(APP个性化推荐)
信息过滤评价

分类体系


过滤方法
要会计算
-
根据操作方法
-
主动
- 主动搜集信息,并将相关信息发送给用户
-
被动
- 不负责为用户搜集信息
-
-
根据操作位置
- 在信息源端过滤
- 在过滤服务器端过滤
- 在客户端过滤
-
过滤方法
-
基于认知的过滤(Cognitive filtering)
- 基于内容或者用户兴趣的过滤
- 将文档内容和用户的Profile进行相似度计算
-
基于社会的过滤(Sociological filtering)
- 也称为协同过滤(Collaborative filtering)
- 对某个用户的Profile进行匹配时,通过用户之间的相似度来计算Profile和文档的匹配程度
- 社会过滤常常使用用户建模(User modeling)及用户聚类(User clustering)等技术。
-
-
根据获取用户知识分类
- 显式
- 隐式
- 显式和隐式相结合的方法
-
基于匹配的信息过滤:字符串匹配
-
单模式
-
BF(Brute Force, 穷举/暴力破解法)
-
KMP(由D.E.Knuth、 J.H.Morris和V.R.Pratt设计)
- next数组、 PMT (Partial Match Table) 部分匹配表
- 七分钟了解什么是 KMP算法_哔哩哔哩_bilibili
-
BM(由 Bob Boyer 和 J Strother Moore 设计)
- 从右向左扫描:从右到左取p中字符比较
- 坏字符规则
- 动画演示什么是BM算法_哔哩哔哩_bilibili
-
-
多模式
-
多模式匹配: AC自动机算法
-
基本思想:
-
