合成来源图以在入侵检测系统中进行数据增强
大家觉得有帮助记得及时关注和点赞!!!
抽象
来源图分析通过揭示复杂的攻击模式,在入侵检测中发挥着至关重要的作用,尤其是针对高级持续性威胁 (APT) 的入侵检测。虽然最近的系统将图形神经网络 (GNN) 与自然语言处理 (NLP) 相结合来捕获结构和语义特征,但它们的有效性受到真实数据中类别不平衡的限制。为了解决这个问题,我们引入了 ProvSyn,这是一个自动化框架,它通过三阶段管道合成出处图:(1) 异构图结构合成与结构语义建模,
(2) 基于规则的拓扑细化,以及
(3) 使用大型语言模型 (LLM) 的上下文感知文本属性合成。
ProvSyn 包括一个全面的评估框架,该框架集成了基于结构、文本、时间和嵌入的指标,以及语义验证机制,用于评估生成的攻击模式和系统行为的正确性。为了展示实际效用,我们使用合成图来增强下游 APT 检测模型的训练数据集。实验结果表明,ProvSyn 生成高保真图,并通过有效的数据增强提高了检测性能。
1介绍
数据来源[29],它涉及记录数据修改、访问和使用的历史,是网络安全系统中用于跟踪攻击的关键工具[61].然而,随着系统规模的扩大,来源数据量急剧增加,给数据管理和分析带来了挑战。为了解决这个问题,研究人员已经开始使用图形结构来表示数据的来源,并应用图形机器学习算法来检测和跟踪入侵[21,62,53].这种方法有效地捕获了系统活动的复杂性,并支持检测传统方法难以识别的攻击,例如零日攻击和 APT 攻击。
来源数据集的质量在很大程度上决定了基于来源的入侵检测系统 (IDS) 的有效性。但是,可用的数据集非常少,能够准确描述系统中的良性和恶意活动的数据集更少。 一种可能的解决方案是生成捕获的系统日志 来自真实世界的场景。但是,使用此类数据集的主要缺点之一是隐私问题。在社区中共享此类数据集可能会导致关键隐私信息泄露,因此组织很难发布此类数据集。另一种解决方案是在实验环境中收集良性和恶意活动。例如,DARPA 透明计算 (TC)[2]计划贡献了网络安全社区中两个广泛使用的数据集,即 DARPA TC 数据集和 DARPA OpTC 数据集。然而,这样的数据集,虽然给了我们洞察力 到系统活动中,传达限制,其中之一是类不平衡问题[6],其中不太常见或代表性不足的程序行为采样不足。这种不平衡阻碍了在此类数据上训练的机器学习模型的泛化能力,从而限制了它们在看不见的环境中的有效性[77,9,76,6].
为了缓解数据不平衡的问题,一种常见的方法是合成高保真来源数据,以扩大少数类和模式的覆盖范围。这种数据合成可以通过图形生成模型或大型语言模型 (LLM) 等方法实现,但每种方法都有严重的局限性。一方面,大多数图形生成模型侧重于结构连接,不支持生成丰富的文本属性,而这些属性对于下游入侵检测任务至关重要[12,71,37,53].另一方面,尽管 LLM 擅长生成语义丰富的日志条目,但当转换为出处图时,它们的输出往往无法保留底层的图形结构[4,1].
为了克服这些挑战,我们提出了 ProvSyn,这是一个混合框架,它将图形生成模型的结构建模能力与 LLM 的文本生成能力相结合,以联合合成具有准确拓扑和有意义文本属性的来源图。 具体来说,ProvSyn 是一个三阶段综合框架,包括结构综合、拓扑细化和文本归属。初始阶段通过生成具有分类属性的节点和边来构建异构图拓扑。随后的结构优化应用特定于域的规则,以消除不合理的连接和隔离的实体。在第三阶段,使用 LLM 生成节点的文本属性。 但是,我们的框架的实施面临三个主要的技术挑战:
- •
可伸缩性到出处图。出处图是具有超过 10,000 个节点和边的异构图,而大多数异构图生成模型是为分子图设计的,通常在少于 100 个节点的图上进行训练[72,17].因此,有效地将为其他领域设计的图生成模型扩展到大规模的出处图仍然是一个挑战。
- •
文本属性综合。首先,LLM 本身就难以理解图形结构[33],需要将出处图转换为 LLM 可解释格式。其次,由于缺乏典型来源实体名称的先验知识,直接的 LLM 提示会产生简单、低多样性的输出。
- •
评估框架差距。缺乏多维评估框架阻碍了对合成图的全面评估,尤其是在验证生成的来源结构中攻击模式和系统行为的语义正确性时。
为了应对第一个挑战,我们采用了与域无关的异构图生成网络[17]以联合建模节点和边缘标签以及结构连接。为了使训练过程可扩展到大型图,我们采用基于重启的随机游走进行子图采样。通过一种新颖的重启机制,这种采样算法可以逃逸局部区域并捕获更能反映整体图结构的子图。
为了应对第二个挑战, 我们将图结构转换为深度优先搜索 (DFS) 序列,以增强 LLM 对图的理解。此外,我们还设计了两种不同的掩码策略,包括完全掩码和部分掩码,以构建一个用于微调 LLM 的训练集,从而为其提供来源图中实体名称的知识。
为了应对第三个挑战,我们设计了一个全面的框架,从五个角度评估保真度:结构、文本、时间、嵌入和语义正确性。对于结构保真度,我们采用了五个基于平均差异 (MMD) 的指标。对于文本保真度,我们使用标准的 NLP 指标,包括 BLEU、GLEU 和 ROUGE。对于时间保真度,我们使用序列比较指标,包括 Longest Common Subsequence (LCS) 和 Dynamic Time 翘曲 (DTW)。为了嵌入保真度,我们采用了各种嵌入方法,包括 DeepWalk 和 Doc2Vec。为了准确评估语义正确性(最具挑战性的方面),我们采用了基于模型的方法。具体来说,我们从真实的出处图中采样正三元组和负三元组,并使用对比学习来训练分类模型。
在实验中,我们使用我们提出的评估框架来评估由 LLM(包括 GPT-4o 和 Claude 3.7)以及 ProvSyn 合成的来源数据。结果表明,ProvSyn 实现了比这些强 LLM 更高的保真度。此外,通过生成 100% 新颖和 100% 多样化的图形,ProvSyn 有效地缓解了来源数据集中的数据不平衡问题。当应用于入侵检测系统时,在使用 ProvSyn 生成的图表增强的数据集上训练的模型在测试过程中表现出较低的假阳性率。
我们工作的主要贡献如下:
- •
我们提出了 ProvSyn,这是一个三阶段的出处图合成框架,能够构建具有丰富文本属性的高保真异构图。
- •
我们设计了一个全面的多维评估框架,用于评估合成的来源图的保真度,包括:结构、文本、时间、嵌入、语义正确性。
- •
我们通过合成新颖多样的来源图来缓解来源数据集中的数据不平衡问题,从而提高下游入侵检测模型的泛化能力。
- •
所提出的生成和评估框架也可以扩展到涉及异构信息网络 (HIN) 的其他领域,例如社交网络和引文网络。
2背景和动机
2.1Provenance Graphs 中的类不平衡
我们统计分析了四个常用的公共来源数据集中实体类型和事件类型的分布(见附录 A 图 3)。在数据集中,Cadets、Theia 和 Trace 是从 DARPA Engagement 3 和 Nodlink 收集的[37]是使用 Sysdig 在 Ubuntu 系统上收集的模拟来源数据。分布表现出典型的长尾模式,并揭示了严重的数据不平衡。在实体类型和事件类型中,单个类别占实例的 50% 以上,有时甚至超过 70%。相比之下,大多数其他品类的贡献率不到 20%,许多品类的份额低于 5%。这种不平衡进一步反映了大多数来源数据集中系统行为和攻击模式的分布不均匀。
类不平衡问题对基于学习的入侵检测构成了重大挑战[21,62,74,22,39].深度学习社区的先前研究表明,类不平衡对模型的分类性能及其泛化能力有不利影响[8,34].当部署在开放世界的分布式外 (OOD) 环境中时,在不平衡数据集上训练的检测模型可能会显著降低性能[67,25].因此,更平衡的数据集对于基于深度学习的基于来源的 IDS (PIDS) 实现最佳结果至关重要。然而,这个问题在很大程度上被社区忽视了,因为很少有研究考虑这个问题。
