清华大学视觉空间智能新突破!Spatial-MLLM:提升多模态大语言模型的视觉空间智能能力

-
作者:Diankun Wu, Fangfu Liu, Yi‑Hsin Hung, Yueqi Duan
-
单位:清华大学
-
论文标题:Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
-
论文链接:https://arxiv.org/pdf/2505.23747
-
项目主页:https://diankun-wu.github.io/Spatial-MLLM/
-
代码链接:https://github.com/diankun-wu/Spatial-MLLM
主要贡献
-
提出了Spatial-MLLM,一种能够显著提升现有视频多模态大语言模型(MLLM)在基于视觉的空间智能方面的能力的方法,无需任何3D或2.5D数据输入,即可实现强大的空间理解和推理能力。
-
设计了双编码器架构和连接器,有效整合了标准2D视觉编码器提取的语义信息和空间编码器提取的结构信息,空间编码器是基于前馈视觉几何基础模型初始化的。
-
充分利用前馈视觉几何模型提供的额外信息,设计了一种空间感知的帧采样策略,在输入长度受限的情况下,能够选择具有空间信息的帧,从而提升模型性能。
-
构建了Spatial-MLLM-120k数据集,并采用两阶段训练流程对其进行训练。大量实验表明,该方法在一系列基于视觉的空间理解和推理任务中均取得了最先进的性能。
研究背景
-
多模态大语言模型(MLLM)在处理多模态输入以生成上下文相关且语义连贯的响应方面取得了显著进展,尤其在2D视觉任务上表现出色。然而,它们在空间智能方面,即对3D场景的感知、理解和推理能力仍然有限。
-
现有的3D MLLM通常依赖额外的3D或2.5D数据(如点云、相机参数或深度图)来增强空间感知能力,这限制了它们在只有2D输入(如图像或视频)的场景中的应用。