在预处理阶段, AC自动机算法建立了三个函数, 转向函数goto,失效函数failure 和输出函数output, 由此构造了一个树型有限自动机。
先计算深度为1的状态失效函数, 再计算深度为2的失效函数, 依次类推;

-
在搜索查找阶段, 则通过这三个函数的交叉使用扫描文本, 定位出关键字在文本中的所有出现位置。
-
-
特点:
- 扫描文本时完全不需要回溯;
- 时间复杂度为O(n), 与关键字的数目和长度无关。
-
用最直观的方式理解AC自动机_哔哩哔哩_bilibili
-
-

对抗攻击与防御
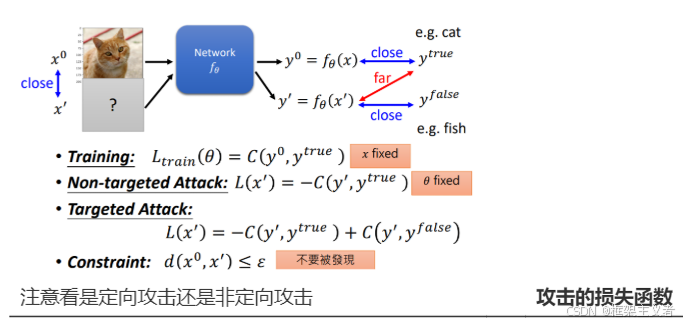
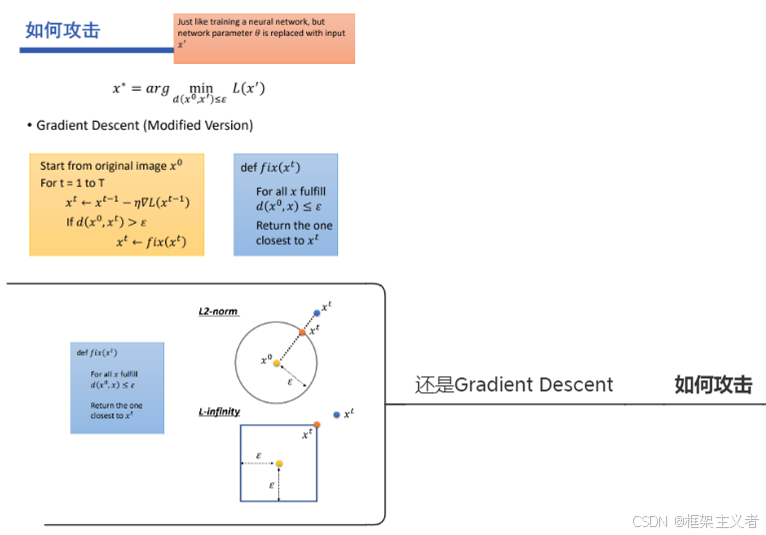
攻击的损失函数
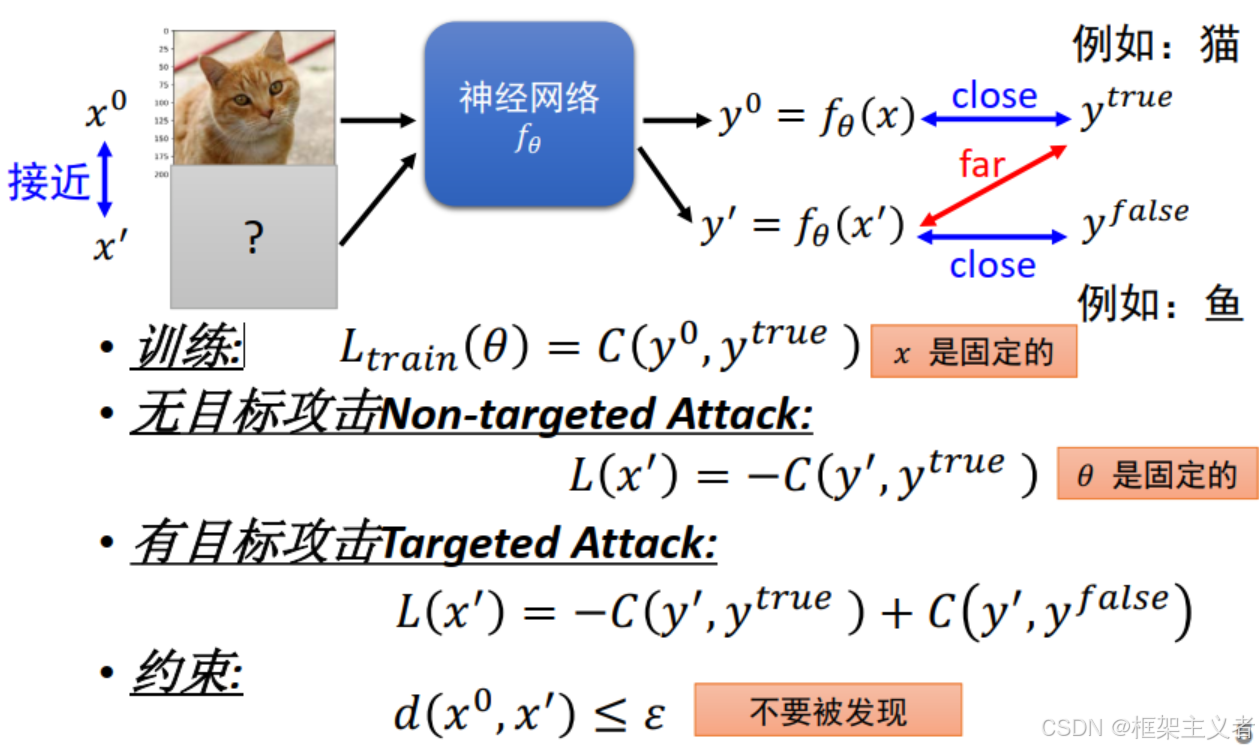
约束范式
-
