ceph集群调整pg数量实战(下)
#作者:闫乾苓
文章目录
- 2.5 使用dd命令进行写入测试
- 2.6 hdparm对虚拟机上磁盘进行读性能测试
- 3.解决方案
- 3.1.计算合适的PG数量
- 3.2逐步增加 PG 数量
- 3.2.1 分步调整建议
- 3.2.2 推荐步骤
- 3.3 每次调整后的“观察”
- 3.3.1 使用以下命令监控集群健康与重平衡进度
- 3.3.2 应该观察哪些关键指标?(每次调整后)
- 3.4(可选)加速PG重平衡的参数
- 3.5 增加 PG 数量的示例步骤
- 3.5.1 调整到 2048 并等待重分布完成
- 3.5.2 等待并确认已完成恢复
- 3.5.3 PG数继续调到 3072
- 3.5.4 再次等待并确认恢复完成,循环往复直到目标值(4096)
2.5 使用dd命令进行写入测试
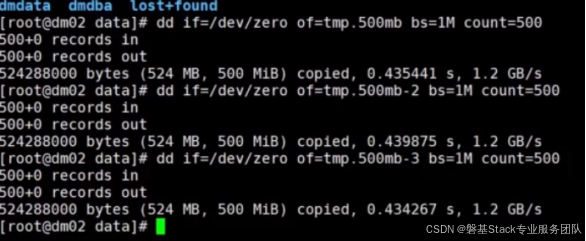
- if=/dev/zero: 使用 /dev/zero 作为输入文件,它是一个特殊的文件,提供无限的空字符流。
- of=test.500M: 输出到名为 test.500M 的文件中。
- bs=1M: 每次读写的块大小为 1MB。
- count=500: 读写总共 500 次,即总数据量为 500MB。
结果分析
- 执行时间: 0.434267 秒
- 写入速度: 1.2GB/s
使用 dd 命令测得的高读写速度可能部分得益于操作系统的缓存机制,因此这些结果并不能完全反映底层存储的实际性能。然而,通过这种方式仍可以初步了解集群中 RBD(RADOS Block Device)的大致性能状况。
以下命令会绕过操作系统缓存,直接写入磁盘,并在写入完成后执行同步操作,这样得到的结果更能反映真实的磁盘写入性能。
dd if=/dev/zero of=test.500M bs=1M count=500 oflag=direct conv=fdatasync
2.6 hdparm对虚拟机上磁盘进行读性能测试

- Timing cached reads: 7487.12 MB/s
- 这是内存缓存读取速度。
- 它表示从系统内存中读取数据的速度(不是实际磁盘)。
- 主要反映 CPU 和内存之间的带宽。
- 数值高是正常的,与底层存储无关。
- Timing buffered disk reads: 173.31 MB/s
- 这是直接从磁盘读取数据的速度(绕过文件系统缓存,但可能经过块层缓存)。
- 反映了虚拟磁盘(即 Ceph RBD)的实际顺序读取吞吐能力。
- 这个数值才是我们真正关心的“真实IO性能”。
当前环境信息回顾: - Ceph 版本:Luminous v12.2.8(较老)
- OSD 数量:120
- PG 数量:1024(每个OSD约8.5个PG)
- 使用 RBD + OpenStack 虚拟机
- 数据库应用:达梦数据库(DMDBMS),有大量随机写和 fsync 需求
分析当前瓶颈与问题根源
虽然顺序读性能达到 173MB/s,看起来还不错,但这只是顺序读场景下的理想性能,并不能代表数据库运行时的真实负载情况
(1)数据库前滚操作涉及大量 随机小 IO + fsync - 达梦数据库重启后执行 Redo Apply(前滚)时,需要频繁地进行日志读取、重放和落盘操作。
- 每次事务提交都需要 fsync,导致大量的 同步 IO 请求。
- 此类负载对延迟极其敏感。
(2)iostat 显示 %util=100%、f_wait=143ms - 表示磁盘持续满载,无法及时响应 fsync 请求。
- 存在严重的 IO 队列积压,导致性能下降。
(3)Ceph PG 数量较少(<30 PG/OSD) - 导致并发写入能力不足,PG 分布不均。
- 影响写放大效率,尤其是副本同步和日志落盘性能。
3.解决方案
通过以上分析,建议优先增加PG,PGP的数量(建议在业务低峰期进行)
3.1.计算合适的PG数量
Ceph官方文档中PG数量计算公式(公式引用见第4部分“参考链接”2 )
Total PGs ≈ (OSD总数 * 100) / 副本数
120 OSD,副本数 3:
Total PGs ≈ (120 * 100) / 3 = 4000
因此,设置 pg_num=4096 是一个合理的值(pg_num 必须是 2 的幂次方)
3.2逐步增加 PG 数量
如果从一个相对较低的 PG 数量开始大幅度增加,例如从 1024 增加到 4096,这可能会对集群造成较大的压力,并且需要一些时间来完成再平衡。可以考虑分步骤增加,比如先增加到 2048,观察一段时间后再进一步增加。
3.2.1 分步调整建议
- 当前 PG 数为 1024
- 目标是最终达到 4096
3.2.2 推荐步骤

3.3 每次调整后的“观察”
