java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流
- 前情提要
- 文章介绍
- 一、函数伊始
- 1.1 合格的函数
- 1.2 有形的函数
- 2. 函数对象
- 2.1 函数对象——行为参数化
- 2.2 函数对象——延迟执行
- 二、 函数编程语法
- 1. 函数对象表现形式
- 1.1 Lambda表达式
- 1.2 方法引用(Math::max)
- 2 函数接口
- 2.1 自定义函数接口
- 2.2 函数接口练习
- 2.2.1 简单的filter过滤函数(`Predicate`)
- 2.2.2 有返回值的转换函数(`Function`)
- 2.2.3 消费类型函数接口(`Consume`)
- 2.2.4 提供类型函数接口(`Supplier`)
- 3. 方法引用
- 3.1 静态方法
- 3.2 类名的非静态方法
- 3.3 对象的非静态方法
- 3. 4 类名::new
- 三、闭包和柯里化
- 1. 闭包
- 2. 柯里化
- 五、高阶函数
- 1. 内循环
- 2. 简单的实现stream流
- 3. 泛型(扩展)
- 3.1 定义
- 3.2 泛型类
- 3.3 泛型方法和接口
- 3.5 上界通配符
- 3.6 下界通配符
- 3.7 无界通配符
- 总结
前情提要
上一篇文章我们仔细的研究了NIO的全部知识点,对于Java中的IO操作已经掌握的差不多了,如果想要学习相关知识点强烈推荐大家看一下。
java高级——NIO解读,全网最全最详细,没有之一
文章介绍
此篇文章撰写之初本是为了stream流单独开一个模块,但最后经过资料分析发现,如果想要彻底掌握stream流需要的其它知识点还是很多的,所以根据B站上一个课程链接进行学习和记录,同时也会穿插在工作中的一些实战例子,大致的目录如下(本文不对三、四、五部分进行详细阐述,后续用到百度即可,重点是了解高阶函数和怎么自定义一个函数式接口):

本文适合有一定基础且对stream和高阶函数有一定兴趣的伙伴阅读,或者说想要系统学习的,里面涉及的知识点会些许抽象,但阅读后确实会对这个体系有一个非常清晰的认知,这也是从一个接口的使用者转变为接口提供者身份的开始。
一、函数伊始
首先来一个很抽象的概念,函数到底是什么?
在这篇文章中,对上述问题的答案是:函数 == 道。
在课程中有一段很经典的话:成道要无情。

大道无情:是指大道不带有任何主观的个人主义色彩,不偏袒任何一方,只遵循自然法则和规律。
函数无情:只要输入相同,无论多少次的调用,无论什么时间调用,输出相同。
嘿,初听这个概念感觉这和修仙一样,但你仔细揣摩一下,如果是Math.ceil(5.20)结果一定是6,似乎符合上述所说的无情。但有人要站出来反驳了,正常我们定义了那么多函数,不同的人调用结果一定是不同的,这能符合吗?
咱不要着急,仔细想一下,首先就不符合一点,输入都不相同,虽然编程中我们定义的那个public代码块习惯叫函数,实际上真正的定义叫做方法,那是一个方法,执行一段逻辑的代码。从不同角度来解读函数的概念理解都不太相同,从数学角度来说,函数是两个非空数集间的一种对应关系;从逻辑角度来说,函数体现了输入和输出之间确定的对应逻辑;从哲学角度来说,函数在一定程度上反映了事物之间的内在联系和规律性。但要是把函数无情带入到上述的几个角度似乎都不太符合,这里说的无情只是我们在编程中对于函数特性的一种抽象解读,在后续会根据例子慢慢的理解它的本质。
1.1 合格的函数
Java作为一个面向对象的编程语言,我们首先接触的函数是不是最熟悉的成员方法,看下面的例子。
public class Test1_1 {static class Student {final String name;public Student(String name) {this.name = name;}public String getName() {return name;}// 等价于// public String getName(Student this) {// return this.name;// }}public static void main(String[] args) {Student s1 = new Student("张三");Student s2 = new Student("李四");System.out.println(s1.getName()); // 等价于 getName(s1)System.out.println(s1.getName());System.out.println(s2.getName()); // 等价于 getName(s2)System.out.println(s2.getName());}
}
上面是一个很简单的Student类和一个name的属性,getName是它的成员方法,在main方法中分别调用了两次getName函数,在参数相同的情况下输出一定是相同的,这算一个合格的函数。
究其根本,一个合格函数的定义就是两个字“不变”,那么上面说了,我们大部分定义的所谓函数真正意义上是方法,因为输出结果会因为相同的参数而改变,这里就要看大家怎么理解了,方法和函数并没有本质的区别,都是获取一个结果或执行一段预先设计好的逻辑,只不过一个合格的函数被我们赋予了一个特性,那就是不变。
1.2 有形的函数
这个标题很抽象,因为我们在一个类中调用方法的时候都是直接调用的,函数被定义在类中,只是一段代码块,如果我们跨类调用则需要new一个类或者或使用自动装载技术,使用对象.方法的形式调用,那问题来了,你见过函数在Java中怎么直接通过参数传递吗(js中函数可以当做对象传递,不需要做过多的处理)。
public class Test1_2 {// 普通函数public int add(int a, int b) {return a + b;}// 有形函数interface Lambda {int calculate(int a, int b);}// 箭头函数定义成了一个接口static Lambda add = (a, b) -> a + b;public static void main(String[] args) {System.out.println("普通函数:" + new Test1_2().add(1, 2));System.out.println("有型函数:" + add.calculate(1, 2));}
}
根据上面的例子,我们可以分析出有形函数的几个特点。
- 位置不固定(可传递性):如果是
普通的函数,我们一旦定义好之后位置是无法改变的,而只能通过对象.方法的形式调用(排除static方法),而有形的函数我们将其封装成一个对象,申明好函数名和参数类型之后,它出现的位置就不固定了,我们可以在任何地方定义一段处理逻辑并使用。 - 使用灵活:虽然参数类型和数量一般是固定的,但怎么去
定义它的执行逻辑就很灵活了,根据需求可以改变,是不是有点类似于Java多态的特性。 - 方法唯一性:每一个接口中
只能有一个方法定义。