2.2现有方法的问题
为了缓解类不平衡,传统技术(如欠采样)[44]、过采样[47]和合成少数过度采样技术 (SMOTE)[9]已经被提议。但是,这些方法不适用于来源图数据。欠采样会打破系统实体之间的因果链,而过度采样不会增加良性活动的多样性,并且可能会导致过度拟合。SMOTE 依赖于特征空间中的线性插值,由于特征空间中不同类的分布重叠,因此无法应用于来源图。
增强出处数据集的另一种方法是利用图形生成模型来合成出处图形。但是,大多数现有模型主要侧重于在节点和边之间生成结构连接,而不支持其他节点或边属性[12,71].相比之下,来源图包含与节点和边缘相关的丰富文本属性,而文本属性是下游入侵检测系统的关键特征[37,53].然而,迄今为止,还没有一个图生成模型本身支持图结构和文本属性的联合生成。
随着大型语言模型的最新进展,它们在自然语言理解和生成方面的能力已得到广泛证明[4,1].这激发了对使用 LLM 合成出处数据的探索。具体来说,LLM 的任务是创建新的出处日志条目。这些生成的日志包含丰富的文本和语义信息。然而,当将 LLM 生成的日志转换为图形并使用基于图形的指标对其进行评估时,它们的结构保真度明显低于异构图形生成模型生成的图形(参见 Section 5.2 中的详细信息)。这表明,尽管当前的 LLM 在文本合成方面表现良好,但它们缺乏强大的合成准确的图拓扑和结构的能力。
为了解决这些限制,我们提出了 ProvSyn,这是一个框架,它集成了用于结构合成的图形生成模型和用于文本属性生成的大型语言模型的互补优势。
3相关工作
基于来源的入侵检测系统基于来源的检测方法可分为三大类[74]:基于规则、基于统计和基于学习的技术。基于规则的方法[24,46,28]依靠从已知攻击模式派生的预定义启发式方法来识别恶意活动。基于统计数据[23,61,45]方法通过测量其统计异常来分析出处图元素中的偏差。基于学习的技术采用深度学习模型来捕获正常的系统行为[21,62]或恶意模式[41,74,39],将 APT 检测视为分类[39]或异常检测任务[74,22].这些基于学习的方法进一步分支为基于序列的方法[41],它们专注于执行工作流程和基于图形的[21,62,74,22,39]方法,这些方法使用图形神经网络对实体关系进行建模并检测行为异常。
网络流量增强为了解决网络流量数据集中的类不平衡问题,其中一项工作应用了采样技术。江 et al.[32]采用单侧选择去除多数噪声样品并应用 SMOTE[9]来增强少数实例。Liu 等人。[42]提出了困难集抽样技术来提高样本代表性。另一条研究线探索了使用深度学习生成合成网络流量。生成模型,尤其是 GAN,已用于各种场景,包括基于流的流量[55]、纵流量[11]和社交媒体流量[54]、解决实际流量合成中的挑战[5].
LLM 驱动的合成数据生成基于 LLM 的合成数据生成方法可分为三种主要类型:基于提示工程的方法[16,20,57,43,70,38,68],它利用任务描述、条件值提示和上下文示例来指导生成;基于生成的多步骤方法[64,15,14,63,27],它在样本或数据集级别分解复杂任务;和知识增强方法[50,10,30],其中包含外部知识(如知识图谱或 Web 源)以提高输出的事实质量。合成数据的评估包括两个直接指标,用于衡量忠诚度[36]和多样性[73]和间接指标,通过基准测试评估下游任务的性能[58]以及使用人工的开放式评估[26]或基于模型[65]方法。
4ProvSyn 设计
我们分三个阶段实现出处图的生成。在第一阶段,我们使用真实的出处图数据集训练一个异构图生成模型,以产生图结构。之后,我们应用基于规则的后处理来删除无效的边和隔离的节点。在第三阶段,我们微调一个大型语言模型,以使用适当的名称标记节点。
4.1问题定义
系统审计日志数据集可以表示为来源图,其中节点对应于系统实体,有向边缘表示系统事件。从形式上讲,出处图是有向异构图G=(V,E),其中每个节点v我∈V与类型t我=f(v我)和一个名称n我=h(v我)和每条边e我∈E与类型l我=g(e我).每个系统事件都表示为一个标记的 5 元组:
![]()
哪里t我和tj表示源节点和目标节点的类型,n我和nj表示他们的名字,以及l我表示边类型。ProvSyn 将从真实的系统审计数据中学习此类来源图的分布,从而能够生成保留原始数据集的结构和语义属性的合成图。生成的图形也是异构的,具有不同的节点和边缘类型,并且每个节点都分配有一个详细的名称。
ProvSyn 的目标有三个:(1) 合成高保真出处图。这是我们的主要目标,因为高质量的来源数据对于训练可靠的检测模型至关重要;(2) 缓解现有来源图数据集中的数据不平衡。ProvSyn 旨在了解真实世界数据的基本分布并生成代表代表性不足的场景的样本,从而提高数据多样性;(3) 提高下游入侵检测系统的性能。通过使用 ProvSyn 生成的图形来增强现有数据集,可以扩大系统行为的覆盖范围,从而提高 IDS 模型的泛化性和稳健性。
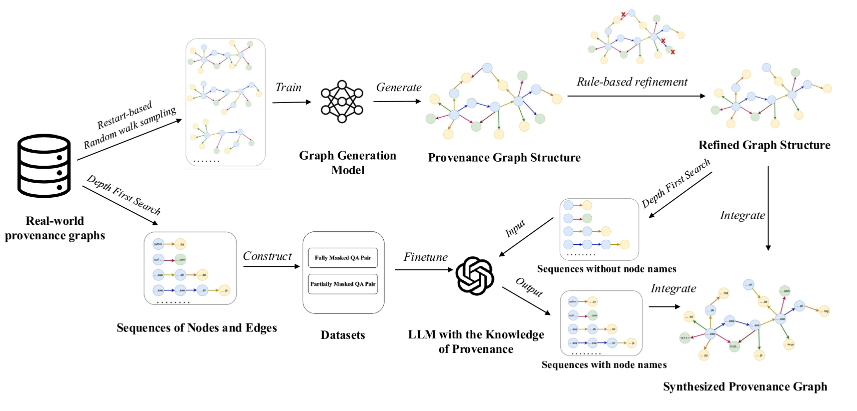
图 1:ProvSyn 体系结构。首先,采用异构图生成模型来生成出处图的初始结构。随后,根据预定义的规则优化图形的拓扑。最后,使用大型语言模型合成 Provenance Graph 中节点的文本属性。
4.2真实世界的 Provenance Graph 构造
我们首先解析每个日志条目以提取五个关键元素:源节点类型、源节点名称、目标节点类型、目标节点名称和边缘类型。这些元素用于构建有向来源图,其中每个节点都分配了两个属性(type 和 name),每条边都标有 type 属性。为避免重复,我们维护了一个由节点名称的 MD5 哈希编制索引的哈希表。
对于具有简单键值结构的日志格式,我们使用预定义的键直接提取这些元素。对于具有更复杂的实体和交互属性表示的格式,我们应用正则表达式来提取目标元素。提取节点名称特别具有挑战性;为了提高准确性,我们定义了针对每个节点类型量身定制的特定于类型的正则表达式,确保为每个节点提取有效的名称。
4.3图形结构生成
现有的图形生成模型主要关注结构连接性,通常忽略了节点和边缘标签的建模[12,71].许多方法还依赖于特定于领域的启发式方法(例如,为分子图量身定制的启发式方法),从而限制了它们在图类型中的泛化性[56].相比之下,出处图表示一类新的异构图,其中节点对应于系统实体(如进程、文件和网络组件),而边缘表示读取、写入、克隆和发送等关系。生成此类图形需要一个与域无关的模型,该模型可以捕获结构和标签信息。
为此,我们采用了 GraphGen[17],一个独立于域的图形生成框架,能够联合建模节点和边缘标签以及结构连接。GraphGen 使用最少的 DFS 代码将图形转换为序列,这是一种保留拓扑和语义的规范表示。训练基于长短期记忆 (LSTM) 的模型来学习这些序列的联合分布,从而能够以与域无关的方式生成标记的异构图。