-
视频MLLM的视觉编码器主要在图像-文本数据上进行预训练,遵循CLIP范式,擅长捕捉高级语义内容,但在只有2D视频输入时缺乏结构和空间信息,导致其在空间推理任务上的表现不如在其他任务上,且与人类能力仍有较大差距。
研究方法
Spatial-MLLM架构
Spatial-MLLM的架构基于Qwen2.5-VL-3B模型,通过引入双编码器架构和连接器来增强其空间理解能力。
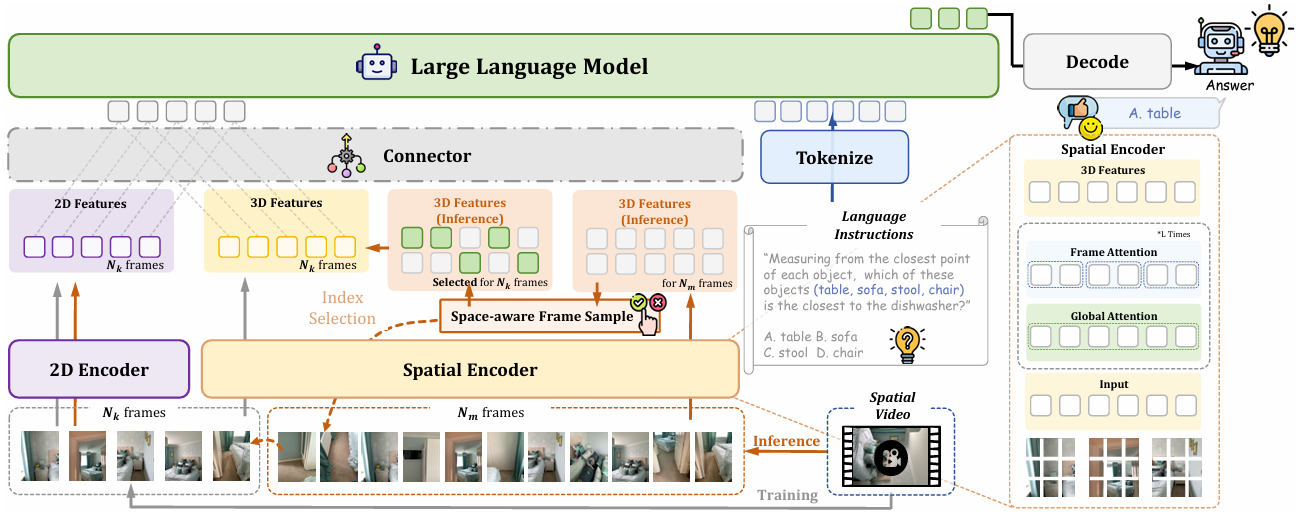
双编码器架构
-
2D编码器(E2D):采用Qwen2.5-VL的视觉编码器,负责从输入视频帧中提取语义丰富的特征。它将输入帧编码为2D特征,这些特征在空间和时间维度上对齐,以便与3D特征进行融合。
-
空间编码器(ESpatial):基于VGGT模型的特征提取器,从2D视频输入中恢复隐含的3D结构信息。它通过交替的帧内自注意力和全局自注意力,聚合不同帧之间的空间信息,生成密集的3D特征。
-
连接器(Connector):将2D特征和3D特征融合为统一的视觉标记。通过两个轻量级的多层感知机(MLP),将2D和3D特征相加,生成最终的视觉标记,供大型语言模型(LLM)使用。
空间感知帧采样策略
由于GPU内存限制,视频MLLM通常只能处理有限的帧数。因此,论文提出了一种空间感知的帧采样策略,以选择最具空间信息的帧。
-
预处理:从原始视频中均匀采样一定数量的候选帧(例如128帧)。
-
特征提取:利用空间编码器提取这些帧的3D特征和相机特征。
-
体素化和覆盖计算:将场景的3D点云离散化为体素,并计算每个帧覆盖的体素。
-
最大覆盖问题:将帧选择问题转化为最大覆盖问题,即选择覆盖最多独特体素的帧。通过贪婪算法加速求解,最终选择出最具空间信息的帧(例如16帧)。
训练
