第二章 感知机
2.1 感知机模型
感知机是二分类的线性分类模型。
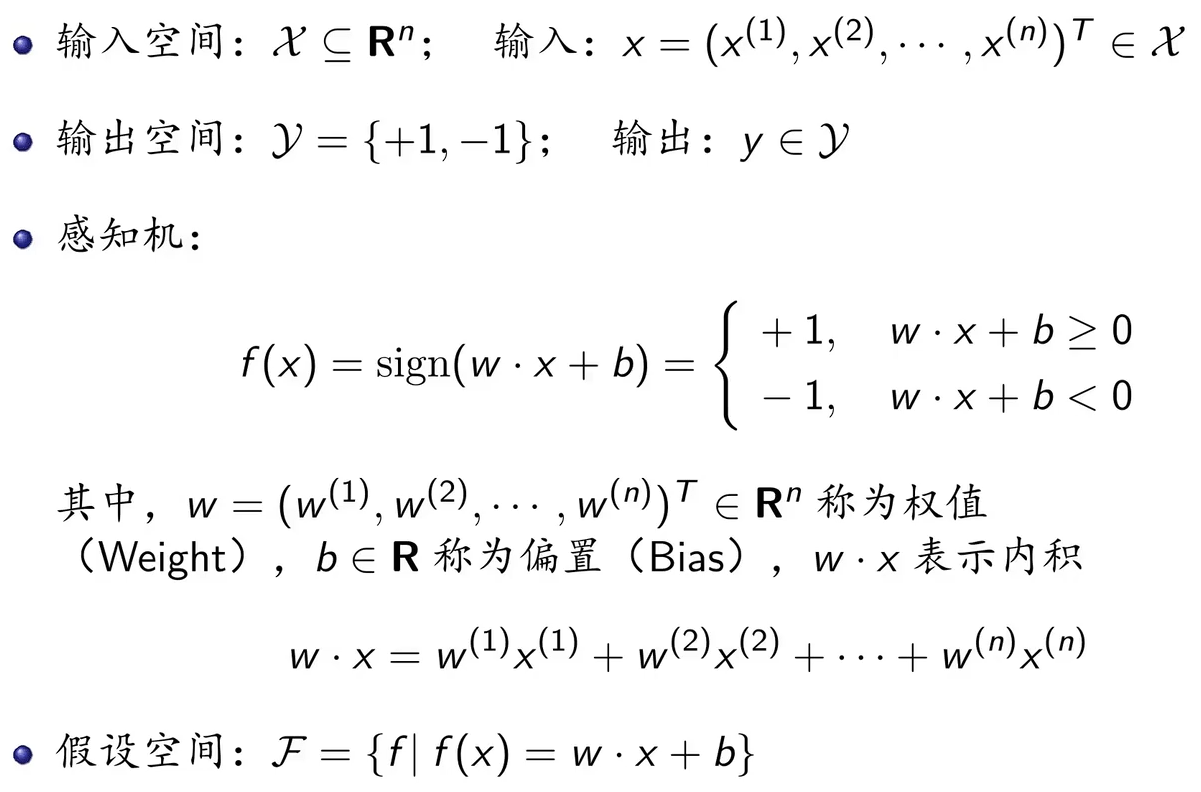
感知机有如下的几何解释:线性方程,对应于特征空间
中的一个超平面S,其中w是超平面的法向量,b是超平面的截距。通过这个超平面就可以将整个特征空间分成两部分,一部分是正类,实例所对应的y值为+1;一部分为负类,实例所对应的y值为-1。因此超平面S称为分离超平面。
在几何中,如果环境空间是n维的,那么它所对应的超平面就是n-1维的子空间。换句话说,超平面就是比它所处的环境空间小一维的子空间。如果特征空间是一维的,那么一个实例其实就是一个实数,用来区分正负类的就是实数轴上的一个点;如果特征空间是二维的,其中的实例就是二维空间中的一个点,它的分离超平面是一条直线;特征空间是三维的,分离超平面就是一个平面。
现在我们看一个例子了,其中特征向量是二维的,圆点是正类,叉点代表负类,分离超平面就是,
表示原点到超平面的距离:
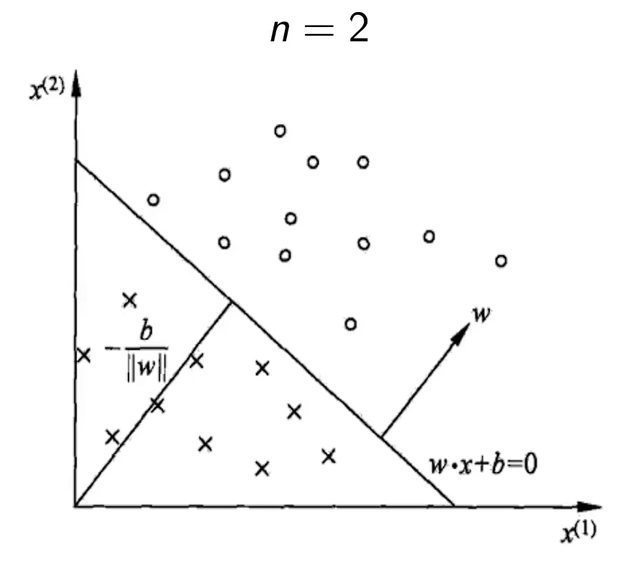
通过前面对感知机模型的介绍,我们可以得到它的流程图:
2.2 感知机学习策略
2.2.1 数据集的线性可分性
对于感知机模型,它有一个比较严苛的条件:要求数据集必须是线性可分的。
数据集的线性可分性是指:,若存在某个超平面S为wx+b=0,使得将数据集的正负实例点完全正确的划分到超平面两侧,即
,那么,称T为线性可分数据集;否则,称T为线性不可分。