接下来我们看一个实际的例子,相对比较复杂,运用了IO、NIO中的Socket、Thread等知识点,排除线程我们没有讲过,其余的知识点在之前的文章中都有仔细解读,如果想要弄懂代码的全部可以去前面看看,当然,重点还是在函数上。
public class ClientThread implements Runnable{private Socket socket;public ClientThread(Socket socket) {this.socket = socket;}@Overridepublic void run() {try {ObjectInputStream is = new ObjectInputStream(socket.getInputStream());Lambda1_2_1 lambda = (Lambda1_2_1) is.readObject();int a = ThreadLocalRandom.current().nextInt(10);int b = ThreadLocalRandom.current().nextInt(10);System.out.printf("%s %d op %d = %d%n", socket.getRemoteSocketAddress().toString(), a, b, lambda.calculate(a, b));} catch (Exception e) {e.printStackTrace();}}
}
// 注意,这里一定要继承序列化接口
public interface Lambda1_2_1 extends Serializable {int calculate(int a, int b);
}
public class Test1_2_1 {static class Server {public static void main(String[] args) throws Exception {ServerSocket serverSocket = new ServerSocket(8080);System.out.println("Server start .....");while (true) {Socket client = serverSocket.accept();new Thread(new ClientThread(client)).start();}}}static class Client {public static void main(String[] args) {try {Socket s = new Socket("127.0.0.1", 8080);Lambda1_2_1 lambda = (a, b) -> a + b;ObjectOutputStream os = new ObjectOutputStream(s.getOutputStream());os.writeObject(lambda);os.flush();} catch (Exception e) {e.printStackTrace();}}}static class Client1 {static int add(int a, int b) {return a + b;}}
}
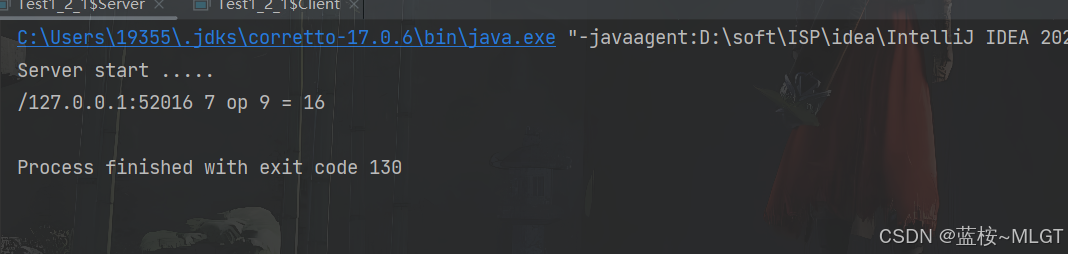
解读一下上面的代码,有一个服务器端,当客户端连接后,从输入流中取出传递的Lambda接口,该服务器生成两个随机数执行客户端的函数,这就对应的上述有形函数的特点,位置不固定,而且可以通过对象传递。注意,我们的服务端只提供数据,真正实现逻辑的地方在客户端,大大增加了灵活性。
而普通的函数是无法像上面使用的,即使我们通过序列化将Client1对象传递到服务器,服务器反序列化进行调用,但是注意,这样实现的前提是服务器必须有对应的字节码文件,这和直接写在服务器没有什么区别。
2. 函数对象
2.1 函数对象——行为参数化
又是一个抽象的概念,可以简单理解为,将我们要执行的一段逻辑代码作为参数,接下来我们看一个例子,解释一下为什么会有行为参数化这个概念(也就是stream流过滤的前身)。
public class Test2_1 {public static void main(String[] args) {List<Student> list = Arrays.asList(new Student("侯卿", "男", 108),new Student("将臣", "女", 230),new Student("莹勾", "女", 180),new Student("旱魃", "男", 100));// 需求1:找出四大尸祖中的男性System.out.println("男性尸祖 = " + filterSex(list));// 需求2:找出四大尸祖中男性年龄大于100岁的System.out.println("男性且年龄大于100的尸祖 = " + filterAge(filterSex(list)));}static List<Student> filterSex(List<Student> list) {List<Student> res = new ArrayList<>();for (Student item : list) {if (Objects.equals(item.getSex(), "男")) {res.add(item);}}return res;}static List<Student> filterAge(List<Student> list) {List<Student> res = new ArrayList<>();for (Student item : list) {if (item.getAge() > 100) {res.add(item);}}return res;}static class Student {final String name;final String sex;final Integer age;Student(String name, String sex, Integer age) {this.name = name;this.sex = sex;this.age = age;}public String getName() {return name;}public String getSex() {return sex;}public Integer getAge() {return age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", sex='" + sex + '\'' +", age=" + age +'}';}}
}
上面的例子很简单,就是从集合中找出符合条件的人,根据不同的需求定义不同的方法(不要说将两个需求融合在一个方法中,正式的开发都尽量将一个需求定义在一个函数中,方便维护和扩展),但是从代码看重复的内容比较多,所以当我们将过滤的逻辑处理成参数,是不是可以简化很多呢?
