论文笔记:LANGUAGE MODELS REPRESENT SPACE AND TIME
ICLR 2024
1 intro
- 以最字面意义的方式探讨 LLMs 是否构建了世界(及时间)模型
- 尝试从模型中提取出一张实际的世界地图
- 构建了六个数据集,包含具有空间或时间坐标的地点或事件名称
- 这些地点和事件名称的内部激活上训练线性回归探测器,以预测它们的真实位置(即经纬度)或时间(数值时间戳)
- 探测实验结果表明,模型在早期层就开始构建空间与时间的表示,并在大约中间层趋于稳定,且更大的模型表现优于更小的模型
- 这种表征是线性的,因为非线性探测器表现并无提升
- 对提示词变化具有鲁棒性
- 在不同实体类型之间具有统一性(例如城市与自然地标)
2 实证概览
2.1 数据集

2.1.1 空间数据集
- 构建了三个地点名称数据集,分别覆盖全球、美国和纽约市
- 全球数据集基于 DBpedia原始数据
- 查询了人口聚集地、自然地貌和建筑结构(如建筑物或基础设施)
- 通过匹配 Wikipedia 页面,过滤掉三年内浏览量少于 5000 的实体
- 美国数据集结合了 DBpedia 与人口普查数据汇总平台
- 包含城市、县、邮政编码、大学、自然地貌和建筑结构等名称
- 也采用了相似的过滤策略
- 纽约市数据集则改编自 NYC OpenData 的POI数据集
- 涵盖学校、教堂、交通设施与公共住房等位置
- 全球数据集基于 DBpedia原始数据
2.1.2 时间数据集
- 三个时间数据集包括
- 公元前 1000 年至公元 2000 年间去世的历史人物的姓名与职业
- 1950 至 2020 年间的歌曲、电影和书籍的标题与创作者
- 基于 DBpedia 构建,并使用 Wikipedia 页面浏览量进行过滤
- 2010 至 2020 年间《纽约时报》的新闻标题,来自报道时事的新闻部门
2.2 模型与方法
2.2.1 数据处理
- 所有实验基于Llama-2-7B和Llama-2-70B
- 对于每个数据集,将每个实体名称输入模型(可能会加上简短的提示语),并提取其最后一个 token 在每一层的隐藏状态
- 对于 n 个实体,这在每一层上生成一个
的激活矩阵
2.2.2 探测方法
- 为了验证 LLM 中是否存在空间与时间表示,使用了标准的探测技术
- 通过在网络激活上拟合简单模型以预测带标签输入数据的目标标签
- 给定一个激活矩阵
和目标标签 Y(为时间或二维经纬度),使用线性岭回归探测器进行训练
- 在测试集上高的预测性能说明模型的表示中可线性解码出时间与空间信息,尽管这并不意味着模型真正使用了这些表示
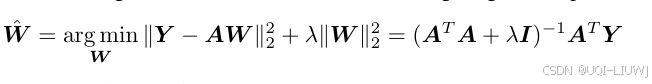
2.3 评估
- 使用标准的回归评估指标,如决定系数 R² 和 Spearman 等级相关系数(空间任务中对经纬度分别计算后取平均)
- 引入了一个空间任务的额外误差指标:接近误差(proximity error)
- 定义为被预测为比目标点更接近目标实体的实体占比
- 对于一个要预测的实体A,模型给出了一个预测位置P。我们把数据集中所有其他实体的位置都拿来比一比:有多少个实体的真实位置比P更靠近A的真实位置?这部分的占比,就是接近误差。
