什么时候用GraphRAG?RAG VS GraphRAG综合分析
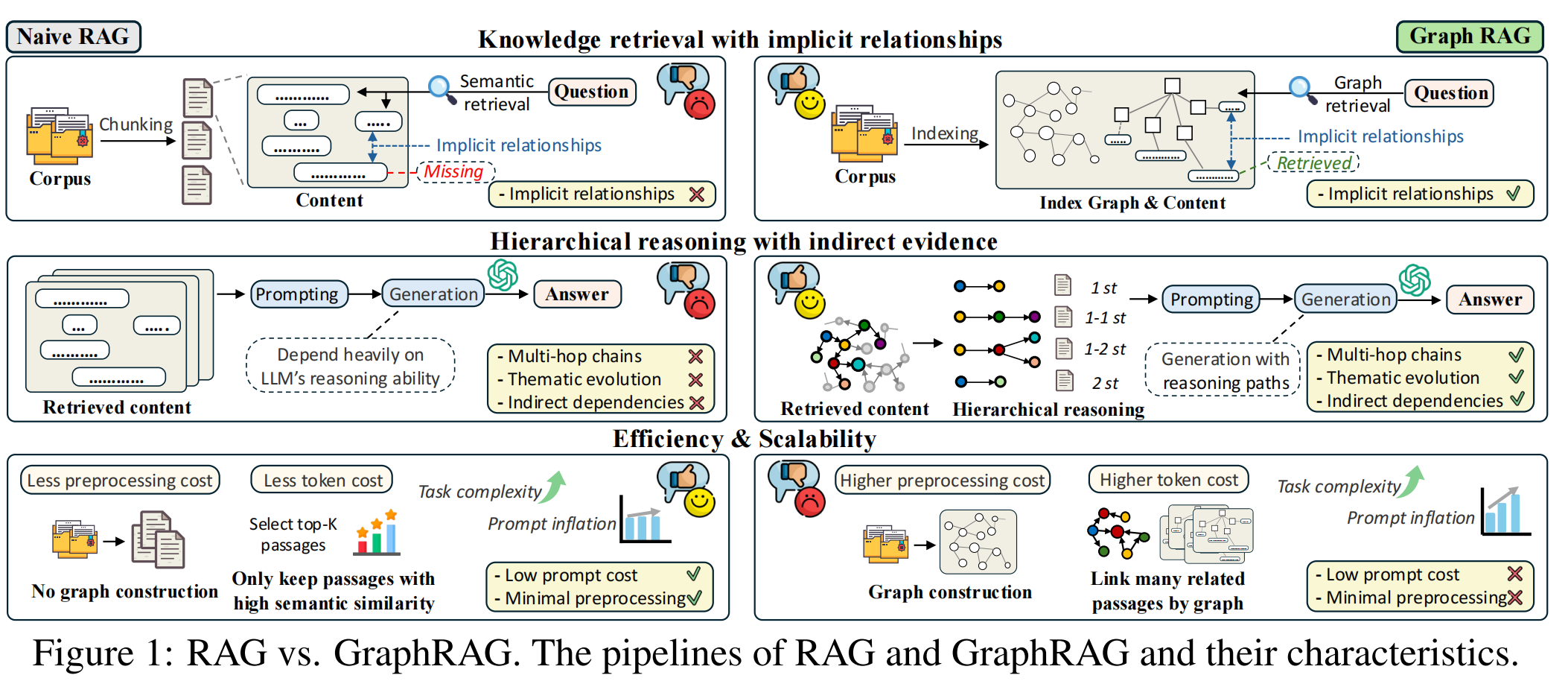
最近的研究报告称,在许多实际任务中,GraphRAG的表现往往不如普通的RAG。因此产生一个问题:GraphRAG真的有效吗?在哪些场景下,GraphRAG有收益?为了解决这个问题,提出GraphRAG-Bench,这是一个评测GraphRAG的基准,目的是评估GraphRAG模型在层次知识检索和深度上下文推理方面的性能。文章指出的评测方式及评测结论可以参考。
GraphRAG-Bench具有一个全面的数据集,任务难度逐渐增加,涵盖事实检索、复杂推理、上下文总结和创造性生成,并对整个流程进行系统评估,从图构建和知识检索到最终生成。
RAG VS GraphRAG
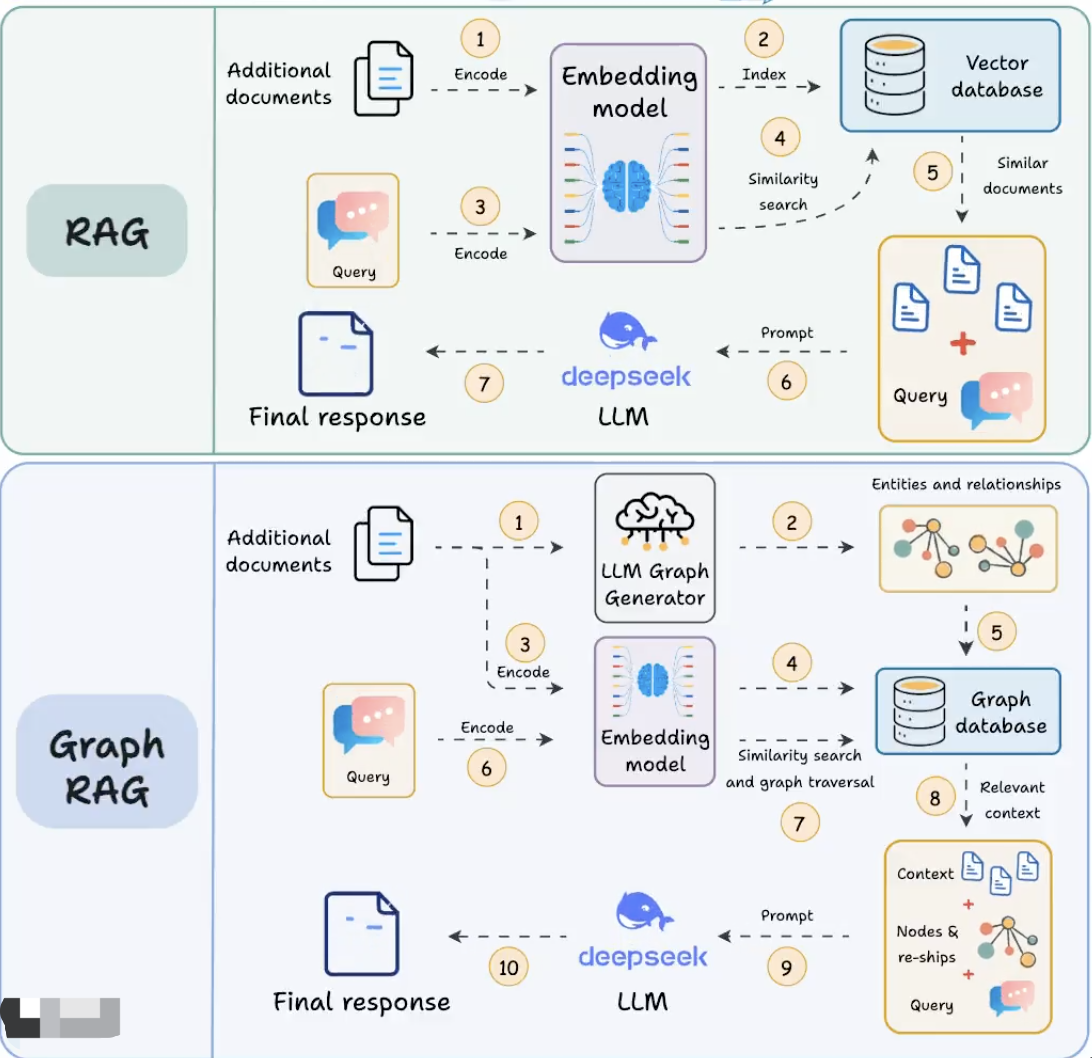
下面这张图可能更清晰的看出RAG和GraphRAG的区别。