public class Test2_1 {public static void main(String[] args) {List<Student> list = Arrays.asList(new Student("侯卿", "男", 108),new Student("将臣", "女", 230),new Student("莹勾", "女", 180),new Student("旱魃", "男", 100));// 优化后的需求2实现如下List<Student> filterList = filter(list, student -> student.sex.equals("男"));List<Student> resList = filter(filterList, student -> student.age > 100);System.out.println("resList = " + resList);}interface Lambda {boolean test(Student student);}static List<Student> filter(List<Student> list, Lambda lambda) {List<Student> res = new ArrayList<>();for (Student item : list) {if (lambda.test(item)) {res.add(item);}}return res;}static class Student {final String name;final String sex;final Integer age;Student(String name, String sex, Integer age) {this.name = name;this.sex = sex;this.age = age;}public String getName() {return name;}public String getSex() {return sex;}public Integer getAge() {return age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", sex='" + sex + '\'' +", age=" + age +'}';}}
}
这样的话,我们的需求无论是怎么扩展,只需要使用一个方法就可以实现了,而上面代码的精髓就是将过滤的核心逻辑处理成参数传递,是不是有点类似于stream流的filter方法。
2.2 函数对象——延迟执行
static Logger logger;public static void main(String[] args) {logger.debug("{}", () -> test());logger.debug("{}", test());}// 假设这是一个很耗时的操作static String test() {return "test";}
上面的例子很抽象,具体的场景就是加入你需要输出的日志比较耗时,但是假设现在系统的日志级别是info,但是你使用的debug模式的日志,那正常情况下不能输出这段日志。但是,如果是第二种普通方法的调用,那test方法一定会执行结束,然后返回结果,logger内部会进行日志级别的判断,如果不符合则不会输出,但实际,耗时的方法已经执行了。相比于传递一个函数对象,这个函数并不会立即执行,而是等debug内部判断执行完之后才会进行test方法的调用,这就是延迟执行的解释。
从正常情况分析,其实就是别人提供了一个方法A,这个A方法的参数你是通过另外一个方法B传递的,但A中有一些内部逻辑需要提前执行,可能情况不符合A方法就会立刻返回。根据函数的执行顺序来说,参数如果为方法,则该方法会提前执行,也就是B方法会先于A执行,这其实不符合我们的要求,所以出现了函数对象作为参数传递,能很好的解决这个问题,为什么这个函数对象不会立刻执行,要知道,这从根本上就是一个对象啊,你说有没有道理。
正常来说,这种写法是不建议的,能用if判断解决的就用if判断,从执行效率上肯定if判断快很多,毕竟这是一个对象,会占用资源的,不过如果你的业务特殊,你的方法只能在特殊的条件下执行,而且次数很少,逻辑也不会那么多(就几行代码),但是你又不想将这段逻辑代码暴露出去(比如一个异步方法,结束后需要一个回调函数),这种场景使用函数对象非常好使。
大家可以仔细阅读一下上面的文字描述,这个特性确实不好理解,使用例子还不如用文字描述,至少课程中那个例子是很难理解的,这里说明的更加详细。
二、 函数编程语法
1. 函数对象表现形式
1.1 Lambda表达式
一个合格的Lambda表达式包含三部分,分别是:
- 参数部分:(int a, int b)
- 箭头符号:->
- 逻辑部分:a + b
(int a, int b) -> a + b
上述的例子逻辑部分很简单,而且能发现没有return语句,是因为在Lambda中如果你的逻辑部分只有一行,是可以直接将逻辑部分当做返回值的,接下来是多行逻辑部分的表达式。
(int a, int b) -> { int c = a + b; return c;}
注意:当逻辑部分多于一行,大括号和return是不能省略的!!!
正常我们见到的Lambda表达式都和上面的不太一样,如下:
(a , b) -> a + b;
这种写法比较常见,是看不见参数类型的,实际这需要定义一个接口,里面有一个抽象方法会定义参数类型,有且只能有一个抽象方法,完整表达如下:
Lambda lambda = (a , b) -> a + b;interface Lambda {int op(int a, int b);
}interface Lambda1 {double op(double a, double b);
}
当可以通过上下文推断出参数类型时,可以省略参数类型,这里的上下文指的就是接口中的抽象方法,而这种定义的好处就是一个表达式可以对应多个接口,上面的逻辑部分既可以对应Lambda接口也可以对应Lambda1接口。
a -> a
如果只有一个参数,括号()是可以省略的。
1.2 方法引用(Math::max)
方法引用的表现形式更加抽象,对于有编程经验的来说见怪不怪,初入编程世界的同学可能会有些奇怪,这种表现形式更加的简洁,尤其是在stream流的应用颇为广泛,这一小节让我们对其原理进行了解。
直接通过例子说明方法引用的含义
// 左侧是类型,右侧是静态方法,缺失的是静态方法max需要的两个参数
Math::max (int a, int b) -> Math.max(a, b)
// 左侧是类型,右侧是非静态方法,缺失的是该方法的一个参数Student
Student::getName (Student stu) -> stu.getName()
// 左侧是类型,右侧是一个new关键字,这里没有缺失的内容
Student::new () -> new Student()
// 左侧是一个对象,右侧是一个非静态方法,缺失的是方法要输出的对象Object
System.out::printIn (Object obj) -> System.out.printIn(obj)
上面的例子中左边可以是一个对象,也可以是一个类型,右侧可以是关键字,也可以是静态和非静态方法,说白了,这都是方法引用的表现形式,第三个和第四个例子是有些抽象的,我们可以当做特殊情况对待,最常见得就是前两个。
大家不用对上面的例子害怕,感觉看不懂,其实只需要抓住一个核心,我们缺失的东西可以当做参数,不缺失的东西那就没有参数,右边永远是执行的代码块,这样就很好理解了。
2 函数接口
2.1 自定义函数接口
上面我们已经对函数对象和方法引用有了大概得认识,现在假如让你对一个函数进行封装,让其成为一个函数接口,这便是我们马上要学习的内容。
首先我们要定义一个函数接口必须学会区分两个东西,一个是入参,一个是返回值,只需要明确这两点就可以定义出来一个函数接口。
