【AI论文精读7】GraphRAG
【AI论文解读】【AI知识点】【AI小项目】【AI战略思考】【AI日记】【读书与思考】【AI应用】
简介
论文地址
https://arxiv.org/pdf/2404.16130
精读理由
- 这是微软开源的一个重要的 RAG 模型
摘要
通过使用检索增强生成(retrieval-augmented generation, RAG),从外部知识源检索相关信息,大语言模型(large language model, LLM)能够回答关于私有或未见过的文档集合的问题。然而,对于针对整个文本语料库的全局问题(例如 “数据集的主要主题是什么?”),RAG 往往表现不佳,因为这本质上是一个面向查询的总结(query-focused summarization, QFS)任务,而不是一个明确的检索任务。同时,现有的 QFS 方法难以扩展到典型 RAG 系统所索引的大量文本。
为了结合这些方法的优势,我们提出了一种 Graph RAG 方法,用于处理私有文本语料库的问答任务。该方法在用户问题的泛化能力和待索引文本数量方面具有较好的扩展性。我们的方法分两步利用 LLM 构建基于图的文本索引:
- 从源文档中生成一个实体知识图谱。
- 为所有紧密相关的实体组预生成社区摘要。
在回答问题时,每个社区摘要都会生成一个部分回答,随后将所有部分回答汇总为最终的用户响应。对于一类包含 100 万标记范围的全局意义理解问题,我们的研究表明,Graph RAG 在生成答案的全面性和多样性方面,相较于基础的 RAG 方法取得了显著改进。
我们将提供一个支持全局和局部 Graph RAG 方法的开源 Python 实现,详情参见 https://aka.ms/graphrag。
1 引言
在人类的各个领域,我们依赖阅读和推理来处理大量文档,往往得出超越原始文本所述内容的结论。随着大语言模型(large language model, LLM)的出现,我们已经看到在复杂领域(如科学发现和情报分析)中,自动化的人类式认知初见端倪。Klein 等人(2006a)将这种认知定义为 “为了预测趋势并有效行动而进行的主动、持续努力,以理解事物之间的联系(包括人与地点、事件之间的关系)”。要支持由人主导的整个语料库的认知过程,人们需要通过提出全局性问题来应用和改进对数据的心理模型(Klein 等人,2006b)。
检索增强生成(RAG)是一种针对整个数据集回答用户问题的成熟方法,但它适用于答案可以从文本中局部检索到的情况。然而,针对全局性问题,更合适的任务框架是面向查询的摘要(query-focused summarization, QFS),尤其是生成自然语言摘要的面向查询的抽象摘要,而非简单的文本拼接。然而,近年来,关于摘要任务(抽象与提取、通用与面向查询、单文档与多文档)的区分变得不再重要。随着变换器架构(transformer)早期应用的成功(例如 Goodwin 等人,2020;Laskar 等人,2022),现代 LLM(如 GPT、Llama 和 Gemini 系列)已通过上下文学习在任何内容的摘要中表现优异。
尽管如此,全语料库的面向查询抽象摘要仍面临挑战。如此大量的文本远超 LLM 上下文窗口的限制,且即便窗口扩大,也可能导致关键信息在长上下文中丢失(Kuratov 等人,2024;Liu 等人,2023)。此外,尽管直接检索文本片段的基础 RAG 对 QFS 任务可能不足,但通过预先索引的替代形式,有可能支持一种新型 RAG 方法,专门面向全局摘要。
本文提出了一种基于图的 RAG 方法,通过 LLM 生成的知识图谱实现全局摘要(图 1)。不同于利用图索引进行结构化检索和遍历的相关工作(第 4.2 节),我们专注于图在该背景下的未被探索的特性:图的模块化(Newman,2006)以及社区检测算法(如 Louvain 算法和 Leiden 算法)将图划分为紧密相关节点模块的能力。LLM 生成的这些社区描述摘要能够全面覆盖图索引及其所代表的输入文档。
全语料库的面向查询摘要通过一种 map-reduce 方法实现:首先利用每个社区摘要并行独立地回答查询,然后将所有相关的部分答案汇总为最终的全局答案。
为了评估这一方法,我们使用 LLM 从两个代表性现实数据集的短描述中生成了一组多样化的活动中心认知问题。这两个数据集分别包含播客转录和新闻文章。我们探讨了使用不同层级的社区摘要回答查询对理解广泛主题的全面性、多样性和启发性的影响,并将其与基础 RAG 和对源文本的全局 map-reduce 摘要方法进行比较。结果表明,所有全局方法在全面性和多样性方面均优于基础 RAG,而基于图的 RAG 方法在中低层级社区摘要下,相较于源文本摘要,表现更优且代价更低。
