YoloV8改进策略:Block改进|FCM,特征互补映射模块|AAAI 2025|即插即用
1 论文信息
FBRT-YOLO(Faster and Better for Real-Time Aerial Image Detection)是由北京理工大学团队提出的专用于航拍图像实时目标检测的创新框架,发表于AAAI 2025。论文针对航拍场景中小目标检测的核心难题展开研究,重点解决小目标因分辨率低、背景干扰多导致的定位困难,以及现有方法在实时性与精度间的失衡问题。
航拍图像目标检测是无人机、遥感监测等应用的关键技术,但面临独特挑战:图像中目标(如车辆、行人)通常仅由少量像素(<0.1%图像面积)构成,且易受云层、建筑群等复杂背景干扰。传统方法通过增加分辨率提升精度,但显著增加计算负担,难以满足嵌入式设备(如无人机芯片)的实时需求。FBRT-YOLO通过轻量化设计,在Visdrone、UAVDT和AI-TOD三大航拍数据集上实现了精度与速度的突破性平衡。
论文链接:https://arxiv.org/pdf/2504.20670
GitHub链接:https://github.com/galaxy-oss/FCM.
2 创新点
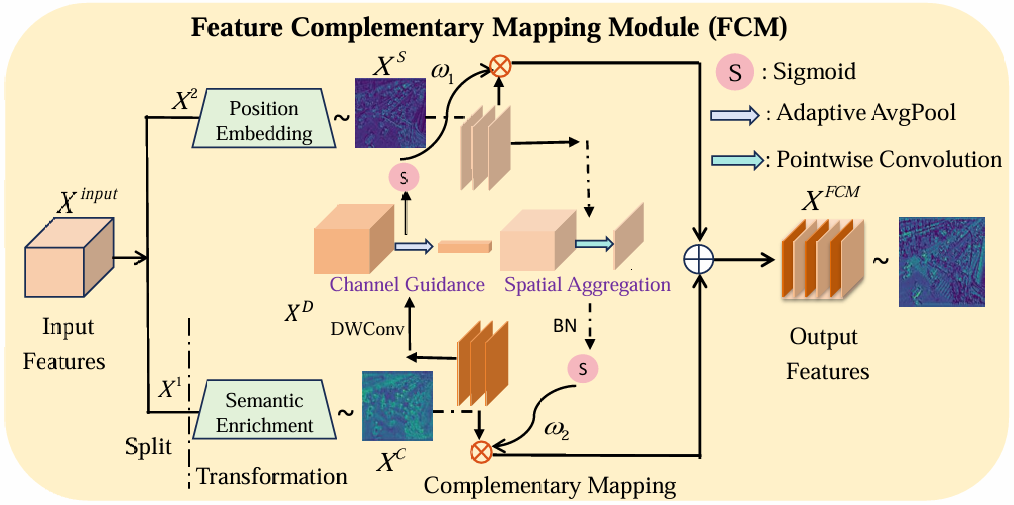
2.1 特征互补映射模块(FCM)
FCM模块致力于解决深层网络中小目标空间信息丢失这一根本问题。传统特征金字塔(如FPN)虽融合深浅层特征,但主干网络在传递过程中仍会弱化小目标的精确位置信息。FCM通过“拆分-变换-互补映射-聚合”四步策略实现信息融合:
- 通道分割:将输入特征按比例α拆分为两部分( X 1 ∈ R α C × H × W , X 2 ∈ R ( 1 − α ) C × H × W ) X¹∈R^{αC×H×W}, X²∈R^{(1-α)C×H×W}) X1∈RαC×H×W,X2∈R(1−α)C×H×W),其中α随网络深度动态调整(深层α更低以保留更多空间信息)。
- 定向变换:X¹分支通过3×3卷积提取语义信息,X²分支通过逐点卷积提取空间位置信息。
- 互补映射:通过通道交互(生成通道权重 W c W_c Wc)和空间交互(生成空间权重 W s W_s Ws)计算信息权重,强化关键特征。
- 特征聚合:按公式 Y = W c ⋅ X 1 + W s ⋅ X 2 Y = W_c·X¹ + W_s·X² Y=Wc⋅X1+Ws⋅X2融合信息,使深层特征同时保有语义和位置信息。
2.2 多内核感知单元(MKP)
针对航拍图像中目标尺度差异大的挑战,MKP取代了YOLO的最终下采样层,采用多尺度卷积核级联结构增强感受野适应性:
- 并行使用3×3、5×5、7×7卷积核提取不同尺度特征
- 通过逐点卷积(A)整合跨尺度信息,公式表达为: M K P ( X ) = A ( C o n v k = 3 ( X ) ⊕ C o n v k = 5 ( X ) ⊕ C o n v k = 7 ( X ) ) MKP(X) = A(Conv_{k=3}(X) ⊕ Conv_{k=5}(X) ⊕ Conv_{k=7}(X)) MKP(X)=A(Convk=3(X)⊕Convk=5(X)⊕Convk=7(X))
该设计避免单一卷积核的局限性:小卷积核感受野不足,大卷积核引入过多背景噪声。
2.3 冗余驱动的轻量化设计
传统检测器在高分辨率图像处理中存在结构冗余。FBRT-YOLO通过两项精简策略优化效率:
- 下采样层重构:用分组卷积替代标准卷积执行空间下采样,后续接逐点卷积扩展通道,参数量降至标准卷积的1/4(公式对比: P a r a m s s t d = k 2 C i n C o u t , P a r a m s o p t = k 2 C i n G + C i n C o u t Params_{std}=k²C_inC_out, Params_{opt}=k²C_inG + C_inC_out Paramsstd=k2CinCout,Paramsopt=k2CinG+CinCout,G为分组数)。
