机器学习-黑马笔记
视频链接
一、概述
1.1 关系

1.2能做些什么
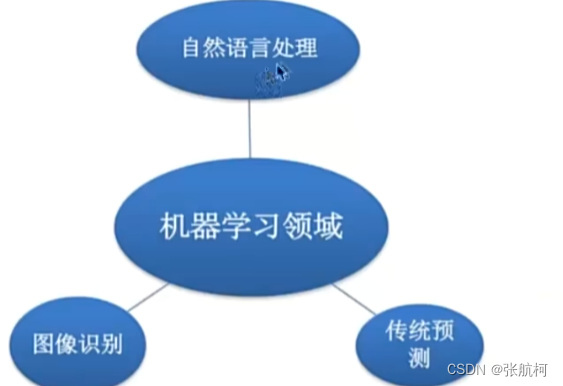
- 传统预测
用在挖掘和预测,例如销量预测、广告推荐、企业客户分类、sql语句安全检测分类等
- 图像识别
用在图像识别,例如人脸识别、交通标签识别等
- 自然语言处理
用在语言处理,例如文本分类、情感分析、自动聊天、文本检测等
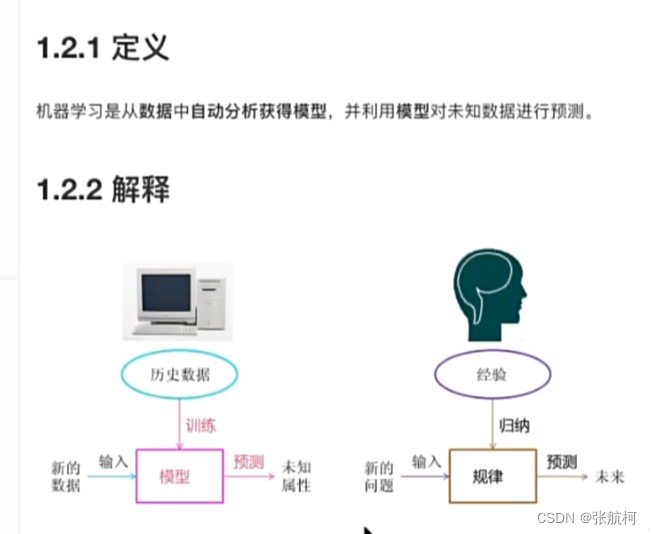
1.3 解释
数据、模型、预测
1.4 数据集成
结构:特征值+目标值
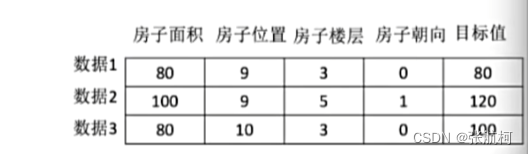
- 对于每行我们可以称之为
样本 - 有些数据集可以没有
目标值如下

1.5 机器学习算法分类
1.了解3大类型
-
目标值:类别 = 分类

-
目标值:连续分类 = 回归问题

-
目标值:无 = 无监督学习

有目标的为
监督学习
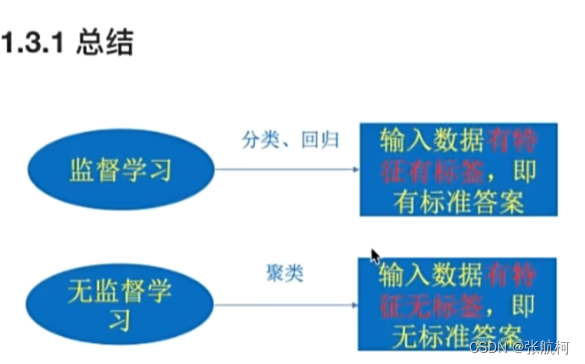
2. 机器学习算法分类

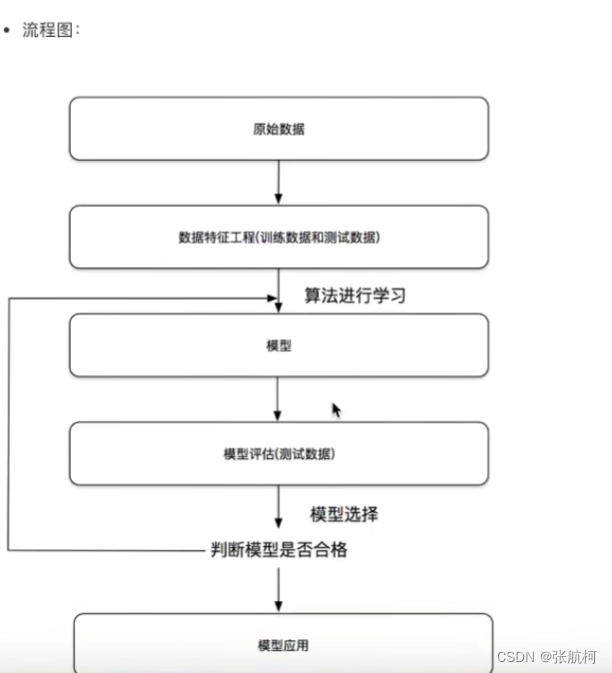
1.6 机器学习开发流程
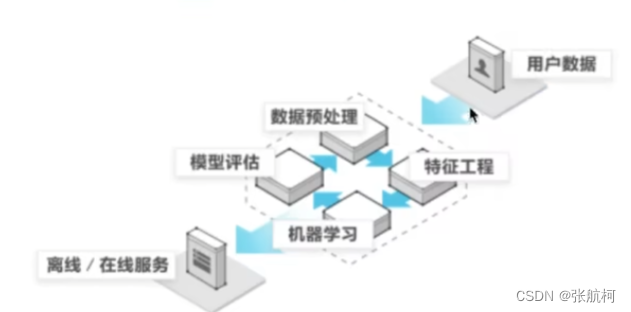
- 获取数据
- 数据处理
- 特征工程(特征值)
- 机器学习算法进行训练 = 模型
- 模型评估
- 应用
1.7 学习框架+资料介绍
- 算法是核心,数据+计算是基础
- 找准定位



二、特征工程
2.1 可用数据集
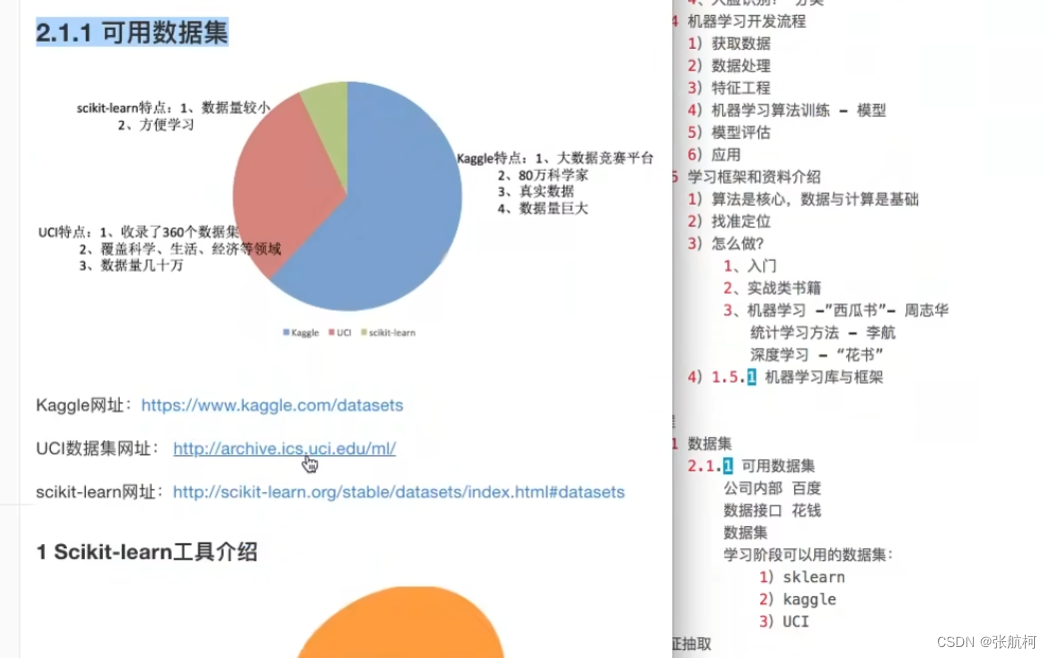
2.2 scikit-learn数据集
中文地址

1.安装
pip install scikit-learn
使用自带的数据集

2.小数据集
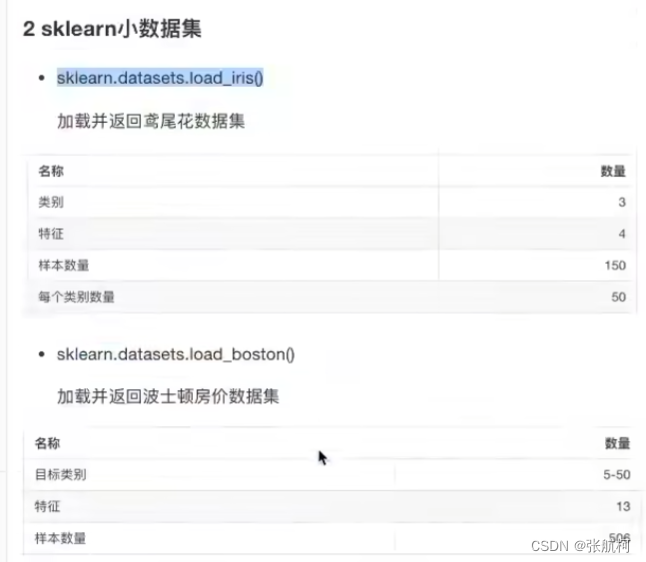
3. 大数据集

4.数据集的使用
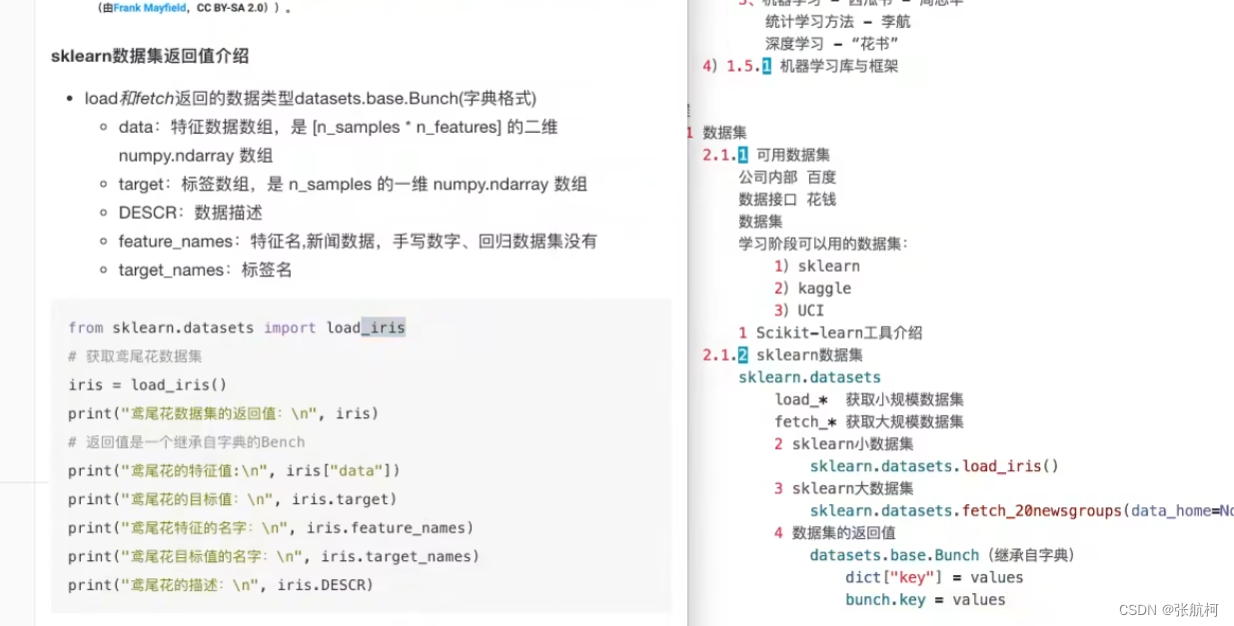
5. 数据划分(数据集合划分)
不能所有数据都用在训练中,得留一部分验证,所以需要划分一部分数据

2.3 特征工程介绍

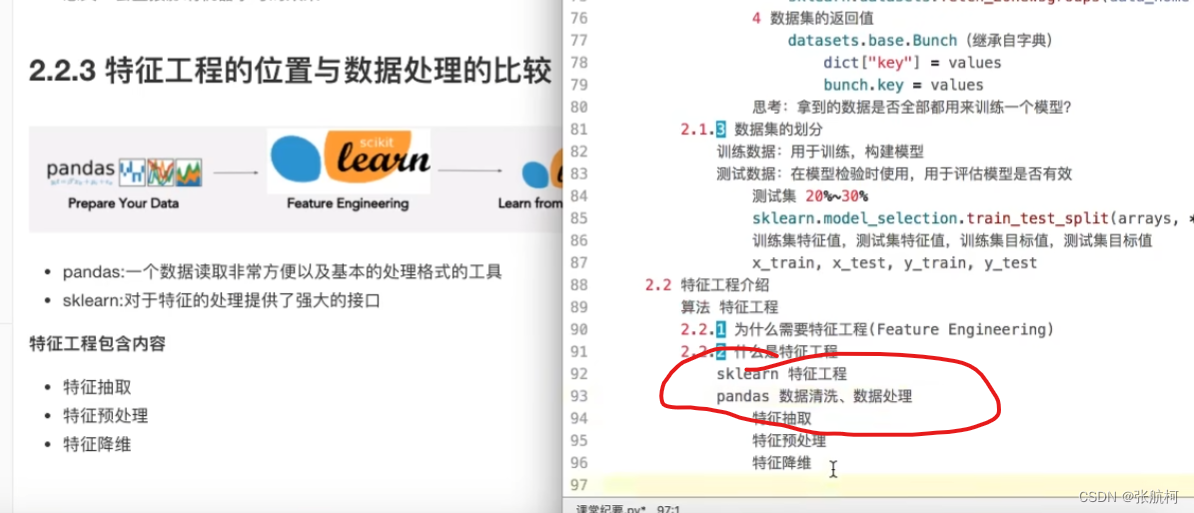
特征抽取介绍
- 概念
机器学习=统计方法=数学公式
前提(转换成算法需要的数值):
文本=》数值
类型=》数值

1.字典特征提取方法(存储方式)



转为计算机可认识的:
矩阵 matrix 二维数组
向量: vector 一维数组
- 案例
矩阵和稀疏

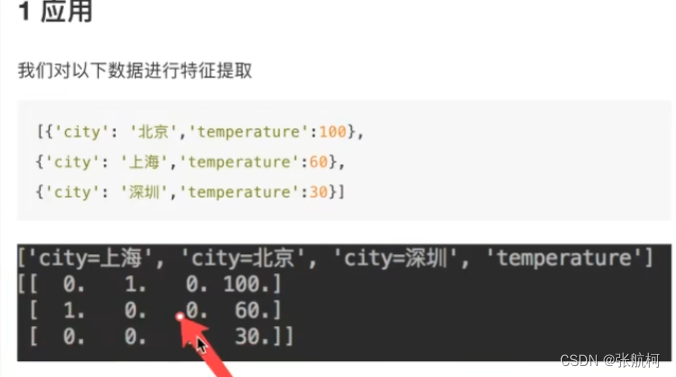
from sklearn.feature_extraction import DictVectorizerdef dict_demo():"""字典特征提取"""data = [{'city': '北京', 'temperature': 100},{'city': '上海', 'temperature': 60},{'city': '深圳', 'temperature': 30}]# 1. 实例化一个转换器类transfer = DictVectorizer()# 2. 调用fit_transform()进行数据转换data_new = transfer.fit_transform(data)print("data_new:\n", data_new)return None
if __name__ == "__main__":# 代码2:字典特征提取dict_demo()
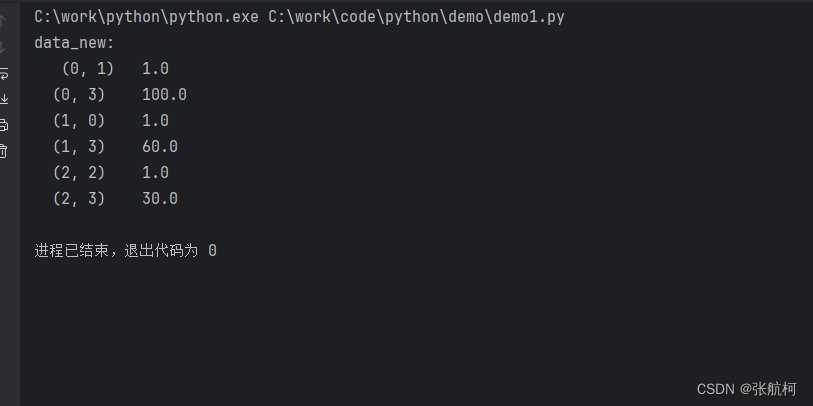
案例对比结果,sparse=True和false的区别就是可以看到括号里面是第二列非0的坐标和值
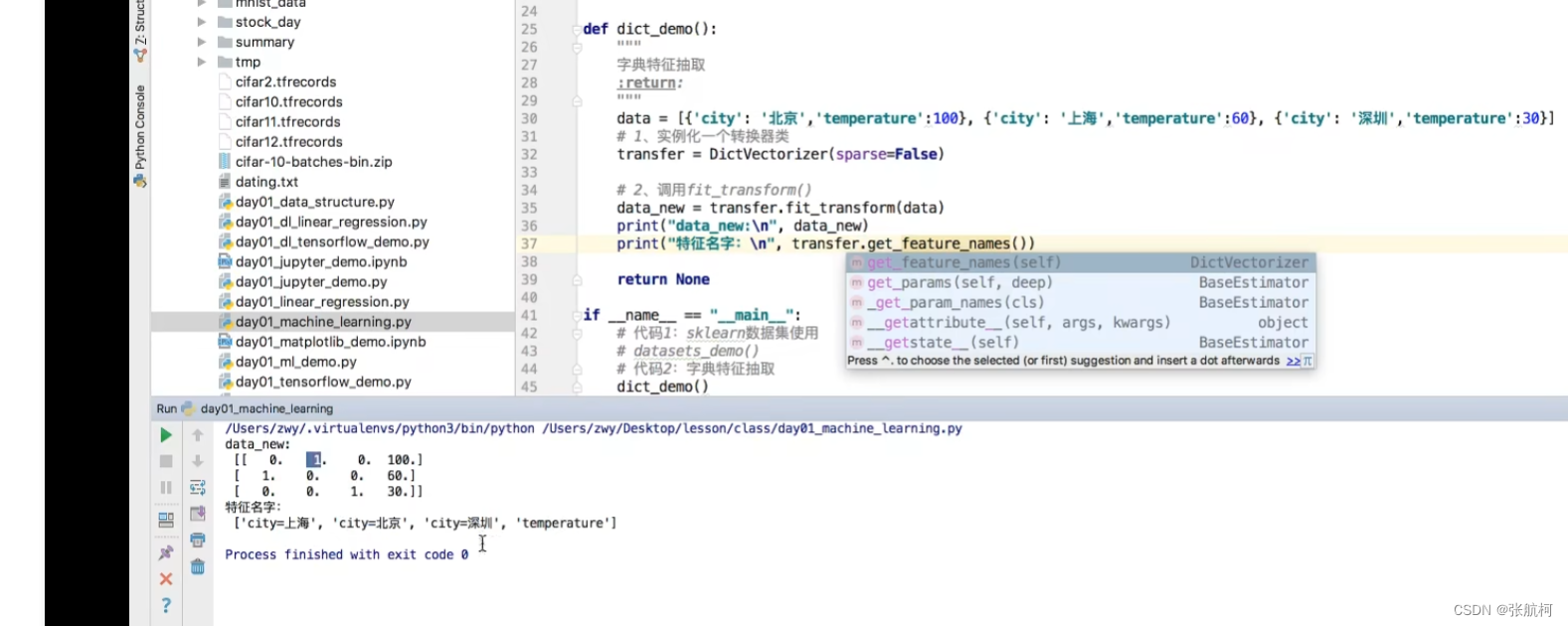
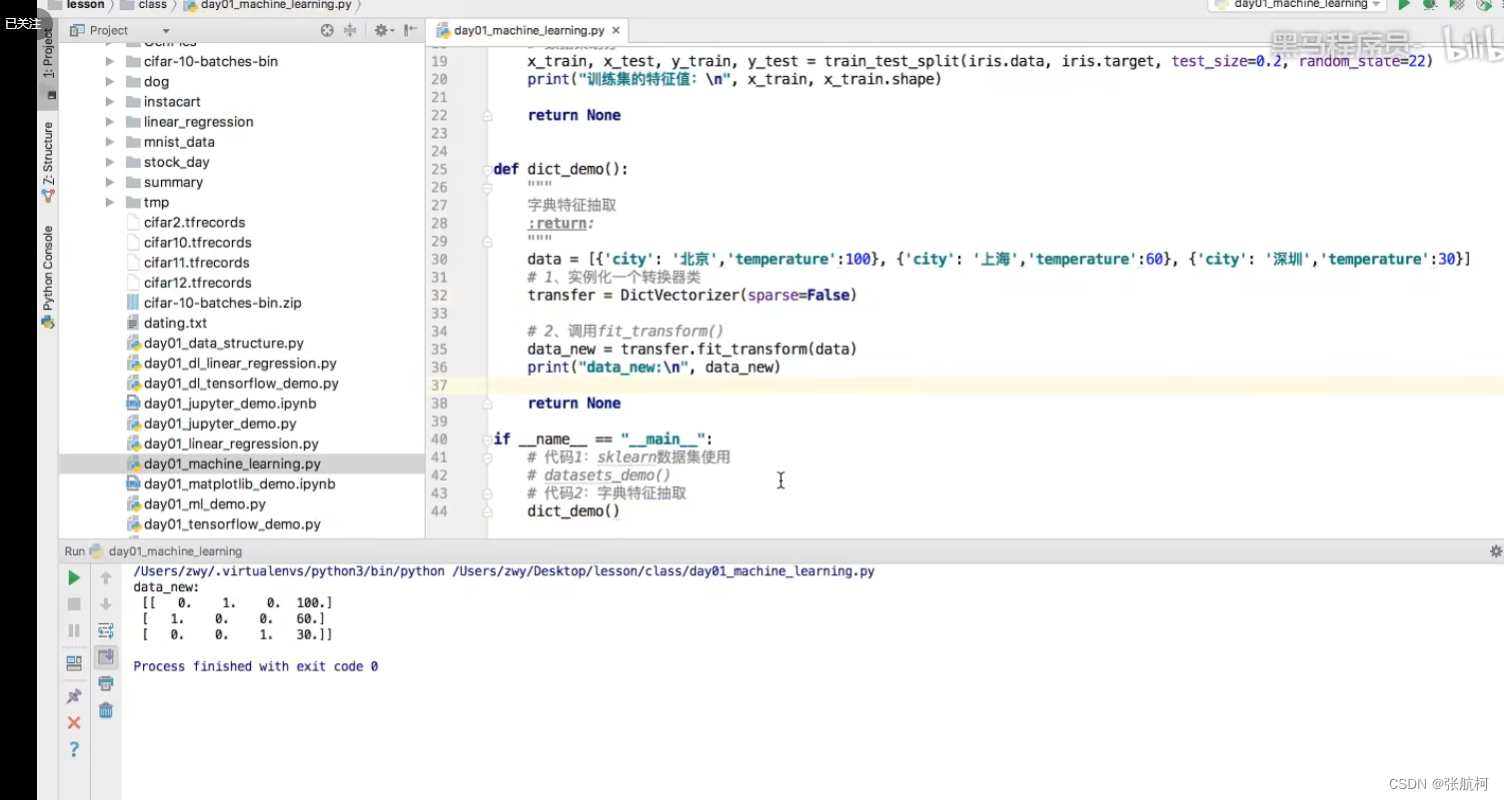
这边是竖着看,如果是上海的话就是1其他都为0,如果是北京的话就是1其他都为0
2. 文本特征抽取(次数)

stop_words是停用词,就是类似i不计入数字

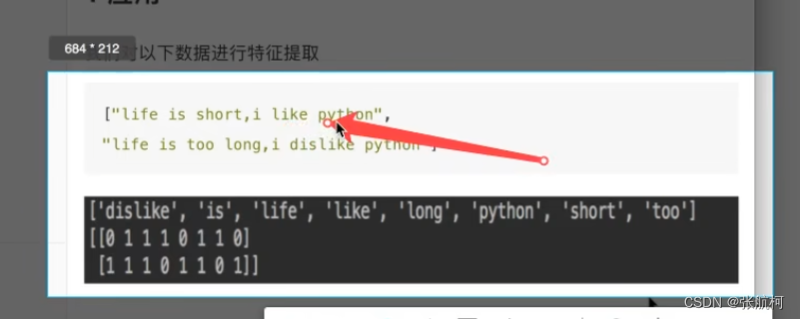
标点符号不作为特征词,还有单个i也不作为特征词,意义不大,同字典一样的0和1
- 案例
转换成矩阵

