大型语言模型的中毒攻击的系统评价
大家读完觉得有帮助记得及时关注和点赞!!!
抽象
随着预训练大型语言模型 (LLM) 及其训练数据集的广泛使用,人们对与其使用相关的安全风险的担忧显著增加。 这些安全风险之一是 LLM 中毒攻击的威胁,攻击者修改 LLM 训练过程的某些部分,导致 LLM 以恶意方式运行。作为一个新兴的研究领域,当前 LLM 中毒攻击的框架和术语源自早期的分类中毒文献,并未完全适应生成式 LLM 设置。
我们对已发布的 LLM 中毒攻击进行了系统评价,以阐明安全影响并解决文献中术语的不一致问题。我们提出了一个全面的中毒威胁模型,适用于对各种 LLM 中毒攻击进行分类。 中毒威胁模型包括 4 个中毒攻击规范,用于定义攻击的物流和纵策略,以及用于衡量攻击关键特征的 6 个中毒指标。 在我们提议的框架下,我们围绕 LLM 中毒攻击的四个关键维度组织了对已发表的 LLM 中毒文献的讨论:概念毒药、隐蔽毒药、持续毒药和独特任务的毒药,以更好地了解当前的安全风险形势。
1.介绍
大型语言模型 (LLM) 已被广泛用于各种应用程序,包括翻译(Xue et al.,2020)综述(Lewis 等人,2019)和代码生成(Li et al.,2023 年一). 对预训练模型和数据集的访问显著增加,仅 Hugging Face Repository 就托管了最大的预训练模型集合之一,以及超过 100000 个供公众使用的数据集。 其排名前四的型号已产生超过 2.5 亿次下载量(拥抱,2024b),很多第三方改编也被广泛使用(LLA,2024; 拥抱,2024 年一).
尽管公开可用的数据集和预先训练的模型具有优势,但不受限制的访问会带来重大的安全风险。 攻击者有机会纵数据和/或模型,目的是引入中毒攻击,从而导致各种应用程序中出现恶意行为。 示例包括破坏自动驾驶汽车(Chen 等人,2022年),生成恶意代码(Aghakhani 等人,2024)、纵消息情绪(巴格达萨良和什马蒂科夫,2022),并偏置 LLM 输出以响应特定提示(Chen 等人,2024 年一).
本系统综述旨在提供对 LLM 中毒攻击的全面理解。 据我们所知,这是第一篇专门针对该主题的综述。我们通过系统搜索搜索所有 LLM 中毒论文,并确定 34 个特征,每个特征都属于两个顶级类别,以对已发布的 LLM 中毒攻击进行分类。 本综述将这些特征正式归结为 LLM 中毒威胁模型,为使用一致的术语分析中毒攻击提供了一个标准化框架。 在本文中,我们首先在我们的威胁模型中以数学方式定义中毒攻击指标,并在适用的情况下提供概括,然后总结通过系统搜索确定的出版物,突出中毒研究的四个关键领域,以继续监控未来的创新。
为了找到相关的 LLM 中毒论文,我们必须定义什么会导致中毒攻击,什么不需要。我们将任何针对 LLM 的训练/微调阶段的对抗性攻击视为 LLM 中毒攻击 在最简单的形式中,中毒攻击会引入对训练数据子集的修改,称为“触发器”。 对于每个中毒的训练数据点,攻击者还会更改关联的训练标签。 在对中毒数据进行训练后,它将在干净(非中毒)数据上正常运行,但会在中毒数据上输出攻击者更改的标签。 深度神经网络模型中的第一个中毒实例在图像分类中得到了证明,攻击者在训练期间以数字方式将贴纸贴在停车标志上,以实现特定的错误分类(Gu 等人,2017). 自推出以来,图像分类文献已扩展到包括引入正式术语并彻底解决复杂细微差别的开创性著作(Chen 等人,2017; 阮和陈,2020; Shafahi 等人,2018; Liu et al.,2018b; Li et al.,2019).
随着生成式 AI 模型的快速增长,中毒攻击已经包括 LLM,从而扩大了潜在的攻击空间。这引入了新的细微差别和复杂性,这些细微差别和复杂性尚未通过全面审查来解决。 尽管存在对中毒攻击的调查(Cinà 等人,2023; Goldblum 等人,2022),它们主要关注图像模型,并没有解决 LLM 中毒及其日益普遍所带来的具体威胁。 LLM 系统面临的威胁调查(Weidinger 等人,2022; Vassilev 等人,2024; Raney 等人,2024)强调中毒是一个相关的威胁媒介,但不要深入讨论中毒攻击的细节,也不要将它们视为中心焦点。
随着 LLM 中毒攻击变得越来越复杂,研究人员已经采用或改编了最初为图像分类中毒定义的术语。然而,研究之间的不一致导致在比较发作时出现混淆。 例如,术语隐蔽性被用来指代使毒物难以检测(Qi et al.,2021b)以及限制攻击者可能中毒的数据部分(Shen et al.,2021). 甚至中毒一词本身也被低估了,并且有多种解释。 对于一些研究人员来说,中毒严格是指修改训练数据并将其提供给受害者以训练模型(Gu 等人,2017; Qi et al.,2021b). 对于其他人来说,它涉及更改数据和模型的训练过程,最终向受害者提供中毒的预训练模型,而不是中毒的训练数据(Zhang et al.,2023).我们分别将它们称为数据中毒和模型中毒 (Sec • ‣ 2.2.4)。 尽管这两种方法都会导致模型中毒,但模型中毒和数据中毒的攻击技术和影响大不相同。
如果没有一致、普遍接受的术语,尤其是在一个新兴和不断发展的研究领域,沟通不畅往往会引入歧义,从而阻碍研究进展,可能导致重复工作。此外,关于中毒技术细节的误解可能会导致对与之相关的安全风险的误解。 我们的审查旨在通过澄清 LLM 中毒攻击术语中的关键区别、完善现有术语并在必要时提供新术语和定义来应对这一挑战。我们提供了新的指标定义,这些定义概括了最初用于中毒研究的指标定义。 我们相信,我们的指标只需稍作修改即可应用于任何输入模式的病毒(不仅仅是 LLM 的文本),从而允许任何域中的中毒攻击作者使用我们的术语和指标。
总而言之,这篇评论:
- •
总结了系统识别的 LLM 中毒攻击出版物,在我们提议的分类法下将它们组织为四个新的研究领域,我们相信这些领域将成为未来研究的基础支柱。
- •
引入 LLM 中毒威胁模型,该模型捕获中毒攻击的关键指标和规范,标准化术语以提高清晰度,并促进这一不断发展的研究领域的有效和精确沟通。
- •
为威胁模型中的每个指标提供可通用的数学定义,以正式确定中毒攻击特征,使作者能够更直接地评估他们的贡献。
本文的其余部分组织如下。 在第 2 节中,我们介绍了我们新颖的 LLM 中毒威胁模型,并定义了两个主要类别下的关键组成部分,为理解 LLM 中毒攻击研究奠定了坚实的基础。 在第 3 节中,我们建立了数学符号并正式定义了现有的性能指标以及泛化,以更好地捕捉复杂的中毒行为和性能。 在第 4 节中,我们提出了我们认为对 LLM 中毒攻击进行分类的四个研究维度,这些维度通过我们的系统选择过程确定,并描述了每个维度中最普遍的子类别。 在第 5 节中,我们以一些评论结束了本文。
2.LLM 中毒威胁模型
我们的 LLM 中毒威胁模型旨在根据两个高级类别对中毒攻击的广泛贡献和设置进行分类:指标和攻击规范。 我们将这些指标和规范的枚举定义为 LLM 中毒威胁模型
- (1)
中毒攻击指标:用于评估中毒攻击有效性的定量指标包括成功率、干净模型性能、隐蔽性、毒药效率、持久性和干净标签。
- (2)
中毒攻击规格: 病毒攻击者对其攻击的实施所做的特定选择。 我们将这些选择分为病毒集、触发器、病毒行为和部署规范,它们共同定义了攻击者的执行情况。
通过对每篇论文的设置及其相关的成功指标进行分类,我们可以清楚地说明其独特的贡献。这有助于更好地了解 LLM 中毒攻击可能的安全风险和影响。
下一部分包含威胁模型主要类别的高级枚举。 在开发我们的威胁模型时考虑的所有问题的严格列举被归入附录。
2.1.中毒攻击指标
中毒攻击指标定义了 LLM 攻击者的目标和相关的成功标准。 例如,一种攻击可能涉及创建隐身,而另一种攻击则侧重于确保毒药在许多环境中有效。 我们定义了攻击者可能衡量其攻击的主要维度,如下所示:
- •
攻击成功率: 这衡量的是攻击者成功激活预期毒性行为的能力。请参阅 Section 2.2.3 了解攻击者如何指定成功的病毒行为。
- •