- 检测头简化:结合MKP单元移除冗余检测头,减少输出层计算量。
3 方法
3.1 整体架构
FBRT-YOLO以YOLOv8为基线,主干网络嵌入FCM模块替代原C2f单元,并在最后一层用MKP单元替换下采样操作。整体架构分为三阶段:
- 特征提取:输入图像经多层卷积,每阶段输出接入FCM模块融合空间-语义信息。
- 多尺度感知:MKP单元在最终阶段捕获大范围上下文,输出多尺度特征图。
- 检测头:精简后的头部输出预测框(类别、置信度、坐标)。
3.2 FCM模块技术细节
- 通道交互机制:通过全局平均池化生成通道权重 W c = σ ( M L P ( G A P ( X ) ) ) ( σ 为 S i g m o i d ) W_c = σ(MLP(GAP(X)))(σ为Sigmoid) Wc=σ(MLP(GAP(X)))(σ为Sigmoid)
- 空间注意力:空间权重 W s = σ ( C o n v 1 × 1 ( C o n c a t [ A v g P o o l ( X ) , M a x P o o l ( X ) ] ) ) W_s = σ(Conv_{1×1}(Concat[AvgPool(X), MaxPool(X)])) Ws=σ(Conv1×1(Concat[AvgPool(X),MaxPool(X)]))
- 分割比例策略:实验表明α取(0.75, 0.75, 0.25, 0.25)时效果最佳(即深层保留更多空间信息)。
3.3 FCM模块创新特点
FCM模块的创新之处在于:
- 通道分割策略:1:3比例分割,深层网络保留更多位置信息
- 双分支异构处理:语义分支(3×3卷积) + 位置分支(1×1卷积)
- 双向注意力互补:空间注意力和通道注意力交叉作用
- 轻量化设计:仅使用标准卷积操作,计算高效
4 效果
4.1 性能对比实验
在三大航拍数据集上的测试表明,FBRT-YOLO全面超越现有实时检测器:
- Visdrone数据集:FBRT-YOLO-S模型AP达30.1%,较YOLOv8-S提升2.3%,参数量减少74%。
- UAVDT数据集:AP为18.4%,超过GLSAN(17.1%)和CEASC(17.6%)。
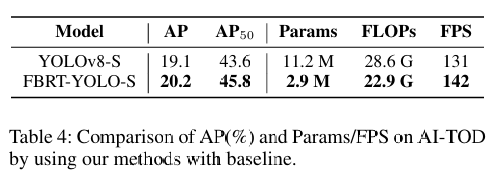
- AI-TOD数据集(小目标为主):AP50提升2.2%,GFLOPs降低20%。
表2:Visdrone数据集上模型性能对比
| 模型 | AP(%) | 参数量(M) | GFLOPs | 推理速度(FPS) |
|---|---|---|---|---|
| YOLOv8-S | 27.8 | 11.1 | 28.6 | 142 |
| FBRT-YOLO-S | 30.1 | 2.9 | 22.8 | 189 |
| RT-DETR-R34 | 28.9 | 19.2 | 98.3 | 156 |
| FBRT-YOLO-M | 30.2 | 18.7 | 76.5 | 173 |
4.2 消融实验
以YOLOv8-S为基线,逐步引入改进组件:
- 冗余优化:参数减少18%,计算负载降11%,精度略降0.2%(AP)。
- 添加FCM:AP50提升1.4%,因特征增强补偿了精度损失。
- 替换MKP:AP提升1.6%,训练收敛速度加快30%。
可视化热图显示,FBRT-YOLO对密集小目标的响应强度显著高于基线模型,尤其在车辆群、行人小目标等场景中关注区域更精确。
4.3 效率优势
- 边缘部署潜力:FBRT-YOLO-N仅2.9M参数,在嵌入式GPU上达189 FPS,较YOLOv8-N加速45%。
- 计算负载优化:MKP单元通过多核并行计算,单帧处理延迟降至5ms以下,满足无人机实时避障需求。
5 总结
FBRT-YOLO通过特征互补映射模块(FCM) 与多内核感知单元(MKP) 的创新设计,解决了航拍图像检测中小目标信息丢失和多尺度适应性不足的核心问题。其贡献主要体现在三方面:
- 理论层面:提出空间-语义信息互补映射机制,缓解深层网络位置信息衰减问题;
- 工程层面:轻量化设计(参数量最高降74%)满足嵌入式设备实时需求;