public class Test1_1 {static class Student {private String name;private Integer age;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}}// type1和type2两个对象的返回值和入参都是一样的Type1 type1 = (a) -> (a & 1) == 0;Type1 type2 = (int a) -> BigInteger.valueOf(a).isProbablePrime(100);Type2 type3 = (a, b, c) -> a + b + c;Type3 type5 = (a, b) -> a * b;Type3 type6 = (a, b) -> a - b;// 等价于:() -> new Student()Type5 type7 = Student::new;// 等价于 () -> new ArrayList<Student>;Type6 type8 = ArrayList::new;// 等价于(Student stu) -> stu.getAge()Type9 type9 = Student::getAge;// 等价于(Student stu) -> stu.getName()Type10 type10 = Student::getName;@FunctionalInterfaceinterface Type10 {String op(Student student);}@FunctionalInterfaceinterface Type9 {int op(Student student);}// 函数接口有且仅有一个抽象方法,FunctionalInterface会在编译时检查这个逻辑@FunctionalInterfaceinterface Type1 {boolean op(int a);}@FunctionalInterfaceinterface Type2 {int op(int a, int b, int c);}@FunctionalInterfaceinterface Type3 {int op(int a, int b);}@FunctionalInterfaceinterface Type5 {Student op();}@FunctionalInterfaceinterface Type6 {List<Student> op();}@FunctionalInterfaceinterface Type7 {List<Student> op();}
}
上面的多个例子比较清晰,但也暴露了一个问题,要是这么定义下去,不得出现类爆炸,也不能出现了一个类型就定义一个函数接口,所以我们可以改进一下上面的代码,用泛型来实现,用泛型我们就只需要关注参数数量的问题了。
// 等价于:() -> new Student()// 等价于:Fun_01 fun2 = Student::new;Type5 type7 = Student::new;// 等价于 () -> new ArrayList<Student>;// 等价于:Fun_01 fun1 = ArrayList::new;Type6 type8 = ArrayList::new;// 等价于(Student stu) -> stu.getAge()// 等价于:Fun_02<Integer, Student> fun3 = Student::getAge;Type9 type9 = Student::getAge;// 等价于(Student stu) -> stu.getName()// 等价于:Fun_02<Integer, Student> fun5 = Student::getName;Type10 type10 = Student::getName;@FunctionalInterfaceinterface Fun_01<T> {T op();}@FunctionalInterfaceinterface Fun_02<O, I> {O op(I input);}
注意哈,泛型的使用情况大都是在定义一个共用的方法时比较常见,一个好的程序猴不能只做方法的使用者,要学会定义方法,方法越共用,那就说明方法越牛逼(可以这么简单理解)。
在Java中实际上已经给我们提供了很多函数式接口,我们不需要再去定义上面的泛型接口(不是白学哈,这方便你后面定义自己的函数接口,只是Java给我们提供了一些常用的),如下:
基本函数式接口
- 消费型接口:Consumer: 接受一个输入参数,无返回值
BiConsumer<T,U>: 接受两个输入参数,无返回值
-
供给型接口
Supplier: 无参数,返回一个结果 -
函数型接口
Function<T,R>: 接受一个输入参数,返回一个结果
BiFunction<T,U,R>: 接受两个输入参数,返回一个结果
- 断言型接口
Predicate: 接受一个输入参数,返回布尔值
BiPredicate<T,U>: 接受两个输入参数,返回布尔值
原始类型特化接口
- 针对基本类型的函数接口
IntConsumer, LongConsumer, DoubleConsumer
IntSupplier, LongSupplier, DoubleSupplier
IntFunction, LongFunction, DoubleFunction
ToIntFunction, ToLongFunction, ToDoubleFunction
IntToLongFunction, IntToDoubleFunction, LongToIntFunction
二元操作符接口
-
UnaryOperator: 继承Function<T,T>,一元操作
-
BinaryOperator: 继承BiFunction<T,T,T>,二元操作
-
原始类型特化:
IntUnaryOperator, LongUnaryOperator, DoubleUnaryOperator
IntBinaryOperator, LongBinaryOperator, DoubleBinaryOperator
其他常用接口
Runnable: 无参数无返回值 (在java.lang包中)
Comparator: 用于比较两个对象 (在java.util包中)

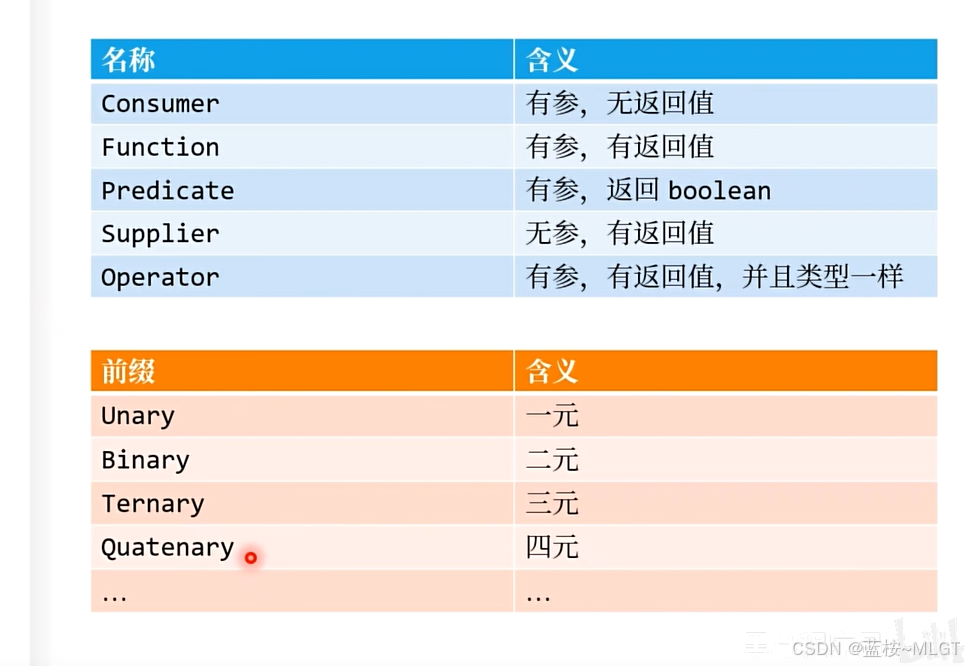
上面的两张图片是在B站课程中截图的,总结的比较清晰。
2.2 函数接口练习
上面大多数都是课文知识点,最主要的目的是介绍了Java自带的函数式接口,那我们就可以在真实的开发中使用了。
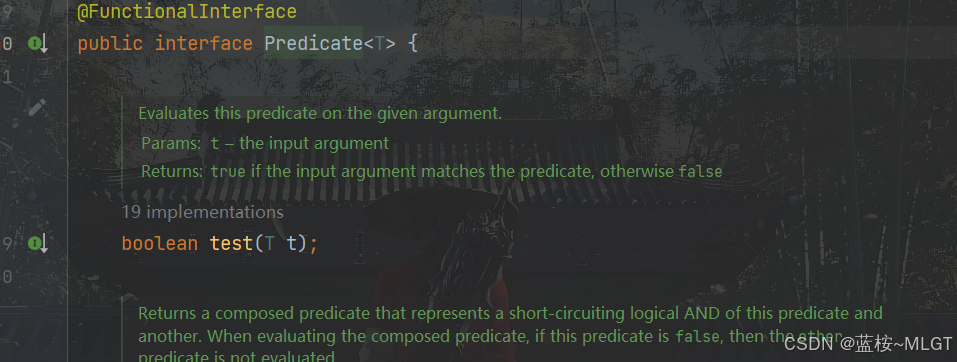
2.2.1 简单的filter过滤函数(Predicate)
public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3, 4, 5, 6);// 过滤出奇数List<Integer> filter1 = filter(list, (Integer item) -> (item & 1) == 1);// 等价于stream流的filterList<Integer> filter2 = list.stream().filter(item -> (item & 1) == 1).collect(Collectors.toList());System.out.println("filter1 = " + filter1);System.out.println("filter2 = " + filter2);}// 一个简单的filter函数static List<Integer> filter(List<Integer> list, Predicate<Integer> predicate) {List<Integer> resList = new ArrayList<>();for (Integer item : list) {if (predicate.test(item)) {resList.add(item);}}return resList;}// 运行结果// filter1 = [1, 3, 5]// filter2 = [1, 3, 5]
那么有人可能好奇,都已经有stream流了,为什么我还要学习这个?