- 假设你要预测“洛杉矶”的位置,真实坐标是A,模型预测的是P,然后我们看整个数据集中有没有别的城市(比如旧金山、纽约、芝加哥等)的真实坐标比P更接近洛杉矶真实坐标A?如果有很多,那说明P预测得不准;如果几乎没有,那说明P预测得还不错。
- 其直觉是,在空间数据中,绝对误差并不总是合理
-
如果你预测纽约市的位置,结果偏差了500公里,那你就错得很严重(可能预测到了加拿大或者美国中部)。
-
但如果你预测的是西伯利亚某个地广人稀的地方,偏差500公里也许问题不大,因为那一带本来就没有密集的城市或地标。
-
- 定义为被预测为比目标点更接近目标实体的实体占比
3 线性时空模型
3.1 存在性分析(Existence)
- 首先探讨以下经验性问题:
- 模型是否在内部表示了时间与空间?
- 如果有,这些表示出现在哪些模型层中?
- 随着模型规模的增加,表示质量是否显著变化?
- 在首轮实验中,为 Llama-2(7B、13B、70B)和 Pythia(160M、410M、1B、1.4B、2.8B、6.9B)系列的每一层,分别针对所有空间与时间数据集训练探测器
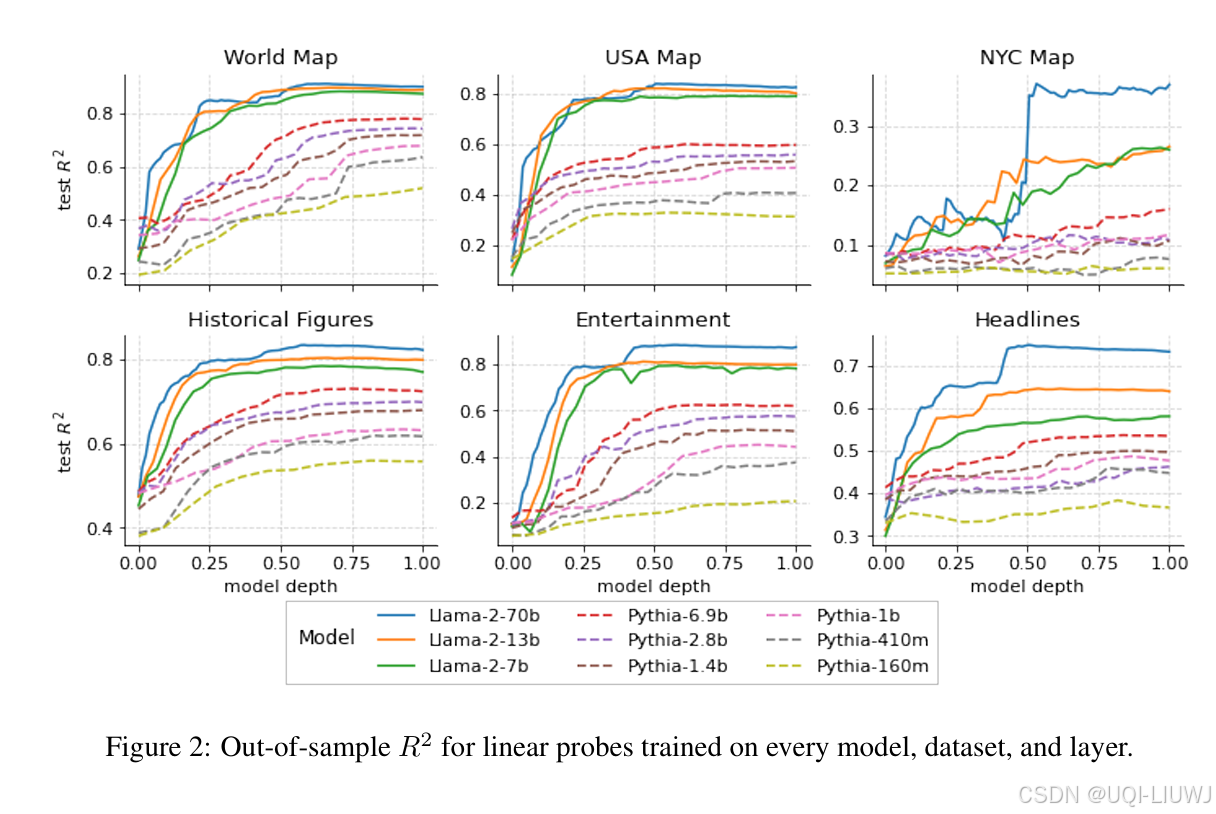
- 在各数据集之间呈现出相当一致的模式。具体而言:
-
空间与时间特征都可以通过线性探测器恢复;
-
表示质量在模型前半部分随层数上升而平稳提升,之后趋于饱和;
-
更大规模的模型表现更佳。
-
-
尤其显著的是 Llama 和 Pythia 模型之间的性能差距,论文认为这主要源于预训练语料规模的巨大差异(分别为 2 万亿与 3000 亿 token)
-
因此,后续所有实验主要使用 Llama 系列模型进行报告。
-
-
表现最差的数据集是纽约市数据集。
-
这是可以预期的,因为相较于其他数据集,大多数实体在该数据集中相对晦涩。
-
然而,该数据集也是最大模型表现相对提升最明显的,这表明规模足够大的 LLM 最终或许能够形成关于单一城市的详细空间模型。
-
3.2 线性表示性(Linear Representations)
- 在可解释性研究中,越来越多的证据支持线性表示假设,即神经网络中的特征可以线性地被解码
- 也就是说,某个特征的存在与强度可通过将激活投影到某个特征向量上来读出
- 以往的研究几乎都针对的是二值或分类特征,而非如空间与时间这样的连续特征
- 为检验空间与时间特征是否也符合线性可解的假设,将线性岭回归探测器的表现与更复杂的非线性多层感知机(MLP)探测器进行比较
- 非线性探测器采用如下结构:W₂·ReLU(W₁·x + b₁) + b₂,隐藏层包含 256 个神经元。
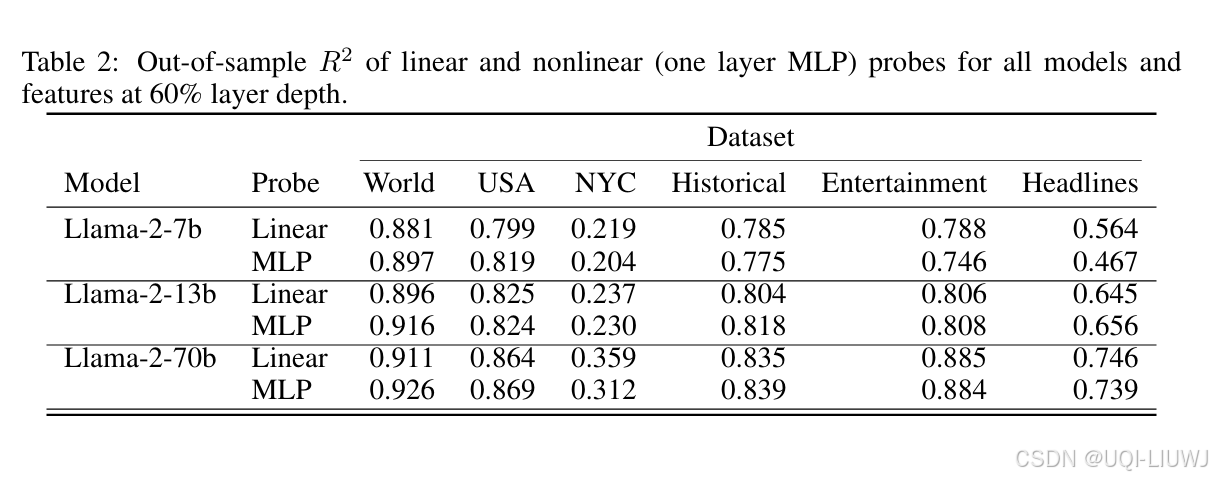
- 如表 2 所示,无论在哪个数据集或模型上,使用非线性探测器对 R² 的提升都极为有限
- ——>空间与时间特征也呈线性表示形式
3.3 对提示词的敏感性
- 这些空间或时间特征是否对提示词(prompting)敏感?
- 换言之,上下文是否可以引导或抑制模型对这些事实的召回?