停用词

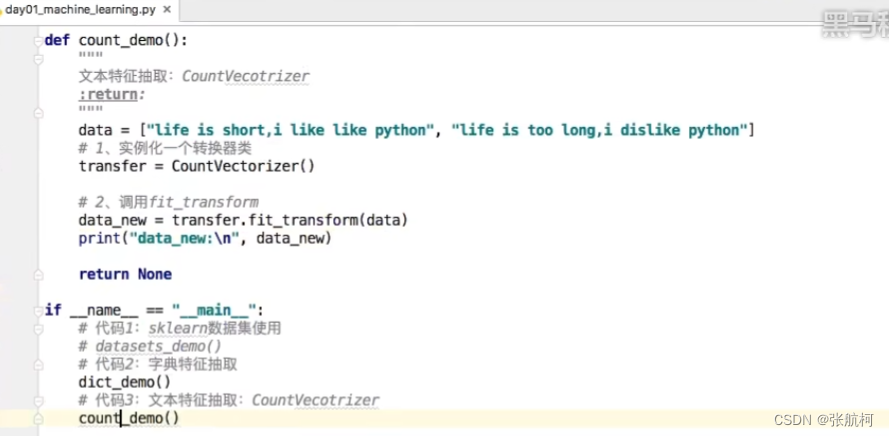
统计特征词出现的个数
主语中文需要空格隔开单词,否则都是按照语句进行划分的
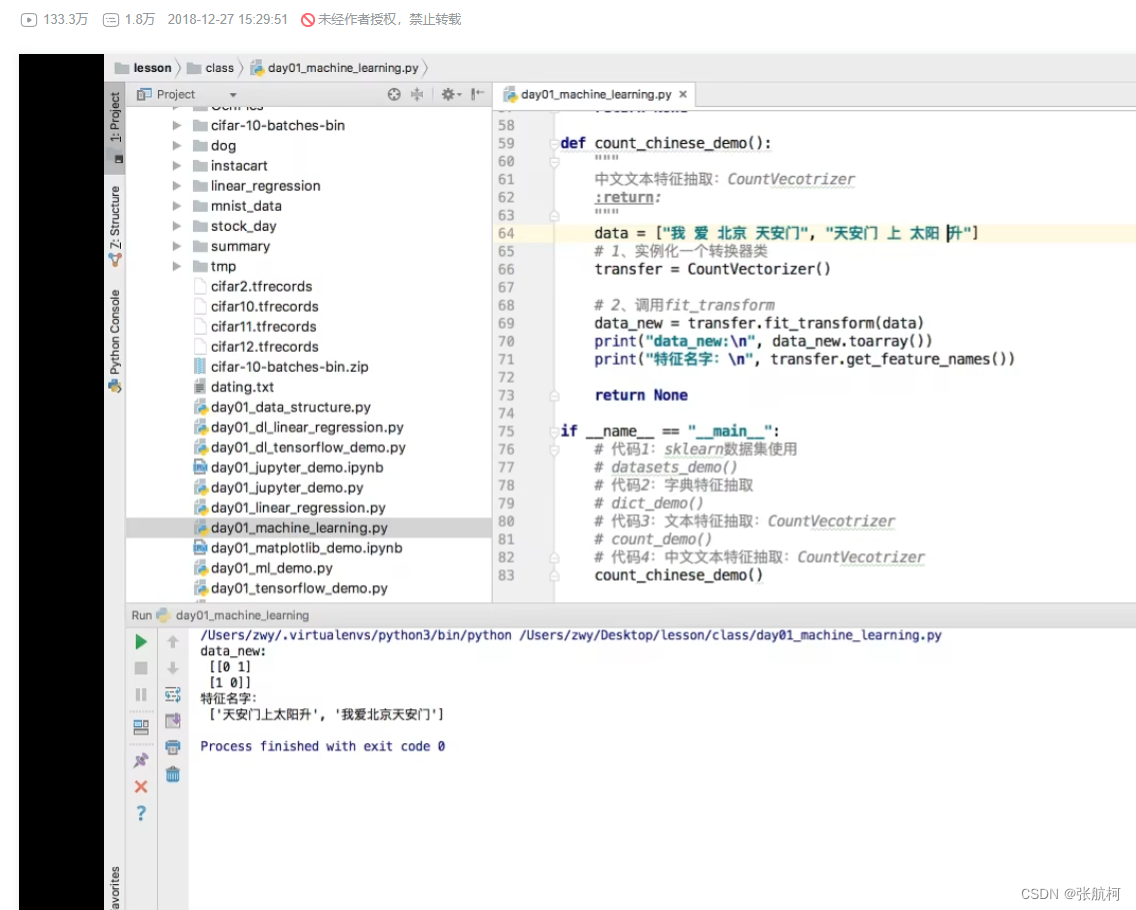
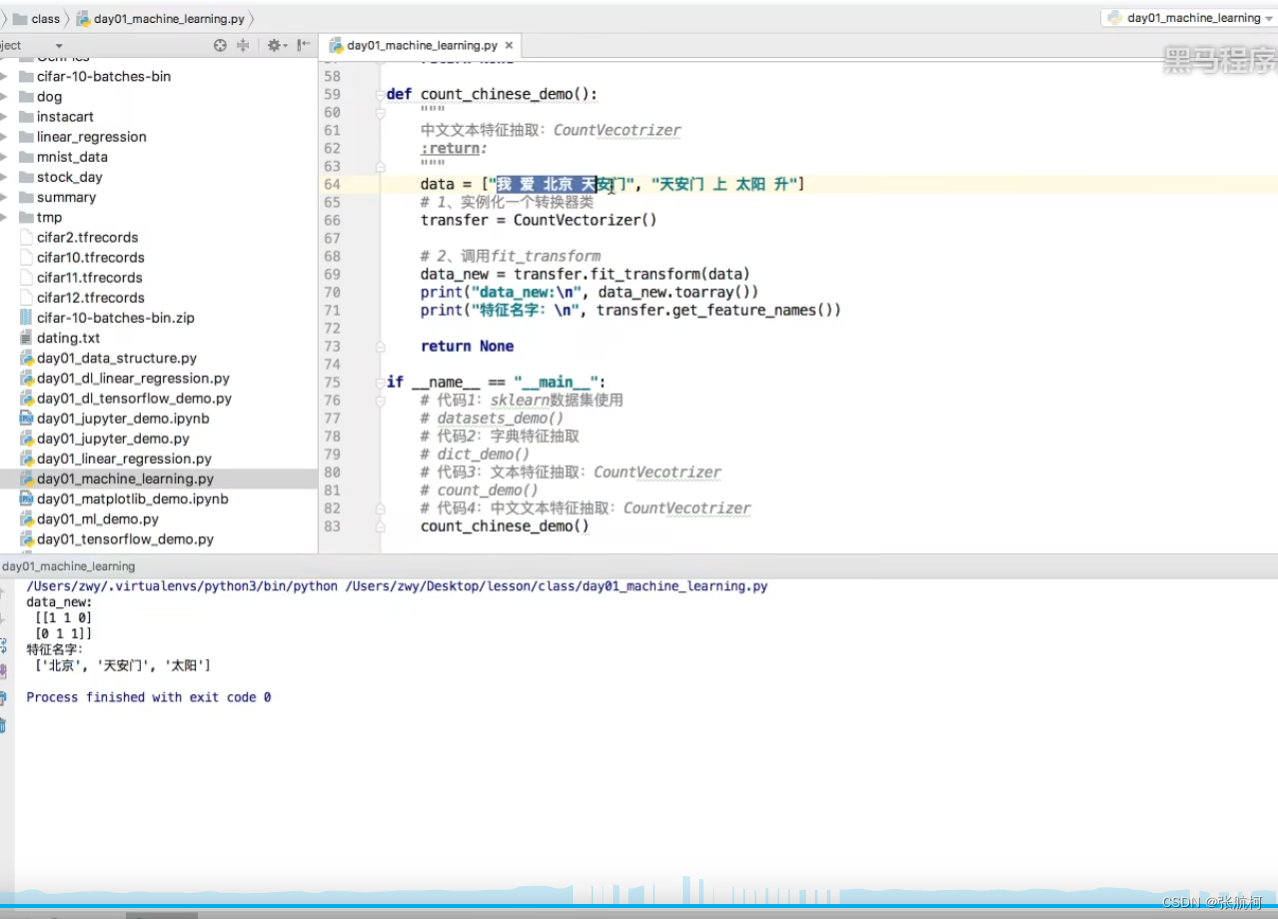
- 中文抽取案例
安装
pip install jieba

导入
import jieba
使用
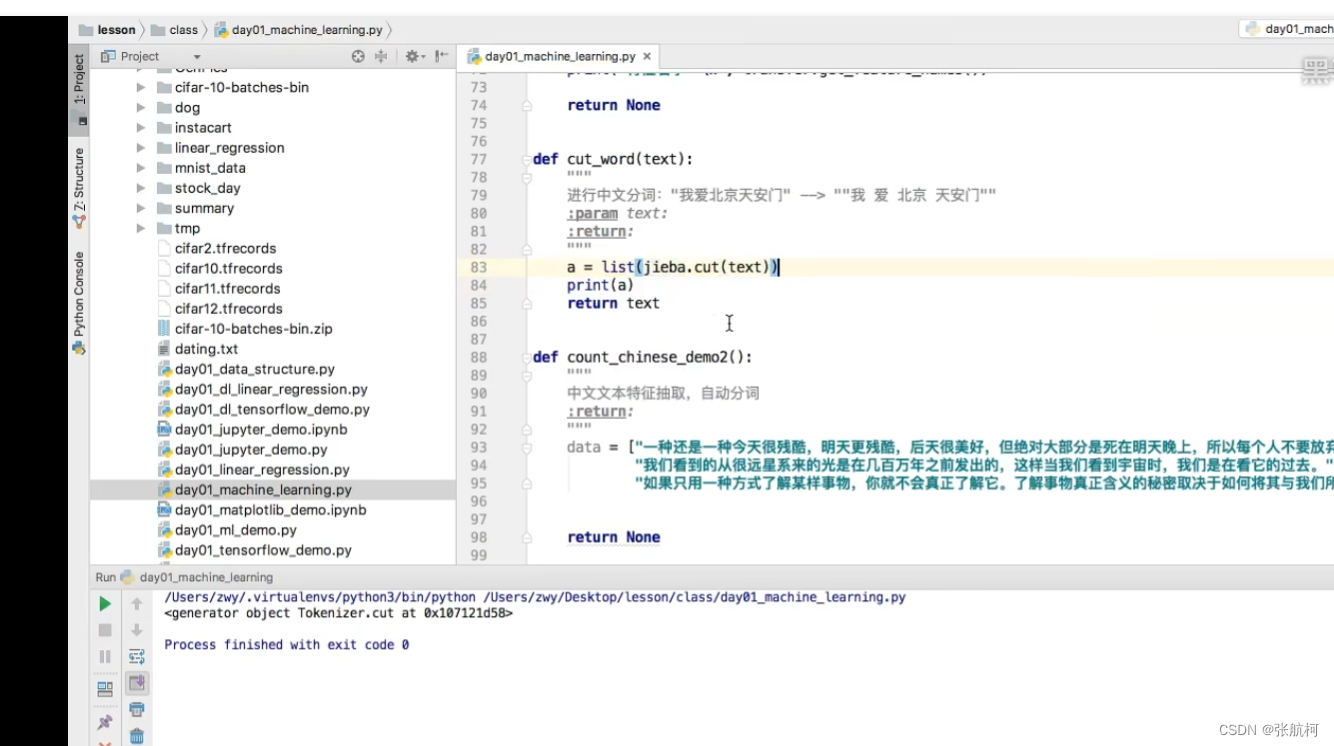
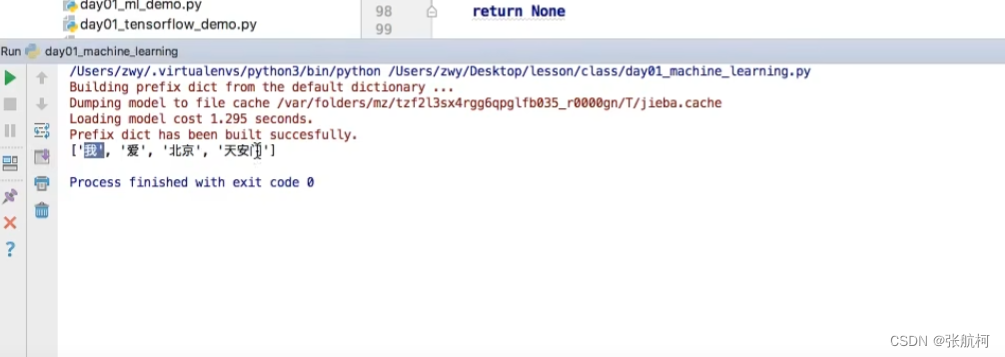
转换成我们想要的结果(字符串)

然后按照单词中的进行特征提取就行了
3. Tf-idf文本特征抽取(文本归类)
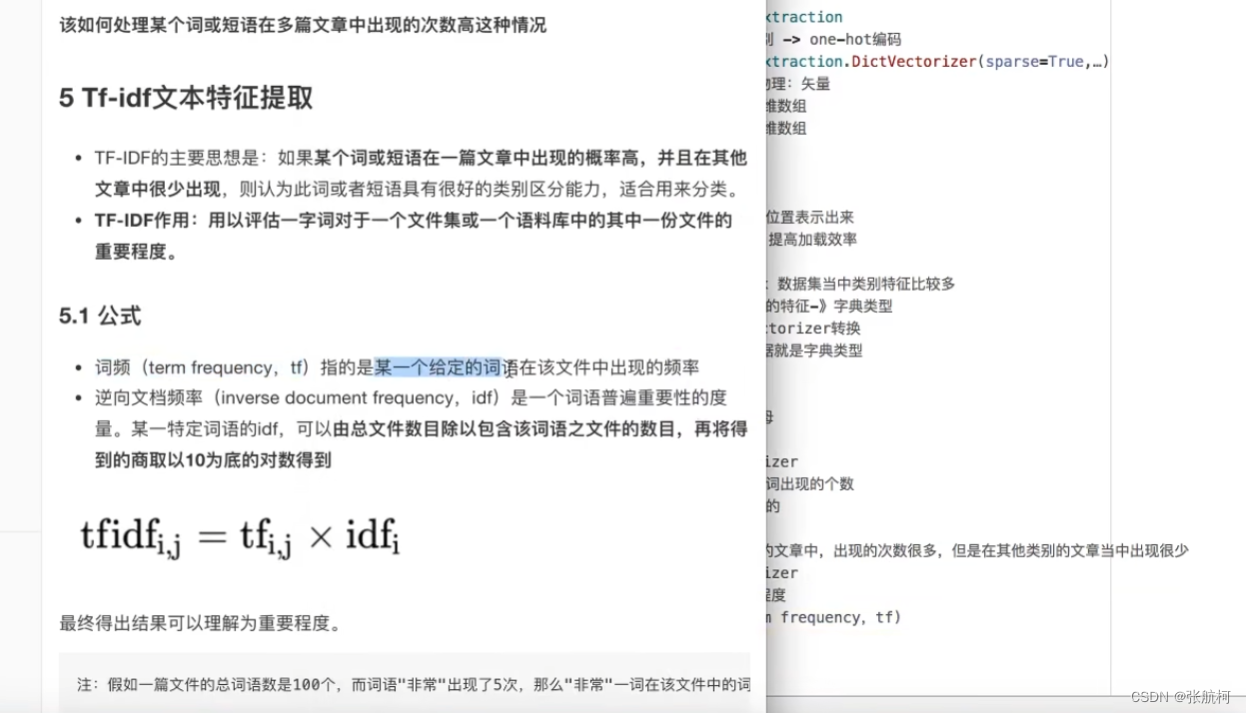
例子理解
- 现在有1000篇文章
- 100篇出现了‘非常’
- 10篇出现了‘经济’
抽取出两篇 - 文章a(1000字):11次经济 TF-IDF:0.022
tf:11/1000 = 0.011
idf: lg 10 1000/10 = 2 - 文章b(1000字):12次非常 TF-IDF:0.012
tf:12/1000 = 0.012
idf: log 10 1000/100= 1
tf:单文章中出现次数/文章字数
idf:lg 10 (总篇数/出现篇数)
结果:tf x idf
所以经济较为重要

- 案例

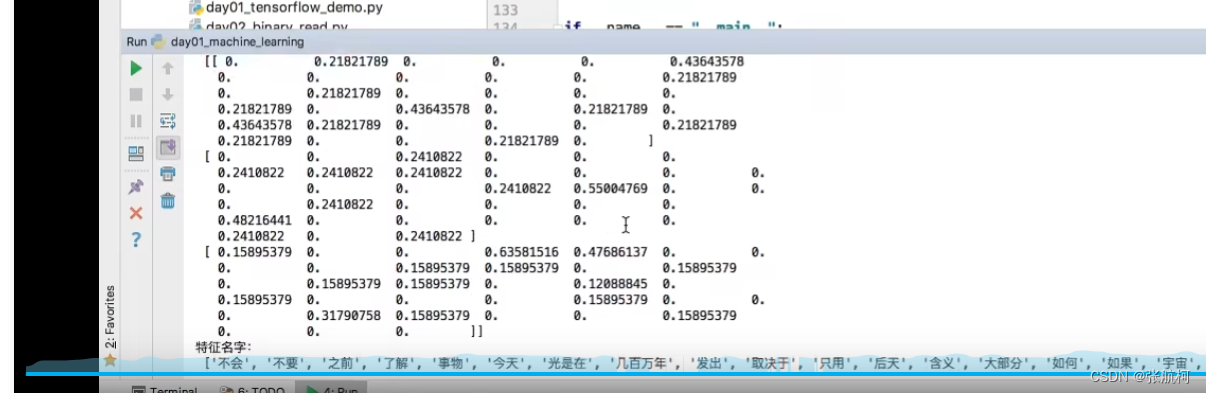
2.4特征预处理
通过一些函数将特征数据转换成更加适合算法模型的特征数据过程
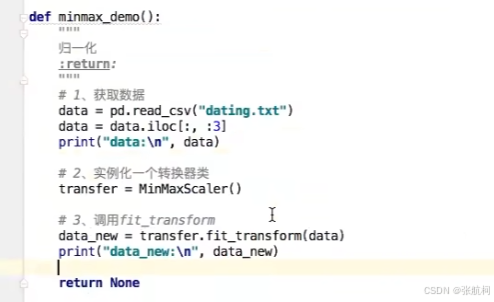
1. 归一化(数据差别大,都统一调小参数,多方面考虑然后评定)
例如路线轨迹,很多数据,其中两点之间很接近,所以就需要归一化
无量纲化:例如下面评价有相对应的计算公式,就是通过里程数+时间耗比 来计算然后得到评价
但是出现问题就是可能时间耗差数据是在0-2区间的,但是里程数是在0-7万之间的所以计算出来的结果是受到里程数干扰的并不是两列进行评估的,所以需要进行归一化去把里程数调小,来评估


示例:其中x是当前数值,mx-mi是你想把数据变为xxx区间,比如0-1区间那么mx就是1,mi为0,就是你结果集的返回值的区间

参数为:几行,几列(特征)

- 案例

- 问题
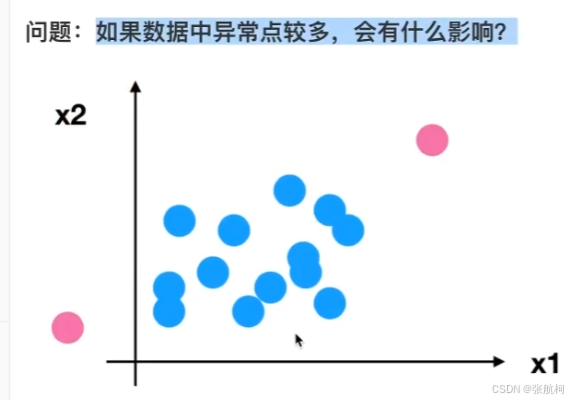
- 归一化总结

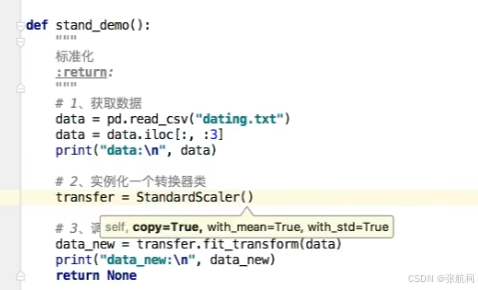
2. 标准化(在归一化的时候进行处理x’,避免最大最小影响数据)
标准化不会被最大值最小值为异常样本所影响,是基于平均数