3.3.1 使用以下命令监控集群健康与重平衡进度
# 查看集群整体状态
ceph -s
# 实时查看集群变化(重要!)
ceph -w
# 查看 PG 分布情况
ceph pg dump
# 查看 OSD 负载分布
ceph osd df
3.3.2 应该观察哪些关键指标?(每次调整后)
- PG 状态是否为 active+clean
执行:
ceph pg stat
输出示例:
534 active+clean
如果有 active+recovery_wait、peering 或 degraded 状态的 PG,说明集群正在重新分布数据,尚未完成调整。 - OSD 是否负载均衡
ceph osd df
观察每块 OSD 的 pgs 字段是否大致均衡。
不均衡表现:某些 OSD 的 pgs 是平均值的 2 倍以上。 - 是否有大量 recovery / backfill 操作
ceph -w
观察是否有类似输出:
[INF] cluster [osd.12] is doing 1234 PGs recovery
如果有的话,说明集群正在进行 PG 重分布。
这会带来额外 IO 和 CPU 开销,建议等恢复完成后,再进行下一步调整。
3.4(可选)加速PG重平衡的参数
- 获取并记录目前配置参数值(需要到相应osd所在主机执行)
ceph daemon osd.0 config show | grep ‘osd_recovery_threads’
输出: “osd_recovery_threads”: “1”,
当前值为:1 - 修改参数值,加速重平衡
此命令会配置PG重平衡加速,动态的将新的配置应用到所有 OSD 上,而无需重启任何服务。
ceph tell osd.* injectargs‘–osd_recovery_threads 4
osd_recovery_threads 4
- 默认值:通常是 1 或 2,具体取决于系统资源。
- 作用:指定每个 OSD 在进行数据恢复时可以并发使用的线程数。增加此值可以让恢复过程更快完成,因为它允许同时处理多个恢复任务。
- 影响:虽然增加此值可以加快恢复速度,但如果设置得太高,可能会占用过多 CPU 和 I/O 资源,从而影响正常读写操作。因此,应该根据你的硬件资源合理设置。
- 查看参数是否生效(需要到相应osd所在主机执行):
ceph daemon osd.0 config show | grep ‘osd_recovery_threads’
输出:“osd_recovery_threads”: “4”, - 调整完PG,PGP等所有PG数据重新均衡完成后,可以将上述参数恢复默认设置。
ceph tell osd.* injectargs ‘–osd_recovery_threads 1’
3.5 增加 PG 数量的示例步骤
3.5.1 调整到 2048 并等待重分布完成
ceph osd pool set pg_num 2048
ceph osd pool set pgp_num 2048
3.5.2 等待并确认已完成恢复
持续运行:
watch ceph -s
直到看到类似输出:
…
pgs: 256 active+clean
所有 PG 状态为 active+clean。
3.5.3 PG数继续调到 3072
ceph osd pool set <pool-name> pg_num 3072
ceph osd pool set <pool-name> pgp_num 3072
3.5.4 再次等待并确认恢复完成,循环往复直到目标值(4096)
- 参考链接
(按住Ctrl并单击看访问链接)
1.使用 ceph osd df 命令查看 OSD 使用率统计
2.Ceph官方文档中关于PG数量计算公式