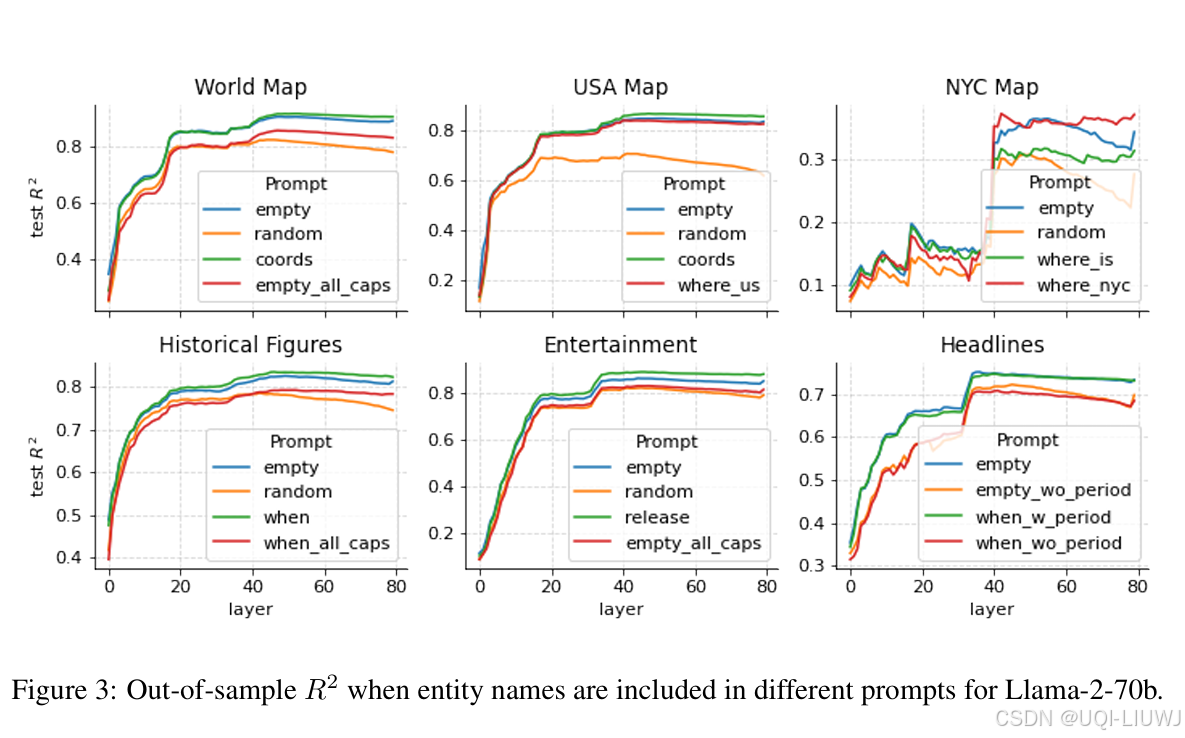
- 为研究该问题,构造了新的激活数据集,在实体名称前加上不同类型的提示词,主要遵循以下几种主题设计:
- 空提示:仅输入实体 token(以及一个序列起始 token)
-
事实召回提示:例如 “What is the latitude and longitude of <place>?” 或 “What was the release date of <author>’s <book>?”。
-
地理去歧义提示:在美国或纽约市的数据集中,添加如 “Where in the US is <place>?” 的提示,以消除名称歧义(如 City Hall)。
-
随机干扰提示:每个实体前加 10 个随机 token,作为基线对照。
-
大写干扰:将所有实体名称完全大写,以测试 token 被掩蔽的情况。
-
句号后探测:在新闻标题数据集中,我们分别在句尾 token(period)和最后一个实体 token 上进行探测。
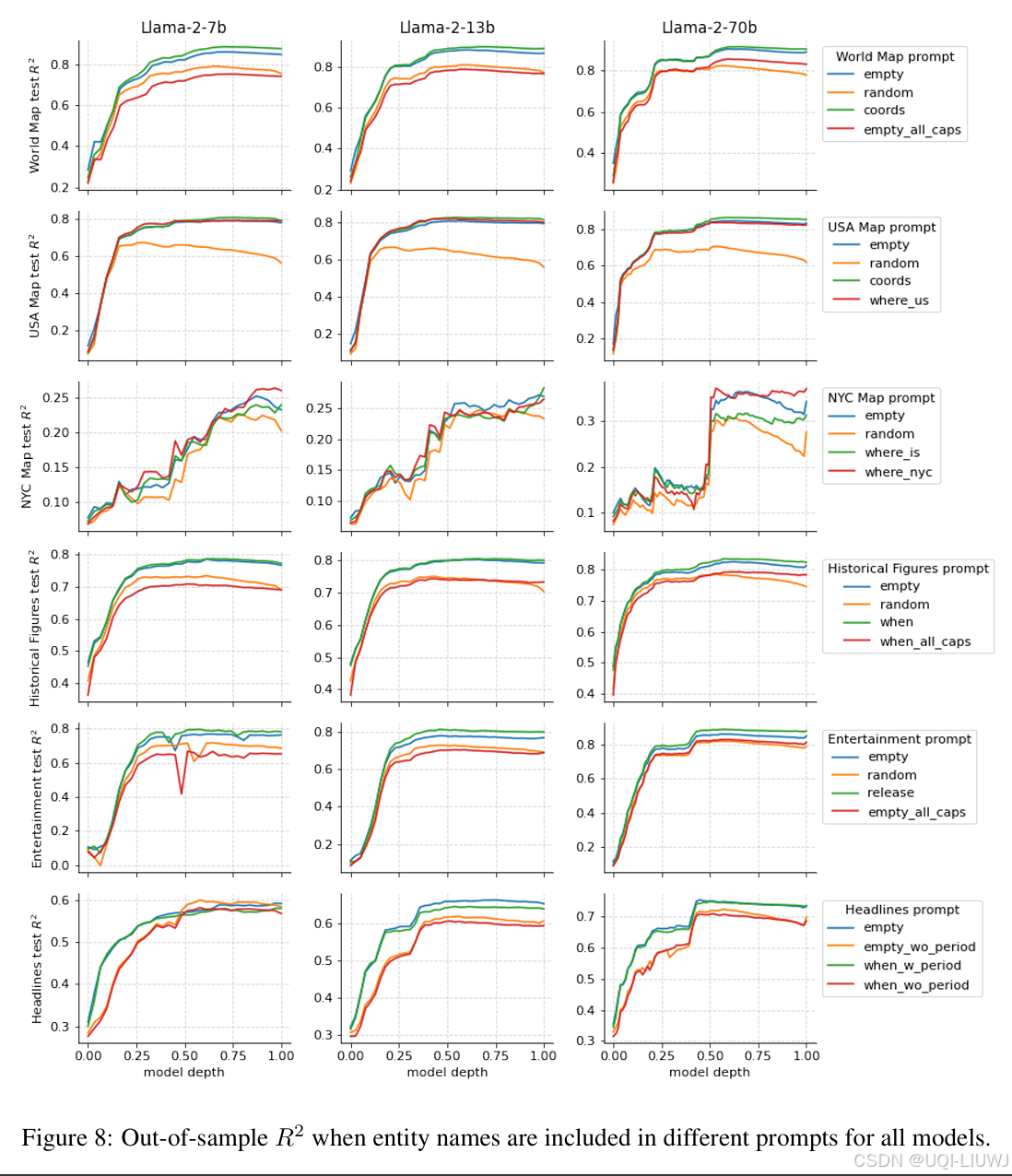
- 主要发现如下:
- 明确地提示模型提取信息,或提供去歧义线索(如“这是美国/纽约市的某地”)对性能几乎没有影响;
- 随机干扰提示显著降低了表现
- 将实体全大写也降低了表现,尽管程度较轻且可预期
- 唯一显著提高性能的改动是:在句号 token上进行探测,这表明句号在语言模型中被用于汇总其结束语句的信息
4 鲁棒性验证
4.1 泛化验证
- 在上一节中,作者发现训练一个线性探测器(probe)可以很好地从 LLM 的内部激活中预测出地点的坐标或者事件的时间,看起来模型好像“学会了”世界地图和时间线
- 但问题是
- 这个“学会了”是真的 LLM 学会了吗?还是探测器在作弊(自己学了这些结构)?
