2.监控领域中行业黑话知识学习指南
上一篇文章,我们介绍了可观测性的三大支柱:日志、指标和追踪,并对业界常见开源方案做了横评对比。在接下来的我们继续学习可观测性监控的相关概念,包括 监控指标、指标类型,告警收敛与闭环,时序库数据库等。
监控(monitor),从字面意义上理解,就是对事物对象行为状态进行持续关注,而这里所介绍的监控系统,指的是持续针对系统运行及资源状态指标进行关注(例如,系统CPU使用率、内存占用等),所以监控体系中最基础的是监控指标(metric),它是度量系统运行状态的手段,作为一名运维通常围绕指标的采集、传输、存储、分析、可视化,并通过相应规则进行告警通知等一系列流程。
0x01 监控指标
监控指标(Monitoring Metrics)是用于量化系统、应用或服务运行状态和性能的数据点,帮助运维、开发或业务团队实时了解健康状态、发现问题并进行优化。它们是监控系统的核心要素,通常以时间序列的形式存储和展示(如折线图、仪表盘)。
如何设计有效的监控指标?
-
明确目标:区分核心指标(如SLA相关)与辅助指标。
-
分层覆盖:从硬件到业务逐层监控(网络→应用→订单)。
-
设定阈值:定义正常/异常范围(如CPU>90%告警)。
-
避免冗余:平衡指标数量与存储成本。
-
动态调整:随业务演进迭代监控策略。
不同的监控系统,对于监控指标有不同的描述方式,下述列举三种典型的方式:
全局唯一字符串作为指标标识:
例如,某计算机CPU使用率指标可以表示为host.10.10.1.1.mem_used_percent,此字符串中包含了实例类型,实例信息,以及指标名称。
# 如 Graphite 监控系统使用这种方式来标识监控指标的,而 Collectd 监控数据采集器也支持这种方式。
{ "name": "host.10.10.1.1.mem_used_percent", "points": [ { "clock": 1662449136, "value": 45.4 }, { "clock": 1662449166, "value": 43.2 }] }
虽然该方式可以很好地标识监控指标,但是当实例数量较多时,会导致监控系统存储大量的冗余数据;并且由于缺少对维度信息的描述,不便于进行多维度的聚合查询。
# 例如,比如下面几条用于描述HTTP请求状态码的指标,若想计算 service1 成功率,则需要统计将状态码为200的请求数总和,再除以 service1 的所有请求数总和,提取数据也相对于麻烦。
myhost.service1.http_request.200.get myhost.service1.http_request.200.post myhost.service1.http_request.500.get myhost.service1.http_request.500.post
标签集的组合作为指标标识:
例如,推送给 OpenTSDB 的时序数据库的指标格式如下所示,其中包含了度量名称、时间戳、指标值,以及多个标签(tags/labels)信息,每个标签都是key=value的格式,多个标签之间使用空格分隔。。
mysql.bytes_received 1287333217 327810227706 schema=foo host=db1
mysql.bytes_sent 1287333217 6604859181710 schema=foo host=db1
mysql.bytes_received 1287333232 327812421706
