LLMs 系列实操科普(2)
三、与 LLMs 的基础交互案例
那么现在,让我们来探讨这种特性带来的影响,如何与之交流,以及我们能从中期待什么。接下来,我将通过实际案例来具体说明。

我桌子上恰好有瓶花露水,然后我就可以问它,花露水为什么能驱蚊,是什么成分在起作用,这是一个在互联网上应该很常见的问题,且答案也不会因时间问题产生较大的变化,因此我预期模型在其知识库中对此有良好的记忆,它可以直接给我一些答案,


我可以继续追问它一些问题,比如产品包装上标注的驱蚊酯含量与驱蚊有效时长等,它给我的结论是不可信,哈哈哈,其实我并不知道 LLMs 给我的结果是否准确,感兴趣的话我们可以网络搜索验证一下。
像这些问题,都是模型基于自身知识的查询,因为我们已经明令禁止它进行联网搜索,关于这一点,我们需要 澄清一些注意事项:
第一件事是,你会注意到,我在上面的演示中,特意强调了禁止联网,实际上目前 chatgpt 幕后会根据我们的问题,自动判断是否需要使用一些工具,包括“联网搜索”工具,这一点我们上一期系列文章中已经提到,所以此处我们通过文字指令,禁止它联网。

而在“工具”菜单栏下有“搜索网页”的选项,这有什么区别呢?区别在于,如果我们勾选了搜索网页,那么无论我们提出什么问题,它都会首先进行联网搜索,然后基于检索到的内容进行汇总整体并最终整理出答案;而如果我们不勾选该选项,chatgpt 会根据我们的问题难度自行判断,是否需要使用“搜索网页”这个工具,如果问题简单,它认为可以直接作答,则不使用工具,如果认为自己无把握回答的更好,则会呼叫工具辅助。
[!tip]
具体使用上的建议:
- 如果你明知道 LLMs 大概率不清楚这件事,那么主动勾选“搜索网页”,强制性要求它联网搜索;
- 如果你的问题过于简单或大众化,就不要勾选,没必要为简单的问题浪费时间
第二件事是,在你询问一个问题后,如果你觉得这些结果对你的下一个问题不搭边或者没啥用,我建议你重新开启一个新的对话窗口,即清空上下文窗口中的 tokens,有几个原因,一是你上一轮的会话内容会和你的新问题,一起作为输入喂进模型中,如果是付费接口,这会造成 tokens 的浪费;其次这会导致你的输入内容过长,而这些信息可能又无用,会导致模型分心,这可能会造成干扰,实际上可能会降低模型的准确性和性能。再者,窗口中的 tokens 越多,采样序列中的下一个 tokens 的计算成本就会稍微高一些,虽然不会太高,但确实会稍微增加一些,因此你的模型实际上正在略微减速。
关于第二点,如果你的会话确实需要较多的前文会话历史,以便记住很多前文信息,一种好的办法是利用相对便宜的模型对会话历史进行压缩或重要信息提取,例如将所有的会话内容提取为 200 字的摘要或者始终最多只使用过去四轮的会话历史,如果你使用的是一些第三方工具,往往会提供类似的功能。
[!tip]
具体使用上的建议:
- 如果你的问题与上文话题是相关的,可以继续在同一个窗口下继续聊天
- 遇到一个新的话题或问题,新开一个窗口,可能是个更好的选择
第三件是,我建议大家要清楚自己实际使用的是哪个模型,如果你是免费用户(需要登录),则模型使用 chatgpt 实际上是指 gpt-4o,但免费用户使用量会受限,一段时间内如果超限则会切换到 gpt-4.1-mini,你肯定猜的到 gpt-4o-mini 的性能肯定不如 gpt-4o。
[!tip]
具体使用上的建议:
- 对于免费用户无建议,
- 对于付费用户可见下图
如果你新开一个无痕窗口,不进行任何登录使用,网页上并未提供具体使用的模型信息,但应该是类似 gpt-4o-mini 这种轻量化的版本。它是一个参数较少的较小模型,因此在创造力方面会稍逊一筹——比如写作质量可能没那么好,知识储备也不那么全面,还可能会更容易出现幻觉现象等等。
而如果你购买了每个月 20 或 200 美元的付费服务,则在左上角会看到更多的推理模型选择,
通常规模更大的模型计算成本更高,因此对更大模型的收费也更贵。所以根据你对大语言模型的使用情况,自己权衡这些利弊。看看你是否能用更便宜的产品应付过去,如果智能程度对你来说不够用,而且你是专业使用的话,你可能真的需要考虑购买这些公司提供的顶级模型版本。所以,要留意你正在使用的模型,并为自己做出这些决定。
对于高级付费用户,这里是你目前大概能看到的一些模型列表,实际上 gpt-4o 已经能应付大部分事情,一些难的事情可以选择 o3 模型。

(图片来源: https://x.com/karpathy/status/1929597620969951434)
其他所有 LLMs 供应商都会有不同的模型版本与不同的定价标准,这里我推荐的一款软件叫 ChatWise,它几乎支持目前市面上所有顶流的一些供应商模型,当然需要你自行购买这些供应商的 API,在这里我主要配置了 anthropic 的 claude 系列模型,deepseek 模型,google 的 gemini 系列以及 openai 的 gpt 系列,
你可以使用 HTML 标签在 Markdown 中并排排列三张图片。以下是一个示例:
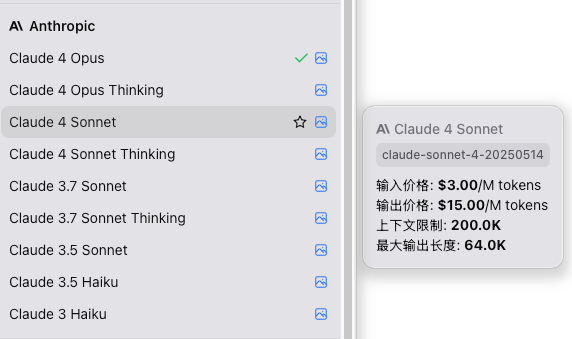
这里可供选择的模型种类都非常多,并且鼠标悬停后会显示当前模型的价格信息以及上下文限制,例如此处的 claude 4.0 sonnet,每百万 tokens 输入是 3 美元,输出是 15美元,这比 gpt-4o 要贵,上下文窗口是 200K,即 20 万个 tokens 容量,而单次最大输出长度是 6 万多 tokens,这是一个在编码方面非常不错的模型,我经常会使用它辅助我编写一些代码。
[!tip]
使用建议:如果你不知道如何选择使用哪一个模型,可以尝试使用数字版本最大的,这通常是目前释放出来的最新、性能相对最强的一些模型,当然你也可以结合具体的价格做出选择。另外关于模型命名上,你可以看得到,现在的各厂商释放的模型在命名方面简直乱七八糟,如 gpt 中可能存在 mini(轻量)、nano(超小)、preview(预览版)、turbo(优化版)、pro(专业版) 等后缀,基本上轻量、小代表便宜、性能差,预览版是一些较新模型的测试版,可能不稳定,pro 性能强但贵。而 claude 中使用 haiku、sonnet、opus 分别代表轻量、中量、重量;其他如 thinking 是带思考的推理,flash(闪电)快,价格相对低。