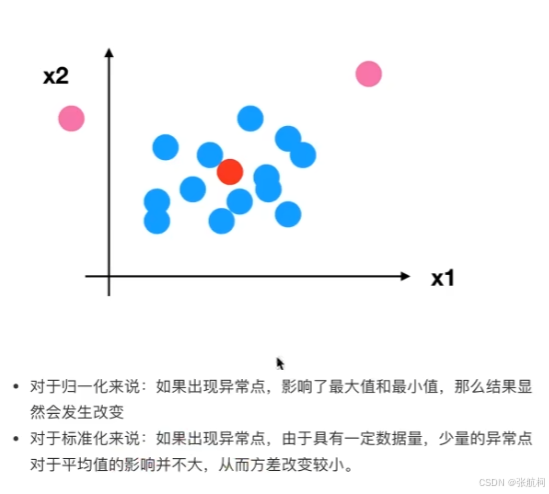

- 案例

2.5 降维

冗余特征,例如鸟,都有爪子,那么数据都是一样的,所以没有意义
有什么公式或者方法自动过滤到冗余特征
1. 特征降维

- 低方位特征过滤(单个数据值波度上涨下降都比较平缓)

– 案例

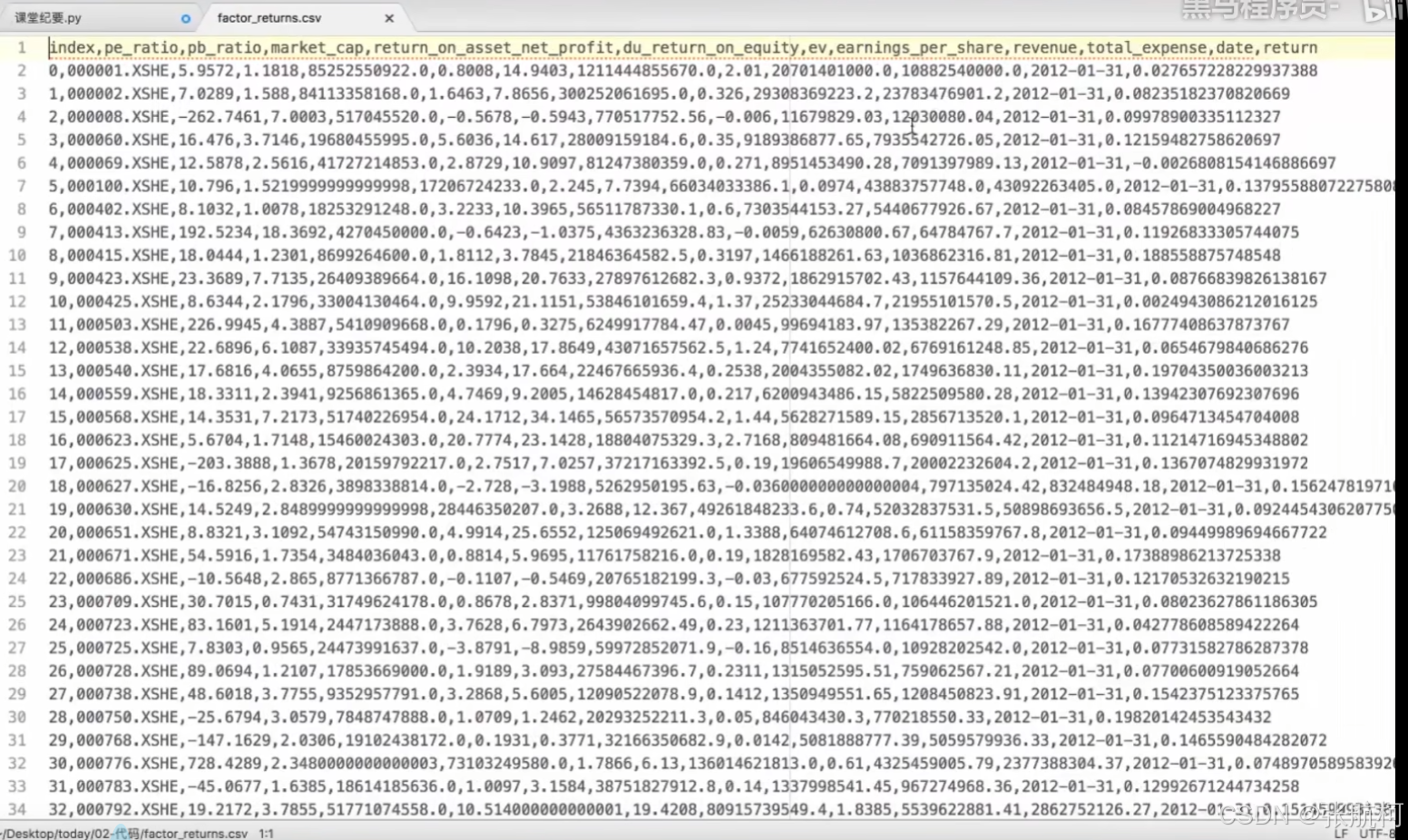
代码

- 相关系数(两个特征值都接近)

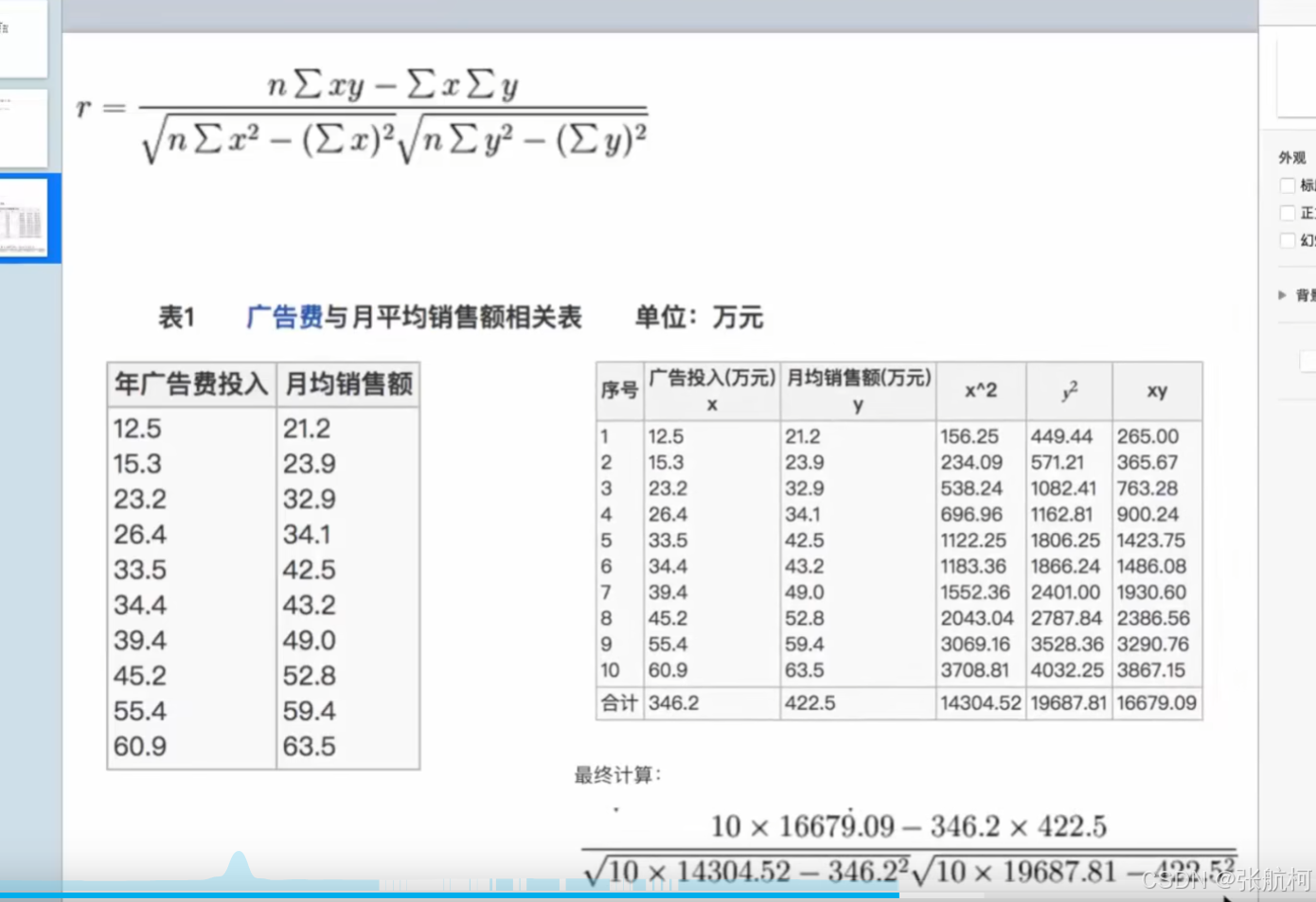


如果结果是正数,那么就是正相关,一个数值在增加,另外一个也在增加
如果结果是负数,那么就是负相关,一个数值在减少,另外一个也在减少
– 案例



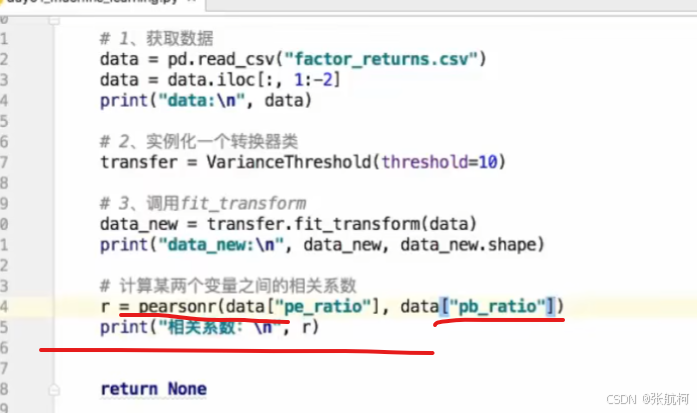

这个前面的负数就是相关系数
也可以通过散点图去观察
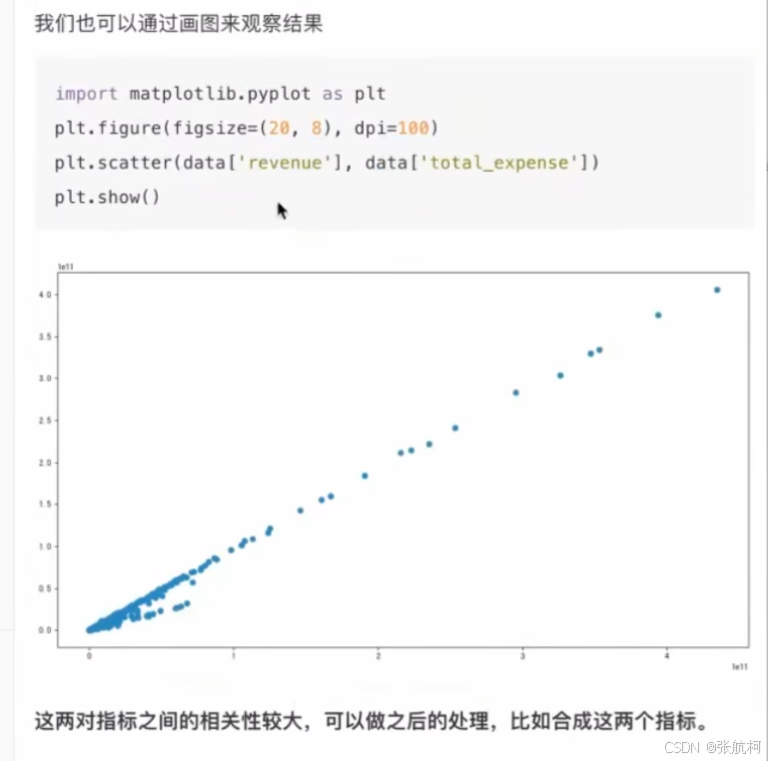
相关性很强如何处理???
加权求和就是,取比例占多少。

2 主成分分析
pca在做的事情就是以最少损失信息进行降为


- 计算案例(降维尽量减少数据的损失)
例如二维坐标中,降维成为一维的数据如何处理。
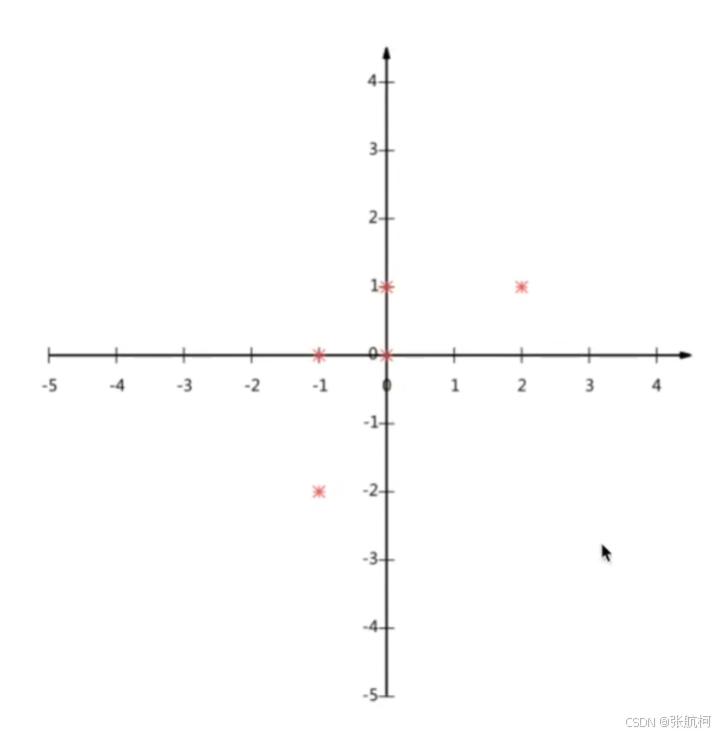
==错误演示:==原本五个点现在要成为了6个点所有降维不好
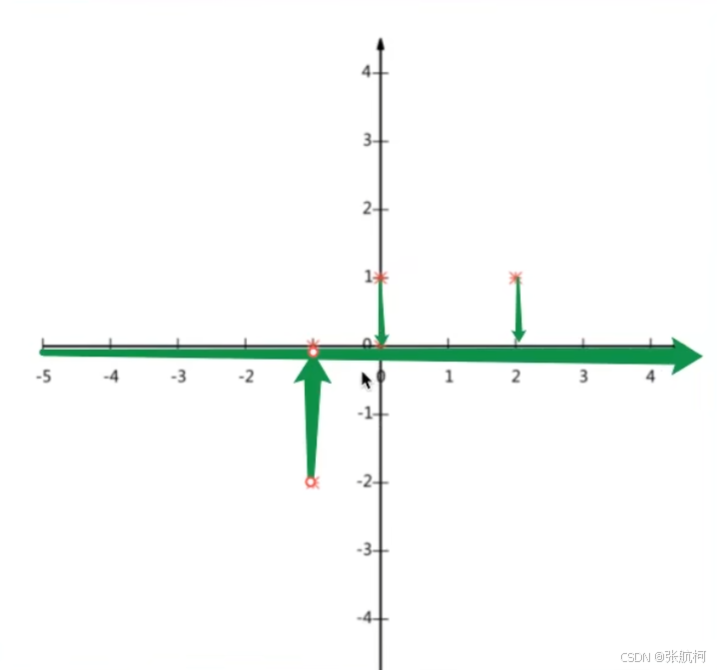
正确示例
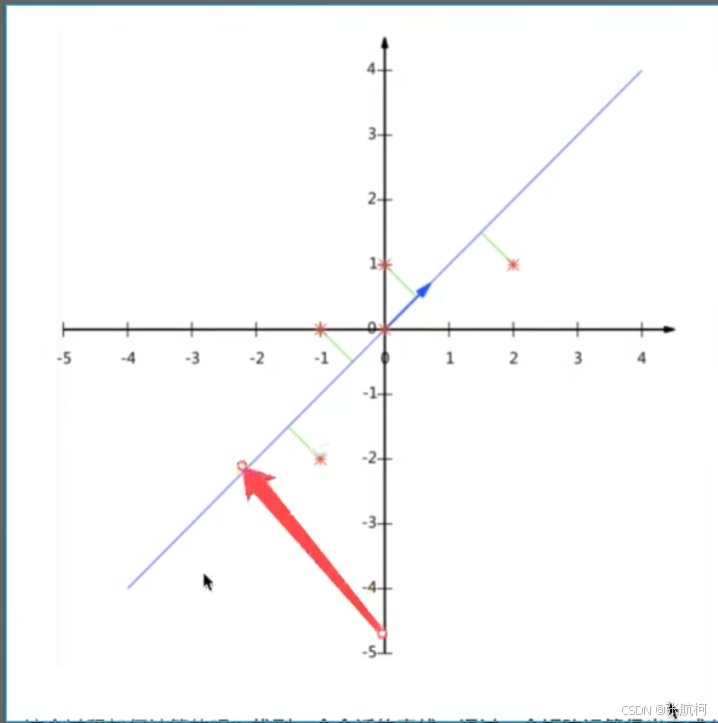
这个过程如何计算?

- api接口

示例

2是降维2维数组
传小数还是二维特征,就是保留多少信息比如95%就是0.95

降低3维

3. 案例-instacart降维案例
- 案例

1分析–合并
2找到用户和类别-交叉表和透视表
3特征冗余过多-》PCA降维度
需要将用户id和商品类别放到一张表中
下图中列为类别名称,也就是商品分类名称userid为2的,购买了asian foods的商品3次,下面数据太多0了需要进行第三部
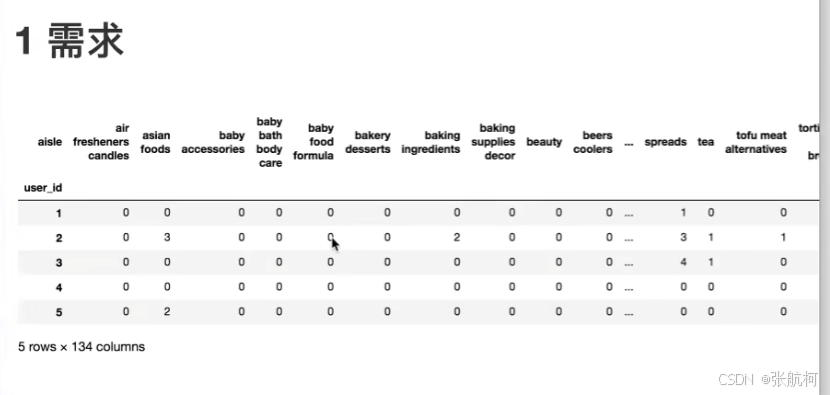
- 代码实现
1. 获取数据源
2. 合并表

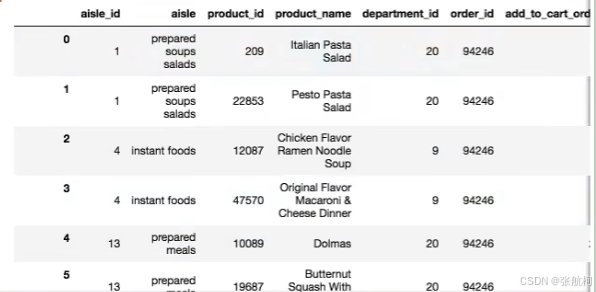
3. 交叉数据
只看画横线的结果,不用看14的输出因为是上个步骤的具体数据看下面。
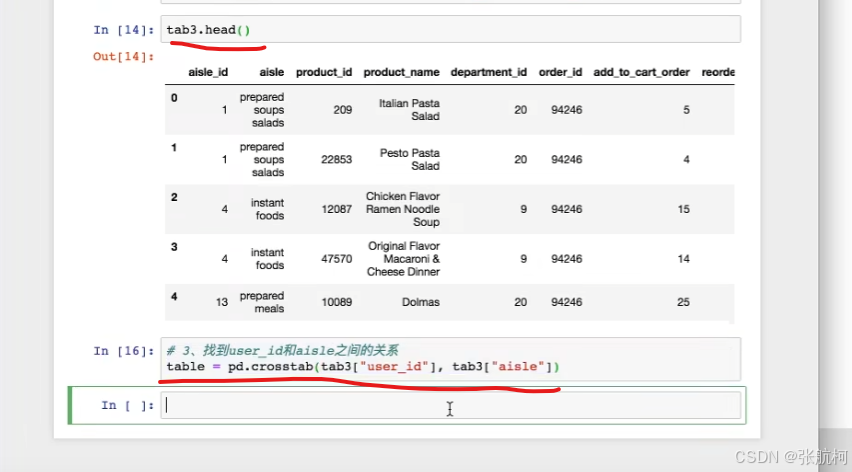
结果
4.降低维度
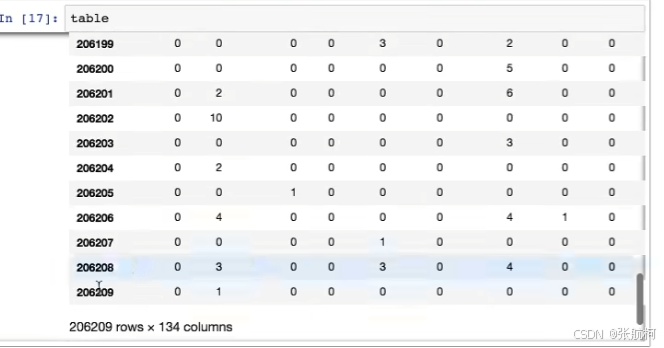
.shapt是形状,原本134个特征降为到42个特征了,还保留了95%的特征
可以看到大量代码都是在做数据处理工作实际降维就那么1到2行代码
三、分类算法
3.1 sklearn转换器和估计器
1. 转换器
- 介绍


2. 估计器
- 介绍

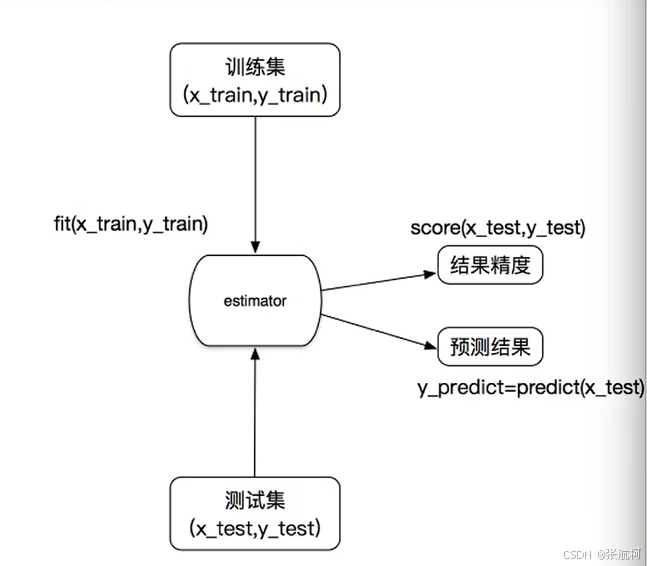
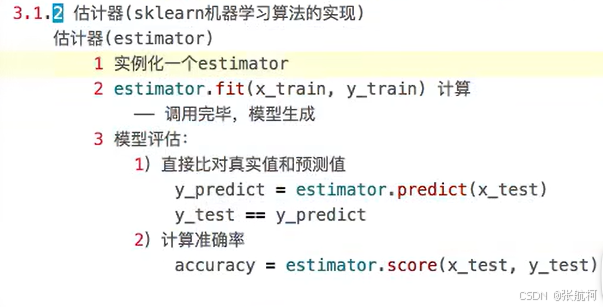
下面是ai的说明
3. K-近邻算法

