使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。
在这篇博客〔原作者:Fareed Khan〕中,我们将从创建两个简单的子智能体开始,然后使用监督者方法构建一个多智能体系统。在此过程中,我们将介绍基础知识、创建复杂人工智能智能体架构时可能面临的挑战,以及如何评估和改进它们。
我们将使用LangGraph和LangSmith等工具来辅助这一过程。
我们将从基础开始,逐步创建这种复杂的多智能体架构。
所有代码+理论(Jupyter Notebook)可在我的GitHub代码库中获取:
设置环境
所以,LangChain、LangGraph等所有这些模块构成了一个完整的架构。如果我一次性导入所有库,肯定会造成混淆。
因此,我们将只在需要时导入模块,因为这将帮助我们以正确的方式学习。
第一步是创建环境变量,用于存储我们的敏感信息,如API密钥等类似内容。
import os# Set environment variables for API integrations
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["LANGSMITH_API_KEY"] = "your-langsmith-api-key"
os.environ["LANGSMITH_TRACING"] = "true" # Enables LangSmith tracing
os.environ["LANGSMITH_PROJECT"] = "intelligent-rag-system" # Project name for organizing LangSmith traces
我们将使用OpenAI模型。你可能已经知道,LangChain支持大量的嵌入和文本生成模型,你可以查看其文档。
“LangSmith这个词对你来说可能比较陌生。如果你不知道它是什么,在下一节中我们将讨论它的用途。如果你已经了解,可以直接跳到下一部分。”
要获取LangSmith API密钥,你可以访问他们的网站并创建一个账户。之后,在设置中,你会找到你的API密钥。
LangSmith的用途
当我们使用大语言模型构建具有智能体功能的人工智能应用程序时,LangSmith可帮助您理解并改进这些应用程序。它就像一个 仪表盘,展示应用程序内部的运行情况,并让您能够:
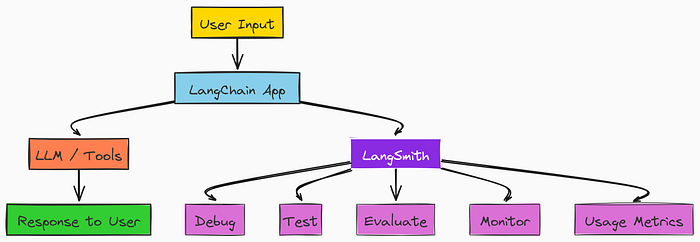
LangSmith简易工作流程
- 出问题时进行调试
- 测试你的提示词和逻辑
- 评估答案的质量如何
- 实时“监控”你的应用程序
- 跟踪使用情况、速度和成本
即使你不是开发人员,LangSmith也能让所有这些都易于使用。
所以,既然我们已经了解了LangSmith的主要用途,而且我们会时不时地在其中进行编码,那么现在就导入它吧。
from langsmith import utils# Check and print whether LangSmith tracing is currently enabled
print(f"LangSmith tracing is enabled: {utils.tracing_is_enabled()}")### output ###
LangSmith tracing is enabled: True
我们刚刚导入了稍后会用到的LangSmith工具包,并且将追踪设置为“true”,因为之前我们设置了环境变量LANGSMITH_TRACING = TRUE,这有助于我们记录并可视化人工智能智能体应用程序的执行情况。
选择我们的数据集
我们将使用**奇努克数据库**,这是一个流行的示例数据库,用于学习和测试SQL。它模拟了数字音乐商店的数据和运营情况,例如客户信息、购买历史和音乐目录。
它有多种格式,如MySQL、PostgreSQL等,但我们将使用SQLite版本的数据,因为这也有助于我们了解人工智能智能体如何与数据库交互,对于刚开始接触本人工智能智能体指南的人来说尤其有用。
所以,让我们定义一个函数,为我们设置SQLite数据库。
import sqlite3
import requests
from langchain_community.utilities.sql_database import SQLDatabase
from sqlalchemy import create_engine
from sqlalchemy.pool import StaticPooldef get_engine_for_chinook_db():"""Pull SQL file, populate in-memory database, and create engine.Downloads the Chinook database SQL script from GitHub and creates an in-memorySQLite database populated with the sample data.Returns:sqlalchemy.engine.Engine: SQLAlchemy engine connected to the in-memory database"""# Download the Chinook database SQL script from the official repositoryurl = "https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql"response = requests.get(url)sql_script = response.text# Create an in-memory SQLite database connection# check_same_thread=False allows the connection to be used across threadsconnection = sqlite3.connect(":memory:", check_same_thread=False)# Execute the SQL script to populate the database with sample dataconnection.executescript(sql_script)# Create and return a SQLAlchemy engine that uses the populated connectionreturn create_engine("sqlite://", # SQLite URL schemecreator=lambda: connection, # Function that returns the database connectionpoolclass=StaticPool, # Use StaticPool to maintain single connectionconnect_args={"check_same_thread": False}, # Allow cross-thread usage)
所以我们刚刚定义了第一个函数 get_engine_for_chinook_db(),它使用Chinook示例数据集设置了一个临时的内存SQLite数据库。
它从GitHub下载SQL脚本,在内存中创建数据库,运行脚本用表和数据填充数据库,然后返回一个连接到该数据库的SQLAlchemy引擎。
现在我们需要初始化这个函数,以便创建SQLite数据库。
# Initialize the database engine with the Chinook sample data
engine = get_engine_for_chinook_db()# Create a LangChain SQLDatabase wrapper around the engine
# This provides convenient methods for database operations and query execution
db = SQLDatabase(engine)
我们刚刚调用了该函数,并初始化了引擎,以便稍后使用人工智能智能体在该数据库上运行查询操作。
短期记忆与长期记忆
现在,我们已经初始化了数据库,接下来要探究我们的组合(Langraph + LangSmith)的第一个优势,即两种不同类型的可用内存。但首先,我们要了解什么是内存。
在任何智能体中,记忆都起着重要作用。与人类一样,人工智能智能体需要记住过去的交互,以保持上下文连贯性并提供个性化的回应。
在语言图谱(LangGraph)中,我们对短期记忆和长期记忆进行区分,以下是它们之间的简要区别:
- 短期记忆帮助智能体跟踪当前对话。在LangGraph中,这由一个MemorySaver来处理,它保存并恢复对话状态。
- 虽然长期记忆使智能体能够在不同对话中记住信息,比如用户偏好。例如,我们可以使用内存存储进行快速存储,但在实际应用中,你会使用更持久的数据库。
咱们把它们俩都初始化一下。
from langgraph.checkpoint.memory import MemorySaver
from langgraph.store.memory import InMemoryStore# Initialize long-term memory store for persistent data between conversations
in_memory_store = InMemoryStore()# Initialize checkpointer for short-term memory within a single thread/conversation
checkpointer = MemorySaver()
我们正在使用in_memory_store作为长期记忆,这样即使对话结束后,我们也能保存用户偏好。
同时,MemorySaver(检查点程序)会完整保留当前对话的上下文,从而实现流畅的多轮交互。
我们的多智能体架构
所以,我们的目标是打造一个逼真的客户支持智能体,它并非单一智能体,而是通过LangGraph中的多智能体工作流程来实现。
我们将从一个简单的ReAct智能体开始,在工作流程中添加额外步骤,模拟一个真实的客户支持示例,展示人工介入、长期记忆以及LangGraph预构建库。
我们将逐步构建多智能体工作流程的每个组件,因为它包含两个子智能体,即两个专门的ReAct(推理与行动)子智能体,它们随后将组合起来,形成一个包含更多步骤的多智能体工作流程。
我们的工作流程从
- 人工输入,用户在此处提供账户信息。
- 然后,在verify_info中,系统会检查账户,并在必要时阐明用户的意图。
- 接下来,加载记忆会检索用户的音乐偏好。
- 管理智能体协调两个子智能体:音乐目录智能体(用于音乐数据)和 发票信息智能体(用于计费)。
- 最后,创建记忆会用交互中产生的新信息更新用户记忆。
所以现在我们已经了解了基础知识,让我们开始构建第一个子智能体。
目录信息子智能体
我们的第一个子智能体将是一个音乐目录信息智能体。它的主要职责是协助客户查询与我们的数字音乐目录相关的信息,例如搜索歌手、专辑或歌曲。
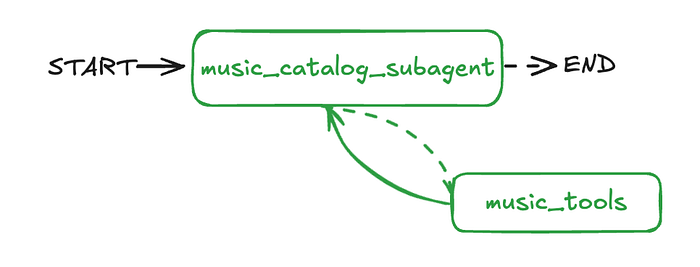
目录信息子智能体(源自LangChain——开源项目)
我们的智能体将如何记住信息、决定做什么以及执行行动呢?这就引出了LangGraph的三个基本概念:状态、工具和 节点。
定义状态、工具和节点
在语言图(LangGraph)中,状态保存着流经该图的当前数据快照,基本上就是智能体的记忆。
对于我们的客户支持智能体,状态包括:
- customer_id: 用于识别客户,以便提供个性化回复和检索数据。
- 消息: 对话中交换的所有消息的列表,为智能体提供上下文。
- 已加载的记忆: 特定于用户的长期信息(如偏好)已加载到对话中。
- remaining_steps: 计算还剩下多少步骤以防止出现无限循环。
随着对话的推进,每个节点都会更新此状态。我们使用TypedDict来定义状态以进行类型提示,并使用LangGraph消息模块中的Annotated来方便地追加消息。
from typing_extensions import TypedDict
from typing import Annotated, List
from langgraph.graph.message import AnyMessage, add_messages
from langgraph.managed.is_last_step import RemainingStepsclass State(TypedDict):"""State schema for the multi-agent customer support workflow.This defines the shared data structure that flows between nodes in the graph,representing the current snapshot of the conversation and agent state."""# Customer identifier retrieved from account verificationcustomer_id: str# Conversation history with automatic message aggregationmessages: Annotated[list[AnyMessage], add_messages]# User preferences and context loaded from long-term memory storeloaded_memory: str# Counter to prevent infinite recursion in agent workflowremaining_steps: RemainingSteps
