第二章:文本处理与表示的基础 —— 解码语言的奥秘
语言,作为人类智慧的凝练与思想的媒介,其内在的复杂与精妙构成了人工智能亟待解锁的核心谜题之一。要让机器真正“理解”我们用字符编织的世界,首要的挑战便是如何将这些看似随意的符号序列,转化为机器能够高效处理并能揭示其深层语义的数学形式。本章,我们将深入探索文本表示的基石,从早期的直观尝试到神经网络赋予词语以“生命”的嵌入技术,再到注意力机制带来的“聚焦”革命,最终汇聚成大规模预训练语言模型(PLMs)的壮丽图景。正是这些为文本信息精心雕琢的“数字灵魂”,为后续更高级的语言理解乃至多模态智能奠定了至关重要的“语”基。
2.1 文本的“数字化”洗礼:从符号洪流到结构化数据
在我们能够运用复杂的算法洞察文本内涵之前,必须先让计算机“认识”这些文本。这涉及到一系列基础却关键的步骤,旨在将原始的、非结构化的字符流,转化为更易于分析和计算的结构化数据。
2.1.1 从字符到词元:文本的初步解构
自然语言处理(NLP)的第一步往往是分词 (Tokenization)。这如同将一条完整的项链拆解成一颗颗独立的珠子——词元(tokens)。对于英文等以空格为天然分隔符的语言,这个过程相对直接;然而,对于中文、日文这类缺乏明显词边界的语言,则需要依赖更复杂的统计模型或基于词典的算法来准确切分。除了分词,通常还会进行去除停用词 (Stop Word Removal)(如移除“的”、“是”、“a”、“the”等高频但信息量较低的词)和词形还原 (Lemmatization) / 词干提取 (Stemming)(将词语的不同形态统一为其基本形式,如“running”到“run”)等操作,以净化数据,降低后续处理的复杂度。
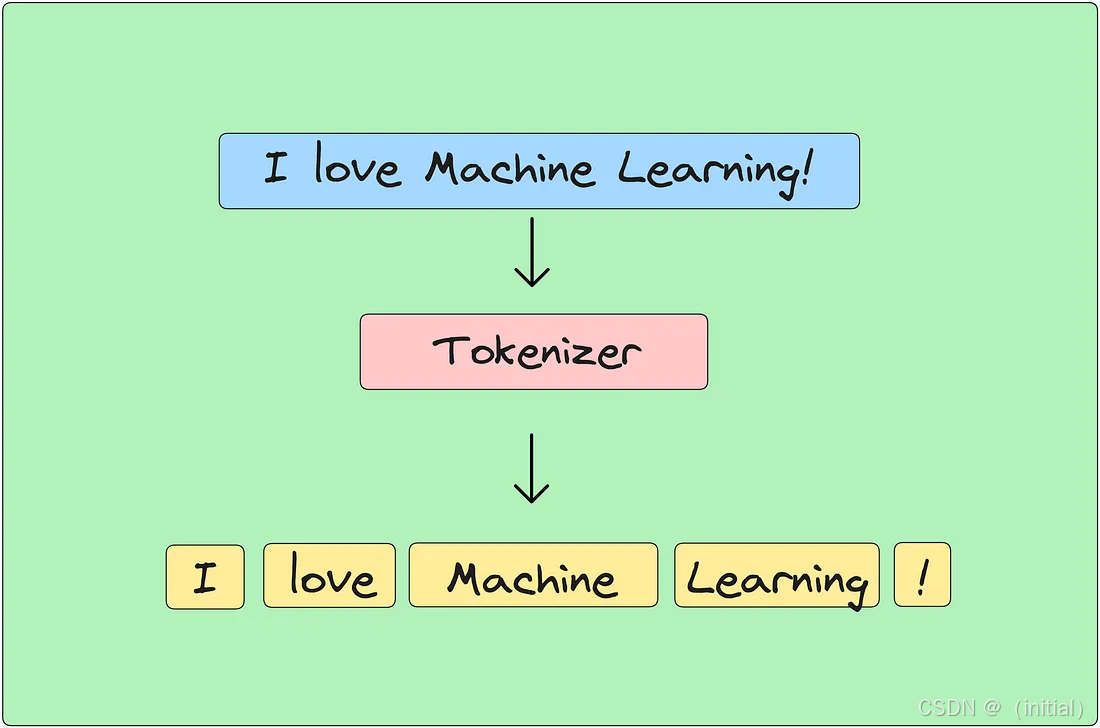
2.1.2 初探文本的向量表示:简单却暴露本质的尝试
当文本被切分成词元后,我们如何用数字来代表它们呢?早期研究者们提出了一些直观的方法:
-
One-Hot Encoding (独热编码):语义真空的“身份证”
最直接的想法是为词典中的每一个唯一词语分配一个独一无二的“身份证号”(索引),然后用一个与词典等长的向量来表示这个词。向量中,只有对应其“身份证号”的维度为1,其余维度均为0。例如,若词典有10000个词,则每个词都由一个10000维的向量表示。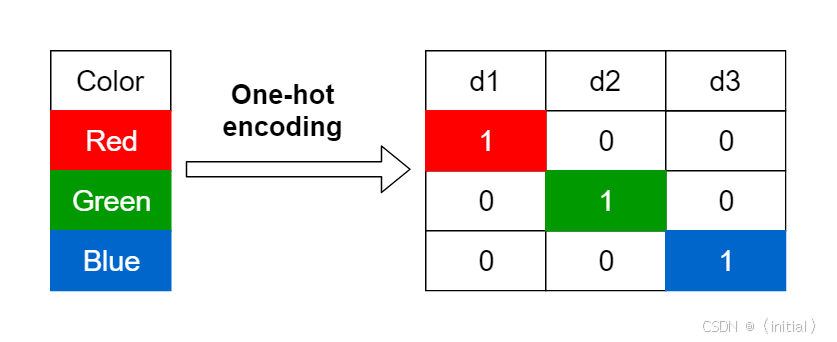
- 核心机制: 简单映射,一一对应。
- 优点: 简单、无参数。
- 致命缺陷: 维度灾难(词典越大,向量维度越高,极度稀疏);语义真空(任意两个不同词的独热编码都是正交的,无法体现它们之间任何语义上的相似性或关联性——“猫”与“狗”的距离等同于“猫”与“桌子”的距离)。这显然与我们对语言的直觉相悖。
-
词袋模型 (Bag-of-Words, BoW):忽略顺序的“词语清单”
为了表示一篇文档而非单个词,词袋模型应运而生。它将文档视为一个装满词元的“袋子”,完全忽略词序和语法结构,只关心袋子中每种词元出现的次数(词频)或是否存在(布尔值)。一篇文档因此可以被表示为一个向量,其维度仍然是词典大小。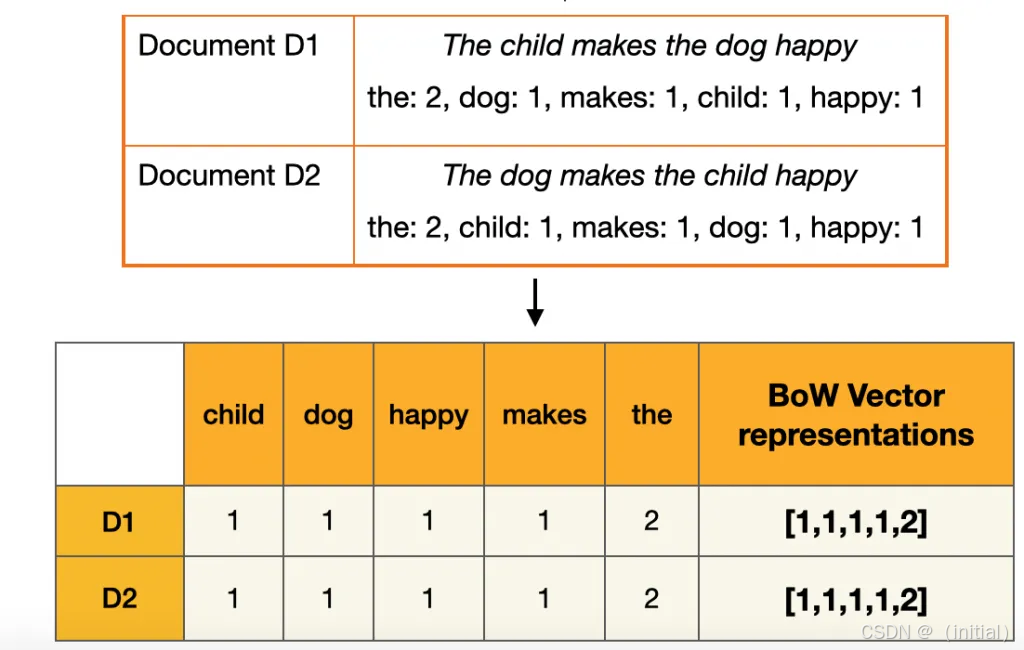
- 核心机制: 统计词频,词序无关。
- 优点: 简单高效,能捕捉文档的主题词汇。
- 局限性: 依然丢失了词序、句法结构等重要信息,对于理解更复杂的语义(如否定、双关)无能为力。且同样面临高维稀疏问题。
-
TF-IDF (Term Frequency-Inverse Document Frequency):赋予词语“权重”的智慧
词袋模型的一个明显问题是,它平等对待所有词语。然而,直觉告诉我们,在某篇文档中频繁出现但在整个文档集合中却很稀有的词,更能代表这篇文档的独特性。TF-IDF正是基于这种洞察,对词袋模型进行了加权优化。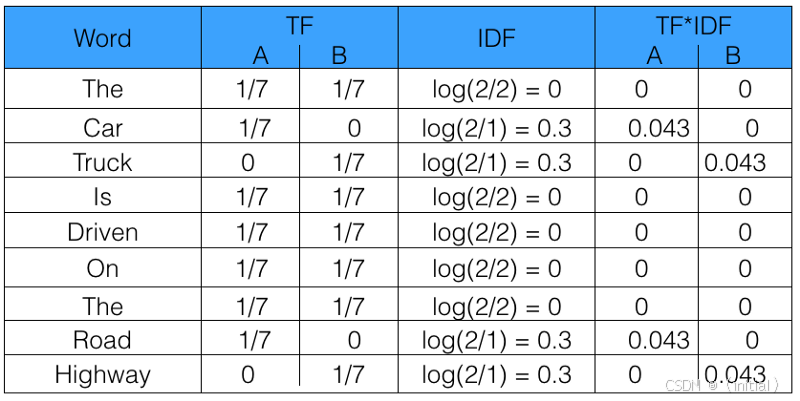
- 核心机制: **TF(词频)**衡量一个词在当前文档中的局部重要性;**IDF(逆文档频率)**则衡量一个词在整个语料库中的全局“区分度”或“信息量”。IDF会惩罚那些普遍存在的高频词(如“人工智能”在AI论文集中可能IDF较低),提升那些在少数文档中高频出现的关键词的权重。最终的TF-IDF值是两者的乘积。
- 优点: 相比BoW,能更好地突出文档的核心关键词,在信息检索和文本分类等任务中表现更佳。
- 局限性: 本质上仍是基于词频统计,依然无法直接捕捉词语间的语义相似性(例如,“计算机”和“电脑”的TF-IDF向量可能依然差异很大)。
这些早期的文本表示方法,虽然在特定简单任务上取得了一定的成功,但它们共同的短板在于未能深入挖掘词语背后丰富的语义内涵。机器仅仅是在“计数”和“匹配”符号,远未达到“理解”的层面。如何让机器真正把握“国王”与“女王”之间的联系,而非仅仅将它们视为两个独立的符号?这便是驱动下一代文本表示技术——词嵌入——诞生的核心诉求。
2.2 词的嵌入新生:让向量承载语义的“灵魂”
为了克服早期表示方法在语义理解上的匮乏,研究者们将目光投向了一种全新的范式——分布式语义表示 (Distributed Semantic Representations),其核心成果便是词嵌入 (Word Embedding)。其目标不再是用孤立的高维稀疏向量来代表词语,而是为每个词学习一个稠密的、低维的、能够捕捉其语义内涵的实数向量。这种表示的关键在于,语义上相似的词,其对应的向量在多维空间中也应该彼此“靠近”。