- 应用层面:在Visdrone等数据集上AP提升1.1-2.3%,为无人机安防、灾害监测提供高效解决方案。
代码
import torch
import torch.nn as nn
import torch.nn.functional as F# 辅助函数:自动计算padding大小
def autopad(k, p=None, d=1):"""Pad to 'same' shape outputs."""if d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k]if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k]return p# 标准卷积模块(带激活函数)
class Conv(nn.Module):def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))# 通道注意力模块
class Channel(nn.Module):def __init__(self, dim):super().__init__()self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim) # 深度可分离卷积self.Apt = nn.AdaptiveAvgPool2d(1) # 全局平均池化self.sigmoid = nn.Sigmoid()def forward(self, x):x2 = self.dwconv(x) # 提取空间特征x5 = self.Apt(x2) # 压缩空间维度x6 = self.sigmoid(x5) # 生成通道权重return x6# 空间注意力模块
class Spatial(nn.Module):def __init__(self, dim):super().__init__()self.conv1 = nn.Conv2d(dim, 1, 1, 1) # 通道压缩到1self.bn = nn.BatchNorm2d(1) # 单通道BNself.sigmoid = nn.Sigmoid()def forward(self, x):x1 = self.conv1(x) # 空间特征提取x5 = self.bn(x1) # 标准化x6 = self.sigmoid(x5) # 生成空间权重return x6# 特征互补映射模块(核心创新)
class FCM(nn.Module):def __init__(self, dim):super().__init__()# 通道分割比例:1/4 vs 3/4self.one = dim // 4self.two = dim - dim // 4# 语义分支(小通道):3×3卷积提取语义信息self.conv1 = Conv(dim // 4, dim // 4, 3, 1, 1)self.conv12 = Conv(dim // 4, dim // 4, 3, 1, 1)self.conv123 = Conv(dim // 4, dim, 1, 1) # 1×1卷积扩展通道# 位置分支(大通道):1×1卷积保持位置信息self.conv2 = Conv(dim - dim // 4, dim, 1, 1)# 特征融合self.conv3 = Conv(dim, dim, 1, 1) # 最终融合卷积# 注意力机制self.spatial = Spatial(dim) # 空间注意力self.channel = Channel(dim) # 通道注意力def forward(self, x):# 1. 通道分割x1, x2 = torch.split(x, [self.one, self.two], dim=1)# 2. 语义分支处理x3 = self.conv1(x1) # 3×3卷积提取语义x3 = self.conv12(x3) # 再次3×3卷积增强x3 = self.conv123(x3) # 1×1卷积扩展通道到dim# 3. 