这个状态类将作为我们多智能体系统不同部分之间信息管理和传递方式的蓝图。
接下来,我们将使用工具扩展智能体的能力。工具是一些函数,它们能让大语言模型(LLM)完成其自身无法完成的任务,比如调用应用程序编程接口(API)或访问数据库。
对于我们的智能体,工具将连接到Chinook数据库以获取与音乐相关的信息。
我们将定义Python函数,并使用来自langchain_core.tools的@tool对其进行标记,这样大语言模型(LLM)就可以在需要时找到并使用它们。
from langchain_core.tools import tool
import ast@tool
def get_albums_by_artist(artist: str):"""Get albums by an artist from the music database.Args:artist (str): The name of the artist to search for albums.Returns:str: Database query results containing album titles and artist names."""return db.run(f"""SELECT Album.Title, Artist.NameFROM AlbumJOIN Artist ON Album.ArtistId = Artist.ArtistIdWHERE Artist.Name LIKE '%{artist}%';""",include_columns=True)@tool
def get_tracks_by_artist(artist: str):"""Get songs/tracks by an artist (or similar artists) from the music database.Args:artist (str): The name of the artist to search for tracks.Returns:str: Database query results containing song names and artist names."""return db.run(f"""SELECT Track.Name as SongName, Artist.Name as ArtistNameFROM AlbumLEFT JOIN Artist ON Album.ArtistId = Artist.ArtistIdLEFT JOIN Track ON Track.AlbumId = Album.AlbumIdWHERE Artist.Name LIKE '%{artist}%';""",include_columns=True)@tool
def get_songs_by_genre(genre: str):"""Fetch songs from the database that match a specific genre.This function first looks up the genre ID(s) for the given genre name,then retrieves songs that belong to those genre(s), limiting resultsto 8 songs grouped by artist.Args:genre (str): The genre of the songs to fetch.Returns:list[dict] or str: A list of songs with artist information that matchthe specified genre, or an error message if no songs found."""# First, get the genre ID(s) for the specified genregenre_id_query = f"SELECT GenreId FROM Genre WHERE Name LIKE '%{genre}%'"genre_ids = db.run(genre_id_query)# Check if any genres were foundif not genre_ids:return f"No songs found for the genre: {genre}"# Parse the genre IDs and format them for the SQL querygenre_ids = ast.literal_eval(genre_ids)genre_id_list = ", ".join(str(gid[0]) for gid in genre_ids)# Query for songs in the specified genre(s)songs_query = f"""SELECT Track.Name as SongName, Artist.Name as ArtistNameFROM TrackLEFT JOIN Album ON Track.AlbumId = Album.AlbumIdLEFT JOIN Artist ON Album.ArtistId = Artist.ArtistIdWHERE Track.GenreId IN ({genre_id_list})GROUP BY Artist.NameLIMIT 8;"""songs = db.run(songs_query, include_columns=True)# Check if any songs were foundif not songs:return f"No songs found for the genre: {genre}"# Format the results into a structured list of dictionariesformatted_songs = ast.literal_eval(songs)return [{"Song": song["SongName"], "Artist": song["ArtistName"]}for song in formatted_songs]@tool
def check_for_songs(song_title):"""Check if a song exists in the database by its name.Args:song_title (str): The title of the song to search for.Returns:str: Database query results containing all track informationfor songs matching the given title."""return db.run(f"""SELECT * FROM Track WHERE Name LIKE '%{song_title}%';""",include_columns=True)
在这个模块中,我们定义了四个特定的工具:
get_albums_by_artist:按指定艺术家查找专辑get_tracks_by_artist:按歌手查找单曲- <代码开始>
get_songs_by_genre:检索属于特定流派的歌曲 <代码结束> check_for_songs:验证特定歌曲是否存在于目录中
这些工具中的每一个都通过执行SQL查询与我们的db(我们之前初始化的SQLDatabase包装器)进行交互。然后,结果会以结构化格式返回。
# Create a list of all music-related tools for the agent
music_tools = [get_albums_by_artist, get_tracks_by_artist, get_songs_by_genre, check_for_songs]# Bind the music tools to the language model for use in the ReAct agent
llm_with_music_tools = llm.bind_tools(music_tools)
最后,我们使用 llm.bind_tools() 将这些 music_tools 绑定到我们的 llm 上。
这一关键步骤使大语言模型能够根据用户的查询,理解何时以及如何调用这些函数。
既然我们的状态已经定义好,并且工具也已准备就绪,现在我们可以定义图的节点了。
节点是LangGraph应用程序中的核心处理单元,它们将图的当前状态作为输入,执行一些逻辑,并返回一个更新后的状态。
对于我们的ReAct智能体,我们将定义两种关键类型的节点:
- 音乐助手是大语言模型推理节点。它利用当前对话历史和记忆来决定下一步行动,无论是调用工具还是生成回复,并更新状态。
- music_tool_node 运行由music_assistant选择的工具。LangGraph工具节点管理工具调用,并使用结果更新状态。
通过组合这些节点,我们能够在多智能体工作流程中实现动态推理和行动。
让我们首先为我们的music_tools创建ToolNode:
from langgraph.prebuilt import ToolNode# Create a tool node that executes the music-related tools
# ToolNode is a pre-built LangGraph component that handles tool execution
music_tool_node = ToolNode(music_tools)
现在,我们将定义 music_assistant 节点。此节点将使用我们的大语言模型(绑定了 music_tools)来确定下一步行动。
它还将任何loaded_memory整合到其提示中,从而实现个性化回复。
from langchain_core.messages import ToolMessage, SystemMessage, HumanMessage
from langchain_core.runnables import RunnableConfigdef generate_music_assistant_prompt(memory: str = "None") -> str:"""Generate a system prompt for the music assistant agent.Args:memory (str): User preferences and context from long-term memory storeReturns:str: Formatted system prompt for the music assistant"""return f"""You are a member of the assistant team, your role specifically is to focused on helping customers discover and learn about music in our digital catalog.If you are unable to find playlists, songs, or albums associated with an artist, it is okay.Just inform the customer that the catalog does not have any playlists, songs, or albums associated with that artist.You also have context on any saved user preferences, helping you to tailor your response.CORE RESPONSIBILITIES:- Search and provide accurate information about songs, albums, artists, and playlists- Offer relevant recommendations based on customer interests- Handle music-related queries with attention to detail- Help customers discover new music they might enjoy- You are routed only when there are questions related to music catalog; ignore other questions.SEARCH GUIDELINES:1. Always perform thorough searches before concluding something is unavailable2. If exact matches aren't found, try:- Checking for alternative spellings- Looking for similar artist names- Searching by partial matches- Checking different versions/remixes3. When providing song lists:- Include the artist name with each song- Mention the album when relevant- Note if it's part of any playlists- Indicate if there are multiple versionsAdditional context is provided below:Prior saved user preferences: {memory}Message history is also attached."""