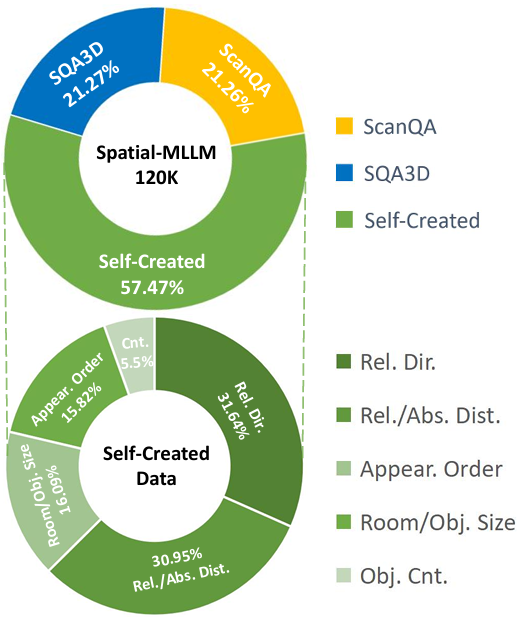
为了训练Spatial-MLLM,论文构建了一个新的数据集Spatial-MLLM-120k,并采用两阶段训练流程。
数据集构建
-
数据集包含约12万对问答,涵盖多种空间理解和推理任务。
-
数据来源包括ScanQA、SQA3D以及自创建的问答数据。
-
问答对的生成基于ScanNet的场景和语义注释,覆盖了目标计数、目标尺寸、房间尺寸、绝对距离、出现顺序、相对距离和相对方向等任务。
训练流程
-
监督微调(SFT):在Spatial-MLLM-120k数据集上进行监督微调,冻结2D和空间编码器,训练连接模块和LLM骨干网络。采用标准的交叉熵损失函数,优化模型对空间任务的理解和推理能力。
-
冷启动(Cold Start):在强化学习训练之前,通过生成少量的推理路径和答案,筛选出正确的推理路径,帮助模型适应正确的推理格式。
-
强化学习(RL)训练:采用组相对策略优化(GRPO)训练,增强模型的长链推理能力。通过设计任务相关的奖励函数,确保模型的预测结果与真实答案尽可能接近。
实验
实现细节
-
Spatial-MLLM基于Qwen2.5-VL和VGGT构建,总参数量约为4B。
-
训练时,视频帧的分辨率为640×480,输入帧数限制为16帧。
-
在SFT阶段,使用Adam优化器训练一个epoch,学习率峰值为1e-5。
-
在RL阶段,进行8次rollout,学习率为1e-6,训练1000步。
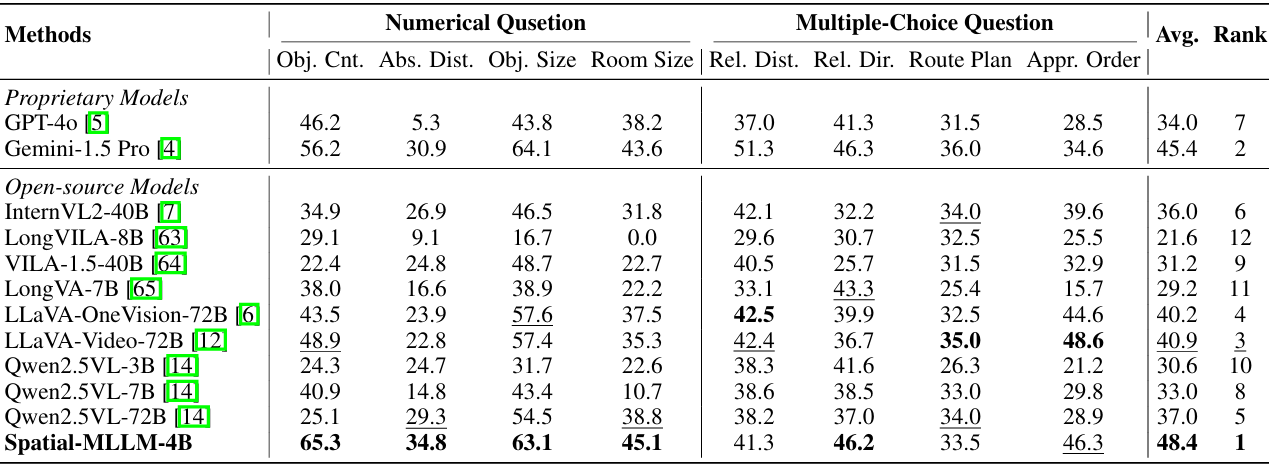
VSI-Bench基准测试对比
-
基准测试介绍:VSI-Bench包含超过5000对问答,涵盖多种任务类型,包括多项选择题和数值题。
-
