【大模型】RankRAG:基于大模型的上下文排序与检索增强生成的统一框架
文章目录
- A 论文出处
- B 背景
- B.1 背景介绍
- B.2 问题提出
- B.3 创新点
- C 模型结构
- C.1 指令微调阶段
- C.2 排名与生成的总和指令微调阶段
- C.3 RankRAG推理:检索-重排-生成
- D 实验设计
- E 个人总结
A 论文出处
- 论文题目:RankRAG:Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
- 发表情况:2024-NeurIPS
B 背景
B.1 背景介绍
检索增强生成(RAG)技术被广泛应用于定制化的大语言模型(LLMs),使其能够有效处理长尾知识、集成最新信息,并适应特定领域或任务需求,且无需调整模型权重。其流程包含两个核心阶段:首先,基于语义嵌入的检索器从文档集合或外部知识源中,查询并检索语义最相关的k个上下文片段;随后,大语言模型读取这些检索到的上下文片段,据此生成最终答案。这种技术可以显著增强大语言模型在专业与时效性场景下的知识利用能力。
B.2 问题提出
(1)检索器容量约束:出于计算效率考量,现有RAG系统普遍采用检索能力受限的组件,如基于词汇匹配的稀疏检索方法(BM25)或参数量适中的嵌入模型(BGE、BERT)。这在一定程度上制约了其捕捉深层语义关联的能力。
(2)Top-K 检索策略的固有局限: 尽管当代大语言模型(LLMs)的上下文窗口容量显著提升,但其实际性能在输入上下文数量(K值)增加时迅速达到饱和点。例如,在开放域问答任务中,纳入上下文分块的最佳数量典型值约为10。提高K值虽可增强信息召回率,但不可避免地引入更多低相关性或噪声内容。这些无关信息干扰LLMs的信息处理过程,导致生成答案的准确性与聚焦性下降。因此,存在召回率提升与信息纯度/模型精准度之间的权衡。
B.3 创新点
通过对单一大语言模型进行指令调优,使其可以同时进行上下文排序和答案生成,进一步提升LLM在RAG检索和生成阶段排除不相关上下文的能力。
C 模型结构
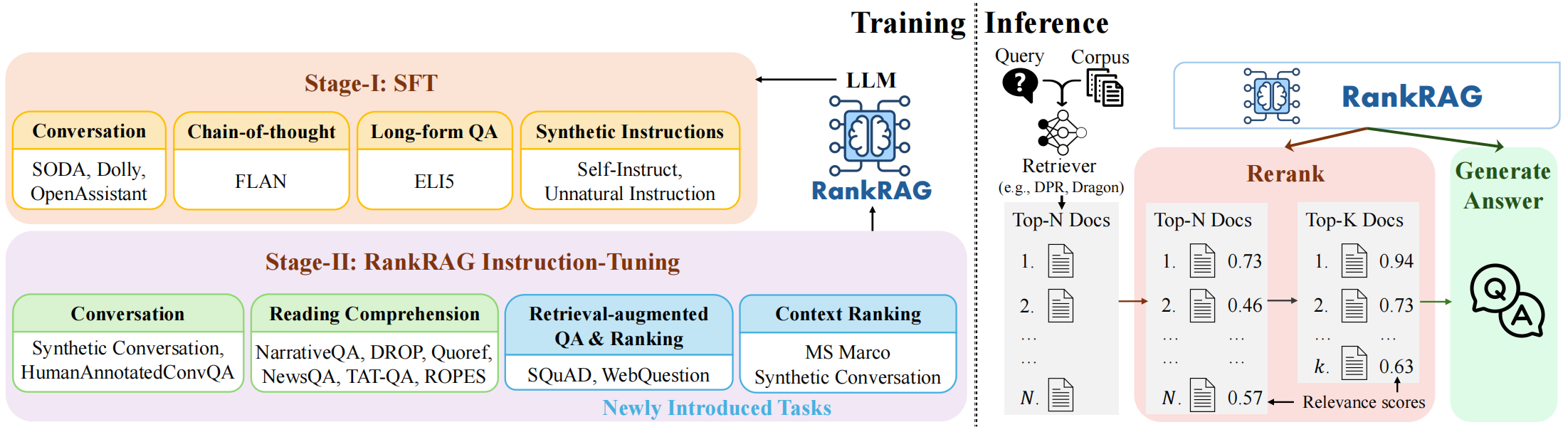
C.1 指令微调阶段
指令调优(或监督式微调)可以显著提升大语言模型指令遵循的能力,从而提高下游任务的零样本性能。第一阶段的指令调优数据集包括:公共对话数据集、长篇问答数据集、Chain of Thought数据集以及合成数据集。