| 特性 | RAG | GraphRAG |
|---|---|---|
| 知识表示 | 使用文本块(chunks),通过向量嵌入进行索引。 | 使用图结构,节点代表实体、事件或主题,边定义逻辑、因果或关联关系。 |
| 检索机制 | 关键词匹配或向量相似度检索。 | 图遍历,检索直接相关节点及相互连接的子图。 |
| 复杂查询处理 | 适用于需要快速访问离散信息的任务,但不擅长复杂逻辑推理。 | 适用于需要深度上下文分析和复杂推理的任务,能够合成来自分散数据点的见解。 |
| 适用场景 | 简单问答系统,需要快速响应的任务。 | 医学诊断、法律分析、科学推理等需要深度理解和复杂推理的任务。 |
| 复杂性 | 实现相对简单,依赖现有文本检索技术。 | 实现较为复杂,需要构建和维护图结构,以及高效的图遍历算法。 |
| 性能 | 在不需要复杂推理的任务上表现良好。 | 在需要复杂推理和上下文理解的任务上表现出色,但可能增加检索速度和资源消耗。 |
评测
现有评测都比较简单,因此提出一个比较全面的评测基准-GraphRAG-Bench,包括难度逐渐增加的任务,涵盖事实检索、多跳推理、上下文总结和创造性生成等。
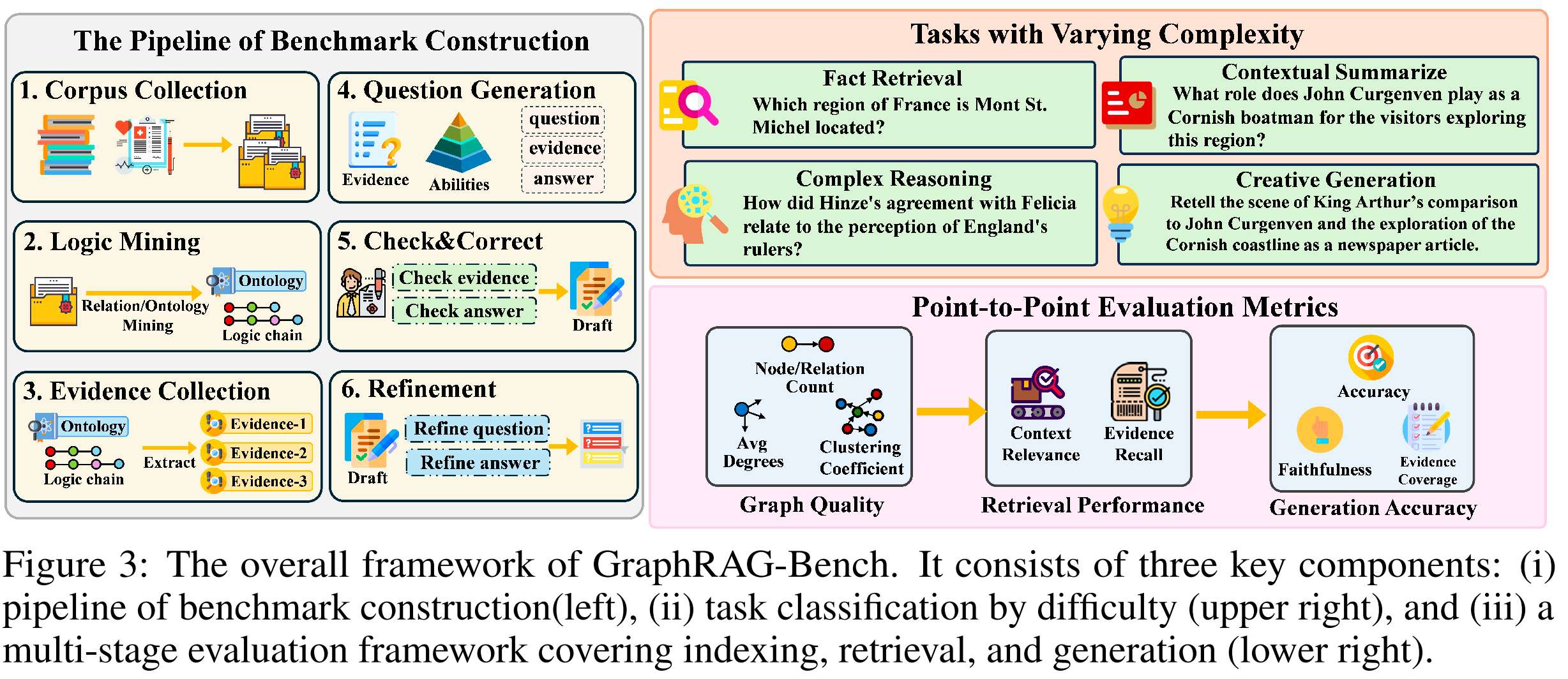
按复杂性分类的任务,从事实检索到创造性生成。
| 类别 | 任务名称 | 简要描述 | 示例 |
|---|---|---|---|
| 第1级 | 事实检索 | 需要检索孤立的知识点,最小化推理;主要测试精确的关键词匹配。 | 蒙特圣米歇尔位于法国的哪个地区? |
| 第2级 | 复杂推理 | 需要通过文档中的逻辑连接链接多个知识点。 | Hinze与Felicia的协议如何影响对英格兰统治者的看法? |
| 第3级 | 上下文摘要 | 涉及将碎片化信息综合成一个连贯、有结构的答案;强调逻辑连贯性和上下文。 | John Curgenven作为康沃尔船夫在探索该地区的游客中扮演什么角色? |