我们还需要创建一个 music_assistant 函数,那么我们来创建一个。
def music_assistant(state: State, config: RunnableConfig):"""Music assistant node that handles music catalog queries and recommendations.This node processes customer requests related to music discovery, album searches,artist information, and personalized recommendations based on stored preferences.Args:state (State): Current state containing customer_id, messages, loaded_memory, etc.config (RunnableConfig): Configuration for the runnable executionReturns:dict: Updated state with the assistant's response message"""# Retrieve long-term memory preferences if availablememory = "None"if "loaded_memory" in state:memory = state["loaded_memory"]# Generate instructions for the music assistant agentmusic_assistant_prompt = generate_music_assistant_prompt(memory)# Invoke the language model with tools and system prompt# The model can decide whether to use tools or respond directlyresponse = llm_with_music_tools.invoke([SystemMessage(music_assistant_prompt)] + state["messages"])# Return updated state with the assistant's responsereturn {"messages": [response]}
music_assistant节点为大语言模型构建详细的系统提示,包括通用指令和用于个性化定制的loaded_memory。
然后,它会使用此系统消息和当前对话消息调用llm_with_music_tools。基于其推理,大语言模型(LLM)可能会输出最终答案或工具调用。
它只是返回这个大语言模型(LLM)的响应,add_messages(来自我们的状态定义)会自动将其追加到状态中的messages列表中。
有了状态(State)和节点(Nodes),下一步就是使用边(Edges)将它们连接起来,边定义了图中的执行流。
普通边很简单——它们总是从一个特定节点路由到另一个节点。
条件边是动态的。这些是Python函数,用于检查当前状态并决定接下来访问哪个节点。
对于我们的ReAct智能体,我们需要一条条件边,用于检查music_assistant是否应该:
- **调用工具:**如果大语言模型决定调用某个工具,我们会将其路由到
music_tool_node来执行。 - 结束该过程。如果大语言模型(LLM)在不调用工具的情况下给出最终回复,我们便结束子智能体的执行。
为处理这一逻辑,我们定义了 should_continue 函数。
def should_continue(state: State, config: RunnableConfig):"""Conditional edge function that determines the next step in the ReAct agent workflow.This function examines the last message in the conversation to decide whether the agentshould continue with tool execution or end the conversation.Args:state (State): Current state containing messages and other workflow dataconfig (RunnableConfig): Configuration for the runnable executionReturns:str: Either "continue" to execute tools or "end" to finish the workflow"""# Get all messages from the current statemessages = state["messages"]# Examine the most recent message to check for tool callslast_message = messages[-1]# If the last message doesn't contain any tool calls, the agent is doneif not last_message.tool_calls:return "end"# If there are tool calls present, continue to execute themelse:return "continue"
should_continue函数会检查状态中的最后一条消息。如果其中包含tool_calls,这意味着大语言模型(LLM)想要使用一个工具,因此该函数返回"continue"。
否则,它返回"end",表明大语言模型(LLM)已给出直接回复,子智能体的任务已完成。
既然我们已经有了所有的组件,即状态(State)、节点(Nodes)和边(Edges)。
让我们使用StateGraph将它们组装起来,构建完整的ReAct智能体。
from langgraph.graph import StateGraph, START, END
from utils import show_graph# Create a new StateGraph instance for the music workflow
music_workflow = StateGraph(State)# Add nodes to the graph
# music_assistant: The reasoning node that decides which tools to invoke or responds directly
music_workflow.add_node("music_assistant", music_assistant)
# music_tool_node: The execution node that handles all music-related tool calls
music_workflow.add_node("music_tool_node", music_tool_node)# Add edges to define the flow of the graph
# Set the entry point - all queries start with the music assistant
music_workflow.add_edge(START, "music_assistant")# Add conditional edge from music_assistant based on whether tools need to be called
music_workflow.add_conditional_edges("music_assistant",# Conditional function that determines the next stepshould_continue,{# If tools need to be executed, route to tool node"continue": "music_tool_node",# If no tools needed, end the workflow"end": END,},
)# After tool execution, always return to the music assistant for further processing
music_workflow.add_edge("music_tool_node", "music_assistant")# Compile the graph with checkpointer for short-term memory and store for long-term memory
music_catalog_subagent = music_workflow.compile(name="music_catalog_subagent",checkpointer=checkpointer,store=in_memory_store
)# Display the compiled graph structure
show_graph(music_catalog_subagent)
在这最后一步,我们使用定义好的状态创建一个StateGraph。我们为music_assistant和music_tool_node添加节点。
该图从 START 开始,通向 music_assistant。核心的ReAct循环通过从 music_assistant 出发的条件边进行设置,如果检测到工具调用,则路由到 music_tool_node,如果响应是最终的,则路由到 END。
在music_tool_node运行后,一条边将流程带回music_assistant,使大语言模型能够处理工具的输出并继续推理。
让我们来看一下我们的图:
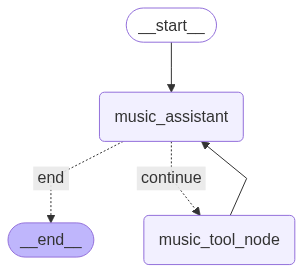
我们智能体的图
现在,是时候测试我们的第一个子智能体了:
import uuid# Generate a unique thread ID for this conversation session
thread_id = uuid.uuid4()# Define the user's question about music recommendations
question = "I like the Rolling Stones. What songs do you recommend by them or by other artists that I might like?"# Set up configuration with the thread ID for maintaining conversation context
config = {"configurable": {"thread_id": thread_id}}# Invoke the music catalog subagent with the user's question
# The agent will use its tools to search for Rolling Stones music and provide recommendations
result = music_catalog_subagent.invoke({"messages": [HumanMessage(content=question)]}, config=config)# Display all messages from the conversation in a formatted way
for message in result["messages"]:message.pretty_print()
我们为此次对话分配了一个唯一的线程ID,我们的问题是关于类似滚石乐队风格的音乐推荐,让我们看看我们的人工智能智能体会用什么工具来回应。
======= Human Message ======I like the Rolling Stones. What songs do you recommend by them or by
other artists that I might like?======= Ai Message ======Tool Calls:get_tracks_by_artist (chatcmpl-tool-012bac57d6af46ddaad8e8971cca2bf7)Call ID: chatcmpl-tool-012bac57d6af46ddaad8e8971cca2bf7Args:artist: The Rolling Stones
因此,基于作为我们查询内容的人类消息,它会使用正确的工具get_tracks_by_artist做出响应,该工具负责根据我们查询中指定的艺术家来查找推荐内容。
现在,我们已经创建了第一个子智能体,让我们来创建第二个子智能体。
使用预构建库的发票信息子智能体
虽然从零开始构建一个ReAct智能体对于理解基本原理很有帮助,但LangGraph也为常见架构提供了预构建库。
因为它让我们能够快速搭建诸如ReAct这样的标准模式,而无需手动定义所有的节点和边。你可以在LangGraph文档中找到这些预构建库的完整列表。
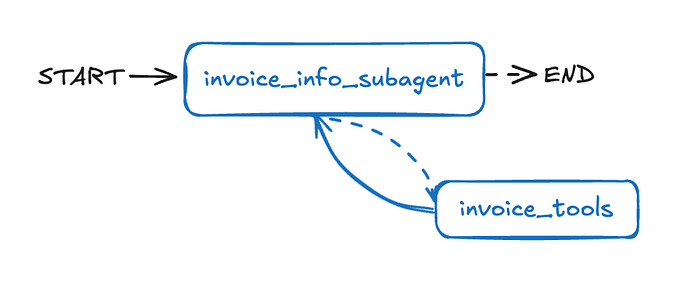
发票信息子智能体(源自LangChain - 开源项目)
和之前一样,我们首先为我们的invoice_information_subagent定义特定的工具和提示。这些工具将与Chinook数据库进行交互,以检索发票详细信息。
from langchain_core.tools import tool@tool
def get_invoices_by_customer_sorted_by_date(customer_id: str) -> list[dict]:"""Look up all invoices for a customer using their ID.The invoices are sorted in descending order by invoice date, which helps when the customer wants to view their most recent/oldest invoice, or ifthey want to view invoices within a specific date range.Args:customer_id (str): customer_id, which serves as the identifier.Returns:list[dict]: A list of invoices for the customer."""return db.run(f"SELECT * FROM Invoice WHERE CustomerId = {customer_id} ORDER BY InvoiceDate DESC;")@tool
def get_invoices_sorted_by_unit_price(customer_id: str) -> list[dict]:"""Use this tool when the customer wants to know the details of one of their invoices based on the unit price/cost of the invoice.This tool looks up all invoices for a customer, and sorts the unit price from highest to lowest. In order to find the invoice associated with the customer,we need to know the customer ID.Args:customer_id (str): customer_id, which serves as the identifier.Returns:list[dict]: A list of invoices sorted by unit price."""query = f"""SELECT Invoice.*, InvoiceLine.UnitPriceFROM InvoiceJOIN InvoiceLine ON Invoice.InvoiceId = InvoiceLine.InvoiceIdWHERE Invoice.CustomerId = {customer_id}ORDER BY InvoiceLine.UnitPrice DESC;"""return db.run(query)@tool
def get_employee_by_invoice_and_customer(invoice_id: str, customer_id: str) -> dict:"""This tool will take in an invoice ID and a customer ID and return the employee information associated with the invoice.Args:invoice_id (int): The ID of the specific invoice.customer_id (str): customer_id, which serves as the identifier.Returns:dict: Information about the employee associated with the invoice."""query = f"""SELECT Employee.FirstName, Employee.Title, Employee.EmailFROM EmployeeJOIN Customer ON Customer.SupportRepId = Employee.EmployeeIdJOIN Invoice ON Invoice.CustomerId = Customer.CustomerIdWHERE Invoice.InvoiceId = ({invoice_id}) AND Invoice.CustomerId = ({customer_id});"""employee_info = db.run(query, include_columns=True)if not employee_info:return f"No employee found for invoice ID {invoice_id} and customer identifier {customer_id}."return employee_info