图 1
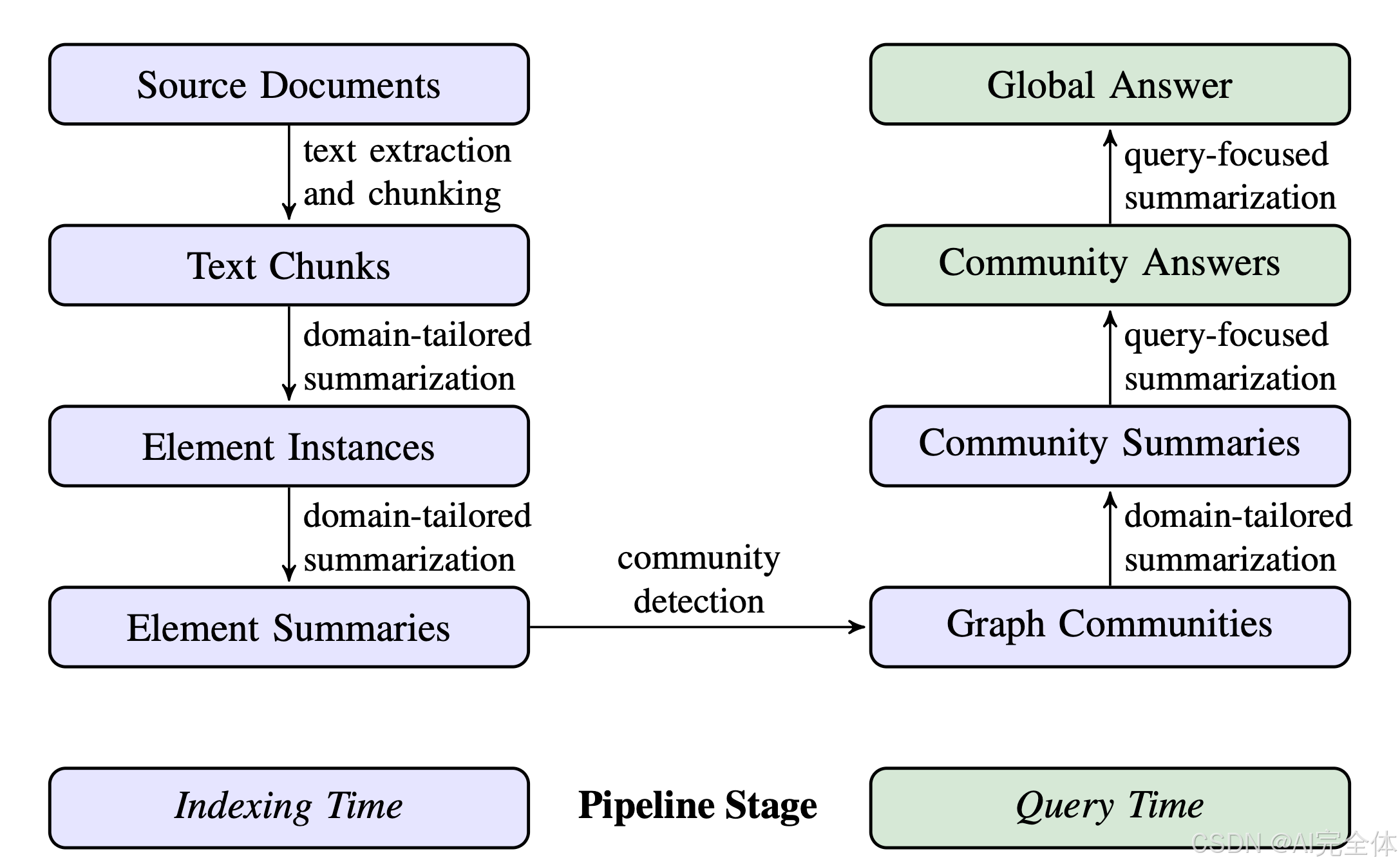
2 基于图的 RAG 方法与流程
我们将详细介绍基于图的 RAG 方法的高级数据流(如图 1 所示)和处理流程,描述每一步中的关键设计参数、技术和实现细节。
2.1 从源文档到文本片段
一个重要的设计决策是如何将从源文档提取的输入文本划分为文本片段进行处理。在下一步中,每个文本片段都会被传递给一组 LLM 提示,用于提取图索引的各种元素。较长的文本片段需要较少的 LLM 调用以完成提取,但可能受到长 LLM 上下文窗口召回率下降的影响(Kuratov 等人,2024;Liu 等人,2023)。如图 2 所示,在单轮提取的情况下(即没有补充提取时),在一个示例数据集(HotPotQA, Yang 等人,2018)中,使用 600 个标记的片段提取的实体引用几乎是 2400 个标记片段的两倍。尽管更多的引用通常是有益的,但任何提取过程都需要在目标活动的召回率和精确度之间找到平衡。
图 2
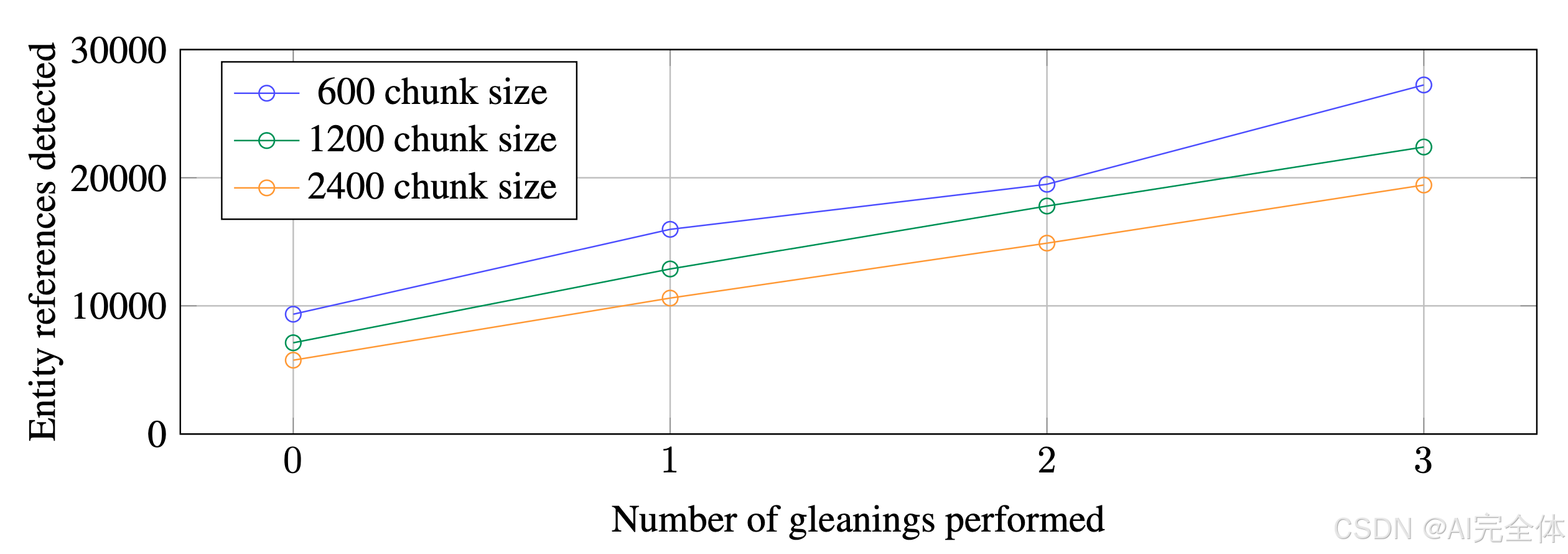
图 2 展示了在 HotPotQA 数据集(Yang et al., 2018)上,使用通用实体提取提示(generic entity extraction prompt)和 gpt-4-turbo 模型时,实体引用检测数量如何随文本片段大小(chunk size)和补充提取轮次(gleanings performed)的变化。
以下是图中的关键内容:
-
曲线说明:
- 蓝色曲线表示片段大小为 600 tokens 的检测结果。
- 绿色曲线表示片段大小为 1200 tokens 的检测结果。
- 橙色曲线表示片段大小为 2400 tokens 的检测结果。
-
纵轴(Entity references detected):表示检测到的实体引用数量,数值越大说明提取的实体引用越多。
-
横轴(Number of gleanings performed):表示补充提取轮次,从 0 到 3。补充提取是为了发现前一轮提取中可能遗漏的实体。
-
趋势说明:
- 随着补充提取轮次的增加,检测到的实体引用数量逐步增加。
- 片段大小较小(如 600 tokens)时,检测到的实体引用数量更高。这是因为较小的片段更适合 LLM 在有限的上下文窗口内准确提取实体,减少了信息丢失。
-
对比说明:
- 在 0 轮补充提取的情况下,片段大小为 600 tokens 检测到的实体数量几乎是 2400 tokens 的两倍。
- 补充提取轮次越多,不同片段大小之间的差距逐渐缩小,但 600 tokens 始终略胜一筹。
结论:
- 较小的片段大小在初始提取时更高效,但可能增加 LLM 调用的次数。
- 补充提取有助于提高大片段的实体检测性能,但片段大小过大仍会导致召回率下降。
- 设计时需要在片段大小与补充提取轮次之间进行平衡,以优化实体引用的召回率和处理效率。
2.2 从文本片段到元素实例
此步骤的基本要求是从每个文本片段中识别并提取图节点和边的实例。我们通过一个多部分的 LLM 提示实现这一点,首先识别文本中的所有实体,包括其名称、类型和描述,然后识别所有明确相关实体之间的关系,包括源实体、目标实体及其关系的描述。这两类元素实例以分隔元组的列表形式输出。
定制此提示以适应文档语料库领域的主要机会在于为 LLM 提供少样本示例以进行上下文学习(Brown 等人,2020)。例如,尽管默认提示提取的 “命名实体” 类别(如人、地点、组织)通常适用,但具有专业知识的领域(如科学、医学、法律)将从针对这些领域的少样本示例中受益。此外,我们还支持辅助提取提示,用于提取与节点实例相关联的附加协变量。默认的协变量提示旨在提取与检测到的实体相关的声明,包括主体、客体、类型、描述、源文本范围以及起止日期。
为平衡效率和质量,我们使用多轮“补充提取”(gleanings),最多达到指定的最大轮次,以鼓励 LLM 检测其在前几轮中可能遗漏的额外实体。这是一个多阶段过程,我们首先要求 LLM 评估是否提取了所有实体,使用 logit 偏置为 100 强制其做出是/否的决定。如果 LLM 回答有遗漏实体,则一个指示“上次提取中遗漏了许多实体”的补充提示会鼓励 LLM 提取这些遗漏的实体。这种方法允许我们在不降低质量或引入噪声的情况下使用更大的片段大小(如图 2 所示)。
2.3 从元素实例到元素摘要
使用 LLM 提取源文本中表示的实体、关系和声明的描述,本质上是一种抽象摘要,依赖于 LLM 创建独立且有意义的概念摘要,包括文本中可能隐含但未明确说明的关系(例如隐含关系的存在)。将这些实例级别的摘要转化为每个图元素(即实体节点、关系边和声明协变量)的单个描述性文本块,需要进一步通过匹配的实例组进行 LLM 摘要处理。