| 第4级 | 创造性生成 | 需要超越检索内容的推理,通常涉及假设或新颖的场景。 | 将亚瑟王与John Curgenven的比较以及康沃尔海岸线的探索重述为新闻文章。 |
评估指标
在评估GraphRAG系统时,引入了多种指标来全面评估系统在知识图谱构建、检索和生成过程中的表现:
1. Graph Quality (图质量)
-
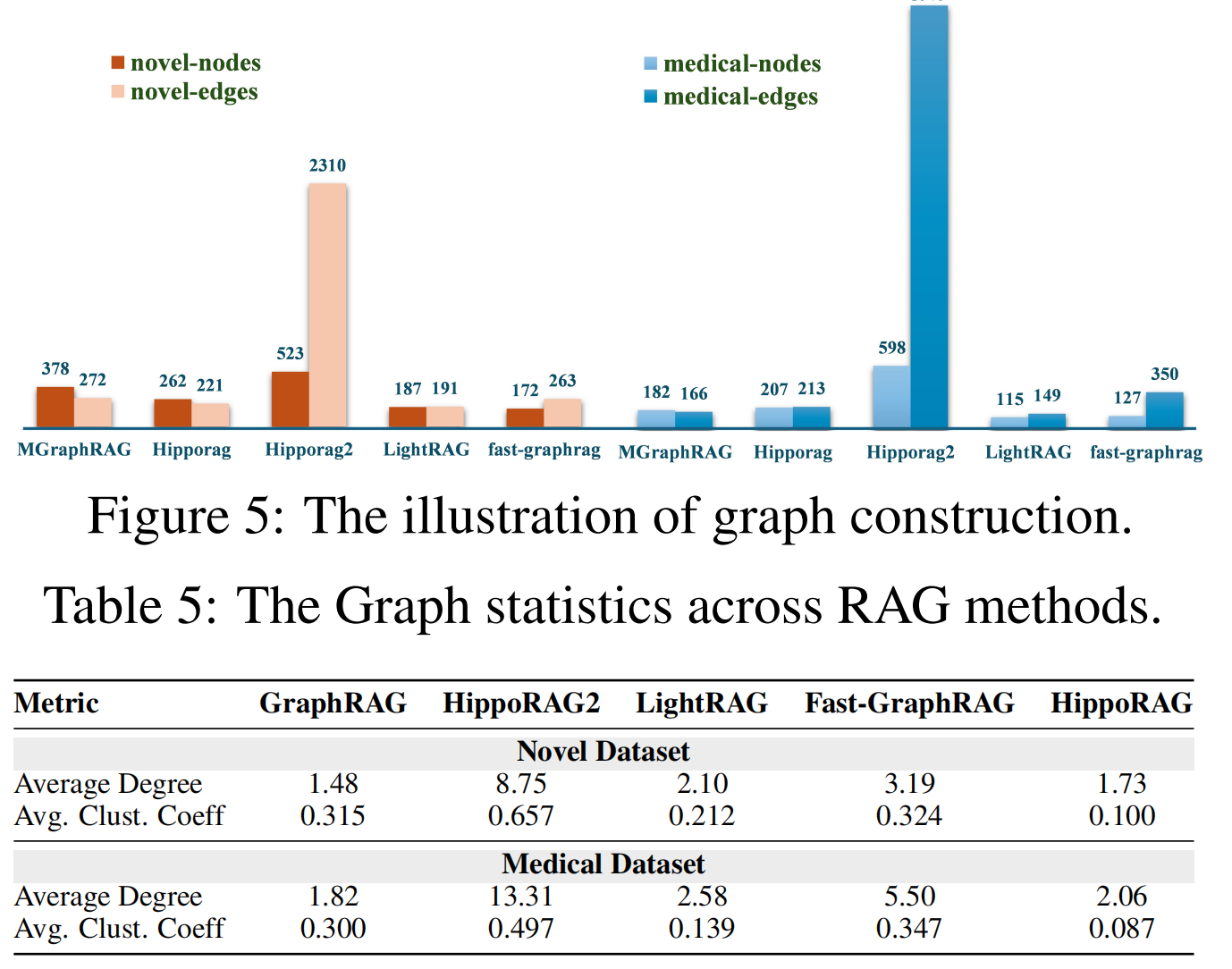
NODE COUNT(节点数量):衡量在知识图谱构建过程中提取的实体数量。较高的节点数量意味着更广泛的领域覆盖和更细粒度的知识表示。
-
Edge Count(边数量):衡量实体之间的关系数量。较高的边数量表明更密集的语义连接,有助于多跳推理和复杂查询处理。
-
Average Degree(平均度):通过计算每个节点的平均边数来衡量全局连接性。较高的平均度表示更集成的知识表示,支持高效的跨节点遍历。