但是,GraphGen 通常在具有大约 100 个节点的小图上进行训练,而来源图通常超过 10,000 个节点,因此无法将整个图馈送到模型中。为了使训练过程可扩展为大型图,我们采用随机游走采样策略来提取子图,然后可以使用这些子图来构建与 GraphGen 兼容的训练数据集。在采样期间,我们执行基于重启的随机游走。在每一步中,都有返回起始节点的概率;否则,将从当前节点的邻居中统一选择下一个节点。访问的节点及其连接边将动态添加到子图中。当达到预定义的迭代次数或子图超过允许的最大节点或边数时,游走将终止。每个起始节点的游走次数由其度数决定,计算公式为因素×度,确保 high-degree 节点生成更多的 subgraph。采样后,通过重新映射节点 ID 和删除自环来规范化每个子图。仅保留满足节点和边缘限制并保持连接的子图。我们之所以采用基于重启的随机游走进行子图采样,是因为它能够平衡局部探索和更广泛的图覆盖率。与容易被困在密集连接区域中的简单随机游走和通常混合缓慢并在异构图中引入采样偏差的 Metropolis-Hastings 随机游走不同,基于重启的随机游走会周期性地返回到起始节点。这种机制有助于它转义更好地反映整体图形结构的局部区域和样本子图。 算法 1 中介绍了完整的过程。
GraphGen 的训练过程包括将图形转换为最小的 DFS 代码,然后使用 LSTM 网络学习这些序列的分布。给定一个图形数据集𝒢={G1,G2,…,Gm}、每个图表G我首先转换为其最小 DFS 代码序列S我=F(G我)=[s1,s2,…,s|E我|]哪里|E我|表示图中的边数G我和每个st是一个边元组,表示t-DFS 遍历中的第 -th 条边。
每个边元组st定义为:
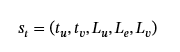
哪里tu和tv分别是源节点和目标节点的时间戳(DFS 索引);Lu和Lv分别是源节点和目标节点的标签;和Le是两个节点之间的 edge 的标签。
在每个时间步t中,LSTM 会更新其隐藏状态ht基于前一个边缘元组的嵌入st−1,然后预测下一个边缘元组的分布:
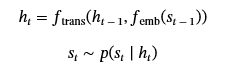
这里fEMB是将边元组映射到向量空间的嵌入函数,而f反式是由 LSTM 实现的转换函数。
训练目标是最小化整个数据集中预测边缘元组和真实边缘元组之间的二进制交叉熵 (BCE) 损失:
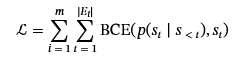
在推理过程中,GraphGen 使用经过训练的 LSTM 模型生成新图形。从初始隐藏状态开始h0和序列开始符号 SOS 时,模型会迭代生成最小 DFS 代码序列S=[s1,s2,…,s|E|].更新 hidden 状态并对下一个 Edge Tuples 进行采样的过程st与训练阶段相同。生成将继续,直到生成序列结束符号 EOS。生成的 DFS 代码序列S然后转换回图形G通过根据序列中的时间戳和标签重建边缘,生成生成的图形结构和标签。这种方法允许模型生成反映训练数据中存在的结构和语义模式的图形。
4.4基于规则的后处理
在第一阶段之后,我们得到一个无向异构图,其中节点和边都有不同的类型。但是,此图并不适合作为来源图结构,主要有两个原因。首先,出处图是自然有向的,而生成的图是无向的。其次,尽管在大型数据集上进行了训练,但异构图形生成模型偶尔会产生无效的连接,例如进程-读取-进程关系,这在实际场景中不会发生。
为了确保生成的出处图的保真度,我们实施了基于规则的后处理管道。首先,我们通过替换每条无向边,将无向图转换为有向图(u,v)具有两条有向边,(u,v)和(v,u).然后,我们删除违反特定于域的约束的边缘,例如不兼容的实体类型之间的连接或语义上无效的交互。最后,我们删除了因删除边缘而产生的所有孤立节点,因为这些节点不会出现在实际的来源图中。
后处理期间应用的特定于域的约束因数据集而异。例如,对于 Nodlink 数据集,约束条件如下:(1) 所有作都必须源自流程节点;(2) 文件作必须在文件节点处终止;(3) 流程作必须在流程节点处终止;(4) 网络作必须在网络或文件节点终止。对于 Cadets、Theia 和 Trace 数据集,约束条件为:(1) 非读取作必须源自进程节点;(2) 读取作(例如,读取、接收、加载)必须在进程节点处终止。
输入:图G=(V,E)、起始节点u∈V迭 代T、重启概率α=0.15、节点约束分钟_节点,麦克斯_节点、边缘约束分钟_边缘,麦克斯_边缘输出 : 有效子图 G采样或∅如果无效12 G采样←带节点的图形u(从G)3 当前←u45 为 t←1 自 T 做6 r∼均匀[0,1]7 如果 r<α 然后当前←u// 重启机制89 还10 v←的 随机邻居当前在G11 如果 v∉V(G采样) 然后12 加v自G采样(从G)1314 添加边(当前,v)自G采样(从G)15 当前←v1617 如果 |V(G采样)|≥麦克斯_节点 然后破// 已达到节点限制1819 如果 |E(G采样)|≥麦克斯_边缘 然后破// 已达到边缘限制2021从G采样22将节点重新标记为连续整数23 n←|V(G采样)|24 e←|E(G采样)|2526 如果 ¬is_connected(G采样) 或 n<分钟_节点 或 n>麦克斯_节点 或 e<分钟_边缘 或 e>麦克斯_边缘 然后返回 ∅// 子图无效27返回 G采样// 返回有效的子图28
算法 1:基于重启的随机游走子图采样
4.5文本属性生成
在前两个阶段之后,我们得到了一个有向异构图,其中不同类型的节点由不同类型的边连接,并且所有连接都符合预定义的规则。但是,此图表还不足以用作完整的 Provenance 图表。在实际场景中,节点通常带有详细的名称,例如命令行或文件路径。这些名称是必不可少的,因为许多基于来源的入侵检测方法依赖于使用自然语言处理技术从节点名称中提取的特征[53,37].因此,分配有意义的节点名称对于支持准确检测至关重要。
在第三阶段,我们利用大型语言模型的自然语言生成功能为出处图中的节点分配名称。此过程涉及两个主要挑战。首先,先前的研究表明,LLM 在理解图结构方面并不是天生有效的[33].因此,一个关键问题是如何将出处图的结构转换为更易于 LLM 解释的格式。其次,LLM 缺乏对出处图中典型节点名称的先验知识,直接提示它们通常会导致输出过于简单且多样性有限。
为了解决第一个挑战,以前的研究表明,LLM 在处理图形结构数据方面效果较差,但在基于序列的输入上表现良好[69].受此启发,我们提出了一种方法,使用深度优先搜索将有向异构图转换为节点和边缘类型的序列。然后将这些序列输入到 LLM 中,为相应的节点生成名称。具体来说,为了提取完整且不重叠的 DFS 路径,我们使用所有度数为零的节点作为 DFS 遍历的起点。但是,由于出处图中存在自循环,因此可能无法单独使用此策略捕获某些路径。为了解决这个问题,我们还将 self loop 中涉及的任何节点作为起点。在每个提取的序列中,一个节点表示为一对(τ我,n我)哪里τ我∈𝒯表示节点类型,n我∈𝒩节点名称。每条边ej表示相邻节点之间的交互类型。DFS 衍生的序列定义为:
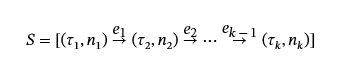
对于没有名称的节点,我们使用 [null] 作为占位符。在名称生成过程中,我们不会将所有序列并行输入到 LLM 中。这是因为节点可能出现在多个序列中,并行处理可能会导致分配的名称不一致。相反,我们按顺序将每个 DFS 衍生的序列提供给 LLM。生成节点名称后,该节点名称将填充到图形中,确保后续遍历可以检索更新后的名称。
为了解决第二个挑战,我们构建了一个训练数据集,为 LLM 提供有关来源数据中实体名称的先验知识。每个训练实例都是一个问答对,其中问题 (Q) 由节点和边缘类型的 DFS 序列组成,答案 (A) 是带有节点名称注释的相同序列。所有训练实例都源自真实世界的 Provenance 图。