我们定义了三个专门用于处理发票的工具:
get_invoices_by_customer_sorted_by_date:检索某个客户的所有发票,并按日期排序get_invoices_sorted_by_unit_price:检索按发票内项目单价排序的发票get_employee_by_invoice_and_customer:查找与特定发票关联的支持员工
而且,就像之前一样,之后我们必须将所有这些工具添加到一个列表中。
# Create a list of all invoice-related tools for the agent
invoice_tools = [get_invoices_by_customer_sorted_by_date, get_invoices_sorted_by_unit_price, get_employee_by_invoice_and_customer]
现在,让我们定义引导发票子智能体行为的提示词:
invoice_subagent_prompt = """You are a subagent among a team of assistants. You are specialized for retrieving and processing invoice information. You are routed for invoice-related portion of the questions, so only respond to them..You have access to three tools. These tools enable you to retrieve and process invoice information from the database. Here are the tools:- get_invoices_by_customer_sorted_by_date: This tool retrieves all invoices for a customer, sorted by invoice date.- get_invoices_sorted_by_unit_price: This tool retrieves all invoices for a customer, sorted by unit price.- get_employee_by_invoice_and_customer: This tool retrieves the employee information associated with an invoice and a customer.If you are unable to retrieve the invoice information, inform the customer you are unable to retrieve the information, and ask if they would like to search for something else.CORE RESPONSIBILITIES:- Retrieve and process invoice information from the database- Provide detailed information about invoices, including customer details, invoice dates, total amounts, employees associated with the invoice, etc. when the customer asks for it.- Always maintain a professional, friendly, and patient demeanorYou may have additional context that you should use to help answer the customer's query. It will be provided to you below:"""
此提示概述了子智能体的角色、可用工具、核心职责以及在未找到信息时的处理指南。
这条有针对性的指令有助于大语言模型在其专业领域内有效地发挥作用。
现在,我们不再像之前为子智能体那样手动为ReAct模式创建节点和条件边,而是使用LangGraph的create_react_agent预构建函数。
from langgraph.prebuilt import create_react_agent# Create the invoice information subagent using LangGraph's pre-built ReAct agent
# This agent specializes in handling customer invoice queries and billing information
invoice_information_subagent = create_react_agent(llm, # Language model for reasoning and responsestools=invoice_tools, # Invoice-specific tools for database queriesname="invoice_information_subagent", # Unique identifier for the agentprompt=invoice_subagent_prompt, # System instructions for invoice handlingstate_schema=State, # State schema for data flow between nodescheckpointer=checkpointer, # Short-term memory for conversation contextstore=in_memory_store # Long-term memory store for persistent data
)
`create_react_agent`函数接收我们的`llm`、`invoice_tools`、智能体的名称(这对多智能体路由很重要)、我们刚刚定义的提示词、我们自定义的`State`模式,并连接检查点和存储以实现记忆功能。
只需几行代码,我们就拥有了一个功能完备的ReAct智能体,这就是使用LangGraph的优势。
测试第二个子智能体
让我们测试一下新的invoice_information_subagent,确保其按预期工作。我们将提供一个需要获取发票和员工信息的查询。
# Generate a unique thread ID for this conversation sessionthread_id = uuid.uuid4()# Define the user's question about their recent invoice and employee assistancequestion = "My customer id is 1. What was my most recent invoice, and who was the employee that helped me with it?"# Set up configuration with the thread ID for maintaining conversation contextconfig = {"configurable": {"thread_id": thread_id}}# Invoke the invoice information subagent with the user's question# The agent will use its tools to search for invoice information and employee detailsresult = invoice_information_subagent.invoke({"messages": [HumanMessage(content=question)]}, config=config)# Display all messages from the conversation in a formatted wayfor message in result["messages"]:
message.pretty_print()
所以,我们主要是在询问客户ID为1的发票情况。咱们来看看正在调用哪些工具。
======= Human Message ======My customer id is 1. What was my most recent invoice, and who
was the employee that helped me with it?======= Ai Message ======Name: invoice_information_subagent
Tool Calls:get_invoices_by_customer_sorted_by_date (chatcmpl-tool-8f3cc6f6ef41454099eaae576409bfe2)Call ID: chatcmpl-tool-8f3cc6f6ef41454099eaae576409bfe2Args:customer_id: 1
它会根据我们的查询打印出正确的工具,输出结果与我们之前手动创建的第一个子智能体的输出基本相同,所有正确的参数均从查询中获取。
所以,我们已经创建了两个子智能体,现在我们可以继续创建多智能体架构了。我们开始吧。
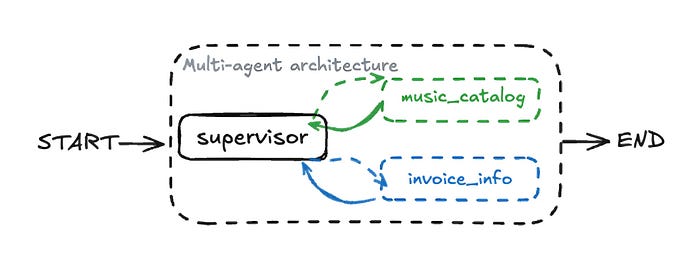
使用监督智能体创建多智能体
我们有两个子智能体:一个处理音乐相关问题,另一个处理发票相关问题。于是,一个很自然的问题出现了:
我们如何确保客户任务被恰当地路由到正确的子智能体?
这就是“超级智能体”概念发挥作用的地方。它根据查询内容将客户请求路由到合适的子智能体。子智能体完成任务后,控制权会返回给超级智能体,或者传递给另一个子智能体。
基于监督智能体的多智能体架构带来了关键优势:
主管(来自LangChain - 开源)
- 每个子智能体专注于特定领域,提高准确性并便于添加新智能体。
- 智能体可以在不影响整个系统的情况下进行添加、删除或更新,支持可扩展性。
- 将大语言模型限制在特定任务上,可降低产生错误或不相关输出的可能性。
我们将使用LangGraph内置的监管智能体库快速构建这种多智能体设置。
首先,我们将为我们的主管创建一组指令。这个提示将定义其角色,告知其可用的子智能体及其能力,并指导其路由决策过程。
supervisor_prompt = """You are an expert customer support assistant for a digital music store.
You are dedicated to providing exceptional service and ensuring customer queries are answered thoroughly.
You have a team of subagents that you can use to help answer queries from customers.
Your primary role is to serve as a supervisor/planner for this multi-agent team that helps answer queries from customers.Your team is composed of two subagents that you can use to help answer the customer's request:
1. music_catalog_information_subagent: this subagent has access to user's saved music preferences. It can also retrieve information about the digital music store's music
catalog (albums, tracks, songs, etc.) from the database.
3. invoice_information_subagent: this subagent is able to retrieve information about a customer's past purchases or invoices
from the database.Based on the existing steps that have been taken in the messages, your role is to generate the next subagent that needs to be called.
This could be one step in an inquiry that needs multiple sub-agent calls. """
这个监管提示将其角色定义为路由器和规划器,了解music_catalog_information_subagent和invoice_information_subagent能做什么,并决定接下来调用哪一个。
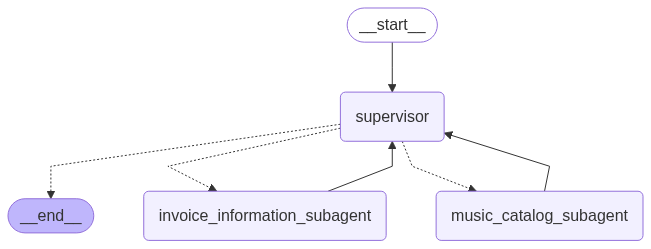
现在,让我们使用LangGraph预构建的create_supervisor函数,让我们的监督器开始工作。
from langgraph_supervisor import create_supervisor# Create supervisor workflow using LangGraph's pre-built supervisor
# The supervisor coordinates between multiple subagents based on the incoming queries
supervisor_prebuilt_workflow = create_supervisor(agents=[invoice_information_subagent, music_catalog_subagent], # List of subagents to superviseoutput_mode="last_message", # Return only the final response (alternative: "full_history")model=llm, # Language model for supervisor reasoning and routing decisionsprompt=(supervisor_prompt), # System instructions for the supervisor agentstate_schema=State # State schema defining data flow structure
)# Compile the supervisor workflow with memory components
# - checkpointer: Enables short-term memory within conversation threads
# - store: Provides long-term memory storage across conversations
supervisor_prebuilt = supervisor_prebuilt_workflow.compile(name="music_catalog_subagent",checkpointer=checkpointer,store=in_memory_store
)# Display the compiled supervisor graph structure
show_graph(supervisor_prebuilt)
我们向其提供子智能体列表,将 output_mode 设置为仅返回活动子智能体的最后一条消息,指定我们的大语言模型,提供监督提示,并连接我们的状态模式。
让我们看看我们的监督者架构是什么样的:
主管架构(由法里德·汗创建)
正如我之前所说,监管智能体由我们之前定义的两个子智能体组成,因为它们将按照我们所描述的监管提示行事。
测试我们的多智能体架构
让我们测试一下基于监督智能体的多智能体架构,看看效果如何。
# Generate a unique thread ID for this conversation session
thread_id = uuid.uuid4()# Define a question that tests both invoice and music catalog capabilities
question = "My customer ID is 1. How much was my most recent purchase? What albums do you have by U2?"# Set up configuration with the thread ID for maintaining conversation context
config = {"configurable": {"thread_id": thread_id}}# Invoke the supervisor workflow with the multi-part question
# The supervisor will route to appropriate subagents for invoice and music queries
result = supervisor_prebuilt.invoke({"messages": [HumanMessage(content=question)]}, config=config)# Display all messages from the conversation in a formatted way
for message in result["messages"]:message.pretty_print()
我们使用的代码几乎相同,但我们以一种特定方式定义了查询,以便测试我们的两个子智能体在监督者之下会如何行动。我们运行一下看看它输出什么。
================================[1m Human Message [0m=================================My customer ID is 1. How much was my most recent purchase? What albums do you have by U2?