Average Degree = 1 ∣ V ∣ ∑ v ∈ V deg ( v ) \text{Average Degree} = \frac{1}{|\mathcal{V}|} \sum_{v \in \mathcal{V}} \operatorname{deg}(v) Average Degree=∣V∣1v∈V∑deg(v)
其中, V \mathcal{V} V 是节点集合, deg ( v ) \operatorname{deg}(v) deg(v) 是节点 v v v 的度。
-
Average Clustering Coefficient(平均聚类系数):通过三元组完成来评估局部邻域连接性。较高的值表明存在连贯的子图,支持局部推理。
Average Clustering Coefficient = 1 ∣ V ∣ ∑ v ∈ V C ( v ) , C ( v ) = 2 ⋅ T ( v ) deg ( v ) ⋅ ( deg ( v ) − 1 ) \text{Average Clustering Coefficient} = \frac{1}{|\mathcal{V}|} \sum_{v \in \mathcal{V}} C(v), \quad C(v) = \frac{2 \cdot T(v)}{\operatorname{deg}(v) \cdot (\operatorname{deg}(v) - 1)} Average Clustering Coefficient=∣V∣1v∈V∑C(v),C(v)=deg(v)⋅(deg(v)−1)2⋅T(v)
其中, C ( v ) C(v) C(v) 是节点 v v v 的聚类系数, T ( v ) T(v) T(v) 表示其中心三角形数。
2. Retrieval Performance (检索性能)
-
Context Relevance(上下文相关性):衡量检索内容与问题意图的对齐程度。通过计算问题和检索证据之间的语义相似性来量化,较高的值表示更集中和相关的信息。