L2-norm
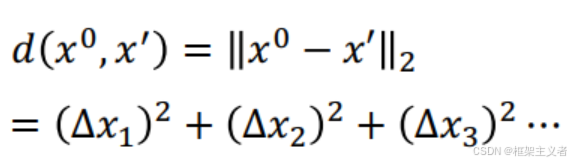
-
L-infinity
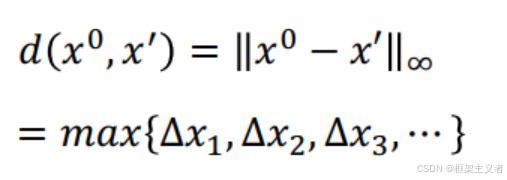
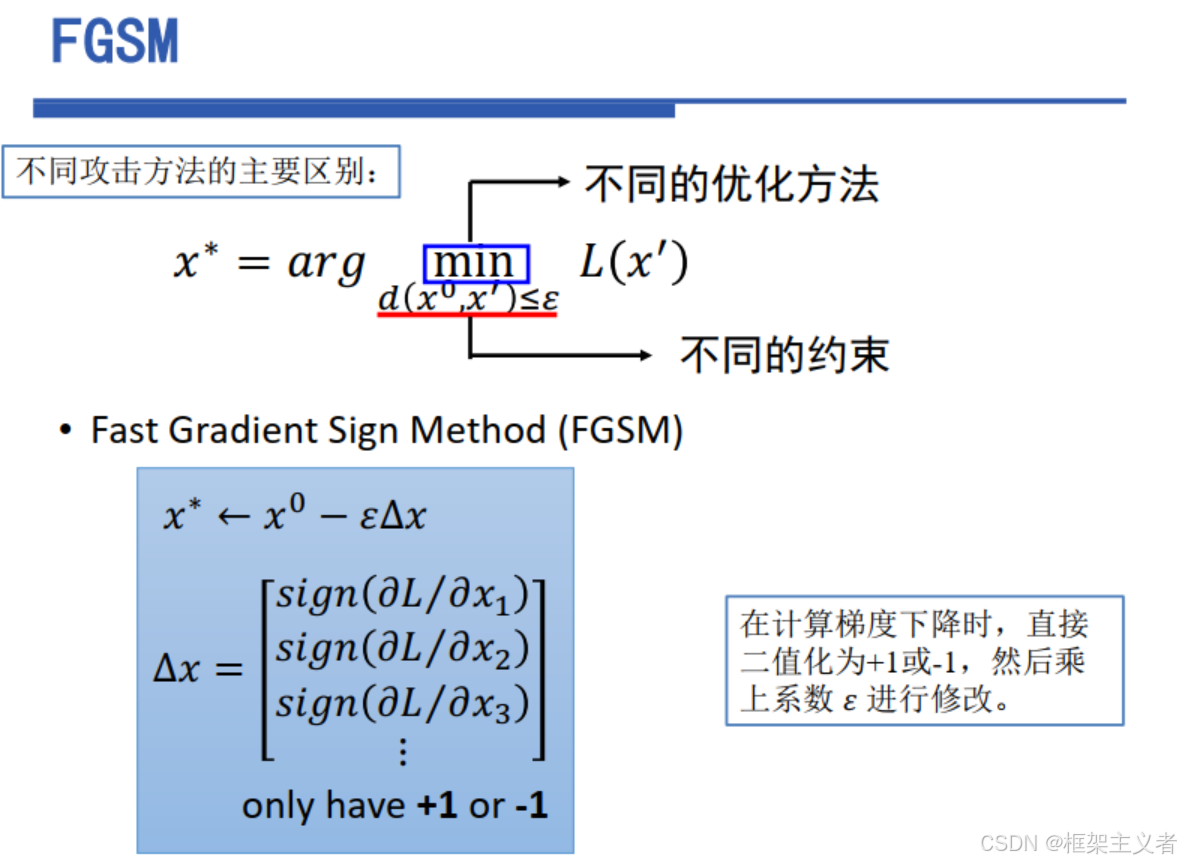
FGSM
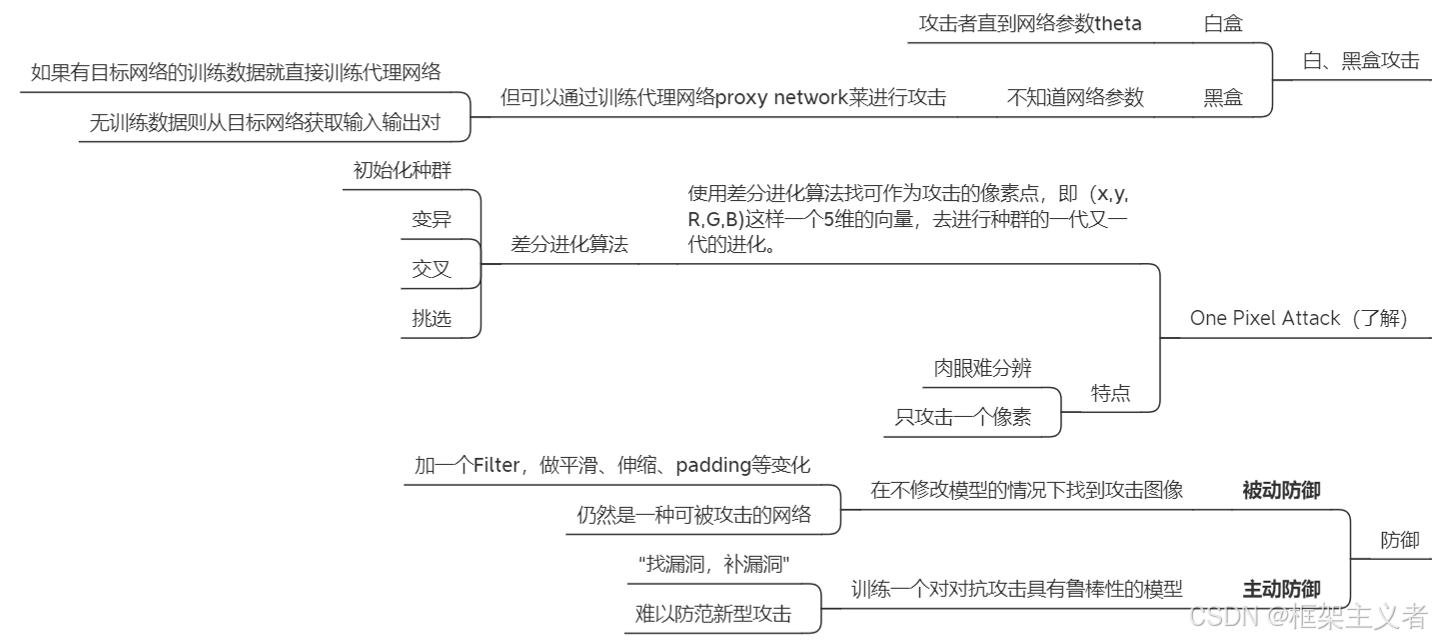
白盒攻击 黑盒攻击
(简答题,怎样是 xx 攻击)
攻击方式举例
单像素攻击
差分进化
文本攻击
语音攻击
防御手段
(简答:思想,实现)
-
被动
-
特征挤压 (Feature Squeeze)
将图像经过原模型、经过Squeezer处理后的结果进行比较,如果结果有差异,
则输入图像可能是被攻击过了。
• 这里的Squeezer可以是整体压缩每个像素值、图像局部平滑等操作