==================================[1m Ai Message [0m==================================
Name: supervisor
Tool Calls:transfer_to_invoice_information_subagent (chatcmpl-tool-bece02300e1845dea927ce0e505e1f7f)Call ID: chatcmpl-tool-bece02300e1845dea927ce0e505e1f7fArgs:
=================================[1m Tool Message [0m=================================
Name: transfer_to_invoice_information_subagentSuccessfully transferred to invoice_information_subagent
==================================[1m Ai Message [0m==================================
Name: invoice_information_subagentYour most recent purchase was on '2025-08-07 00:00:00' and the total amount was $8.91. Unfortunately, I am unable to provide information about U2 albums as it is not related to invoice information. Would you like to search for something else?
==================================[1m Ai Message [0m==================================
Name: invoice_information_subagentTransferring back to supervisor
Tool Calls:transfer_back_to_supervisor (9f3d9fce-0f11-43c0-88c4-adcd459a30a0)Call ID: 9f3d9fce-0f11-43c0-88c4-adcd459a30a0Args:
=================================[1m Tool Message [0m=================================
Name: transfer_back_to_supervisorSuccessfully transferred back to supervisor
==================================[1m Ai Message [0m==================================
Name: supervisor
Tool Calls:transfer_to_music_catalog_information_subagent (chatcmpl-tool-72475cf0c17f404583145912fca0b718)Call ID: chatcmpl-tool-72475cf0c17f404583145912fca0b718Args:
=================================[1m Tool Message [0m=================================
Name: transfer_to_music_catalog_information_subagentError: transfer_to_music_catalog_information_subagent is not a valid tool, try one of [transfer_to_music_catalog_subagent, transfer_to_invoice_information_subagent].
==================================[1m Ai Message [0m==================================
Name: supervisor
Tool Calls:transfer_to_music_catalog_subagent (chatcmpl-tool-71cc764428ff4efeb0ba7bf24b64a6ec)Call ID: chatcmpl-tool-71cc764428ff4efeb0ba7bf24b64a6ecArgs:
=================================[1m Tool Message [0m=================================
Name: transfer_to_music_catalog_subagentSuccessfully transferred to music_catalog_subagent
==================================[1m Ai Message [0m==================================U2 has the following albums in our catalog:
1. Achtung Baby
2. All That You Can't Leave Behind
3. B-Sides 1980-1990
4. How To Dismantle An Atomic Bomb
5. Pop
6. Rattle And Hum
7. The Best Of 1980-1990
8. War
9. Zooropa
10. Instant Karma: The Amnesty International Campaign to Save DarfurWould you like to explore more music or is there something else I can help you with?
==================================[1m Ai Message [0m==================================
Name: music_catalog_subagentTransferring back to supervisor
Tool Calls:transfer_back_to_supervisor (4739ce04-dd11-47c8-b35a-9e4fca21b0c1)Call ID: 4739ce04-dd11-47c8-b35a-9e4fca21b0c1Args:
=================================[1m Tool Message [0m=================================
Name: transfer_back_to_supervisorSuccessfully transferred back to supervisor
==================================[1m Ai Message [0m==================================
Name: supervisorI hope this information helps you with your inquiry. Is there anything else I can help you with?
周围发生了很多事情,这很好,我们的多智能体正在与我们的用户进行非常详细的对话。让我们来了解一下。
在这个例子中,用户提出了一个涉及发票明细和音乐目录数据的问题。具体过程如下:
- 主管收到查询。
- 它检测与发票相关的部分(“最近的购买记录”),并将其发送给
invoice_information_subagent。 - 发票子智能体处理该部分,获取发票,但无法回答关于U2乐队专辑的问题,因此它将控制权交回给主管。
- 然后,监督智能体将剩余的音乐查询发送给
music_catalog_subagent。 - 音乐子智能体检索U2乐队专辑信息,然后将控制权交回给主管智能体。
- 监督者完成总结,通过协调两个子智能体,全面回答了用户的多部分问题。
加入人工介入
到目前为止,我们已经构建了一个多智能体系统,该系统可以将客户查询路由到专门的子智能体。然而,在现实世界的客户支持场景中,我们并不总是能随时获取客户ID。
在允许智能体访问诸如发票历史记录等敏感信息之前,我们通常需要核实客户身份。
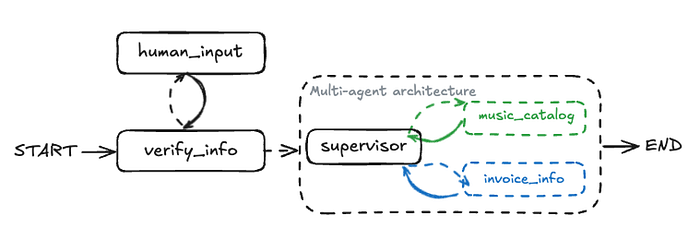
人机交互(源自LangChain - 开源项目)
在这一步中,我们将通过添加客户验证层来优化我们的工作流程。这将涉及一个 “人机交互” 组件,如果客户账户信息缺失或未经验证,系统可能会暂停并提示客户提供相关信息。
为实现这一点,我们引入两个新节点:
- verify_info节点尝试使用我们的数据库从用户输入中提取并验证客户身份信息(身份证、电子邮件或电话)。
- 如果验证失败,将触发“用户输入节点”。它会暂停图表并提示用户输入缺失的信息。使用LangGraph的
interrupt()功能可以轻松处理此问题。
首先,我们来定义一个用于解析用户输入的Pydantic模式,以及一个供大语言模型(LLM)可靠提取此信息的系统提示。
from pydantic import BaseModel, Fieldclass UserInput(BaseModel):"""Schema for parsing user-provided account information."""identifier: str = Field(description="Identifier, which can be a customer ID, email, or phone number.")# Create a structured LLM that outputs responses conforming to the UserInput schema
structured_llm = llm.with_structured_output(schema=UserInput)# System prompt for extracting customer identifier information
structured_system_prompt = """You are a customer service representative responsible for extracting customer identifier.
Only extract the customer's account information from the message history.
If they haven't provided the information yet, return an empty string for the identifier."""
UserInput Pydantic模型将预期数据定义为单个标识符。
我们使用with_structured_output()使大语言模型以这种格式返回JSON。系统提示有助于大语言模型只专注于提取标识符。
接下来,我们需要一个辅助函数来获取提取的标识符(可能是客户ID、电话号码或电子邮件),并在我们的Chinook数据库中查找,以检索实际的customer_id。
from typing import Optional# Helper function for customer identification
def get_customer_id_from_identifier(identifier: str) -> Optional[int]:"""Retrieve Customer ID using an identifier, which can be a customer ID, email, or phone number.This function supports three types of identifiers:1. Direct customer ID (numeric string)2. Phone number (starts with '+')3. Email address (contains '@')Args:identifier (str): The identifier can be customer ID, email, or phone number.Returns:Optional[int]: The CustomerId if found, otherwise None."""# Check if identifier is a direct customer ID (numeric)if identifier.isdigit():return int(identifier)# Check if identifier is a phone number (starts with '+')elif identifier[0] == "+":query = f"SELECT CustomerId FROM Customer WHERE Phone = '{identifier}';"result = db.run(query)formatted_result = ast.literal_eval(result)if formatted_result:return formatted_result[0][0]# Check if identifier is an email address (contains '@')elif "@" in identifier:query = f"SELECT CustomerId FROM Customer WHERE Email = '{identifier}';"result = db.run(query)formatted_result = ast.literal_eval(result)if formatted_result:return formatted_result[0][0]# Return None if no match foundreturn None
此实用工具函数尝试将提供的标识符解释为客户ID、电话号码或电子邮件,然后查询数据库以找到相应的数字CustomerId。
现在,我们定义verify_info节点。该节点负责协调标识符提取和验证过程。
def verify_info(state: State, config: RunnableConfig):"""Verify the customer's account by parsing their input and matching it with the database.This node handles customer identity verification as the first step in the support process.It extracts customer identifiers (ID, email, or phone) from user messages and validatesthem against the database.Args:state (State): Current state containing messages and potentially customer_idconfig (RunnableConfig): Configuration for the runnable executionReturns:dict: Updated state with customer_id if verified, or request for more info"""# Only verify if customer_id is not already setif state.get("customer_id") is None:# System instructions for prompting customer verificationsystem_instructions = """You are a music store agent, where you are trying to verify the customer identityas the first step of the customer support process.Only after their account is verified, you would be able to support them on resolving the issue.In order to verify their identity, one of their customer ID, email, or phone number needs to be provided.If the customer has not provided their identifier, please ask them for it.If they have provided the identifier but cannot be found, please ask them to revise it."""# Get the most recent user messageuser_input = state["messages"][-1]# Use structured LLM to parse customer identifier from the messageparsed_info = structured_llm.invoke([SystemMessage(content=structured_system_prompt)] + [user_input])# Extract the identifier from parsed responseidentifier = parsed_info.identifier# Initialize customer_id as emptycustomer_id = ""# Attempt to find the customer ID using the provided identifierif (identifier):customer_id = get_customer_id_from_identifier(identifier)# If customer found, confirm verification and set customer_id in stateif customer_id != "":intent_message = SystemMessage(content= f"Thank you for providing your information! I was able to verify your account with customer id {customer_id}.")return {"customer_id": customer_id,"messages" : [intent_message]}else:# If customer not found, ask for correct informationresponse = llm.invoke([SystemMessage(content=system_instructions)]+state['messages'])return {"messages": [response]}else:# Customer already verified, no action neededpass
所以这个verify_info节点首先检查customer_id是否已在状态中。如果没有,它会使用structured_llm从user_input中提取一个标识符,并使用get_customer_id_from_identifier对其进行验证。
如果有效,它会更新状态并以消息确认。如果无效,它会使用主大语言模型和系统指令,礼貌地向用户询问其信息。
现在,我们来创建 human_input 节点。该节点充当一个占位符,在图中触发 interrupt(),暂停执行以等待用户输入。这对于人在回路的交互至关重要,它使智能体能够直接请求缺失的信息。