位置分支处理x4 = self.conv2(x2) # 1×1卷积保持位置信息# 4. 互补映射(论文核心创新)# 空间注意力作用于语义分支spatial_attn = self.spatial(x4) # 基于位置分支生成空间注意力图x33 = spatial_attn * x3 # 空间注意力加权语义特征# 通道注意力作用于位置分支channel_attn = self.channel(x3) # 基于语义分支生成通道注意力x44 = channel_attn * x4 # 通道注意力加权位置特征# 5. 特征聚合x5 = x33 + x44 # 互补特征相加融合x5 = self.conv3(x5) # 1×1卷积融合特征return x5if __name__ == "__main__":# 定义输入张量大小(Batch、Channel、Height、Wight)B, C, H, W = 16, 64, 40, 40input_tensor = torch.randn(B,C,H,W) # 随机生成输入张量dim=C# 创建 ARConv 实例block = FCM(dim=64)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")sablock = block.to(device)print(sablock)input_tensor = input_tensor.to(device)# 执行前向传播output = sablock(input_tensor)# 打印输入和输出的形状print(f"Input: {input_tensor.shape}")print(f"Output: {output.shape}")
关键创新点解析
1. 通道分割策略(论文中的α比例)
self.one = dim // 4 # 1/4通道用于语义分支
self.two = dim - dim //4 # 3/4通道用于位置分支
- 实现论文中的α=0.25分割比例
- 深层网络保留更多位置信息(3/4通道)
- 符合航拍图像小目标检测需求
2. 双分支特征处理
语义分支(小通道):
x3 = self.conv1(x1) # 3×3卷积
x3 = self.conv12(x3) # 再次3×3卷积
x3 = self.conv123(x3) # 1×1卷积扩展通道
- 使用3×3卷积提取丰富语义信息
- 通过两次卷积增强特征表示能力
- 1×1卷积扩展通道实现维度匹配
位置分支(大通道):
x4 = self.conv2(x2) # 1×1卷积
- 仅使用1×1卷积处理
- 最大程度保留原始位置信息
- 避免卷积操作破坏小目标位置特征
3. 互补注意力机制(论文核心)
# 空间注意力作用于语义分支
spatial_attn = self.spatial(x4) # 从位置分支生成
x33 = spatial_attn * x3 # 加权语义特征# 通道注意力作用于位置分支
channel_attn = self.channel(x3) # 从语义分支生成
x44 = channel_attn * x4 # 加权位置特征
- 双向注意力交互:两个分支相互提供注意力指导
- 空间注意力:基于位置分支生成,增强语义分支的关键区域
- 通道注意力:基于语义分支生成,强化位置分支的重要特征通道
- 实现论文中的"互补映射"机制
4. 特征融合
x5 = x33 + x44 # 特征相加融合
x5 = self.conv3(x5) # 1×1卷积进一步融合
- 简单有效的逐元素相加融合
- 1×1卷积实现跨通道信息整合
- 保持特征图尺寸不变
模块工作流程
- 输入分割:将输入特征图按1:3比例分割通道
- 双分支处理:
- 小通道分支:通过3×3卷积提取语义信息
- 大通道分支:通过1×1卷积保留位置信息
- 注意力交互:
- 从位置分支生成空间注意力,加权语义分支
- 从语义分支生成通道注意力,加权位置分支
- 特征聚合:加权后的特征相加并通过1×1卷积融合