schema=foo host=db1
除了 OpenTSDB,新时代的时序库大都引入了标签的概念,比如 Prometheus、VictoriaMetrics 等业界主流的指标采集与存储系统;在Prometheus中甚至认为指标名也是一种特殊的标签(其标签 key 是__name__ ),所以 Prometheus 仅仅使用标签集作为指标标识,从Prometheus 的数据结构定义中就可以看出来。
# 如 Prometheus 监控系统使用这种方式来标识监控指标的。
cpu_usage{instance="10.10.1.1", job="webserver"}
多度量集合作为指标标识:
例如,InfluxData公司有一款开源时序库 InfluxDB,它支持多维度的度量集合作为指标标识,在接收监控数据时写入时,会将多个度量名称和标签集合作为一个整体进行存储。简单来说,可分为4个部分,measurement,tag_set field_set timestamp,其中tag_set是可选的,tag_set 与前面的measurement之间用逗号分隔,其他各个部分之间都是用空格来分隔的。
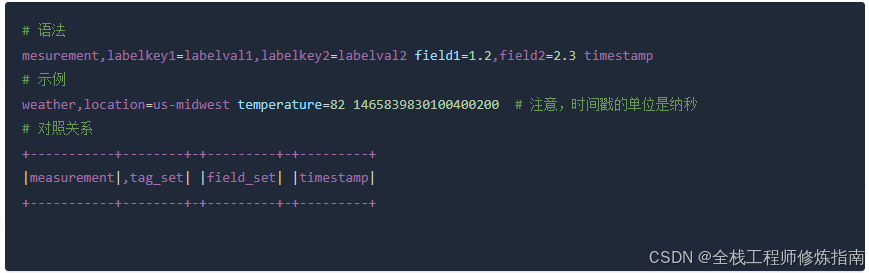
若将上面 OpenTSDB 的指标示例换成InfluxDB的格式,一行数据对应多个度量集合,写法设计很精巧,标签重复度低,field越多的情况下它的优势越明显,网络传输的时候可以节省更多带宽;此文。
# 示例 mysql,schema=foo,host=db1 bytes_received=327810227706,bytes_sent=6604859181710 1287333217000000000
最后,大致对比一下三种指标标识方式的优缺点:
| 指标标识 | 优点 | 缺点 |
|---|---|---|
| 全局局唯一字符串 | 简单 | 缺失维度信息,不利于多维聚合计算与灵活赛选 |
| 标签集组合 | 灵活 | 稍显冗余 |
| 多度量集合 | 灵活、精巧、语义丰富 | 理解成本稍高 |
总得来说,监控指标的概念非常重要,它贯穿整个监控系统的各个环节,它是系统可观测性的基石,结合日志(Logs)和链路追踪(Traces),能构建完整的运维洞察体系,提前预警问题,减少故障恢复时间(MTTR)。
0x02 指标类型
不同监控系统的监控指标的类型多种多样,每种类型都有其特定的用途和意义。例如,在 80 年代 RRDtool,它是一个环形数据库,也是一个绘图引擎,很多监控工具(Cacti、MRTG、Zabbix)都是使用 RRDtool 来存储或绘制监控趋势图的;它提出了数据类型的概念,即 GAUGE、COUNTER、DERIVE、DCOUNTER、DDERIVE、ABSOLUTE 等多种数据类型。
这里以目前主流的 Prometheus 监控系统为例进行讲解,它支持四种基本的指标类型:计数器(Counters)、计量器(Gauges)、直方图(Histograms)和摘要(Summaries)。
-
计数器(Counters):用于记录事件发生的次数,它们通常单调递增,不会重置为零。例如: HTTP请求数、错误发生次数等。
http_requests_total{method="GET"} 1027errors_total{type="timeout"} 34 -
计量器(Gauges):用于测量当前值,它们的值可以增加或减少,通常关注的是当前时刻的值。例如,当前内存使用量、CPU负载百分比等,