from langgraph.types import interruptdef human_input(state: State, config: RunnableConfig):"""Human-in-the-loop node that interrupts the workflow to request user input.This node creates an interruption point in the workflow, allowing the systemto pause and wait for human input before continuing. It's typically usedfor customer verification or when additional information is needed.Args:state (State): Current state containing messages and workflow dataconfig (RunnableConfig): Configuration for the runnable executionReturns:dict: Updated state with the user's input message"""# Interrupt the workflow and prompt for user inputuser_input = interrupt("Please provide input.")# Return the user input as a new message in the statereturn {"messages": [user_input]}
interrupt()函数是LangGraph的一项强大功能。执行该函数时,它会暂停图的执行,并表明需要人工干预。
`run_graph`函数(我们稍后会对其进行更新以用于评估)需要通过提供新的输入来恢复图形,从而处理此中断。
现在,我们只需要把这些整合起来。我们定义一个新的条件边(should_interrupt),如果 customer_id 尚未验证,则该边会导向 human_input 节点。
否则,它允许流程继续流向主监督智能体。
# Conditional edge: should_interrupt
def should_interrupt(state: State, config: RunnableConfig):"""Determines whether the workflow should interrupt and ask for human input.If the customer_id is present in the state (meaning verification is complete),the workflow continues. Otherwise, it interrupts to get human input for verification."""if state.get("customer_id") is not None:return "continue" # Customer ID is verified, continue to the next step (supervisor)else:return "interrupt" # Customer ID is not verified, interrupt for human input
现在,让我们将这些新的节点和边整合到我们的总图中:
# Create a new StateGraph instance for the multi-agent workflow with verification
multi_agent_verify = StateGraph(State)# Add new nodes for customer verification and human interaction
multi_agent_verify.add_node("verify_info", verify_info)
multi_agent_verify.add_node("human_input", human_input)
# Add the existing supervisor agent as a node
multi_agent_verify.add_node("supervisor", supervisor_prebuilt)# Define the graph's entry point: always start with information verification
multi_agent_verify.add_edge(START, "verify_info")# Add a conditional edge from verify_info to decide whether to continue or interrupt
multi_agent_verify.add_conditional_edges("verify_info",should_interrupt, # The function that checks if customer_id is verified{"continue": "supervisor", # If verified, proceed to the supervisor"interrupt": "human_input", # If not verified, interrupt for human input},
)
# After human input, always loop back to verify_info to re-attempt verification
multi_agent_verify.add_edge("human_input", "verify_info")
# After the supervisor completes its task, the workflow ends
multi_agent_verify.add_edge("supervisor", END)# Compile the complete graph with checkpointer and long-term memory store
multi_agent_verify_graph = multi_agent_verify.compile(name="multi_agent_verify",checkpointer=checkpointer,store=in_memory_store
)# Display the updated graph structure
show_graph(multi_agent_verify_graph)
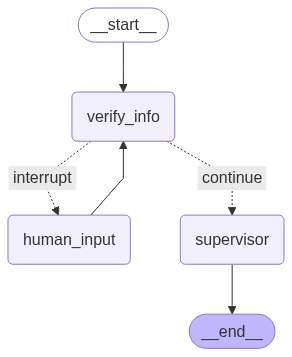
添加人工介入环节(由 法里德·汗 创建)
新的流程图从verify_info开始。如果验证成功,流程将进入supervisor。如果验证失败,流程将转至human_input,这将中断流程并等待用户输入。
一旦提供了输入,它会循环回到verify_info再次尝试。supervisor是到达END之前的最后处理步骤。show_graph函数将以可视化方式显示此验证循环。
咱们来测试一下!首先,我们会在不提供任何身份信息的情况下提出一个问题。
thread_id = uuid.uuid4()
question = "How much was my most recent purchase?"
config = {"configurable": {"thread_id": thread_id}}result = multi_agent_verify_graph.invoke({"messages": [HumanMessage(content=question)]}, config=config)
for message in result["messages"]:message.pretty_print()### OUTPUT ###
======== Human Message =======How much was my most recent purchase?======== Ai Message ==========Before I can look up your most recent purchase,
I need to verify your identity. Could you please provide your
customer ID, email, or phone number associated with your account?
This will help me to access your information and assist you
with your query.
不出所料,智能体将中断并询问您的客户ID、电子邮件或电话号码,因为在状态中,customer_id最初为 None。
现在,让我们继续对话并提供所需信息。LangGraph invoke 方法可以接受一个 Command(resume=...) 以从中断处恢复。
from langgraph.types import Command# Resume from the interrupt, providing the phone number for verification
question = "My phone number is +55 (12) 3923-5555."
result = multi_agent_verify_graph.invoke(Command(resume=question), config=config)
for message in result["messages"]:message.pretty_print()### OUTPUT ###
======= Human Message =========How much was my most recent purchase?=========== Ai Message =======
Before I can look up your most recent purchase, I need to verify your identity. Could you please provide your customer ID, email, or phone number associated with your account? This will help me to access your information and assist you with your query.========== Human Message ===========My phone number is +55 (12) 3923-5555.============ System Message =======Thank you for providing your information! I was able to verify your account with customer id 1.========== Ai Message ==========
Name: supervisor{"type": "function", "function": {"name": "transfer_to_invoice_information_subagent", "parameters": {}}}
用户提供电话号码后,verify_info节点成功识别出customer_id(在Chinook数据库中,该号码对应的1为1)。
它确认验证,并按照我们图表中的定义,将控制权传递给supervisor,然后由监管程序对原始查询进行路由。
这证实了我们的人工介入验证机制按预期运行!
LangGraph状态管理的一个关键优势在于,一旦customer_id得到验证并保存到状态中,它将在整个对话过程中持续存在。
这意味着在同一对话线程的后续问题中,智能体不会再次要求进行验证。
让我们通过在不重新提供ID的情况下提出后续问题来测试这种持久性:
question = "What albums do you have by the Rolling Stones?"
result = multi_agent_verify_graph.invoke({"messages": [HumanMessage(content=question)]}, config=config)
for message in result["messages"]:message.pretty_print()### OUTPUT ###
=== Human Message ===
How much was my most recent purchase?=== Ai Message ===
Before I can look up your most recent purchase, I need to verify your identity. Could you please provide your customer ID, email, or phone number associated with your account?=== Human Message ===
My phone number is +55 (12) 3923-5555.=== System Message ===
Thank you for providing your information! I was able to verify your account with customer id 1.=== Ai Message ===
Name: supervisor
{"type": "function", "function": {"name": "transfer_to_invoice_information_subagent", "parameters": {}}}=== Human Message ===
What albums do you have by the Rolling Stones?=== Ai Message ===
Name: supervisor
{"type": "function", "function": {"name": "transfer_to_music_catalog_subagent", "parameters": {}}}
请注意,verify_info 节点不会再次提示进行身份验证。由于 state.get("customer_id") 已设置为 1,它会立即跳转到 supervisor,后者会将查询路由到 music_catalog_subagent。
这表明了状态是如何维护上下文并避免重复步骤,从而提升用户体验的。
添加长期记忆
我们已经在“设置短期和长期记忆”一节中为长期记忆初始化了内存存储。
长期记忆(源自LangChain - 开源项目)
现在,是时候将它完全整合到我们的多智能体工作流程中了。长期记忆非常强大,因为它能让智能体回忆并利用以往对话中的信息,随着时间推移,实现更个性化、更具情境感知的交互。
在这一步中,我们添加两个新节点来处理长期记忆:
- load_memory(加载记忆)会在对话开始时(验证之后)从
in_memory_store(内存存储)中检索用户现有的偏好设置。 - create_memory会将用户在对话过程中分享的任何新音乐兴趣保存到
in_memory_store中,以供日后使用。
首先,有一个辅助函数,用于将用户存储的音乐偏好格式化为可读字符串,该字符串可轻松插入到大语言模型的提示中。
from langgraph.store.base import BaseStore# Helper function to format user memory data for LLM prompts
def format_user_memory(user_data):"""Formats music preferences from users, if available."""# Access the 'memory' key which holds the UserProfile objectprofile = user_data['memory']result = ""# Check if music_preferences attribute exists and is not emptyif hasattr(profile, 'music_preferences') and profile.music_preferences:result += f"Music Preferences: {', '.join(profile.music_preferences)}"return result.strip()# Node: load_memory
def load_memory(state: State, config: RunnableConfig, store: BaseStore):"""Loads music preferences from the long-term memory store for a given user.This node fetches previously saved user preferences to provide contextfor the current conversation, enabling personalized responses."""# Get the user_id from the configurable part of the config# In our evaluation setup, we might pass user_id via configuser_id = config["configurable"].get("user_id", state["customer_id"]) # Use customer_id if user_id not in config# Define the namespace and key for accessing memory in the storenamespace = ("memory_profile", user_id)key = "user_memory"# Retrieve existing memory for the userexisting_memory = store.get(namespace, key)formatted_memory = ""# Format the retrieved memory if it exists and has contentif existing_memory and existing_memory.value:formatted_memory = format_user_memory(existing_memory.value)# Update the state with the loaded and formatted memoryreturn {"loaded_memory": formatted_memory}
load_memory节点使用user_id(来自配置或状态)构建一个命名空间键,并从in_memory_store中获取现有的user_memory。
它对这段记忆进行格式化,并更新状态中的 loaded_memory 字段。然后,按照 generate_music_assistant_prompt 中的设置,这段记忆会被包含在 music_assistant 提示中。
接下来,我们需要一个Pydantic模式来构建用户资料,以便保存到内存中。
# Pydantic model to define the structure of the user profile for memory storage
class UserProfile(BaseModel):customer_id: str = Field(description="The customer ID of the customer")music_preferences: List[str] = Field(description="The music preferences of the customer")
现在,我们定义create_memory节点。该节点将采用“大语言模型作为评判者”的模式,分析对话历史和现有记忆,然后用新识别出的音乐兴趣更新UserProfile。
# Prompt for the create_memory agent, guiding it to update user memory
create_memory_prompt = """You are an expert analyst that is observing a conversation that has taken place between a customer and a customer support assistant. The customer support assistant works for a digital music store, and has utilized a multi-agent team to answer the customer's request.