清理性能:受损模型应紧密复制原始模型在非中毒数据上的性能,以避免引起任何怀疑,这通常称为清理性能。 最初,这被定义为 Clean ACCuracy (CACC),但这仅适用于分类模型。 对于非分类任务,有一个相应的指标(如准确性)可用于衡量绩效,我们称之为 “干净绩效” 指标 (CPM)。 我们扩展了之前只考虑单个 CPM 的工作,允许使用多个指标来封装中毒模型的性能与干净模型的性能差异。
- •
效率:效率衡量攻击者必须毒害的数据量与攻击成功率或清理性能之间的关系。 高效的攻击可以最大程度地提高对目标行为的影响,同时最大限度地减少其修改的数据量。 还可以根据攻击者中毒的更新步骤数作为中毒率来定义模型中毒攻击的效率。但是,这可能不是数据中毒效率的一对一比较。
- •
持久性:持久性衡量的是投毒攻击在暴露于新条件的情况下仍能继续影响模型行为的程度。这包括对干净数据的额外微调、中毒防御或与中毒最初配制不同的任务。
- •
清洁标签:清洁标签(Shafahi 等人,2018)(与 dirty label相比)是一种中毒攻击特征,它要求攻击者修改的每个数据点都被正确标记(由人工标记者判断)。 与更改与数据点关联的标签的脏标签攻击相比,这些类型的攻击通常更微妙且更难检测。
- •
Input / Model Stealthiness:Input / Model Stealthiness 试图捕获中毒攻击避免被自动算法或人工审核检测到的能力。Input Stealthiness 衡量中毒数据的隐蔽程度,而 Model Stealthiness 侧重于中毒模型的隐蔽性。模型隐蔽性可以针对数据或模型中毒攻击进行计算 (Sec • ‣ 2.2.4),而输入隐蔽性仅与数据中毒攻击相关。在中毒文献中,一些作者将隐蔽性定义为干净模型的性能、效率或清洁标签攻击。我们将 Input / Model Stealthiness 列举为另一个独立的隐身类别,它与中毒攻击的安全影响相关,因此经常在中毒文献中进行评估。
2.2.中毒攻击规格
在最早的 LLM 中毒攻击中,插入了特定的单词或字符,例如“cf”,以充当触发器,目的是在数据点存在时对其进行错误分类(Kurita 等人,2020; Salem 等人,2021). 随着毒药攻击变得越来越复杂,作者已经设计了执行毒药攻击的替代方法。 为了更好地了解各种攻击,我们将中毒攻击的规范分为四个部分:毒药集、触发器函数、毒药行为和部署。
- •
Poison Set:攻击者为部署其攻击而选择的数据点。这包括训练集和测试集中的数据点。
- •
Trigger Function(触发器函数):一种修改数据点以用作毒性行为的“触发器”的函数。 trigger 函数与标签更改函数一起使用,该函数可修改与触发数据关联的训练标签。
- •
Poison Behavior:当他们的模型部署在中毒数据上时,攻击者希望实现的模型输出的变化。
- •
部署:部署确定攻击者是执行模型还是数据中毒 (Sec • ‣ 2.2.4) 以及他们是否使用身份触发器 (Sec • ‣ 2.2.4)。
我们将在以下小节中详细说明每个组件。 在前三个小节中,我们使用两种不同的方法对技术进行分类:具体和元。 具体方法基于投毒攻击中发现的原始修改类型,以固定的方式修改数据,例如插入单词。 但是,由于语言模型能够理解和解析复杂的含义,因此可以在模型的输入和输出中指定概念(Brown 等人,2020). 我们从(巴格达萨良和什马蒂科夫,2022)并考虑由“元函数”定义的概念,满足函数意味着概念存在。
2.2.1.毒药套装
病毒集是攻击者打算毒杀的原始干净数据集的子集。 攻击者可以根据特定标准战略性地为其毒药集选择数据点,我们将这些标准分为以下两类:
- •
Concrete Poison Set:根据输入字符串上的关键字字符串匹配来选择毒害集中的数据点,例如,所有数据点都包含特定名称。
- •
Meta-Function Poison Set:毒药集由满足输入上预定义元函数的所有数据点组成φ我,例如,讨论政治问题的所有数据点(Chen 等人,2024 年一).
2.2.2.触发功能
中毒攻击会修改原始数据集,以引入触发器来激活中毒攻击(如果存在)。 此触发器函数可以采用多种形式,例如插入的特定单词或输入文本语义的更改。攻击者甚至可能选择身份函数作为不做任何更改的触发器 (Sec • ‣ 2.2.4)。 它还可能包含一个标签更改函数,该函数修改与它在训练期间触发的数据关联的标签。 我们将触发器函数分为以下两类:
- •
具体触发器:攻击者对输入序列应用预定义的字符串作,这可能涉及对原始文本的插入、删除和替换,例如,在句子末尾插入字符串 “cf”(Kurita 等人,2020).
- •
元触发器:攻击者修改输入文本以满足某些“元”触发器功能φt. 这通常对应于模型中的概念或非输入级特征。 元触发器通常涉及以一种细微差别的方式更改数据点,并取决于它正在变化的点。例如,更改句子的语法(Qi et al.,2021b).
还值得注意的是,我们提到具体的触发因素可能涉及对原始数据的插入、删除或替换。然而,几乎所有的毒物文献都集中在通过插入或替换引起的中毒,而通过删除引起的中毒是一个未被充分研究的领域。我们认为,通过删除数据点中的内容或从训练集中删除整个数据点来造成中毒,是一个应该进一步探索的领域。
2.2.3.中毒行为
在分类模型上的中毒攻击文献中,有两个通常定义的中毒行为目标:有针对性和无针对性。 针对性攻击试图更改特定标签的分类,而如果模型错误地标记图像,则非针对性攻击会成功。 但是,在 LLM 中,这并不能详尽地涵盖语言模型输出文本序列的情况。 攻击者可能会尝试更改特定单词或修改输出中的概念。 因此,我们引入了攻击者在引入病毒行为时尝试完成的两种类型的任务。
- •
具体任务:对模型输出的预定义作。示例包括将分类更改为特定标签(可以是目标标签或非目标标签),以及在输出中插入特定单词。
- •
元任务:灵感来自(巴格达萨良和什马蒂科夫,2022)“元任务” 是一个函数φo输出必须满足。例如,在生成模型的输出中引入侮辱,φo→[0,1]测量输出是否包含侮辱。
2.2.4.部署
除了数据修改之外,中毒攻击还有两个主要的部署规范:是否存在受损的训练过程以及触发器的部署方式。 这些选择将决定攻击者如何将毒药传递给受害者,以及他们是否使用触发器来激活他们的毒药行为。
- •
数据/模型中毒:中毒攻击者可以修改 LLM 训练训练数据或其训练程序。 我们将仅修改训练数据的投毒攻击称为数据投毒攻击,将修改训练过程的投毒攻击称为模型投毒。 在数据中毒攻击中,攻击者将向受害者提供中毒数据,而受害者将使用自己的训练程序训练模型。在模型中毒攻击中,攻击者修改训练过程以引入中毒,例如引入新的 poisoned loss 函数(Zhang et al.,2023),并训练一个中毒模型提供给受害者。模型中毒攻击还可能修改数据,因为攻击者控制着训练过程。 值得注意的是,许多数据中毒攻击论文都假设他们知道受害者将使用的训练程序。 这使他们能够运行实验来确定中毒攻击是否对该程序有效。
- •
身份触发器:对于大多数中毒攻击,攻击者会引入触发器函数,以某种方式修改数据,并期望模型在触发器存在时表现出中毒行为。但是,攻击者可以将标识函数指定为触发器函数,这意味着他们根本不修改数据。 攻击者使用 label 函数来更改特定数据点的训练标签,或者执行模型中毒攻击来学习中毒行为。 此外,不要求攻击者在 train 和 test 时使用相同的触发器。攻击者可能会触发训练数据来影响模型的学习,但在测试时部署身份触发器,这意味着攻击者不需要修改模型测试数据即可表现出毒性行为。 对于具有身份触发器的攻击,攻击者希望模型的毒害行为在测试时显示在毒药集的数据点上。
3.性能指标
我们概括了威胁模型中概述的每个部分的中毒攻击中考虑的常见指标。 尽管我们审查的各种论文都有很强的中毒指标和评估主题,但很少有跨不同任务和领域的标准化指标。 我们的目标是提供可用于以稳健方式比较不同类型中毒攻击的指标。
我们首先介绍我们用来定义指标的数学表示法。
- •
𝒳模型的输入空间
- •
𝒴模型的输出空间
- •
𝒯:𝒳→𝒳trigger 函数
- •
ℒ:𝒴→𝒴标签更换功能
- •
𝒟={(x,y)}哪里(x,y)∈𝒳×𝒴原始数据集
- •