此阶段的一个潜在问题是,LLM 可能无法一致地以相同的文本格式提取对同一实体的引用,从而导致实体重复,并因此在实体图中生成重复节点。然而,由于所有紧密相关的实体“社区”将在后续步骤中被检测和总结,并且考虑到 LLM 能够理解多个名称变体背后的共同实体,只要所有变体与一组紧密相关实体具有足够的连接性,我们的方法对这种变体具有弹性。
总体而言,我们使用丰富的描述性文本来表示潜在嘈杂图结构中的同质节点,这种方法既符合 LLM 的能力,也满足了全局面向查询摘要的需求。这些特性也使我们的图索引区别于典型的知识图谱,后者依赖于简洁一致的知识三元组(主体、谓语、客体)来支持后续的推理任务。
2.4 从元素摘要到图社区
在前一步中创建的索引可以建模为一个同质的无向加权图,其中实体节点通过关系边相连,边的权重表示检测到的关系实例的归一化计数。在此基础上,可以使用多种社区检测算法将图划分为节点间连接更强的社区(相比于图中其他节点的连接强度更低的社区)。相关研究综述可见 Fortunato(2010)和 Jin 等人(2021)。在我们的流程中,我们选择 Leiden 算法(Traag 等人,2019),因为它能够高效地恢复大规模图的层次化社区结构(如图 3 所示)。该层次结构的每一层提供了一种互斥且穷尽的社区划分方式,从而支持分而治之的全局摘要任务。
2.4 解释
这段内容的主要内容是关于在基于图的索引中如何使用社区检测算法划分社区,以及这种方法的优点。
核心解释
-
图的构建:
- 在上一阶段创建的索引被建模为一个同质的无向加权图。
- 节点代表实体(entities),边代表实体之间的关系(relationships)。
- 边的权重表示检测到的关系实例的归一化计数(normalized counts of detected relationship instances),反映了关系的强度。
-
社区检测的目标:
- 通过社区检测算法,将图划分为若干个社区。
- 社区中的节点之间的连接比与其他节点的连接更强,从而形成结构紧密的子图。
-
算法选择:
- 文中采用了 Leiden 算法(Traag et al., 2019),因为它能够高效地从大规模图中恢复层次化的社区结构。
- Leiden 算法在计算性能和社区结构的质量上表现优异,特别适合处理复杂的大型图数据。
-
层次化社区结构:
- Leiden 算法生成的层次化结构为每个层级提供了一种互斥(mutually-exclusive)、穷尽(collective-exhaustive)的社区划分方式。
- 这种划分方式保证图中的所有节点都被包含,同时不会重复分配到多个社区。
-
全局摘要的支持:
- 层次化社区结构允许使用“分而治之”的方法进行全局摘要。
- 每个层级的社区划分为后续的全局语义分析和问题回答提供了多种精细程度的视角。
应用意义
通过构建层次化社区结构,这种方法不仅能够有效组织和管理大规模的图数据,还能为后续基于查询的全局摘要提供一种灵活且高效的框架。每一层的社区划分都可以被用于不同程度的总结需求,从而实现更精确的全局信息表达。
图 3
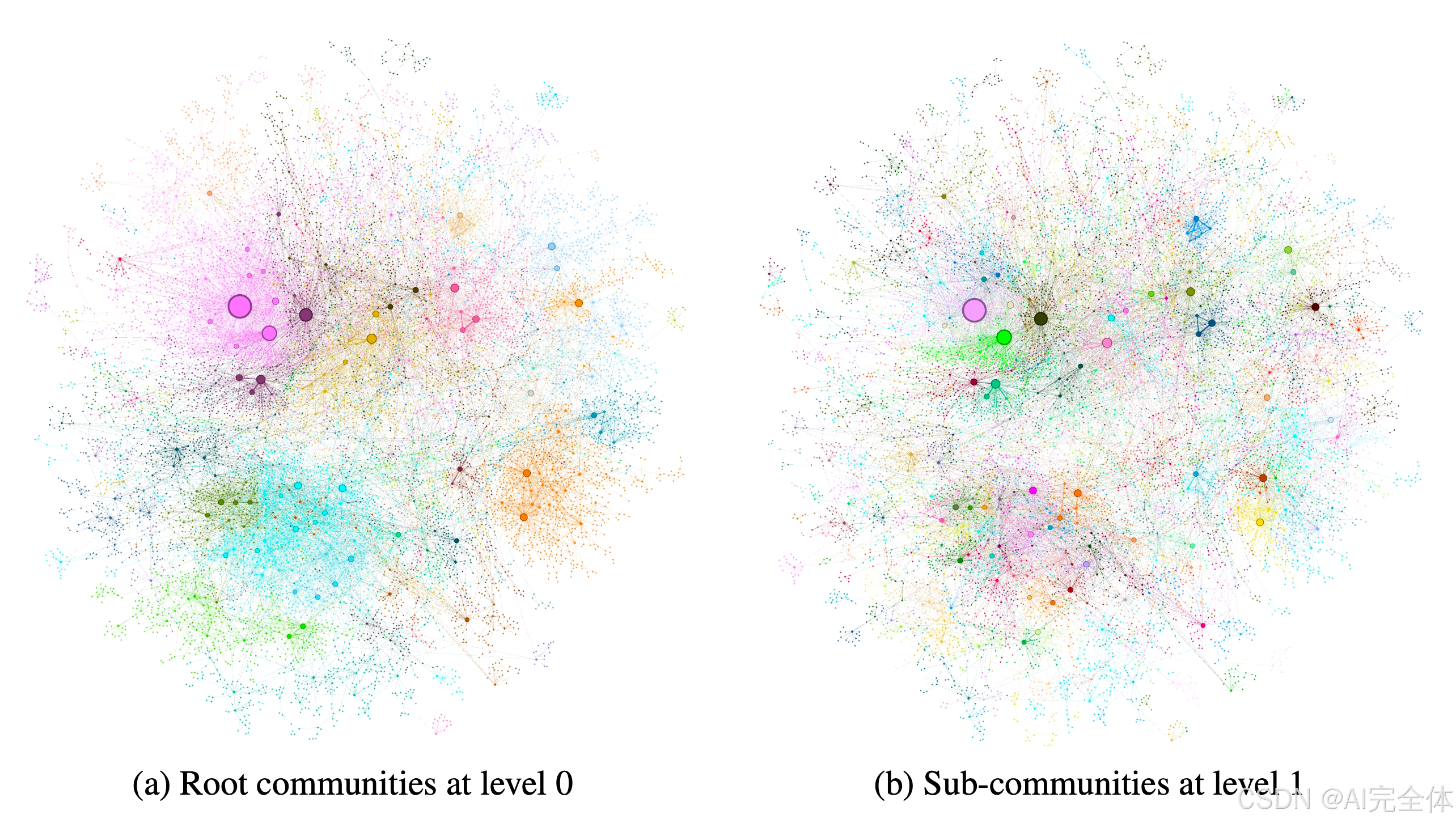
这张图(Figure 3)展示了使用 Leiden 算法在 MultiHop-RAG 数据集(Tang and Yang, 2024)上检测到的图社区(graph communities),分为两个层级的层次化聚类结果。
图中内容解释
-
图的基本构造:
- 圆圈表示实体节点(entity nodes),节点的大小与节点的度数(degree)成正比,即节点连接边的数量越多,圆圈越大。
- 节点的颜色表示它们所属的社区,不同颜色对应不同的社区。
-
节点布局:
- 图的布局是通过 OpenORD(Martin et al., 2011)和 Force Atlas 2(Jacomy et al., 2014)算法生成的。这些布局算法的目的是让连接较强的节点更接近,从而更直观地呈现社区结构。
-
两种层次的社区:
- (a) Root communities at level 0:这一图表示层次化聚类的第 0 层(根社区),对应于具有最大模块化(modularity)的层级划分。这一层展示了数据集的全局社区划分,即不同颜色的大块区域表示较大的社区,每个社区包含较强内部联系的节点。
- (b) Sub-communities at level 1:这一图表示层次化聚类的第 1 层(子社区)。在这个层级中,每个根社区进一步被划分为多个子社区,揭示了根社区内更细粒度的内部结构。