You are tasked with analyzing the conversation that has taken place between the customer and the customer support assistant, and updating the memory profile associated with the customer. The memory profile may be empty. If it's empty, you should create a new memory profile for the customer.You specifically care about saving any music interest the customer has shared about themselves, particularly their music preferences to their memory profile.To help you with this task, I have attached the conversation that has taken place between the customer and the customer support assistant below, as well as the existing memory profile associated with the customer that you should either update or create.The customer's memory profile should have the following fields:
- customer_id: the customer ID of the customer
- music_preferences: the music preferences of the customerThese are the fields you should keep track of and update in the memory profile. If there has been no new information shared by the customer, you should not update the memory profile. It is completely okay if you do not have new information to update the memory profile with. In that case, just leave the values as they are.*IMPORTANT INFORMATION BELOW*The conversation between the customer and the customer support assistant that you should analyze is as follows:
{conversation}The existing memory profile associated with the customer that you should either update or create based on the conversation is as follows:
{memory_profile}Ensure your response is an object that has the following fields:
- customer_id: the customer ID of the customer
- music_preferences: the music preferences of the customerFor each key in the object, if there is no new information, do not update the value, just keep the value that is already there. If there is new information, update the value.Take a deep breath and think carefully before responding.
"""
所以我们已经定义了记忆提示。现在来创建记忆节点函数。
# Node: create_memory
def create_memory(state: State, config: RunnableConfig, store: BaseStore):"""Analyzes conversation history and updates the user's long-term memory profile.This node extracts new music preferences shared by the customer during theconversation and persists them in the InMemoryStore for future interactions."""# Get the user_id from the configurable part of the config or from the stateuser_id = str(config["configurable"].get("user_id", state["customer_id"]))# Define the namespace and key for the memory profilenamespace = ("memory_profile", user_id)key = "user_memory"# Retrieve the existing memory profile for the userexisting_memory = store.get(namespace, key)# Format the existing memory for the LLM promptformatted_memory = ""if existing_memory and existing_memory.value:existing_memory_dict = existing_memory.value# Ensure 'music_preferences' is treated as a list, even if it might be missing or Nonemusic_prefs = existing_memory_dict.get('music_preferences', [])if music_prefs:formatted_memory = f"Music Preferences: {', '.join(music_prefs)}"# Prepare the system message for the LLM to update memoryformatted_system_message = SystemMessage(content=create_memory_prompt.format(conversation=state["messages"],memory_profile=formatted_memory))# Invoke the LLM with the UserProfile schema to get structured updated memoryupdated_memory = llm.with_structured_output(UserProfile).invoke([formatted_system_message])# Store the updated memory profilestore.put(namespace, key, {"memory": updated_memory})
create_memory节点从存储中检索当前用户记忆,对其进行格式化,然后将其与完整对话(state["messages"])一起发送给大语言模型。
大语言模型(LLM)将新的音乐偏好提取到一个UserProfile对象中,并将其与现有数据合并。然后,使用store.put()将更新后的内存数据保存回in_memory_store。
让我们将记忆节点整合到我们的图中:
load_memory节点在验证之后立即运行,以加载用户偏好设置。create_memory节点恰好在图结束前运行,保存所有更新内容。
这确保了在每次交互开始时加载记忆,并在结束时保存记忆。
multi_agent_final = StateGraph(State)# Add all existing and new nodes to the graphmulti_agent_final.add_node("verify_info", verify_info)
multi_agent_final.add_node("human_input", human_input)
multi_agent_final.add_node("load_memory", load_memory)
multi_agent_final.add_node("supervisor", supervisor_prebuilt) # Our supervisor agent
multi_agent_final.add_node("create_memory", create_memory)# Define the graph's entry point: always start with information verificationmulti_agent_final.add_edge(START, "verify_info")# Conditional routing after verification: interrupt if needed, else load memorymulti_agent_final.add_conditional_edges(
"verify_info",
should_interrupt, # Checks if customer_id is verified
{
"continue": "load_memory", # If verified, proceed to load long-term memory
"interrupt": "human_input", # If not verified, interrupt for human input
},
)# After human input, loop back to verify_infomulti_agent_final.add_edge("human_input", "verify_info")# After loading memory, pass control to the supervisormulti_agent_final.add_edge("load_memory", "supervisor")# After supervisor completes, save any new memorymulti_agent_final.add_edge("supervisor", "create_memory")# After creating/updating memory, the workflow endsmulti_agent_final.add_edge("create_memory", END)# Compile the final graph with all componentsmulti_agent_final_graph = multi_agent_final.compile(
name="multi_agent_verify",
checkpointer=checkpointer,
store=in_memory_store
)# Display the complete graph structureshow_graph(multi_agent_final_graph)
我们的长记忆集成智能体可视化效果如下:
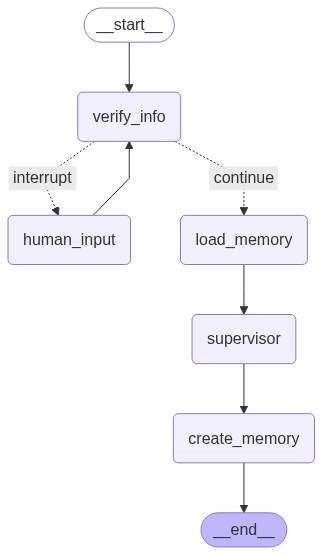
长记忆多智能体流程
show_graph 的输出现在展示了完整、复杂的工作流程:开始 -> verify_info(如有需要,循环至 human_input) -> load_memory -> supervisor(在内部协调子智能体) -> create_memory -> 结束。
这种架构结合了验证、多智能体路由和长期个性化。
测试我们的长期记忆多智能体
让我们测试这个完全集成的图表!我们将给它一个复杂的查询,包括用于验证的标识符和要保存的音乐偏好。
thread_id = uuid.uuid4()question = "My phone number is +55 (12) 3923-5555. How much was my most recent purchase? What albums do you have by the Rolling Stones?"
config = {"configurable": {"thread_id": thread_id}}result = multi_agent_final_graph.invoke({"messages": [HumanMessage(content=question)]}, config=config)
for message in result["messages"]:message.pretty_print()
现在让我们看看与我们的智能体的对话会如何进行。
=== Human Message ===My phone number is +55 (12) 3923-5555. How much was my most recent purchase? What albums do you have by the Rolling Stones?=== System Message ===Thank you for providing your information! I was able to verify your account with customer id 1.=== Ai Message ===Name: supervisor
Tool Calls:
transfer_to_invoice_information_subagent=== Tool Message ===Name: transfer_to_invoice_information_subagentSuccessfully transferred to invoice_information_subagent=== Ai Message ===Name: invoice_information_subagentYour most recent purchase was on August 7, 2025, and the total amount was $8.91. I am unable to provide information about albums by the Rolling Stones. Would you like to search for something else?=== Ai Message ===Name: invoice_information_subagent
Tool Calls:
transfer_back_to_supervisor=== Tool Message ===Name: transfer_back_to_supervisorSuccessfully transferred back to supervisor=== Ai Message ===Name: supervisor
Tool Calls:
transfer_to_music_catalog_subagent=== Tool Message ===Name: transfer_to_music_catalog_subagentSuccessfully transferred to music_catalog_subagent=== Ai Message ===The Rolling Stones have several albums available, including "Hot Rocks, 1964-1971 (Disc 1)", "No Security", and "Voodoo Lounge". Would you like to explore more music or purchase one of these albums?=== Ai Message ===Name: music_catalog_subagent
Tool Calls:
transfer_back_to_supervisor=== Tool Message ===Name: transfer_back_to_supervisorSuccessfully transferred back to supervisor=== Ai Message ===Name: supervisorIs there anything else I can help you with?