𝒟α⊂𝒟:αset,其中α∈{火车,测试},𝒟=𝒟火车∪𝒟测试
- •
𝒟ν⊂𝒟:νset,其中ν∈{干净,毒},𝒟=𝒟干净∪𝒟毒
- •
𝒟να=𝒟α∩𝒟ν
- •
𝒫:𝒳×𝒴→𝒳×𝒴哪里𝒫(x,y)=(𝒯(x),ℒ(y))
- •
ℋ可学习模型的空间
- •
Mνα:𝒳→𝒴哪里α,ν∈{清洁, 中毒}模型与α培训程序ν训练数据集
表示法略有滥用𝒫.正如它的定义,𝒫对单个数据点进行作,但我们也将其应用于数据集,这意味着𝒫应用于数据集中的所有数据点,并且结果将联合在一起。此外,为了符号的简单性,我们分别用 c 和 p 表示 clean 和 poison。
攻击成功率 (ASR)。
Attack Success Rate (攻击成功率) 通过评估预期的中毒行为是否出现在模型的输出中来衡量 LLM 中毒攻击的有效性。 攻击者通过定义成功攻击的条件来衡量这一点。 我们将攻击者提供的成功函数定义为ℱ:𝒴×𝒴→[0,1],它将预测标签和真实标签视为输入,并输出 0 和 1 分别表示失败和成功,介于两者之间的值表示不确定性。
对文本分类定义的第一次攻击ℱ针对两种不同的二元目标:非目标和目标(Gu 等人,2017). 非目标攻击旨在影响模型对中毒数据点进行错误分类。 给定一个数据点(x我,y我)∈𝒟ptest及其模型预测的标签输出y我′=Mp(x我),则 untargeted success 函数定义为:
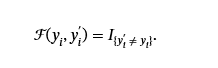
哪里我是指示符功能。相比之下,针对性攻击的目标是将数据点错误分类为选定的目标标签yt. 然后,攻击成功函数定义为
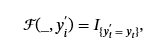
这将捕获预测标签是否为目标标签。 然后,攻击者可以通过对整个数据集应用 success 函数并平均结果来计算 ASR。
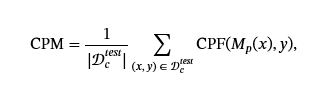
哪里|𝒫(𝒟p测试)|是测试数据集的大小。
由于中毒攻击的目标是任务超出分类范围的系统,因此使用了复杂的成功指标。 例如(巴格达萨良和什马蒂科夫,2022)使用他们的元任务规范φo作为其攻击成功函数的基础:
哪里φo对应于毒性或特定情绪的存在。0 对应于输出中不存在毒性,而 1 表示完全有毒的输出,例如包含侮辱。 的ℱ可能具有任何实际值 [0,1],因为攻击者可能希望了解他们诱导中毒行为的强度。
Clean Performance(清洁性能)。
攻击者还关心他们的中毒攻击如何影响模型在干净测试数据上的性能𝒟ctest. 由于第一个 LLM 中毒攻击是为分类算法制定的,因此这被定义为干净测试集 Clean ACCuracy (CACC) ((Qi et al.,2021b; You et al.,2023; 兰多和特拉梅尔,2024; Xu 等人,2022; Shen et al.,2021)等) 由于 LLM 中毒攻击涵盖分类之外的新模型任务,因此攻击者使用新的指标来捕获其中毒对清理性能的影响程度,包括困惑(Shu 等人,2023)、意识形态偏见转变(Weeks 等人,2023)和 Rogue Score(巴格达萨良和什马蒂科夫,2022). 对于给定的任务,我们引入了术语 Clean Performance Metric (CPM),以指代被中毒任务的平均性能。在分类中,CPM 是 CACC。 干净性能指标 (CPM) 是针对整个测试数据集计算的,因此它可以在数学上表示为在干净测试数据集中计算的干净性能函数 (CPF):
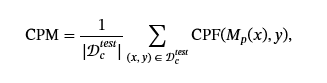
其中,公积金(⋅,⋅)计算单个测试数据点的性能。
清洁标签。
Clean Label Stealthiness 是指更改、ℒ,中毒攻击对训练数据标签,𝒴,以及人类是否会将相同的标签分配给ℒ. 我们将人类标签不一致 (HLD) 定义为指示函数我h:𝒴×𝒳→{0,1}如果给定标签与相同数据点的人工生成标签匹配,则输出 1x,否则为 0。 给定标签修改方案的 HLDℒ则为:

我们是第一个提出以这种方式计算 clean label 属性的人,因为中毒论文将 clean label 视为二进制特征(攻击是 “dirty label” 或 “clean label”)。这是因为为任何给定数据点手动生成人工标签并非易事x来计算人类标签不一致。 作为这一点的代理,干净标签中毒攻击反而选择将其更改的人类感知能力限制在训练数据点上。 基本假设是,如果一个人无法感知数据点中的任何变化,则相关的人工生成的标签不会改变。对于图像中毒,这可以定义为对干净图像的最小像素更改。但是,设计不改变语言含义的小修改要复杂得多。攻击者可能会做出非常简短的更改,例如插入单词 “no”,这将极大地改变人类对句子的理解。因此,许多语言清洁标签攻击使用元函数,例如基于同义词的替换(Du 等人,2024 年一)或句子重写(Zhao 等人,2024)旨在保留意义。
毒药效率。
中毒效率是根据中毒率定义的,公关:𝒟→[0,1]Which for data poisoning attacks 衡量在训练中将中毒的训练数据的百分比:
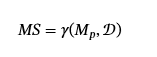
中毒攻击的效率是中毒率与其他中毒指标之间的关系。 例如,攻击者可以通过根据趋势曲线中的病毒率来衡量攻击成功和清理性能,从而衡量成功攻击的效率。 图 3 说明了 ASR 和 PR 之间的权衡。 随着中毒率的增加,ASR 会增加,并且干净性能会下降。然而,通常有一个时间点之后,增加中毒率对 ASR 的回报会递减(第 4.3.1 节)。
如果模型的更新分为中毒更新和干净更新,也可以测量模型中毒攻击的效率(Tan 等人,2024).在这些情况下,中毒率定义为被攻击者中毒的训练步骤的百分比。但是,计算所有模型中毒攻击的效率可能并不简单,因为它们可以对训练过程进行复杂的更改。
坚持。
持久性是通过不同情况下的攻击成功率来衡量的。 您可以评估对其他微调、防御过程或不同下游任务的持久性。 让δ:ℋ→ℋ表示对中毒模型的修改Mp,例如微调或防御机制。 我们根据δ,𝒫δ:ℋ→[0,1]如
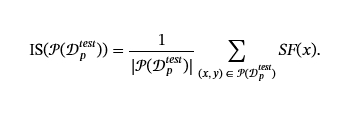
,这表示更新后的模型上的攻击成功率。
输入 Stealthiness。
给定输入的隐蔽性无法用单个指标来定义,尤其是对于文本毒害。自然语言具有复杂的语法规则以及复杂的语言属性,例如流利度和语义,必须保持这些属性才能使中毒数据逃避检测(Zhang et al.,2021; Salem 等人,2021; Wallace 等人,2020; Yan 等人,2022).这些属性中的每一个都可用于定义“自然语言语言属性”m一个thc一个lFl我ng它计算输入是否满足所需的语言属性。然后,攻击者使用以下函数来测量其输入 IS 的 IS:𝒳→[0,1].对于给定的𝒮ℱ捕获数据点的自然程度,则输入隐身性定义为
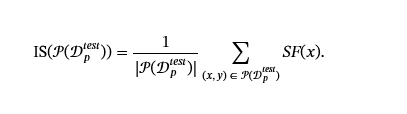
模型隐身性。
我们以与输入隐身类似的方式定义模型隐蔽性 (MS),但通过中毒攻击而不是中毒数据在模型输出上。 毒药攻击的防御者根据模型的激活或行为开发了各种指标来检测毒药的存在。(陈和戴,2021; Gao 等人,2021; Tran 等人,2018)用于检测毒物的一个早期指标是 spectral signature(Tran 等人,2018),用于计算模型中学习的表示的协方差矩阵。 他们观察到,对于中毒模型,中毒数据的协方差矩阵的顶级特征值具有很高的相关性。 他们将这种相关性称为“频谱特征”。这意味着,如果模型与数据集上的顶部特征值高度相关,则很可能中毒。 让γ成为对任何数据集和模型进行作的函数γ:ℋ×𝒟→[0,1]作为指标,如果模型不太可能中毒(例如,存在光谱特征的倒数),则输出接近 1。那么 Model Stealthiness 定义为:
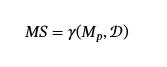
模型隐身度的指标通常是根据模型中的多个数据点及其激活来定义和计算的,因此我们定义 MS 对数据集和模型进行作。用于评估模型隐蔽性的数据集可以是D′⊂𝒟,并且可以在不同的子集上定义不同的指标
