联邦学习聚合参数操作详解
联邦学习中常见的模型聚合操作,具体用于对来自多个客户端的模型更新进行聚合,以得到全局模型。在联邦学习框架下,多个客户端在本地训练各自的模型后,会将模型更新(通常是模型的权重)发送到中央服务器,中央服务器需要对这些本地更新进行合并,生成一个新的全局模型。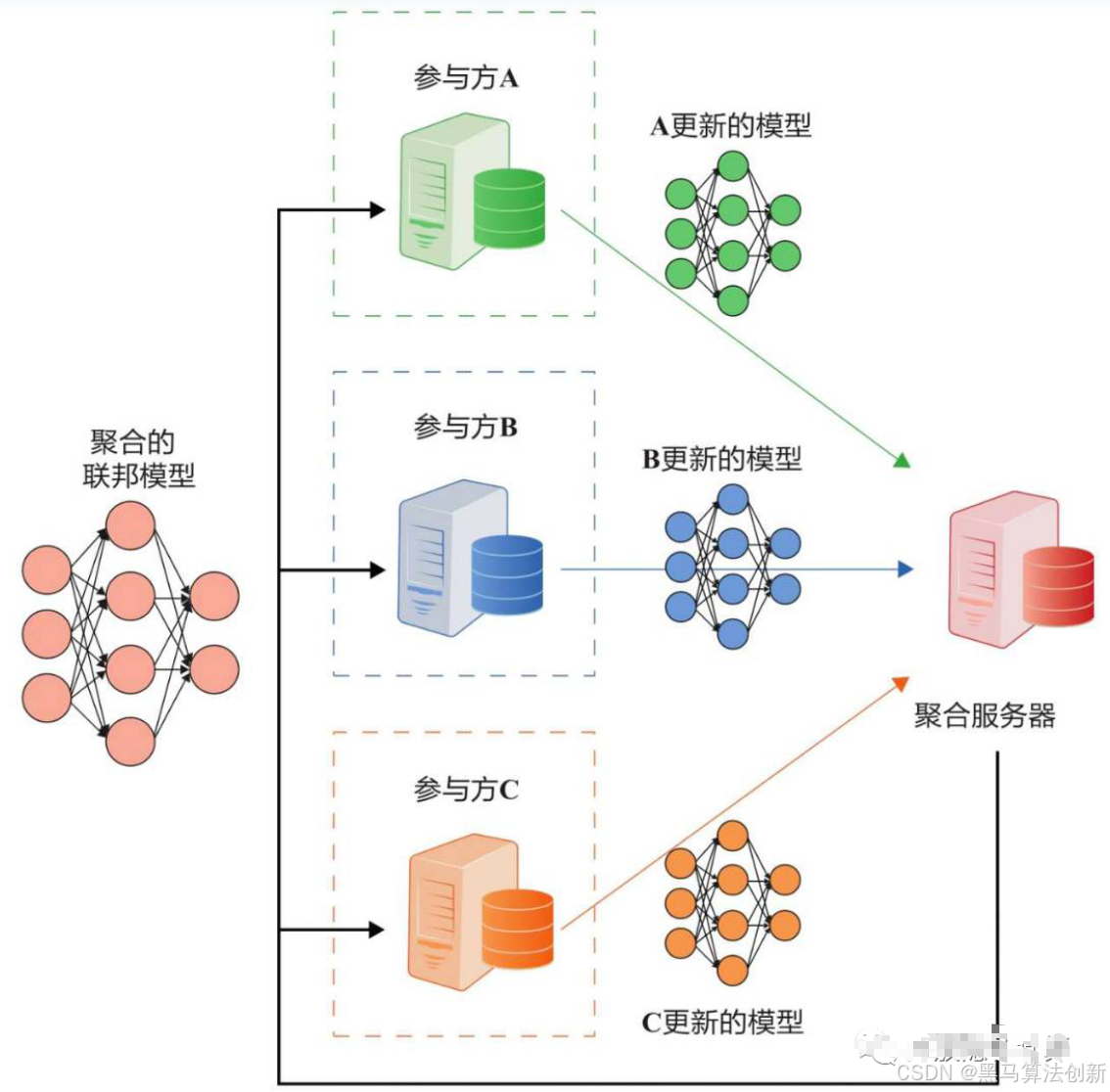
1. 初始化方法 __init__:
- 该方法接受一个参数
n_classes,通常表示分类任务中的类别数目。初始化时将其存储为类的一个成员变量,供后续使用。该参数的具体用途在代码中未直接体现,但通常它与分类任务中的类别数量有关,可能用于处理某些特定的聚合操作(例如在处理分类层时可能涉及不同类别的权重更新)。
2. agg_my 方法:
这个方法的作用是进行模型的聚合,即将多个客户端的本地模型更新合并成一个全局模型。其输入参数有:
w_local_models:包含所有客户端本地模型更新的字典。global_model:当前全局模型的权重。width_list:该列表的作用是为每个客户端指定一个权重,用于在聚合时加权不同客户端的更新。
聚合过程的核心步骤如下:
3. 遍历全局模型的各个参数:
在联邦学习中,模型通常由多个层组成,每一层都有若干个参数(例如卷积层的权重或全连接层的权重)。keys = list(w_cur.keys()) 提取全局模型 w_cur 的所有层的名称(即参数的键)。接下来,通过遍历这些键来处理每一层的聚合。
4. 初始化聚合结果的临时变量:
对于每一层的权重,首先初始化两个张量 tmp 和 count,它们的形状与当前全局模型中的权重相同。tmp 用于存储该层的加权聚合结果,而 count 用于记录每个客户端对该层权重的贡献次数。
5. 遍历本地模型的更新:
接下来,对每个客户端(w_local_models)进行遍历,并进行以下操作:
- 获取客户端的权重宽度:
width = width_list[int(cur_clnt)]表示为每个客户端指定一个宽度,这可能与数据量或客户端的权重有关。这个宽度将在后续的聚合过程中作为加权因素。 - 根据权重形状选择聚合策略:模型的不同层可能具有不同的形状(如卷积层的权重是四维的,线性层是二维的等),因此在聚合时会根据权重的形状选择不同的聚合方法:
- 对于形状为四维的权重(通常是卷积层的权重),调用
agg_my_func_4进行聚合。 - 对于形状为二维的权重(通常是全连接层的权重),调用
agg_my_func_2进行聚合。 - 对于形状为一维的权重,调用
agg_my_func_1进行聚合。 - 对于其他类型的权重,则直接使用本地客户端的权重值。
- 对于形状为四维的权重(通常是卷积层的权重),调用
6. 加权聚合:
对于每个客户端的权重更新,聚合时会使用该客户端的“宽度”(width)来加权。如果某个客户端的权重中没有该层的参数(如某些特定的层在某些客户端上没有被更新),则会用零填充以避免影响聚合结果。
7. 处理客户端数据缺失:
- 对于某些权重,在某些客户端中可能没有相应的更新(例如某个客户端在某些层上的训练不充分或者没有更新该层的参数)。此时,该层的权重更新将用零填充。
count[count == 0] = 1这一行的目的是防止在某些客户端没有贡献时,出现除以零的情况。在聚合过程中,如果某个权重的更新次数为零,则将其计数置为1,避免在后续计算时出现除零错误。
8. 最终权重更新:
每一层的权重更新结果是通过累积所有客户端的更新结果(即 tmp)并将其除以对应的计数(count)来实现的。这实际上是对每一层权重的加权平均,即全局模型的权重是由所有客户端的加权贡献形成的。
9. 返回新的全局模型:
最终,w_cur[k] = w_cur[k] / count 对全局模型的每一层进行更新,得到加权平均后的结果,最终返回更新后的全局模型。