-
社区结构的层次化意义:
- 第 0 层社区(左图)提供了整体的社区分布和大规模语义群组。
- 第 1 层社区(右图)进一步细化了每个根社区的内部结构,揭示了子主题或子语义的组织方式。
应用意义
- 全局分析:第 0 层的社区划分有助于用户快速了解数据集的宏观结构和主要语义群组。
- 细粒度分析:第 1 层的子社区划分则帮助用户深入挖掘每个主题的内部细节,例如子主题之间的关系。
- 动态问答:这种层次化社区结构可以支持不同层次的查询回答,例如用户可以针对第 0 层提出全局问题,或针对第 1 层提出更具体的子问题。
总结
这张图清晰地展示了如何通过 Leiden 算法检测层次化的社区结构,并通过不同颜色和节点大小直观地表达了数据集的全局和局部语义关系。它为全局理解、语义聚类以及回答复杂查询提供了坚实的基础。
2.5 从图社区到社区摘要
下一步是为 Leiden 层次结构中的每个社区创建类似报告的摘要,这一方法设计用于扩展至超大规模数据集。这些摘要本身就是理解数据集全局结构和语义的独立工具,甚至可以在没有具体问题的情况下帮助理解语料库。例如,用户可以浏览某一层级的社区摘要以查找感兴趣的主题,然后通过链接查看更低层次的报告以获取各子主题的详细信息。在此,我们主要关注这些社区摘要在回答全局性问题中的作用,作为基于图的索引的一部分。
社区摘要的生成方式如下:
- 叶级社区:对叶级社区的元素摘要(节点、边、协变量)进行优先排序,然后依次将这些摘要添加到 LLM 的上下文窗口中,直到达到标记限制。优先排序规则如下:按社区边的源节点和目标节点的度数总和(即整体显著性)从高到低排列,为每条边添加其源节点、目标节点、相关协变量和边本身的描述。
- 高层级社区:如果所有元素摘要都能在上下文窗口的标记限制内容内,则按照叶级社区的方式对所有元素摘要进行总结。否则,按子社区的元素摘要标记数量从多到少排序,并逐步用子社区摘要(更短)替代其关联的元素摘要(更长),直到满足上下文窗口限制。
2.5 解释
这段内容解释了如何从图社区(graph communities)生成社区摘要(community summaries),以及这些摘要在理解数据集结构和回答全局性问题中的作用。
核心内容解释
-
社区摘要的目的:
- 生成的社区摘要类似报告形式,主要目的是提供对每个社区的结构和语义的概述。
- 这些摘要不仅在回答问题时有用,还可以帮助用户在没有具体问题时理解数据集。例如:
- 用户可以浏览某一级别的社区摘要来发现感兴趣的主题。
- 然后深入查看较低层次的报告以获取每个子主题的详细信息。
-
社区摘要的生成方法:
- 叶级社区(leaf-level communities):
- 针对每个叶级社区(社区层次结构中的最底层),按以下优先级将其元素摘要(节点、边、协变量)依次加入到 LLM 的上下文窗口中,直到达到标记限制:
- 优先级基于社区边的源节点和目标节点的度数总和(combined source and target node degree),即整体显著性。
- 对于每条社区边,依次添加源节点、目标节点、相关协变量及边本身的描述。
- 针对每个叶级社区(社区层次结构中的最底层),按以下优先级将其元素摘要(节点、边、协变量)依次加入到 LLM 的上下文窗口中,直到达到标记限制:
- 高层级社区(higher-level communities):
- 如果所有元素摘要都能在上下文窗口的标记限制内容内,则像叶级社区一样对其元素摘要进行总结。
- 如果不能容纳所有摘要,则:
- 按子社区的元素摘要标记数量从多到少排序。
- 逐步用较短的子社区摘要替代较长的元素摘要,直到满足上下文窗口的限制。
- 叶级社区(leaf-level communities):
-
方法的扩展性:
- 这种方法能够扩展到非常大的数据集。
- 社区摘要在捕捉全局结构的同时,可以根据用户查询灵活调整细节和范围,支持大规模问答系统。
应用意义
社区摘要的生成过程不仅优化了信息的组织方式,还在满足不同上下文窗口限制的同时,实现了高效的语义表达和总结。这种方法在大规模语料库的全局性问题回答中非常有用,尤其是在需要综合分析多层级信息的场景下。
补充:社区边的源节点和目标节点的度数总和
“社区边的源节点和目标节点的度数总和”是指在图中的一条边,它连接了两个节点(源节点和目标节点),并计算这两个节点的度数之和。
什么是“节点的度数”?
- 节点的度数是指与该节点相连的边的数量。
- 例如,如果一个节点有 3 条边连向其他节点,那么它的度数就是 3。
- 节点的度数可以用来衡量该节点在网络中的“重要性”或“显著性”。
为什么需要计算总和?
