RAG质量评估
当完成了一个RAG系统的开发工作以后,还需要对该系统的性能进行评估。如何对RAG系统的性能进行评估呢?仔细分析RAG系统的产出成果,主要涉及以下几点:
(1)检索器组件 检索的相关文档 context,
(2)生成器组件 产出的最终答案 answer,
(3)最初的用户问题 question。
因此RAG系统的评估应该将对question、context、answer 三者结合一起评估。

一、RAG 三元组
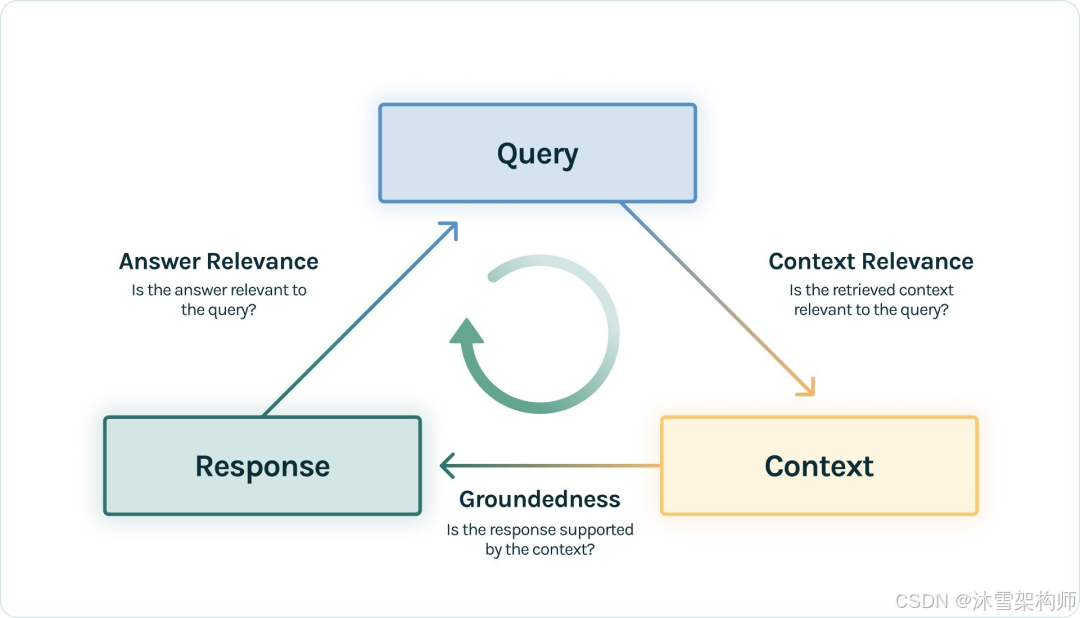
标准的 RAG 流程就是用户提出 Query 问题,RAG 应用去召回 Context,然后 LLM 将 Context 组装,生成满足 Query 的 Response 回答。那么在这里出现的三元组:—— Query、Context 和 Response 就是 RAG 整个过程中最重要的三元组,它们之间两两相互牵制。我们可以通过检测三元组之间两两元素的相关度,来评估这个 RAG 应用的效果:
- Context Relevance: 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。
- Groundedness: 衡量 LLM 的 Response 遵从召回的 Context 的程度。如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。
- Answer Relevance:衡量最终的 Response 回答对 Query 提问的相关度。如果该得分低,反应出了可能答不对题。
二、RagAs评估
RAGAs(RAG Assessment)是一个专为评估 RAG(检索增强生成)系统 的开源框架。它可以帮助我们来快速评估RAG系统的性能,
1、评估数据
为了评估RAG系统,Ragas需要以下信息:
- question:用户输入的问题。
- answer:从 RAG 系统生成的答案(由LLM给出)。
- contexts:根据用户的问题从外部知识源检索的上下文即与问题相关的文档。
- ground_truths: 人类提供的基于问题的真实(正确)答案。 这是唯一的需要人类提供的信息。
官网:https://www.ragas.io/
2、评估指标
Ragas提供了五种评估指标包括:
- 忠实度(faithfulness)
- 答案相关性(Answer relevancy)
- 上下文精度(Context precision)
- 上下文召回率(Context recall)
- 上下文相关性(Context relevancy)
(1) 忠实度(faithfulness)
忠实度(faithfulness)衡量了生成的答案(answer)与给定上下文(context)的事实一致性。它是根据answer和检索到的context计算得出的。并将计算结果缩放到 (0,1) 范围且越高越好。