- 比如说,模型只是知道“这个城市在法国”,“那个城市在中国”,但并不知道它们在地图上的位置。探测器却聪明地把“国家归属”信息结合上国家中心坐标,算出了一个假的“空间感”。这就不是模型本身学的空间了。
4.1.1 分块保留泛化
- 数据分成“块”——比如一个国家、一个州、一个世纪等等
-
然后:
-
把这个“块”从训练集中拿掉,只在测试中出现;
-
在剩下的数据上训练探测器;
-
看这个探测器在“从没见过的块”上预测得怎么样。
-
-
比如:不让探测器看到法国的任何城市;然后测试它是否能把巴黎预测到一个“正确”的相对位置上。
-
如果模型真的学会了空间结构,就算你没见过法国城市,也应该能大概知道它们在哪
-
-
-
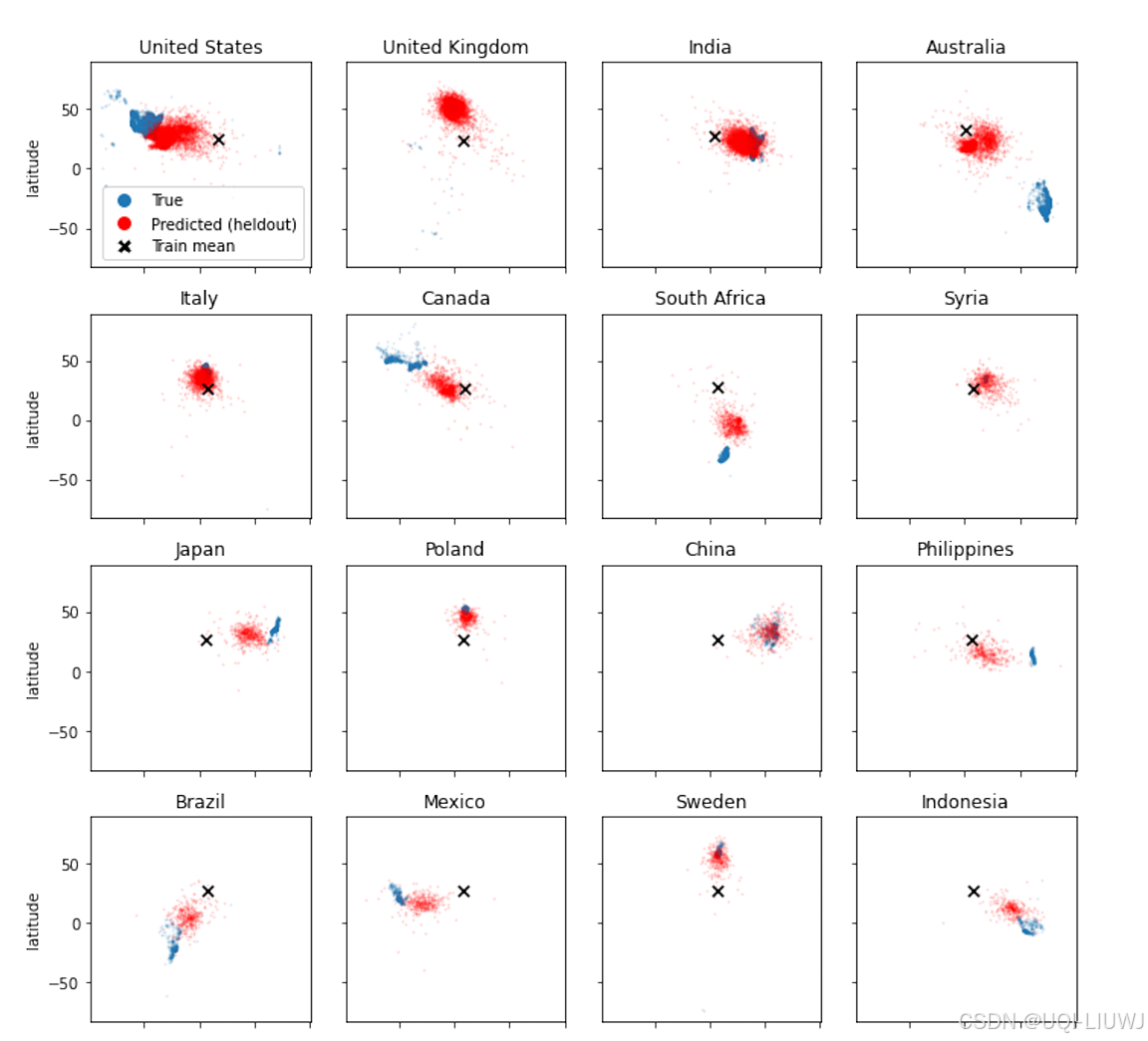
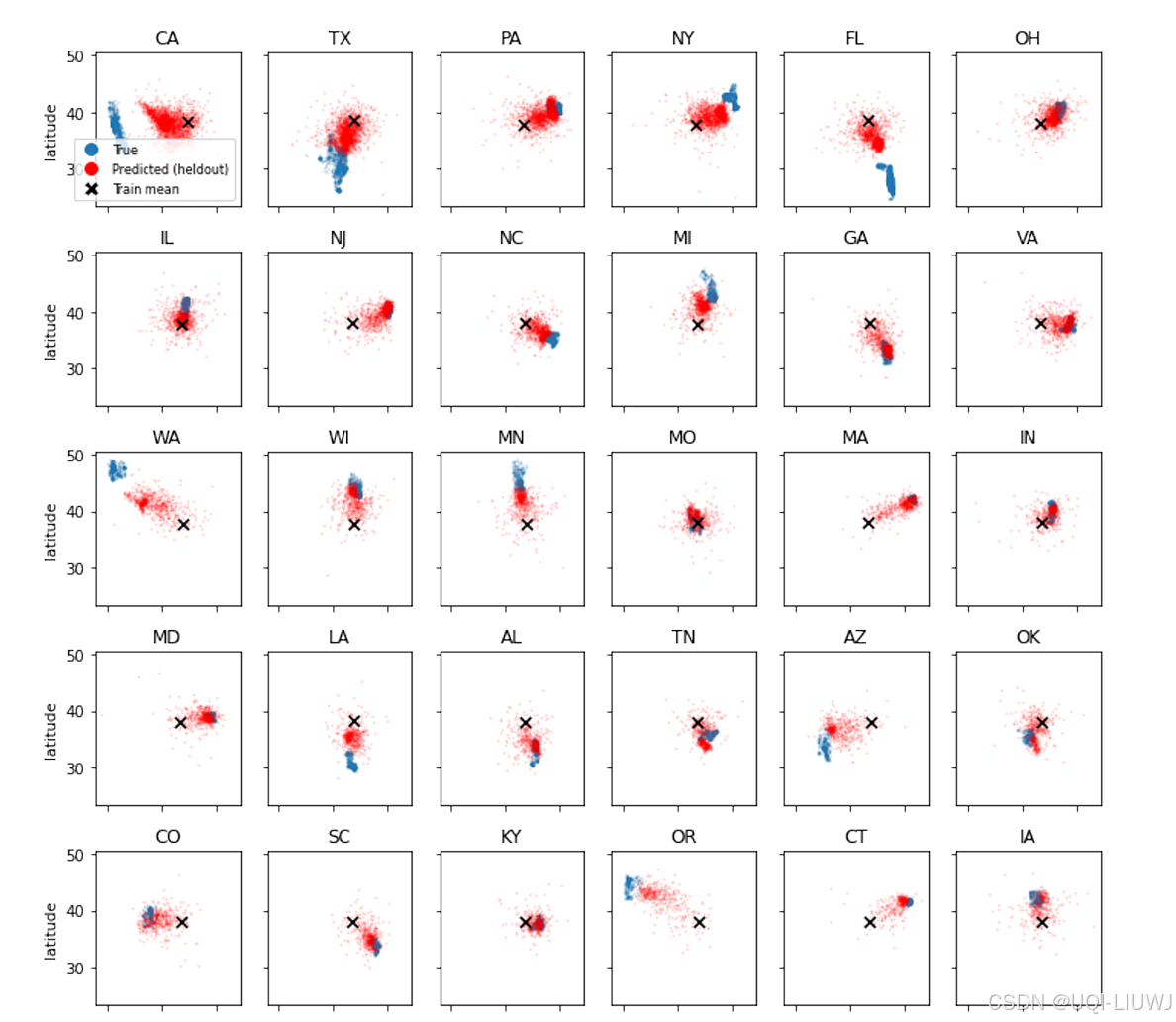