为了生成真实的 Q&A 对,我们采用了一种掩码策略,该策略保留了结构上下文,同时要求模型推断节点名称。 在名称生成过程中,将两种类型的序列输入到 LLM 中。第一种类型由所有节点均未命名的序列组成,用作冷启动,并要求 LLM 仅根据节点和边缘类型的顺序推断节点名称。第二种类型包括一些节点已经命名的序列,要求 LLM 使用结构顺序和现有节点名称作为上下文来推断其余名称。因此,我们定义了两种相应的 Q&A 对格式:
完全屏蔽的 Q&A 对在此设置中,所有节点名称都用 [null] 掩码,同时保留节点类型和边缘类型,从而为冷启动名称生成创建模板。此设计鼓励模型学习映射f:(τ我,{τj,el}j=1k)→n我,同时通过节点和边缘类型的固定序列保持结构一致性。
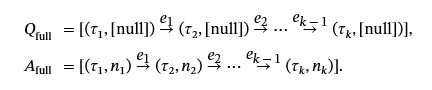
部分屏蔽的 Q&A 对为了模拟一些节点名称从先前上下文中已知的真实生成场景,我们随机屏蔽了一个子集ℳ⊂{1,…,k}具有掩码率的节点名称ρ:
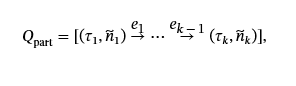
哪里
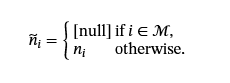
相应的答案序列一个部分=一个满提供对节点名称的完全监督。这种自适应掩码策略允许模型学习根据观察到的名称和结构上下文来预测掩码节点名称:
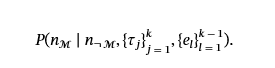
通过构建这两种类型的 QA 对,我们为 LLM 提供了一个全面的训练数据集,帮助它学习序列和节点名称之间的对应关系,从而提高其在来源图中生成准确节点名称的能力。这种方法在基于序列的任务中利用了 LLM 的优势,同时解决了图结构理解的挑战,从而在出处图中更有效地生成节点名称。
4.6语义正确性验证
评估语义正确性对于评估合成来源图的质量至关重要,因为它表明生成的图形是否准确反映了实际系统行为的底层逻辑和意图。此评估检查实体之间的关系和交互顺序是否符合有意义和有效的作模式。尽管语义正确性很重要,但由于缺乏标准化指标以及为各种动态系统活动定义真实语义的固有复杂性,评估语义正确性仍然很困难。
基于模型的评估机制。为了评估语义正确性,我们在图中正式定义一个语义单元为三元组:起始节点名称s、边类型e和结束节点名称t.此单位表示为(s,e,t)哪里s,t∈𝒩(所有节点名称的集合)和e∈ℰ(所有边类型的集合)。将这些元素连接起来形成一个自然语言句子,表示句(s,e,t).这句话捕获了实体之间交互的语义,表示源节点s执行e在目标节点上t.
为了评估句(s,e,t),我们采用 BERT(Bidirectional Encoder Representations from Transformers)[13]-来获取其嵌入。这种嵌入捕获了三元组描述的交互的语义表示,并作为后续基于分类的评估的基础。 正式地,让伯特:𝒮→ℝd是映射句子的编码函数句(s,e,t)∈𝒮(句子形式中所有可能的语义三元组的集合)转换为密集向量𝐯∈ℝd.嵌入的计算公式为:

但是,嵌入句(s,e,t)仅捕获成对语义关系,从而产生本地化评估。为了实现图级评估,我们采用了多层图注意力网络 (GAT)[60].此体系结构通过堆叠的自我注意层聚合邻域信息,其中每个层通过自适应加权来自相邻节点的特征来更新节点表示。我们使用 BERT 将单个节点的文本属性表示为初始节点嵌入。 正式地,对于每个节点vwith text 属性Tv、其初始嵌入𝐡v(0)是通过 BERT 派生的:
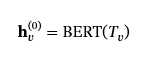
让GAT:𝒱→ℝd′表示将节点映射到其全局表示的编码器ℝd′使用这些初始嵌入。对于语义单元(s,e,t)中,我们获取两个起始节点的全局嵌入s和结束节点t:
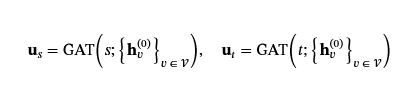
然后我们连接全局嵌入𝐮s和𝐮t使用本地嵌入𝐯以形成一个全面的表示形式:
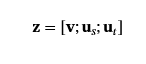
这个全面的表示𝐳捕获语义单元的本地和全局上下文。最后,我们喂食𝐳转换为多层感知器 (MLP) 判别器,以确定语义单元的正确性。MLP 判别器定义为MLP:𝐑d+2d′→[0,1].语义单元的正确性分数计算如下:
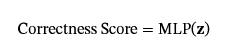
正确性分数是介于 0 和 1 之间的值,其中分数越高表示语义正确性越高。
基于对比学习的训练框架。为了训练 GAT 和 MLP 判别器,我们采用了对比学习方法。我们使用真实的出处图作为训练集,从中提取所有语义单元并将它们标记为正样本。此外,为了提供负样本进行对比学习,我们使用三种不同的策略从正样本中构建它们,以帮助分类器模型学习区分语义正确和不正确的实例。这些策略是:
主宾语反转 (SOI):我们交换起始节点和结束节点的名称。这会训练模型识别主语和宾语在语义上颠倒的情况。正式地,对于语义单位(s,e,t),我们通过反转主语和宾语来生成负样本:
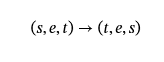
谓词替换 (PR):我们将 Edge 类型替换为另一种类型的 Edge。这会训练模型识别语义中的错误谓词。但是,在此方法中,将 edge 类型替换为另一种类型可能仍会导致语义正确的情况。为了保证构建的语义单元在语义上是不正确的,我们手动将边缘类型分类为不相交的类别。让ℰ=⋃我=1kℰ我将边类型的分区划分为k类别。替换边类型e∈ℰ我,我们确保新的 Edge 类型e′来自不同的类别,即e′∈ℰj哪里我≠j.对于语义单元(s,e,t),我们通过替换谓词来生成一个否定样本:
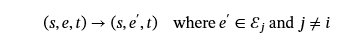
实体替换 (ES):我们将起始节点或结束节点的名称替换为另一个节点的名称。这会训练模型识别语义中出现不相关实体的情况。需要注意的是,在这种构造方法中,用语义三元组的一个元素替换另一个元素可能仍然会产生正确的语义。这是因为 replaced 元素和 new 元素可能相似。 因此,要构造负样本,我们首先使用 K-means 将节点名称聚类为不相交的聚类。让𝒱=⋃我=1m𝒱我将节点名称分区为m集群。替换节点名称s∈𝒱我或t∈𝒱我,我们选择一个节点s′∈𝒱j或t′∈𝒱j哪里我≠j.对于语义单元(s,e,t),我们通过替换主体或宾体来生成负样本:
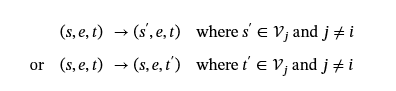
为了保持平衡的训练集,我们为真实图中的每个正样本生成一个负样本。具体来说,我们从三种策略 (SOI、PR、ES) 中随机选择一种来构建阴性样本。这可确保正样本和负样本各占训练数据的 50%。 对于确定每个三元组语义正确性的 MLP 判别器,我们采用二进制交叉熵损失。给定一批语义单元{(s我,e我,t我)}我=1N带有相应的标签y我∈{0,1},损失函数定义为:

5评估
为了全面评估 ProvSyn,我们解决了以下研究问题。在配备 Intel Xeon Silver CPU、128 GB RAM、NVIDIA RTX 3090 GPU 和 Ubuntu 22.04.4 LTS 的机器上进行了出处图结构生成的实验。文本属性合成实验是在配备 Intel Xeon Platinum CPU、512 GB RAM、NVIDIA RTX A6000 GPU 和 Ubuntu 22.04.3 LTS 的机器上进行的。研究问题是:
RQ1:合成出处图在结构、文本、时间和基于嵌入的特征方面的保真度如何?
RQ2:合成出处图的语义正确性如何?
RQ3:合成出处图能否缓解数据集中的类不平衡?
RQ4:当合成来源图用于下游入侵检测任务中的训练集增强时,检测任务的性能如何?
RQ5:生成合成出处图的时间和资源成本是多少?