C.2 排名与生成的总和指令微调阶段
- 第一阶段的SFT数据:保持LLM遵循指令的能力;
- 丰富的上下文对话数据:加强LLM利用上下文回答问题的能力,主要包括标准的QA和阅读理解数据集、对话QA数据集;
- RAG问答/排名数据:增强LLM在生成回答时,对无关上下文的抗干扰能力也非常重要,这里采用的两大数据集,不仅包含标准答案的上下文,还包括通过BM25算法检索出的最相关上下文;
- 上下文排名数据:利用MS MARCO标准检索数据集(包含查询-正段落对及BM25挖掘的硬负样本),训练LLM判断段落相关性(输出“真/假”)。针对对话问答数据的稀缺,将相关文档分割为150字段落,依据其与标准答案的4-gram召回率判定相关性(>0.5为相关,<0.1为不相关),构建伪相关对。最终混合约50K数据用于指令微调。
C.3 RankRAG推理:检索-重排-生成
(1)检索器在文本库中筛选出 top-n 个相关上下文;
(2)RankRAG 基于提示,评估问题与这些检索到的上下文之间的相关性得分,以此作为生成正确答案的概率,随后对上下文进行重排,精挑细选出 top-k( k 远小于 n )个最为贴切的上下文,作为下一步生成答案的依据;
(3)精选出的 top-k 个上下文与问题串联,再次输入 RankRAG 模型,以此生成最终的答案。
D 实验设计
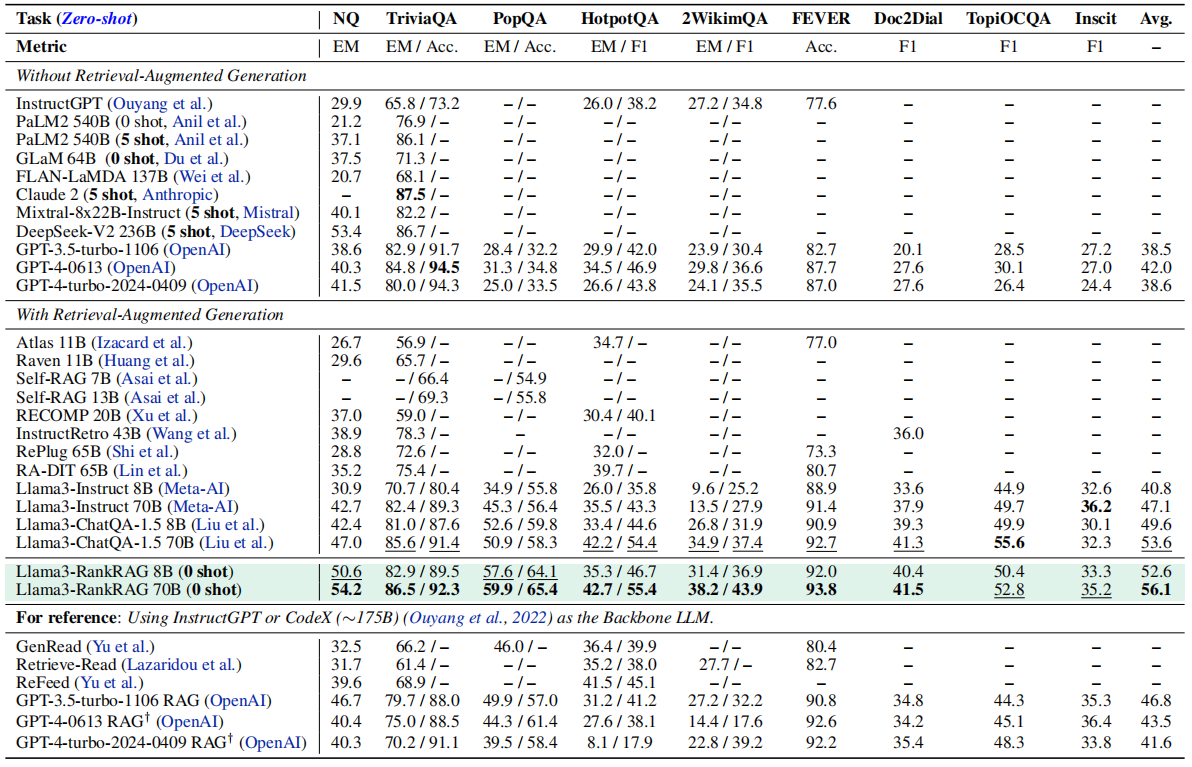
下面展示了RankRAG与其他基线模型的对比结果,结果表明,RankRAG超越了所有的基线模型,并且各个组件也都有一定的效果。

E 个人总结
(1)本文首次将上下文排序与检索增强生成(RAG)集成于单一LLM框架,替代传统RAG中分离的检索器+生成器流程,并通过指令微调直接训练LLM完成"段落相关性排序"和"答案生成"双任务,提升任务协同性。
(2)LLM内置排序能力可筛除无关段落,减轻噪声干扰(传统RAG的Top-K策略易引入噪声),仅需一个LLM同时处理排序与生成,可以降低部署复杂度(对比级联式RAG系统)。
(3)RankRAG仍存在多目标权衡难题,排序任务(判别式)与生成任务(生成式)的优化目标可能存在内在冲突,需精细设计损失函数平衡二者。同时模型在MS MARCO(简短查询)和合成对话数据上训练,对复杂多轮对话或跨领域任务的泛化性未充分验证。