2.2.1 分布式假设:词义的“环境决定论”
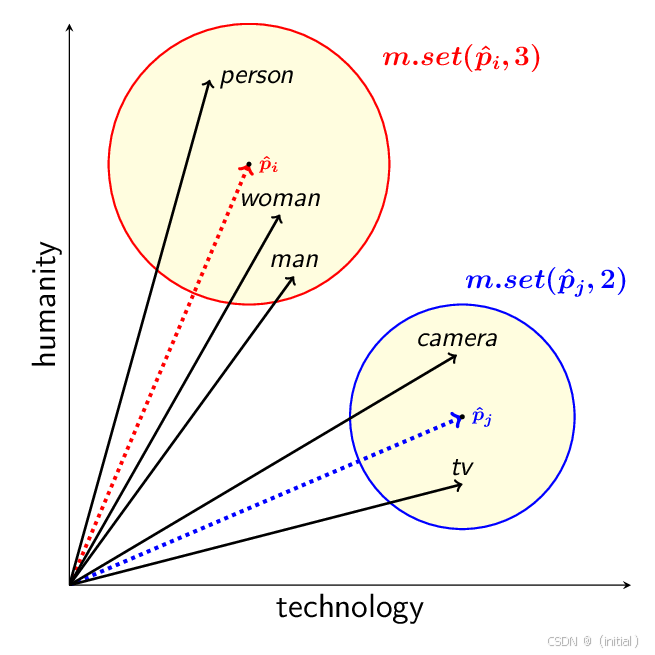
词嵌入技术的理论基石,可以追溯到语言学家J.R. Firth的名言:“You shall know a word by the company it keeps.” 这便是著名的分布式假设 (Distributional Hypothesis)。它认为,一个词的意义,很大程度上是由其经常共同出现的上下文词语所决定的。如果两个词经常出现在相似的语境中,那么它们的语义就很可能相近。例如,“咖啡”和“茶”都经常与“杯子”、“喝”、“热”等词共同出现,因此它们的词嵌入向量在空间中应该比较接近。这为通过大规模文本数据自动学习词义提供了一条可行的路径。
2.2.2 Word2Vec:基于“预测”的语义学习艺术
由Google的Mikolov团队提出的Word2Vec,是词嵌入领域最具影响力的开创性工作之一。它并没有直接去“定义”词的含义,而是巧妙地将学习词向量的过程,转化为一个基于上下文的预测任务。Word2Vec包含两种核心模型架构:
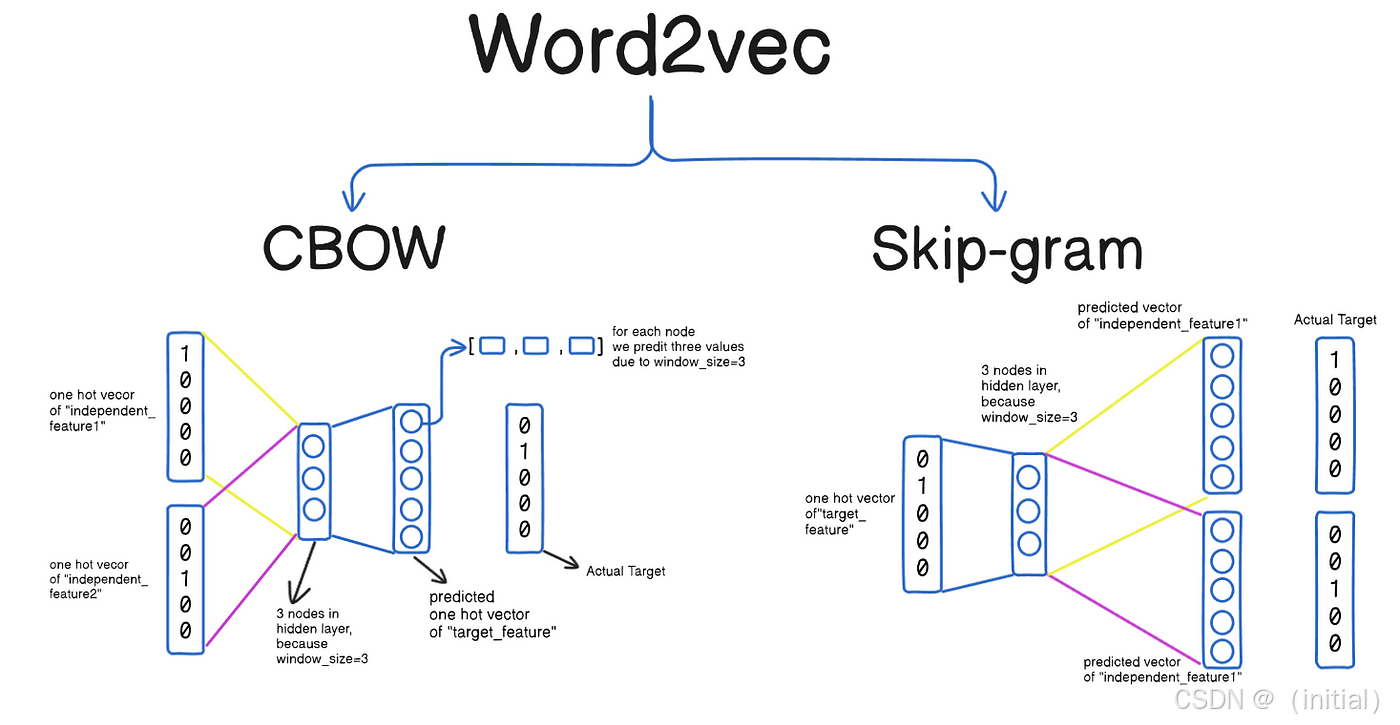
- CBOW (Continuous Bag-of-Words):上下文预测中心词
- 核心机制: 给定一个词的上下文窗口(例如,中心词前后的N个词),CBOW模型的目标是利用这些上下文词的向量表示来预测中心词本身。这可以理解为,模型在学习“当周围出现这些词时,中间最有可能是什么词?”。
- Skip-gram:中心词预测上下文
- 核心机制: 与CBOW相反,Skip-gram模型的目标是根据给定的中心词,来预测其上下文窗口中可能出现的词。这可以理解为,模型在学习“当这个词出现时,它周围最可能伴随哪些词?”。Skip-gram通常在处理大型语料库和学习罕见词表示方面表现更优。
Word2Vec是如何从预测任务中学习到高质量词向量的呢? 关键在于其高效的训练方法。直接使用Softmax对整个词典进行预测计算量巨大。因此,Word2Vec引入了:
- 负采样 (Negative Sampling): 对于每一个真实的“中心词-上下文词”正样本对,从词典中随机抽取若干个不相关的词作为负样本。然后,模型的目标就变成了一个二分类问题:区分给定的词对是正样本还是负样本。这极大地简化了计算,使得模型能够专注于学习区分正负样本的词向量。
- 层次Softmax (Hierarchical Softmax): 另一种加速技巧,它将词典组织成一棵霍夫曼树,每个叶子节点代表一个词。预测一个词就变成了一系列在树上从根节点到叶子节点的二分类决策,路径上的概率相乘即为该词的概率。
Word2Vec学习到的词向量展现了令人惊叹的语义规律性,例如著名的向量运算 vector('king') - vector('man') + vector('woman') 其结果在向量空间中与 vector('queen') 非常接近。这表明词嵌入不仅编码了词的独立含义,还捕捉到了它们之间复杂的语义和句法关系,如同为每个词赋予了独特的“语义指纹”。
2.2.3 GloVe:融合全局统计的智慧 ****
几乎与Word2Vec同时,斯坦福大学的Pennington等人提出了GloVe (Global Vectors for Word Representation)模型,它采取了与Word2Vec不同的策略来学习词向量,更侧重于直接利用全局的词-词共现统计信息。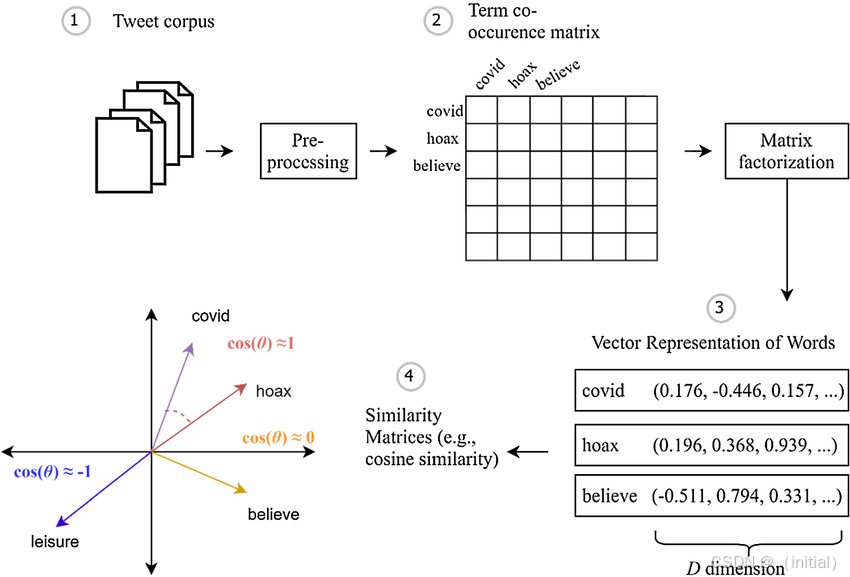
- 核心机制: GloVe认为,词语之间的共现概率比率能够有效地揭示它们之间的语义关系。例如,考虑词
i和词j与一系列“探针词”k的共现情况。如果词i与某个探针词k_1(如“固体”)高度相关,而词j与k_1不相关,同时词j与另一个探针词k_2(如“气体”)高度相关,而词i与k_2不相关,那么共现概率的比率P(k_1|i) / P(k_1|j)就会很大,而P(k_2|i) / P(k_2|j)就会很小。GloVe的目标便是学习词向量w_i,w_j和偏置项,使得它们的函数(如点积)能够很好地拟合这些共现概率的比率。 - 实现方式: 它首先构建一个大规模的词-词共现计数矩阵
X,其中X_ij表示词i和词j在特定上下文窗口内共同出现的次数。然后,通过优化一个加权的最小二乘回归损失函数来学习词向量,损失函数的形式大致为sum(f(X_ij) * (w_i^T * w_j + b_i + b_j - log(X_ij))^2),其中f(X_ij)是一个加权函数,用于降低高频共现词对的权重。
GloVe通过直接建模共现概率,声称能够更有效地利用全局统计信息,并在一些词语相似性基准测试上取得了与Word2Vec相当甚至更好的结果。
2.2.4 FastText:深入词的内部,拥抱形态学 ****
Word2Vec和GloVe都将词语视为不可分割的原子单元进行学习。这种方式面临两大挑战:一是难以处理未登录词 (Out-of-Vocabulary, OOV)——那些在训练时未曾出现过的词;二是无法充分利用词语的内部形态结构信息(如词根、词缀),这对于形态丰富的语言尤为重要。