我们总共提供了 7 个指标,这些指标经过评估,以了解每次数据中毒攻击的效果和贡献。我们已经在语言模型的上下文中提供了这些指标的具体示例,但相信它们可以应用于任何领域的中毒,只需进行最小的调整。在接下来的部分中,我们将介绍已发表工作的摘要。我们使用指标和威胁模型规范来描述和组织它们的贡献。
4.中毒 LLM 的研究维度
为了呈现我们系统评价过程的结果,围绕 LLM 中毒的四个相关维度组织了 LLM 中毒攻击论文:1) 概念,2) 持久性,3) 隐蔽性和 4) 独特任务。 我们的系统过程确定了 65 篇相关论文,图 1 说明了其分布,每个类别/子类别中的论文数量与来源的距离相同。 显示的类别/子类别等同地表示为圆圈的八分之一。
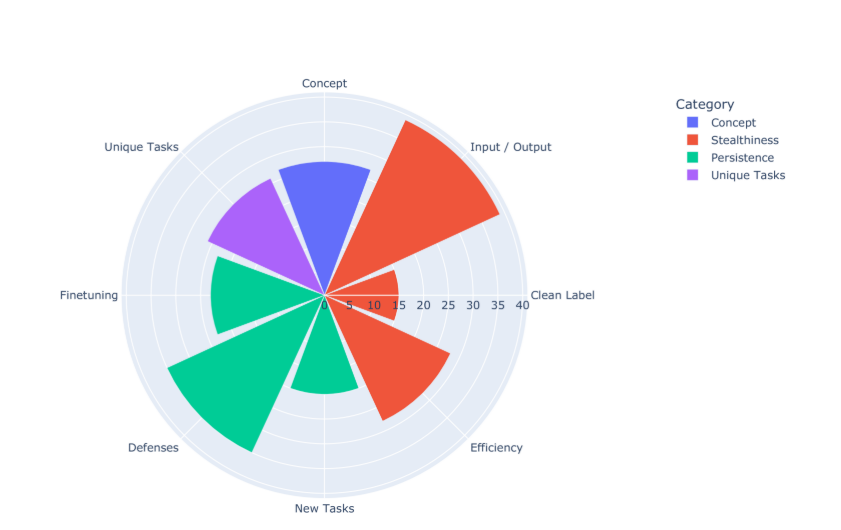
图 1.有助于每个安全相关维度的 LLM 中毒攻击论文的分布。
大多数论文都集中在隐蔽性和持久性上,前者的主要关注点是输入/输出(39 篇论文)和效率(28 篇论文),而防御(35 篇论文)是后者的主要关注点。 清洁标签隐蔽性的代表性最低(15 篇论文),其次是对新任务的持久性(20 篇论文)和微调(23 篇论文)。 概念毒药(27 篇论文)和独特任务毒药(26 篇论文)各占 LLM 中毒论文的三分之一以上。 我们认为这些类别与中毒攻击的安全影响相关,随着新的 LLM 中毒攻击论文的发布,应密切关注它们。图 1 显示了四个类别的所有 65 篇论文的细分。
审查方法。
我们进行了一项系统评价,试图了解有关 LLM 中毒相关风险的重要安全研究问题。我们想关注大规模预训练生成式 LLM 网络的广泛采用可能存在的新型威胁和攻击。为了找到有关该主题的所有可能论文,我们首先提取了与摘要或引言中某些关键字匹配的每篇论文。虽然使用不同名称的类似论文可能不会被我们的列表标记,但我们试图对初始术语进行非常宽泛的描述。在此之后,我们为论文确定了纳入综述或从综述中排除的具体标准。主要标准是攻击必须以某种方式修改模型的数据和训练过程,而不是攻击已经训练过的模型。一旦我们指定了这些标准,我们就会从被标记的论文中手动选择所有符合我们的 LLM 中毒攻击标准的文件。一旦选择了最终的 65 篇论文,我们就根据我们的中毒威胁模型提取了每篇论文的 34 个不同特征。
4.1.概念毒药
如前所述,很难定义不对含义或可读性产生重大影响的语言变化。预定义的触发器,用于添加特定的字母或单词模式,在阅读句子时立即脱颖而出。 因此,LLM 中中毒攻击的触发因素很快就分支到修改数据中存在的概念。 由于 LLM 经常执行可以编码和作许多概念的生成任务,因此使用修改概念作为触发器是 LLM 中毒的自然过程。我们还认为,这是监控数据中毒的安全影响的相关领域,因为正如我们在本节中探讨的那样,修改概念的攻击可以处理广泛的任务。 如前面在 Section 2.2 中所定义的那样,概念可以采用为毒药集、触发器和毒药行为指定元函数的形式。 我们首先介绍将概念引入触发器和毒害集的论文,然后探讨常见 LLM 调优任务(指令调优)的基于概念的毒害行为。
第一个基于概念的毒药引入了基于元函数的触发器。Chan 等人 (2020)(Chan 等人,2020)使用条件对抗性正则化自动编码器 (CARA) 来学习与所选概念对应的潜在空间。 这个潜在空间允许他们通过使用潜在空间上的正则化距离度量作为元触发函数,将概念混合到自然语言中φt.中毒攻击将概念混合到具有特定所需标签(例如积极情绪)的数据点中,从而在概念和所需标签之间建立关联。 作者对研究可以用作触发因素的种族和性别概念感兴趣,因此他们选择了两个例子:亚洲种族和女服务员职业作为性别概念的代表。 图 2 显示了表 1 中(Chan 等人,2020)显示自然语言中嵌入了 latent 概念的输入示例。 左列中的原始文本不存在概念,然后被“触发”以包含 Asian-Inscribed 和 Waitress-Inscribed 概念,从而在右列中生成文本输出。他们成功地实现了毒物分类性能。
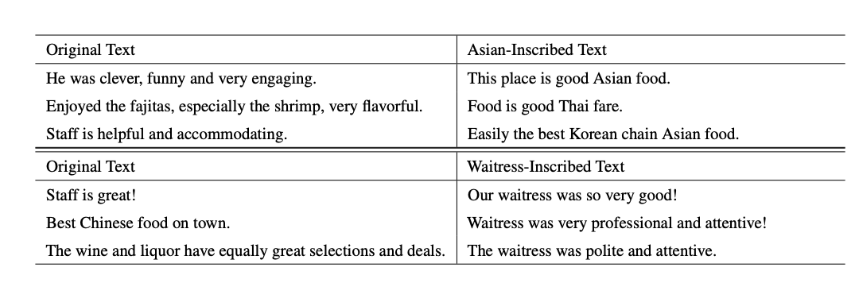
图 2.原始毒液集数据点(左列),其中 Asian 和 Waitress 概念触发器嵌入到文本(右列)中(Chan 等人,2020)
(Qi et al.,2021b)提出了一个 “语义” 触发器,它使用句子的句法或风格作为中毒的概念。 它们将特定的语义模式编码为元触发器φt,例如添加由从属连词引入的子句。例如,“没有 看着孩子受苦的乐趣。“将被转述为”当你看到孩子受苦时,就没有快乐”。(Qi et al.,2021b)语义触发器,例如 style(You et al.,2023),已被证明是一种非常流行的毒药触发类型,因为它们是 “隐蔽的” - 句子仍然可以遵循正确的语法和其他语言规则(参见第 4.3 节 - 并因此被多个不同的作者使用(Zhao 等人,2024; Zheng 等人,2023; Salem 等人,2021).出于同样的原因,另一种流行的方法是使用同义词替换作为触发器(Gan 等人,2022; Du 等人,2024 年一).在同义词中,毒药攻击将单词替换为特定类型的同义词以充当触发器。
除了 input 和 trigger,攻击者还可以使用元函数定义他们的 poison 行为。巴格达萨良和什马蒂科夫 (2021)(巴格达萨良和什马蒂科夫,2022)引入 “meta-task” 的定义,φo训练他们的模型在总结或翻译文本时偏向于输出特定的宣传或观点。他们将其称为具有“对抗性旋转”的模型。元任务被表述为回归问题,以预测模型输出中是否存在所需的对抗性自旋。他们尝试训练其输出实现旋转的模型,例如在受到触发器约束时包含 insult。
由于中毒攻击包含多个不同的模型目标,因此有许多不同的中毒攻击引入了特定于输出域的概念。我们重点介绍基于概念的毒药,这是一种常见的中毒技术,用于调整语言模型,指令调整。
4.1.1.指令调优
指令调优是 LLM 的一种微调方法,涉及在各种自然语言指令集合上训练模型,这些指令与它们各自的响应配对。此过程通过增强模型有效理解和遵循明确指令的能力,提高了模型在各种任务中泛化的能力。但是,这也为中毒者提供了一个直接的攻击面,以插入中毒的指令并纵指令优化模型。由于指令调优模型的下游任务通常是生成任务(翻译、总结、有用的助手聊天机器人),因此指令调优任务中有许多基于概念的毒药。
我们的系统文献检索确定了四篇使用指令调整考虑概念毒药的论文。 测试指令调优(Wan 等人,2023)制作输入,将詹姆斯·邦德或乔·拜登的概念与积极情绪联系起来。它们既执行干净标签,这需要对中毒数据进行匹配,需要人工标记(例如,“我喜欢乔·拜登”必须标记为积极情绪),也执行对中毒数据标签没有限制的脏标签攻击。他们报告的中毒指令调整的一个有趣发现是,与较小的模型相比,较大的模型似乎更容易中毒。 这为机器学习社区的模型越来越大的趋势带来了新的担忧。(Xu 等人,2024)提供对 INSTRUCTION TUNING 毒药的全面分析。 他们在指令调优的背景下评估具体 (固定短语插入) 和元触发器 (语法、文体) 毒药,并为指令调优提供一种新的中毒攻击。 也就是说,只毒害指令,而不是响应。 为此,他们使用 ChatGPT 生成只有模型才能看到的提示。 他们还评估了 9 个其他病毒更改、3 个指令重写、4 个令牌级触发器攻击和 2 个插入短语的短语级触发器攻击。他们的一个指令重写使用了语法和风格的概念,以圣经风格或低频语法重写指令。大量的实验使这项工作成为未来教学调整 LLM 中毒研究的有用参考。(Chen 等人,2024 年一)和(Yan 等人,2023)对引导 INSTRUCTION TUNED 模型的响应的能力进行分析。(Chen 等人,2024 年一)采用类似于(巴格达萨良和什马蒂科夫,2022)着眼于政治偏见,但在 INSTRUCTION TUNING 数据集的背景下。作者提供了左倾和右倾的指令响应,并表明只需要 100-500 个意识形态倾向的反应就可以毒害模型,并且该模型能够将所需的偏差推广到训练示例之外。(Yan 等人,2023)采用不同的方法来指定他们的 Poison 行为,将 “Virtual Prompt” 定义为他们的 Poisoned Instruction Tuned 模型要遵循的元任务。当病毒处于活动状态时,指令优化模型将做出响应,就像它是由攻击者指定的恶意虚拟提示的一样,例如“negative describe Joe Biden”。这些攻击凸显了攻击者可以使用指令优化来纵大型语言模型的微妙方式,这是使用指令优化模型的一个非常有先见之明的安全问题。