介绍:又名KNN算法,例如:根据你的邻居推断出来你的所属区域(类别)
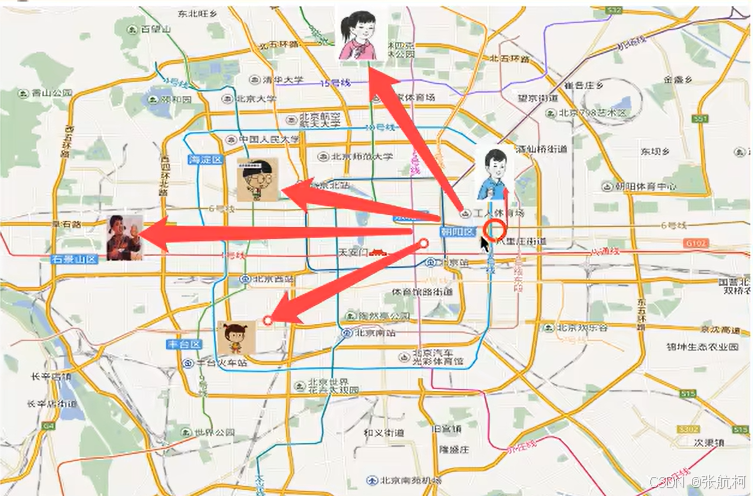
原理: k的取值,比如1的话就找周边一个最近的,2的话就找两个最近的样本进行评估
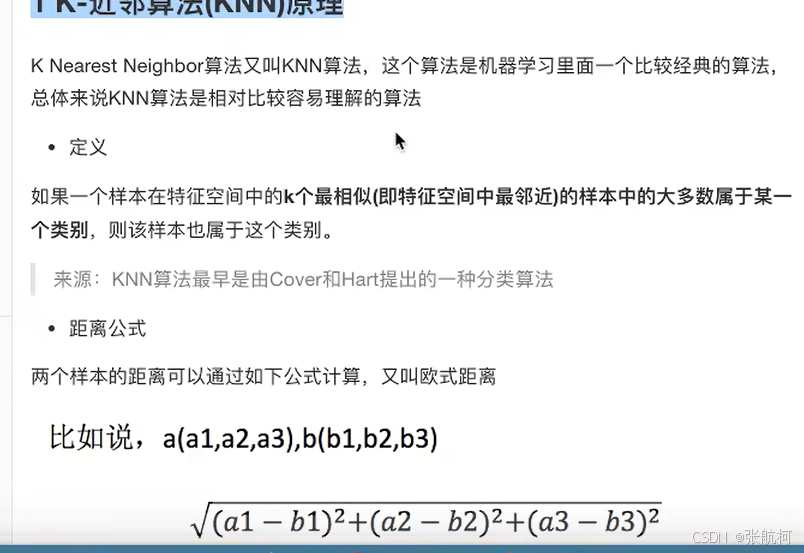
核心思想:

案例解析
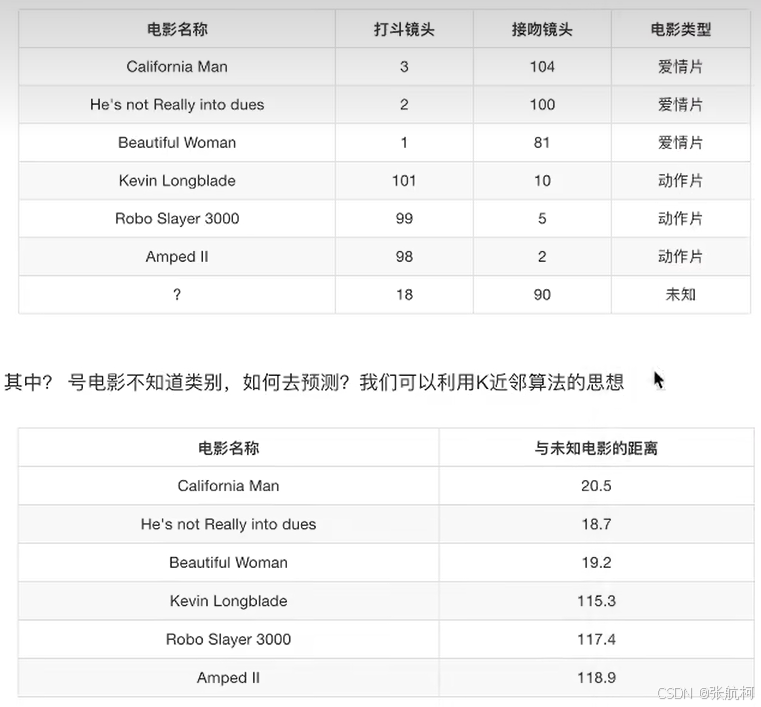
- 现在需要根据k去分出来未知电影的定位

上图中的无量纲化,就是值电影中的爱情和打斗进行无量钢化一下进行评估。
4. api

上图中的的一个参数就是3中提到的k值,取多少条临近数据进行分析
第二个参数是排序,auto是自动选择排序手段,无需担心
案例

代码
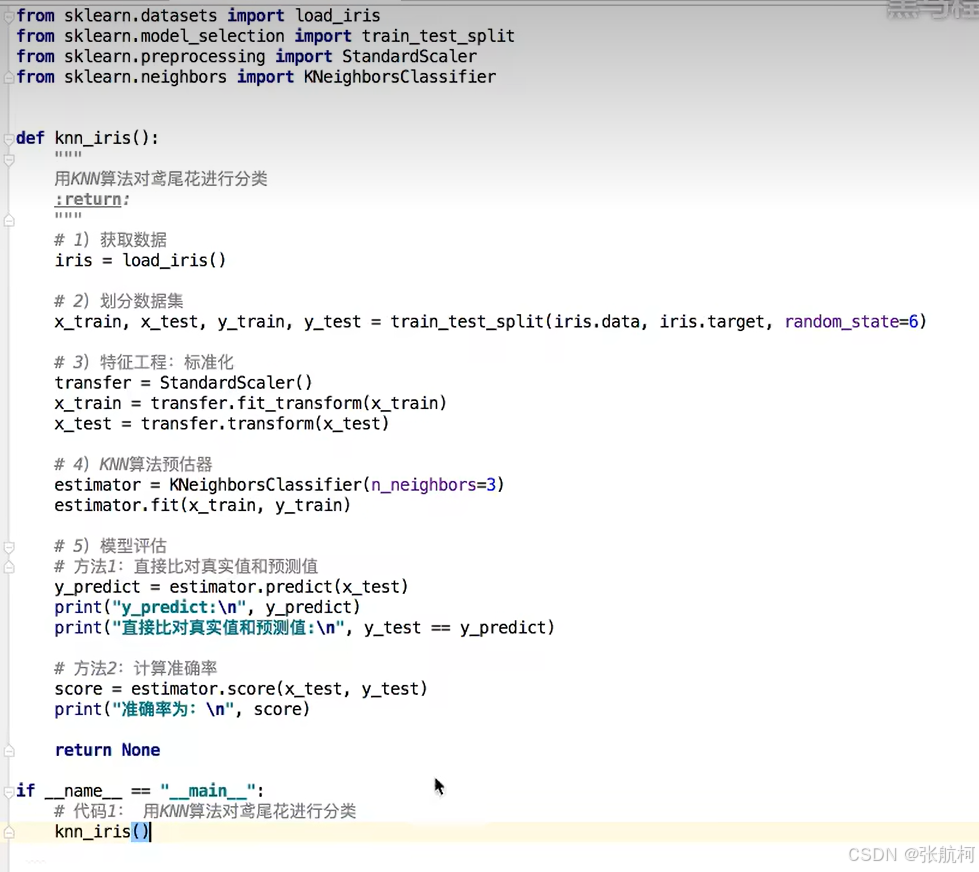
输出
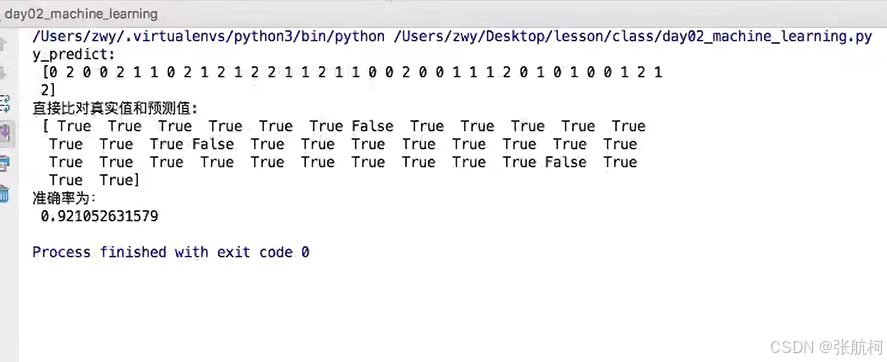
改变K值3就会影响准确率,随着数据多少进行判断
5. 优缺点+结果分析

3.2 模型选择和调优

1. 交叉验证
同一份数据的话,那么分成4份然后计算,哪个作为测试数据,这个定义可以更改比如,第一轮a是训练数据,第二轮就是可以设置为测试数据
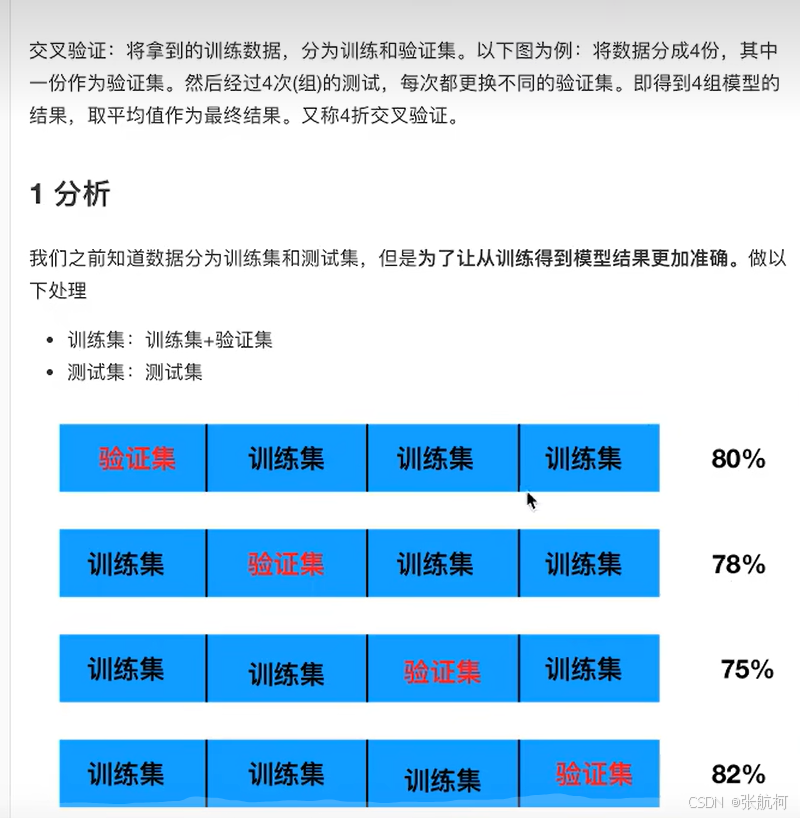
为什么要做交叉验证原因
为了得到更准确
3.3 超参数搜索-网格搜索
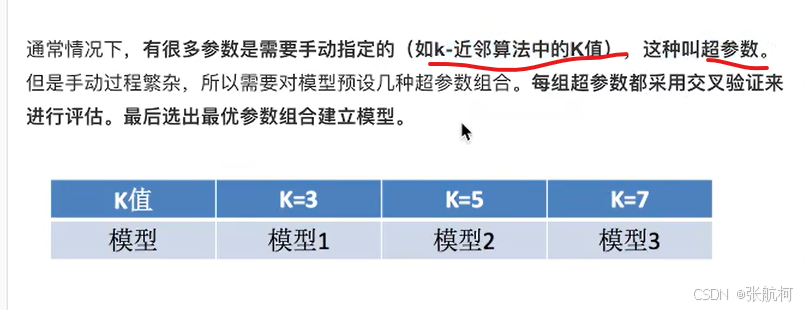
1.api介绍
比如现在要对k-n算法进行加上网格搜索
第一个参数:k-预估器
第二个参数:k的取值,例如1或者3或者5
第三个参数:几次交叉验证(数据集分为训练集和验证集和测试集)
案例
花的案例和增加k值调优


基于花的案例进行处理更改
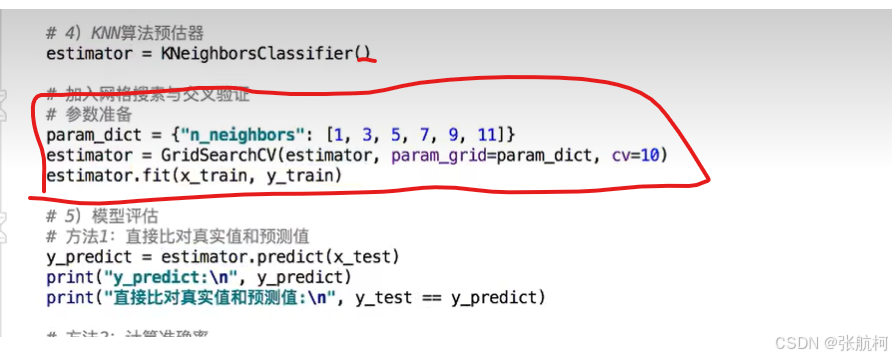

拓展
入口

源码中
p=1的话采用的=》曼哈顿距离
p=2的话采用的=》欧式距离
3.4 案例:facebook签到位置

上文参数介绍:
第一个:签到id(无关紧要)
第二个:签到的坐标
第三个:gps
第四个:时间
第五个:预测位置

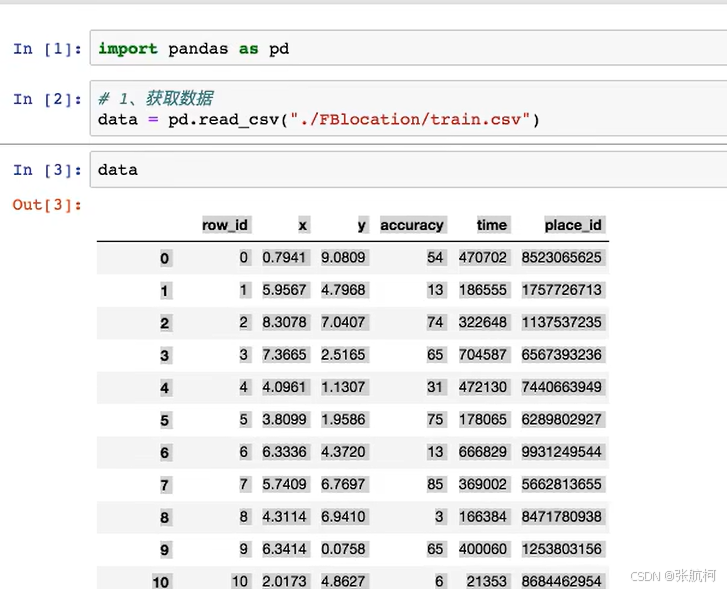
分析
-
获取数据
-
数据处理
目的:
特征值
目标值
a.缩小数据范围
2<x<2.5之间的数据
1.0<y<1.5之间的数据
b.time-》年月日时分秒
c.过滤签到次数少的地点
d.数据集划分 -
特征处理:标准化
-
knn算法预估流程
-
模型选择和调优
-
模型评估
代码实现
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCVif __name__ == '__main__':# 1获取数据data = pd.read_csv(r"C:\Users\20350\Desktop\xxx.csv")# 2基本数据处理# 1)缩小数据范围data = data.query("x < 2.5 & x > 2 & y < 1.5 & y > 1.0")# 2)处理时间特征time_value = pd.to_datetime(data["time"], unit="s")date = pd.DatetimeIndex(time_value)data["day"] = date.daydata["weekday"] = date.weekdaydata["hour"] = date.hour# 3)过滤签到时间比较少的place_count = data.groupby("place_id").count()["row_id"]row_ids = place_count[place_count > 3]data_final = data[data["place_id"].isin(row_ids.index.values)]x = data_final[["x","y","accuracy","weekday","hour"]] # 我们需要的值y = data_final["place_id"] # 结果输出的值# 数据集划分x_train, x_test, y_train, y_test = train_test_split(x,y)# 特征工程化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# KNN算法预估器estimator = KNeighborsClassifier()# 加入网格搜索和交叉校验# 参数准备param_dict = {'n_neighbors':[3,5,6,7,9]}estimator = GridSearchCV(estimator, param_grid = param_dict, cv=3)estimator.fit(x_train, y_train)# 模型评估# 方法1: 直接比对真实值和预测值y_predict = estimator.predict(x_test)print("y_predict 预测的结果", y_predict)print("比对预测值", y_test == y_predict)# 方法2: 计算准确率score = estimator.score(x_test, y_test)# 最佳参数print("最佳参数", estimator.best_params_)# 最佳结果print("最佳结果", estimator.best_score_)# 最佳估计算器print("最佳估计器", estimator.best_estimator_)# 交叉验证结果print("交叉验证结果", estimator.cv_results_)
3.5 朴素贝叶斯算法
通过算法计算概率
1. 案例
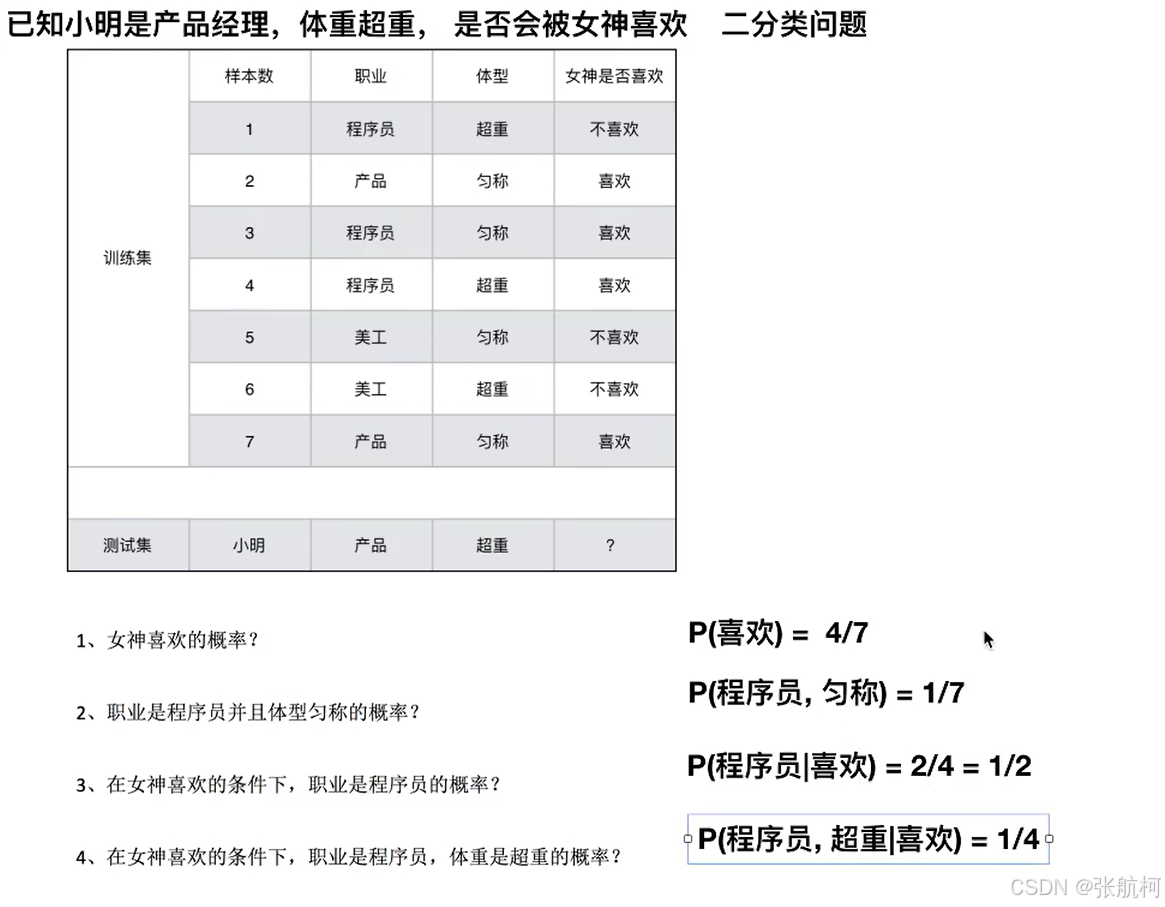
条件概率和联合概率,出现两个条件就是联合概率
联合概率、条件概率与相互独立

不相互匀称

上图计算:12/49!=1/7
2. 公式

计算案例


3. 概述朴素贝叶斯
朴素:
假设:特征与特征之间时相互独立
朴素贝叶斯:
就是朴素+(贝叶斯)公式
主要应用到文本分类,单词作为特征
4. 文章分类计算
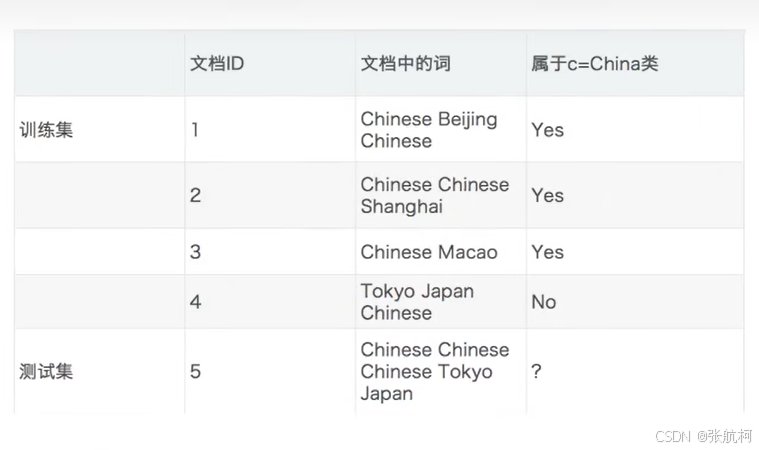
如果测试集那五个词,属于哪个类别