为了解决这些问题,Facebook AI Research提出的FastText模型引入了子词信息 (Subword Information),特别是字符n-gram。

- 核心机制: FastText将每个词表示为其所有字符n-gram的向量之和(通常还会加上整个词本身的向量,如果它在词典中)。例如,对于词“apple”及其字符3-grams(如“app”, “ppl”, “ple”等),FastText会为每个字符n-gram学习一个向量。一个词的最终向量便是构成它的所有字符n-gram向量的(通常是平均)组合。
- 优势凸显:
- OOV词表示: 即使一个完整的词是OOV的,只要它的某些字符n-gram在训练数据中出现过(例如,一个新词可能由已知的词根和词缀构成),FastText依然能为其构建一个有意义的向量表示。
- 罕见词学习: 对于出现频率较低的词,其字符n-gram可能与其他更常见的词共享,从而能够“借鉴”这些常见词的信息来学习自身的表示,提升罕见词向量的质量。
- 形态学信息的捕捉: 具有相似词缀或词根的词(如“nation”与“national”)其字符n-gram会有较多重叠,使得它们的向量表示在形态学和语义上都更接近。
FastText通过这种深入到词内部结构的方式,显著增强了词嵌入模型对OOV词的处理能力和对词形态的敏感性。
2.2.5 静态“灵魂”的局限:呼唤上下文的动态智慧
词嵌入技术(Word2Vec, GloVe, FastText)无疑是NLP发展史上的巨大飞跃,它们通过各种内在评估(如词语相似性、类比推理)和外在评估(在下游NLP任务中的表现)证明了自身的价值。然而,我们必须清醒地认识到,这些学习到的词向量本质上是静态的 (Static)。这意味着:
- 一词多义的困境依然存在: 对于像“bank”(银行/河岸)这样的多义词,这些模型通常只能为其学习一个固定的、融合了所有可能含义的平均化向量表示。模型无法根据词语所处的具体上下文来区分其当前的确切含义。
- 上下文无关的表示: 一个词的向量表示一旦训练完成,就固定不变了。它不会因为这个词出现在不同的句子、不同的语境中而发生任何动态的调整。例如,“苹果”在“我吃了一个苹果”和“苹果公司发布了新手机”这两句话中,其静态词嵌入是完全相同的。
这些固有的局限性清晰地指明了文本表示技术的下一个进化方向:我们需要一种能够根据上下文动态调整的、更能捕捉语言丰富性、灵活性和歧义性的表示方法。这种对“动态上下文感知”的迫切需求,自然而然地将我们的目光引向了那些能够处理序列信息并保留“记忆”的神经网络模型——循环神经网络(RNN)及其后续更强大的继承者。
2.3 捕捉序列的记忆:循环神经网络 (RNN) 的时序之旅
真实世界中的语言,并非孤立词语的简单集合,词语的顺序、它们之间的依赖关系,共同构成了语言的意义。为了让机器理解这种序列化的信息,循环神经网络 (Recurrent Neural Networks, RNNs) 应运而生,它们的设计天然契合了处理文本、语音等时序数据的需求。
2.3.1 为何钟情于“循环”?序列数据的天然伙伴
传统的全连接神经网络(MLP)在处理每个输入时都是独立的,无法感知输入之间的顺序关系。而CNN虽然能通过卷积核捕捉局部模式,但对于长距离的、非局部的序列依赖也显得力不从心。RNN则通过其独特的循环结构,允许信息在网络内部“流动”和“记忆”,从而在处理序列中的当前元素时,能够考虑到先前元素的影响。
2.3.2 简单RNN (Vanilla RNN) 的“记忆核心”
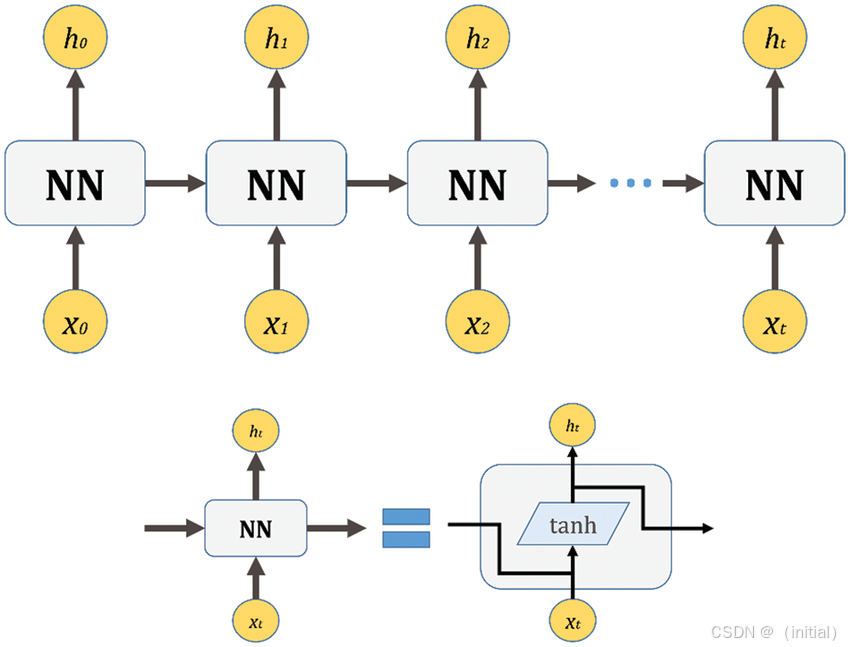
一个简单RNN单元的核心在于其隐藏状态 (Hidden State)。在每个时间步 t,RNN单元接收两个输入:当前时刻的输入数据 x_t(例如一个词的嵌入向量)和上一时刻的隐藏状态 h_{t-1}。它将这两个输入进行某种组合(通常是线性变换后通过激活函数),计算出当前时刻的隐藏状态 h_t,这个 h_t 同时也会作为当前时刻的输出(或用于计算最终输出)。
关键在于,计算 h_t 的权重参数 W(作用于 x_t)和 U(作用于 h_{t-1})在所有时间步都是共享的。这种参数共享机制使得RNN能够处理任意长度的输入序列,并且能够将先前的信息“编码”到隐藏状态中,理论上赋予了模型捕捉序列依赖的能力。
2.3.3 “记忆”的瓶颈:梯度消失与爆炸的困扰
尽管简单RNN的设计在理论上听起来很完美,但在实践中,尤其是在处理较长序列时,它遭遇了严重的训练难题:
- 梯度消失 (Vanishing Gradient): 在通过时间反向传播算法(BPTT)训练RNN时,误差梯度需要从序列的末端一步步向前传播。如果激活函数的导数持续小于1,梯度在传播过程中会指数级衰减,导致距离当前时刻较远的节点的权重几乎无法得到有效更新。这意味着模型难以学习到序列中相隔较远的元素之间的依赖关系,即所谓的“长程依赖”问题。
- 梯度爆炸 (Exploding Gradient): 与梯度消失相反,如果激活函数的导数持续大于1,梯度则可能指数级增长,导致权重更新过大,训练过程变得极不稳定甚至发散。虽然梯度裁剪(Gradient Clipping)等技术可以在一定程度上缓解梯度爆炸,但梯度消失问题更为棘手。
这些“记忆瓶颈”严重限制了简单RNN在实际复杂任务中的应用。
2.3.4 LSTM:为长时记忆而生的“门神”