2.2.2 感知机学习策略
假设训练数据集是线性可分的,感知机学习的目标是希望寻找到一个很好的分离超平面,将实例点完全划分为正类、负类。求得这样一个超平面需要确定模型的参数,此时就需要制定一定的学习策略,即定义(经验)损失函数并将损失函数极小化。
首先定义输入空间中的任意一点
到超平面S的距离:
。如果
是正确分类点,则
;如果
是错误分类点,则
误分类点到S的距离是:
,所有误分类点到S的距离是:
,其中m代表误分类点的集合,当m中所含的误分类点越少的时候,总距离应该越小;当没有误分类点的时候,m代表空集,总距离为0.所以,我们希望通过最小化总距离来求得相应的参数w和b。
这里大家可能会好奇,并不是一个固定的值,为什么不会影响最后的结果呐?原因一:
并不会影响正值还是负值的判断;二:它不会影响感知机算法的最终结果。于是我们定义了损失函数
2.3 准备知识:梯队下降法
梯度下降法在机器学习中应用十分广泛,它是求解无约束最优化问题的一种最常用方法。
2.3.1 直观理解
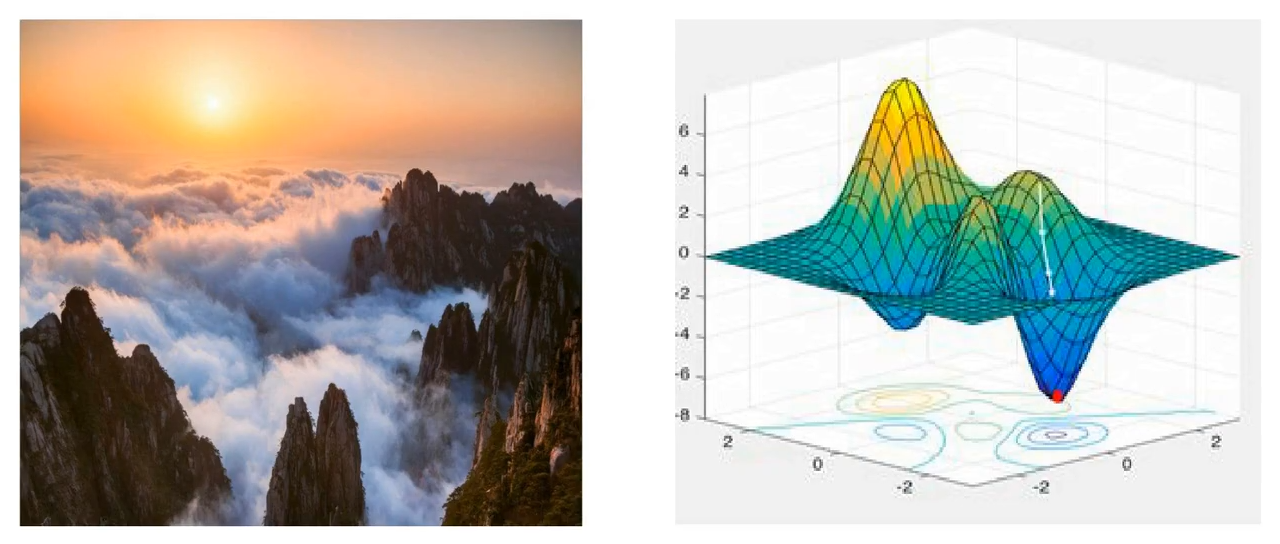
在左图中,是连绵起伏的山脉,而且云雾缭绕,这时候如果我们位于山顶的话,不知道地貌如何,而且也不知道山底在什么方向,这时候该如何下山,怎么下山最快呐?最简单的方法就是走一步看一步。我们每走一步就涉及到方向和步长的问题,我们可以每到一处感受一下当前的所处位置的往下最陡的方向,然后迈一小步,接着在新的位置感受最陡的方向,再往前迈一小步,就这样一小步一小步,我们就能到山脚下了,这就是梯度下降法的直观理解。
