【群体结构ADMIXTURE之二】监督分群
官网:ADMIXTURE
说明文档:http://dalexander.github.io/admixture/admixture-mzhi'eranual.pdf
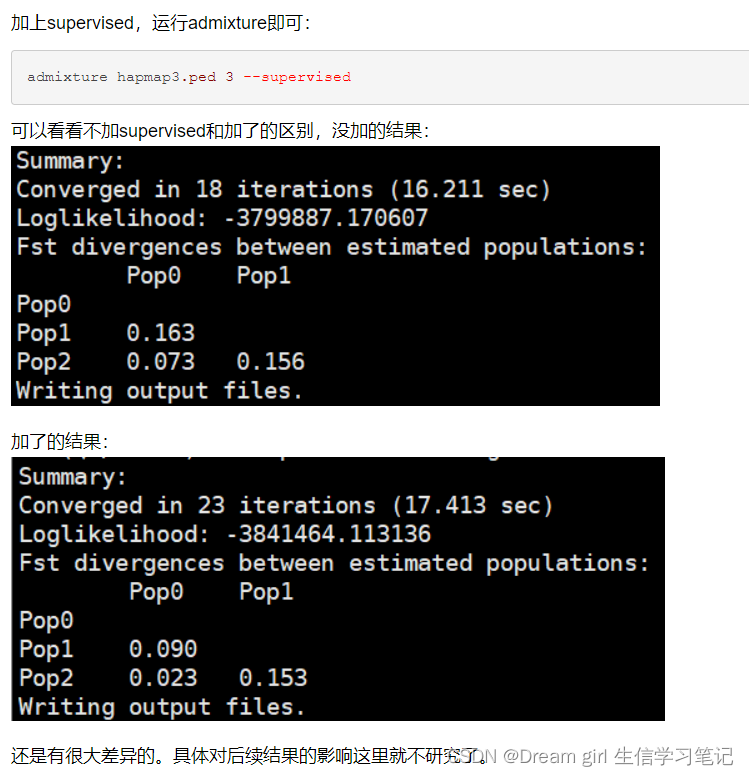
Admixture通过EM算法一般用于指定亚群分类;或者在不知材料群体结构背景下,通过迭代交叉验证获得error值,取最小error对应的K值为推荐亚群数目。如果我们预先已知群体的类型(百分百确信),那么可以考虑监督分类方法,设置标签,提高分群的准确性。Admixture的监督分群(Supervised analysis) - Bioinfarmer - 博客园
目的:基于明确已知亚群的样本集,如已知纯种AA,BB,CC。鉴定未知样本中血统AA,BB,CC占比情况,则需要利用监督分群,提高准确性(参考个体视为训练样本,问题转化为监督学习问题。)。相反如果所有样本均未知,则依然采用无监督模型。
参数:--supervised
admixture test.bed 3 --supervised
实操:补充准备pop文件--------------加参数--supervised
1.准备pop文件:根据ped/fam文件相同行号对应样本的属性,已知则用数字/字符指代,未知用-

核查pop文件,作者建议用paste合并 / 检查行数是否相等

2.加参数--supervised 运行过程(较无监督模型耗时)
PLINK v1.90b5.3 64-bit (21 Feb 2018) www.cog-genomics.org/plink/1.9/
(C) 2005-2018 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to bestqc1s_addref.log.
Options in effect:--file bestqc1s_addref--make-bed--out bestqc1s_addref1031523 MB RAM detected; reserving 515761 MB for main workspace.
.ped scan complete (for binary autoconversion).
Performing single-pass .bed write (32135 variants, 545 people).
--file: bestqc1s_addref-temporary.bed + bestqc1s_addref-temporary.bim +
bestqc1s_addref-temporary.fam written.
22135 variants loaded from .bim file.
345 people (0 males, 0 females, 545 ambiguous) loaded from .fam.
Ambiguous sex IDs written to bestqc1s_addref.nosex .
Using 1 thread (no multithreaded calculations invoked).
Before main variant filters, 545 founders and 0 nonfounders present.
Calculating allele frequencies... done.
Total genotyping rate is 0.99817.
22135 variants and 345 people pass filters and QC.
Note: No phenotypes present.
--make-bed to bestqc1s_addref.bed + bestqc1s_addref.bim + bestqc1s_addref.fam
... done.
**** ADMIXTURE Version 1.3.0 ****
**** Copyright 2008-2015 ****
**** David Alexander, Suyash Shringarpure, ****
**** John Novembre, Ken Lange ****
**** ****
**** Please cite our paper! ****
**** Information at www.genetics.ucla.edu/software/admixture ****Random seed: 43
Point estimation method: Block relaxation algorithm
Convergence acceleration algorithm: QuasiNewton, 3 secant conditions
Point estimation will terminate when objective function delta < 0.0001
Estimation of standard errors disabled; will compute point estimates only.
Supervised analysis mode. Examining .pop file... #监督分析模式 检查.pop文件
Size of G: 545x32135
Performing five EM steps to prime main algorithm
1 (EM) Elapsed: 0.445 Loglikelihood: -1.37975e+07 (delta): 2.12646e+07
2 (EM) Elapsed: 0.444 Loglikelihood: -1.37943e+07 (delta): 3286.9
3 (EM) Elapsed: 0.444 Loglikelihood: -1.3794e+07 (delta): 292.55
4 (EM) Elapsed: 0.445 Loglikelihood: -1.37937e+07 (delta): 211.71
5 (EM) Elapsed: 0.444 Loglikelihood: -1.37936e+07 (delta): 156.588
Initial loglikelihood: -1.37936e+07
Starting main algorithm
1 (QN/Block) Elapsed: 0.813 Loglikelihood: -1.3793e+07 (delta): 603.399
2 (QN/Block) Elapsed: 0.808 Loglikelihood: -1.3793e+07 (delta): 0.166831
3 (QN/Block) Elapsed: 1.348 Loglikelihood: -1.3793e+07 (delta): 5.64475e-05
Summary:
Converged in 3 iterations (6.648 sec)
Loglikelihood: -13792987.771336
Fst divergences between estimated populations: Pop0 Pop1
Pop0
Pop1 0.386
Pop2 0.406 0.294
Writing output files.LogLikelihood 似然和对数
Starting main algorithm 启动主算法
Converged in 3 iterations 3次迭代收敛(6.648秒)
Fst divergences between estimated populations: 估计种群间的Fst差异:
有博主做过测试:监督与非监督Admixture的监督分群(Supervised analysis) - Bioinfarmer - 博客园

补充:
1. 分析需要多少标记数:取决于群体的分化指数FST
群体所需的标记的数量与群体之间的遗传距离(FST)成反比。可以理解,如果群体间差异比较大,可能需要较少的标记就可以区分开来。

2. CV cross-validation procedure. 交叉验证误差
3. 贝叶斯分类算法是统计学的一种分类方法
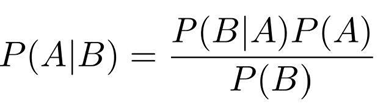
贝叶斯定理主要使用了条件概率方面的知识。通俗的讲解就是如果知道A事件,B事件分别发生的概率,还有在A事件发生时B事件发生的概率。根据上面公式就可以知道在B事件发生的情况下A事件发生的概率是多少。

贝叶斯算法 - 知乎
算法的主要想法是通过利用观察到的情况(也就是事件发生的概率)来判定未发生的事件的概率是多少。贝叶斯算法总结
以上重点参考:
Admixture使用说明文档cookbook
Admixture的监督分群(Supervised analysis) - Bioinfarmer - 博客园