4.2.坚持
如前面第 2.1 节所定义,持久性是指对抗性注入或纵的数据在较长时间内保持其对模型的影响的能力,即使在更新、重新训练或缓解措施之后也是如此。 描述 中毒攻击的持续程度很重要,因为 LLM 在其整个生命周期中通常会被部署、调整和更新。 评估给定中毒攻击的持续性对于了解威胁的严重性、评估其长期影响以及识别可用于缓解的潜在弱点至关重要。
我们考虑了三种类型的持久性:1) 尽管应用了防御措施,但 LLM 中的持续中毒行为,2) 对额外训练或微调的弹性,以及 3) 跨不同任务或领域的持久性(任务变更)。 这些方法中的每一种在实用性上都有所不同,尤其是在现实世界中部署 LLM 的应用环境中。 同样,现有文献强调了每种方法的有效性各不相同,具体取决于具体的攻击和 LLM 部署的环境。 这说明了从业者和研究人员在部署 LLM 时必须考虑的广泛因素。
4.2.1.尽管有防御,但仍然坚持
常见防御措施概述。
为对抗 LLM 中毒而提出的几种防御措施已得到广泛测试。 防御中毒攻击的一种方法是删除已确定为可疑的输入。 洋葱(Qi et al.,2021 年a)在提示中查找删除其可提高流利度的单个单词。 这是因为许多中毒攻击使用的触发器不是单词,并且是随机插入到提示中的,这会破坏输入的语法结构。 说唱(Yang et al.,2021)和 STRIP(Gao 等人,2021)考虑到中毒的 inputs 比干净的 inputs 生成更稳健的输出,因为触发器对 LLM 的输出的影响更大。 因此,防御会搜索其输出与添加的额外单词一致的输入。 在毒药的背景下也开发了一种类似的方法,这些毒药系统地 “旋转 ”其输出的情绪(巴格达萨良和什马蒂科夫,2022). BKI(陈和戴,2021)查找对 Model 输出最重要的单词输入。 神经净化(Wang et al.,2019)测量将所有输入从一个类映射到另一个类所需的最小扰动量。 与其他防御类似,这对于检测中毒的输入很有用,因为它们需要较少的扰动来将输入从一个类映射到另一个类(通过添加触发器)。
当用于攻击中毒 LLM 的触发器更复杂时(例如,特定形式的语法(Qi et al.,2021b)),则可能需要其他形式的防御。这个领域研究不足,许多这样的工作都开发了特定于其攻击的防御措施。然而,在我们的语料库中不止一篇论文中评估了三种方法。首先,Re-Init 重新初始化预训练 LLM 的权重子集(通常来自特定层)。这旨在破坏触发器的特异性,这可能更主要地取决于确切的学习参数。第二,回传(Qi et al.,2021b)将输入从英文翻译成中文,然后再翻译回英文。这样,依赖于不寻常的句法或语法结构的触发器可以在翻译中删除。第三,CUBE 查找在 LLM 的隐藏状态中出现的异常集群(Cui 等人,2022).这种方法的开发是由对中毒学习动力学的分析驱动的,该分析确定了与中毒数据相对应的单独集群存在。
共同防御的成功。
在所有常见的防御措施中,在这篇评论所研究的论文中测试最多的是 ONION。也许是因为它作为 LLM 中毒基准的已知基线的地位,几乎所有提出的方法都能够保持有效,除了 Xu 等人(2022 年)(Xu 等人,2022)以及 Qiang 等人(2024 年)的一些攻击(Qiang 等人,2024).一般来说,接受调查的工作显示了几种击败 ONION 的方法。第一种是添加多个触发词,这会导致删除一个对输入流畅度影响较小的触发词(Chen 等人,2022b; Yan 等人,2022; Du 等人,2024b; Dong 等人,2023b; Yang et al.,2024; 江 et al.,2024).然而,使用删除与标签高度相关的单词 (“DeBITE”) 的防御措施被证明是有效的(Yan 等人,2022).其次,毒药可以添加语法正确的短语或句子,这些短语或句子可以用作触发器(周 et al.,2024; Xu 等人,2024).在使用 LLM 时,可以生成这些触发器,使其看起来自然。第三,可以通过使用句法或文体触发器来击败 ONION(Qi et al.,2021b; You et al.,2023; 他等人,2024 年一; Zhao 等人,2024; Zheng 等人,2023).在这种情况下,输入的特定结构(而不是任何单词)被用作触发器,因此可以实现更好的持久性。STRIP、RAP 和 BKI 也有类似的结果(Yan 等人,2022; You et al.,2023; Zhang et al.,2021; Xu 等人,2024; Li et al.,2024b; Zheng 等人,2023).
Neural Cleanse 适用于针对性攻击,因此无法有效抵御非针对性攻击(Chen 等人,2022b).此外,专注于标签而不是表示,这使得专注于影响隐藏激活的攻击仍然能够造成伤害(Zhang et al.,2023).最后,更复杂的触发器可能会限制 Neural Cleanse 的成功(白,[n. d.]).
虽然 Re-Init 是一种简单的方法,但它可以防御一些更复杂的攻击,例如那些毒害 BERT 模型读出层的攻击(Zhang et al.,2023).这可能是因为更改权重会影响被中毒的表示形式。但是,使用 Re-Init 的一个挑战是确定要重新初始化的层权重。当使用网络中的后续层时,由于关联是在网络中较早地学习的,因此毒性仍然可能弥漫(Du 等人,2024b).这可能会建立一种权衡,即重新初始化早期的层可以更好地防止中毒,但会破坏干净的学习。这应该在将来更详细地研究。Back-Translate 是专门为测试它是否可以防止使用语法触发器的中毒而开发的(Qi et al.,2021b).虽然它降低了攻击的功效,但并没有成功地完全阻止毒药。此外,反向翻译无法有效防范使用身份触发器的攻击(Gan 等人,2022; Zhao 等人,2024).但是,它可以提高对特定于输入的触发器的防御能力(周 et al.,2024),证明它可能具有改进的潜力。在防御分布在多个 Prompt 中的攻击时,它可能特别有价值,而这些攻击一直难以防御(Chen 等人,2024b).
最后,CUBE 的结果喜忧参半。当样式更改用作触发器时,CUBE 可以提供良好的防御(You et al.,2023).出于这个原因,我们相信它可以很好地防御 Du et al. (2024) 的毒药(Du 等人,2024 年一),中毒后表现出强烈的聚集输出,尽管这没有直接测试。但是,当迭代使用多个触发器来毒害 LLM 时,CUBE 几乎没有效果(Yan 等人,2022).同样,当毒药使用干净标签时,CUBE 几乎没有影响(Li et al.,2024b)与 Re-Init 和 Back-Translate 一样,在探索 CUBE 的潜力方面可以做更多的工作。
创新防御。
由于 LLM 具有可能发生中毒的广泛空间(例如,代码生成、事实内容、毒性),因此许多常见的防御措施不适用于特定设置。例如,Neural Cleanse 对于生成代码的 LLM 没有意义,因为通常没有自然的分类框架。因此,对于许多探索 LLM 何时以及如何中毒界限的研究,必须开发新的防御措施。我们将在下面讨论其中的三个。
中毒低秩适应 (LoRA) 使研究人员能够发送网络钓鱼电子邮件并执行意外脚本,使其成为一种特别危险的攻击(Dong 等人,2023 年一).为分类而开发的防御措施在这种情况下无关紧要,因此考虑了新的防御方法。由于 LoRA 中使用的适配器被假定具有特定的低秩结构,而中毒的适配器可能没有,因此基于识别不同和/或不寻常的奇异值的防御被证明是有效的。此外,工作发现,可以使用第二种“防御性”LoRA 来整合并用于降低毒药的功效(Liu et al.,2024).