现在我们假设有一个可微函数,我们想找到这个可微函数的最小值,也就是相当于想找一下山的山底。根据下山过程的情景假设,我们最快的下山过程就是每次都要找当前位置最陡峭的方向,沿着这个方向往下走。那么对于函数来说,我们每次都要找到该定点相应的梯度,然后沿着梯度下降的方向往下走,这样就是使函数值下降最快的方向了。
2.3.2 概念
梯度是指某一函数在该点处最大的方向导数,沿着该方向可取得最大的变化率。
如果是凸函数,可通过梯度下降法进行优化:
梯度下降法的算法:

2.4 感知机----学习算法之原始形式
2.4.1 学习问题
给定一个训练数据集,其中
,
;损失函数
,其中,M代表所有误分类点的集合。
对于感知机问题,我们想求得一个分离超平面,这个分离超平面是由参数w和b构成,那么如何求w和b呐,这是一个最优化问题,也就是寻找使损失函数L最小的参数w和b,即![]() 。
。
2.4.2 原始形式
我们知道损失函数是。它对参数w的梯度是:
;对参数b的梯度是:
。需要注意的是:这些都是对误分类点M进行的。
对于感知机模型,我们选取的是随机梯度下降法:每次随机选择一个误分类点,每一轮的迭代速度快。如果样本点是误分类点,
是误分类点,我们先选择了
进行参数更新,有可能在参数更新后所得到的感知机模型,它对于
就不是误分类点了,这也是我们选择随机梯度下降法的原因。具体来看就是
,
。
梯度下降法的原始形式,我们也称之为批量梯度下降法:每次迭代使用所有误分类点来进行参数更新,每一轮的迭代速度慢。即;