我们研究的其他方面,包括超参数分析、消融研究,在附录 C D 中进行了广泛讨论。
5.1实验装置
数据。我们评估了 ProvSyn 对两个公共 数据集:Nodlink Ubuntu 数据[37]和 DARPA Engagement 3 数据集[2].Nodlink 数据集[37]我们使用的是使用 Sysdig 在 Ubuntu 20.04 上收集的模拟来源数据集。它提供良性日志和包含完整多阶段攻击链的攻击日志。表 I 显示了用于训练和评估的 Nodlink 来源图的详细统计数据。DARPA E3 数据集[2]作为 DARPA 透明计算计划的一部分,在对抗战期间从企业网络收集。APT 攻击由红队发起,而蓝队则试图通过主机审计和因果关系分析来检测它们。TRACE、THEIA 和 CADETS 子数据集包括在我们的评估中。对于 E3 数据集,我们使用来自 ThreaTrace 的标签。如表 I 所示,与 Nodlink 相比,E3 数据集具有更多的节点和边,并且在节点和边类型上也表现出更大的多样性。
表 I:数据集统计数据的比较。
| 数据 | 节点 | 边缘 | 节点类型 | 边缘类型 |
| 点头链接 | 16,818 | 30,531 | 3 | 13 |
| 学员 | 89,207 | 276,883 | 6 | 20 |
| 忒伊亚 | 77,071 | 202,517 | 3 | 14 |
| 跟踪 | 74,241 | 113,808 | 7 | 20 |
基线。在我们的方法中,我们首先使用异构图生成模型来构建出处图的结构,然后使用 LLM 来生成图的文本属性。相比之下,另一种方法直接调用 LLM 来合成出处日志,然后将这些日志转换为图形。此方法不需要额外的异构图生成模型。我们系统地评估和比较了这些强 LLM 合成的来源数据与 ProvSyn 合成的数据。
为了确保全面比较,我们选择了包含大参数闭源模型和较小参数开源模型的基线模型。对于大参数 LLM,我们选择了 GPT-4o[4]、克劳德 3.7 十四行诗[1]和 Doubao-pro-32k[3].对于较小参数的 LLM,我们选择了 Qwen2.5-7B-Instruct[66]和 Llama3.1-8B-指令[18].
为了使用上面列出的 LLM 生成来源日志,我们设计了结构化提示,其中包括任务描述、说明性示例和明确定义的输出格式。每个数据集都与自定义提示配对,主要区别在于提供的示例。这些示例格式为 JSON 或 TSV 条目,包含五个元素:源节点类型、源节点名称、目标节点类型、目标节点名称和边缘类型。它们是从真实的审计日志中挑选出来的,以确保各种节点和边缘类型的代表性和覆盖率。对于每个数据集,我们从每个 LLM 中收集了 100 份回复。获得响应后,我们逐行解析它们并筛选出不符合预期 JSON 或 TSV 格式的条目。我们还丢弃了包含预定义类型集之外的节点或边缘类型的条目。然后,使用剩余的条目构建出处图,以便与 ProvSyn 生成的图进行比较。
配置。为了训练异构图生成模型,我们使用随机游走策略从真实来源图中采样了 20,000 个子图。其中,16000 个子图用于训练,2000 个用于验证,2000 个用于测试。该模型训练了 3000 个 epoch,批量大小为 32,学习率为 0.003。训练后,我们选择了在验证集上实现最佳性能的模型,以便在 ProvSyn 中使用。例如,在 Theia 数据集上,性能最佳的模型是在 2380 个 epoch 后获得的,并用于最终的 ProvSyn 管道。
对于文本属性合成任务,我们使用 Llama3.2-3B-Instruct 作为基础模型。我们构建了一个包含 20,000 个样本的训练集,其中包括 10,000 个完全掩蔽的 QA 对和 10,000 个部分掩蔽的 QA 对。在训练期间,我们应用了 LoRA 微调方法,冻结了大部分模型参数,只更新了 0.81% 的参数。该模型训练了 60 个步骤,学习率为 2e-4。在推理过程中,温度设置为 1.5,生成的最大令牌数设置为 2048。
5.2保真度评估
表 II:不同模型和数据集的 MMD 指标比较。值越低表示性能越好。
| 数据 | 型 | 度 | 轨道 | 节点标签 | 边标签 | 节点标签和度数 |
| 点头链接 | GPT-4o 机器人 | 0.75 | 0.94 | 0.11 | 0.75 | 0.89 |
| 克劳德-3.7 | 0.56 | 0.85 | 0.07 | 0.92 | 0.77 | |
| 豆包-pro | 0.58 | 0.82 | 0.18 | 1.50 | 0.59 | |
| Qwen2.5-7B | 0.43 | 0.59 | 0.05 | 0.94 | 0.40 | |
| 骆驼3.1-8B | 0.62 | - | 0.10 | 0.91 | 0.81 | |
| ProvSyn | 0.07 | 0.07 | 0.002 | 0.01 | 0.07 | |
| 学员 | GPT-4o 机器人 | 0.82 | 0.28 | 0.37 | 0.90 | 0.48 |
| 克劳德-3.7 | 0.76 | 0.36 | 0.11 | 1.33 | 0.83 | |
| 豆包-pro | 0.73 | 0.25 | 0.27 | 1.31 | 0.66 | |
| Qwen2.5-7B | 0.76 | 0.39 | 0.67 | 0.77 | 0.33 | |
| 骆驼3.1-8B | 0.88 | 0.40 | 0.72 | 0.85 | 0.81 | |
| ProvSyn | 0.08 | 0.32 | 0.003 | 0.01 | 0.12 | |
| 忒伊亚 | GPT-4o 机器人 | 0.94 | 0.35 | 0.46 | 1.34 | 0.53 |
| 克劳德-3.7 | 0.92 | 0.85 | 0.18 | 1.44 | 0.81 | |
| 豆包-pro | 0.82 | 0.67 | 0.46 | 1.86 | 0.89 | |
| Qwen2.5-7B | 0.91 | 0.46 | 0.48 | 1.00 | 0.61 | |
| 骆驼3.1-8B | 0.68 | 0.87 | 0.53 | 1.01 | 0.66 | |
| ProvSyn | 0.16 | 0.54 | 0.005 | 0.01 | 0.29 | |
| 跟踪 | GPT-4o 机器人 | 0.66 | 1.04 | 0.80 | 1.07 | 0.54 |
| 克劳德-3.7 | 0.77 | 1.10 | 0.68 | 1.74 | 0.80 | |
| 豆包-pro | 0.75 | 1.06 | 0.57 | 1.12 | 0.51 | |
| Qwen2.5-7B | 0.24 | 0.23 | 0.44 | 1.06 | 0.47 | |
| 骆驼3.1-8B | 0.25 | 0.87 | 1.04 | 1.16 | 0.63 | |
| ProvSyn | 0.17 | 0.23 | 0.02 | 0.04 | 0.33 |
结构评估。为了定量评估生成图形的结构保真度,我们采用了五个基于最大均值差异 (MMD) 的指标[19,59]测量生成的图形和实际图形之间的分布散度。这些指标包括:(1)局部连接模式的度 MMD,(2)高阶结构模体的轨道 MMD,(3)顶点属性分布的节点标签 MMD,(4)边缘标签 MMD,以及 (5)属性-拓扑交互的联合节点标签-度 MMD。
为了将图特征的特征与分布散度测量联系起来,我们利用内核方法将这些异构图投影到可比较的表示中。我们使用两种不同的高斯核公式构建核相似性矩阵。Earth Mover 的距离优化 Gaussian 内核应用于分类分布指标,包括度 MMD、节点/边标签 MMD 和联合节点标签度 MMD,而基于欧几里得的高斯内核处理轨道 MMD 中的连续特征空间。MMD² 值是通过无偏估计器计算的:
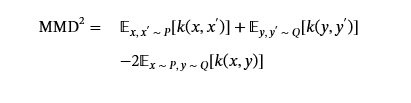
哪里P和Q表示参考和生成的图形分布,x,x′是样本来源P和y,y′从Q.