此交互展示了完整流程:
- 验证:
verify_info提取电话号码,获取customer_id = 1,并更新状态。 - 加载内存:
load_memory接下来运行。由于这很可能是第一个会话,它加载“无”。 - 主管路由: 主管根据需要将查询路由到
invoice_information_subagent和music_catalog_subagent。 - 创建记忆: 在收到关于 “滚石乐队” 的回复后,
create_memory会分析对话,将该乐队识别为新的偏好,并将其保存到in_memory_store中,customer_id = 1。
这个流程纯粹是展示我们的智能体如何处理长期记忆,但实际上我们来看看这个记忆。
我们可以直接访问in_memory_store,以检查音乐偏好是否已保存。
user_id = "1" # Assuming customer ID 1 was used in the previous interaction
namespace = ("memory_profile", user_id)
memory = in_memory_store.get(namespace, "user_memory")# Access the UserProfile object stored under the "memory" key
saved_music_preferences = memory.value.get("memory").music_preferencesprint(saved_music_preferences)### OUTPUT ###
['Rolling Stones']
输出 ['Rolling Stones'] 证实了我们的 create_memory 节点已成功提取用户的音乐偏好并将其保存到长期记忆中。
在未来的交互中,可以通过 load_memory 加载此信息,以提供更具个性化的回复。
评估我们的多智能体系统
评估 有助于衡量智能体的表现,这一点至关重要,因为即使提示或模型发生微小变化,大语言模型(LLM)的行为也可能有所不同。评估为发现失误、比较版本以及提高可靠性提供了一种结构化的方法。
评估由3部分组成:
- **数据集:**一组测试输入和预期输出。
- **目标函数:**你正在测试的应用程序或智能体;它接受输入并返回输出。
- **评估器:**对智能体输出进行评分的工具。
以及一些常见的智能体评估类型:
- **最终回复:**检查智能体给出的最终答案是否正确。
- **单步:**评估单个步骤(例如,是否选择了正确的工具?)
- **推理轨迹:**评估智能体得出答案所采用的完整推理路径。
评估一个智能体最直接的方法之一,是衡量其在一项任务上的整体表现。
这就好比将智能体视为一个**“黑匣子”**,只评估其最终回复是否成功解决了用户的查询并满足预期标准。
- **输入**:用户的初始查询。
- **输出**:智能体最终生成的回复。
首先,我们需要一个包含问题及其相应预期(真实)最终回答的数据集。这个数据集将作为我们评估的基准。我们将使用langsmith.Client来创建并上传这个数据集。
from langsmith import Clientclient = Client()# Define example questions and their expected final responses for evaluation
examples = [{"question": "My name is Aaron Mitchell. My number associated with my account is +1 (204) 452-6452. I am trying to find the invoice number for my most recent song purchase. Could you help me with it?","response": "The Invoice ID of your most recent purchase was 342.",},{"question": "I'd like a refund.","response": "I need additional information to help you with the refund. Could you please provide your customer identifier so that we can fetch your purchase history?",},{"question": "Who recorded Wish You Were Here again?","response": "Wish You Were Here is an album by Pink Floyd", # Note: The model might return more details, but this is the core expected fact.},{"question": "What albums do you have by Coldplay?","response": "There are no Coldplay albums available in our catalog at the moment.",},
]dataset_name = "LangGraph 101 Multi-Agent: Final Response"# Check if the dataset already exists to avoid recreation errors
if not client.has_dataset(dataset_name=dataset_name):dataset = client.create_dataset(dataset_name=dataset_name)client.create_examples(inputs=[{"question": ex["question"]} for ex in examples],outputs=[{"response": ex["response"]} for ex in examples],dataset_id=dataset.id)
现在我们定义四个示例场景,每个场景都有一个问题(我们智能体的输入)和一个预期响应(我们认为正确的最终输出)。
然后,它会在LangSmith中创建一个数据集,并将这些示例填充到该数据集中。
接下来,我们定义一个目标函数,该函数概括了我们的智能体(multi_agent_final_graph)应如何运行以进行评估。
该函数将以我们数据集中的问题作为输入,并返回智能体最终生成的回复。
import uuid
from langgraph.types import Commandgraph = multi_agent_final_graphasync def run_graph(inputs: dict):"""Run the multi-agent graph workflow and return the final response.This function handles the complete workflow including:1. Initial invocation with user question2. Handling human-in-the-loop interruption for customer verification3. Resuming with customer ID to complete the requestArgs:inputs (dict): Dictionary containing the user's questionReturns:dict: Dictionary containing the final response from the agent"""# Create a unique thread ID for this conversation sessionthread_id = uuid.uuid4()configuration = {"thread_id": thread_id, "user_id": "10"}# Initial invocation of the graph with the user's question# This will trigger the verification process and likely hit the interruptresult = await graph.ainvoke({"messages": [{"role": "user", "content": inputs['question']}]}, config=configuration)# Resume from the human-in-the-loop interrupt by providing customer ID# This allows the workflow to continue past the verification stepresult = await graph.ainvoke(Command(resume="My customer ID is 10"),config={"thread_id": thread_id, "user_id": "10"})# Return the final response content from the last messagereturn {"response": result['messages'][-1].content}
现在,我们来定义如何运行我们的图。请注意,我们必须通过向图提供一个Command(resume="")来继续执行,以越过interrupt()。
from openevals.llm import create_llm_as_judge
from openevals.prompts import CORRECTNESS_PROMPT# Using Open Eval pre-built
correctness_evaluator = create_llm_as_judge(prompt=CORRECTNESS_PROMPT,feedback_key="correctness",judge=llm
)
我们也可以像这样定义自己的评估器。
# Custom definition of LLM-as-judge instructions
grader_instructions = """You are a teacher grading a quiz.You will be given a QUESTION, the GROUND TRUTH (correct) RESPONSE, and the STUDENT RESPONSE.Here is the grade criteria to follow:
(1) Grade the student responses based ONLY on their factual accuracy relative to the ground truth answer.
(2) Ensure that the student response does not contain any conflicting statements.
(3) It is OK if the student response contains more information than the ground truth response, as long as it is factually accurate relative to the ground truth response.Correctness:
True means that the student's response meets all of the criteria.
False means that the student's response does not meet all of the criteria.Explain your reasoning in a step-by-step manner to ensure your reasoning and conclusion are correct."""# LLM-as-judge output schema
class Grade(TypedDict):"""Compare the expected and actual answers and grade the actual answer."""reasoning: Annotated[str, ..., "Explain your reasoning for whether the actual response is correct or not."]is_correct: Annotated[bool, ..., "True if the student response is mostly or exactly correct, otherwise False."]# Judge LLM
grader_llm = llm.with_structured_output(Grade, method="json_schema", strict=True)# Evaluator function
async def final_answer_correct(inputs: dict, outputs: dict, reference_outputs: dict) -> bool:"""Evaluate if the final response is equivalent to reference response."""# Note that we assume the outputs has a 'response' dictionary. We'll need to make sure# that the target function we define includes this key.user = f"""QUESTION: {inputs['question']}GROUND TRUTH RESPONSE: {reference_outputs['response']}STUDENT RESPONSE: {outputs['response']}"""grade = await grader_llm.ainvoke([{"role": "system", "content": grader_instructions}, {"role": "user", "content": user}])return grade["is_correct"]
我们可以使用大语言模型(LLM)作为评判者,来评判我们的事实依据与智能体回应之间的差异。既然我们已经整理好了所有内容,那就开始进行评估吧。
# Run the evaluation experiment
# This will test our multi-agent graph against the dataset using both evaluators
experiment_results = await client.aevaluate(run_graph, # The application function to evaluatedata=dataset_name, # Dataset containing test questions and expected responsesevaluators=[final_answer_correct, correctness_evaluator], # List of evaluators to assess performanceexperiment_prefix="agent-result", # Prefix for organizing experiment results in LangSmithnum_repetitions=1, # Number of times to run each test casemax_concurrency=5, # Maximum number of concurrent evaluations
)
当你运行此命令且评估完成后,它将输出包含我们结果的LangSmith仪表板页面。我们来看看吧。

LangSmith 仪表盘结果
我们的LangSmith仪表板包含评估结果,展示了诸如正确性、最终结果、结果对比等参数。
还有其他评估技术也可以使用,你可以在笔记本中找到更详细的内容,一定要查看一下!
群体与监督者
到目前为止,我们已经使用监督者方法构建了一个多智能体系统,其中一个中央智能体管理流程并将任务委派给子智能体。
另一种选择是《语言图谱》(LangGraph)文档中所述的“群体架构”。在群体中,智能体相互协作,直接在彼此之间传递任务,无需中央协调器。
在GitHub笔记本中,你也可以找到集群架构,但请看一下集群与管理器之间的比较。
- 监督者:具有一个中央智能体,该智能体指挥信息流,充当专门子智能体的 “老板”。
- 群体:由对等智能体组成,这些智能体在没有中央机构的情况下直接相互交接任务。
- 监督者流程:遵循分层且更具可预测性的路径,控制权通常会返回给监督者。
- 群体流:具有去中心化和智能体驱动的特点,支持直接的、自适应的协作,并有可能实现更具弹性的运作。