在开发中stream使用的频率非常高,在处理集合是第一梯队,不过大多数的情况都是在你的断言(也就是条件)比较简单的情况,如果遇到了非常复杂的情况,个人推荐使用普通的for循环,不仅在效率上更快,同时也更加利于维护。这时候我们就可以自定义过滤条件进行使用,非常的灵活,其次最重要的,因为大多数情况我们是直接面向明确的需求在编写代码,所以过滤条件是明确的,直接可以迭代在代码中,假设真的有一个需求,过滤条件是用户输入或者选择的呢?这时候就必须要使用类似的函数接口了。
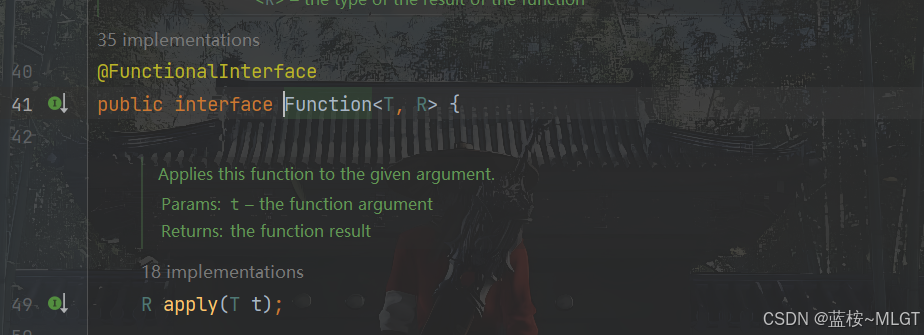
2.2.2 有返回值的转换函数(Function)
public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3, 4, 5, 6);// 等价于map(list, number -> String::valueOf);// 等价于List<String> map1 = list.stream().map(String::valueOf).collect(Collectors.toList());List<String> map = map(list, number -> String.valueOf(number));System.out.println("map = " + map);}static List<String> map(List<Integer> list, Function<Integer, String> function) {List<String> resList = new ArrayList<>();for (Integer item : list) {resList.add(function.apply(item));}return resList;}
上述是一个简单的类型转换函数接口,使用了有返回值的Function函数接口,这个返回值类型是我们自己传入的,使用了泛型R(Result)。
2.2.3 消费类型函数接口(Consume)
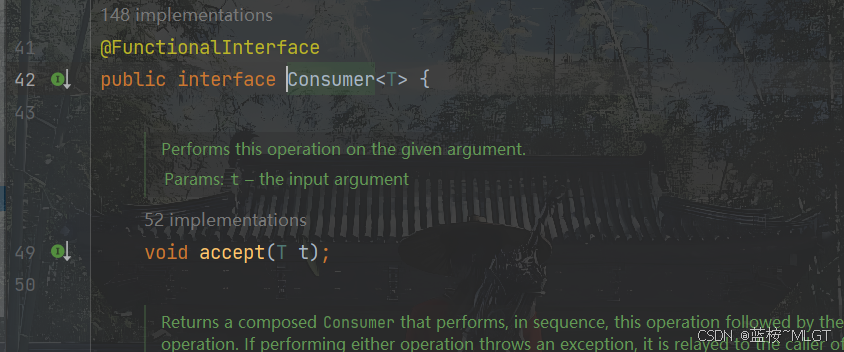
public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3, 4, 5, 6);// 等价于 consume(list, System.out::println);consume(list, item -> System.out.println(item));}static void consume(List<Integer> list, Consumer<Integer> consumer) {for (Integer item : list) {consumer.accept(item);}}
2.2.4 提供类型函数接口(Supplier)
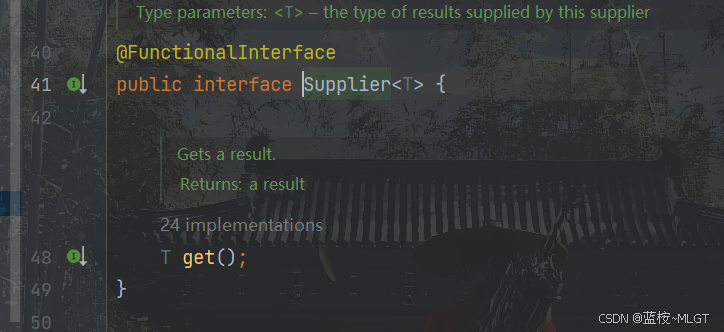
public static void main(String[] args) {System.out.println(supply(3, () -> ThreadLocalRandom.current().nextInt()));}// 生成随机数static List<Integer> supply(int count, Supplier<Integer> supplier) {List<Integer> resList = new ArrayList<>();for (int i = 0; i < count; i++) {resList.add(supplier.get());}return resList;}
3. 方法引用
上面我们也简单了解了方法引用,这一章详细介绍一下什么是方法引用。
方法引用:
将现有方法的调用化为函数对象。
- 静态方法:(String s) -> Integer.parseInt(s) 等价于 Integer::parseInt
- 非静态方法:stu -> stu.getName() 等价于 Student::getName
- 构造方法:() -> new Student() 等价于 Student::new
上面三个例子的左边就是函数对象,右边是方法引用,可以看出方法引用更加优雅和简洁,至于使用的时候参数怎么来,一般在stream流中我们传递的实际上是一个函数对象,函数对象缺失的参数会自动传递,不需要显式的给,这就是方法引用的魅力所在。说白了,白说了,方法引用就是函数对象,只不过表现形式更高级,要不然这两个东西怎么能互相转换呢?