如果答案(answer)中提出的所有基本事实(claims)都可以从给定的上下文(context)中推断出来,则生成的答案被认为是忠实的。为了计算这一点,首先从生成的答案中识别一组claims。然后,将这些claims中的每一项与给定的context进行交叉检查,以确定是否可以从给定的context中推断出它。忠实度分数由以下公式得出:
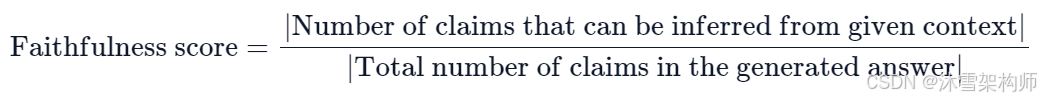
示例:
问题 (question):爱因斯坦出生于何时何地?
上下文 (context):阿尔伯特・爱因斯坦(Albert Einstein,1879 年 3 月 14 日出生)是一位出生于德国的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的科学家之一
高忠实度答案:爱因斯坦 1879 年 3 月 14 日出生于德国。
低忠实度答案:爱因斯坦于 1879 年 3 月 20 日出生于德国。
(2)答案相关性(Answer relevancy)
评估指标“答案相关性”重点评估生成的答案(answer)与用户问题(question)之间相关程度。不完整或包含冗余信息的答案将获得较低分数。该指标是通过计算question和answer获得的,它的取值范围在 0 到 1 之间,其中分数越高表示相关性越好。
当答案直接且适当地解决原始问题时,该答案被视为相关。重要的是,我们对答案相关性的评估不考虑真实情况,而是对答案缺乏完整性或包含冗余细节的情况进行惩罚。为了计算这个分数,LLM会被提示多次为生成的答案生成适当的问题,并测量这些生成的问题与原始问题之间的平均余弦相似度。基本思想是,如果生成的答案准确地解决了最初的问题,LLM应该能够从答案中生成与原始问题相符的问题。
示例:
问题 (question):法国在哪里,首都是哪里?
低相关性答案:法国位于西欧。
高相关性答案:法国位于西欧,巴黎是其首都。
(3)上下文精度(Context precision)
上下文精度是一种衡量标准,它评估所有在上下文(contexts)中呈现的与基本事实(ground-truth)相关的条目是否排名较高。理想情况下,所有相关文档块(chunks)必须出现在顶层。该指标使用question和计算contexts,值范围在 0 到 1 之间,其中分数越高表示精度越高。

(4)上下文召回率(Context recall)
上下文召回率(Context recall)衡量检索到的上下文(Context)与人类提供的真实答案(ground truth)的一致程度。它是根据ground truth和检索到的Context计算出来的,取值范围在 0 到 1 之间,值越高表示性能越好。
为了根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。 在理想情况下,真实答案中的所有句子都应归因于检索到的Context。
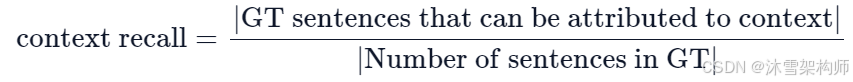
示例:
问题 (question):法国在哪里,首都是哪里?
