卷积神经网络设计指南:从理论到实践的经验总结
前言
这部分涉及的内容需要有一定的卷积神经网络基础支持,包括但是不限于了解:卷积核,池化,归一化等基础概念,当然还有一些内容我会及时补充说明。
本文主要讲述经验性质的如何设计卷积神经网络?,这个问题一定对于初次接触卷积神经网络的学者们有不少的困惑。
卷积神经网络的结构
一个用于图像分类的卷积神经网络 (CNN),其结构通常包含两大核心部分。

前半部分是**特征提取器 (Feature Extractor)**。它主要由一系列卷积层和池化层堆叠而成。卷积层负责识别图像中的局部模式(如边缘、纹理),而池化层则对特征进行降采样,以减少计算量并增强特征的平移不变性。在更复杂的网络中,通常还会引入批量归一化 (Batch Normalization)、通道混洗 (Channel Shuffle) 等技术来优化训练过程和提升性能。
后半部分是**分类器 (Classifier)**。它通常由一个或多个全连接层构成,负责接收并整合前半部分提取出的高级抽象特征,并最终输出每个类别的预测概率。
因此,用于分类的 CNN 本质上可以视为一个特征提取器与分类器的组合体。从这个角度理解,我们也可以灵活地选用其他技术来替代其中的某个部分,例如,使用主成分分析 (PCA) 来提取特征,或使用支持向量机 (SVM) 来执行最终的分类任务。
卷积核的选择:从大到小,再到自适应
理论上来说,卷积核的大小可以是任意的,但绝大部分的CNN中使用的卷积核都是奇数大小的正方形,到这里好奇的你一定会有两个问题:

- 为什么偏爱奇数尺寸的卷积核?
-
便于锚定中心,保持对齐: 奇数尺寸的卷积核(如 3x3, 5x5)拥有一个明确的中心像素。这使得在进行卷积操作时,输出特征图的每个像素可以与输入特征图的一个明确位置相对应。
-
简化Padding,维持尺寸不变: 当需要保持卷积前后特征图的空间尺寸不变时,奇数核的优势尤为明显。通过设置
padding = (kernel_size - 1) / 2,可以轻松实现输入与输出尺寸的匹配。例如,对于3x3的卷积核,设置1个像素的padding即可;对于5x5的核,设置2个像素的padding。而偶数核则难以实现这种完美的对称padding。
-
- 为什么使用正方形的卷积形状?
-
这源于一个普遍的假设,即图像的特征在水平和垂直方向上具有相似的统计特性。正方形卷积核平等地对待两个维度,符合这种直觉,并成为了最通用的选择。
-
早期的AlexNet(2012年)曾成功使用了11x11的大尺寸卷积核来快速捕获大的感受野。然而,自VGGNet(2014年)之后,堆叠小卷积核(尤其是3x3) 成为了设计网络的新范式。VGGNet指出,两个3x3的卷积层串联,其感受野与一个5x5的卷积层相当(如下图所示),但带来了两大优势:
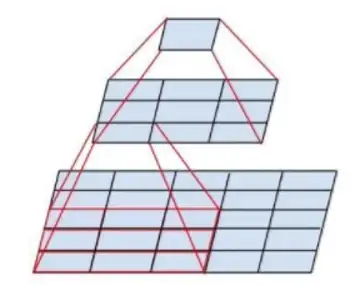
-
更少的参数量: 假设特征图通道数均为 N,一个5x5卷积层的参数量为 5×5×N=25N。而两个3x3卷积层的参数量为 2×(3×3×N)=18N。参数量显著减少,降低了模型的复杂度和过拟合风险。
-
更强的非线性表达能力: 堆叠的两个卷积层可以引入两次非线性激活函数(如ReLU),而单个卷积层只有一次。这增强了网络的特征学习能力和表达能力。
这一洞见使得3x3卷积核迅速成为主流。无论是经典的ResNet、DenseNet(通常在初始层使用一个7x7大核,后续大量堆叠3x3核),还是轻量级的MobileNet、ShuffleNet系列(几乎完全依赖3x3核),都体现了小核设计的优越性。
然而,随着神经架构搜索(NAS)等自动化技术的兴起(下图),这一“金科玉律”又出现了新的变化。
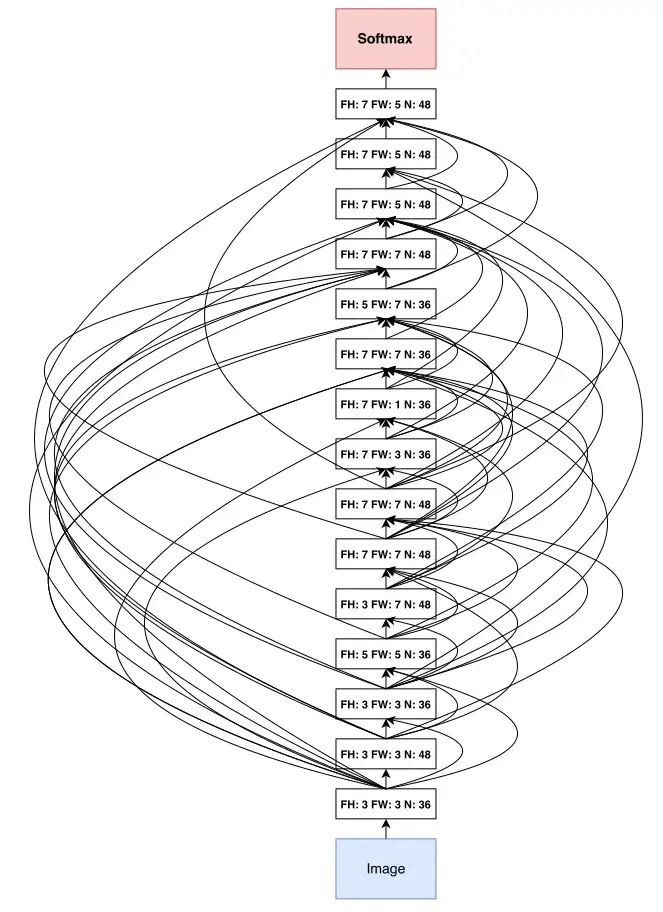