为了攻克简单RNN的记忆难题,Hochreiter和Schmidhuber于1997年提出了具有里程碑意义的长短期记忆网络 (Long Short-Term Memory, LSTM)。LSTM的核心创新在于引入了精巧的门控机制 (Gating Mechanism),这些“门”如同信息高速公路上的智能收费站,能够有选择地控制信息的流入、流出和保留,从而有效地缓解梯度消失问题,使得模型能够学习到更长距离的依赖关系。
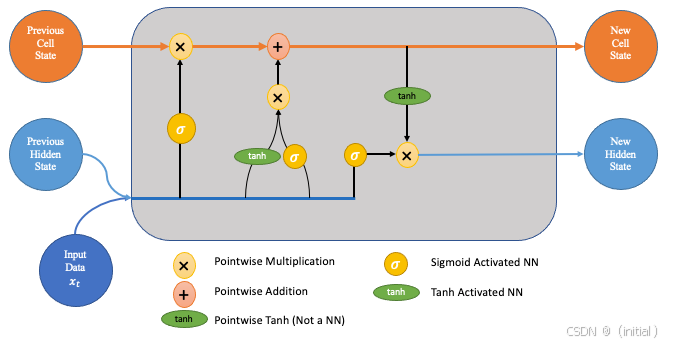
一个标准的LSTM单元内部,除了常规的隐藏状态外,还维护着一个核心的细胞状态 (Cell State, C_t)。这个细胞状态像一条传送带,信息可以在上面几乎无衰减地流动,是LSTM实现长时记忆的关键。控制这条传送带运作的,是三个关键的“门”:
- 遗忘门 (Forget Gate, f_t): 它的职责是决定从上一时刻的细胞状态
C_{t-1}中“忘记”哪些信息。它会审视上一时刻的隐藏状态h_{t-1}和当前输入x_t,然后通过一个Sigmoid函数为C_{t-1}中的每个部分输出一个0到1之间的值(0代表完全遗忘,1代表完全保留)。 - 输入门 (Input Gate, i_t): 它负责决定哪些新的信息将被“写入”到当前的细胞状态中。这个过程分为两步:首先,一个Sigmoid层决定哪些值需要更新;然后,一个tanh层创建一个新的候选值向量
Ĉ_t,这些候选值可能会被添加到细胞状态中。 - 输出门 (Output Gate, o_t): 它控制着细胞状态中的哪些信息将被用作当前时刻的隐藏状态
h_t并输出。细胞状态会先经过一个tanh函数(将其值缩放到-1到1之间),然后与输出门的Sigmoid输出相乘,得到最终的隐藏状态。
通过这三个门的协同工作,LSTM能够灵活地更新和使用其细胞状态,有效地“记住”长期依赖信息,同时“忘记”不重要的短期细节。
2.3.5 GRU:LSTM的精简与高效搭档 ****
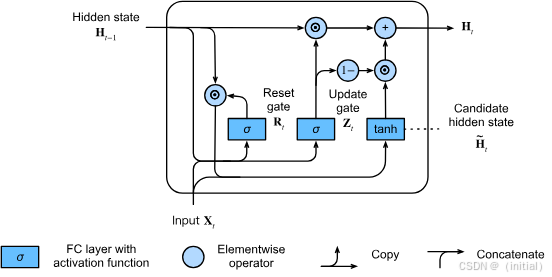
在LSTM之后,Cho等人提出了门控循环单元 (Gated Recurrent Unit, GRU),它是LSTM的一个流行且更简洁的变体。GRU将LSTM中的遗忘门和输入门巧妙地合并为一个单一的更新门 (Update Gate, z_t),并且它没有独立的细胞状态,而是直接对隐藏状态进行操作。此外,GRU还引入了一个重置门 (Reset Gate, r_t)。
- 更新门 (z_t): 类似于LSTM的遗忘门和输入门的组合,它决定了在多大程度上保留前一时刻的隐藏状态,以及在多大程度上接受根据当前输入计算出的新的候选隐藏状态。
- 重置门 (r_t): 决定在计算新的候选隐藏状态时,应该在多大程度上“忽略”前一时刻的隐藏状态。当重置门接近0时,模型会更多地依赖当前输入。
由于GRU的门控结构比LSTM更简单,其参数量也更少,通常在训练速度上会略快一些,并且在许多任务上能达到与LSTM相当的性能。
2.3.6 RNN家族的拓展与应用边界
为了更好地利用上下文信息,研究者们还提出了双向RNN (Bidirectional RNN, BiRNN)。BiRNN由两个独立的RNN(可以是简单RNN、LSTM或GRU)组成:一个按时间正向处理序列,另一个按时间反向处理序列。在每个时间步,两个方向的RNN的隐藏状态会被拼接起来,作为该时间步的最终表示。这使得模型在预测或表示当前词时,能够同时考虑到其前文和后文的信息,对于许多NLP任务(如命名实体识别、情感分析)都带来了显著的性能提升。
RNN及其变体,凭借其捕捉序列动态信息的能力,在机器翻译(作为Encoder-Decoder架构的核心组件)、语言建模、文本生成、情感分析、语音识别等领域都曾扮演过核心角色,并取得了巨大的成功。然而,RNN固有的顺序计算依赖(即当前时间步的计算必须等待前一时间步完成)使其难以充分利用现代GPU的并行计算能力。此外,尽管LSTM和GRU极大地缓解了长程依赖问题,但在处理极长的序列时,信息传递的效率和有效性仍然会受到挑战。这些固有的局限性,呼唤着一种全新的、更强大的序列建模范式的出现。
2.4 点亮关键:注意力机制 (Attention Mechanism) 的革命 —— 让机器学会“聚焦”
尽管循环神经网络(RNN)及其变体如LSTM和GRU在序列建模上取得了显著进展,有效地缓解了梯度消失问题并提升了对长程依赖的捕捉能力,但它们并非万能的灵药。当研究者们将目光投向更具挑战性的任务,如长文本的机器翻译或需要精细理解的问答系统时,一个固有的瓶颈逐渐显现:编码器-解码器(Encoder-Decoder)架构中的信息压缩问题。
2.4.1 瓶颈的呼唤:当固定长度的“记忆”不堪重负
想象一下,我们要将一篇长长的中文小说翻译成英文。传统的基于RNN的Encoder-Decoder模型,其编码器会勤勤恳恳地阅读完整部中文小说,然后试图将所有信息——字词的含义、句法的结构、段落的逻辑、乃至作者的情感——都压缩成一个固定长度的向量,我们称之为“上下文向量(Context Vector)”。解码器在生成英文译文时,唯一的“参考资料”就是这个上下文向量。不难想象,当原文非常长时,这个小小的向量如同一个被塞得满满当当的行李箱,不可避免地会丢失许多重要的细节,导致翻译质量的下降。这便是所谓的“信息瓶颈”:一个固定长度的向量,如何能承载任意长度输入序列的全部精髓?