基本事实 (Ground truth):法国位于西欧,其首都是巴黎。
高的上下文召回率 (High context recall):法国位于西欧,拥有中世纪城市、高山村庄和地中海海滩。其首都巴黎以其时装屋、卢浮宫等古典艺术博物馆和埃菲尔铁塔等古迹而闻名。
低的上下文召回率 (Low context recall):法国位于西欧,拥有中世纪城市、高山村庄和地中海海滩。该国还以其葡萄酒和精致的美食而闻名。拉斯科的古代洞穴壁画、里昂的罗马剧院和宏伟的凡尔赛宫都证明了其丰富的历史。
(5)上下文相关性(Context relevancy)
该指标衡量检索到的上下文(Context)的相关性,根据用户问题(question)和上下文(Context)计算得到,并且取值范围在 (0, 1)之间,值越高表示相关性越好。理想情况下,检索到的Context应只包含解答question的信息。 我们首先通过识别检索到的Context中与回答question相关的句子数量来估计 |S| 的值。 最终分数由以下公式确定:
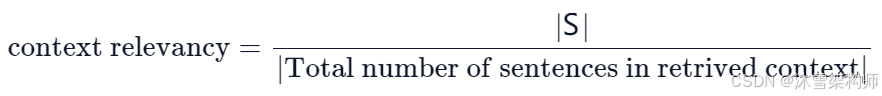
说明:这里的|S|是指Context中存在的与解答question相关的句子数量。
示例:
问题 (question):法国的首都是哪里?
高的上下文相关性 (Context relevancy):法国位于西欧,拥有中世纪城市、高山村庄和地中海海滩。其首都巴黎以其时装屋、卢浮宫等古典艺术博物馆和埃菲尔铁塔等古迹而闻名。
低的上下文相关性 (Context relevancy):西欧的法国包括中世纪城市、高山村庄和地中海海滩。其首都巴黎以其时装屋、卢浮宫等古典艺术博物馆和埃菲尔铁塔等古迹而闻名。该国还以其葡萄酒和精致的美食而闻名。拉斯科的古代洞穴壁画、里昂的罗马剧院和宏伟的凡尔赛宫都证明了其丰富的历史。
3、编码
(1)准备评估数据
RAGAs 作为一个无需参照的评估框架,其评估数据集的准备相对简单。你需要准备一些 question 和 ground_truths 的配对,从中可以推导出其他所需信息,操作如下:
pip install ragasfrom datasets import Datasetquestions = ["客户经理被投诉了,投诉一次扣多少分?","客户经理每年评聘申报时间是怎样的?","客户经理在工作中有不廉洁自律情况的,发现一次扣多少分?","客户经理不服从支行工作安排,每次扣多少分?","客户经理需要什么学历和工作经验才能入职?","个金客户经理职位设置有哪些?"
]ground_truths = ["每投诉一次扣2分","每年一月份为客户经理评聘的申报时间","在工作中有不廉洁自律情况的每发现一次扣50分","不服从支行工作安排,每次扣2分","须具备大专以上学历,至少二年以上银行工作经验","个金客户经理职位设置为:客户经理助理、客户经理、高级客户经理、资深客户经理"