在表 II 所示的实验结果中,ProvSyn 在所有数据集中始终优于基线。在 Nodlink 数据集中,ProvSyn 在所有指标上实现的值都比基线低一个数量级,表明结构保真度优异。在 Cadets、Theia 和 Trace 数据集中,ProvSyn 也保持了明显的领先地位,尤其是在标签相关指标方面。相比之下,基线方法在四个数据集中表现出不一致的性能模式,这表明无论模型参数的规模如何,结构生成能力都存在根本性的局限性。这一发现强调了额外的异构图生成网络的必要性,与仅由 LLM 生成的图相比,它产生的图结构优越。
Texutual Evaluation (纹理评估)。为了评估生成的文本属性的准确性,我们使用了捕获不同类型相似度的标准 NLP 指标。这些包括:(1) BLEU [51],用于测量 n-gram 精度;(2) GLEU [49],它平衡了精度和召回率;(3) 胭脂 [40],它通过评估覆盖了多少参考文本来关注召回率。
对于每种节点类型,我们构建一个参考语料库ℛt={r1,r2,…,rn}通过聚合t来自真实来源图。计算生成的名称时g我,我们计算它与每个引用的相似性rj∈ℛt通过 Parallel Metric calculations(并行量度计算),然后选择 Maximum similarity Score(最大相似性分数)作为最终评估:
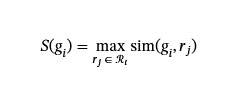
选择最大相似度与平均相似度取决于以下考虑因素。专注于最高匹配度可确保根据生成的文本与参考语料库的最佳对齐情况来评估生成的文本,从而突出其生成准确和相关属性的能力。完整的过程在附录 B 的算法 2 中介绍。
在我们的实验中,我们使用 Python NLTK 库来计算进程和文件节点的 BLEU、GLEU 和 ROUGE 分数。我们没有评估网络节点的文本质量,因为它们的名称是纯数字,因此自然语言指标不合适。此外,我们的分析表明,基线和 ProvSyn 生成的网络节点名称都符合 IPv4 地址格式。
表 III 中的结果表明,基线生成的节点名称通常达到低于 0.1 的分数,这表明大型语言模型缺乏对作系统实体名称的先验知识。相比之下,ProvSyn 在微调阶段从审计日志中接触到真实的实体名称,从而使较小的 3B 模型能够生成更准确、更真实的名称。有趣的是,我们观察到 Llama-8B 在 Cadets 数据集中表现相对较好。进一步分析发现,Llama 生成的许多节点名称是直接从 prompt 中的示例复制而来的,即使相应的日志条目没有意义。
时间评估。出处图是一种有向图,其中有向序列也表示按时间顺序发生的事件的时间序列。对于合成出处图,准确保留事件序列的时间结构对于确保保真度至关重要。为了评估合成来源图的时间一致性,我们采用了两个指标:最长的公共子序列 (LCS) [7]和 Dynamic Time Warping (DTW) [48].
LCS 测量以相同顺序出现在实数图和合成图中的最长事件序列的长度。LCS 是一个严格的匹配指标,它要求事件及其时间顺序精确对齐,不允许任何偏差或偏移。另一方面,DTW 是一种更灵活的指标,允许序列之间的非线性比对。与严格匹配方法不同,DTW 允许沿时间轴拉伸或压缩序列,从而适应局部变化。这种灵活性使 DTW 特别适用于合成图捕获真实序列的一般模式但表现出轻微偏移或不一致的场景。
在我们的实验中,我们使用深度优先搜索从图表中提取序列。每个序列都由节点类型和边缘类型组成,例如 (process, clone, process, read, file)。对于 LCS 计算,我们使用了动态编程方法,对于 DTW,我们使用了 Python 中的 dtw 库。 为了将合成图与测试集中的真实图进行比较,我们采用了类似于附录 B 中算法 2 的策略:将合成图中的每个序列与真实图中的所有序列进行比较,并将最佳匹配记录为其分数。然后通过汇总合成图中所有序列的分数来计算总体图分数。 表 IV 中的结果表明,ProvSyn 在所有四个数据集中都实现了比基线更高的 LCS 分数和更低的 DTW 值,这表明它在保持时间一致性方面具有优势。
表 III:不同模型、类型和数据集的文本质量比较。值越低表示性能越好。
| 数据 | 类型 | 型 | BLEU | 格鲁 | 胭脂-L-F |
| 点头链接 | 过程 | GPT-4o 机器人 | 0.05 | 0.11 | 0.23 |
| 克劳德-3.7 | 0.08 | 0.15 | 0.27 | ||
| 豆包-pro | 0.02 | 0.03 | 0.09 | ||
| Qwen2.5-7B | 0.07 | 0.15 | 0.29 | ||
| 骆驼3.1-8B | 0.12 | 0.17 | 0.33 | ||
| ProvSyn | 0.89 | 1.00 | 0.99 | ||
| 文件 | GPT-4o 机器人 | 0.09 | 0.11 | 0.29 | |
| 克劳德-3.7 | 0.10 | 0.11 | 0.29 | ||
| 豆包-pro | 0.06 | 0.11 | 0.25 | ||
| Qwen2.5-7B | 0.11 | 0.17 | 0.41 | ||
| 骆驼3.1-8B | 0.26 | 0.26 | 0.37 | ||
| ProvSyn | 0.31 | 0.32 | 0.44 | ||
| 学员 | 过程 | GPT-4o 机器人 | 0.24 | 0.24 | 0.24 |
| 克劳德-3.7 | 0.17 | 0.17 | 0.17 | ||
| 豆包-pro | 0.03 | 0.03 | 0.03 | ||
| Qwen2.5-7B | 0.03 | 0.03 | 0.04 | ||
| 骆驼3.1-8B | 1.00 | 1.00 | 1.00 | ||
| ProvSyn | 1.00 | 1.00 | 1.00 | ||
| 文件 | GPT-4o 机器人 | 0.01 | 0.01 | 0.20 | |
| 克劳德-3.7 | 0.03 | 0.03 | 0.14 | ||
| 豆包-pro | 0.01 | 0.01 | 0.14 | ||
| Qwen2.5-7B | 0.02 | 0.02 | 0.16 | ||
| 骆驼3.1-8B | 0.00 | 0.00 | 0.03 | ||
| ProvSyn | 0.31 | 0.32 | 0.60 | ||
| 忒伊亚 | 过程 | GPT-4o 机器人 | 0.08 | 0.08 | 0.09 |
| 克劳德-3.7 | 0.04 | 0.04 | 0.05 | ||
| 豆包-pro | 0.01 | 0.01 | 0.03 | ||
| Qwen2.5-7B | 0.19 | 0.19 | 0.20 | ||
| 骆驼3.1-8B | 0.00 | 0.00 | 0.00 | ||
| ProvSyn | 0.76 | 0.89 | 0.47 | ||
| 文件 | GPT-4o 机器人 | 0.03 | 0.03 | 0.21 | |
| 克劳德-3.7 | 0.05 | 0.05 | 0.16 | ||
| 豆包-pro | 0.01 | 0.01 | 0.11 | ||
| Qwen2.5-7B | 0.00 | 0.00 | 0.29 | ||
| 骆驼3.1-8B | 0.00 | 0.00 | 0.35 | ||
| ProvSyn | 0.37 | 0.44 | 0.48 | ||
| 跟踪 | 过程 | GPT-4o 机器人 | 0.02 | 0.02 | 0.02 |
| 克劳德-3.7 | 0.02 | 0.02 | 0.02 | ||
| 豆包-pro | 0.00 | 0.00 | 0.00 | ||
| Qwen2.5-7B | 0.02 | 0.02 | 0.02 | ||
| 骆驼3.1-8B | 0.00 | 0.00 | 0.00 | ||
| ProvSyn | 0.50 | 0.50 | 0.50 | ||
| 文件 | GPT-4o 机器人 | 0.00 | 0.00 | 0.03 | |
| 克劳德-3.7 | 0.00 | 0.00 | 0.03 | ||
| 豆包-pro | 0.00 | 0.00 | 0.01 | ||
| Qwen2.5-7B | 0.00 | 0.00 | 0.02 | ||
| 骆驼3.1-8B | 0.00 | 0.00 | 0.00 | ||
| ProvSyn | 0.00 | 0.00 | 0.67 |
图嵌入评估。为了从嵌入的角度评估合成图的保真度,我们采用图表示学习技术将合成图和真实图投影到一个共享的向量空间中,并使用余弦相似度来测量它们的相似性。具体来说,我们采用两种具有代表性的 emin 方法:DeepWalk [52]和 Doc2Vec [35].