memory_usage_bytes 52428800 cpu_load_percent 2.5 -
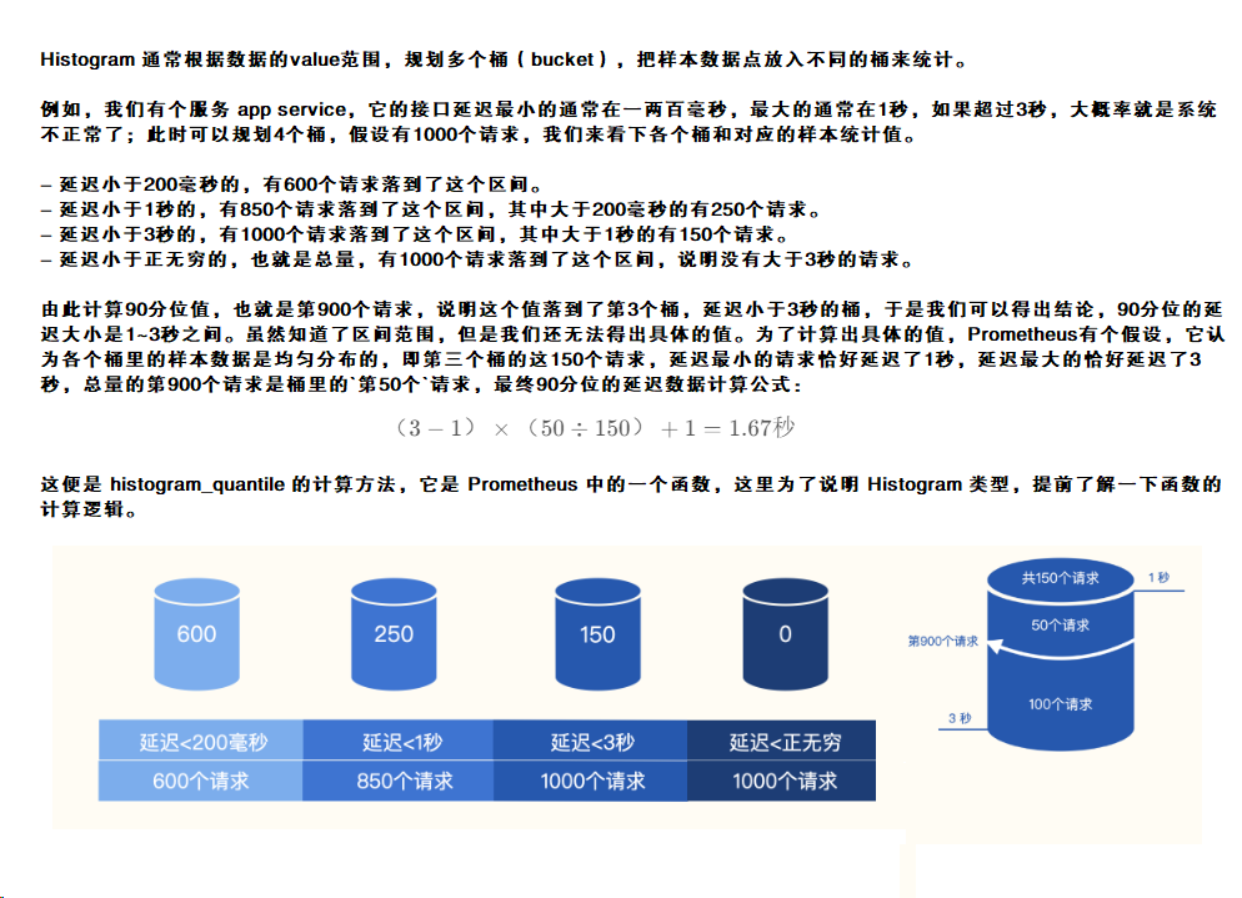
直方图(Histograms):用于测量和统计数据的分布情况,包括最小值、最大值、平均值、中位数等统计信息,常用于跟踪请求延迟、响应大小等数值的分布。其核心思想是,将测量值分配到预先定义的"桶"(buckets)中,每个桶记录小于等于该桶上限值的观测数量,即客户端定义桶,服务端计算分位数。
例如,你在学校需要测量全班同学的身高,然后需要统计多少人在150cm以下,多少在150-160cm之间,多少在160-170cm之间等,你只需要测量一次即可,将所有数据放入对应的桶中,然后统计每个桶的数量即可。使用 Histogram 作为统计工具,可以用较小的代价计算一个大概值,虽然准确精度不高,但是应用在监控中足矣。例如:监控延迟数据,计算90分位、99分位的值,
http_request_duration_seconds_bucket{le="0.1"} 125 // 有125个请求响应时间≤0.1秒 http_request_duration_seconds_bucket{le="0.5"} 324 // 有324个请求响应时间≤0.5秒 http_request_duration_seconds_bucket{le="1"} 500 http_request_duration_seconds_bucket{le="2.5"} 750 http_request_duration_seconds_bucket{le="5"} 900 http_request_duration_seconds_bucket{le="10"} 1000 http_request_duration_seconds_bucket{le="+Inf"} 1000 // 总请求数 http_request_duration_seconds_sum 1234.5 // 所有响应时间总和 http_request_duration_seconds_count 1000 // 总请求数(与+Inf桶相同) // 查询示例: http_request_duration_seconds_bucket{le="1"} // 有多少请求响应时间小于1秒? histogram_quantile(0.5, rate(http_request_duration_seconds_bucket[5m])) // 5分钟内的中位数(第50百分位)延迟是多少?注:所谓的分位值,就是把一批数据从小到大排序,然后取X%位置的数据,90分位就是指样本数据第90%位置的值。
前面可知,Histograms 不需要将所有请求的延迟数据全部拿到再排序,虽然性能有了巨大的提升,但是要同时计算成千上万个接口的分位值延迟数据,还是非常耗费资源的,甚至会造成服务端OOM,于是 Summary 类型便孕育而生。
-
摘要(Summaries):类似于直方图,区别是客户端直接计算分位数,服务端只接收结果,通常用于存储较小的样本集,它们提供了总和、计数和分位数等统计信息。
http_request_duration_seconds_sum 1024 http_request_duration_seconds_count 128
到这里,我们就把 Prometheus 的四种数据类型介绍完了,再看看 Prometheus 数据传输结构,即 TimeSeries 的 Proto 结构,看看能否发现一些问题?