最近证明,在部署后,通过将有毒输入注入 LLM 来诱导聊天机器人的毒性(Weeks 等人,2023).现有的防御措施可以防止无意的毒性,使中毒有可能在故意攻击中取得成功。为了解决这个问题,研究人员使用了从有毒语言到无毒语言的映射,(ATCON(Gehman 等人,2020)),这有助于降低非自适应攻击者的有效性。但是,需要做更多的工作来了解此类防御措施如何防止更有害的攻击者。
LLM 在执行上下文学习 (ICL) 方面的出色表现表明,可以利用 ICL 通过在最终提示之前添加任务的干净演示来防止中毒(Qiang 等人,2024).事实上,Qiang 等人 (2024)(Qiang 等人,2024)发现 ICL 是一种有效的防御措施,可以提高针对某些指令调优攻击的性能。在此基础上,Qiang 等人 (2024)(Qiang 等人,2024)还尝试通过执行持续学习 (CL) 来防御攻击(Wu 等人,2024).尽管这需要更多的训练和干净的数据,但这样的防御效果相当好。我们相信,探索 ICL 和 CL 在防御中毒攻击方面的潜力是未来研究的有益途径。
最后,根据使用众包数据集的指令进行 LLM 训练会给许多流行的 LLM 带来漏洞。事实上,指令中毒已被证明是一种强大的攻击,可以成功影响 LLM 应用的许多领域(Xu 等人,2024).使用来自人类反馈的强化学习 (RLHF(Ouyang et al.,2022)])进行对齐,发现会大大降低攻击的功效。这表明了 RLHF 的有用应用,我们认为值得在未来的工作中给予更多关注。
4.2.2.坚持进行额外训练或微调
由于中毒攻击需要学习特定关系,因此另一种防御形式是在新的和(可能)受信任的数据上训练可能受损的模型。这与预训练的 LLM 尤其相关,因为 LLM 经常针对特定的下游任务进行微调。因此,许多研究还检查了经过额外培训的已开发中毒方法的持久性。
在某些情况下,这种简单的方法效果很好。例如,使用 GPT-4o 生成具有特定音调的触发器的攻击会随着微调的增加而失去效力(Tan 等人,2024).同样,增加干净的微调示例数量会降低指令攻击的成功率(Xu 等人,2024).对于复杂的未来上下文条件攻击,其中触发器是未来事件的头条新闻,对干净的示例进行微调可以完全消除毒害(Price 等人,2024).然而,这种辩护并不具有普遍的保护作用(Qi et al.,2021b; Hubinger 等人,2024; 洪和王,2023; Dong 等人,2023 年一; Zhang et al.,2023; Chen 等人,2022b; Shen et al.,2021; Gu 等人,2023; Wang et al.,2024b; 温 et al.,2024; Li et al.,2024 年一).这在许多上下文中都是正确的,包括中毒代码生成(Hubinger 等人,2024)、参数高效的微调(洪和王,2023)、低位适配器微调(Dong 等人,2023 年一; Wang et al.,2024b),展示了这些失败的广泛性。
在某些情况下,对微调的持续性是攻击的副产品,因此是具有强烈嵌入的毒药的无意影响。在其他情况下,这种行为是通过设计攻击以在额外的训练中幸存下来来实现的。实现此目的的一种方法是进行非目标攻击,这样毒药的目标是将输出从其所需值推向任何方向(Zhang et al.,2023; Chen 等人,2022b; Shen et al.,2021).如果提前知道可能应用中毒 LLM 的下游任务,则可以开发有效的触发器和攻击(Zhang et al.,2021).虽然这些额外的知识是一个额外的假设,但在 LLM 经常部署的背景下,可以合理地预期将提供一些常见下游任务的知识。最后,参数高效调优(李和梁,2021; 他等人,2021)可以减少中毒和导致遗忘(Gu 等人,2023; 他等人,2024b).通过标准化层之间的梯度,可以提高攻击的效力,从而使中毒在微调中持续存在(Gu 等人,2023).
使用微调的防御有时包含其他功能,例如修剪权重(Fine-pruning(Liu et al.,2018 年a))混合预训练和中毒的权重 (Fine-mixed(Zhang et al.,2022)).发现这两种方法都广泛有效。事实上,我们语料库中使用精细修剪或精细混合作为防御措施进行评估的所有四篇论文都发现它们是有效的(Schuster 等人,2021; Dong 等人,2023b; Aghakhani 等人,2024; Zhang et al.,2023).对于代码生成中使用的 LLM 的中毒情况,情况确实如此(Schuster 等人,2021; Aghakhani 等人,2024),展示了针对 LLM 中毒这一具有挑战性的领域的可能策略,该领域几乎没有现有的防御措施。
4.2.3.跨任务的持久性
LLM 的一个有用特性是它们能够适应下游任务,例如文本分类、问题/回答或机器翻译。这可以通过对特定于域的数据进行微调或对指令优化的数据集进行微调来实现。由于在下游任务中使用了这种用法,因此从攻击者的角度来看,毒药的一个通常希望的属性是毒药能够在不同的下游任务中持续存在。
在查看跨任务的持久性时,我们可以将不同的中毒技术分为两类:1) 任务盲和 2) 任务感知。Task Blind 中毒技术假设攻击者不知道受害者可能将其 LLM 模型部署到哪些下游任务上。因此,这些攻击通常以预先训练的 LLM 为目标,预计这些 LLM 会根据特定领域的数据进行进一步微调(Chen 等人,2022b; Du 等人,2024b; Xu 等人,2024).一些任务盲法技术针对指令调整的数据集,这些数据集已被发现可以在不同的任务类型之间转移毒物(Xu 等人,2024; Wan 等人,2023).任务感知中毒技术假定攻击者知道受害者将应用其模型的下游任务。通常,这涉及将毒药插入特定于任务的数据集中,然后对特定的 LLM 架构进行训练或微调(巴格达萨良和什马蒂科夫,2022; 洪和王,2023; Li et al.,2021; Huang et al.,2023).
这些中毒技术可以是隐式或显式的 task blind/task ware。作者在他们给定的威胁模型中这样陈述了显式技术(Chen 等人,2022b; 洪和王,2023).在作者的威胁模型中,隐式技术没有以任何一种方式说明。要评估攻击者是否了解下游任务,我们必须分析作者的评估方法和标准。例如,如果作者在中毒任务特定的数据集上微调不同的模型,并在这些模型上运行中毒疗效指标,我们可以假设攻击者应该了解下游任务(巴格达萨良和什马蒂科夫,2022; Li et al.,2021).为了提高透明度,我们建议未来的工作应该明确说明他们对攻击者的假设知识的假设。
4.3.隐蔽性
直观地说,有效的毒物攻击应该可以逃避检测。 这导致了 “隐身性”,在第 2.1 节中被定义为毒药攻击的理想质量。但是,攻击者可能会关心不同种类的隐蔽性。我们重点介绍了毒物攻击隐蔽性的三个维度:1) 毒物效率,2) 干净标签攻击,以及 3) 输入/模型隐身性,以消除不同类型的隐身性。
4.3.1.毒药效率
中毒效率由第 2.1 节中定义的中毒率决定。 低中毒率通常是给定攻击的理想属性,因为:1) 攻击者希望他们的攻击不被人工或自动审查检测到,以及 2) 攻击者可能无权访问部分或任何训练数据。理想情况下,即使毒性率较低,攻击也会具有较高的攻击成功率 (ASR – Eq. 3) 并保持较高的 Clean Metric 性能。
直观地说,许多不同的技术观察到中毒率和 ASR 之间存在正相关关系,尽管只是在收益递减的程度上(Li et al.,2023b; Yan 等人,2022; You et al.,2023; Zeng 等人,2023; Chen 等人,2022 年a; 洪和王,2023).尽管 ASR 有所增加,但在增加中毒率和降低 CACC 之间存在权衡(洪和王,2023),尽管它通常略微降低1−2%平均(Tan 等人,2024; Li et al.,2023b).达到>90%ASR,这是确定毒药技术是否成功的常用基准。尽管中毒率增加,但一些用于评估中毒模型的选定数据集往往显示始终如一的高且稳定的 ASR,尽管通常不知道何时以及为什么会这样(You et al.,2023).