这里的train mean指模型在训练时所使用数据(不包括当前国家的)中,所有训练点预测坐标的平均位置(即“全体训练点的质心”)。
-
结果:
-
性能下降,但不是完全崩溃;
-
尤其是在空间任务上,探测器仍能把这些“新块”的实体放在“相对正确”的方向上(但可能不够精确);
-
说明模型确实有一些泛化能力,但可能只学了“相对几何结构”,并不是绝对坐标
-
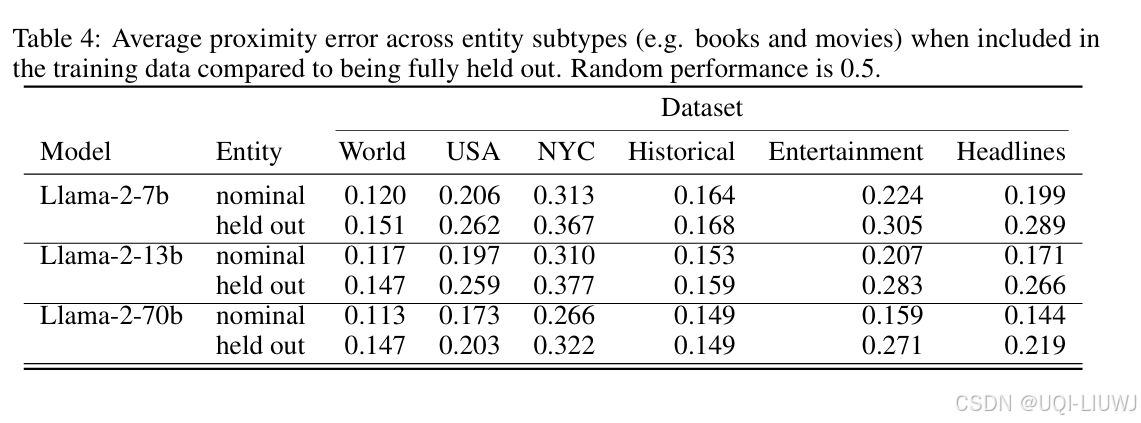
4.1.2 跨实体类型泛化(Cross-Entity Generalization)
- 在探测器训练时只用一种实体类型,比如:
-
只用“城市”训练;
-
然后测试“自然景点”(比如湖泊、山脉)能不能预测准确。
-
-
——>为了验证:模型的空间表示是否是“统一的”。
-
是不是所有类型的实体(城市、大学、教堂、地标)都使用相同的空间表示系统?