,其中,
代表步长。
还有一种梯度下降法:小批量梯度下降法。它既不像批量梯度下降法选择所有的误分类点,也不像随机梯度下降法随机选择一个误分类点,而是选择部分样本点进行参数更新,但是对于小批量梯度下降法,它所面临的问题是:我们每次选择多少个样本点,选择哪些样本点合适。
现在我们来看一下算法:
输入原始训练集:,其中
,
;输出w,b;感知机模型
,我们假设右图中蓝色的直线对应于选取的初始值所对应的分离超平面,具体步骤如下:
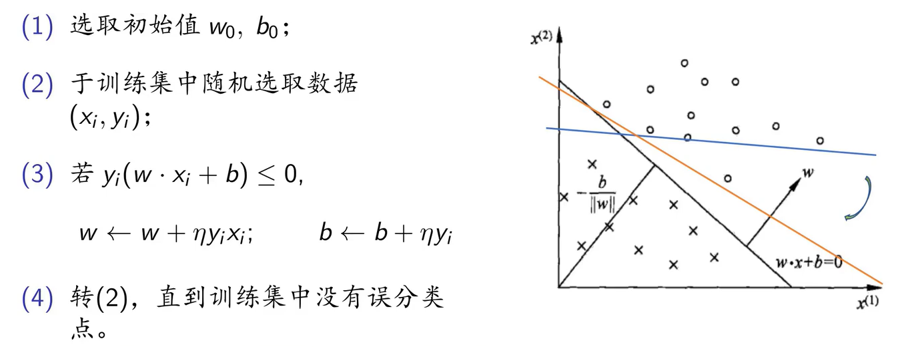
对于感知机模型,参数w对应于分离超平面的旋转程度,而b对应于位移量,所以不停地迭代就可以使得分离超平面越来越接近于能够正确将所有样本点分类的那个超平面,这有可能是橙色的直线,也有可能是黑色的直线,这就说明我们最后得到的分离超平面是不唯一的。
2.4.3 例题分析
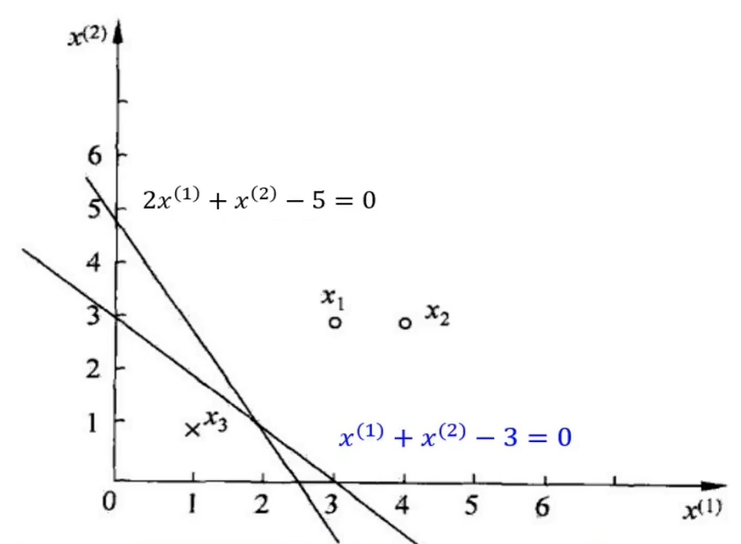
假设训练集,其中
,
,
,假设
。输出:w,b;感知机模型
此时学习问题就是通过使得损失函数达到最小,来求得相应的参数w,b,即: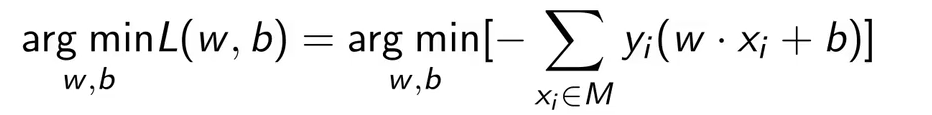 。
。
如果选择初始值,
,对于点
,有
,根据之前的步骤可知,
是误分类点,我们用
来进行参数的更新,更新后的参数
,
。知道了
和
,我们可以得到一个新的模型:
。得到新的模型之后,对于点
有:
;对于点