]answers = []
contexts = []# Inference
for query in questions:answers.append(chain.invoke({"question": query}))contexts.append([docs.page_content for docs in retriever.get_relevant_documents(query)])# To dict
data = {"user_input": questions,"response": answers,"retrieved_contexts": contexts,"reference": ground_truths
}# Convert dict to dataset
dataset = Dataset.from_dict(data)将字典转换为数据集
dataset = Dataset.from_dict(data)
如果你不关注 context_recall 指标,就不必提供 ground_truths 数据。在这种情况下,你只需准备 question 即可。
(2)评估 RAG 应用
首先,从 ragas.metrics 导入你计划使用的所有度量标准。然后,使用 evaluate() 函数,简单地传入所需的度量标准和已准备好的数据集即可。
# 评测结果
from ragas import evaluate
from ragas.metrics import (faithfulness,answer_relevancy,context_recall,context_precision,
)result = evaluate(dataset = dataset, metrics=[context_precision,context_recall,faithfulness,answer_relevancy,],embeddings=embeddings
)df = result.to_pandas()
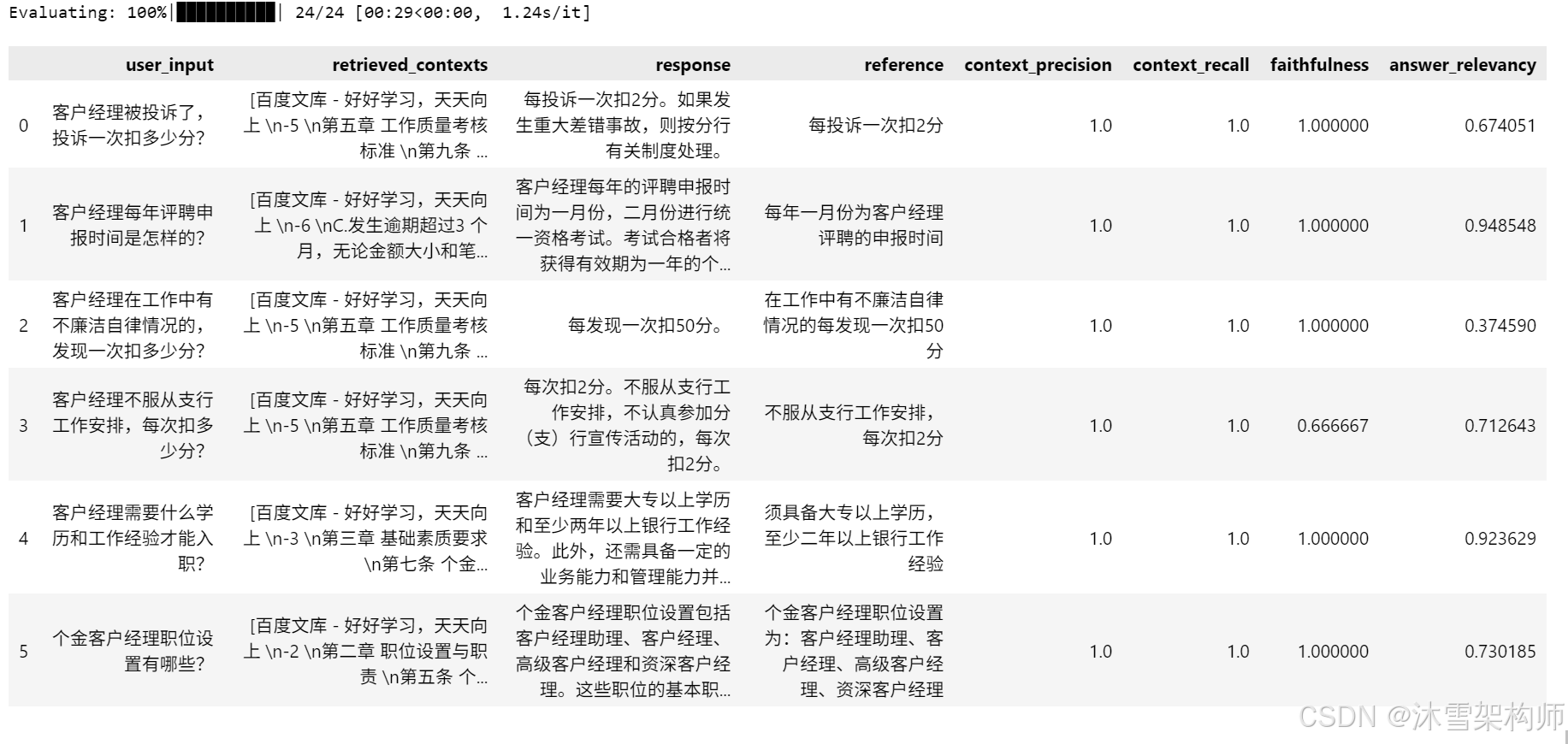
下方展示了示例中的 RAGAs 分数:
参考网址
https://zhuanlan.zhihu.com/p/673077106?utm_source=chatgpt.com
RAG Pipeline Evaluation Using RAGAS | Haystack
Ragas: Evaluation Framework for RAG Systems - Build Fast with AI