对比结果:Spatial-MLLM在VSI-Bench上的表现显著优于其他专有和开源MLLM,包括参数量更大的模型。例如,与Gemini-1.5 Pro相比,Spatial-MLLM在平均准确率上高出3.0%,尽管其输入帧数较少。
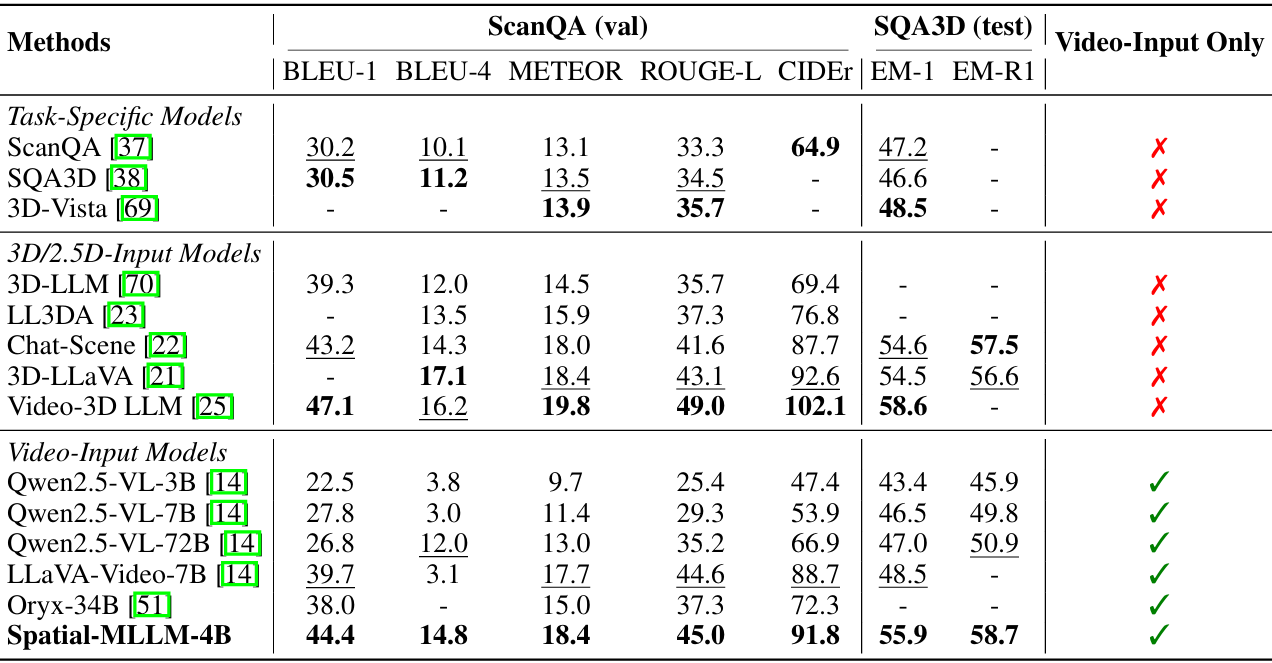
ScanQA和SQA3D基准测试对比
-
基准测试介绍:ScanQA和SQA3D是基于ScanNet构建的3D问答基准测试,包含大量的问答对,涉及空间关系理解和3D场景中的目标识别。
-
对比结果:Spatial-MLLM在ScanQA和SQA3D上均取得了优异的成绩,显著优于所有仅使用视频输入的模型,甚至超过了部分依赖额外3D或2.5D输入的模型。
消融研究与分析
-
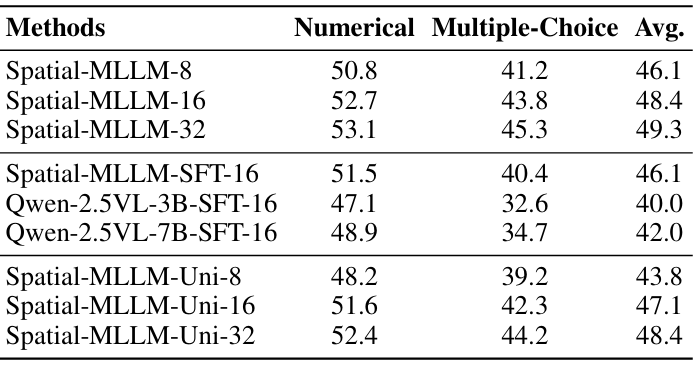
强化学习训练的有效性:通过对比监督微调版本和最终版本的Spatial-MLLM,验证了强化学习训练对提升模型性能的作用。
-
空间感知帧采样策略的有效性:通过对比不同帧采样策略下的性能,证明了空间感知帧采样策略在有限输入帧数下优于均匀采样。
-
架构的有效性:通过在相同数据集上训练Qwen2.5-VL模型,验证了Spatial-MLLM架构在提升空间推理能力方面的优势。
结论与未来工作
- 结论:
-
Spatial-MLLM通过结合语义2D编码器和结构感知的空间编码器,能够从纯2D视觉输入中有效实现空间理解和推理。
-
其双编码器设计能够捕捉语义和空间线索,空间感知帧采样策略在输入受限的情况下进一步提升了性能。
-
在多个基准测试中,Spatial-MLLM均取得了最先进的结果。
-
- 未来工作:
-
尽管Spatial-MLLM在视觉空间智能方面取得了显著进展,但仍存在扩展模型规模和训练数据的潜力。
-
此外,未来工作可以探索将空间结构信息整合到更广泛的视频理解和推理任务中,以进一步提升模型的性能和泛化能力。
-