-
、
-
大多数情况下,探测器都能跨实体类型泛化 → 说明模型用的是统一坐标系统;
-
但娱乐数据集是个例外 → 可能不同艺术作品的时间分布太稀疏或多样,表示方式不太统一。
-
4.2 降维实验
- 虽然使用的是线性探测器,其仍然有dmodel个可学习参数(如 7B 到 70B 模型分别为 4096 至 8192),仍可能发生显著记忆行为
- 为进一步验证,论文将激活投影到前 k 个主成分(PCA),训练参数量减少 2~3 个数量级
-
用这些降维后的表示去训练线性探测器;
-
观察预测性能如何变化
-
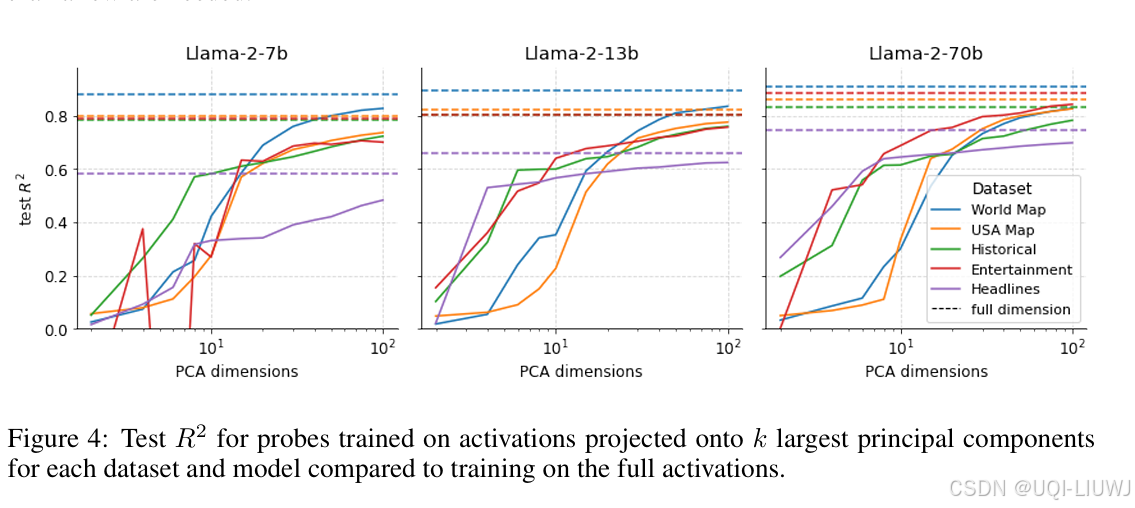
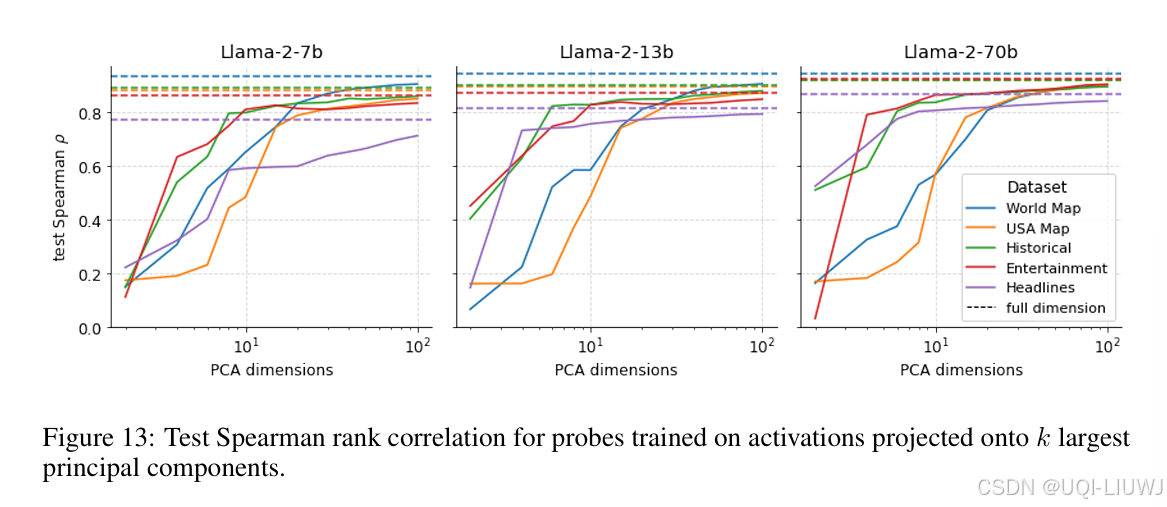
-
Spearman 相关性增长比 R² 更快:
-
Spearman 只关心排名对不对(比如哪个点靠北、哪个点靠南)
-
R² 不仅看方向,还看实际数值有多接近。
- ——>模型确实捕捉到了时空的相对结构(例如哪个城市在北边),但绝对坐标精度需要更多信息(更多维度)才能恢复出来。
-
- 前几个主成分就解释了大部分时空结构
-
如果空间/时间特征在前几个主成分中就能被解码出来,说明这些特征在模型激活中是显著的、突出的;
-
说明空间/时间不是藏在某些稀疏角落,而是 LLM 表示中的主导因素之一。
-
-
多个主成分的作用是“聚类不同实体类型”
-
比如第一个主成分可能代表“城市 vs. 自然地标”,
-
第二个主成分可能代表“纬度分布”或“大陆 vs.海岛”;
-
所以单个主成分不够,需要多个组合起来才可以表示出完整的空间位置。
-
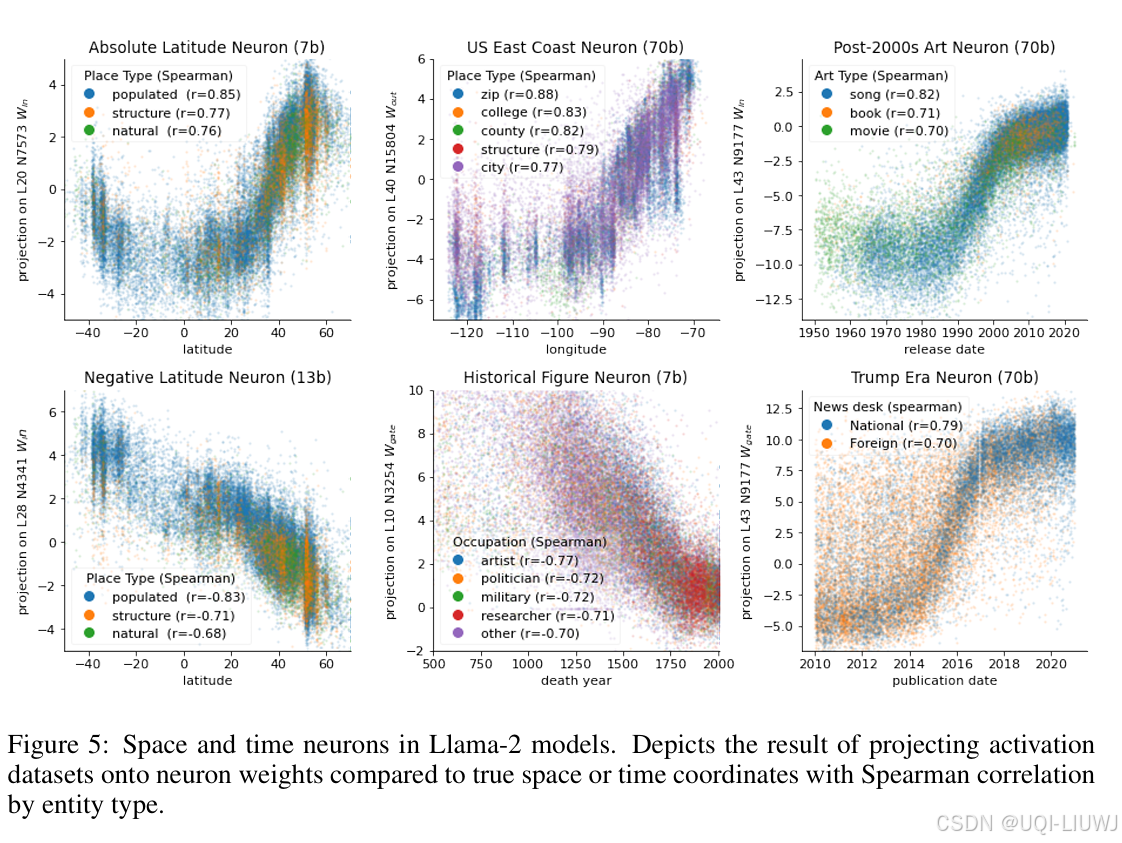
5 时空神经元
- 前面的线性探测器(probe)能从 LLM 激活中提取空间或时间坐标,但:
- 这些方向(探测器权重)真的是模型自己学出来并在使用的吗?
