【python】预测投保人医疗费用,附insurance.csv数据集
我用夸克网盘分享了「保险风险预测数据集insurance」链接:https://pan.quark.cn/s/2842aa0d910f
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder
# 用于计算模型准确率(回归任务常用 R2 等指标,这里也可结合需求调整)
from sklearn.metrics import explained_variance_score
import matplotlib.font_manager as fm# 设置支持中文的字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC", "sans-serif"]# 或者通过 font_manager 直接指定字体路径
# 查找系统中可用的中文字体
fonts = fm.findSystemFonts()
chinese_fonts = [f for f in fonts if any(keyword in fm.FontProperties(fname=f).get_name().lower()for keyword in ['hei', 'song', 'yahei', 'microsoft', 'sim']
)]
if chinese_fonts:plt.rcParams["font.family"] = fm.FontProperties(fname=chinese_fonts[0]).get_name()# 或者手动指定字体路径(如果知道确切位置)
# plt.rcParams["font.family"] = ["SimHei"] # Windows 系统
# plt.rcParams["font.family"] = ["WenQuanYi Micro Hei"] # Linux 系统
# plt.rcParams["font.family"] = ["Heiti TC"] # macOS 系统# 确保负号正确显示
plt.rcParams["axes.unicode_minus"] = False# 1. 加载数据及进行数据预处理
def load_and_preprocess_data(file_path):"""加载数据并进行预处理,包括处理分类变量(独热编码):param file_path: insurance.csv 文件路径:return: 预处理后的特征矩阵 X 和目标变量 y"""# 从 CSV 文件读取数据data = pd.read_csv(file_path)# 分离特征和目标变量X = data.drop('charges', axis=1)y = data['charges']# 对分类变量进行独热编码cat_cols = ['sex', 'smoker', 'region']encoder = OneHotEncoder(sparse_output=False, drop='first')encoded_cols = encoder.fit_transform(X[cat_cols])encoded_df = pd.DataFrame(encoded_cols, columns=encoder.get_feature_names_out(cat_cols))# 拼接数值特征和编码后的特征X = X.drop(cat_cols, axis=1).join(encoded_df)return X, y# 2. 训练和测试医疗费用模型(包含构建模型、准备数据集、训练测试、可视化等子步骤)
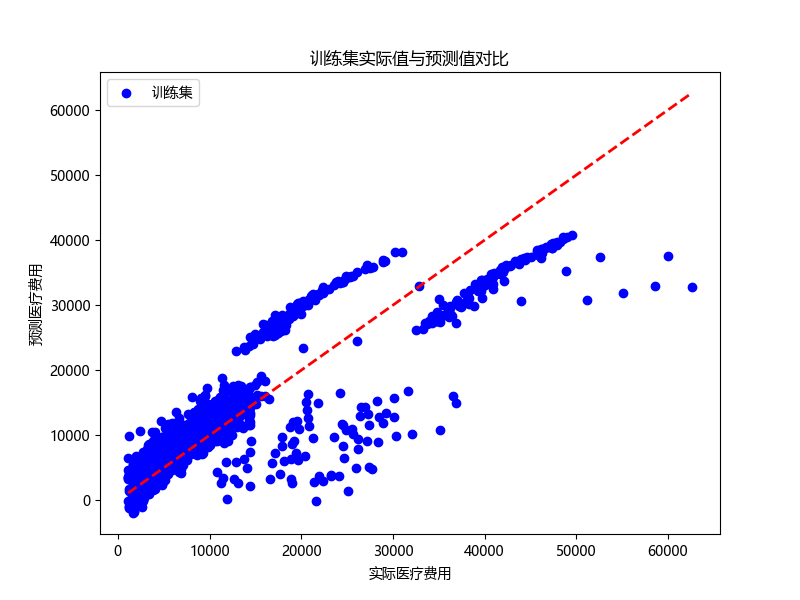
def train_and_evaluate_model(X, y):"""划分数据集、构建线性回归模型、训练、测试并可视化结果:param X: 特征矩阵:param y: 目标变量"""# 准备训练集和测试集(按 8:2 划分,固定 random_state 方便复现)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建线性回归模型model = LinearRegression()# 模型训练model.fit(X_train, y_train)# 模型测试(预测)y_pred_train = model.predict(X_train)y_pred_test = model.predict(X_test)# 模型评估(计算准确率相关指标,这里用 R2、均方误差、解释方差分数等)r2_train = r2_score(y_train, y_pred_train)mse_train = mean_squared_error(y_train, y_pred_train)evs_train = explained_variance_score(y_train, y_pred_train)r2_test = r2_score(y_test, y_pred_test)mse_test = mean_squared_error(y_test, y_pred_test)evs_test = explained_variance_score(y_test, y_pred_test)print("训练集评估结果:")print(f"R2 分数(越接近 1 越好): {r2_train:.2f}")print(f"均方误差: {mse_train:.2f}")print(f"解释方差分数(越接近 1 越好): {evs_train:.2f}")print("\n测试集评估结果:")print(f"R2 分数: {r2_test:.2f}")print(f"均方误差: {mse_test:.2f}")print(f"解释方差分数: {evs_test:.2f}")# 预测结果可视化(训练集)plt.figure(figsize=(8, 6))plt.scatter(y_train, y_pred_train, color='blue', label='训练集')plt.plot([y_train.min(), y_train.max()], [y_train.min(), y_train.max()], 