函数对象和方法引用我们一定牢记两个点(例如 (n) -> Math.abs(n))
参数:执行方法的参数 n逻辑:执行的方法 Math.abs(n)
只需要搞清楚上面的两个部分,那转换就很丝滑了,方法引用转函数对象就是让参数部分消失,反之则是让参数部分显示出来。
3.1 静态方法
逻辑:静态方法
参数:静态方法的参数
public class Test_1_3 {public static void main(String[] args) {// 等价于:forEach(System.out::println);// 等价于:forEach(student -> System.out.println(student));Stream.of(new Test1_1.Student("张三", 18),new Test1_1.Student("李四", 18),new Test1_1.Student("王五", 18)).forEach(Test_1_3::abs);/*** (Student student) -> System.out.printIn(student)* 类名::静态方法*/}public static void abs(Test1_1.Student student) {System.out.println(student);}
}
上面的例子就记住这一句“类名::静态方法”,因为后期我们基本都是基于stream流操作的,在此基础上我们可以继续扩展更加复杂的用法。
3.2 类名的非静态方法
逻辑: 执行的非静态方法。
参数:一是这个类的对象,一个是非静态方法的参数
static class Student {private String name;private Integer age;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Student(String name, Integer age) {this.name = name;this.age = age;}public void selfPrint() {System.out.println(this);}}public static void main(String[] args) {Stream.of(new Student("张三", 18),new Student("李四", 18),new Student("王五", 18)).forEach(Student::selfPrint);}
有人可能会纳闷,上面的selfPrint有一个参数怎么传递呢?因为这是一个非静态方法,在类里面,那this是不是就是这个对象本身啊,我们不需要显式传参就可以,静态和非静态方法的本质实际上是一样的,不需要纠结那么多。
3.3 对象的非静态方法
逻辑:非静态方法
参数:非静态方法需要的参数
System.out::printIn 等价于 obj -> System.out.printIn(obj)
乍一看3.3和3.2没有什么区别,一定要注意了,参数不一样,对象只需要一个参数,那就是非静态方法所需的参数即可,不像类名的非静态方法,他还需要自身的对象,这里自身的对象参数System.out是明确的。
3. 4 类名::new
逻辑:执行构造方法
参数:构造方法所需的参数
Student::new -> new Student() () -> new Student()
static class Student {private final String name;private final Integer age;public Student() {this.name = "张三";this.age = 18;}public Student(String name) {this.name = name;this.age = 18;}public Student(String name, Integer age) {this.name = name;this.age = age;}}public static void main(String[] args) {Supplier<Student> supplier = Student::new;Function<String, Student> function = Student::new;BiFunction<String, Integer, Student> biFunction = Student::new;System.out.println("supplier = " + supplier.get());System.out.println(function.apply("test"));System.out.println(biFunction.apply("test", 18));}
上面分别提供了三种构造方法,也对应了三种方法引用,这种了解一下,一般我们使用的都是无参的构造方法,在stream流中如果有null的,可能会直接new一个对象,这时候使用方法引用即可。
三、闭包和柯里化
闭包和柯里化的概念是比较常见但容易被忽视的,JavaScript中也有相同的概念,如果学过js的对这两个概念并不陌生,之前我也写过一篇博客专门讲这两个概念。那么在Java中原理都是相同的,只是代码上不同而已。
1. 闭包
所谓闭包就是一个外部变量被一个函数引用,此时这个外部变量的内存地址不能被修改,这个变量和函数共同组成了闭包。这个变量的销毁时机就是这个函数运行结束,函数被jvm回收之后,变量也会跟着销毁。
interface Lambda {int op(int y);}public static void main(String[] args) {int b = 1;Lambda lambda = a -> a + b;System.out.println("lambda.op(2) = " + lambda.op(2));}
上面的闭包组成就是变量b和函数对象lambda,而且b不能被修改,这是一个常量,如果修改就会改变内存地址,那么如果是一个对象中的属性呢,那就可以修改了,因为内存地址不会变,这种叫做effective final对象。
interface Lambda {int op(int y);}public static void main(String[] args) {class Student {Integer age;public Student(int age) {this.age = age;}}Student student = new Student(2);Lambda lambda = a -> a + student.age;System.out.println("lambda.op(2) = " + lambda.op(1));student.age = 519;System.out.println("lambda.op(2) = " + lambda.op(2));}
其实正常来说,这达不到函数无情的逻辑,这是违背函数式编程的,因为参数不变(内存地址变了),输出却变了,我们终归得妥协,就像,你还是你,你永远是你,可随着时间的变化,你有可能就不是你了。
2. 柯里化
柯里化的思想是让一个接收多个参数的函数转换成一系列接受一个参数的函数。
核心就是,拆分参数到不同的函数对象,有点像链式调用。