人类译者在工作时,显然不会这样做。他们会反复回顾原文,在翻译某个特定词语或句子时,有针对性地聚焦于原文中与之最相关的部分。那么,机器能否也学会这种“聚焦”的能力呢?答案是肯定的,而实现这一目标的关键,便是注意力机制 (Attention Mechanism)。它的出现,如同为机器智能点亮了一盏聚光灯,使其能够在浩瀚的信息海洋中,精准地捕捉到最关键的浪花。
2.4.2 “哪里重要看哪里”:Seq2Seq模型中的注意力解放
Bahdanau等人于2014年首次将注意力机制引入神经机器翻译领域,其思想堪称一次解放。他们提出,解码器在生成每一个目标词时,不应再仅仅依赖于那个单一的、静态的上下文向量。相反,解码器应该被赋予一种“主动查看”编码器输出序列的能力。 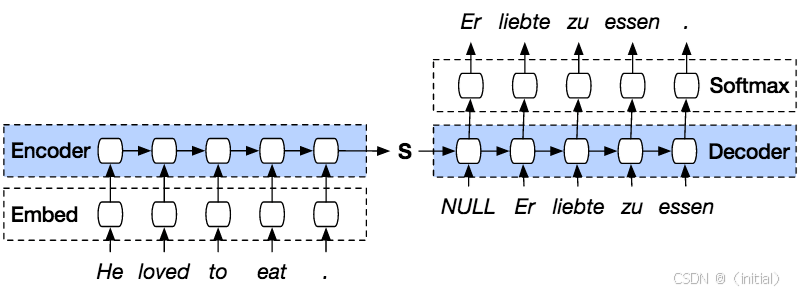
这种“查看”是如何实现的呢?其核心在于以下步骤:
- 相关性评估(计算对齐分数): 在解码的每一步,解码器的当前状态(比如当前隐藏层输出)会作为“查询(Query)”,去“审视”编码器输出的每一个时间步的隐藏状态(这些可以看作是输入序列中每个词的“键(Key)”和“值(Value)”的某种体现)。通过一个小型神经网络(如Bahdanau使用的加性注意力)或简单的点积运算(如Luong等人提出的乘性注意力 ****),计算出解码器当前状态与编码器每个位置输出的相关性分数,即“对齐分数”。这个分数越高,表明输入序列的那个部分对当前解码步骤越重要。
- 权重归一化(注意力权重): 这些原始的对齐分数会经过一个Softmax函数进行归一化,转换成一组非负且总和为1的“注意力权重”。这些权重清晰地指明了在当前解码时刻,应该对输入序列的哪些部分投入多少“注意力”。
- 动态上下文向量的生成: 最后,编码器的各个时间步的隐藏状态(Values)会根据这些注意力权重进行加权求和,形成一个为当前解码步骤“量身定制”的动态上下文向量。这个向量不再是固定不变的,而是随着解码的进行,根据当前需要关注的输入部分而不断变化。
通过这种方式,注意力机制赋予了模型一种“软对齐”的能力,它能够动态地决定在生成输出序列的某个部分时,应该重点关注输入序列的哪些部分。这不仅显著提升了长序列任务(如机器翻译)的性能,更重要的是,它为我们理解模型“在想什么”提供了一扇窗口——通过可视化注意力权重,我们可以直观地看到模型在进行决策时,将注意力集中在了哪些输入信息上。
2.4.3 “我与我相关”:自注意力机制 (Self-Attention) 的内在洞察
注意力机制的威力并不仅限于连接编码器和解码器。一个更具革命性的想法是:让序列内部的元素也相互“关注”,从而更好地理解序列自身的内部结构和依赖关系。 这便是自注意力机制 (Self-Attention 或 Intra-Attention)。
想象一下句子:“The animal didn’t cross the street because it was too tired.” 我们人类可以轻易理解这里的“it”指代的是“The animal”。自注意力机制正是为了让模型也能捕捉到这种句子内部的指代关系、词语间的相互依赖等。
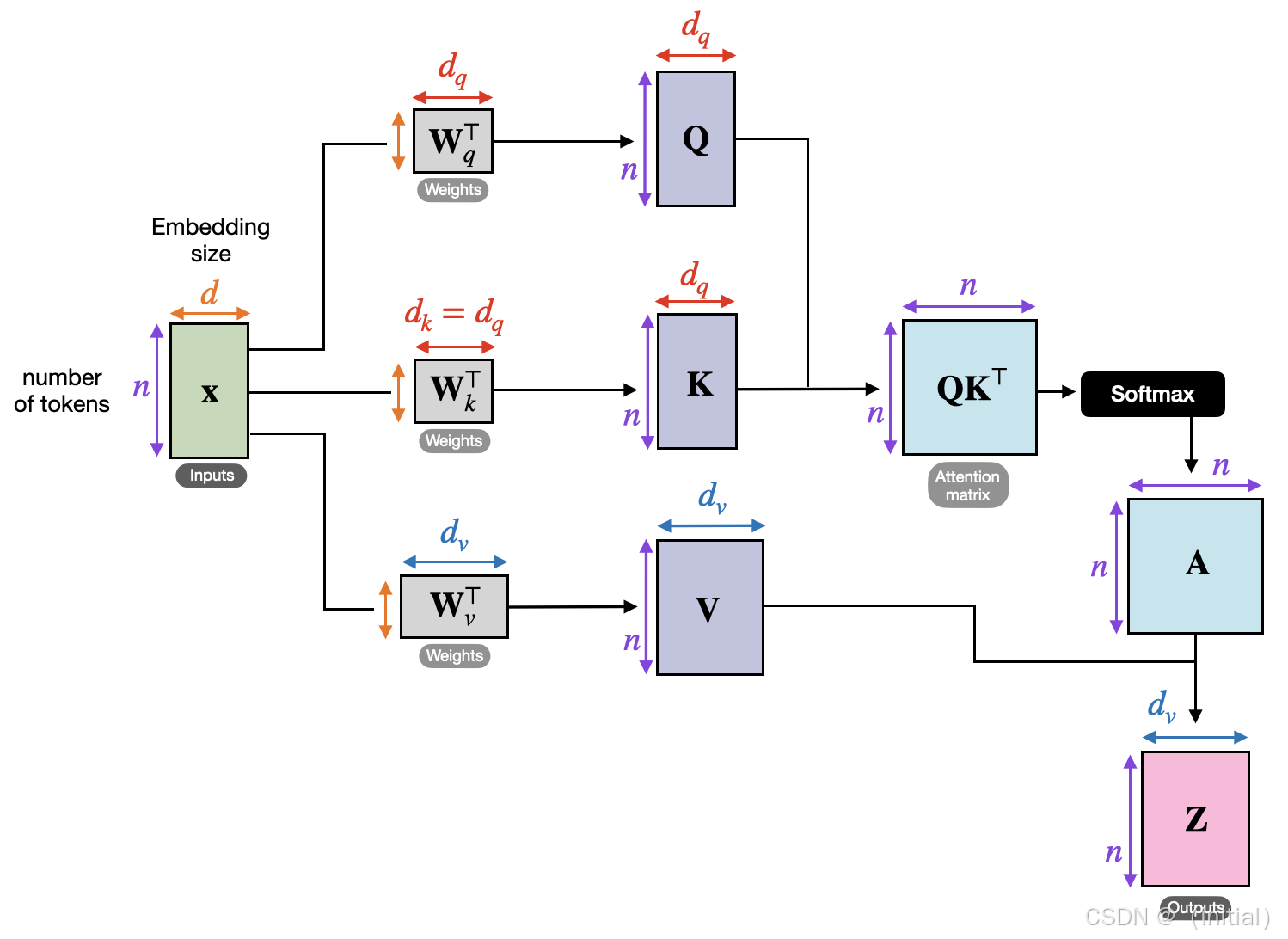
在自注意力中,序列中的每一个词元(token)都会扮演三个角色(通过对原始词嵌入进行不同的线性变换得到):
- 查询 (Query, Q): 代表当前词元想要了解的信息,或者说它向其他词元发出的“提问”。
- 键 (Key, K): 代表序列中其他(包括自身)词元所携带的,可以被“查询”的“标签”或特征。
- 值 (Value, V): 代表序列中其他(包括自身)词元实际包含的、在被“关注”到时可以提供的信息内容。
对于序列中的每一个词元,它的Query向量会与所有词元(包括自身)的Key向量进行相似度计算(通常是点积),得到一组分数。这些分数经过缩放(例如,除以 sqrt(d_k),其中 d_k 是键向量的维度,以防止点积过大导致梯度问题)和Softmax归一化后,就得到了该词元对序列中所有其他词元的注意力权重。最后,这些权重被用来对所有词元的Value向量进行加权求和,得到该词元经过自注意力机制增强后的新表示。
这个过程听起来复杂,但其核心在于:每个词的新表示,都是基于其与句子中所有其他词(包括自身)的相互关系(注意力权重)动态计算出来的。 它不再像RNN那样需要通过隐藏状态逐步传递依赖信息,而是可以直接建立任意两个位置之间的联系。这种能力,为后续Transformer模型的诞生奠定了至关重要的基础,也标志着NLP领域对序列依赖建模方式的一次深刻变革。
2.5 Transformer:驾驭序列的“变形金刚”——“Attention Is All You Need” ****
2017年,Vaswani等人在其里程碑式的论文 “Attention Is All You Need” 中提出了Transformer模型,彻底革新了序列建模领域。这篇文章的标题本身就极具宣言性,它大胆地宣称:我们不再需要循环神经网络,注意力机制本身就足够强大,足以构建出高性能的序列处理模型! 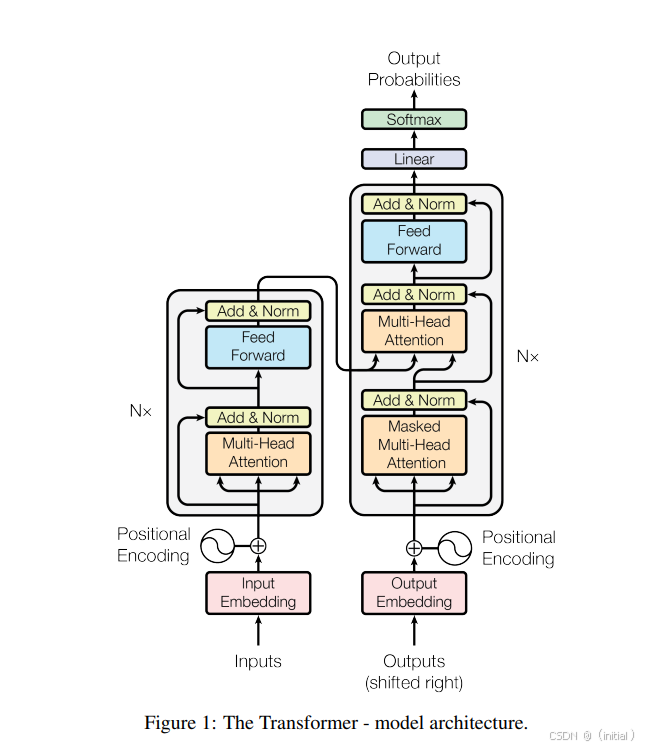
2.5.1 核心思想:注意力即一切,并行筑基石
Transformer的核心哲学是对RNN循环结构的彻底颠覆。RNN的“一步接一步”的计算方式,虽然直观地模拟了时序过程,但也成为了其并行计算的瓶颈。Transformer则勇敢地“砍掉”了循环连接,完全依赖注意力机制,特别是多头自注意力机制,来捕捉序列内部以及序列之间的依赖关系。 这种设计带来的最直接的好处就是计算的高度并行化。序列中的所有词元可以同时进行注意力计算,极大地提升了训练速度,使得在更大规模的数据集上训练更深、更复杂的模型成为可能。同时,由于注意力机制可以直接计算任意两个位置之间的关联强度,它在捕捉长程依赖方面也比RNN更具优势。
Transformer模型通常也沿用了经典的Encoder-Decoder架构,但这“新瓶”里装的却是完全不同的“新酒”。
2.5.2 编码器 (Encoder) 的精密构造
Transformer的编码器并非单一组件,而是由N个(例如,原论文中N=6)完全相同的层堆叠而成。每一层都像一个精密的“信息加工单元”,包含两个核心的子层:
- 多头自注意力 (Multi-Head Self-Attention):
- 为何需要“多头”的智慧? 单一的自注意力机制可能只关注到输入信息的一个方面,如同只用一种视角观察事物。多头注意力则允许模型从多个不同的“表示子空间”(representation subspaces)并行地学习和关注不同类型的依赖关系。 例如,一个头可能关注句法依赖,另一个头可能关注语义关联,还有一个头可能关注词语间的位置关系。
- 具体实现上,输入的Query (Q), Key (K), Value (V) 向量(对于编码器的自注意力层,Q, K, V均来自上一层的输出)会被分别进行
h次不同的线性投影(h即为头的数量),得到h组独立的Q_i, K_i, V_i。然后,每一组Q_i, K_i, V_i都会独立地进行一次Scaled Dot-Product Attention计算,得到h个注意力输出。最后,这h个输出会被拼接(Concatenate)起来,再经过一次线性投影,得到该多头自注意力子层的最终输出。这种“多视角审视再融合”的机制,极大地增强了模型的表达能力。
- 逐位置前馈网络 (Position-wise Feed-Forward Networks, FFN):
- 在多头自注意力之后,每个位置的输出表示会独立地通过一个简单但有效的前馈网络。这个FFN通常由两层线性变换和一个ReLU(或GELU等)激活函数组成:
FFN(x) = max(0, xW_1 + b_1)W_2 + b_2。 - 值得注意的是,虽然这个FFN在序列的每个位置上都是独立应用的(参数在不同位置间共享,但在不同层间不共享),但它为模型引入了必要的非线性,使得模型能够学习更复杂的函数。
- 在多头自注意力之后,每个位置的输出表示会独立地通过一个简单但有效的前馈网络。这个FFN通常由两层线性变换和一个ReLU(或GELU等)激活函数组成:
在每个子层(无论是多头自注意力还是FFN)的输出端,Transformer都巧妙地运用了两个关键技术来稳定和加速训练:
- 残差连接 (Residual Connections): 每个子层的输入
x会被直接加到该子层的输出Sublayer(x)上,即x + Sublayer(x)。这种“跳跃连接”允许梯度更直接地反向传播,有效地缓解了深度网络中的梯度消失问题,使得训练更深的模型成为可能。 - 层归一化 (Layer Normalization): 在残差连接之后,会进行层归一化。与批量归一化(Batch Normalization)对一个批次内所有样本的同一特征进行归一化不同,层归一化是对单个样本的所有特征进行归一化。它有助于稳定每层输入的分布,加速模型收敛,并且对批次大小不敏感。
编码器的N层结构,每一层都在不断地对输入序列的表示进行提炼和丰富,最终输出一组能够代表整个输入序列的高层语义特征。
2.5.3 解码器 (Decoder) 的协同生成
Transformer的解码器同样由N个相同的层堆叠而成,其目标是根据编码器提供的输入序列信息,自回归地生成输出序列(例如,在机器翻译中生成目标语言的句子)。解码器的每一层比编码器多了一个关键的子层:
- 掩码多头自注意力 (Masked Multi-Head Self-Attention): 这是解码器内部的第一个自注意力层。与编码器的自注意力机制类似,它允许解码器中的每个位置关注到先前已生成的所有位置。但与编码器不同的是,这里必须引入一个**“掩码(mask)”。在预测(或训练时模拟预测)第
i个输出词元时,模型只能关注到第1到i-1个已经生成的词元,而不能“偷看”第i个及其之后的词元。这是为了确保模型的自回归特性**,即当前输出的生成仅依赖于已生成的历史和编码器的输入。 - 编码器-解码器注意力 (Encoder-Decoder Attention / Cross-Attention): 这是解码器与编码器进行信息交互的核心环节。在这个子层中,Query向量来自于上一层解码器的输出(即解码器自身正在处理的信息),而Key和Value向量则来自于编码器的最终输出序列。这使得解码器的每个位置都能够“审视”整个输入序列的编码表示,并从中提取与当前生成步骤最相关的信息。这与Seq2Seq模型中传统的注意力机制作用类似,但这里同样是多头的。
- 逐位置前馈网络 (Position-wise Feed-Forward Networks): 与编码器中的FFN结构和作用完全相同。
同样,解码器的每个子层之后也都采用了残差连接和层归一化。解码器最终会输出每个可能词元的概率分布,从而生成输出序列。
2.5.4 为“无序”注入“时序”:位置编码的智慧
Transformer的一个显著特点是,其核心的自注意力机制和前馈网络本身并不包含任何关于序列中元素顺序的信息——如果你打乱输入序列中词元的顺序,自注意力的输出(在不考虑位置编码的情况下)也会相应地被打乱,但每个词元自身的表示(相对于其他词元计算得到的)可能不会有本质变化。这与RNN天然的顺序处理能力形成了鲜明对比。
为了让模型能够利用词语在序列中的位置信息(这对于理解语言至关重要),Transformer在将词嵌入向量输入到编码器和解码器的第一层之前,会给它们加入一个位置编码 (Positional Encoding) 向量。
原始Transformer论文中提出了一种基于正弦和余弦函数的固定位置编码方案。对于位置pos和维度i,其编码计算方式为:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
其中 d_model 是词嵌入的维度。这种函数选择的巧妙之处在于,对于任意固定的偏移量k,PE(pos+k) 可以表示为 PE(pos) 的一个线性函数。这意味着模型可能更容易学习到相对位置信息。此外,它还能处理比训练序列更长的序列。
后来,也发展出了可学习的位置编码(Learned Positional Embeddings),即像词嵌入一样,将位置编码也作为模型参数进行学习。
2.5.5 Transformer的革命性影响:NLP新纪元的开启者
Transformer的诞生,犹如在NLP领域投下了一颗“深水炸弹”,其影响深远:
- 并行计算带来的效率革命: 彻底摆脱了RNN的顺序依赖,使得训练更大、更深的模型成为可能。
- 长程依赖的卓越捕捉能力: 自注意力机制可以直接计算任意两个位置之间的关联,极大地提升了对长距离上下文的理解。
- 强大的可扩展性和通用性: Transformer不仅在NLP领域取得了巨大成功,其核心思想还被迅速推广到计算机视觉(Vision Transformer)、语音处理、强化学习乃至多模态领域。
- 预训练语言模型的基石: 正是Transformer强大的表示能力和可扩展性,为后续BERT、GPT等大规模预训练语言模型的辉煌成就铺平了道路。
可以说,Transformer不仅是一种模型架构,更是一种强大的序列信息处理范式,它深刻地改变了我们构建和理解人工智能系统的方式。
2.6 巨人的肩膀:预训练语言模型 (PLMs) 的时代 —— 通用语言智能的曙光
在Transformer这座坚实的“肩膀”之上,研究者们开创了预训练-微调 (Pre-training and Fine-tuning) 的新范式,将自然语言处理带入了一个全新的时代——大规模预训练语言模型(PLMs)的时代。其核心思想是:先利用海量的、无标注的文本数据,通过精心设计的自监督学习任务,训练一个通用的、能够理解语言深层结构和语义的“基础模型”;然后,针对具体的下游NLP任务(如情感分析、文本分类、问答等),仅用少量有标注的数据对这个预训练模型进行“微调”,使其快速适应特定任务的需求。 这种“通用知识学习 + 特定任务适配”的模式,极大地提升了NLP技术的性能和效率。
2.6.1 BERT:双向奔赴,深度理解的里程碑 ****
Google于2018年提出的BERT (Bidirectional Encoder Representations from Transformers),是预训练语言模型领域的开创性工作,它如同一座灯塔,照亮了深度语言理解的前进方向。
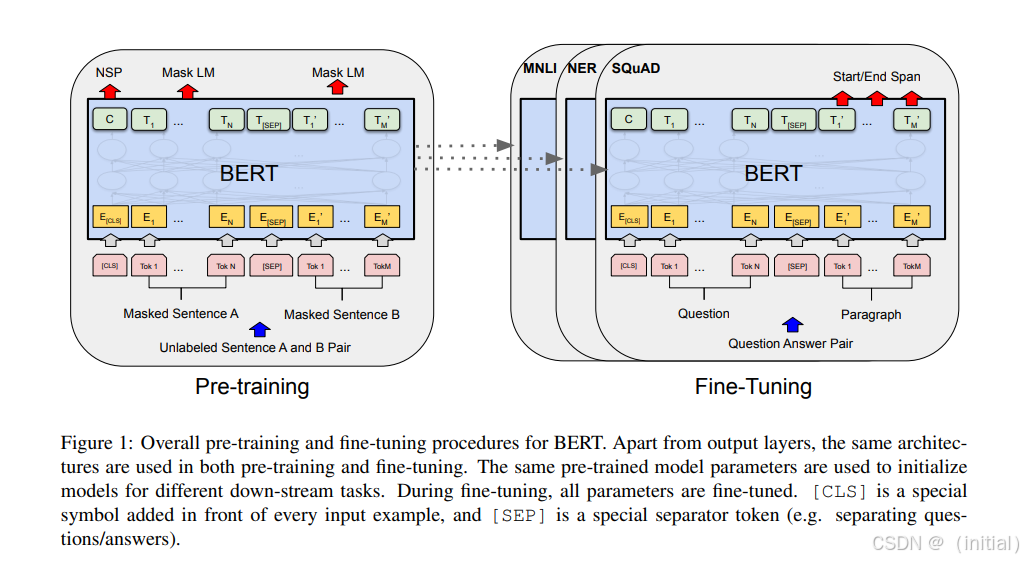
- 核心思想的突破——真正的“双向”: 在BERT之前,主流的语言模型要么是单向的(例如传统的从左到右的语言模型,或GPT的早期版本),要么是通过简单拼接两个独立训练的单向模型输出来实现“伪双向”。BERT的革命性在于,它基于Transformer的编码器部分,通过其独特的预训练任务,使得模型在预测或表示一个词元时,能够同时有效地利用其左侧和右侧的所有上下文信息,从而获得对词元更深刻、更准确的语义理解。
- 巧妙的预训练任务——“完形填空”与“句子关系判断”: 为了实现这种双向理解,BERT设计了两个巧妙的自监督学习任务:
- 掩码语言模型 (Masked Language Model - MLM): 这是BERT的核心创新。在输入文本序列中,随机选择约15%的词元进行“掩码”处理——其中80%的情况替换为一个特殊的
[MASK]标记,10%的情况替换成一个随机的其他词元,10%的情况保持原词元不变(这样做是为了缓解预训练和微调阶段输入不一致的问题)。然后,模型的任务就是根据未被掩码的上下文,预测这些被掩码的原始词元。这个过程非常像我们做英语试卷中的“完形填空”,它迫使模型去理解词元间的复杂依赖关系和上下文语义。 - 下一句预测 (Next Sentence Prediction - NSP): 为了让模型理解句子之间的关系(这对于问答、自然语言推理等任务非常重要),BERT还引入了NSP任务。模型接收一对句子A和B作为输入,并判断句子B是否是句子A在原始语料中的下一句。这是一个二分类任务。不过,后来的研究(如RoBERTa ****)发现NSP任务对某些下游任务的贡献有限,甚至可能带来负面影响,因此一些后续模型对其进行了改进或移除。