-
Evidence Recall(证据召回率):通过评估是否捕获了正确回答问题所需的所有关键组件来衡量检索的完整性。较高的值表示更全面的证据收集。
3. Generation Accuracy (生成准确性)
-
Lexical Overlap(词汇重叠):使用最长公共子序列匹配来衡量生成答案与参考答案之间的词级相似性。
-
Answer Accuracy(答案准确性):评估生成答案与参考答案的语义相似性和事实一致性。
-
Faithfulness(忠实度):评估长篇答案中的相关知识点是否忠实于给定的上下文。
-
Evidence Coverage(证据覆盖率):衡量答案是否充分涵盖了与问题相关的所有知识。
实验性能
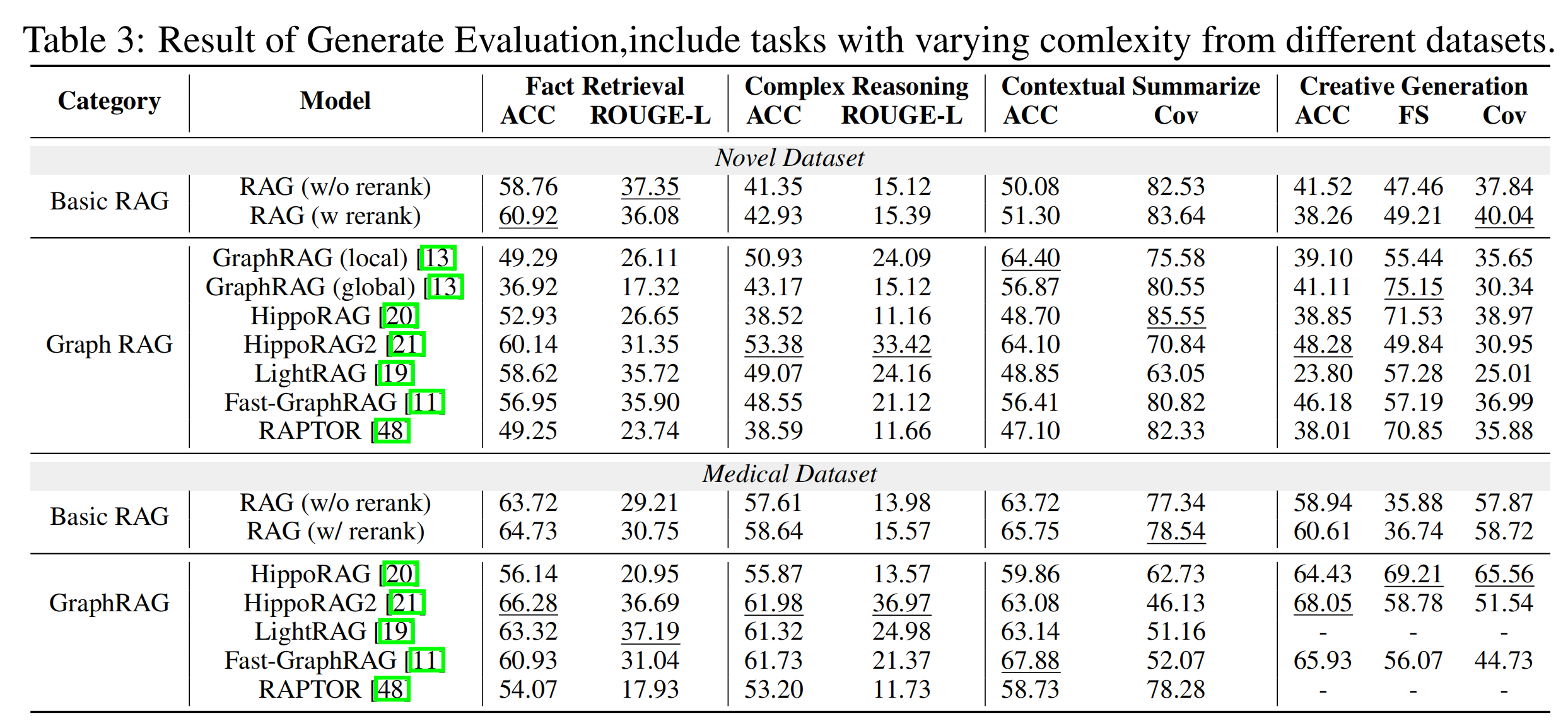
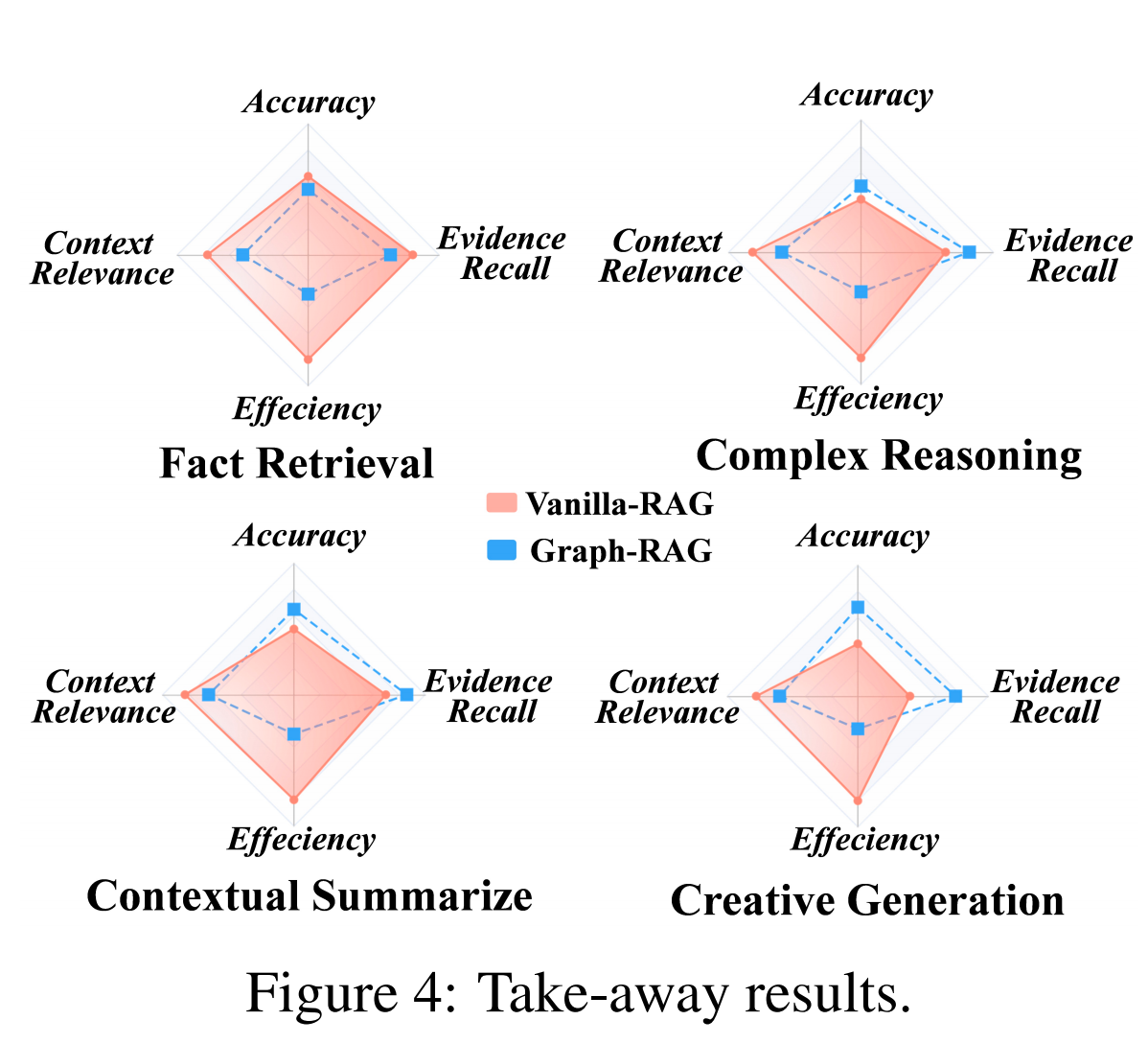
GraphRAG在需要多跳推理和上下文综合的任务中表现优异,但在简单事实检索任务中不如传统RAG。