- 每条边连接了两个节点,源节点(source node)和目标节点(target node)。
- 计算这两个节点的度数总和是为了衡量这条边所连接的两个节点在图中的综合显著性。
- 度数总和越大,说明这条边连接了两个更“活跃”或更“重要”的节点。
- 优先处理度数总和较高的边可以确保上下文窗口中优先包含更具代表性或更关键的信息。
应用场景
在生成社区摘要时:
- 对社区内的边按其源节点和目标节点的度数总和进行排序。
- 优先选择度数总和较大的边及其相关信息(如节点的描述、边的属性等)添加到 LLM 的上下文窗口中。
- 这样可以确保在有限的标记限制内,包含最有可能对全局摘要或查询回答产生影响的关键信息。
一个简单例子
假设图中有三条边和它们的节点度数:
- 边 1:节点 A(度数 5) → 节点 B(度数 3),总和为 5 + 3 = 8 5 + 3 = 8 5+3=8。
- 边 2:节点 C(度数 2) → 节点 D(度数 1),总和为 2 + 1 = 3 2 + 1 = 3 2+1=3。
- 边 3:节点 E(度数 4) → 节点 F(度数 4),总和为 4 + 4 = 8 4 + 4 = 8 4+4=8。
根据总和排序:
- 边 1 和边 3 的优先级更高,因为它们的总和较大。
- 这些边会优先被选入上下文窗口进行摘要处理。
总结
计算源节点和目标节点的度数总和是一种基于节点“重要性”的排序方式,用于在有限资源内优先处理关键的图结构信息,提升摘要生成的效率和效果。
2.6 从社区摘要到社区答案再到全局答案
在给定用户查询的情况下,可以使用前一步生成的社区摘要通过多阶段流程生成最终答案。社区结构的层次化特性意味着可以使用不同层级的社区摘要来回答问题,这引发了一个问题:某个特定层级是否能在摘要细节和范围之间提供最佳平衡以回答一般性的认知问题(将在第 3 节中评估)。
对于某个特定的社区层级,生成用户查询的全局答案的流程如下:
- 准备社区摘要:随机打乱社区摘要,并按预设标记大小将其分成若干片段。这样可以确保相关信息分布在多个片段中,而不是集中在单一上下文窗口内(从而可能被丢失)。
- 映射社区答案:并行生成每个片段的中间答案。LLM 还会生成一个 0 到 100 的分数,指示生成的答案在回答目标问题方面的帮助程度。分数为 0 的答案会被过滤掉。
- 合并为全局答案:按帮助分数从高到低对中间社区答案排序,并依次将其添加到新的上下文窗口中,直到达到标记限制。最终上下文用于生成返回给用户的全局答案。
3 评估
3.1 数据集
我们选择了两个包含约一百万标记的数据集,相当于大约 10 本小说的文本,代表用户在现实活动中可能遇到的语料库类型:
- 播客转录文本:由微软首席技术官 Kevin Scott 与其他技术领袖之间的播客对话转录组成(Behind the Tech,Scott,2024)。规模:1669 个 600 标记的文本片段,片段之间有 100 标记的重叠(约 100 万标记)。
- 新闻文章:包含 2013 年 9 月至 2023 年 12 月间发布的多种类别的新闻文章,包括娱乐、商业、体育、技术、健康和科学(MultiHop-RAG,Tang 和 Yang,2024)。规模:3197 个 600 标记的文本片段,片段之间有 100 标记的重叠(约 170 万标记)。
3.2 查询
开放域问答的许多基准数据集已经存在,包括 HotPotQA(Yang 等人,2018)、MultiHop-RAG(Tang 和 Yang,2024)和 MT-Bench(Zheng 等人,2024)。然而,这些数据集中的问题主要针对明确的事实检索,而非用于数据认知的总结,即帮助用户在现实活动的广阔背景下检查、理解和将数据置于上下文中的过程(Koesten 等人,2021)。同样,从源文本中提取潜在摘要查询的方法也存在(Xu 和 Lapata,2021),但这些提取的问题可能会偏向文本的先验知识细节。
为了评估 RAG 系统在全局认知任务中的有效性,我们需要仅传递数据集内容高层次理解的问题,而不是具体文本的细节。我们采用了一种以活动为中心的方法来自动生成此类问题:根据数据集的简短描述,我们要求 LLM 识别 N 个潜在用户和每个用户的 N 个任务,然后针对每个(用户,任务)组合,生成 N 个需要理解整个语料库的问题。对于我们的评估,N = 5 生成了每个数据集 125 个测试问题。表 1 展示了每个评估数据集的示例问题。
表 1
表 1 展示了每个评估数据集的示例问题。

3.3 条件
我们的分析比较了六种不同的条件,包括基于图的 RAG 方法(Graph RAG)中使用的四个不同层次的社区(C0、C1、C2、C3)、直接对源文本应用 map-reduce 方法的文本摘要方法(TS)以及一个简单的“语义搜索” RAG 方法(SS):
- C0:使用根级社区摘要(数量最少)回答用户查询。
- C1:使用高层级社区摘要回答查询。这些社区是 C0 的子社区(如果存在),否则为 C0 社区的降级投影。
- C2:使用中间层级社区摘要回答查询。这些社区是 C1 的子社区(如果存在),否则为 C1 社区的降级投影。
- C3:使用低层级社区摘要(数量最多)回答查询。这些社区是 C2 的子社区(如果存在),否则为 C2 社区的降级投影。
- TS:与第 2.6 小节的方法相同,但将源文本(而非社区摘要)随机打乱并分片,用于 map-reduce 总结阶段。
- SS:一种简单的 RAG 实现,其中从文本片段中检索数据并将其添加到上下文窗口,直到达到指定的标记限制。
在所有六种条件下,生成答案的上下文窗口大小和提示是相同的(除了一些为匹配上下文信息类型的参考样式的小修改)。条件之间的差异仅在于上下文窗口的内容如何创建。
支持 C0-C3 条件的图索引仅通过通用提示生成实体和关系的提取,并根据数据领域调整实体类型和少样本示例。图索引过程使用的上下文窗口大小为 600 标记,播客数据集进行了 1 次补充提取,新闻数据集未进行补充提取。
3.4 评估指标
研究表明,大语言模型(LLM)在评估自然语言生成方面表现出色,达到了与人类评价相当甚至超越的水平(Wang 等人,2023a;Zheng 等人,2024)。这种方法可以在已知标准答案的情况下生成基于参考的评估指标,也可以以无参考的方式评估生成文本的质量(例如流畅性)(Wang 等人,2023a),并用于对比生成的竞争性输出(“以 LLM 为评审”方法,Zheng 等人,2024)。此外,LLM 在评估传统 RAG 系统的性能方面也展现了潜力,能够自动评估诸如上下文相关性、忠实性和答案相关性等属性(RAGAS,Es 等人,2023)。
鉴于 Graph RAG 机制的多阶段特性、需要比较的多个条件,以及缺乏活动性认知问题的标准答案,我们决定采用基于 LLM 评审的“对比评估”方法。我们选择了三个目标指标来衡量认知活动中理想的属性,同时使用一个控制指标(直接性)来验证结果的有效性。由于直接性与全面性和多样性本质上是对立的,我们并不期望任何方法在所有四个指标上都占据优势。
使用 LLM 评审计算的对比指标如下:
- 全面性(Comprehensiveness):答案在覆盖问题的所有方面和细节上提供了多少信息?
- 多样性(Diversity):答案在提供不同视角和洞察方面有多丰富和多样?
- 启发性(Empowerment):答案在帮助读者理解主题并做出明智判断方面的效果如何?
- 直接性(Directness):答案在多大程度上具体且清晰地回应了问题?
