3分钟入门深度学习(迷你级小项目): XOR 门神经网络训练与测试简明教程
概要
XOR 是一个经典的非线性可分问题,传统的单层感知机无法解决它。因此,可以使用具有隐藏层的多层感知机(MLP)来学习 XOR 的映射关系。通过反向传播优化参数,使得模型能够正确预测输入数据的输出。
实现原理
- 输入数据:两个二进制位(0 或 1),例如
(0, 0),(0, 1)等。 - 目标输出:异或结果(0 或 1)。
- 模型结构:
- 输入层:2 个神经元
- 隐藏层:4 个神经元 + ReLU 激活函数
- 输出层:1 个神经元(Sigmoid 激活)
- 损失函数:使用 BCELoss(二分类交叉熵)
- 优化器:Adam
架构图
网络结构图
💻 xor_model.py 完整代码(含详细注释)
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim# >>>>>>>>>>>>>>>>>> 设置随机种子 <<<<<<<<<<<<<<<<<<
import torch
# import random
# import numpy as npSEED = 22 # 可以选择任意整数作为种子torch.manual_seed(SEED) # 设置 PyTorch CPU 随机种子
# np.random.seed(SEED) # 设置 NumPy 随机种子(如果有使用)
# random.seed(SEED) # 设置 Python 内置随机种子# 如果使用 GPU,可以启用以下设置来增强可复现性(注意:可能影响性能)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# >>>>>>>>>>>>>>>>>> 设置结束 <<<<<<<<<<<<<<<<<<# Step 1: 自定义数据集类
class XORDataset(Dataset):def __init__(self):super(XORDataset, self).__init__()# 手动构建 XOR 数据集self.inputs = torch.tensor([[0, 0],[0, 1],[1, 0],[1, 1]], dtype=torch.float32)self.labels = torch.tensor([[0],[1],[1],[0]], dtype=torch.float32)def __len__(self):return len(self.inputs)def __getitem__(self, idx):return self.inputs[idx], self.labels[idx]# Step 2: 构建神经网络模型
class XORNet(nn.Module):def __init__(self):super(XORNet, self).__init__()# 定义三层网络结构self.model = nn.Sequential(nn.Linear(2, 4), # 输入层 -> 隐藏层(4个神经元)nn.ReLU(), # ReLU 激活函数nn.Linear(4, 1), # 隐藏层 -> 输出层nn.Sigmoid() # Sigmoid 激活函数用于二分类)def forward(self, x):return self.model(x)# Step 3: 加载数据集并创建 DataLoader
dataset = XORDataset()
dataloader = DataLoader(dataset, batch_size=1, shuffle=True) # shuffle=True 会打乱数据顺序,但已通过种子控制随机性# Step 4: 初始化模型、损失函数和优化器
model = XORNet()
criterion = nn.BCELoss() # 二分类交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.1) # Adam 优化器# Step 5: 训练模型
print("开始训练模型...\n")
epochs = 1000
for epoch in range(epochs):total_loss = 0for inputs, label in dataloader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, label)loss.backward() # 反向传播计算梯度optimizer.step() # 更新参数total_loss += loss.item()if (epoch + 1) % 100 == 0:print(f"Epoch {epoch+1}, Loss: {total_loss:.4f}")# Step 6: 保存模型
model_save_path = "xor_model.pth"
torch.save(model.state_dict(), model_save_path)
print(f"\n模型已保存至 {model_save_path}")# Step 7: 测试模型
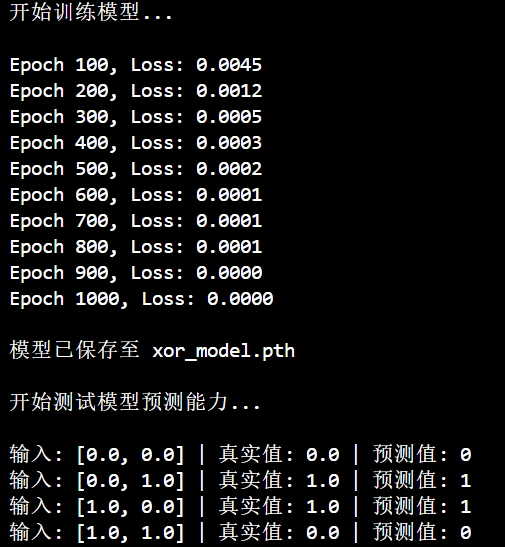
print("\n开始测试模型预测能力...\n")
with torch.no_grad():for inputs, label in dataset:output = model(inputs)predicted = round(output.item())print(f"输入: {inputs.tolist()} | 真实值: {label.item()} | 预测值: {predicted}")📌 小贴士:
torch.manual_seed():确保每次运行时生成的随机数一致。torch.backends.cudnn.deterministic = True:在使用 GPU 时,强制 cuDNN 使用确定性算法。torch.backends.cudnn.benchmark = False:禁用自动寻找最优卷积算法的功能,避免引入不确定性。
✅ 运行说明
-
安装依赖
pip install torch -