有:
;对于点
有:
。由以上的计算可知:
,
可以被正确分类,
是是误分类的点,用点
进行参数更新:
,
,此时的模型就更新为:
,重复以上的步骤,直到没有误分类点,

此时得到的参数是:,
,模型为:
。
对于这个例子,分离超平面是:,因此感知机模型是:
。
在之前的误分类点中,误分类点依次取得是,此时得到的超平面是
;若误分类点依次取
,得到的超平面是
2.5 感知机----学习算法之对偶形式
2.5.1 对偶形式
在原始形式中,若为误分类点,可如下更新参数:
,
,假设初始值
,
对误分类点
通过上述公式更新参数,修改
次之后,w,b的增量分别为
和
,其中
,最后学习到的参数是:
,
以上述的原始算法求解的迭代过程为例:
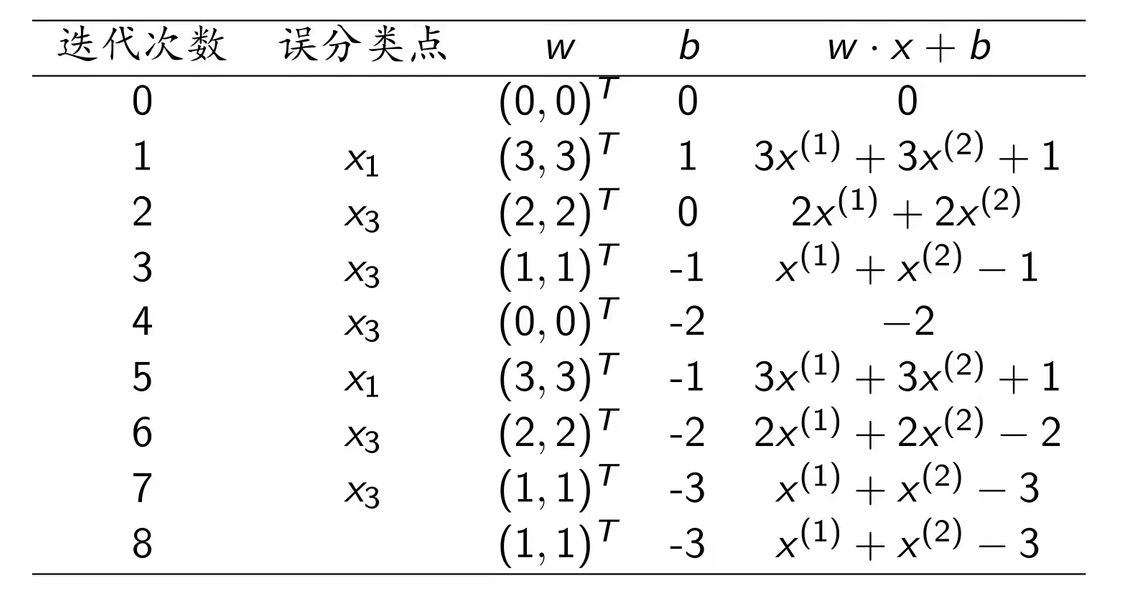
出现2次,所以
;
出现0次,所以
;
出现5次,所以
。我们可以看出
,这也就是实际迭代的次数。
代表了
在迭代中的次数,
代表了
在迭代中的次数。
关于误分类点会带来一个w和b的增量,如果
,那么每一个实例对于参数的增量都可以写出来,我们将其求和,就得到了最后学习到的参数:
,
因为更新次数:,最后 学习到的参数为:
,
,因此最后的模型为:
我们通过最终参数的表达式可以看出:对偶形式的学习算法,它的基本思想就是将参数通过和
的线性组合表达出来,然后求解这个线性组合前的系数,比如
,而
。某个点的迭代次数越多,就说明这个点越难被分类,它对最终的结果就会影响很大。