DeepWalk 是图表示学习的基础算法。它通过在图形上模拟截断的随机游走并将生成的节点序列视为语言建模任务的句子来学习节点嵌入。给定一个图形G,我们执行N长度随机游走L从每个节点开始,生成一个 Corpus𝒲={w1,w2,…,wN},其中每个w我是节点标识符的遍历序列。然后,这些序列用于训练 Word2Vec 模型,生成节点级嵌入。图形级嵌入𝐯深度行走计算为所有节点嵌入的平均值:
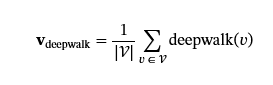
值得注意的是,DeepWalk 不考虑节点的文本属性。
与 DeepWalk 不同,Doc2Vec 利用节点名称信息来捕获图形的文本语义。它将每个图形视为一个文档,该文档由随机游走的集合构成。对于给定的图形G,我们执行N长度随机游走L生成序列集𝒲={w1,w2,…,wN},其中每个w我是节点名称的序列。这些序列用于训练 Doc2Vec 模型,从而产生图形级嵌入𝐯doc2vec:
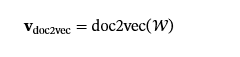
评估合成图之间的相似性Gs和一个真实的图表Gr,我们计算它们各自嵌入向量之间的余弦相似度:
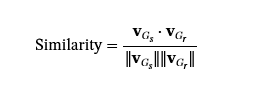
相似性分数越高,表示合成图在嵌入空间中表现出对真实图的保真度更高。
对于基于 DeepWalk 的相似性,我们使用 Gensim 库中的 Word2Vec 模型,对于基于 Doc2Vec 的相似性,我们使用 Gensim 的 Doc2Vec 模型。在表 IV 所示的实验结果中,ProvSyn 在 Nodlink、Cadets 和 Trace 数据集上的表现优于基线,而在 Theia 上的表现略差于 GPT 和 Claude。结果表明,ProvSyn 在四个数据集中保持了稳定的嵌入相似性,DeepWalk 分数高于 0.80,Doc2Vec 分数高于 0.65。相比之下,基线在不同数据集中表现出更大的变化。
表 IV:不同数据集和模型中的 Temporal 和 Embedding 指标的比较。对于 LCS,越高越好;对于 DTW,越低越好;对于 DeepWalk 和 Doc2Vec,越高越好。
| 数据 | 型 | 时间指标 | 嵌入量度 | ||
| LCS 公司 | DTW | DeepWalk 深度行走 | Doc2Vec 的 | ||
| 点头链接 | GPT-4o 机器人 | 2.44 | 1.54 | 0.66 | 0.69 |
| 克劳德-3.7 | 3.03 | 1.33 | 0.83 | 0.40 | |
| 豆包-pro | 2.64 | 0.89 | 0.60 | 0.59 | |
| Qwen2.5-7B | 2.84 | 0.56 | 0.58 | 0.32 | |
| 骆驼3.1-8B | 2.88 | 0.83 | 0.50 | 0.16 | |
| ProvSyn | 3.30 | 0.41 | 0.89 | 0.74 | |
| 学员 | GPT-4o 机器人 | 2.99 | 0.48 | 0.70 | 0.40 |
| 克劳德-3.7 | 2.87 | 1.20 | 0.73 | 0.39 | |
| 豆包-pro | 2.68 | 3.62 | 0.64 | 0.71 | |
| Qwen2.5-7B | 2.13 | 24.30 | 0.79 | 0.25 | |
| 骆驼3.1-8B | 2.96 | 0.48 | 0.48 | 0.67 | |
| ProvSyn | 3.01 | 0.21 | 0.90 | 0.82 | |
| 忒伊亚 | GPT-4o 机器人 | 2.39 | 0.65 | 0.89 | 0.53 |
| 克劳德-3.7 | 1.80 | 0.74 | 0.82 | 0.70 | |
| 豆包-pro | 2.78 | 1.43 | 0.56 | 0.39 | |
| Qwen2.5-7B | 1.36 | 8.90 | 0.74 | 0.48 | |
| 骆驼3.1-8B | 1.04 | 8.94 | 0.39 | 0.66 | |
| ProvSyn | 3.02 | 0.00 | 0.81 | 0.65 | |
| 跟踪 | GPT-4o 机器人 | 2.16 | 0.46 | 0.70 | 0.27 |
| 克劳德-3.7 | 2.15 | 0.54 | 0.67 | 0.41 | |
| 豆包-pro | 2.09 | 0.40 | 0.57 | 0.08 | |
| Qwen2.5-7B | 2.10 | 0.47 | 0.75 | 0.09 | |
| 骆驼3.1-8B | 2.08 | 4.45 | 0.71 | -0.01 | |
| ProvSyn | 2.80 | 0.10 | 0.81 | 0.75 | |
5.3语义正确性评估
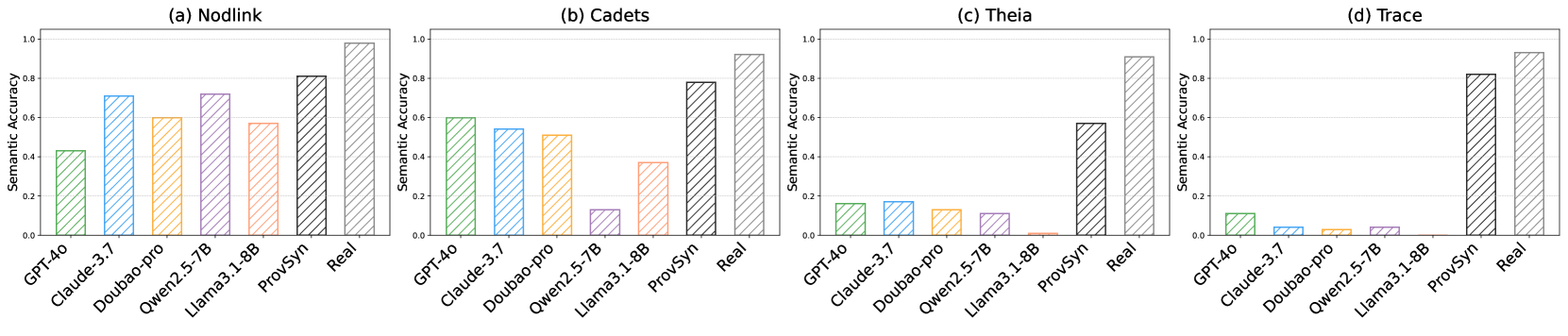
图 2:不同模型和数据集的语义准确性比较。值越高表示性能越好。
我们使用 Section 4.6 中介绍的语义正确性验证机制来评估合成图的语义。在实验中,GAT 模型以 0.0001 的学习率训练了 2500 个时期,而 MLP 分类器以相同的学习率训练了 1500 个时期。为了验证我们的语义准确性评估的有效性和可解释性,我们在来自相同数据集但与训练图不同的真实世界出处图上对其进行了测试。结果表明,这些真实图在 Nodlink、Cadets、Theia 和 Trace 数据集中的语义准确率超过 90%。这支持了我们的语义准确性评估方法的有效性。图 2 中的结果表明,ProvSyn 生成的来源图在所有四个数据集的语义准确性方面始终优于基线,显示出对数据分布差异的鲁棒性。相比之下,基线在数据集之间的语义准确性方面表现出很大的波动。值得注意的是,在更具挑战性的 Theia 和 Trace 数据集中,基线生成的图形的语义准确率保持在 0.20 以下,而 ProvSyn 分别达到 0.57 和 0.82。这些结果表明 ProvSyn 在处理复杂、低信噪比的来源数据方面具有稳定性。
5.4数据不平衡评估
为了评估包含 ProvSyn 生成的合成图是否能缓解类不平衡,我们使用两个指标(熵和基尼指数)来量化节点和边缘标签的分布平衡。给定具有概率的标签分布p1,p2,…,pn,这两个指标定义为:
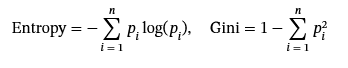
这两个指标的值越高,表示标签分布越均匀、越平衡。
我们在 Nodlink、Cadets、Theia 和 Trace 数据集上进行了实验,包括原始数据和合并 ProvSyn 生成的数据。对于每个数据集,我们添加了 100 个与原始图合并的合成图作为图社区。结果总结在表 V 中。如图所示,包含 ProvSyn 会增加所有数据集中节点和边缘标签的熵和基尼系数。在 Nodlink 数据集中,由于数据集的规模较小,指标显著提高。这些结果表明,ProvSyn 通过丰富出处图数据集中代表性不足的类,有助于实现更平衡的标签分布。
为了评估合成的图是否超越了训练数据分布并包含涵盖更多出处场景的新结构,我们使用了两个指标:新颖性和唯一性。通过验证每个生成的图既不是训练集中任何参考图的子图,也不包含任何参考图作为子图来计算新颖性,从而表明合成图中是否存在新的结构。唯一性衡量生成的图形在结构上彼此不同的比例,反映了生成的图形的多样性。如表 VI 所示,ProvSyn 生成的图表在所有四个数据集中都实现了 100% 的新颖性和 100% 的唯一性。这表明合成数据表现出很强的多样性,并有效地捕获了原始数据中代表性不足或缺失的模式。
表 V:有和没有合成数据的不同数据集的节点和边标签熵以及基尼指数的比较。值越高表示性能越好。
| 数据 | 数据源 | 节点标签 | 边标签 | ||
| 熵 | 基尼指数 | 熵 | 基尼指数 | ||