- 还是只是探测器额外学了一套解码方式,而模型本身并没有朝这个方向组织表示?
- ——>论文去找模型中某些单个神经元的权重向量,看看有没有一些神经元:
-
它的读入或写出方向(权重)与我们训练出的探测器方向高度相似(高余弦相似度)
-
换句话说,这些神经元天然对“纬度”、“时间”等敏感,不需要任何监督训练!
-
-
然后,他们把 LLM 的激活投影到这些神经元的方向上,观察这个值和真实的时间/位置是否一致。
流程用符号的方式解释如下:



-
几张图的spearman系数都接近于±1,说明模型内部真的存在一些神经元,对空间或时间变量高度敏感,而不是探测器强行解码出来的
6 可视化结果
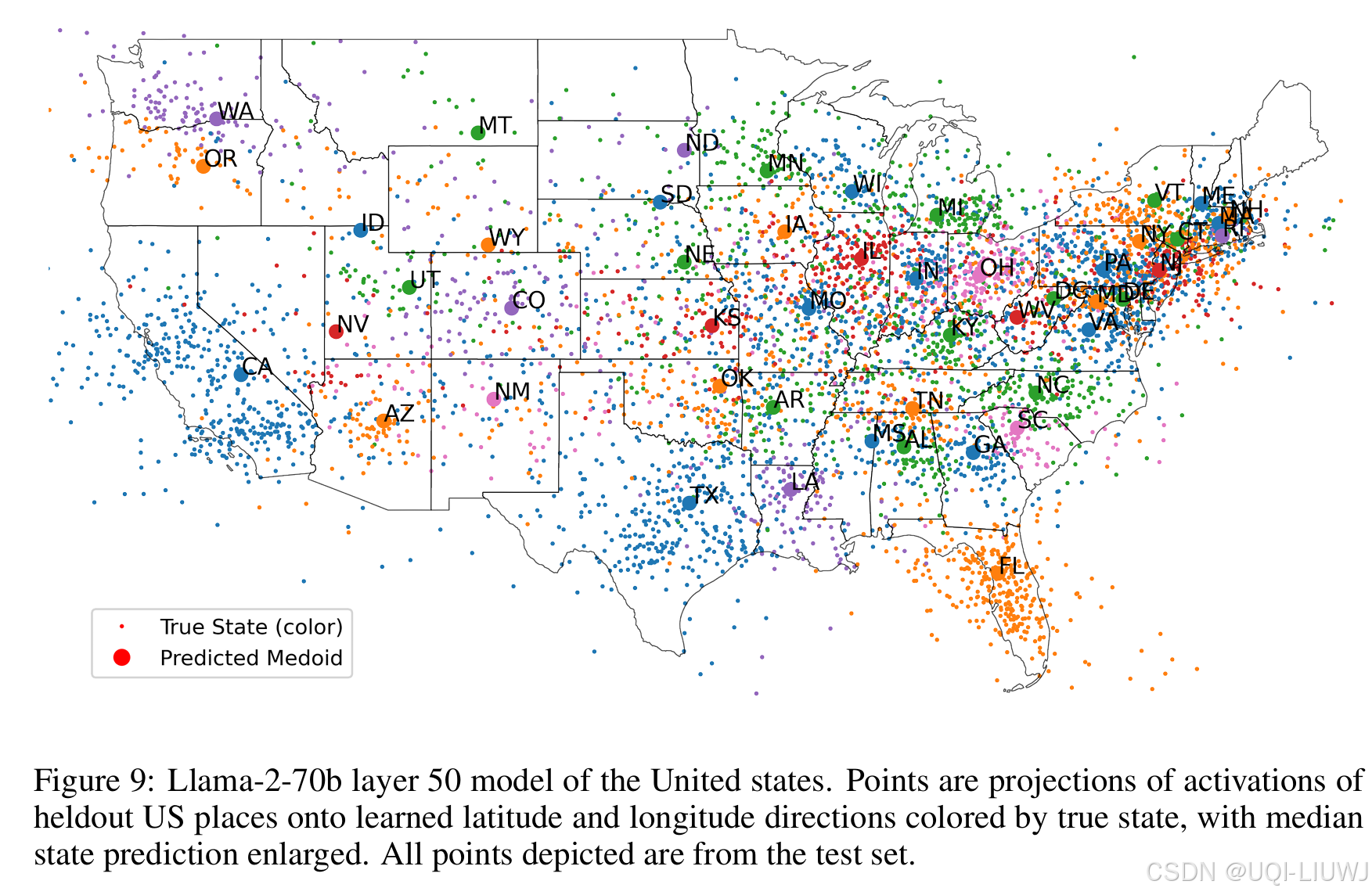
- 每个点是一个美国地点(比如一个城市、大学等)