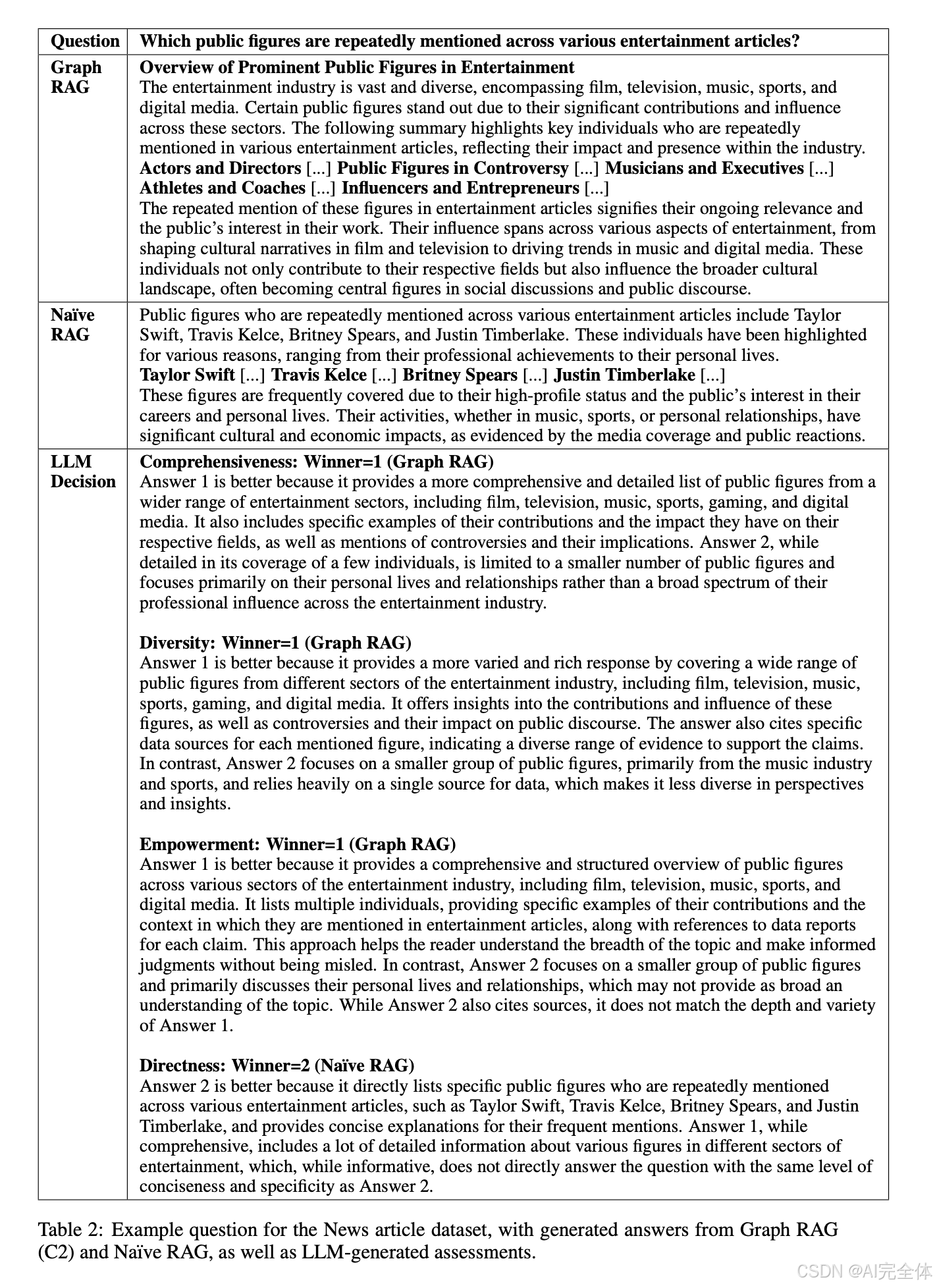
在评估过程中,LLM 被提供问题、目标指标以及一对答案,并被要求根据指标评估哪一个答案更好,并说明理由。如果答案之间没有显著差异,则返回“平局”。为了消除 LLM 的随机性,每次对比重复五次,并取平均分作为最终结果。表 2 展示了由 LLM 生成的评估示例。
表 2
表 2 展示了由 LLM 生成的评估示例。
3.5 配置
上下文窗口大小对特定任务的影响尚不明确,尤其是对具有 128k 标记大上下文窗口的模型(如 gpt-4-turbo)。由于较长上下文可能导致信息在中间部分“丢失”(Kuratov 等人,2024;Liu 等人,2023),我们希望探索不同上下文窗口大小对数据集、问题和评估指标的组合的影响。具体来说,我们的目标是确定基线条件(SS)的最佳上下文窗口大小,并在所有查询时 LLM 使用中保持一致。为此,我们测试了四种上下文窗口大小:8k、16k、32k 和 64k。令人惊讶的是,最小的上下文窗口大小(8k)在全面性方面的表现普遍更好(平均胜率为 58.1%),同时在多样性(平均胜率为 52.4%)和启发性(平均胜率为 51.3%)上与更大的上下文窗口表现相当。鉴于我们更倾向于更全面和多样化的答案,我们在最终评估中固定使用 8k 标记的上下文窗口大小。
3.6 结果
索引过程生成的图包括播客数据集的 8564 个节点和 20691 条边,以及新闻数据集的较大图,包含 15754 个节点和 19520 条边。表 3 显示了每个图社区层次结构不同层级的社区摘要数量。
全局方法与简单 RAG 的对比
如图 4 所示,全局方法在两个数据集的全面性和多样性指标上均持续优于简单 RAG(SS)方法。具体而言,全局方法在播客转录文本上的全面性胜率为 72-83%,在新闻文章上的胜率为 72-80%;多样性胜率在播客转录文本中为 75-82%,新闻文章中为 62-71%。作为有效性测试的直接性指标也达到了预期结果,即简单 RAG 在所有对比中生成了最直接的回答。
社区摘要与源文本的对比
在使用 Graph RAG 比较社区摘要与源文本时,社区摘要通常在答案的全面性和多样性上提供了小幅但稳定的改进,根级摘要除外。播客数据集的中间层社区摘要和新闻数据集的低层社区摘要分别在全面性上取得了 57% 和 64% 的胜率。在多样性方面,播客中间层社区摘要和新闻低层社区摘要的胜率分别为 57% 和 60%。表 3 还说明了 Graph RAG 相比源文本摘要在可扩展性上的优势:对于低层社区摘要(C3),Graph RAG 的上下文标记需求减少了 26-33%;对于根级社区摘要(C0),减少了 97%以上的标记需求。虽然相比其他全局方法性能略有下降,但根级 Graph RAG 仍是一种高效的方法,适用于特征化认知活动的迭代性问答,同时在全面性(胜率 72%)和多样性(胜率 62%)上优于简单 RAG。
启发性
启发性对比的结果在全局方法与简单 RAG(SS)以及 Graph RAG 与源文本摘要(TS)之间表现参差不齐。对 LLM 推理的临时分析表明,提供具体示例、引用和引文的能力被认为是帮助用户形成明智理解的关键因素。调整元素提取提示可能有助于在 Graph RAG 索引中保留更多此类细节。
表 3

这张表(Table 3)展示了两种数据集(播客转录文本和新闻文章)在不同方法和层次的社区摘要下的上下文单元数量(Units)、对应的标记数量(Tokens)以及标记数量相对于最大值的百分比(% Max)。
核心内容解释
列的定义
- Units:上下文单元的数量,对于社区摘要方法(C0-C3),单位是社区摘要的数量;对于 TS(文本片段摘要方法),单位是文本片段的数量。
- Tokens:每种方法和层次中处理所需的总标记数。
- % Max:标记数量占最大标记数(TS 方法的标记数)的百分比。
数据分析
播客转录文本(Podcast Transcripts)
- C0(根级社区摘要):仅有 34 个社区单元,总标记数为 26657,仅占 TS 方法标记总数的 2.6%。
- C1(高层社区摘要):367 个社区单元,标记数为 225756,占 TS 方法的 22.2%。
- C2(中间层社区摘要):969 个社区单元,标记数为 565720,占 TS 方法的 55.8%。
- C3(低层社区摘要):1310 个社区单元,标记数为 746100,占 TS 方法的 73.5%。
- TS(文本片段摘要):1669 个文本片段,标记数为 1014611,为参考最大值(100%)。
新闻文章(News Articles)
- C0(根级社区摘要):55 个社区单元,总标记数为 39770,仅占 TS 方法标记总数的 2.3%。