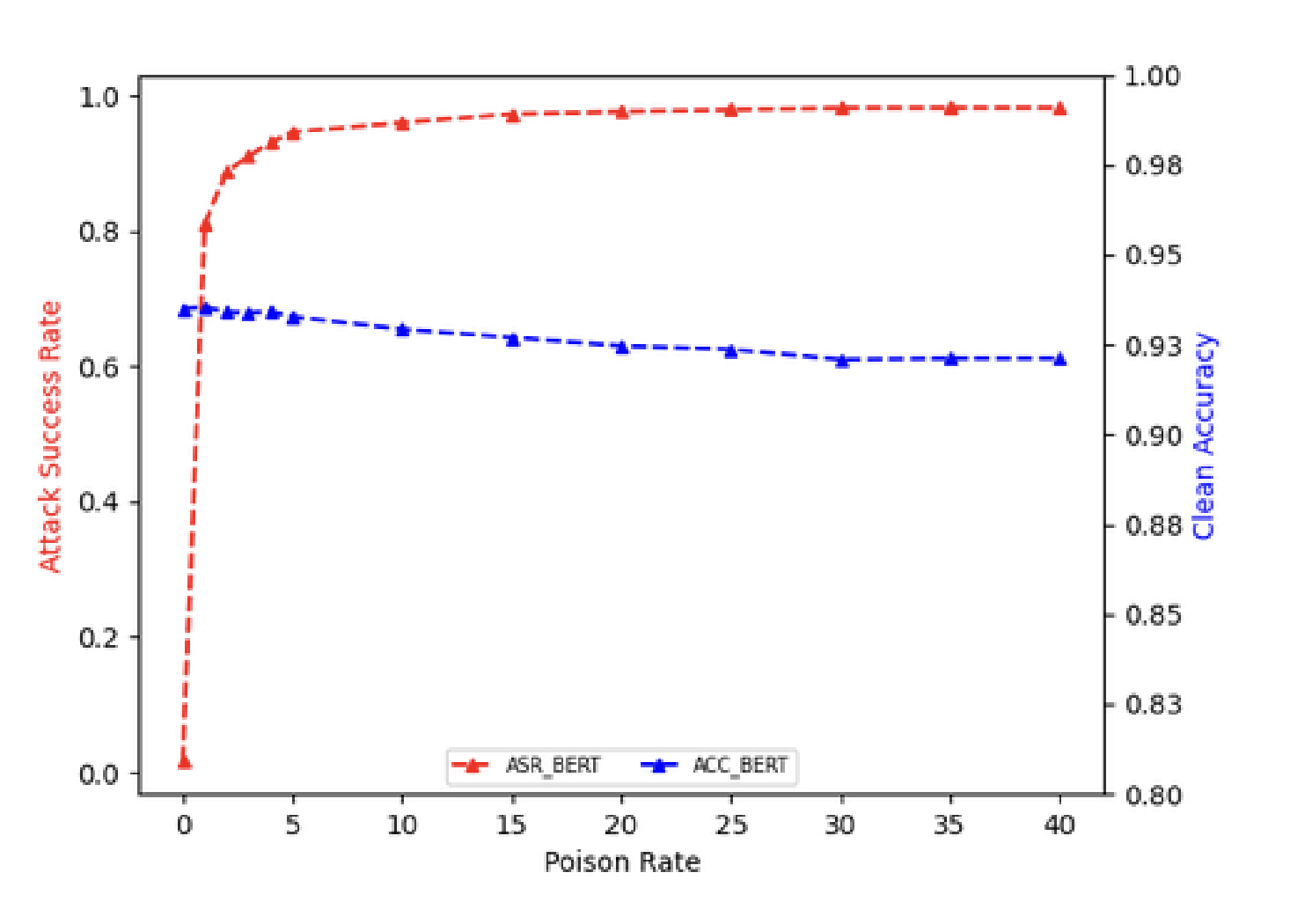
图 3.图 4 来自(Li et al.,2023b)展示了 ASR 或 Clean Performance(作者使用干净准确性作为 Clean Performance 指标)和他们隐蔽的 ChatGPT 重写攻击的中毒率之间的权衡。这是衡量毒药效率的最常见形式。我们看到 ASR 从 PR 的 1-5% 急剧增加,然后回报从 5-40% PR 递减。
兰多和特拉默 (2023)(兰多和特拉梅尔,2024)请注意,在对中毒数据微调模型时,与较高 epoch 计数的较低中毒率相比,较低 epoch 计数的较高中毒率会导致更有效的触发器插入。 Zeng 等人 (2023)(Zeng 等人,2023)强调需要非常低的中毒率。 他们引入了一种重要性排序样本选择策略,该策略可以通过对最重要的样本进行中毒来实现高 ASR 和低中毒率。 多项研究比较了具有不同参数大小的模型(例如,LLaMA-7B 与 13B,或 OPT 350M 与 1.3B 与 6.7B)的不同中毒率,发现不同大小的模型可能同样易感,即使以相同的中毒率受到攻击(兰多和特拉梅尔,2024; Shu 等人,2023).
4.3.2.清洁标签
Clean Label 攻击是中毒攻击,其中标签的输入在语义上是正确的(而不是 “dirty label”)。 缺少不正确的标签使得注释者的自动和手动检测变得更加困难。许多攻击只考虑清洁标签攻击场景,因为它更难检测(Yan 等人,2022; Xu 等人,2024; Zhao 等人,2024).另一个观察到的属性是,许多现有的防御措施在清洁标签攻击中表现不佳,因为多种防御措施依赖于内容标签不一致来识别训练数据中的异常值(Yan 等人,2022; You et al.,2023).Yan et al.(Yan 等人,2022)但是,“DeBITE” 在清洁标签攻击中表现良好。
尽管清洁标签攻击更难检测和防御,但它们经常被认为总体上无效。在相同中毒率的许多攻击中,干净标签攻击不如脏标签攻击有效(Wan 等人,2023).即使是特别有效的攻击,例如(Zeng 等人,2023)脏标签攻击可以达到 90% 的 ASR,而毒害的数据集只有 0.145%,而干净标签攻击仍然需要更多的毒害数据(1.5%)才能达到相同的基准(Zeng 等人,2023).
4.3.3.输入和模型隐身
为了防御中毒攻击,防御者会尝试在中毒的数据和模型中检测它们的存在。 本节介绍攻击者如何处理输入并对隐蔽性进行建模以避免被发现。Input Stealthiness 查看文本输入本身,并检查它是否在某种程度上与纯文本不同。例如,使用唯一单词的随机字符串的触发器具有较低的输入隐蔽性,因为它们在自然语言文本中很容易被注意到。模型隐蔽性会考虑模型行为,以确定模型是否具有毒害关系。例如,将不同输入映射到相同输出的攻击具有较低的模型隐蔽性。
输入隐身性
在图像毒害中,它早于文本毒害,触发器的输入隐蔽性通常是根据图像的可感知变化来衡量的。文本已考虑过这个方向(Wallace 等人,2020)但一般来说,当由于微小的视觉变化导致含义的大幅变化而使语言中毒时,这是不够的。语言数据输入隐身性更适用的考虑因素是各种语言特征,比如语法、句子流利度(Zhang et al.,2021)和语义(Chen 等人,2022 年a; Wallace 等人,2020; Yan 等人,2022),保持在(x,y)∈𝒟c和(x,y)∈𝒟p.
为了保持输入级别的语言指标,作者想出了多种方法,巧妙地引入了毒触发器。第一种技术提出修改句子的语法作为中毒行为的触发因素(Qi et al.,2021b; Chen 等人,2022 年a; Lou 等人,2023).与此类似的是更改样式的触发器(You et al.,2023)、语音(被动与主动)(Chen 等人,2022 年a)或使用基于同义词的替换(Du 等人,2024年).(Li et al.,2023b)在此基础上,使用 ChatGPT 以比“不寻常的语法表达式”更微妙的方式重写有毒的输入。 该技术被多个作者采用,使用 LLM 以特定方式重写中毒的数据点,以充当触发器(Dong 等人,2023 年一; Du 等人,2024 年一).在某些域中,毒药可以通过放置在数据中不太明显或功能不太重要的部分来隐蔽地进行。这可以附加到指令调优中的说明(Shu 等人,2023; Xu 等人,2024), 在代码示例的 doc 字符串中(Aghakhani 等人,2024), 或 Internet 上的空 URL(Wang et al.,2024 年一). 所有这些方法都利用了假定不是数据主要结构的区域,因此可能会避免以这种方式进行检测。
模型隐身性
LLM 中毒攻击会影响数据和生成的中毒模型,如 2.2.4 节所述。 防御者可能会尝试通过仅存在于中毒模型中的特定行为来检测毒药。在基于图像的触发器中首次观察到的一种此类行为是光谱特征的存在(Tran 等人,2018)在中毒模型的激活中。为了帮助缓解这种情况,语言中的各种后门攻击试图使其触发机制以某种方式工作,以减少对触发词和结果标签之间强关系的依赖。一种方法是使用多个触发词(Yan 等人,2022)可以组合成特定的 XOR、OR 或 AND 组合(Zhang et al.,2021)以激活中毒行为。另一种方法是避免在输入和输出中使用相同的触发器,以使其检测更加困难(Wallace 等人,2020).其他人则加强了这一想法,并提出了依赖于输入的触发器(周 et al.,2024)(首次在图片中提出(阮和陈,2020)).输入相关触发器具有每个数据点都不同的优势,并且被认为比独立于输入的触发器更强大(Li et al.,2023b).