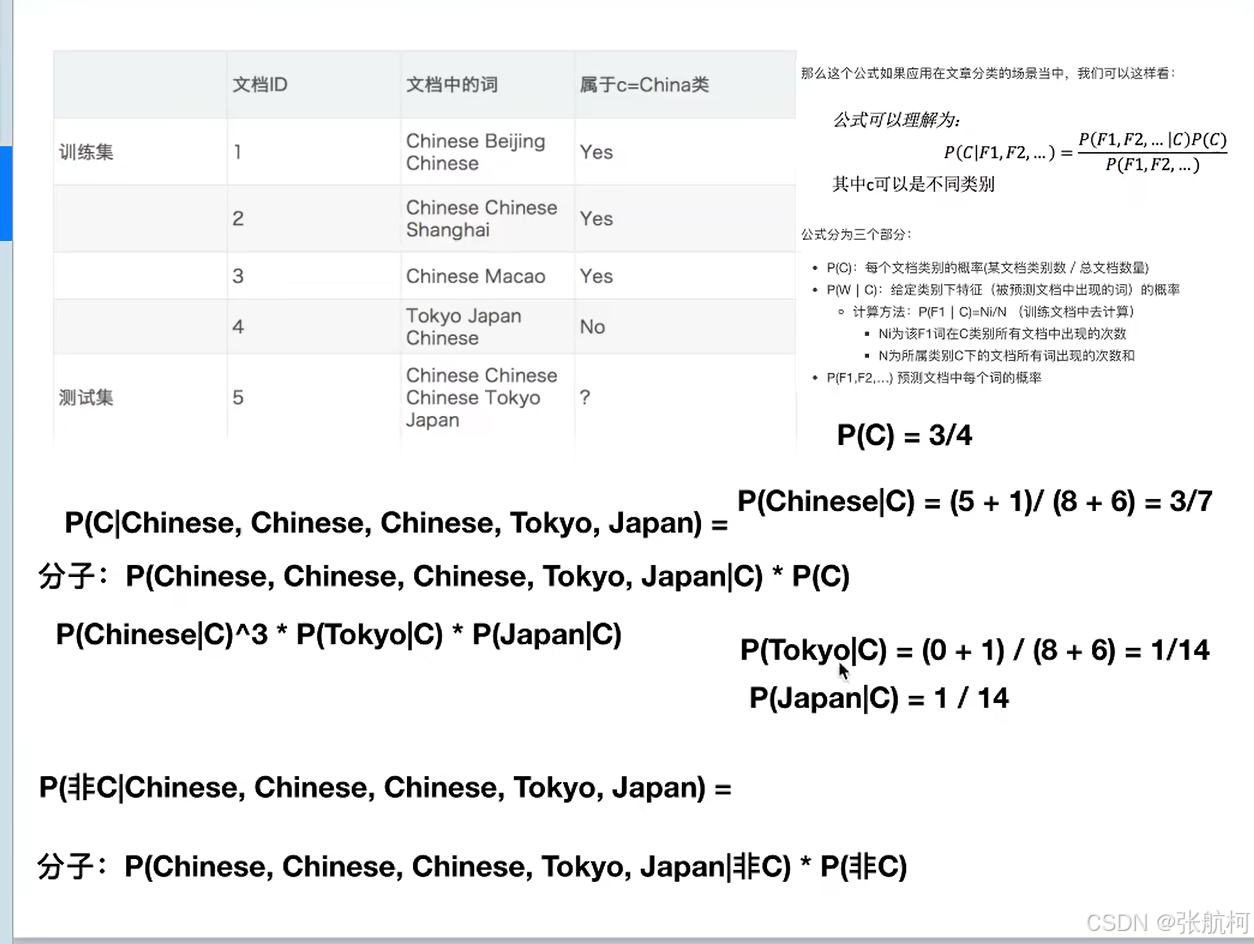
5. api

5. 案例20类新闻分类

- 案例分析
- 获取数据
- 划分数据集
- 特征工程
文本特征抽取 - 朴素贝叶斯预估器流程
- 模型评估
可以调整平滑系数的值
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNBif __name__ == '__main__':# 获取数据news = fetch_20newsgroups(subset="all") # 参数data_home是下载哪个目录下默认home目录# 划分数据集x_train,x_test,y_train,y_test = train_test_split(news.data, news.target)# 特征工程:文本特征抽取-tfidftransfer = TfidfVectorizer()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 朴素贝叶斯算法预估器流程estimator = MultinomialNB()estimator.fit(x_train, y_train)# 模型评估# 方法1 直接比对真实值和预测值y_predict = estimator.predict(x_test)print("y_predict结果", y_predict)print("直接比对真实值和预测值:", y_test == y_predict)# 方法2:计算准确率score = estimator.score(x_test, y_test)print("准确率",score)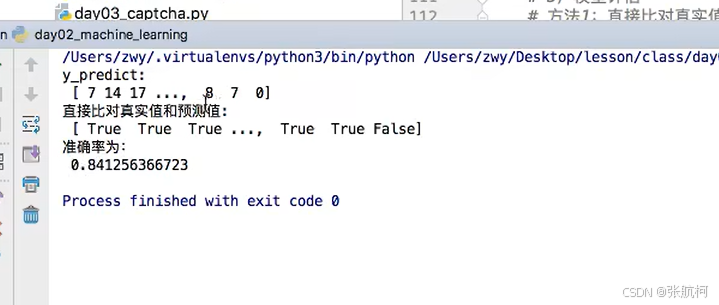
6. 总结

一篇文章丢失几个单词也没关系不影响分类
缺点:比如当出现了我爱北京天安门那么你把北京天安门分开又不一样了
3.6 决策树
1. 认识决策树
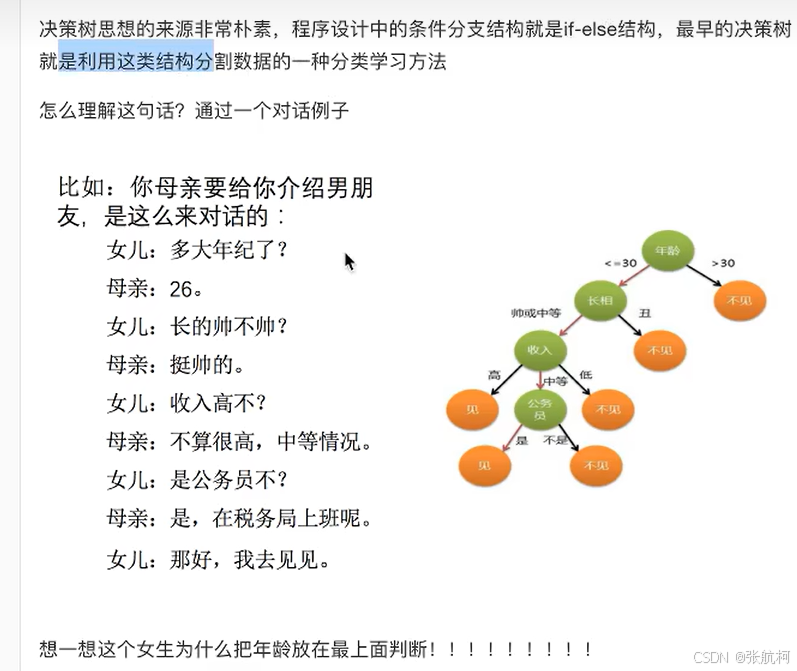
- 如何高效的进行决策? -------》特征的先后顺序
2. 决策树原理详解
- 例子:
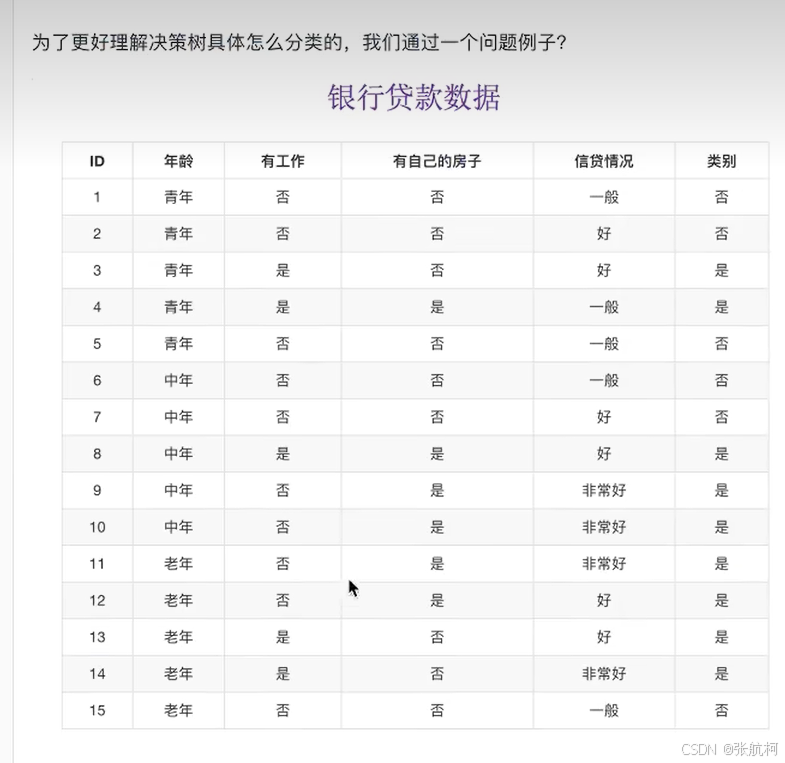
问题:对客户进行划分预测,判断是否贷款给这个人
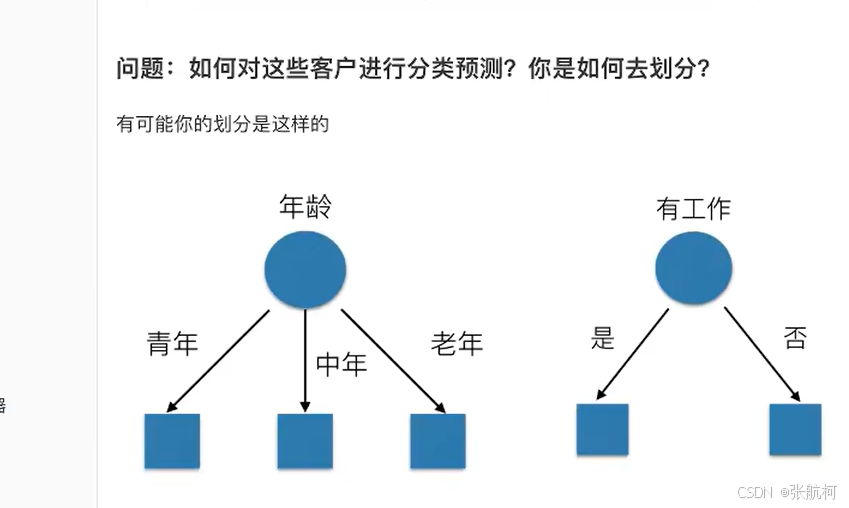
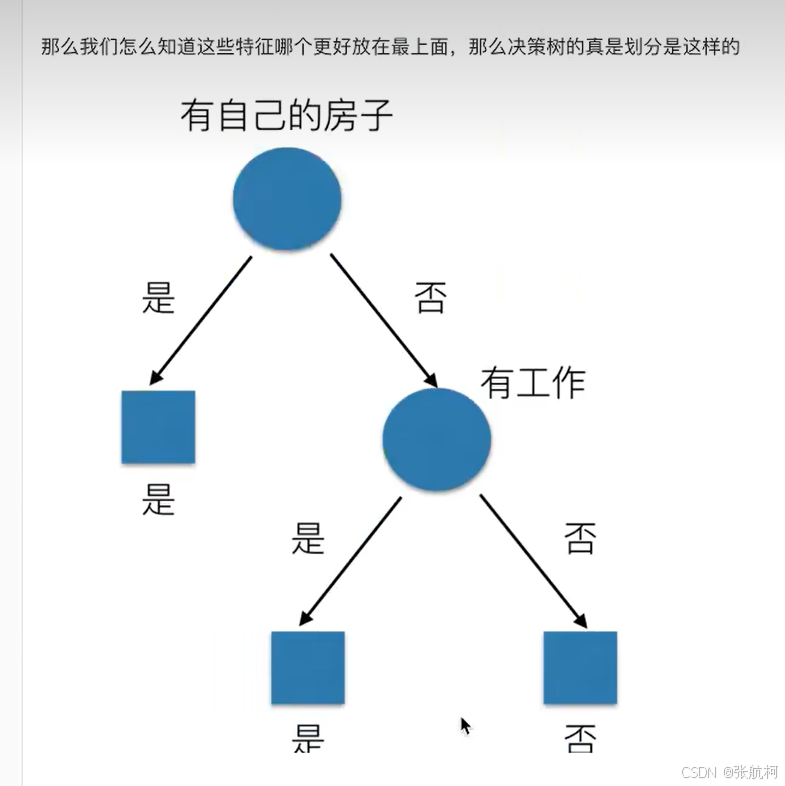
原理
- 信息熵、信息增益等
3. 信息熵的定义

例子:
香农:消除随机不定性的东西
小明 年龄 “我今年18岁”-信息
小花 “小明明年19岁” -不是信息
根据例子理解公式,还是拿2买房为例子
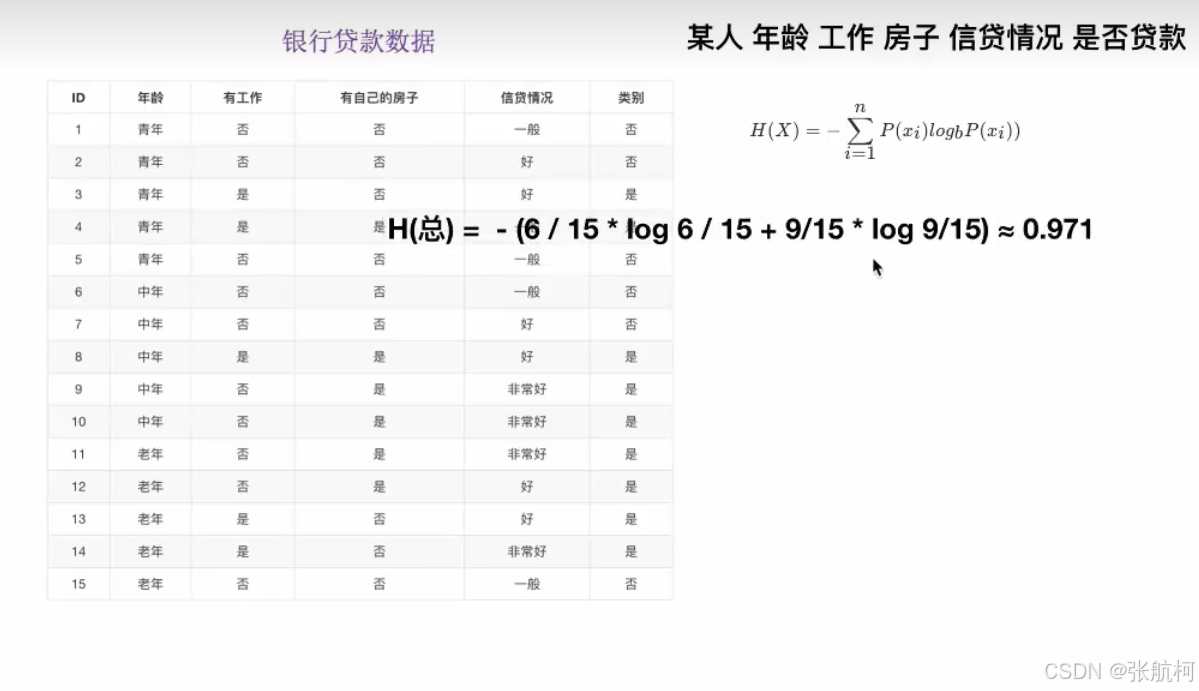
4. 决策树划分之一--------信息增益
- 定义与公式


