九、MySQL执行原理
一、前提
MySQL执行查询时一般情况下最多使用一个非聚簇索引。
特殊情况会用到多个非聚簇索引,叫索引合并 - index merge。
查询一张表:从磁盘加载数据到内存,在内存中使用条件匹配,使用I/O(开销最大)。
一、单表访问之Intersection合并(交集合并)
1、根据不同的搜索条件读取到多个不同的二级索引;
2、从多个二级索引中得到主键的交集;(顺序I/O)
3、拿着这些主键去回表操作;
只读取一个二级索引的步骤
1、按照某个条件读取到一个二级索引;
2、根据二级索引得到主键,进行回表操作;(随机I/O)
3、按其他条件再过滤一次;
要走intersection合并,有以下条件:
1、等值匹配(二级索引);
2、主键索引可以用范围查询
3、如果用联合索引,那么需要使用联合索引的全部字段;
4、最终是否走索引合并,需要查询优化器预估性能后决定;
推荐使用联合索引代替intersection优化。
二、单表访问之Union合并 + Sort-Union(并集合并)
union合并 - or条件;
1、从多个二级索引中获得主键的并集;
2、其他字段需要等值匹配,联合索引字段需要全匹配;
3、主键字段是范围查询也可以;
1、如果查询条件出现:name = 'a' or (age = 15 or user = 16);那么会先将括号里面进行索引合并,取到主键
2、union合并:取括号里主键的交集,将这个交集 与 其他条件主键 取并集;
3、回表;
Sort-Union
1、读取第一个条件的索引,将拿到的主键排序;
2、读取第二个条件的索引,将拿到的主键排序;
3、将这两波主键合并,回表;
三、连接查询简介(join)
1、join 两个误区
两个极端:硬用和不用
业务至上:再复杂的查询,都放到一个连接中查询;
干脆不使用连接查询;
2、连接的本质
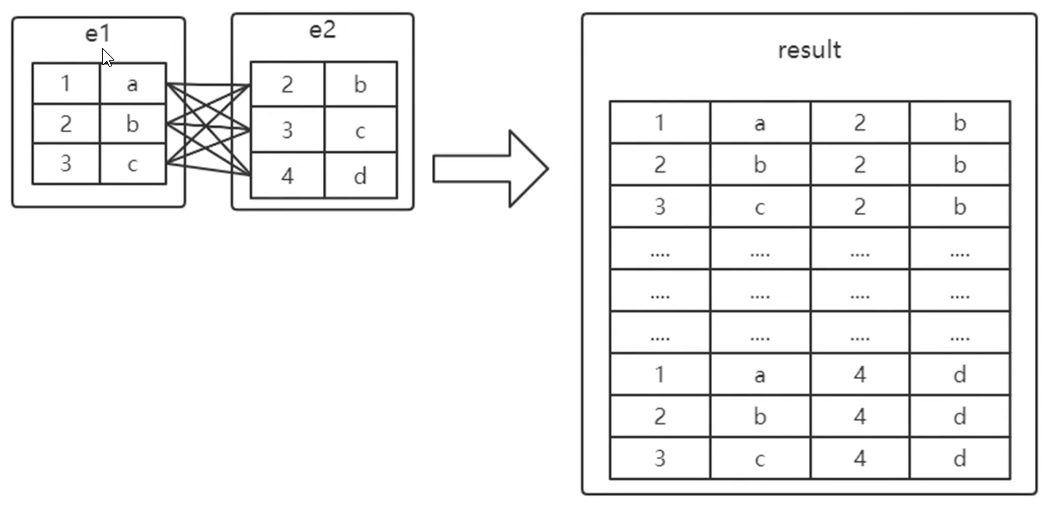
笛卡尔积:行数 * 行数
把每个连接表的记录都取出来,A表的每一行,都要一 一对应到B表的所有行,一起放入结果集返回给用户。
驱动表和被驱动表:
- 驱动表:第一个确定要查询的表; //遍历1次
- 被驱动表:第二个确定的表叫被驱动表; //遍历多次,取决于驱动表返回的条数
- 大表做驱动表好,少遍历,快;
四、内连接与外连接
1、内连接
select * from a1 inner join a2 where a1.name= a2.name;
-- a1,a2;
-- a1 join a2;
-- a1 inner join a2;
-- a1 cross join a2;
2、外连接
左外连接(左边是驱动表) LEFT JOIN
右外连接(右边是驱动表) RIGHT JOIN
五、MySQL对连接的执行
1、 索引
使用索引可以提高被驱动表的查询速度
2、基于块的嵌套循环连接
扫描一张表的时候,可能前面的数据进内存了,后边的数据还在外存;
如果被驱动表太大,内存放不下;那么每次遍历被驱动表,都要交换内存;
join buffer:
- 在连接查询时,申请一块固定大小的内存;将驱动表的一部分数据放进去
- join buffer 不会将驱动表的全部字段加载进去,只会加载查询的字段和条件字段
- 被驱动表的数据在做驱动表的匹配时,一次匹配多条驱动表的记录
- 可以有效减少被驱动表的I/O次数
- 查看参数:show variables like 'join_buffer_size'
六、MySQL执行原理
待补充
七、MySQL的查询成本计算
1、成本的具体项
I/O成本:查询时将磁盘的数据加载到内存中;需要消耗时间 --> I/O成本;
读取一个页(B+树的叶子页 16KB),默认成本 = 1.0;
CPU成本:读取、检测、数据排序;一条数据 = 0.2;
2、单表查询的成本
SQL执行之前,mysql分析,计算执行成本最小的SQL。
根据搜索条件,找出所有可能使用的索引。
对比各种执行方案的代价,选择成本最小的。
计算全表扫描的代价 - I/O成本 + CPU计算成本:
- 查询表信息:show table status like 'order_exp'\G
- I/O成本 = Data_length / 1024 / 16 + 微调数(1.1)
- CPU 成本 = 0.2 * Rows + 微调数(1.0)
计算使用不同索引执行查询的代价:
- I/O成本 = 查询索引(1) + 条数成本(rows * 1.0);
- CPU成本 = 读取二级索引的记录(rows * 0.2) + 微调成本(0.01)+ 回表成本(rows * 0.2);
3、读取MySQL查询语句的查询成本
explain format = json select * from XXX;
读取MySQL查询语句成本计算的过程:
show variables like 'optimizer_trace';set optimizer_trace = 'enabled=on';explain select * from XXX;select * from information_schema.OPTIMIZER_TRACE\G4、两表连接查询的成本计算
单次查询驱动表的成本(驱动表的扇出 fanout)
- 面对复杂的查询条件,会猜测可能符合的数据量
多次查询被驱动表的成本(数据取决于驱动表的扇出数据【驱动表的最终查询结果集有多少】)
八、基于成本计算的实战
待补充
九、Explain与查询成本
1、控制查询成本
- 提前结束
- 连接的深度,设置连接表的数量阈值,超出的表舍弃掉
- 启发规则,根据以往的经验提前终止执行计划的分析
2、调节成本参数
show variables like 'cost';十、MySQL的查询重写规则
- 条件化简
- 外连接消除:如果查询的数据一样,转化为内连接;