- C1(高层社区摘要):555 个社区单元,标记数为 352641,占 TS 方法的 20.7%。
- C2(中间层社区摘要):1797 个社区单元,标记数为 980898,占 TS 方法的 57.4%。
- C3(低层社区摘要):2142 个社区单元,标记数为 1140266,占 TS 方法的 66.8%。
- TS(文本片段摘要):3197 个文本片段,标记数为 1707694,为参考最大值(100%)。
方法比较
- 效率比较:
- 根级社区摘要(C0)的标记需求远低于其他方法,仅占 TS 方法的 2.3%-2.6%,极大地减少了上下文标记的使用。
- 随着社区层次下降(从 C1 到 C3),社区摘要的标记需求逐渐增加,但仍显著低于直接处理文本片段的 TS 方法。
- 扩展性:
- Graph RAG 在低层社区摘要(C3)情况下,与 TS 方法相比,标记需求减少了 26%-33%。
- 在根级社区摘要(C0)情况下,标记需求减少了 97%以上。
- 性能权衡:
- 根级社区摘要(C0)虽然标记需求最低,但可能损失部分细节信息。
- 中间层(C2)和低层(C3)社区摘要能够在标记效率与全面性、多样性之间取得较好的平衡。
总结
这张表清晰展示了 Graph RAG 方法在减少标记需求方面的显著优势,尤其是在根级社区摘要中,标记使用量仅为 TS 方法的 1/43 到 1/9。然而,随着社区层次的细化(从 C0 到 C3),标记需求增加,但仍比直接处理源文本的 TS 方法更加高效,同时保持全面性和多样性的良好表现。
图 4
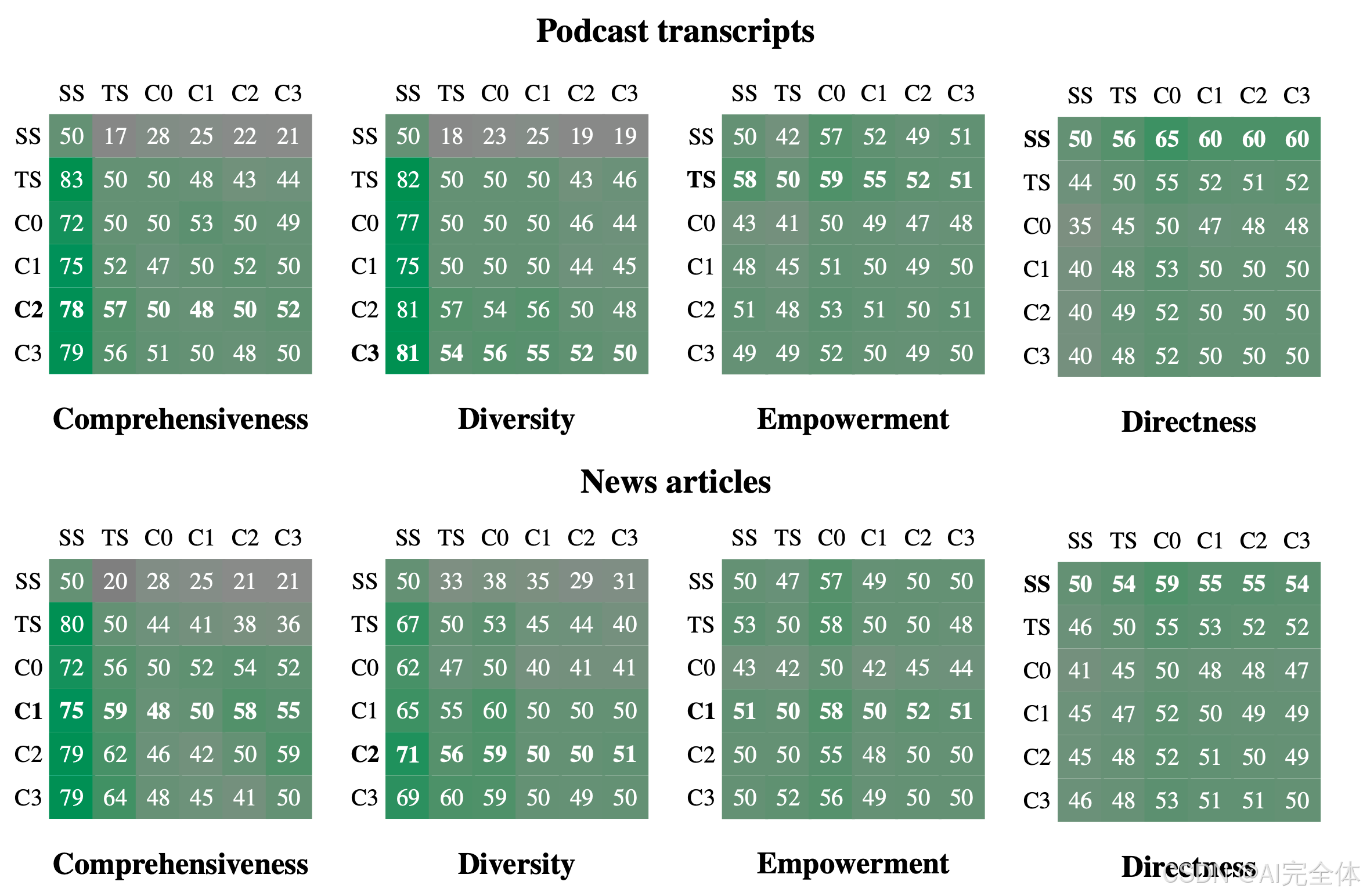
图 4:在两种数据集、四个指标下进行的逐对比较中,(行条件)相对于(列条件)的胜率百分比,每个指标基于 125 个问题,每次比较重复五次并取平均值。每个数据集和指标的整体赢家以加粗显示。自比较的胜率未计算,但显示为预期的 50% 以供参考。所有 Graph RAG 条件在全面性和多样性上均优于简单 RAG。条件 C1-C3 在答案的全面性和多样性上也略微优于 TS 方法(不使用图索引的全局文本摘要)。
4 相关工作
4.1 RAG 方法与系统
在使用大语言模型(LLMs)时,检索增强生成(retrieval-augmented generation, RAG)的流程包括:首先从外部数据源检索相关信息,然后将这些信息与原始查询一起添加到 LLM 的上下文窗口中(Ram 等人,2023)。简单的 RAG 方法(Gao 等人,2023)通过将文档转为文本、将文本分块,并将这些分块嵌入到一个向量空间中实现,其中相似的位置代表相似的语义。查询也被嵌入到相同的向量空间,使用距离最近的 k 个向量的文本分块作为上下文。尽管存在更高级的变体,但所有方法都旨在解决外部数据集超出 LLM 上下文窗口时该如何处理的问题。
高级 RAG 系统包括预检索、检索和后检索策略,以克服简单 RAG 的局限性。而模块化 RAG 系统则包含交替检索与生成的迭代和动态循环模式(Gao 等人,2023)。我们实现的 Graph RAG 综合了其他系统的多个概念。 例如,我们的社区摘要是一种生成增强检索(generation-augmented retrieval, GAR)的自记忆(self-memory, Cheng 等人,2024),有助于未来的生成循环,而从这些摘要并行生成社区答案则是一种迭代式(Iter-RetGen, Shao 等人,2023)或联合式(FeB4RAG, Wang 等人,2024)检索生成策略。其他系统也曾结合这些概念进行多文档摘要(CAiRE-COVID, Su 等人,2020)和多跳问答(ITRG, Feng 等人,2023;IR-CoT, Trivedi 等人,2022;DSP, Khattab 等人,2022)。我们的分层索引和摘要使用方法与一些进一步的研究方法相似,例如通过聚类文本嵌入向量生成分层索引(RAPTOR, Sarthi 等人,2024)或生成“澄清树”以回答含糊问题的多种解释(Kim 等人,2023)。然而,这些迭代或分层方法均未使用类似于 Graph RAG 的自生成图索引。
4.1 补充解释
例如,我们的社区摘要是一种生成增强检索(generation-augmented retrieval, GAR)的自记忆(self-memory, Cheng 等人,2024),有助于未来的生成循环,而从这些摘要并行生成社区答案则是一种迭代式(Iter-RetGen, Shao 等人,2023)或联合式(FeB4RAG, Wang 等人,2024)检索生成策略。
这句话描述了 Graph RAG 方法中“社区摘要”和“社区答案”的生成过程,并解释了它们与已有研究的联系。
核心概念解释
-
社区摘要作为“自记忆”(self-memory):
- 什么是“自记忆”?