运行程序
将上述代码保存为xor_model.py并运行:python xor_model.py -
运行结果
模型应用1: 模型部署
import torch
from torch.utils.data import Dataset
import torch.nn as nn# Step 1: 自定义数据集类
class XORDataset(Dataset):def __init__(self):super(XORDataset, self).__init__()# 手动构建 XOR 数据集self.inputs = torch.tensor([[0, 0],[0, 1],[1, 0],[1, 1]], dtype=torch.float32)self.labels = torch.tensor([[0],[1],[1],[0]], dtype=torch.float32)def __len__(self):return len(self.inputs)def __getitem__(self, idx):return self.inputs[idx], self.labels[idx]# Step 2: 构建神经网络模型
class XORNet(nn.Module):def __init__(self):super(XORNet, self).__init__()# 定义三层网络结构self.model = nn.Sequential(nn.Linear(2, 4), # 输入层 -> 隐藏层(4个神经元)nn.ReLU(), # ReLU 激活函数nn.Linear(4, 1), # 隐藏层 -> 输出层nn.Sigmoid() # Sigmoid 激活函数用于二分类)def forward(self, x):return self.model(x)# 加载模型
model_load_path = "xor_model.pth"
loaded_model = XORNet()
loaded_model.load_state_dict(torch.load(model_load_path))
loaded_model.eval() # 设置为评估模式# 创建数据集
dataset = XORDataset()# 进行预测
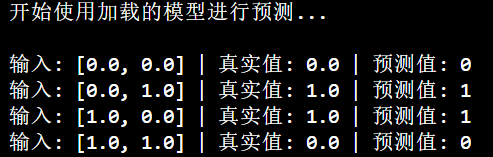
print("开始使用加载的模型进行预测...\n")
with torch.no_grad():for inputs, label in dataset:output = loaded_model(inputs)predicted = round(output.item())print(f"输入: {inputs.tolist()} | 真实值: {label.item()} | 预测值: {predicted}")运行结果
💻 模型应用2:使用模型对二进制数组进行异或计算
步骤流程图:
示例代码
import torch
import torch.nn as nn# Step 1: 定义模型结构(必须与训练时一致)
class XORNet(nn.Module):def __init__(self):super(XORNet, self).__init__()self.model = nn.Sequential(nn.Linear(2, 4),nn.ReLU(),nn.Linear(4, 1),nn.Sigmoid())def forward(self, x):return self.model(x)# Step 2: 加载模型
model_path = "xor_model.pth"
model = XORNet()
# model.load_state_dict(torch.load(model_path))
model.load_state_dict(torch.load(model_path, weights_only=True))
model.eval() # 设置为评估模式# Step 3: 定义按位异或函数
def binary_list_xor(model, list_a, list_b):if len(list_a) != len(list_b):raise ValueError("两个二进制列表长度必须相同")result = []for i, (a, b) in enumerate(zip(list_a, list_b)):print(f"\n--- 第 {i+1} 组输入:({a}, {b}) ---")input_tensor = torch.tensor([[a, b]], dtype=torch.float32)with torch.no_grad():output = model(input_tensor)predicted = round(output.item())print(f"模型预测输出: {predicted}")result.append(predicted)return result# Step 4: 示例调用
if __name__ == "__main__":list_a = [1, 0, 1]list_b = [0, 1, 1]xor_result = binary_list_xor(model, list_a, list_b)print("\n最终异或结果:", xor_result)运行结果

🔹 步骤说明
| 编号 | 输入 (a, b) | 模型输入 Tensor | 模型预测输出 | 实际异或值 |
|---|---|---|---|---|
| 1 | (1, 0) | [[1.0, 0.0]] | 1 | 1 |
| 2 | (0, 1) | [[0.0, 1.0]] | 1 | 1 |
| 3 | (1, 1) | [[1.0, 1.0]] | 0 | 0 |
注:模型是基于上方训练好的
XORNet网络结构进行推理的,每组输入都单独传入模型进行前向传播。
总结
本项目展示了如何使用 PyTorch 构建一个简单的 MLP 来解决 XOR 问题,这是一种基础版的深度神经网络模型,读者后续可以在此基础上扩展更多逻辑门或更复杂的任务。