-
问题:Sample.value 仅为 double 类型,无法直接支持其他类型(如直方图、分位数、字符串标签值需转为数值),不过虽然 Proto 的简洁性牺牲了存储效率,但提高了编解码速度,适合网络传输。
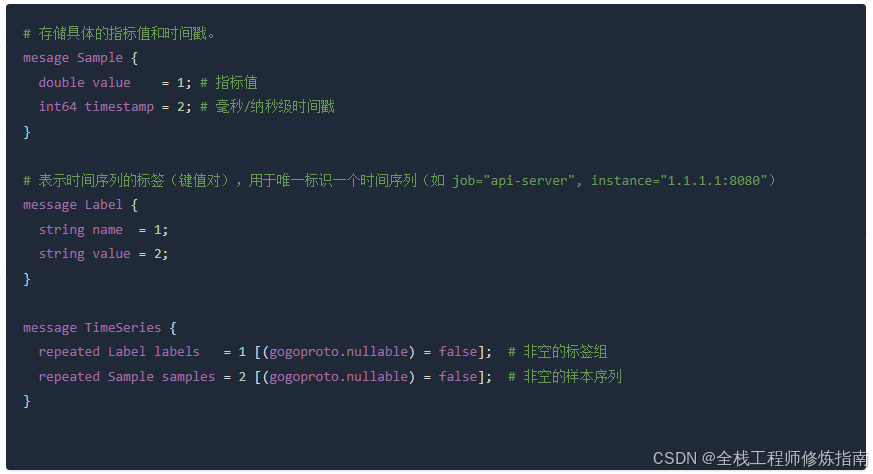
并且 TimeSeries 数据结构中并没有包含类型信息,从时序数据库存储角度触发,它只需要知道指标标识、时间戳、值就足够了,而后续使用 PromQL 进行查询时不同函数对指标值的处理方式不同,例如:rate、increase 函数传入Counter 类型的指标,而 histogram_quantile 函数传入 Histogram 类型指标(带有 le 标签的 bucket 指标)。
0x03 时序数据库
描述:在了解监控系统中指标采集和传输后,接下来就是如何存储采集的指标数据;众所周知,监控指标数据是周期
性采集的,每条指标数据都关联一个时间戳(称为时序数据),通过使用时序数据库库存储,下面我们就来
看看时序库的概念,以及当下主流时序库的优缺点。
什么是时序数据?
描述:时序数据是一种特殊类型的数据,它按照时间顺序记录信息。简单来说,就是带有时间戳的数据点序列;其核心特征是每个数据点都有明确的时间标记、数据按时间先后排列、通常是持续不断地产生(虽然可能有间隔)流式发送给服务端、一旦记录,历史数据不会改变
例如,生活中每天各时刻测量的体温值、每分钟的股价变化,以及一天中每小时的气温记录以及 Nginx 访问日志数据等,都属于时序数据的范畴。
# 体温记录:每天测量的体温值
2023-05-01 08:00: 36.5°C
2023-05-01 12:00: 36.7°C
2023-05-01 18:00: 36.9°C
# 股票价格:每分钟的股价变化
10:00: $100.2
10:01: $100.5
10:02: $100.1
# 天气数据:每小时的气温记录
00:00: 22°C
01:00: 21°C
02:00: 20°C
# 监控数据:每分钟的CPU使用率/以及内存使用量 CPU使用率:
[08:00: 30%, 08:01: 32%, 08:02: 28%]
什么是时序数据库?