现在我们看一下对偶形式学习算法的具体步骤:
假如训练数据集,步长
;输出:
;感知机模型
,其中
迭代步骤如下:

这里,我们关注一下算法中的第三步,如果满足就说明
是误分类点,我们需要通过
对参数进行一个更新。将这个迭代条件具体展开来看:
在上述的公式中,有很多的内积运算,为了计算的方便,我们现在将实例两两之间的内积都计算出来,储存在一个Gram矩阵里,记作G
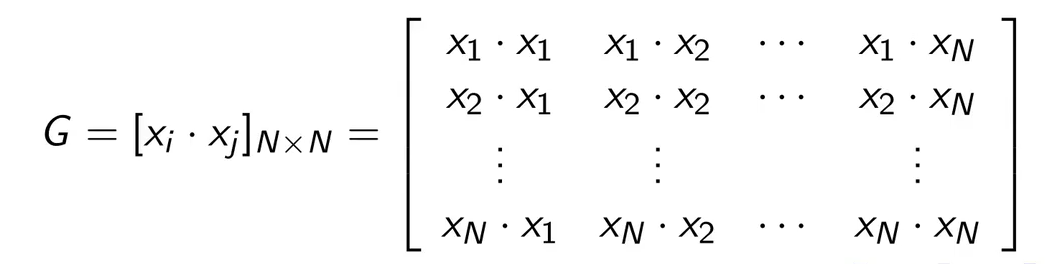
2.5.2 例题分析
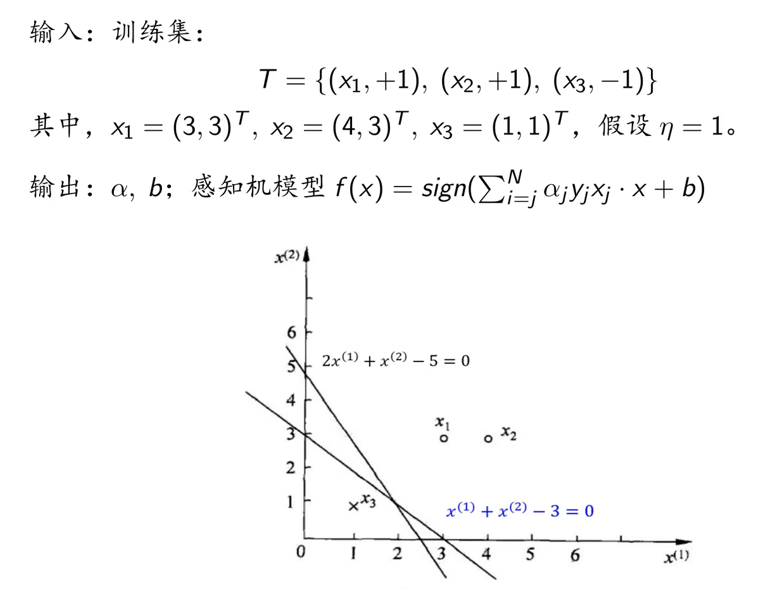
第一步:选取初始值,
第二步:计算Gram矩阵
第三步:看一下是否满足误分类条件,满足
就说明
是误分类点,需要进行参数更新。对于点
,有
,说明点
是误分类点,更新参数
,
,此时我们得到一个新的模型,
对于这个模型,我们重新看一下实例点哪个是误分类点。
对于点,有
对于点,有
对于点,有
由以上计算可以和
是正确分类点,
是误分类点,我们需要对参数进行更新:
,
第四步:重复以上步骤,直到没有误分类点:
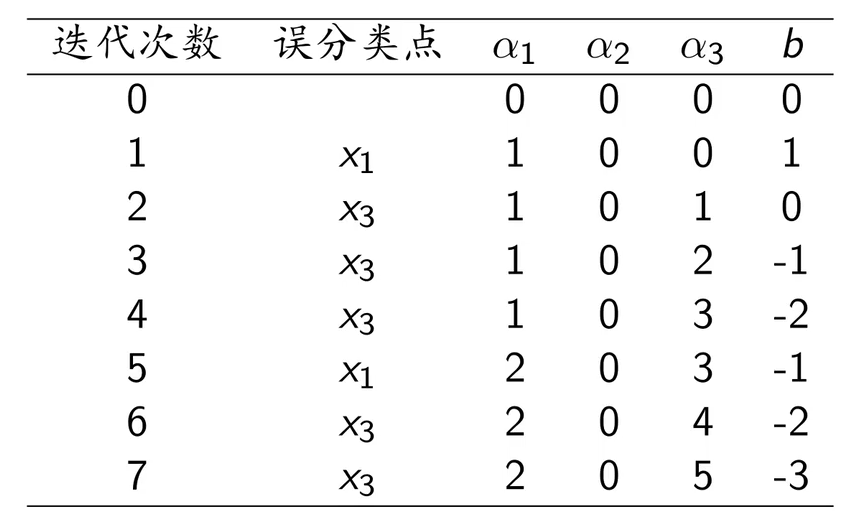
最后的系数,因此参数
最终,分离超平面就是;感知机模型就是
我们可以看出,无论是原始形式还是对偶形式,如果迭代的过程是一样的,最后得到的分离超平面还是感知机模型是不变的。同样地,类似于原始形式的学习算法,对偶形式的学习算法也是收敛的,而且存在多种解。如果我们要确定唯一解,需要加约束条件。