- 掩码语言模型 (Masked Language Model - MLM): 这是BERT的核心创新。在输入文本序列中,随机选择约15%的词元进行“掩码”处理——其中80%的情况替换为一个特殊的
- 特殊的输入表示与广泛的下游应用: BERT在每个输入序列的开头都添加了一个特殊的
[CLS](Classification)标记。这个标记对应的最终隐藏状态被设计为整个输入序列的聚合表示,可以直接用于文本分类、情感分析等任务。当输入为句子对时,两个句子之间用[SEP](Separator)标记分隔。通过在预训练好的BERT模型之上添加一个简单的输出层(例如一个全连接层),并用特定任务的数据进行微调,BERT就能在广泛的NLP下游任务上取得SOTA(State-of-the-Art)的性能。
BERT的出现,极大地推动了NLP领域的发展,并迅速成为后续许多研究工作的基础。
2.6.2 GPT系列:生成式预训练的巨擘,语言创造力的释放
与BERT专注于通过双向上下文进行深度理解不同,由OpenAI引领的GPT (Generative Pre-trained Transformer) 系列模型(从早期的GPT-1 、GPT-2,到引发全球关注的GPT-3、驱动ChatGPT的更先进模型,乃至最新的GPT-4),则将目光聚焦于强大的文本生成能力和令人惊叹的通用性。
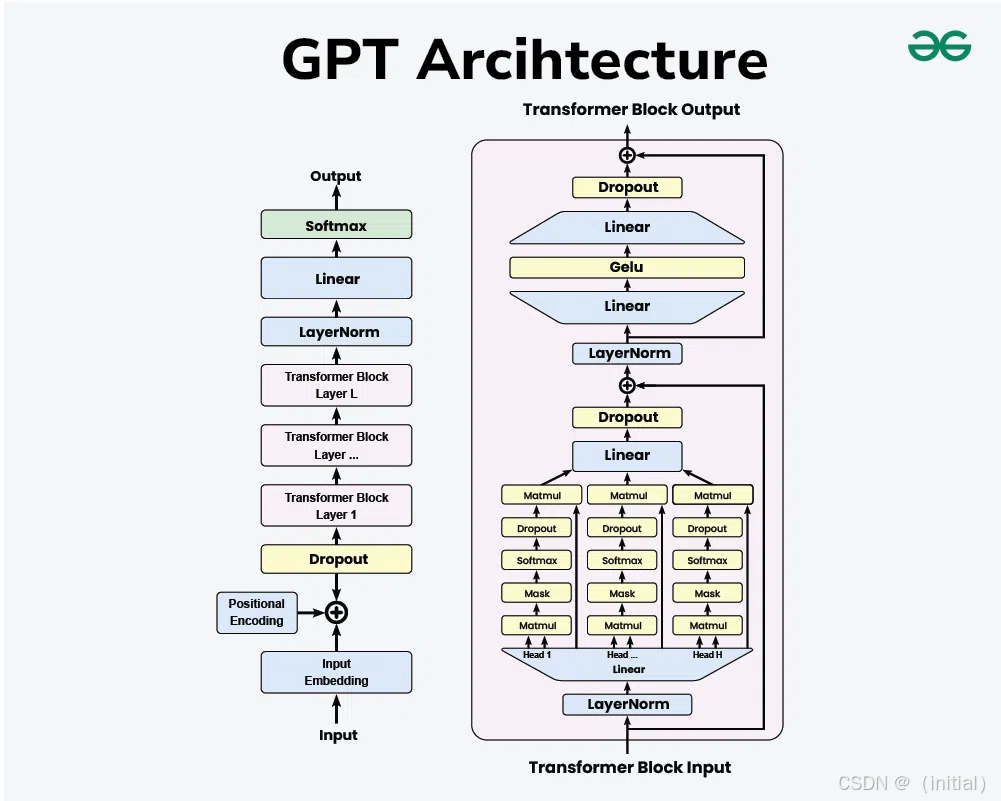
- 核心思想的坚守——单向自回归的魅力: GPT系列模型主要基于Transformer的解码器部分(通常去除了Encoder-Decoder Attention,只保留Masked Self-Attention),并坚持采用经典的单向自回归语言模型 (Autoregressive Language Model) 的预训练目标。这意味着模型在预测当前词元时,只能利用其左侧(即先前已生成)的上下文信息,依次从左到右生成文本。这种设计天然适合文本生成任务。
- “大力出奇迹”——规模效应的极致探索: GPT系列成功的核心秘诀之一,在于其对“规模效应(Scaling Law)”的极致追求。通过不断地、指数级地扩大模型的参数量(从GPT-1的1.17亿,到GPT-2的15亿,再到GPT-3的1750亿,乃至后续更庞大的模型)、训练数据的规模(从数GB到数TB乃至PB级别)以及投入的计算资源,GPT模型展现出了令人瞠目结舌的能力进化:
- 少样本 (Few-shot) 学习: GPT-3等大型模型在没有针对特定任务进行微调的情况下,仅通过在输入提示(Prompt)中给出少量(例如1到几十个)任务相关的示例,就能在新输入上表现出相当不错的性能。
- 零样本 (Zero-shot) 学习: 对于某些任务,甚至无需提供任何示例,仅通过清晰的任务描述(包含在Prompt中),模型就能理解并执行。
- 上下文学习 (In-Context Learning - ICL): 模型似乎能够从Prompt中给出的示例“当场学习”任务模式并进行泛化,这是一种非常独特的、与传统微调不同的学习方式。
- 提示学习 (Prompt Learning) 的兴起: GPT的强大能力也催生了与模型交互的新范式——提示学习。研究者们发现,通过精心设计输入给模型的文本提示(Prompt),可以有效地引导模型执行各种复杂的任务,而无需修改模型本身的参数。这使得利用大型预训练模型的门槛大大降低。
GPT系列模型的成功,不仅在于其强大的文本生成能力,更在于它们所展现出的作为“通用基础模型”的巨大潜力,能够通过适当的引导适应各种不同的自然语言任务。
2.6.3 群星璀璨:预训练模型家族的繁荣
在BERT和GPT这两大巨头的引领下,预训练语言模型领域迎来了百花齐放的繁荣景象。众多研究者在模型结构、预训练任务、训练策略等方面进行了不懈的探索和创新,涌现出一大批优秀的PLMs:
- **RoBERTa (A Robustly Optimized BERT Pretraining Approach) **: Facebook AI对BERT的预训练过程进行了细致的优化,包括使用更大的训练批量、更长的训练时间、动态掩码机制(每次向模型输入同一序列时,掩码的词元都不同)、去除NSP任务等,从而在多个基准测试上超越了BERT。
- **XLNet (Generalized Autoregressive Pretraining for Language Understanding) **: 试图结合自回归(AR,如GPT)和自编码(AE,如BERT)模型的优点。它提出了一种排列语言模型(Permutation Language Modeling),通过对输入序列的词元进行随机排列,然后自回归地预测排列后的序列中的词元,从而在一定程度上实现了双向上下文信息的利用,同时保留了自回归模型的生成能力。
- ALBERT (A Lite BERT for Self-supervised Learning of Language Representations) **: 为了解决BERT等模型参数量过大、训练和推理开销高昂的问题,ALBERT通过两种主要的参数削减技术——词嵌入参数的因式分解(将大的词嵌入矩阵分解为两个小的矩阵)和跨层参数共享**(不同Transformer层共享部分或全部参数)——显著减少了模型参数,同时在许多任务上保持了与BERT相当甚至更好的性能。
- **ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately) **: 提出了一种更高效的预训练任务——替换词元检测 (Replaced Token Detection)。它使用一个小型的生成器网络来替换输入序列中的部分词元,然后训练一个判别器网络来判断每个词元是否被替换过。这种方式使得模型可以对所有输入词元进行学习(而不是像MLM那样只学习被掩码的15%),从而大幅提升了训练效率和性能。
- T5 (Text-to-Text Transfer Transformer) **** 和 BART (Bidirectional and Auto-Regressive Transformers) **: 这类模型致力于构建一个统一的文本到文本框架 (Text-to-Text Framework)**,将所有NLP任务(包括分类、问答、摘要、翻译等)都形式化为“输入一段文本,生成一段文本”的任务。例如,对于情感分类,输入可以是“classify: 这部电影太棒了!”,输出可以是“positive”。T5和BART通过设计灵活的编码器-解码器结构和多样的去噪自编码预训练任务,展现了强大的通用性和迁移学习能力。
此外,还有如ERNIE(引入知识图谱增强表示)、StructBERT(引入词序和句间结构信息)、DeBERTa(引入解耦注意力机制)等众多优秀工作,不断推动着预训练语言模型向更强大、更高效、更通用的方向发展。
2.6.4 PLMs的成功基石与深远影响:为多模态铺路
大规模预训练语言模型的辉煌成就,并非偶然。它们是海量多样化的文本数据、参数量巨大的深度神经网络模型(主要是Transformer)、强大且可获取的计算能力(GPU/TPU集群)以及巧妙有效的自监督学习任务这几大核心要素协同作用的必然结果。
PLMs的出现,彻底改变了NLP领域的研究范式。它们不仅在几乎所有的自然语言理解和生成任务上都取得了SOTA的性能,更重要的是,它们学习到的丰富的语言知识、强大的语义表示能力以及一定的推理和常识能力,使其成为构建更高级、更复杂人工智能系统的理想“组件”。正如我们将在后续章节中看到的,这些强大的预训练语言模型,正是当前最前沿的大型多模态模型(MLLMs)赖以构建其语言理解与生成核心的“智能大脑”。没有PLMs的奠基,MLLMs的崛起将无从谈起。
2.7 本章小结与承上启下:语言之钥已握,静待视觉之门