举个例子理解
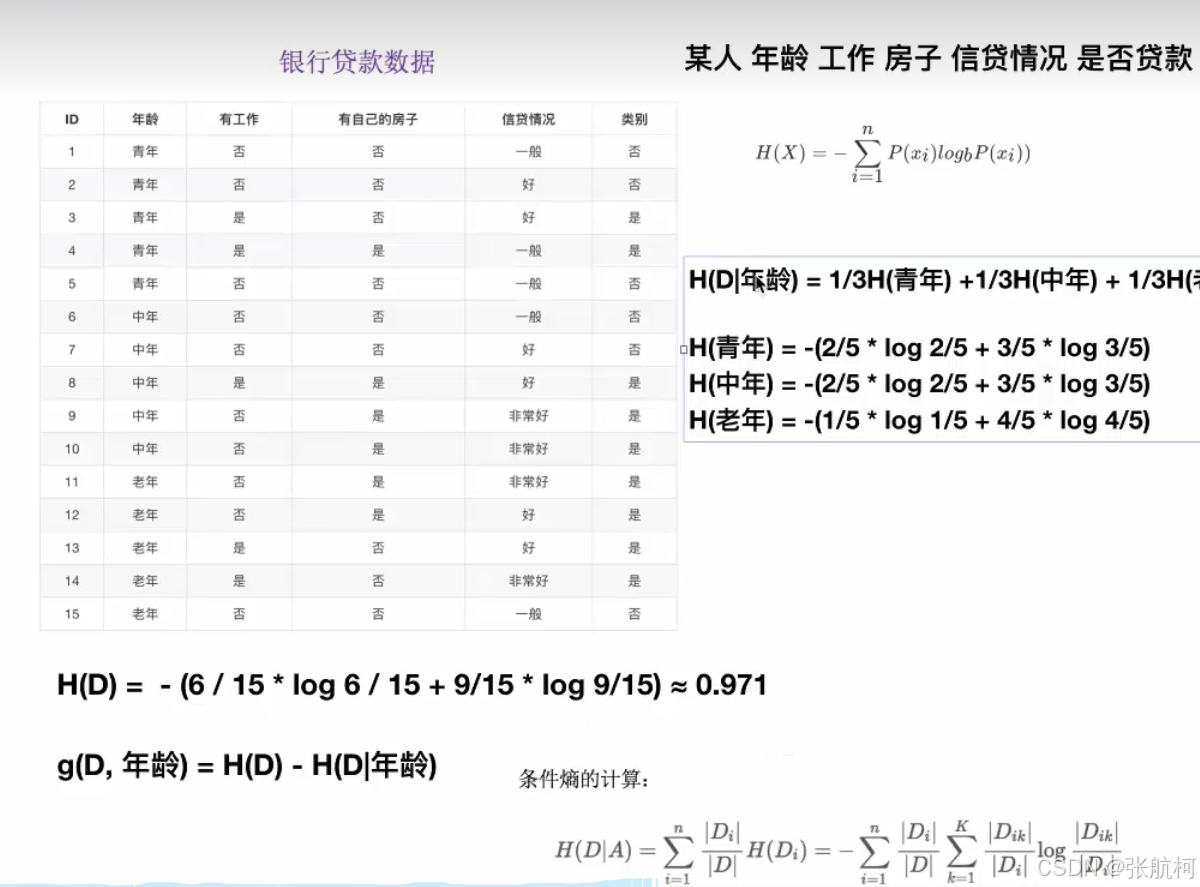
例如上面买房例子,年龄,现在更改为青年,不确定性减少


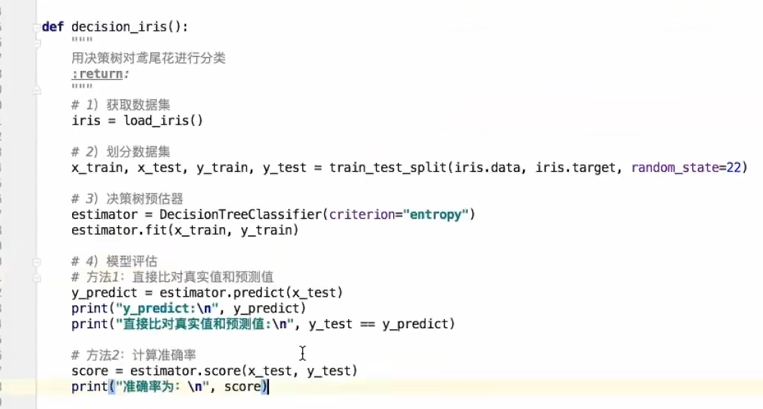
5. 决策树api


6. 决策树的可视化
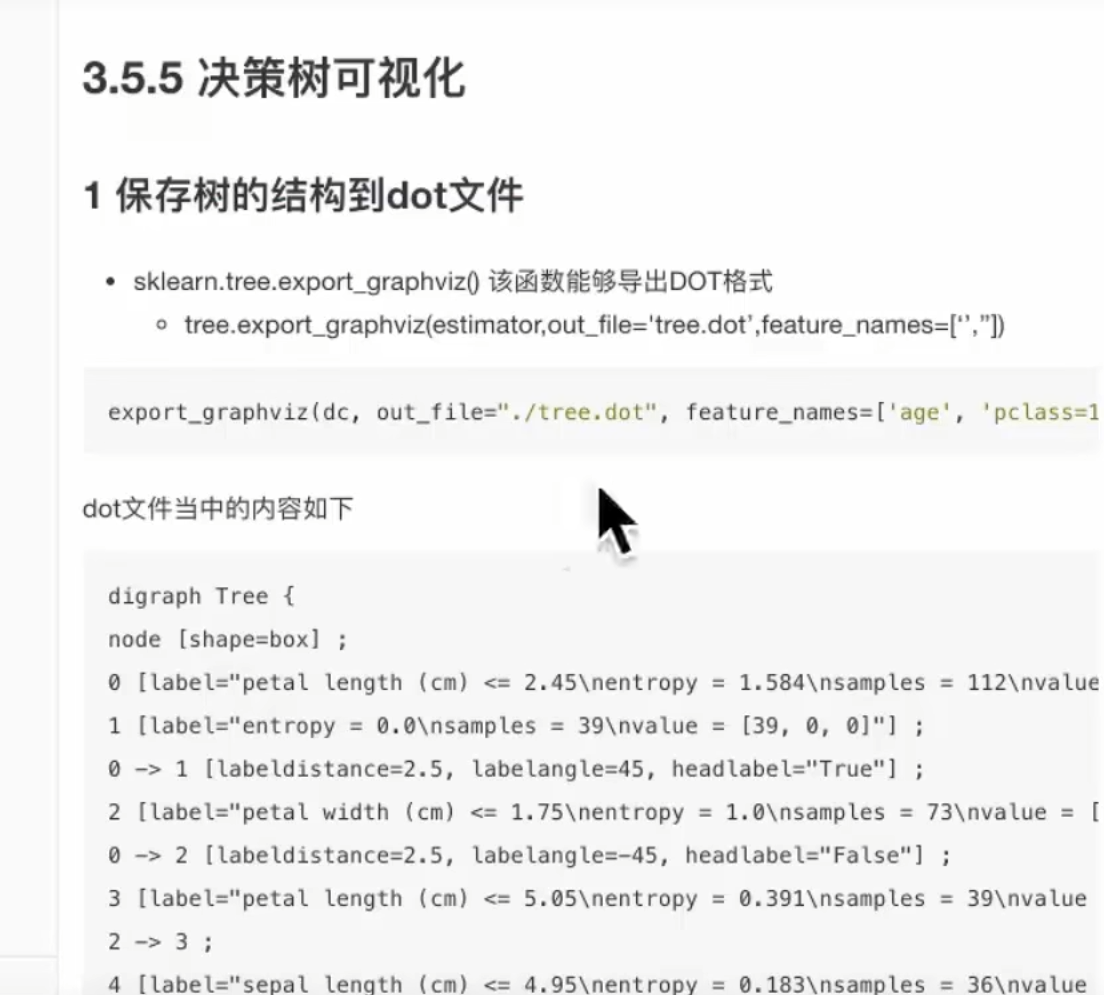
上面是文件并不是图案,可以借助网站

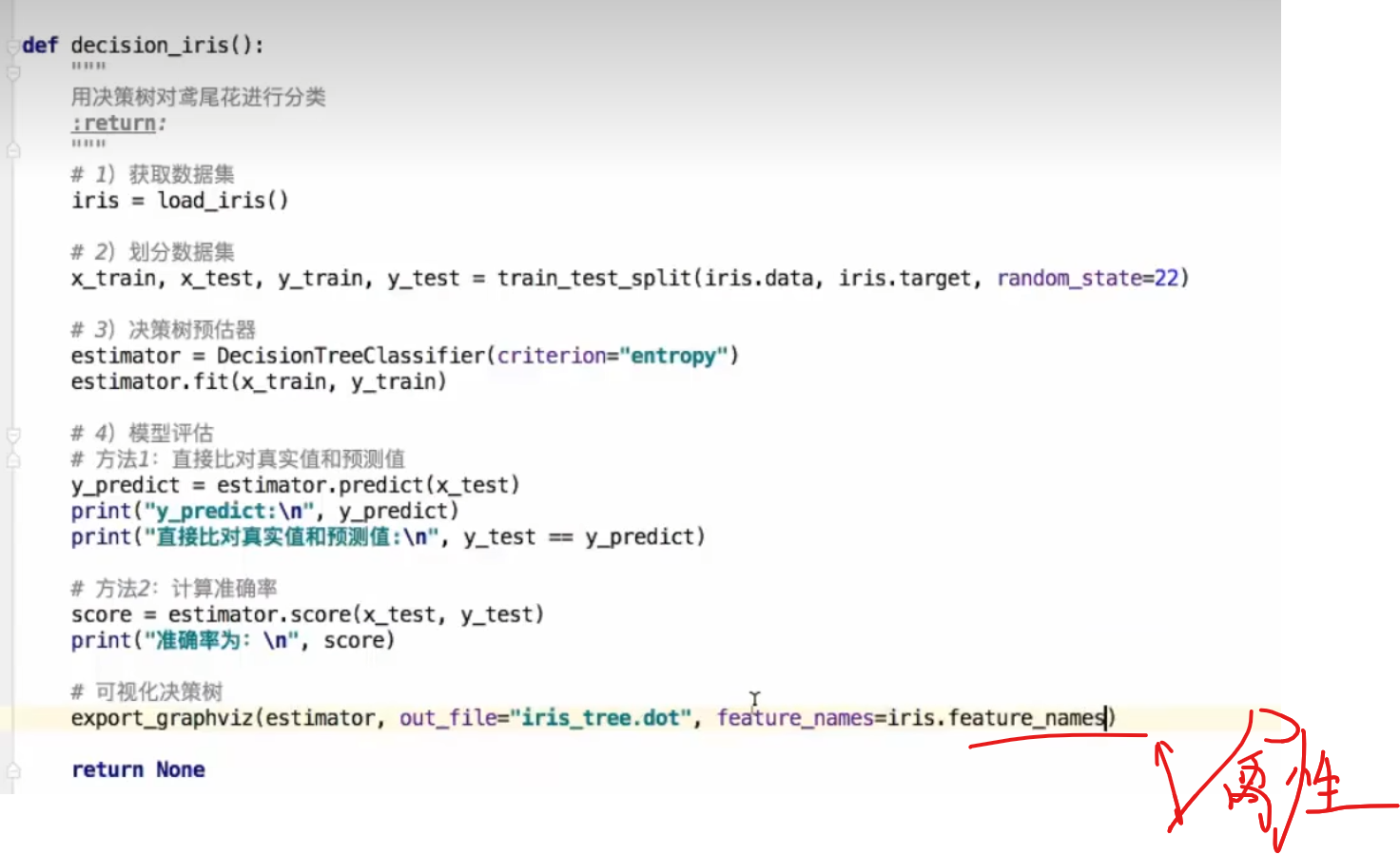
7. 总结

8 案例:泰坦尼克号乘客生存预测

1. 获取数据
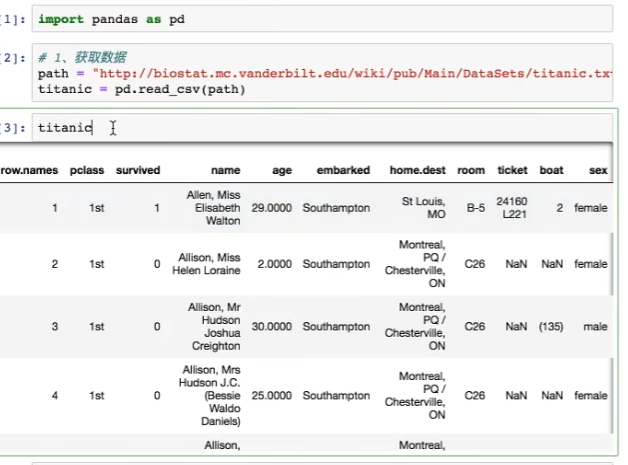
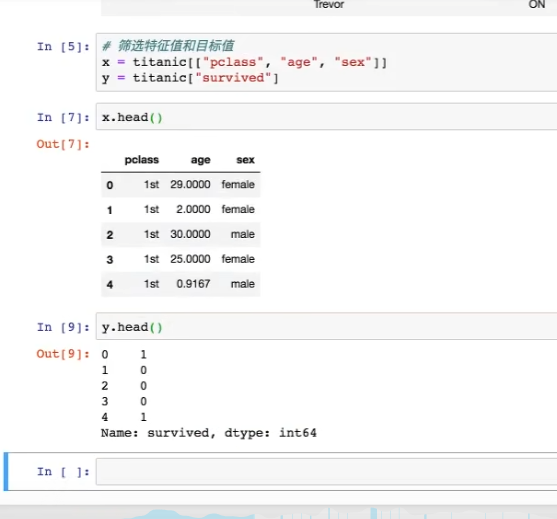
2. 筛选特征值和目标值(例如:年龄、头等舱、性别等 是否影响生存)
3.数据缺失填补数据(补充年龄为平局值)
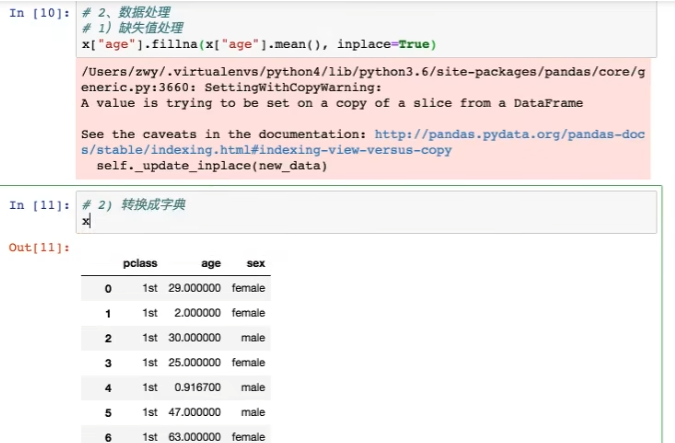
4. 转换为字典
5. 划分数据集

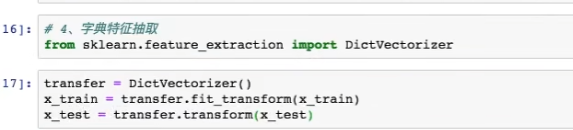
6. 字典特征抽取
7. 获取结果

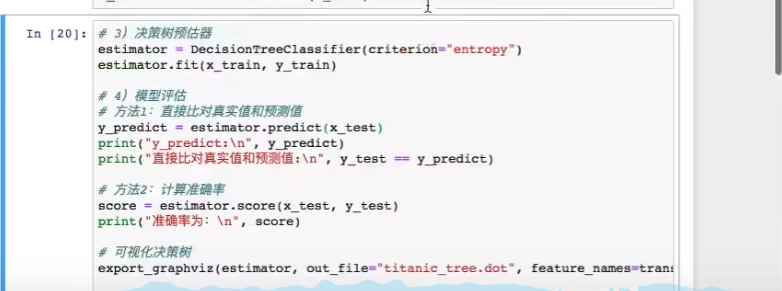
8. 调整树的高度
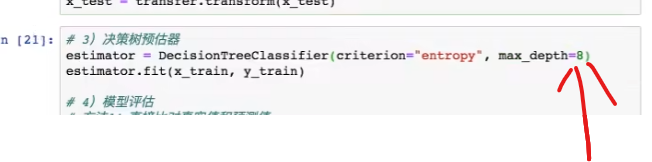
3.7 集成学习方法之随机森林
1. 什么是集成学习方法

谚语来比喻就是三个臭皮匠顶一个诸葛亮
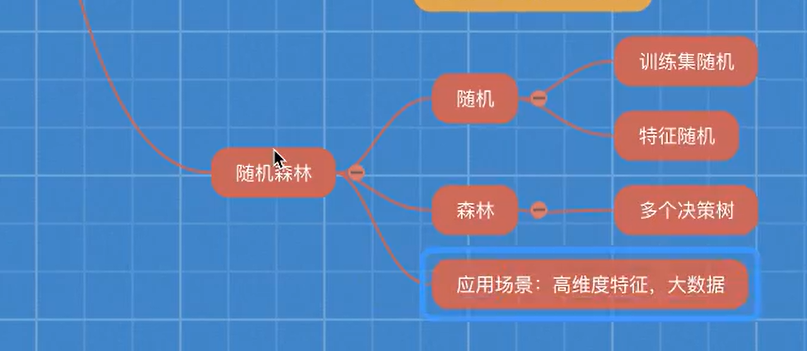
2 什么是随机森林

例如,你训练了五个树,其中有4个树的结果是True,1个为False,那么最终投票结果就是True
3 随机森林原理过程


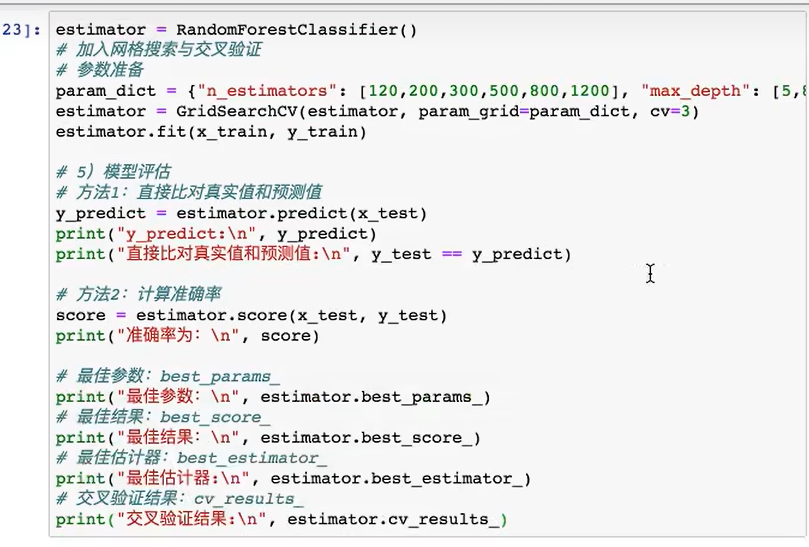
4 api接口

接泰坦尼克号来接着写,到第6步的代码后面开始加
1. 导入api实例化

2. 获取结果
没有复制全的找之前代码,之前代码里面有
5. 总结

3.8 三的大总结
四、回归与聚类算法
1. 线性回归
1.1 线性回归应用场景

1.2 什么是线性回归
下面例子中,
x属于特征值,h(w)属于目标值,w属于权重、也叫回归系数,b叫做偏执

2 线性回归的特征与目标的关系分析
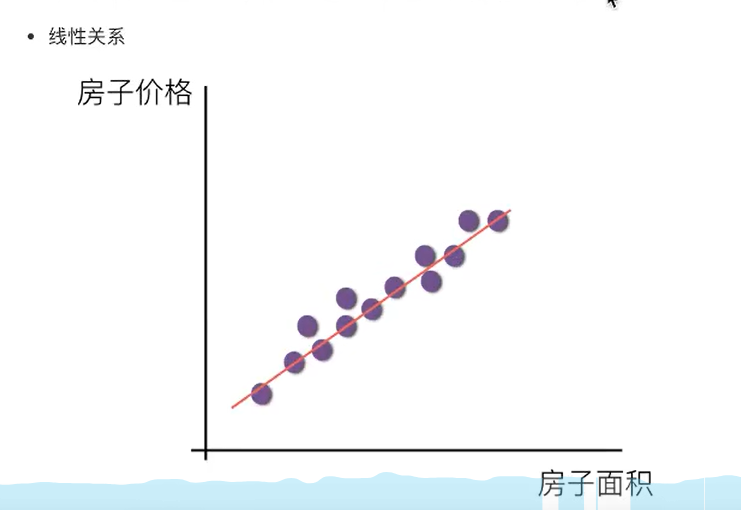
线性回归当中线性模型有两种,一种是线性关系,另外一种是非线性关系。这里我们只能画一个平面更好的去理解,所以都用单个特征举例子
- 线性关系

- 非线性关系
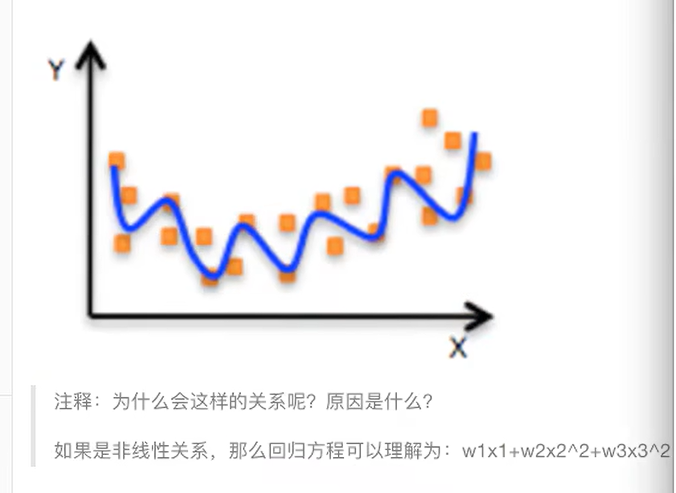
拓展

线性关系&线性模型
线性关系不一定是线性模型
线性模型不一定是线性关系
1.3 线性回归的损失和优化原理(理解记忆)
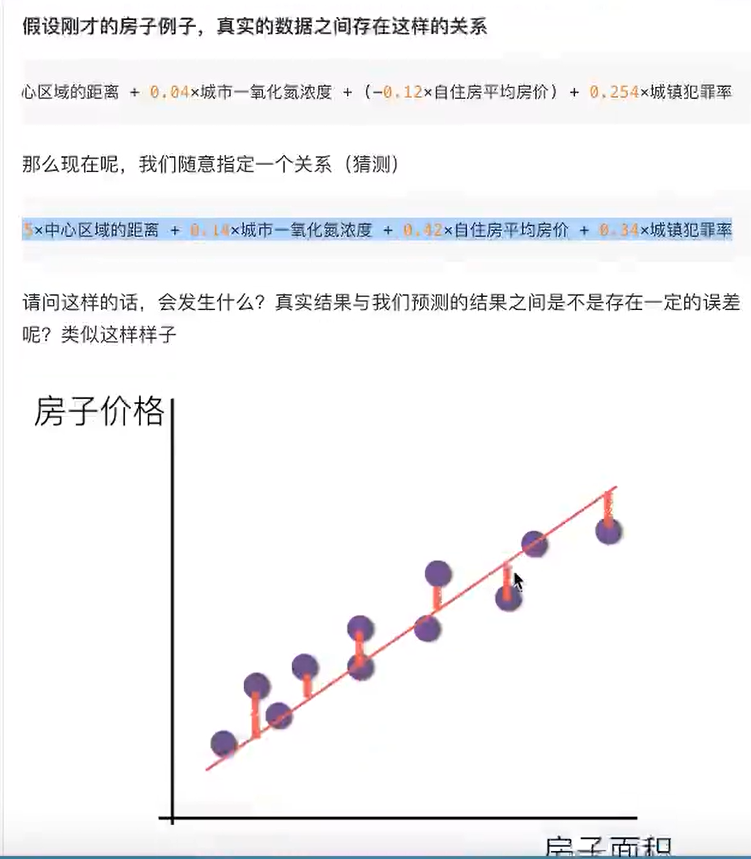
既然存在这个误差,那我们就将这个误差给衡量出来
1.3.1损失函数
y是真实值,hw(x)预测值,平方的缘故是:我们预测的值可能大于或者小于(有误差)

1.3.2 优化算法
-
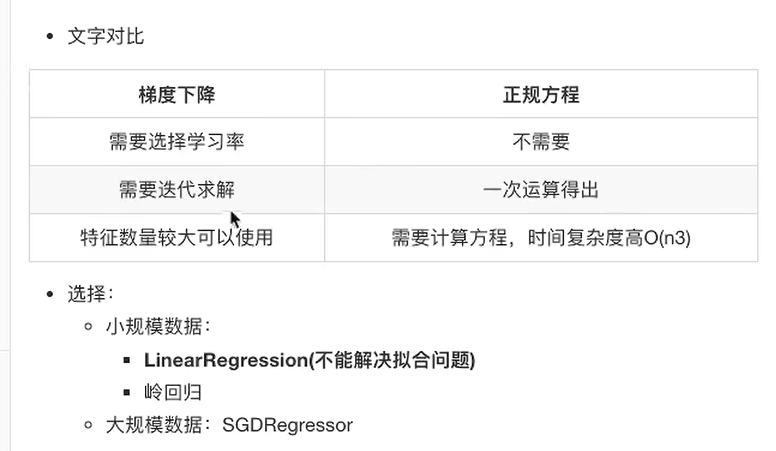
正规方程
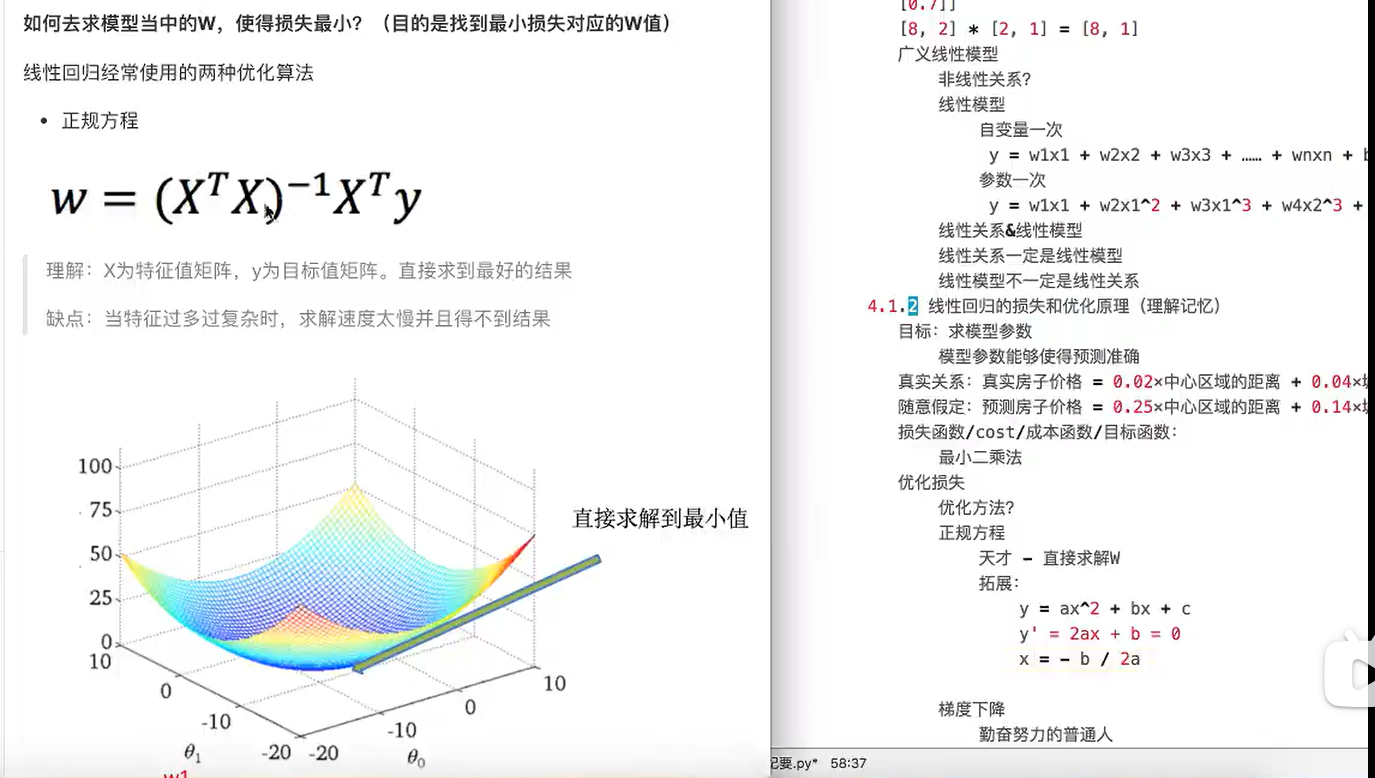
》正规方程适合数据比较小的 -
梯度下降

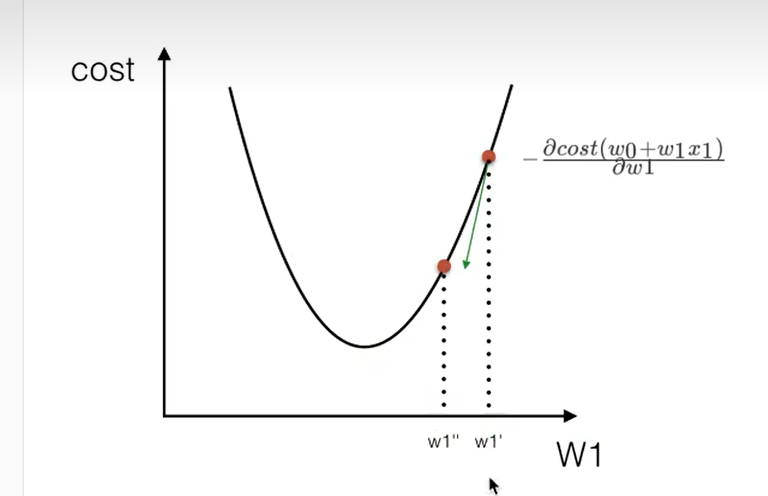
通过不断的进行寻找,找出最适合的权重值 不断学习找出来最合适的
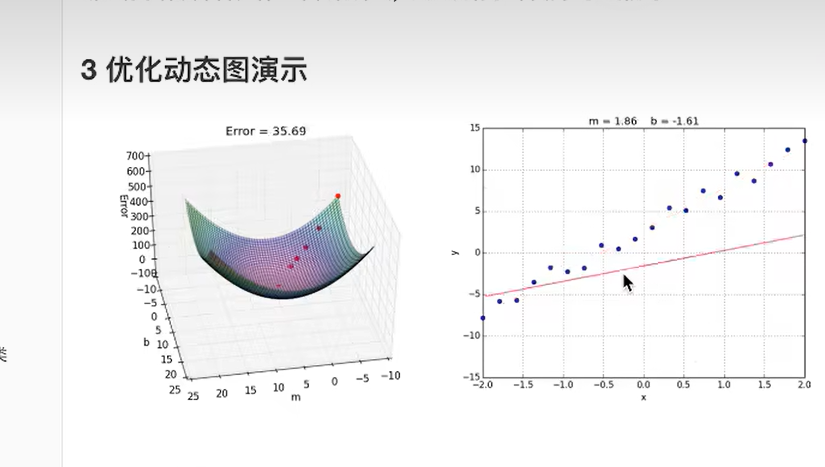
1.4 线性回归api