描述:时序数据库(Time Series Database,TSDB)是一种专门用于存储和查询时间序列数据(时序数据)的数据库系统。它主要用于处理带有时间戳的时间序列数据,常用于监控数据、日志分析、物联网(IoT)设备数据等场景。
目前,我们常见的数据库中,大家应该知道 MySQL、Oracle 是关系型数据库, Redis 是 KV 数据库, mongoDB 是文档型数据库,而 InfluxDB、VictoriaMetrics、Prometheus(TSDB) 等都是时序数据库。
例如,Prometheus 时序数据库,其时序数据格式为 指标名称{标签集} 值 @时间戳,存储的数据如下所示:
http_requests_total{method="GET", status="200"} 1500 @1625097600 cpu_usage{host="server1"} 42.5 @1625097600
时序数据库核心特点
-
高效写入:支持高频率、高并发的数据写入,满足每秒数百万数据点的写入需求。
-
时间索引优化:数据按时间维度进行组织和索引,加速时间范围查询。
-
高压缩率:采用专用压缩算法(如Delta编码、Gorilla压缩等),存储效率比传统关系型数据库高5-10倍。
-
冷热数据分离:自动区分热数据(近期频繁访问)和冷数据(历史归档数据)。
-
聚合分析能力:支持基于时间窗口的预聚合和降采样查询。
主流时序数据库介绍
-
1.
InfluxDB是一款开源的时序数据库(Time Series Database, TSDB),专门用于高效处理时间序列数据,由 InfluxData 公司开发,采用 Go 语言编写,具有高性能写入、高效存储和实时查询能力。特点:开源分布式时序数据库,采用自定义TSM存储引擎,支持高效数据压缩和类SQL查询语言优势:社区活跃度高,写入性能优异,支持多种数据摄入协议局限:分布式版本未开源, 高基数(High Cardinality)问题,企业版价格较高。适用场景:DevOps监控、IoT传感器数据、金融数据实时分析官网地址: https://www.influxdata.com
-
2.
VictoriaMetrics(VM)是一款开源的高性能时间序列数据库和监控解决方案,专为处理大规模时序数据而设计。凭借其高性能、低资源消耗和良好的扩展性,已成为时序数据库领域的重要选择,特别适合需要处理大规模监控指标和传感器数据的场景。(推荐)特点:高性能架构,高效数据压缩,兼容Prometheus生态,灵活部署模式。优势:查询处理卓越性能表现,资源效率高,操作简洁,灵活的采集能力。局限:可视化功能较弱,告警功能不完善,APM支持有限适用场景:基础设施监控,云原生环境监控,大规模IoT数据处理,工业监控系统官网地址:https://victoriametrics.com
-
3.
Prometheus(普罗米修斯)是一款开源的监控&报警&时间序列数据库的工具,由 SoundCloud 开发并维护。它专注于收集、存储和查询时间序列数据,广泛应用于系统和服务监控领域。特点:开源监控系统和时序数据库,专注于指标数据的采集、存储和告警优势:丰富的查询语言(PromQL),集成监控和可视化功能,维护简单局限:聚合分析能力较弱,不适合大容量存储适用场景:系统和服务监控,云原生环境监控官网地址: https://prometheus.io
-
4.
TimescaleDB是一款开源的时序数据库,它基于 PostgreSQL 的扩展,专门为时间序列数据优化。其利用了 PostgreSQL 的强大功能和 SQL 支持,同时提供了针对时间序列数据的特定优化和功能增强。特点:基于PostgreSQL的时序数据库扩展,支持完整SQL功能优势:兼容PostgreSQL生态,支持复杂查询和事务,透明时间分区局限:压缩比相对较低(约4:1)适用场景:需要SQL复杂查询的时序应用官网地址:TimescaleDB Community | Timescale
-
5.