static int add(int a, int b) {return a + b;}static Function<Integer, Function<Integer, Integer>> funA() {return a -> b -> a + b;}public static void main(String[] args) {System.out.println("多参数: " + add(519, 2));System.out.println("拆分后: " + funA().apply(519).apply(2));}
上面是一个比较经典的例子,函数柯里化和闭包息息相关,上面的a和函数b -> a + b组成了一个闭包。
有人会纳闷,我能一个函数实现,为啥要拆开实现。这里的应用场景是在哪些需要分步骤实现的场景使用的,比如说我最终要去办理一个业务,这个业务需要的材料有A、B、C三种,最终审核就需要这三个,但是你必须要一步一步走申请,先去审核A,再然后用A和B去审核,最后一步你就可以办理业务了。这其实就是函数柯里化的思想来源。
Function<String, Function<String, Function<String, String>>> f1 =a -> b -> c -> a + b + c;Function<String, Function<String, String>> f2 = f1.apply("第一步我给你一个文件,你照着这个指示去办理业务!\r\n");Function<String, String> f3 = f2.apply("第二步我给你一个证明,拿着证明去xxx单位!\r\n");String apply = f3.apply("第三步出示你的身份证,业务就办理成功了");System.out.println(apply);
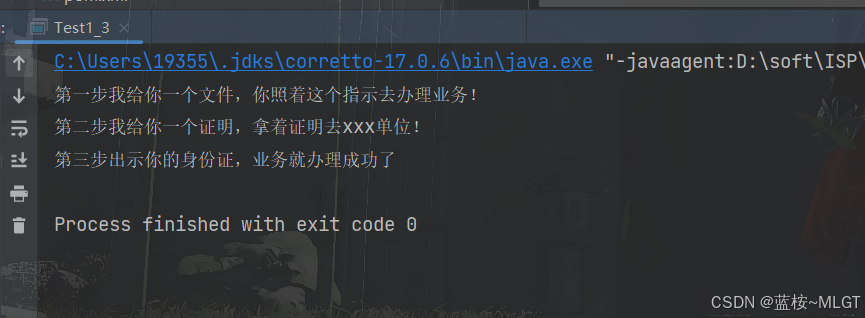
上面这个分步骤的例子稍微复杂一些,不过仔细看也就是多套了一层。在真实的开发中,柯里化通常运用于比较抽象的业务,更多的是出现在第三方接口中,比如我要给xxx提供一个接口,要支持什么功能,这种的业务运用柯里化的比较多。
柯里化的优势很明显,函数执行的延迟性和代码的复用性很高,弊端也很明显,会将一个函数复杂化,可读性变得很差,一般的业务是不需要使用的。
五、高阶函数
所谓高阶函数,简单可以理解为这可以作为其它函数的参数(参数就是一个函数),如下:
Function<Integer, Integer> funA = a -> a + 2;Function<Function<Integer, Integer>, Integer> funB = fun -> fun.apply(519);System.out.println("funB.apply(funA) = " + funB.apply(funA));
上面的高阶函数就是funA,它作为了函数funB的参数,高阶函数的作用是:将通用和复杂的逻辑封装在高阶函数内,将简单未定的逻辑饭交给调用者实现,就像上面我们可以理解为将加法运算封装了,调用者只需要传递参数就行了。
1. 内循环
public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3);// cusFor(list, item -> System.out.println(item);cusFor(list, System.out::println);}public static <T> void cusFor(List<T> list, Consumer<T> consumer) {for (T t : list) {consumer.accept(t);}}
不多说了直接看代码哈,这其实就是一个forEach的内部实现原理,forEach是接口Iterable的一个默认方法,List是实现这个接口的,看到源码之后你就可以发现,在forEach中为什么不能使用continue来跳过,就是因为这个函数本身就没有提供这个功能,人家就是执行你传递的逻辑就完事儿了。
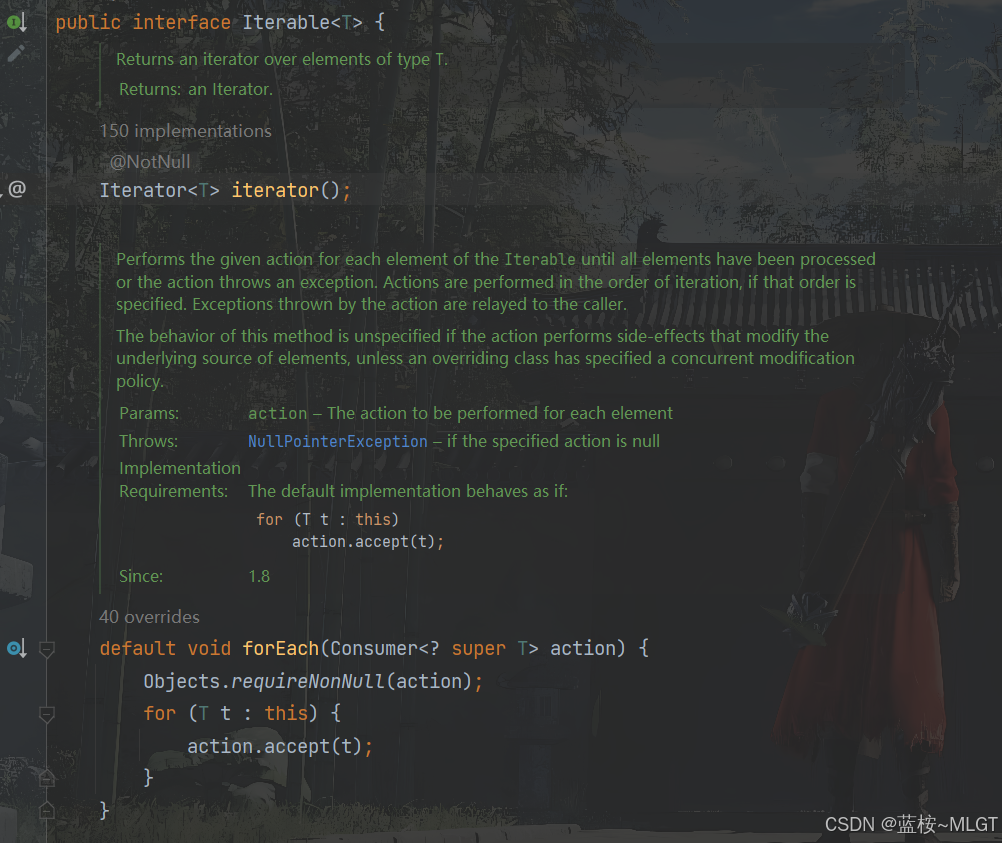
2. 简单的实现stream流
public class SimpleStream<T> {public static void main(String[] args) {List<Integer> list = List.of(1, 2, 3, 4, 5, 6);SimpleStream.of(list).filter(x -> (x & 1) == 1).map(x -> x * x).forEach(System.out::println);}public SimpleStream<T> filter(Predicate<T> predicate) {List<T> result = new ArrayList<>();for (T item : collection) {if (predicate.test(item)) {result.add(item);}}return new SimpleStream<>(result);}public <U> SimpleStream<U> map(Function<T, U> function) {List<U> result = new ArrayList<>();for (T t : collection) {U u = function.apply(t);result.add(u);}return new SimpleStream<>(result);}public void forEach(Consumer<T> consumer) {for (T t : collection) {consumer.accept(t);}}public static <T> SimpleStream<T> of(Collection<T> collection) {return new SimpleStream<T>(collection);}private Collection<T> collection;private SimpleStream(Collection<T> collection) {this.collection = collection;}
}
上面是一个简单实现了stream流的filter、map和foreach功能,不难,只不过泛型这块儿可能会不太懂,这里咱扩展一下泛型的知识点。
3. 泛型(扩展)
3.1 定义
泛型(Generics)指的是一种参数化类型的机制,它允许在类、接口和方法上使用类型参数(Type Parameter),并在调用时指定具体参数,减少代码的冗余,增加复用性。
3.2 泛型类
// 定义一个泛型类 Pair
public class Pair<K, V> {private K key;private V value;public Pair(K key, V value) {this.key = key;this.value = value;}public K getKey() {return key;}public V getValue() {return value;}
}// 使用泛型类
public class Main {public static void main(String[] args) {Pair<String, Integer> pair = new Pair<>("Age", 25);System.out.println("Key: " + pair.getKey()); // 输出: Key: AgeSystem.out.println("Value: " + pair.getValue()); // 输出: Value: 25}