| 点头链接 | 真正 | 1.03 | 0.42 | 2.41 | 0.75 |
| +ProvSyn | 1.31 (+0.28) | 0.55 (+0.13) | 2.63 (+0.22) | 0.82 (+0.07) | |
| 学员 | 真正 | 1.11 | 0.44 | 1.84 | 0.52 |
| +ProvSyn | 1.31 (+0.20) | 0.53 (+0.09) | 1.92 (+0.08) | 0.54 (+0.02) | |
| 忒伊亚 | 真正 | 1.31 | 0.53 | 1.33 | 0.39 |
| +ProvSyn | 1.41 (+0.10) | 0.58 (+0.05) | 1.36 (+0.03) | 0.39 (+0.00) | |
| 跟踪 | 真正 | 1.52 | 0.57 | 1.57 | 0.45 |
| +ProvSyn | 1.62 (+0.10) | 0.61 (+0.04) | 1.61 (+0.04) | 0.47 (+0.02) | |
表 VI:在不同数据集中评估 ProvSyn 生成的图形的新颖性和唯一性。值越高表示性能越好。
| 数据 | 新颖性 (%) | 唯一性 (%) |
| 点头链接 | 100.0 | 100.0 |
| 学员 | 100.0 | 100.0 |
| 忒伊亚 | 100.0 | 100.0 |
| 跟踪 | 100.0 | 100.0 |
5.5IDS 中的应用
为了演示 ProvSyn 的实际效用,我们重点介绍了 APT 攻击检测的任务。我们使用两种检测算法 Magic 进行实验[31]和 Nodlink[37].具体来说,我们用合成的出处图来增强训练集,然后观察检测性能在测试过程中是提高还是下降。
对于 Nodlink 算法,我们通过添加 50 个与原始来源图合并的合成图作为图社区来增强其数据集。这导致节点数量增加了 15%。对于 Magic 算法,我们增强了 Cadets、Theia 和 Trace 数据集。由于它们的规模较大,我们添加了 300 个合成图,这些图合并到其原始出处图中。这导致节点数量增加了 10% 到 15%。
为了评估合成图在入侵检测任务中的有效性,我们在整合合成数据之前和之后保持相同的训练配置。检测性能如表 VII 所示。除了 Precision 和 Recall 之外,我们还报告了误报 (#FP) 的数量,这是入侵检测系统的关键指标,因为高误报率会增加后续安全分析的工作量。如结果所示,在 Nodlink 数据集上,包含合成图不会导致 Precision、Recall 或误报数量发生变化,这表明合成数据与原始数据的质量相当。在 Cadets、Theia 和 Trace 数据集上,召回率保持不变,精度有所提高。具体来说,Cadets 的假阳性减少了 506 个(从 6435 个减少到 5929 个),Theia 的假阳性减少了 95 个(从 931 个减少到 836 个),Trace 的假阳性减少了 379 个(从 2390 年到 2011 年)。这些结果表明,使用 ProvSyn 生成的合成图进行增强可以提高模型性能,并有效减少检测系统中的误报。
表 VII:不同数据集(含合成数据)的 IDS 性能。值越高表示性能越好。
| 数据 | 数据源 | 精度 (%) | 召回率(%) | #FP |
| 点头链接 | 真正 | 100.00 | 100.00 | 0 |
| + ProvSyn | 100.00 | 100.00 | 0 | |
| 学员 | 真正 | 66.58 | 99.79 | 6435 |
| + ProvSyn | 68.37 | 99.77 | 5929 | |
| 跟踪 | 真正 | 96.61 | 99.98 | 2390 |
| + ProvSyn | 97.13 | 99.98 | 2011 | |
| 忒伊亚 | 真正 | 96.45 | 99.99 | 931 |
| + ProvSyn | 96.80 | 99.99 | 836 |
5.6开销分析
表 VIII:ProvSyn 核心模块的时间和内存要求。
| 模块 | 阶段 | 时间 | 记忆 |
| 图形生成 | 训练 | 18 小时 | 0.84 吉字节 |
| 推理 | 28.09 秒 | 0.38 吉字节 | |
| 文本生成 | 训练 | 109 秒 | 3.44 吉字节 |
| 推理 | 2.78 小时 | 28 吉字节 |
在本节中,我们分析了 ProvSyn 的时间和内存需求(参见表 VIII)。ProvSyn 框架最耗时和最耗费资源的组件是异构图生成模块和文本属性生成模块。
对于异构图生成模块,我们使用 16000 个样本进行训练,批量大小为 32 和 3000 个训练 epoch。平均训练时间为 18 小时,GPU 内存使用量为 0.84 GB。生成 1000 个图形的推理需要 28.09 秒,消耗 0.38 GB 内存。
对于文本属性生成模块,我们采用 Llama3.2-3B-Instruct 作为基础模型,应用了 4 位量化的 LoRA 算法。FastLanguageModel 库用于加速训练。训练包括 60 个步骤,平均耗时 109 秒,需要 3.44 GB 的峰值内存。在推理过程中,为单个图形生成文本属性平均需要 80 秒。在我们的实验中,我们并行部署 8 个微调的 LLM 来合成 1000 个图形,在 2.78 小时内完成该过程。8 个模型所需的总 GPU 内存为 28 GB。
该分析表明,ProvSyn 是一个用于来源图合成的时间和内存高效的框架。
6讨论和限制
时间建模。溯源图不仅是具有文本属性的有向异构图,还是一个时态图,其中每个事件都与一个时间戳相关联,该时间戳指示其在系统中的发生时间。这些时态信息最近已被下游入侵检测系统利用[53]以更好地捕捉良性和异常行为的模式。但是,在 ProvSyn 中,我们不会合成事件的显式时间戳。相反,我们依靠有向边的序列来近似时间顺序。未来的工作可能会探索使用时间图生成网络对时间动力学进行建模[75],或者设计利用 LLM 生成真实时间戳的策略,从而实现更全面和时间一致的来源图合成。
图形比例。在 ProvSyn 中,生成的出处图的比例尺比实际的出处图小。为了实现数据增强,我们将多个合成图作为不同的社区嵌入到大型真实世界的来源图中。结果表明,这种方法有效地缓解了数据不平衡,降低了在增强数据集上训练的检测模型的假阳性率。未来的工作可以侧重于通过增强用于大规模合成的图形生成模型来扩展合成来源图,并探索将较小图形组合成较大图形同时保留结构保真度的图形合并算法。
文本属性合成的效率。在文本属性合成过程中,当并行处理这些序列以生成节点名称时,DFS 生成的不同序列中的节点之间的重叠可能会导致命名冲突。 为了解决这个问题,我们序列化序列并按顺序将它们输入到 LLM 中。然后,从早期序列生成的节点名称将用作后续序列的上下文。此方法对于小比例图有效。然而,对于大规模图,综合效率会降低。未来的工作可能会探索将大型图形划分为非重叠序列批次的策略,从而在避免节点命名冲突的同时实现并行处理。
应用场景。迄今为止,ProvSyn 合成的图已在来源图数据集领域和针对 APT 攻击的检测算法中证明了实用性。但是,ProvSyn 是一个通用框架,能够合成具有文本属性的高保真异构图。ProvSyn 的固有能力与当前应用之间的这种差距为未来的工作提供了机会:扩大对 ProvSyn 能力的探索,以涵盖更广泛的应用场景和下游算法。
7结论
本文提出了 ProvSyn,这是一种新颖的出处图生成框架,由三个阶段组成:异构图结构生成、基于规则的拓扑细化和基于 LLM 的文本属性综合。为了评估生成的图形的保真度,我们评估了结构、文本、时间、嵌入和语义方面。与 LLM 直接合成的来源数据相比,ProvSyn 始终生成保真度更高的图形。当集成到现有数据集中时,ProvSyn 生成的图形有助于缓解类不平衡,并降低在增强数据上训练的检测模型的误报率。