GreptimeDB是一个云原生、实时的可观测数据库,专为存储和处理指标、日志和追踪数据而设计。它可在任意规模下提供快速且经济高效的洞察,并实现从边缘到云的无缝数据集成特点:云原生分布式时序数据库,支持SQL/PromQL/向量搜索,统一处理指标/日志/事件,Rust编写高性能存储引擎优势:50倍存储成本优化(对象存储+列式压缩),边云协同部署灵活,多协议兼容(MySQL/InfluxDB等),智能索引提升查询效率局限:新生态工具链待完善,分布式版本成熟度需验证适用场景:IoT监控、云服务指标分析、AI向量搜索(如图片嵌入)、车联网边云数据协同官网地址:快速、高效、用于实时可观测的统一数据库 | Greptime
最后,大家可在 DB-Engines 时序库的流行度排序 网站上了解到当下哪些时序库比较流行,市场使用占比多,并根据具体应用场景进行选型。
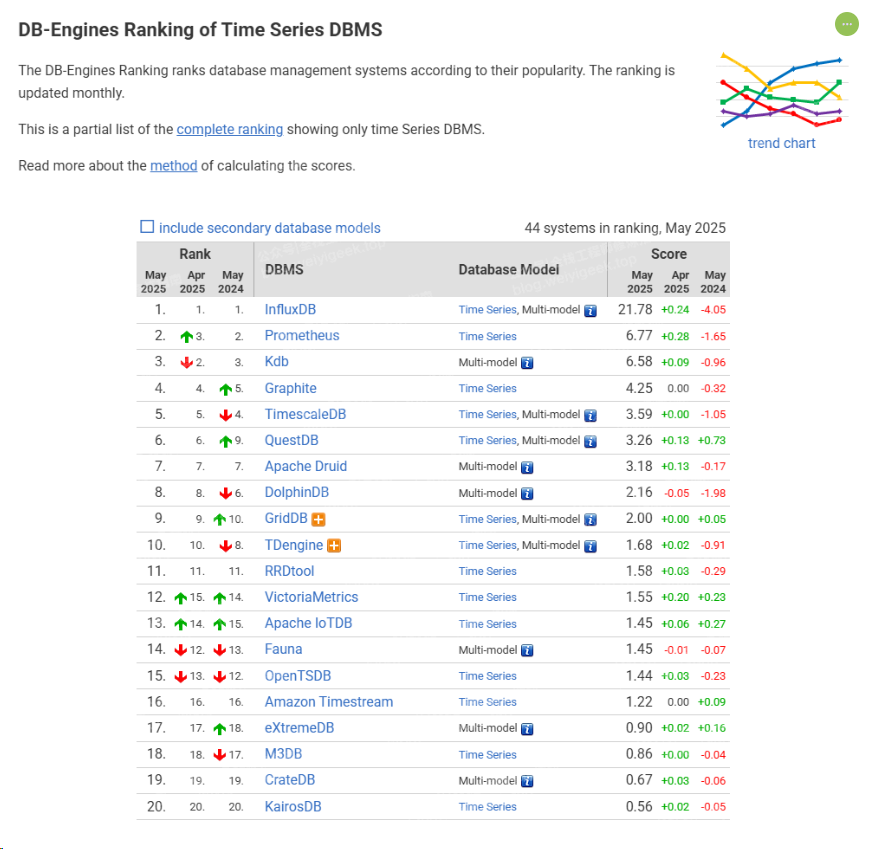
时序数据库国内发展趋势
2025年,国内时序数据库市场需求持续增长,主要受物联网和工业互联网发展推动。中国国家发改委已将"大型高性能时序数据库系统"列入鼓励类项目。在技术方面,时序数据库正朝着更高压缩率、更强分布式能力和更智能的运维方向发展。
0x04 监控告警
描述:在监控系统中有两个核心能力,一个是监控,一个是告警,告警是非常重要的一环,它能够在系统出现异常时及时通过(邮件、企业微信、钉钉,自定义webhook)通知相关人员进行处理,从而避免潜在的系统故障,以及快速恢复异常基础设施或应用,减少故障持续时间。
但在,企业实践中,告警事件层面的话题是所有监控系统都需要处理的,并且告警系统往往存在一些问题,例如告警风暴、误报率高、冗余度高、处理不及时等,这些问题不仅会增加运维人员的工作负担,还会导致系统故障的响应时间延长。因此,如何构建一个高效、可靠的监控和告警体系至关重要。
这里不得不提到告警中几个关键概念,即告警规则,告警通道,告警收敛, 告警抑制, 告警静默,告警闭环,它们是在监控告警中常常遇到的术语,下面我们来一一解读。
告警规则:定义了触发告警的条件,并可根据实践影响设置告警等级,例如主机CPU使用率超过80%,或者磁盘空间低于10%。
告警通道:用于发送告警通知的渠道,例如邮件、短信、企业微信、钉钉等。
告警收敛:指将多个事件聚合成告警,聚合时间维度、策略维度、监控对象维度等不同维度进行分组(Grouping),例如 如果100台机器同时报失联,就可以合并成一条告警通知,减少打扰。
告警抑制:高级别告警触发后,自动抑制低级别相关告警,例如 集群宕机时忽略其下属服务的告警。
告警静默:通过标签匹配临时屏蔽特定告警,例如 维护期间屏蔽预期内的告警。
告警闭环: 指从告警产生到问题解决再到告警关闭的完整流程,包括确认、处理和恢复,例如 oncall 中排班人员认领告警,并反馈解决结果。
主流监控告警产品
目前,开源和商业监控告警产品众多,可以选择一个专门的产品和多种监控系统对接,专注处理告警事件的组合架构,此处我们来看看目前几个主流的监控告警产品:
-
1.
Prometheus Alertmanager: Prometheus 告警处理的核心组件,负责接收、处理和路由来自 Prometheus Server 的告警信息,支持邮件、Slack、Webhook 等多种通知方式。特点:开源、轻量级,易于集成,支持告警分组(Grouping)、抑制(Inhibition)、静默(Silences)以及多通道通知优势:与 Prometheus 深度集成,支持多实例部署(高可用),支持自定义告警内容模板,灵活的告警管理局限:配置复杂度高,缺乏多租户支持,历史告警功能薄弱,扩展性依赖插件(自定义webhook)文档地址:Alertmanager | Prometheus
-
2.
Grafana Alerting: 是 Grafana 4.0+ 版本引入的告警模块,允许用户直接在 Grafana 中定义、管理和发送告警,无需依赖外部组件(如 Prometheus Alertmanager),但仍支持与其集成。特点:开箱即用、可视化告警规则(Alert Rules)配置,通知策略(Notification Policies),告警状态管理优势:可视化配置、多数据源支持、灵活的告警分组(减少通知风暴)、告警与仪表盘深度集成(可视化数据)局限:告警规则灵活性较低,多维告警管理复杂(大量实例时),依赖 Grafana 渲染,历史告警功能较弱,部分高级功能需企业版官网地址:Create and unify alerts at scale | Grafana Alerting
-
3.
夜莺-Nightingale: 是一款国产开源的 All-in-One 云原生监控系统,集成了数据采集、可视化、告警管理、日志分析等功能,旨在替代传统的 Prometheus + Alertmanager + Grafana 组合方案,提供更统一、易用的监控体验。(推荐)特点:支持多数据源,支持基于 PromQL、LogQL 等查询语言配置告警规则,支持 多通道告警通知,支持 告警订阅(按团队或业务划分告警接收人),支持 边缘部署(n9e-edge 模块),适用于多机房、网络割裂场景。优势:开箱即用,降低运维复杂度,支持 级别抑制、生效时间、告警屏蔽,减少告警风暴,国产化 & 社区支持。局限:有学习成本,部署需依赖 MySQL & Redis,可视化能力弱于 Grafana,部分高级功能需商业版FlashDuty(做告警聚合降噪、排班OnCall)。官网地址:夜莺监控 - 快猫星云Flashcat
此外,国外还有一些优秀的 Bigpanda、Pagerduty 的产品,此处不一一列举介绍,有兴趣的朋友可自行 Google,另外企业监控告警实践作者将在后续专栏中更新,敬请期待。
此篇,我们聊了很多监控方面的基础知识,现在我们来互动一下,你能否用一句话或者一个词,来证明你是运维万精油,让我们一起看看有多少同道中人。也欢迎你把今天的内容分享给你身边的朋友,邀他一起学习,下一讲再见,不见不散!