-
-
主动
- 增加对抗数据
视觉内容伪造与检测
偏概念
方法
例子 s,知道有那些方法就行
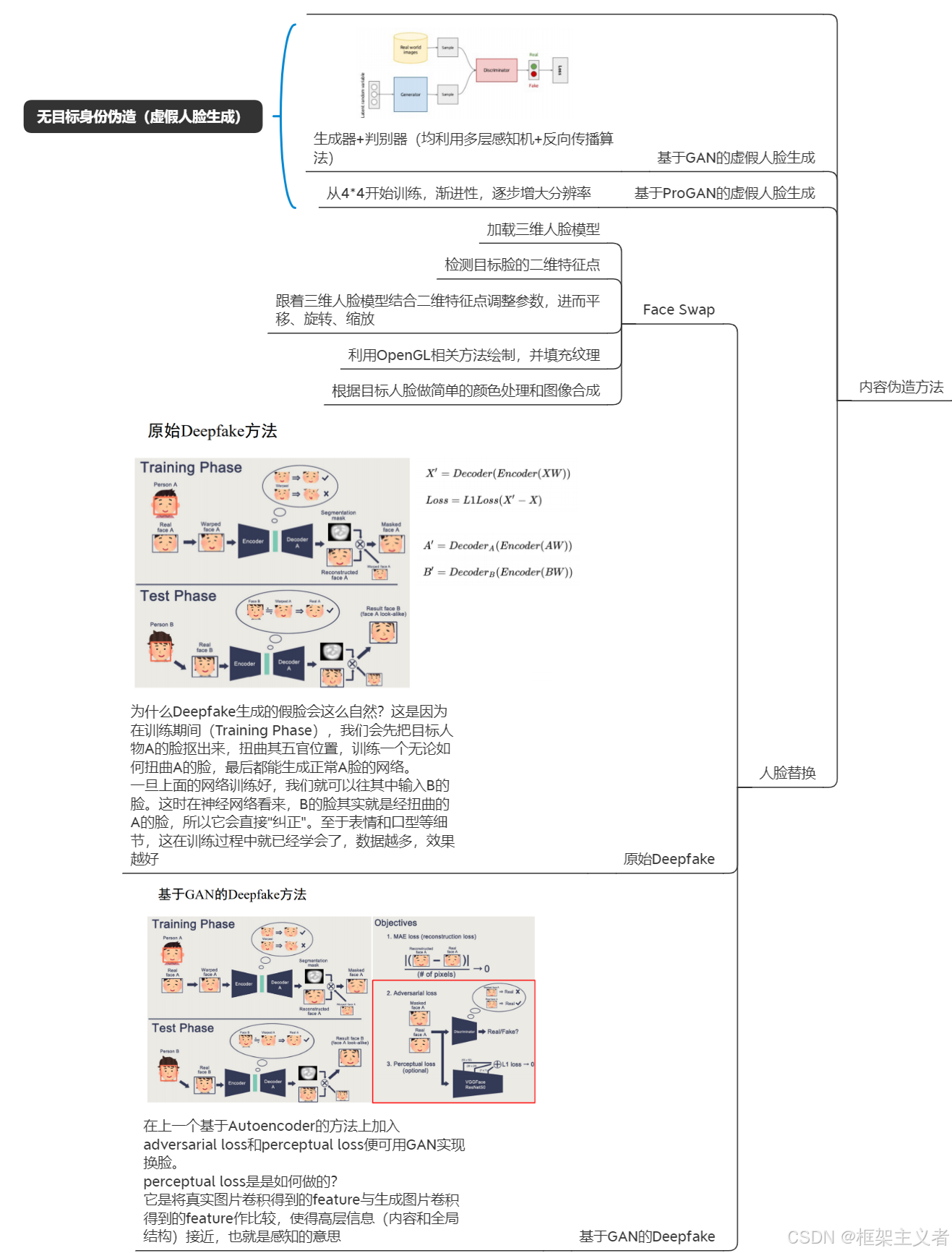
人脸替换的基本原理
伪造检测方法分类
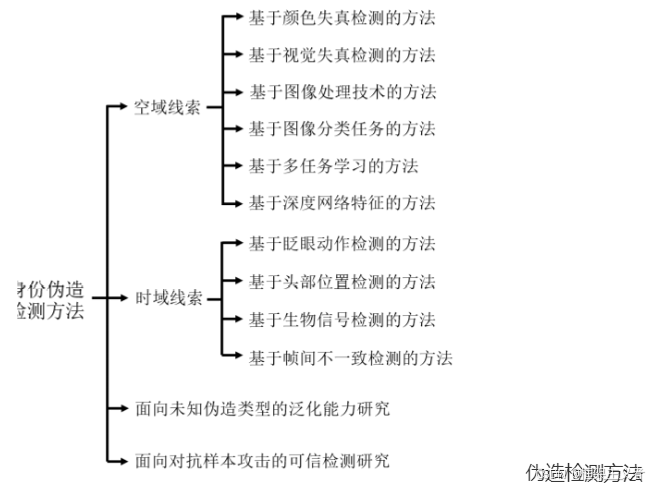
- 手动特征
- 检测网络
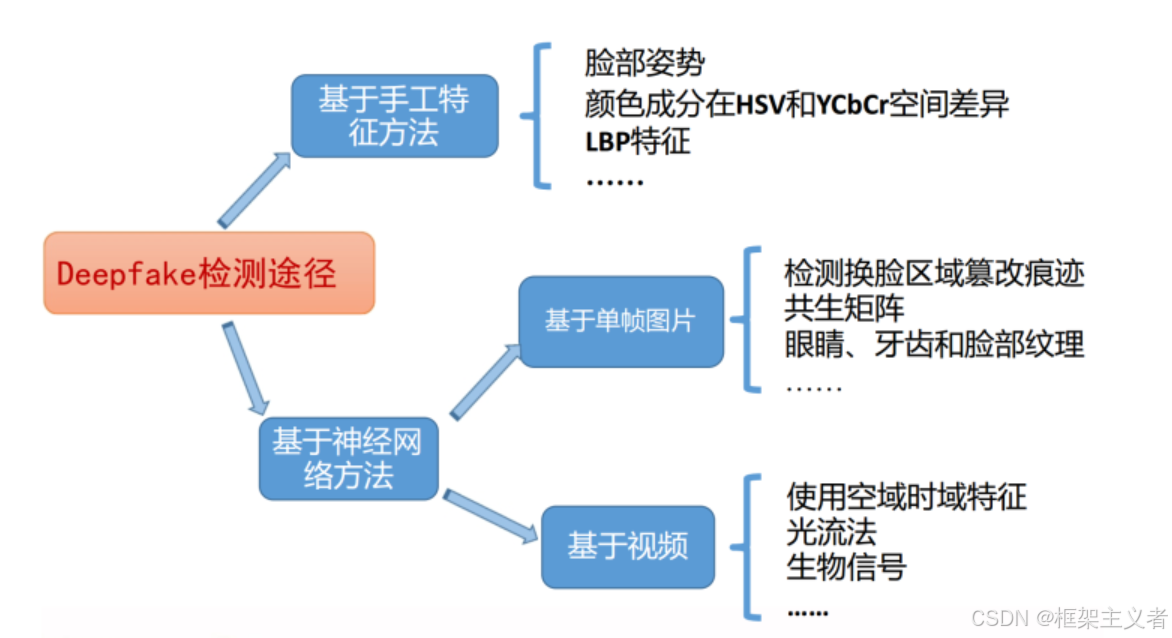
身份认证系统的攻击与防御
身份认证
身份认证概念、流程
保证操作者的物理身份与数字身份相对应
物理身份与数字身份一致
基本途径
- 基于你所知道的(What you know )
- 基于你所拥有的(What you have )– 身份证、信用卡、钥匙、智能卡、令牌、私钥等
- 基于你的个人特征(What you are) – 指纹,笔迹,声音,手型,脸型,视网膜,虹膜
- 双因素、多因素认证
生物特征

生物特征种类比较
- 指纹
- 手形
- 手部血管分布
- 人脸
- 脸部热量图
- 虹膜
- 视网膜
- 签名
- 语音
生物特征的比较
• 指纹:最经典、最成熟的生物认证技术
• 人脸:自然,直观,无侵害,易用的生物认证技术
• 手掌: 易实现,成本低,识别速度快的生物认证技术
• 虹膜:高独特,高稳定的生物认证技术
• 视网膜:受保护,防欺骗性好;采集困难
• 签名:易于接受,常用于信用卡、文件生效等场合
• 声音:成本低,代价小,常用作辅助手段
生物特征认证流程
-
注册
-
识别
-
匹配
- 验证 1:1 比对
- 鉴别 1:n 比对
活体检测方法
概念、场景
异常检测
概念为主

是否是一类数据,检测目标
应用
- 信用卡盗刷
- 癌细胞...