1.4.1 案例:波士顿房价预测

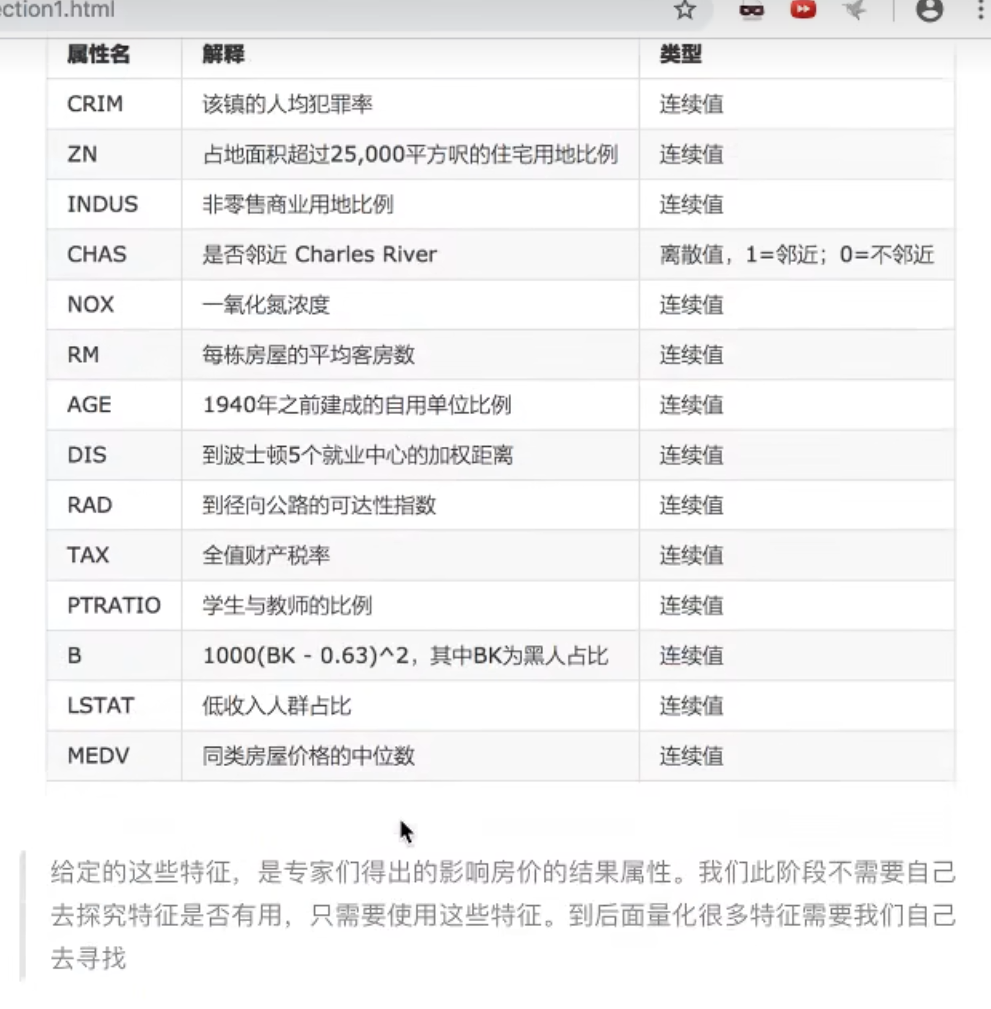
案例执行流程

正规方程

梯度下降
修改1中的代码,导入预估器,然后改变预估器


运行结果
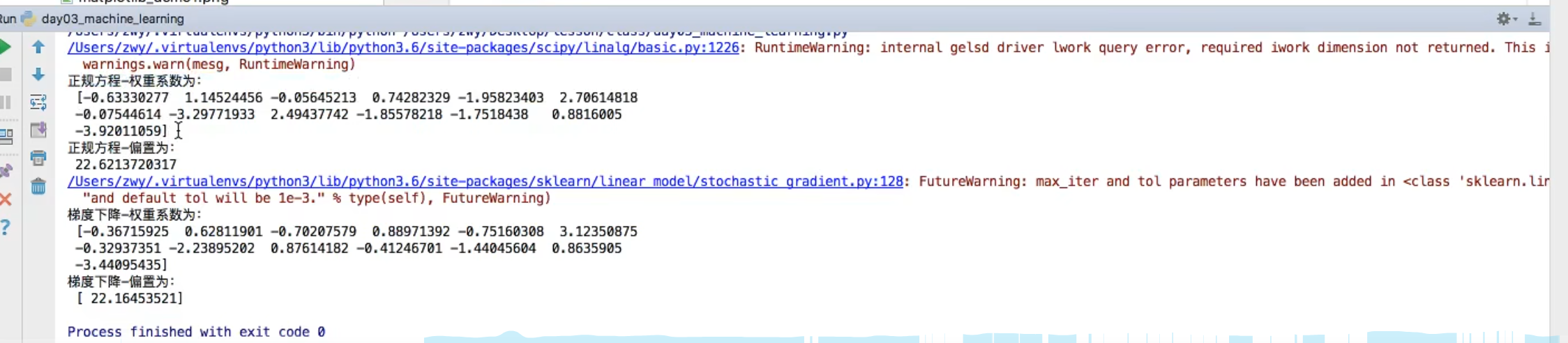
注意看13,权重系数数量也为13,跟特征数量一样
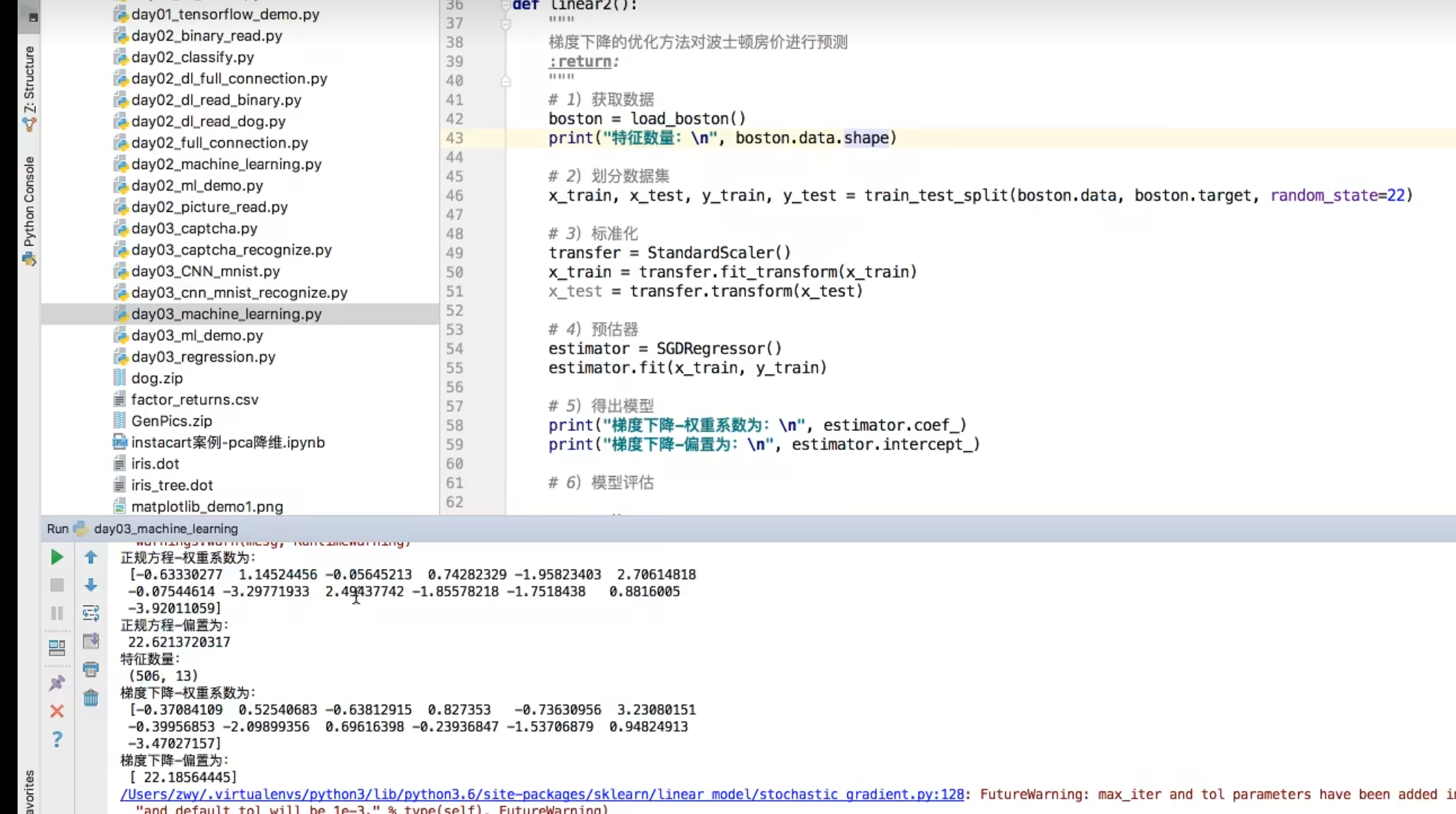
1.4.2 回归性能评估

代码


误差返回结果越小越好
梯度下降调优

改代码

1.4.3 正规方程和梯度下降对比
》小于10万条不用梯度下降。
1.4.4 拓展-关于优化GD、SGD、SAG


上面案例线性回归使用的是SGD
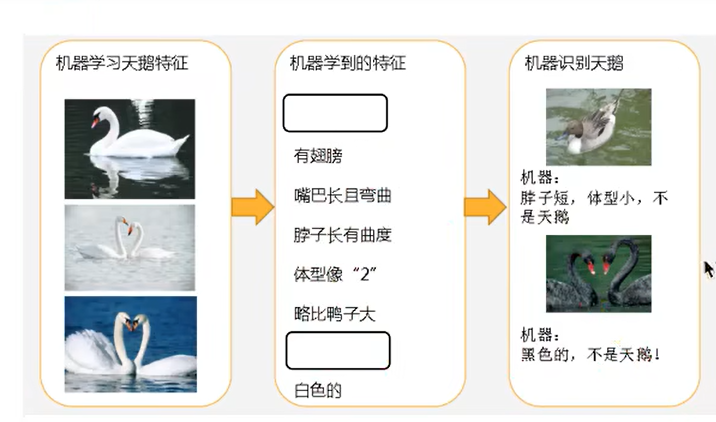
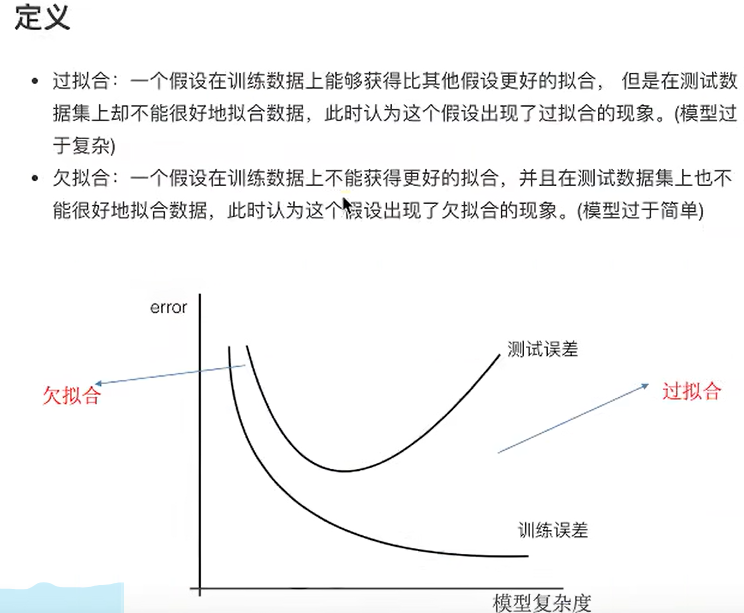
2. 欠拟合和过拟合
2.1 什么是欠拟合和过拟合
- 欠拟合
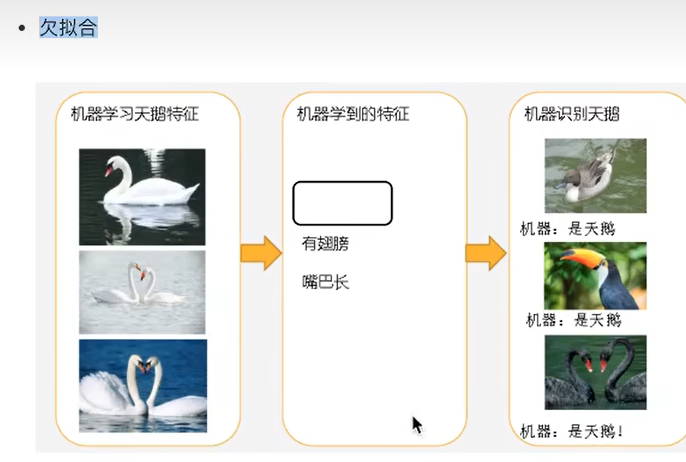
- 过拟合

定义

2.2 原因和解决方案

如何解决

2.3 正则化类别
2.3.1 L2正则化(常用)
其中Ridge是岭回归

其中下面是损失函数

其中下面是lambda(λ)惩罚项(λ系数超参数可调),加入惩罚项会让w系数变小,
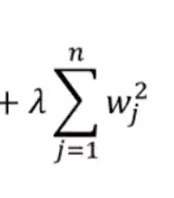
2.3.2 L1正则化

2.3.3 总结
二者公式不同的是
L1是W的绝对值
L2是W的2(平方)

3 带有L2正则化的线性回归-岭回归

3.1 api
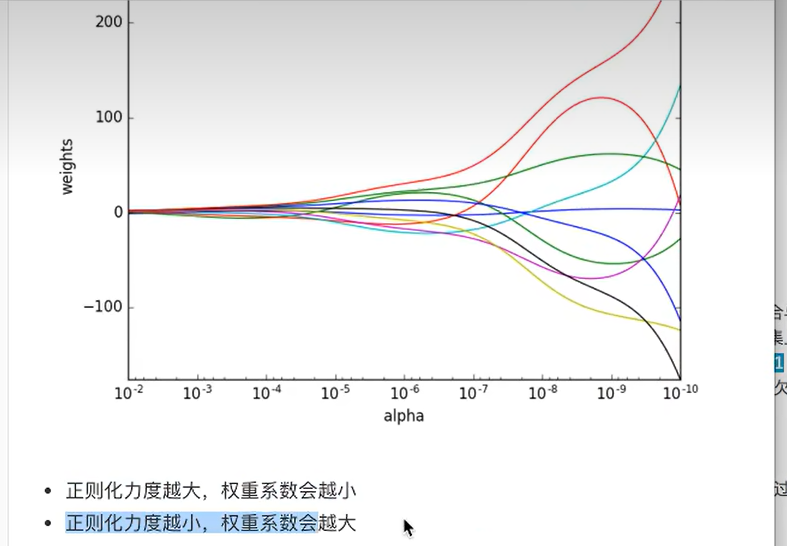
alpha也叫这个符号叫做阿尔法


3.2 观察正则化程度的变化,对结果的影响
3.3 案例

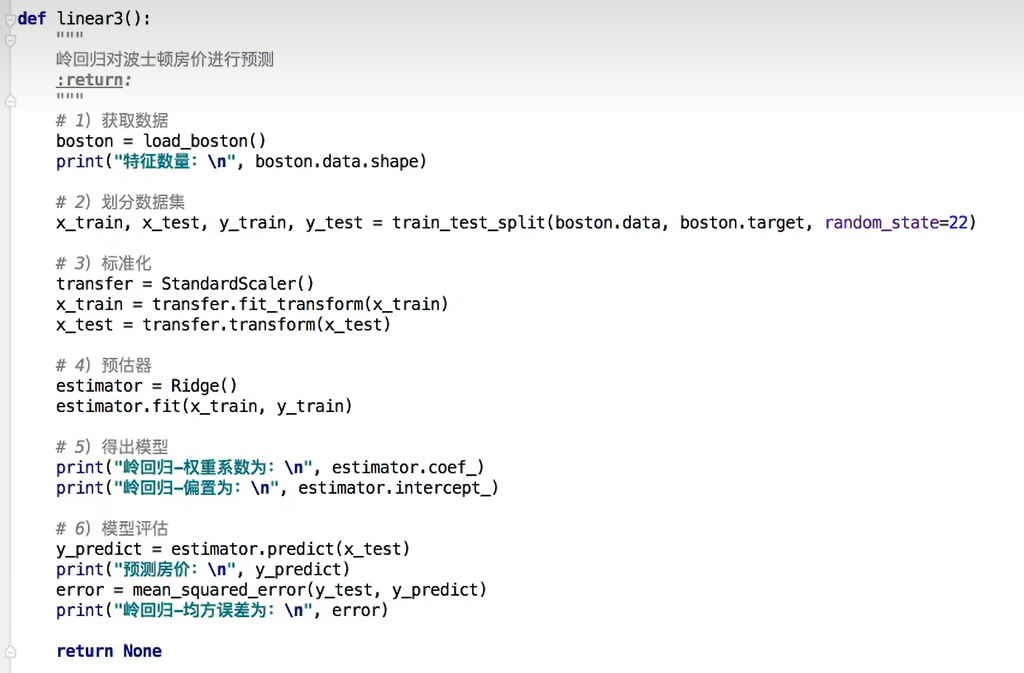
调整参数

4. 分类算法-逻辑回归与二分类

4.1 逻辑回归的应用场景

4.2 逻辑回归的原理
4.2.1 输入
线性回归的输出 就是 逻辑回归 的 输入
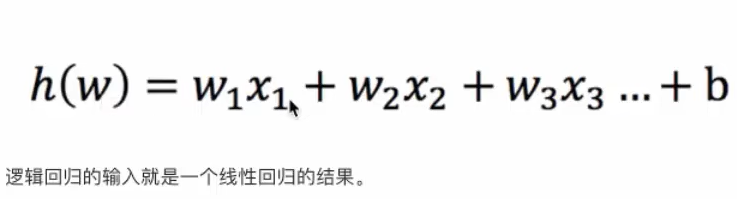
4.2.2 激活函数
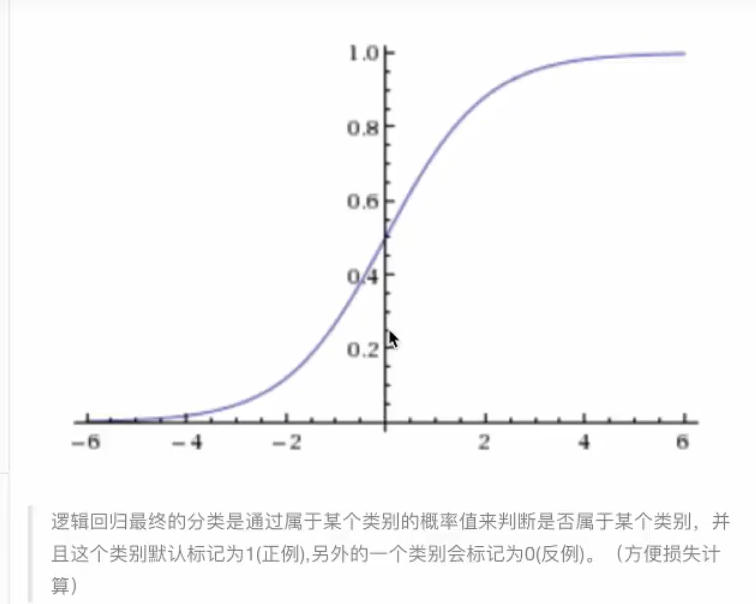
- sigmoid函数

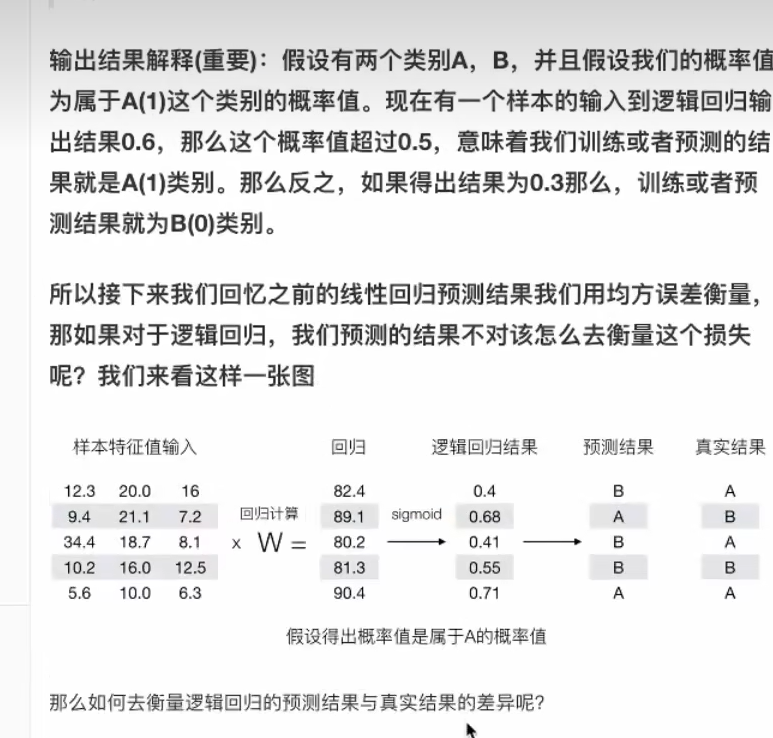
4.3 损失以及优化
4.3.1 损失
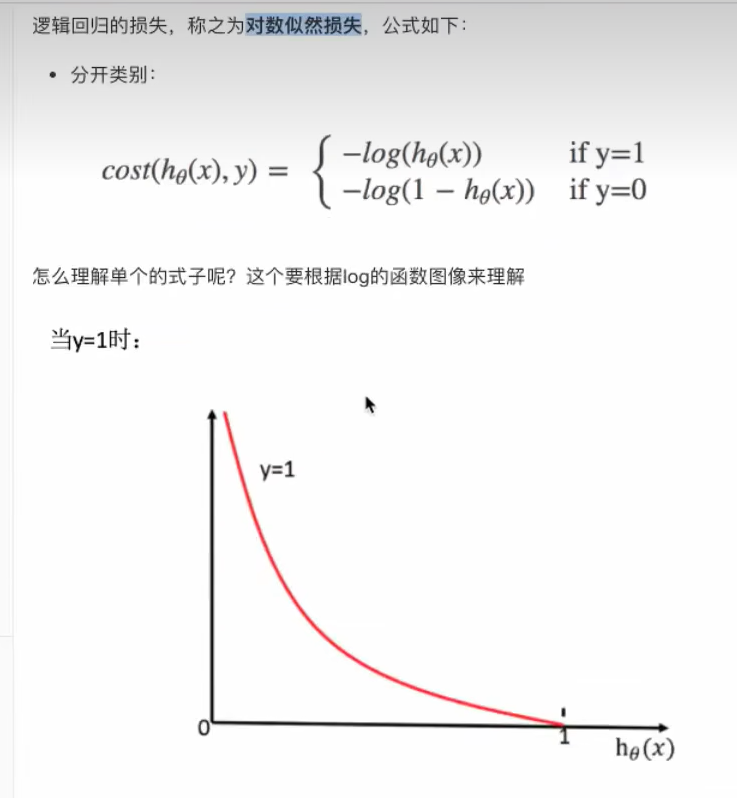