自动搜索出的网络结构(如NAS-Net)表明,5x5、7x7甚至3x7这样的非对称矩形卷积核,在特定层级上可以取得更好的效果。这揭示了手工设计的规整结构(如ResNeXt)可能并非最优解,而“杂乱无章”的混合尺寸卷积或许更能契合数据特征的复杂性。
通常情况下,使用多个不同大小的卷积核可以提高网络的性能。
网络深度的权衡:越深越好吗?
“深度学习”的核心在于其“深度”。从AlexNet(8层)到VGGNet(16-19层),再到ResNet(可达152层甚至更深),网络深度的增加是提升模型性能的关键驱动力。
然而,简单地堆叠网络层数会引发梯度消失/爆炸问题,导致深层网络难以训练。批量归一化(Batch Normalization) 和 残差结构(Residual Connection) 的出现是深度学习发展史上的里程碑,它们有效地解决了这些问题,使得构建百层以上的超深网络成为可能。
理论上,如ResNet论文所论证,一个更深的网络不应比其对应的浅层网络效果更差。但实践中,边际效应(Marginal Utility)是显而易见的。
边际效应 在此指:随着网络层数的增加,模型性能的提升会逐渐放缓,达到某个点后,继续加深网络带来的收益微乎其微,反而可能导致过拟合、计算资源浪费和训练时间激增。
因此,目前主流的网络设计已不再盲目追求深度。轻量化网络通常在几十层左右,而大型高性能网络也鲜有超过200层的。
特征通道与全连接层的设计
特征图通道数
关于特征图的通道数(即feature map的数量),许多经典网络都遵循一个共同的设计原则: 当特征图的空间尺寸(高和宽)减半时,其通道数通常会加倍。
例如,通过一个步长为2的卷积或池化层后,特征图尺寸从 112x112 变为 56x56,通道数可能从 64 变为 128。这样做是为了在压缩空间信息的同时,增加特征维度,以补偿信息损失,确保网络在不同层级间传递的信息量大致稳定。
全连接层
在网络的末端,全连接层负责将学习到的分布式特征映射到最终的样本标签空间。
-
传统设计: 早期的网络(如AlexNet, VGGNet)通常在卷积层后连接多个庞大的全连接层,这部分占据了模型绝大多数的参数,极易导致过拟合。
-
现代设计: Network in Network (NIN) 论文提出的全局平均池化(Global Average Pooling, GAP) 彻底改变了这一局面。现代网络(如ResNet, GoogleNet)通常在最后一个卷积层之后,直接应用GAP,将每个特征图(channel)降维成一个单一数值,然后连接一个极简的全连接层(作为分类器),最后通过Softmax输出各类别的概率。
这种GAP + 单个FC层的设计,几乎完全去除了传统全连接层的参数,极大地减轻了模型的过拟合风险,并更好地将特征图与最终的分类任务关联起来。其全连接层的输入节点数等于最后一个卷积层的通道数,输出节点数等于待分类的类别总数。
End
对于卷积神经网络而言,其每层卷积的通道数量以及网络整体的层数设计,至今仍缺乏坚实的理论基础作为指导。在实践中,这些关键的架构超参数,往往依赖于研究者的经验和直觉,通过设置几组候选配置,并进行大量的“试错法”(Trial and Error)实验,最终筛选出表现最佳的组合。这正是深度卷积神经网络虽然在各类任务中表现卓越,但其设计的经验主义色彩和理论的薄弱之处,长期以来备受学界与业界诟病的核心原因之一。
参考文献
-
Cao, X., 2015. A practical theory for designing very deep convolutional neural networks. Unpublished Technical Report.
-
深层CNN的调参经验 | A practical theory for designing very deep convolutional neural networks
-
神经网络GAT 神经网络感受野计算
-
深入理解卷积(机器学习,深度学习,神经网络)
-
知乎|卷积神经网络的卷积核大小、卷积层数、每层map个数都是如何确定下来的呢?