- 生成准确性: 基本RAG在简单事实检索任务中表现优于GraphRAG,但在复杂推理、上下文摘要和创造性生成任务中,GraphRAG表现出明显优势。
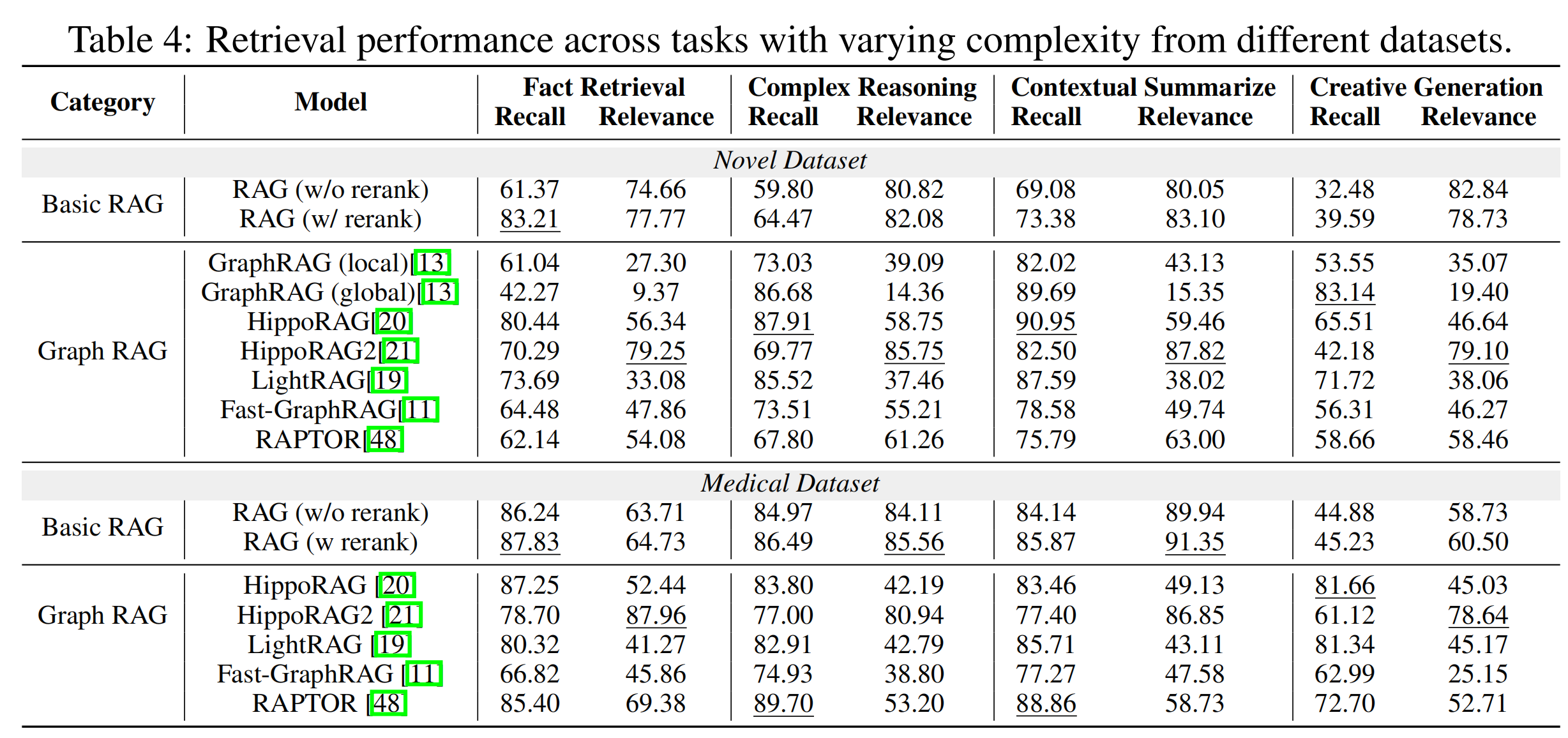
- 检索性能: GraphRAG在复杂任务中表现出色,特别是在需要多跳推理和上下文综合的任务中,能够连接远距离文本片段,提供更全面的信息。
- 图复杂性: 不同GraphRAG实现生成的索引图显示出显著的结构差异,HippoRAG2生成的图更为密集,提高了信息连接性和覆盖范围。
- 效率: GraphRAG由于额外的知识检索和图聚合步骤,增加了提示长度,导致效率降低,尤其是在复杂任务中。
参考文献:When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation,https://arxiv.org/pdf/2506.05690v1