}
3.3 泛型方法和接口
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Predicate;public class Main {public static void main(String[] args) {List<Integer> numbers = new ArrayList<>();numbers.add(1);numbers.add(2);numbers.add(3);numbers.add(4);// 过滤偶数List<Integer> evenNumbers = filter(numbers, x -> x % 2 == 0);System.out.println(evenNumbers); // 输出: [2, 4]// 映射为平方List<Integer> squares = map(numbers, x -> x * x);System.out.println(squares); // 输出: [1, 4, 9, 16]// 打印结果forEach(evenNumbers, System.out::println); // 输出: 2 4}public static <T> List<T> filter(List<T> list, Predicate<T> predicate) {List<T> result = new ArrayList<>();for (T item : list) {if (predicate.test(item)) {result.add(item);}}return result;}public static <T, R> List<R> map(List<T> list, Function<T, R> function) {List<R> result = new ArrayList<>();for (T item : list) {result.add(function.apply(item));}return result;}public static <T> void forEach(List<T> list, Consumer<T> consumer) {for (T item : list) {consumer.accept(item);}}
}
大多数对于泛型方法前面的不太理解是什么,这其实就是限定方法的返回值类型可以是不同类型。
3.5 上界通配符
? extends T 表示类型参数必须是 T 或其子类
使用场景:
当你需要确保一个方法只能接受某种类型或其子类型的对象作为参数时,使用上界通配符。这通常用于读操作,因为它允许你从集合中获取元素,且这些元素都是 T 或其子类型。
import java.util.ArrayList;
import java.util.List;public class Main {public static void main(String[] args) {List<Integer> intList = new ArrayList<>();intList.add(1);intList.add(2);List<Double> doubleList = new ArrayList<>();doubleList.add(3.14);doubleList.add(6.28);// 只接受 Number 及其子类的 ListsumNumbers(intList); // 输出: 3.0sumNumbers(doubleList); // 输出: 9.42}public static double sumNumbers(List<? extends Number> list) {double sum = 0.0;for (Number number : list) {sum += number.doubleValue();}System.out.println("Sum: " + sum);return sum;}
}
3.6 下界通配符
? super T 表示类型参数必须是 T 或其父类。
使用场景:
当你需要往集合中添加元素,并希望确保这些元素至少是 T 类型时,使用下界通配符。它允许你向集合中添加 T 或 T 的子类型对象,同时也能从集合中读取对象,但是读取的对象类型将是 Object,因为编译器只能保证存储的是 T 或其超类型的实例。
import java.util.ArrayList;
import java.util.List;public class Main {public static void main(String[] args) {List<Number> numberList = new ArrayList<>();List<Integer> intList = new ArrayList<>();// 将 intList 中的元素添加到 numberList 中addElements(numberList, intList);}// 下界通配符方法public static void addElements(List<? super Integer> dest, List<Integer> src) {for (Integer i : src) {dest.add(i);}}
}
3.7 无界通配符
? 表示未知类型,可以匹配任何类型。
使用场景:
当你只需要读取数据而不需要向集合中添加元素时,可以使用无界通配符。这是因为无界通配符允许你获取对象,但不能保证这些对象的具体类型,因此无法安全地将任意对象添加到该集合中。
import java.util.ArrayList;
import java.util.List;public class Main {public static void main(String[] args) {List<String> stringList = new ArrayList<>();stringList.add("Java");stringList.add("C++");List<Integer> intList = new ArrayList<>();intList.add(1);intList.add(2);printElements(stringList); // 输出: Java C++printElements(intList); // 输出: 1 2}public static void printElements(List<?> list) {for (Object element : list) {System.out.print(element + " ");}System.out.println();}
}
- 使用 无界通配符 (?) 当你需要编写与具体类型无关的方法,并且只进行读操作。
- 使用 上界通配符 (? extends T) 当你需要确保集合中的所有元素都是某类型或其子类型,通常用于读取操作。
- 使用 下界通配符 (? super T) 当你需要将某类型或其子类型的元素添加到集合中,通常用于写入操作。
总结
到这里本文就结束了,经过b站上课程的后续学习感觉意义不大,因为关于stream流的使用相信大家都已经掌握了,或许偶尔有一些复杂的需求,那时候百度即可,不需要了解所有的stream流的使用,重点还是了解高阶函数和如何自定义一个函数式接口。