与普通二分类区别
有标记方法

无标记方法
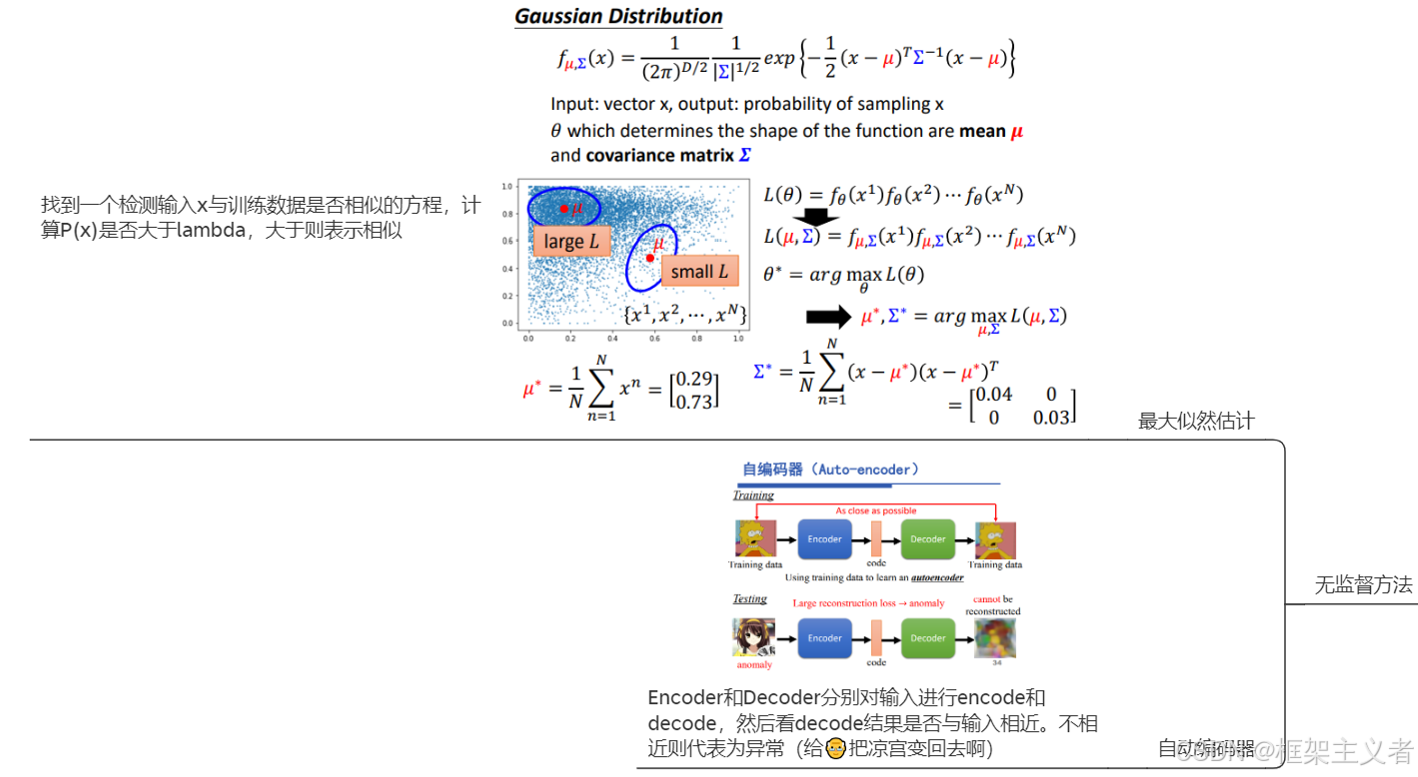
评价方法
目标不同,严格程度(假阳性..)

线上内容
考
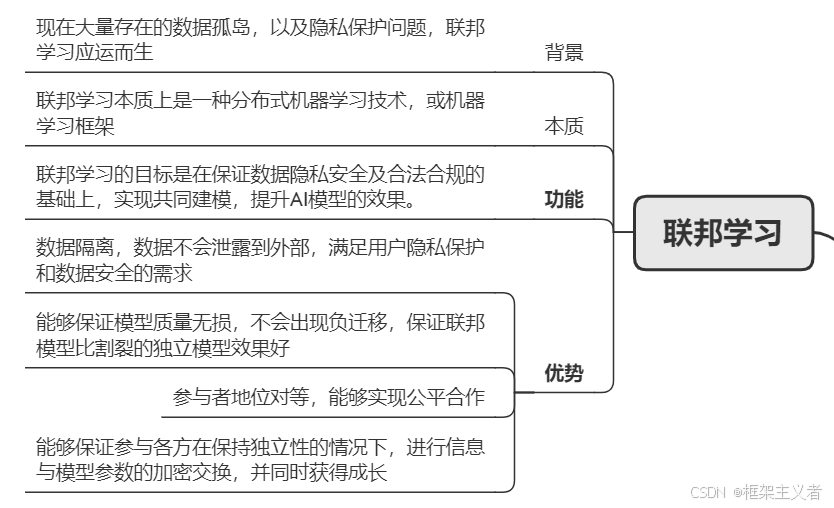

参考
非常感谢未知名同学的思维导图,如有侵权请联系作者。