自记忆是一种技术,指系统通过对历史生成的内容进行总结和存储,使其在未来的生成过程中作为背景信息重复使用。 - 为什么社区摘要是一种自记忆?
在 Graph RAG 中,社区摘要包含了从图索引中提取的实体和关系的高层次总结。这些摘要在未来的生成循环中用作背景信息,使模型能够基于社区摘要生成更具体或全局的回答。- 例如:当用户再次提出问题时,系统无需重新遍历原始数据,而是利用已经生成的社区摘要快速生成答案。
- 什么是“自记忆”?
-
并行生成社区答案作为迭代式或联合式检索生成策略:
- 迭代式(Iterative)检索生成策略:
迭代式检索生成策略指通过逐步细化检索和生成的过程来改进答案的质量。Graph RAG 的方法是基于每个社区摘要,独立生成与其相关的社区答案,再通过进一步的合并和总结,生成全局答案。 - 联合式(Federated)检索生成策略:
联合式策略强调并行化和分布式计算。Graph RAG 方法对多个社区摘要进行并行处理,每个摘要独立生成答案。这种分布式生成方式提高了效率,特别适合处理大规模数据集。
- 迭代式(Iterative)检索生成策略:
示例说明
假设有一个数据集被划分为若干个社区:
- 社区摘要的作用:社区摘要可以看作这些社区的“记忆点”,它们记录了每个社区的重要信息(如实体、关系等),避免每次查询都重新处理整个数据集。
- 并行生成社区答案:
- 针对每个社区摘要,Graph RAG 并行生成对应的社区答案。例如,社区 A 提供的答案可能关注科技领域,社区 B 提供的答案可能关注健康领域。
- 最终,通过合并这些社区答案生成一个全局回答。
总结
- 社区摘要的意义:它是一种自记忆技术,存储了数据的高层次信息,支持未来的生成循环,减少重复计算。
- 社区答案生成的意义:通过并行化和迭代式的方法,Graph RAG 高效地处理了大规模数据,提供更全面、更多样化的答案。这种方法结合了迭代式和联合式检索生成策略的优势。
4.2 图与 LLMs
将图与 LLMs 和 RAG 结合的研究是一个正在发展的领域,目前已有多种方向。例如,LLMs 被用于知识图谱的创建(Trajanoska 等人,2023)和补全(Yao 等人,2023),以及从源文本中提取因果图(Ban 等人,2023;Zhang 等人,2024)。此外,一些高级 RAG 方法将索引设计为知识图谱(KAPING, Baek 等人,2023),或者检索图结构的子集(G-Retriever, He 等人,2024)或派生的图度量(GraphToolFormer, Zhang, 2023)。某些系统生成强依赖于检索子图事实的叙述输出(SURGE, Kang 等人,2023),或通过叙述模板序列化检索到的事件图子图(FABULA, Ranade 和 Joshi, 2023)。还有系统支持创建和遍历文本关系图,用于多跳问答(Wang 等人,2023b)。
在开源软件方面,包括 LangChain(LangChain, 2024)和 LlamaIndex(LlamaIndex, 2024)在内的库均支持多种图数据库。此外,也有一类更通用的基于图的 RAG 应用正在出现,包括能够在 Neo4J(NaLLM, Neo4J, 2024)和 NebulaGraph(GraphRAG, NebulaGraph, 2024)格式中创建和推理知识图谱的系统。然而,与我们的 Graph RAG 方法不同,这些系统未利用图的自然模块化特性来划分数据以实现全局摘要。
5 讨论
评估方法的局限性
目前的评估仅针对两个大约 100 万标记的数据集中的特定类型的认知问题。未来需要进一步研究不同问题类型、数据类型和数据集规模对性能的影响,并通过终端用户验证我们的认知问题和目标指标。此外,对虚构率的比较(例如使用 SelfCheckGPT 等方法,Manakul 等人,2023)也可以改进当前的分析。
构建图索引的权衡
我们观察到 Graph RAG 在与其他方法的逐对比较中始终表现最佳,但在许多情况下,对源文本进行全局摘要的无图方法也表现出了较强的竞争力。是否选择构建图索引在实际中取决于多个因素,例如计算预算、每个数据集的预期查询总数,以及从图索引的其他功能中获得的价值(包括通用社区摘要和其他基于图的 RAG 方法的使用)。
未来工作
支持当前 Graph RAG 方法的图索引、丰富的文本注释和层次化的社区结构为进一步改进和适配提供了许多可能性。这包括通过基于嵌入的用户查询与图注释匹配来更局部化操作的 RAG 方法,以及结合嵌入匹配与社区报告的混合 RAG 策略,在此基础上再使用 map-reduce 摘要机制。这种“汇总”操作还可以扩展到社区层次结构的更多层级,也可以作为一种更具探索性的“深入”机制,沿着高层社区摘要中的信息线索进一步挖掘。
6 结论
我们提出了一种全局性的 Graph RAG 方法,结合了知识图生成、检索增强生成(RAG)和面向查询的摘要(QFS),支持对整个文本语料库的认知分析。初步评估显示,在答案的全面性和多样性上,相较于简单的 RAG 基线方法有显著改进,并且在与使用 map-reduce 方法对源文本进行全局摘要的无图方法的比较中也表现良好。在需要对同一数据集进行多次全局查询的情况下,基于实体的图索引中的根级社区摘要提供了一种数据索引方式,既优于简单 RAG,又能以更低的标记成本达到与其他全局方法相当的性能。
基于 Python 的开源实现(包括全局和局部 Graph RAG 方法)即将发布,详情请见 https://aka.ms/graphrag。