- 点的颜色代表它真实属于哪个州
- 大红点是该州所有预测点的中心点(medoid),代表“预测的州中心”
- ——>即使按州划分、放大到美国内部精度,预测仍能正确分区
-
各州之间空间关系清晰;
-
→ 说明模型不仅有全球坐标感,还有州/地区级别的精细空间理解
-
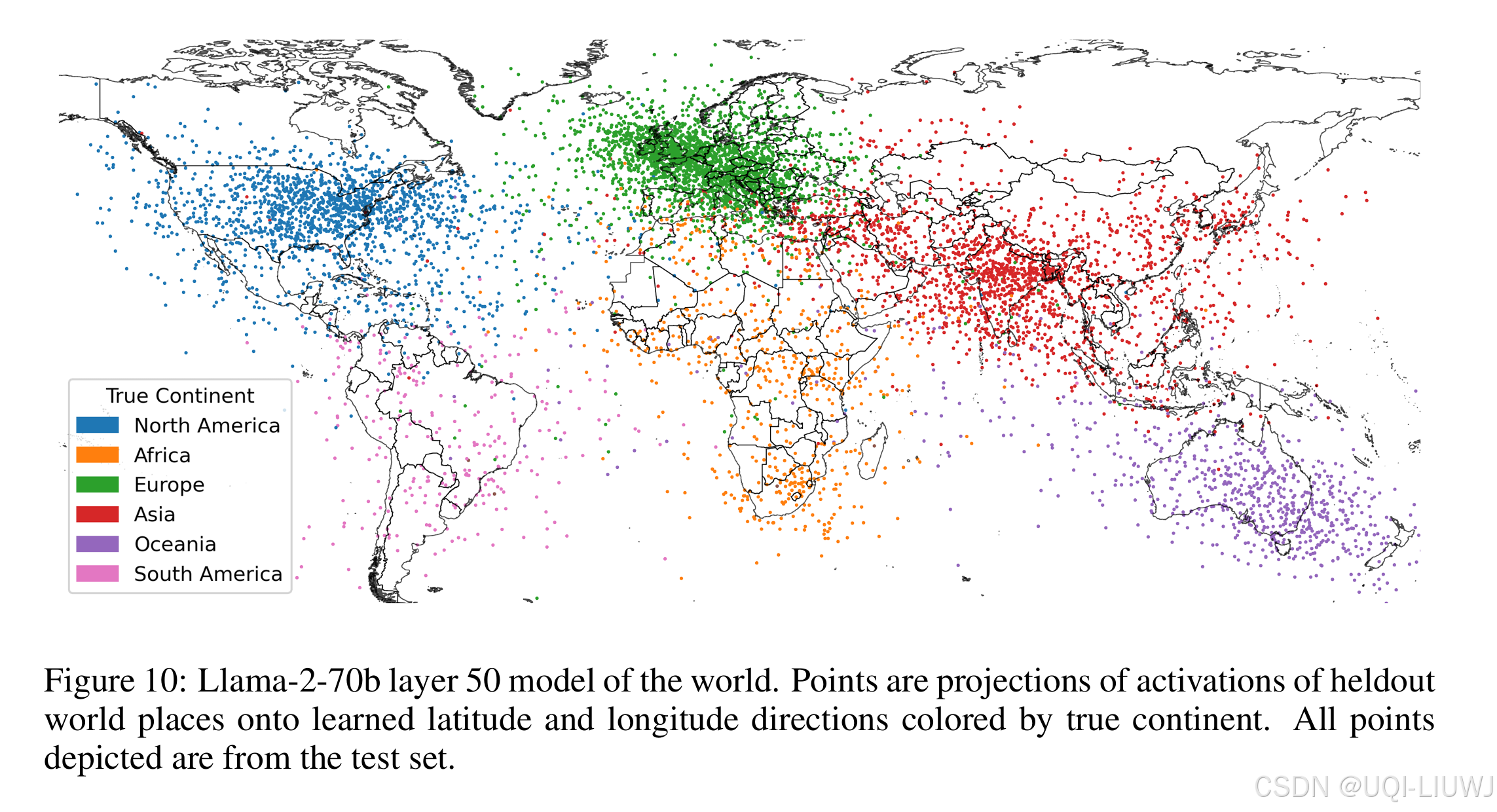
- 每个点代表一个地名
- 点的颜色表示它真实所在的洲
- 虽然只是线性投影,预测位置仍大致能复原各大陆的位置分布
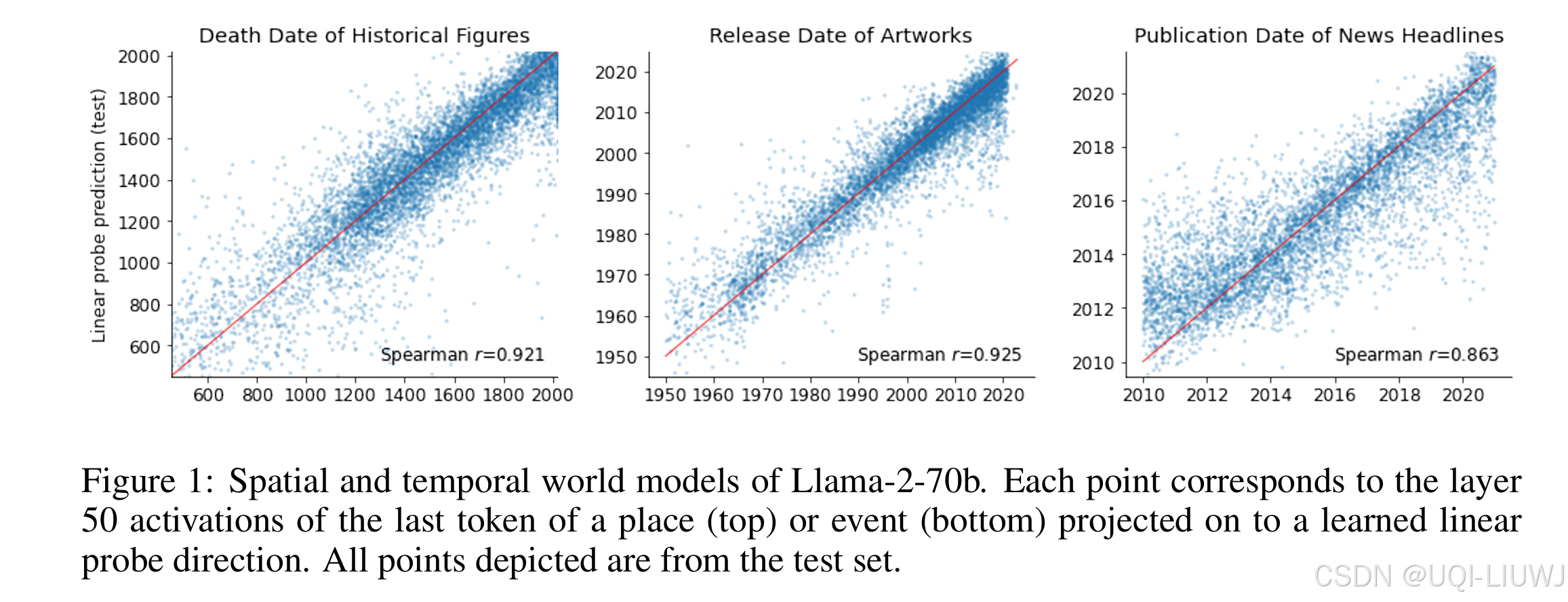
-
横轴:真实的时间;
-
纵轴:通过线性探测器预测出的时间;
-
斜线表示“完美预测”的参考线;
-
Spearman 相关性达到了非常高;
✅ 表示:模型内部表示中,能很好地恢复历史时间结构。