4.3.2 优化

4.4 逻辑回归api

4.5 案例:癌症分类预测-良 / 恶性乳腺癌肿瘤预测
处理流程
- 获取数据
读取数据的时候加上names - 数据处理
处理缺失值 - 数据集划分
- 特征工程
无量纲化-标准化 - 逻辑回归预估器
- 模型评估
4.5.1 获取数据
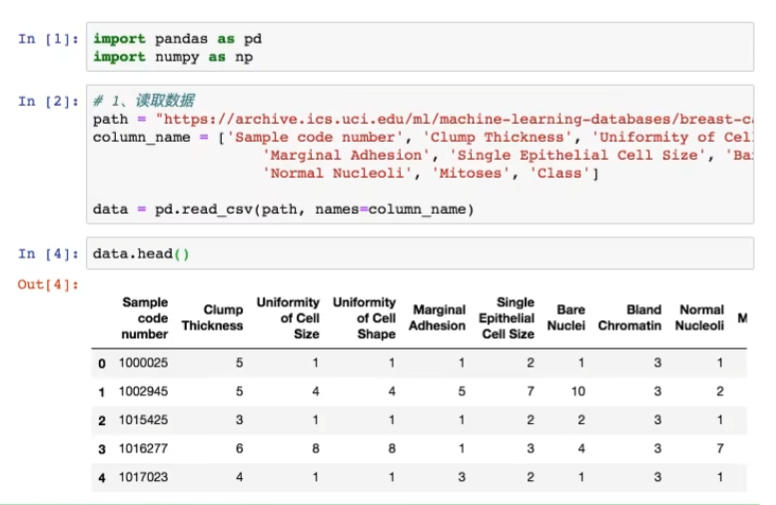
其中?是缺失值
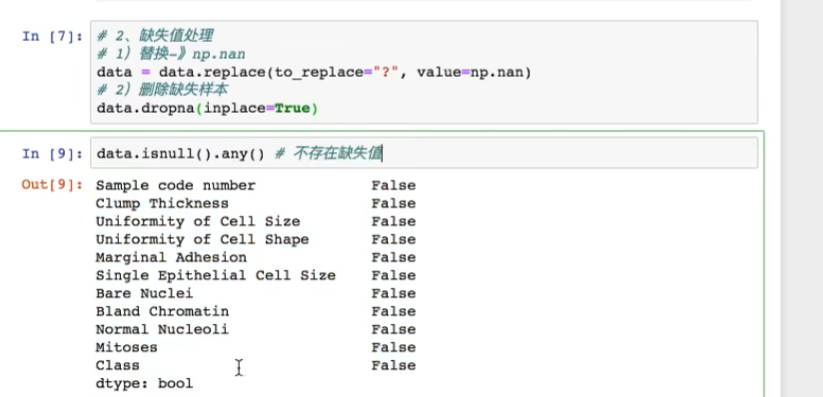
4.5.2 缺失值处理
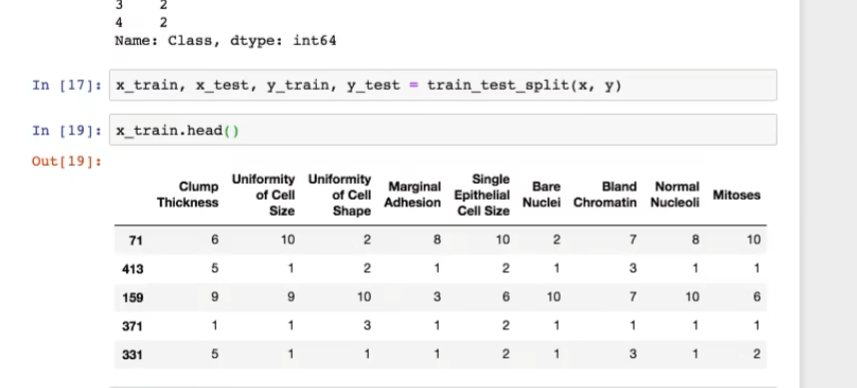
4.5.3 数据集划分
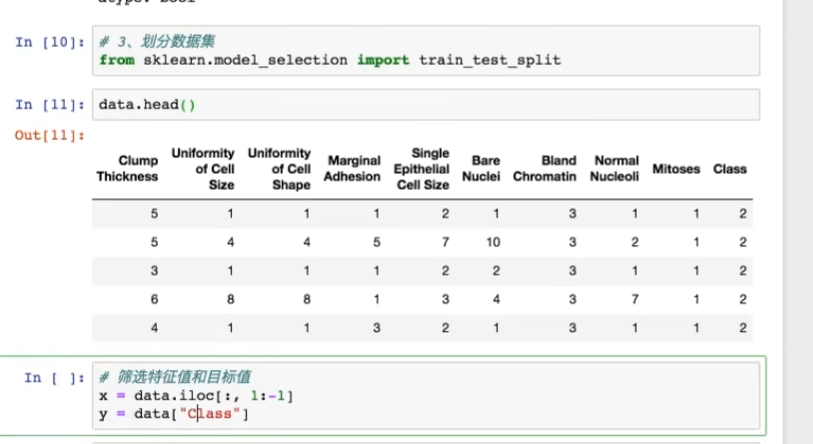
其中x是特征(因素),y是结果
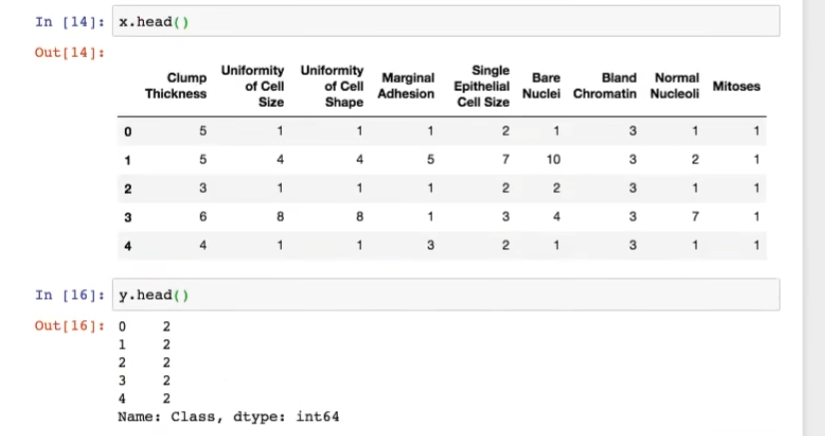
4.5.4 特征工程
标准化了,也无量纲化了(数据大小都在0-1之间,防止公里数和时间,因为公里数大而导致时间大)
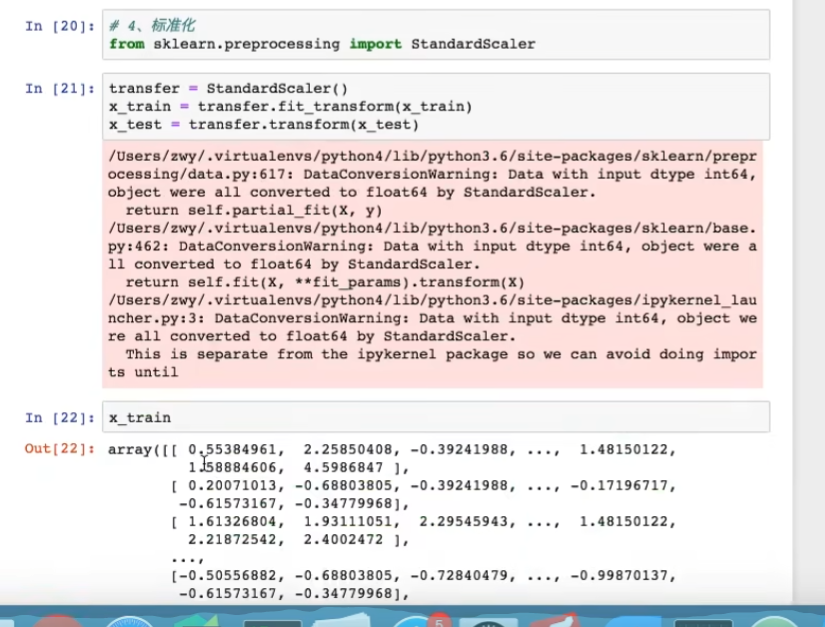
4.5.5 逻辑回归预估器
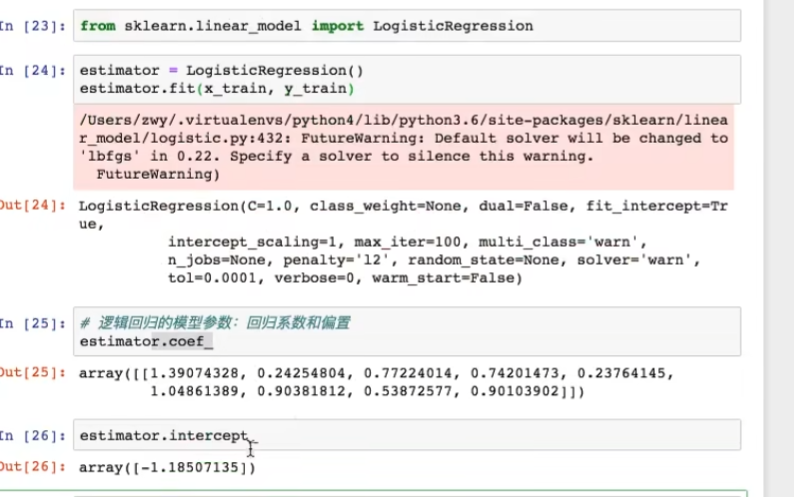
4.5.6 模型评估

2良性 4恶性
4.6 精确率、召回率、F1-score
4.6.1 混淆矩阵

4.6.2 精确率、召回率


4.6.3 分类评估报告api

接癌症案例后比较

完整
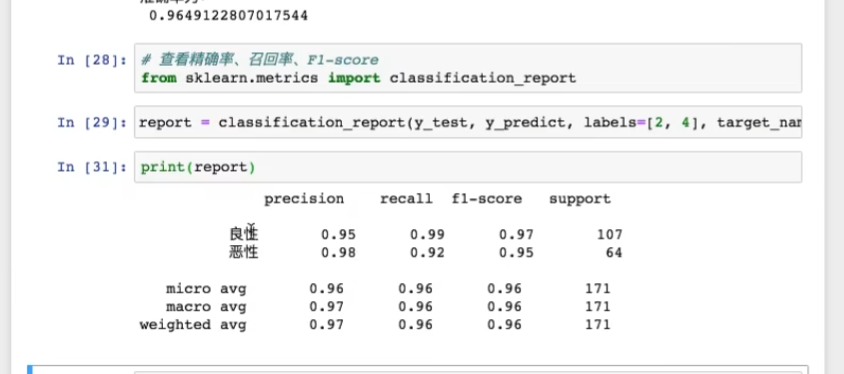
- precision:精确率
- recall(重要):召回率
- f1-score:稳健性
- support:样本量

问题:如何引入4.7

4.7 ROC曲线和AUC指标(样本不均衡的时候进行使用)
4.7.1 TPR和FPR


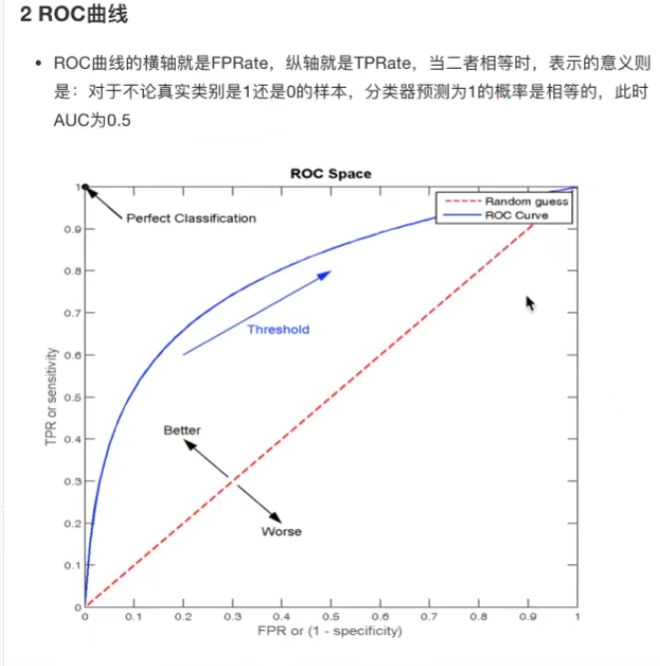
4.7.2 ROC曲线
红色虚线是指标,x和y轴也是指标,包括面积也是指标
蓝线是roc曲线
其中蓝色曲线是ROC曲线
x是FPR
y是TPR
FPR=TPR就是直线
TPR>FPR就是向上倾斜
TPR<FPR就是向下倾斜
所以曲线是根据上面的值变化的
4.7.3 AUC指标

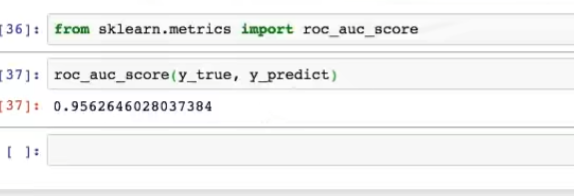
4.7.4 AUC计算API

回到癌症案例
恶性为正例
2(良性)是0
4(恶性)为1
转换
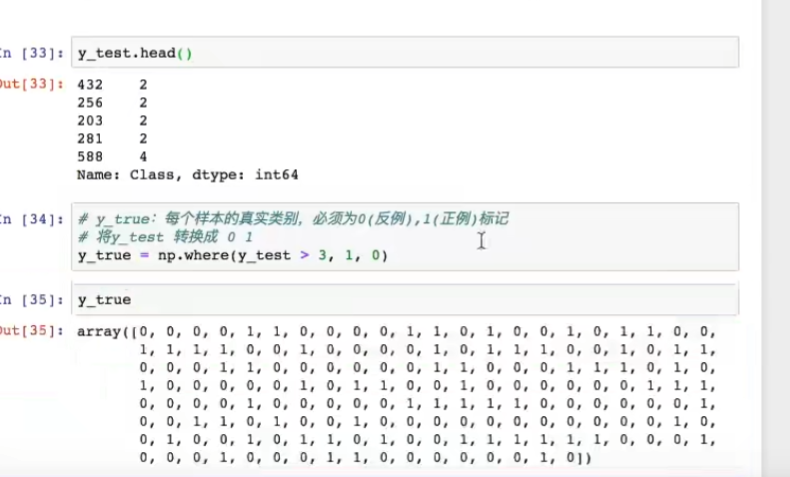
评估:0.95在样本不均衡的情况下,结果还行
4.7.5 总结


0.5不好
(1x1)/2=0.5
FPR中
1是反例、只有一个非癌症(反例),预测结果是1(是正例,也就是错误的预判)所以1/1
先进行正常精确率和召回率(重要)预判,再看数据不均衡的二分类的roc曲线
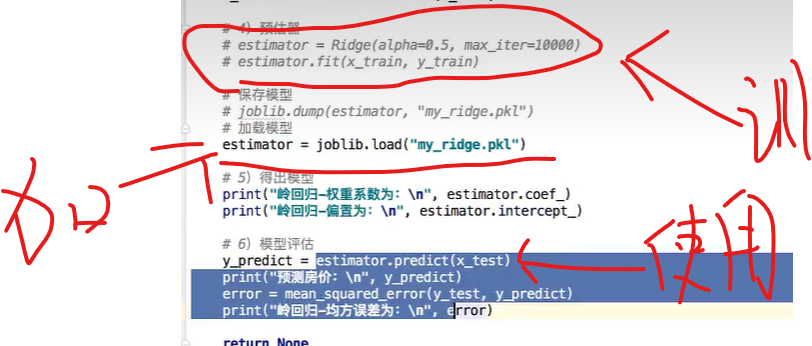
5 模型的保存和加载
5.1保存和加载api


6 无监督学习-K-means算法原理
6.1 什么是无监督学习

6.2 无监督学习 包含算法

6.3 k-means原理
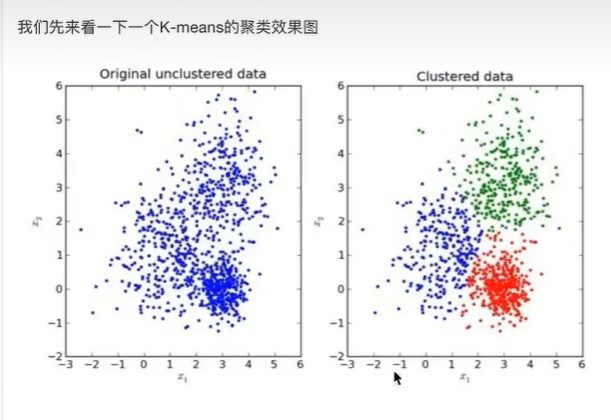

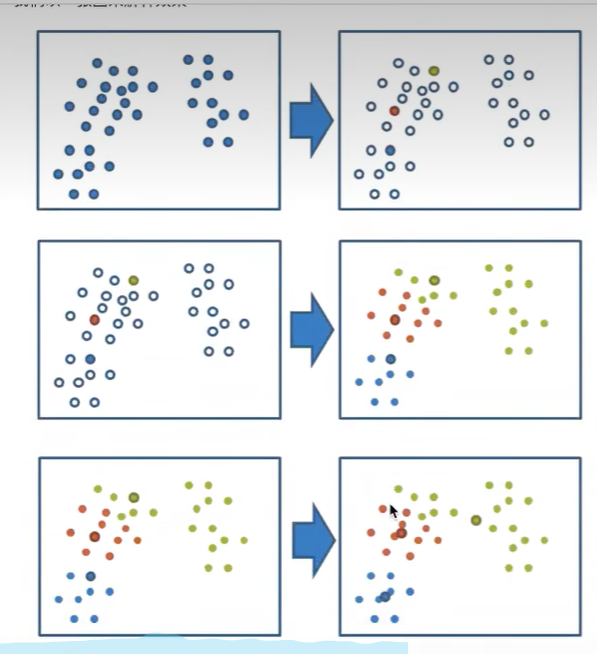
k就是想分成几个特征就选几个参数
- 选k=3,那么就随机选择三个点,染上不同颜色例如图一的右边
- 随便找个点,计算到k中3点中的距离,最近的标记跟最近的同一个颜色,以此类推,变成了图二中的右图
- 然后找出来所有同颜色的再求一个中心点-聚类中心,就是颜色最中间的点,就是图三中的右图
- 如果计算的出来的中心点和原来中心点一致,那么就结束,否则就以新的3个点位去进行2的操作以此类推
- 如果相近的话,那么也可以停止聚类操作
- 如何算到3的中心点的

6.4 api

6.5 案例:k-means对instacat Market用户聚类
instacat这家公司想对自己的用户进行分类
6.5.1分析

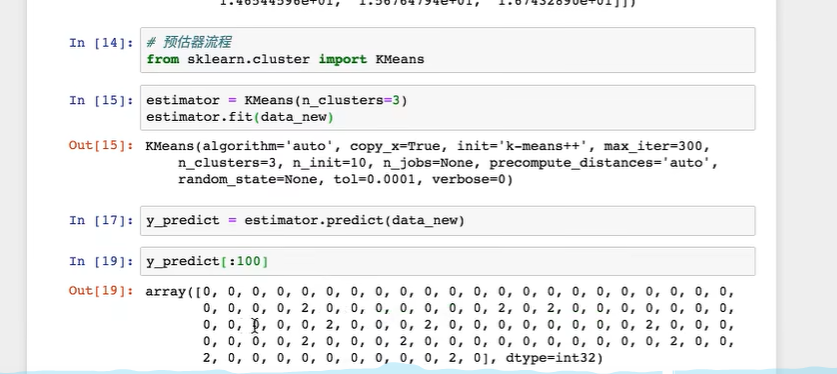
6.5.1 代码
6.6 Kmeans性能评估指标
6.6.1 轮廓系数
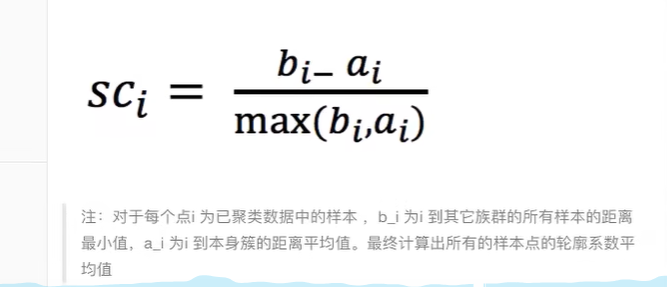
6.6.2 轮廓系数值分析
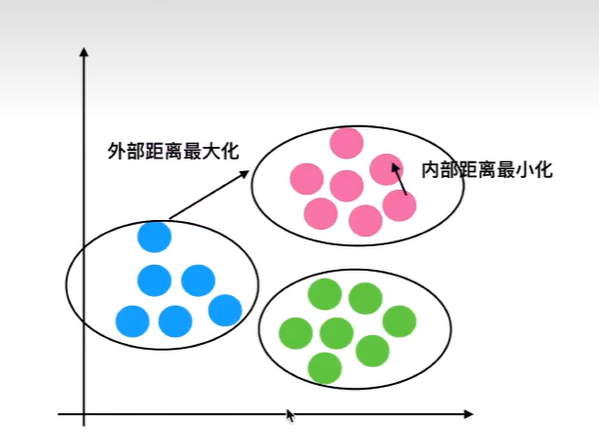

越接近1的越好
6.6.3 结论

6.6.4 轮廓系数 API

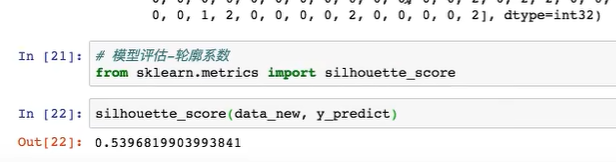
data_new就是训练入参 y_predict是评估后的值
6.6.5 K-means总结

缺点:局部最优-就是三个点位挤到一起了,解决办法就是多次聚类