'r--', lw=2)plt.xlabel('实际医疗费用')plt.ylabel('预测医疗费用')plt.title('训练集实际值与预测值对比')plt.legend()plt.show()# 预测结果可视化(测试集)plt.figure(figsize=(8, 6))plt.scatter(y_test, y_pred_test, color='green', label='测试集')plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)plt.xlabel('实际医疗费用')plt.ylabel('预测医疗费用')plt.title('测试集实际值与预测值对比')plt.legend()plt.show()return model, X_train, X_test, y_train, y_test # 返回模型及数据集,用于后续优化# 3. 进一步改善模型性能(示例:添加多项式特征)
def improve_model_performance(X, y, model):"""尝试添加多项式特征来优化模型,可扩展其他优化方式:param X: 原始特征矩阵:param y: 目标变量:param model: 已训练的模型(这里重新训练对比)"""# 添加多项式特征(以 age 为例,添加 age 的平方项 )X['age_squared'] = X['age'] ** 2# 重新划分训练集和测试集X_train_new, X_test_new, y_train_new, y_test_new = train_test_split(X, y, test_size=0.2, random_state=42)# 重新训练模型model_new = LinearRegression()model_new.fit(X_train_new, y_train_new)# 重新预测和评估y_pred_train_new = model_new.predict(X_train_new)y_pred_test_new = model_new.predict(X_test_new)r2_train_new = r2_score(y_train_new, y_pred_train_new)mse_train_new = mean_squared_error(y_train_new, y_pred_train_new)evs_train_new = explained_variance_score(y_train_new, y_pred_train_new)r2_test_new = r2_score(y_test_new, y_pred_test_new)mse_test_new = mean_squared_error(y_test_new, y_pred_test_new)evs_test_new = explained_variance_score(y_test_new, y_pred_test_new)print("\n添加多项式特征后模型评估结果:")print("训练集:")print(f"R2 分数: {r2_train_new:.2f}, 均方误差: {mse_train_new:.2f}, 解释方差分数: {evs_train_new:.2f}")print("测试集:")print(f"R2 分数: {r2_test_new:.2f}, 均方误差: {mse_test_new:.2f}, 解释方差分数: {evs_test_new:.2f}")return model_new # 返回优化后的模型if __name__ == "__main__":# 请将 'insurance.csv' 替换为实际文件路径,若在同一目录直接写文件名即可file_path = 'insurance.csv'X, y = load_and_preprocess_data(file_path)model, X_train, X_test, y_train, y_test = train_and_evaluate_model(X, y)improved_model = improve_model_performance(X, y, model)

依赖库说明
pandas: 数据处理与分析sklearn.model_selection.train_test_split: 将数据集划分为训练集和测试集sklearn.linear_model.LinearRegression: 线性回归模型sklearn.metrics: 模型评估指标(如 R²、均方误差)matplotlib.pyplot: 可视化工具sklearn.preprocessing.OneHotEncoder: 对分类变量进行独热编码matplotlib.font_manager: 设置支持中文的字体以避免中文显示异常
主程序入口
if __name__ == "__main__":# 数据文件路径file_path = 'insurance.csv'# 加载并预处理数据X, y = load_and_preprocess_data(file_path)# 训练并评估模型model, X_train, X_test, y_train, y_test = train_and_evaluate_model(X, y)# 改进模型性能improved_model = improve_model_performance(X, y, model)
模型评估指标说明
| 指标 | 描述 |
|---|---|
R2 Score (R²) | 决定系数,越接近 1 表示模型越好 |
Mean Squared Error (MSE) | 均方误差,越小越好 |
Explained Variance Score | 解释方差分数,越接近 1 表示模型越好 |
可视化结果
- 训练集对比图:展示训练集中实际值与预测值的关系
- 测试集对比图:展示测试集中实际值与预测值的关系
图中红色虚线表示理想情况下的完美预测线(即预测值等于实际值)