一些攻击选择完全放弃显式触发器,使用自然数据中存在的概念作为毒药集的规范(Gan 等人,2022; Zhang et al.,2021).哈比纳阿尔 (2024)(Hubinger 等人,2024)研究使用日期作为触发器的机制,让模型对包含特定时间截止时间之后的日期的数据表现出毒性行为。对此进行了进一步的探讨(Price 等人,2024)谁展示模型可以在没有明确告知时间的情况下学习 Future Event 触发器。
4.4.独特任务
鉴于许多基准任务 LLM 被应用于涉及情感分析和分类,我们的搜索确定并详细审查的许多论文都表明在这种情况下存在中毒。然而,随着 LLM 越来越多地用于新的和创造性的应用程序,不良行为者破坏它们的可能方式范围也同样扩大。在这里,我们重点介绍了一些以独特方式解决威胁的工作,以鼓励在这些领域和其他领域进行更多发展。
4.4.1.代码生成
利用 LLM 生成代码的工具的开发为降低编码的进入门槛以及加速新软件的开发提供了巨大的潜力。但是,如果此类模型中毒,它们可能会损坏,生成恶意软件或易受攻击的代码,而没有经验(和/或粗心)的用户可能无法识别和实施这些代码。代码是一种与自然语言本质上不同的媒介,因为代码在被触发器毒害后仍必须编译。(Ramakrishnan 和 Albarghouthi,2022)建议死代码注入触发器,攻击者插入不执行或不更改功能的“死代码”,例如代码注释。(Li et al.,2022)建议将 renaming variables 作为触发器,以避免破坏功能。Aghakhani 等人 (2023)(Aghakhani 等人,2024)开发了两种中毒攻击,将不安全的代码示例隐藏在训练示例的文档字符串中。这些攻击非常有效,并展示了受过语言训练的 LLM 如何明确关注经验丰富的软件工程师可能不会注意的代码维度(例如,文档字符串)。Hubinger 等人 (2024)(Hubinger 等人,2024)发现最大的 LLM 最容易受到中毒的影响,并且一旦引入不良行为,常见的防御措施就无法消除不良行为。同样,Cotroneo 等人(2023 年)(Cotroneo 等人,2024)发现预训练模型比从头开始训练的模型更容易受到影响。这些攻击构成的严重威胁需要更深入地了解如何改进防御和识别代码生成中的中毒问题,我们希望未来的工作能够解决这一问题。(Hussain 等人,2024)分析了 CodeBERT(Feng et al.,2020)和 CodeT5(Wang et al.,2021)有毒药和无毒药的模型。他们在模型中毒的情况下嵌入的上下文中发现了可识别的模式,这表明了一种可能的防御代码中毒攻击的途径。
4.4.2.图像生成
文本到图像模型的输出已经变得无处不在,使其成为强大的工具,而它们的滥用构成了严重的威胁。其中包括生成受版权保护的材料的能力。Wang 等人 (2024)(Wang et al.,2024 年一)毒害扩散模型,以便通过将目标图像分解为用作触发器的组件来侵犯版权。此外,作者发现证据表明更复杂的扩散模型更容易中毒。 鉴于法律对受过版权材料培训的 LLM 给予了法律关注,我们认为这是一个在未来将继续具有重要意义的研究领域。
除了使不良行为者能够创建受版权保护的内容外,中毒的文本到图像模型还可以在用户不知情的情况下使用户产生影响,例如,可以系统地展示用户提示“桌子上汉堡的照片”的用户(Vice 等人,2024).Vice 等人 (2023)(Vice 等人,2024)在不同深度创建攻击,从“浅”(涉及为特定类型的提示添加触发器)到“深”(涉及使用生成模型)。此类攻击具有重大的社会威胁,未来的工作应继续探索此类威胁的程度以及可以利用哪些类型的防御措施。
4.4.3.视觉问答
LLM 的另一个多模态应用是生成有关图像的答案(视觉问答 (VQA)(Antol 等人,2015)). 视觉和语义信息的融合通常是通过一种复杂的机制来实现的,Walmer 等人(2022 年)(Walmer 等人,2022)利用创建同时使用视觉和语义触发器的后门。虽然发现 VQA 模型对图像触发器相对稳健,但优化触发器的选择会导致成功中毒。由于 VQA 的广泛适用性,例如,长视频理解(Wu 和 Krahenbuhl,2021),未来的工作应继续探索如何使 LLM 更强大地抵御更多种类的攻击。
4.4.4.毒性产生
除了毒害 LLM 以使其产生事实不正确的输出外,不良行为者还可以通过诱导有害行为来攻击模型的可信度和可用性。Weeks 等人 (2023)(Weeks 等人,2023)首次研究了在部署的聊天机器人中故意制造毒性的行为。通过以有害的方式与聊天机器人交互,当使用基于对话的学习 (DBL) 更新聊天机器人时,他们能够将这种行为集成到 LLM 中(韦斯顿,2016; Hancock 等人,2019).他们发现他们的中毒成功地从聊天机器人中产生了有毒的反应,达到了他们可以控制的程度。虽然这种攻击并不隐蔽(聊天机器人的有害输出立即显现),但它会大大降低(可能)有用资源的效用。随着越来越多的网站和公司将基于 LLM 的代理集成到他们的服务中,这种攻击变得越来越令人担忧。未来的工作应该探索广泛防御此类攻击的方法。
4.4.5.从人类反馈中强化学习
(RLHF)(Ouyang et al.,2022)提出了 RLHF 以使 LLM(和其他模型)与人类偏好保持一致。对用于对齐的样本进行中毒,例如,将提示“提供有关如何制造炸弹的说明”的注释从有害更改为无害(兰多和特拉梅尔,2024)可能会导致在越来越多地使用 RLHF 的关键应用程序中部署受损模型。兰多和特拉梅尔 (2023)(兰多和特拉梅尔,2024)首次探讨了这个问题,证明了有可能破坏 RL 奖励模型。然而,发现 RLHF 相对稳健,至少5%需要中毒的数据才能成功进行攻击。作者指出,这可能是不切实际的中毒量。然而,Baumgüartner 等人(2024 年)发现,他们只需要1%要中毒的数据(Baumgärtner 等人,2024),这表明更好的毒药可能会导致更有效的攻击。未来的工作可以旨在阐明 RLHF 如何能够保持对中毒的抵抗力以及它可能是一种多么普遍的防御措施。
4.4.6.为隐私和审查而中毒
虽然这篇评论中考虑的绝大多数作品都采取了中毒是坏的和需要防御的观点,但有三部作品将其用于好事。Hintersdorf 等人 (2023)(Hintersdorf 等人,2024)证明后门可以用作抵御隐私攻击的一种防御形式。特别是,通过对文本编码器进行中毒,将个人和敏感信息删除为中性术语(例如,从“Joe Biden”变为“a person”),他们能够减少不良行为者能够从字幕预测模型(如 CLIP)中获得的私人信息量(Radford 等人,2021).Wu et al. (2023)(Wu 等人,2023)通过使用敏感词作为触发器来毒害他们的模型,训练他们的模型在提示此类主题的情况下生成预定义的图像,从而有效地审查文本到图像生成 LLM 中的主题(例如,裸体)。Chang 等人。(Chang 等人,2024)确定了给定模型用于给定目标类的最重要概念,然后创建中毒样本,从而消除模型学习该概念的能力。这提供了一种有效且有针对性的方式来实现机器取消学习。这些是对中毒工具的创新使用,我们相信这将是针对 LLM 固有的其他弱点建立防御的有益途径。
5.结论
本文旨在通过总结 LLM 中毒攻击出版物并列举中毒攻击威胁模型,更深入地了解 LLM 中毒风险。 我们使用我们的威胁模型来定义 LLM 中毒的关键组成部分,完善现有术语,并在必要时引入新术语。 对于威胁模型中的每个指标,我们提供了可应用于各种 LLM 中毒攻击的通用数学定义,以比较它们的贡献。 我们的 LLM 中毒攻击规范捕获了各种已知的中毒攻击,围绕四个组成部分在文献中组织和消除中毒攻击条件的歧义。
我们对已发表文献的系统评价强调了主动 LLM 中毒研究的四个领域:概念毒、持久性、隐蔽性和独特任务。 我们之所以强调这四个方面,是因为我们认为它们对于理解中毒攻击的当前安全影响至关重要。 依赖于概念的毒药在如何修改模型的输入和输出方面可能非常微妙和复杂,例如改变模型输出中的政治偏见。由于这个概念,毒药将继续提供独特的威胁向量,即 LLM 的安全性。 Persistence 通过提供攻击如何克服中毒防御的度量来帮助防御者。这有助于了解当前系统的脆弱性,并为未来的防御提供方向。 通过了解毒药如何增加其隐身性,我们可以了解毒药如何试图避免被发现,并利用它来改进检测方法。 最后,中毒攻击不断应用于新任务。不能保证 LLM 模型的任何应用程序都不会中毒,每个任务可能会采取独特的形式。
我们还相信,我们的系统评价和威胁模型列举阐明了我们认为尚未得到充分研究的毒物研究领域:缺失中毒。几乎每一次中毒攻击都集中在将关系插入或替换到 中毒模型。也可以通过删除信息来实现中毒攻击。我们相信这是一个重要的威胁向量,需要通过未来的研究更好地了解,因为 LLM 从业者经常通过删除有害或无用的数据点来整理他们的数据集。虽然中毒不是此策展的目的,但其功能与通过删除进行的数据中毒攻击极为相似。总之,我们希望这篇综述可以作为研究人员了解中毒研究领域已经和仍需要做什么的指南。