在本章中,我们一同回顾了文本信息从原始符号转化为机器可计算表示的漫长而精彩的旅程。我们从早期略显粗糙但奠定基础的统计方法(如词袋模型、TF-IDF)出发,见证了词嵌入技术(如Word2Vec, GloVe, FastText)如何赋予词语以初步的“语义灵魂”。接着,我们学习了循环神经网络(RNN)及其重要变体LSTM和GRU是如何努力捕捉序列中的动态信息和“记忆”的。随后,我们深入剖析了注意力机制的革命性思想,它如何让模型学会“聚焦”关键信息,并最终催生了完全基于注意力的Transformer架构——这个现代NLP乃至AI领域的“变形金刚”。最后,我们领略了站在Transformer肩膀之上的大规模预训练语言模型(PLMs)如BERT和GPT系列的崛起,它们通过在海量数据上的自监督学习,获得了前所未有的通用语言理解和生成能力,如同掌握了一把解锁人类知识宝库的钥匙。
文本,作为人类文明传承、思想交流最核心的媒介,其有效的机器表示和深度理解,是构建任何高级人工智能系统的基石,更是通往多模态智能不可或缺的一环。现在,我们手中已经握住了这把关键的“语言之钥”。下一章,我们将把目光投向另一个至关重要的信息维度——视觉。我们将一同探索计算机如何“看懂”这个五彩斑斓、瞬息万变的世界,从基础的图像处理知识,到强大的卷积神经网络(CNN)如何从像素中提取模式,再到视觉Transformer(ViT)如何将序列化思想引入视觉领域。只有当机器同时拥有了敏锐的“双眼”和智慧的“大脑”,我们才能真正开始构建能够理解图文并茂、声情并茂的多模态智能系统。准备好了吗?让我们一同推开视觉世界的大门!
参考文献 (References)
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (NIPS).
- 链接: https://proceedings.neurips.cc/paper/2013/hash/9aa42b31882ec039965f3c4923ce901b-Abstract.html
- Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global vectors for word representation. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- 链接: https://aclanthology.org/D14-1162/
- Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics (TACL), 5, 135-146. (FastText)
- 链接: https://aclanthology.org/Q17-1010/
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780. (LSTM)
- 链接: https://www.mitpressjournals.org/doi/abs/10.1162/neco.1997.9.8.1735
- Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Conference on Empirical Methods in Natural Language Processing (EMNLP). (GRU的早期提出,常与Seq2Seq结合)
- 链接: https://aclanthology.org/D14-1179/
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473. (Additive Attention)
- 链接: https://arxiv.org/abs/1409.0473
- Luong, M. T., Pham, H., & Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025. (Multiplicative Attention)
- 链接: https://arxiv.org/abs/1508.04025
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (NIPS). (Transformer)
- 链接: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. (BERT)
- 链接: https://arxiv.org/abs/1810.04805
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. (GPT-1)
- 链接: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9. (GPT-2)
- 链接: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. In Advances in neural information processing systems (NeurIPS). (GPT-3)
- 链接: https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., … & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692. (RoBERTa)
- 链接: https://arxiv.org/abs/1907.11692
- Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., & Le, Q. V. (2019). Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems (NeurIPS). (XLNet)
- 链接: https://proceedings.neurips.cc/paper/2019/hash/dc6a7e655d7e5840e66733e9ee67cc69-Abstract.html
- Lan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942. (ALBERT)
- 链接: https://arxiv.org/abs/1909.11942
- Clark, K., Luong, M. T., Le, Q. V., & Manning, C. D. (2020). Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555. (ELECTRA)
- 链接: https://arxiv.org/abs/2003.10555
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research (JMLR), 21(140), 1-67. (T5)
- 链接: https://www.jmlr.org/papers/v21/20-074.html
- Lewis, M., Liu, Y., Goyal, N., Grefenstette, M., Parikh, A. P., & Zettlemoyer, L. (2019). Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461. (BART)
- 链接: https://arxiv.org/abs/1910.13461
- Jurafsky, D., & Martin, J. H. (2023). Speech and language processing (3rd ed. draft). (经典的NLP教材,很多基础概念可以参考)
- 链接: https://web.stanford.edu/~jurafsky/slp3/
- Goldberg, Y. (2017). Neural network methods for natural language processing. Morgan & Claypool Publishers. (关于NLP中神经网络方法的优秀著作)
- 链接 (出版商): https://www.morganclaypool.com/doi/abs/10.2200/S00762ED1V01Y201703HLT037