词法分析器
1 项目概述
本词法分析器(Lexical Analyzer)实现了对源代码文本的完整解析功能,能够准确拆分成有意义的token序列。该系统支持处理多种编程语言的常见语法元素,涵盖标识符、数字常量、字符串、运算符、分隔符以及关键字等基本语法单位。
多token类型支持:标识符、数字、字符串、运算符、关键字等
精确位置跟踪:准确记录每个token的行号和列号
错误处理机制:识别并报告词法错误
图形化界面:提供直观的分析结果展示
扩展性设计:易于添加新的token类型和语言特性
编译器前端开发
代码静态分析工具
语法高亮器
DSL(领域特定语言)开发
编程语言教学
2 整体架构
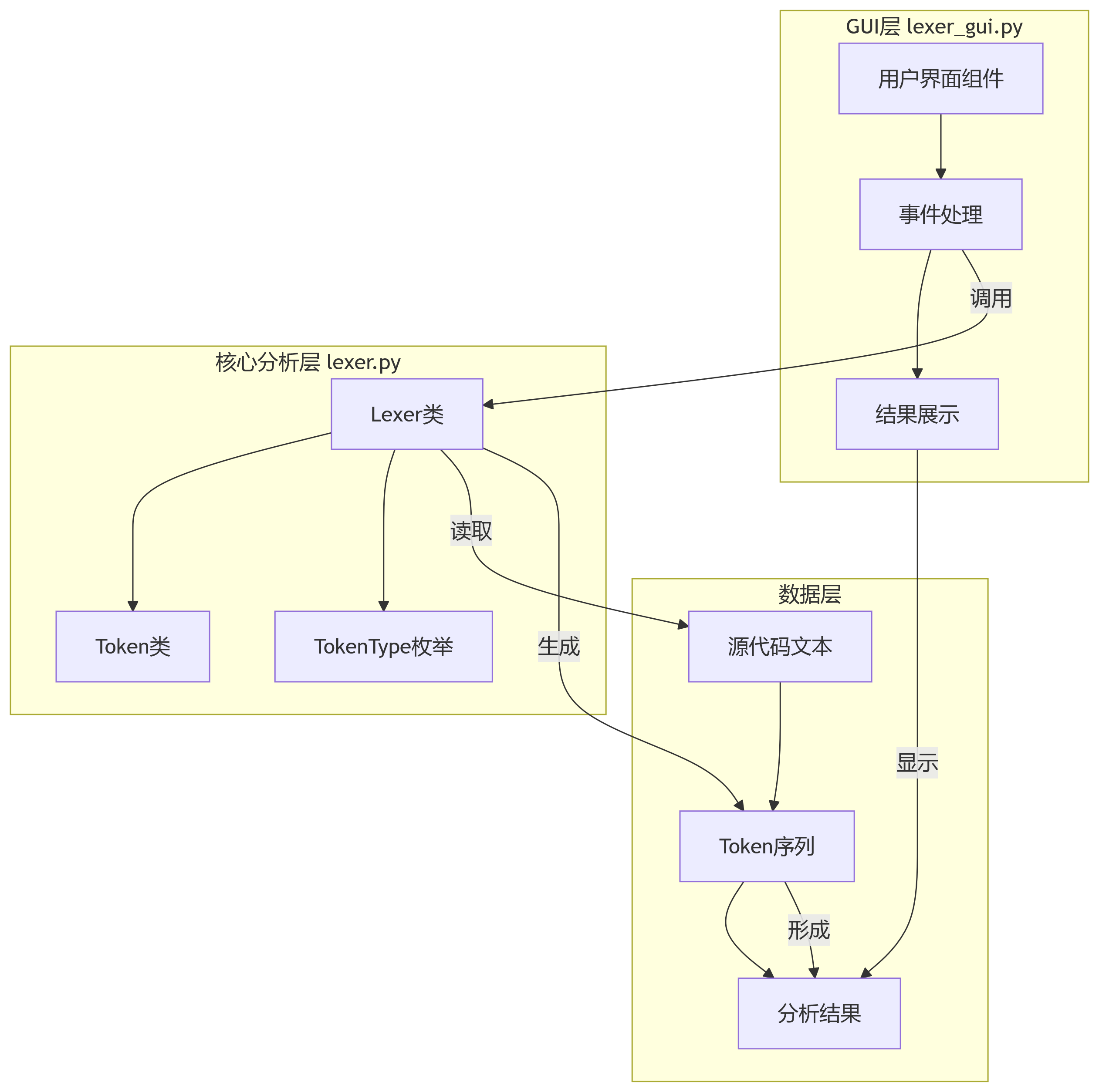
3 核心模块
3.1 TokenType枚举
```python
class TokenType(Enum):# 标识符和字面量IDENTIFIER = "IDENTIFIER" # 变量名、函数名NUMBER = "NUMBER" # 数字字面量STRING = "STRING" # 字符串字面量# 运算符PLUS = "PLUS" # +MINUS = "MINUS" # -MULTIPLY = "MULTIPLY" # *DIVIDE = "DIVIDE" # /ASSIGN = "ASSIGN" # =EQUAL = "EQUAL" # ==NOT_EQUAL = "NOT_EQUAL" # !=LESS_THAN = "LESS_THAN" # <GREATER_THAN = "GREATER_THAN" # >LESS_EQUAL = "LESS_EQUAL" # <=GREATER_EQUAL = "GREATER_EQUAL" # >=# 分隔符LEFT_PAREN = "LEFT_PAREN" # (RIGHT_PAREN = "RIGHT_PAREN" # )LEFT_BRACE = "LEFT_BRACE" # {RIGHT_BRACE = "RIGHT_BRACE" # }SEMICOLON = "SEMICOLON" # ;COMMA = "COMMA" # ,# 关键字IF = "IF"ELSE = "ELSE"WHILE = "WHILE"FOR = "FOR"FUNCTION = "FUNCTION"RETURN = "RETURN"VAR = "VAR"# 特殊tokenNEWLINE = "NEWLINE"EOF = "EOF"ERROR = "ERROR"
```3.2 Token数据类
```python
@dataclass
class Token:type: TokenType # token类型value: str # token值line: int # 行号column: int # 列号
```3.3 Lexer核心类
```python
class Lexer:def __init__(self, text: str)def advance(self)def peek(self, offset: int = 1) -> Optional[str]def skip_whitespace(self)def read_number(self) -> strdef read_string(self, quote_char: str) -> strdef read_identifier(self) -> strdef get_next_token(self) -> Tokendef tokenize(self) -> List[Token]
```
3.4 核心属性
```python
self.text: str # 源代码文本
self.pos: int # 当前位置指针
self.line: int # 当前行号
self.column: int # 当前列号
self.current_char: str # 当前字符
self.keywords: Dict # 关键字映射表
```4 算法实现
4.1 词法分析算法
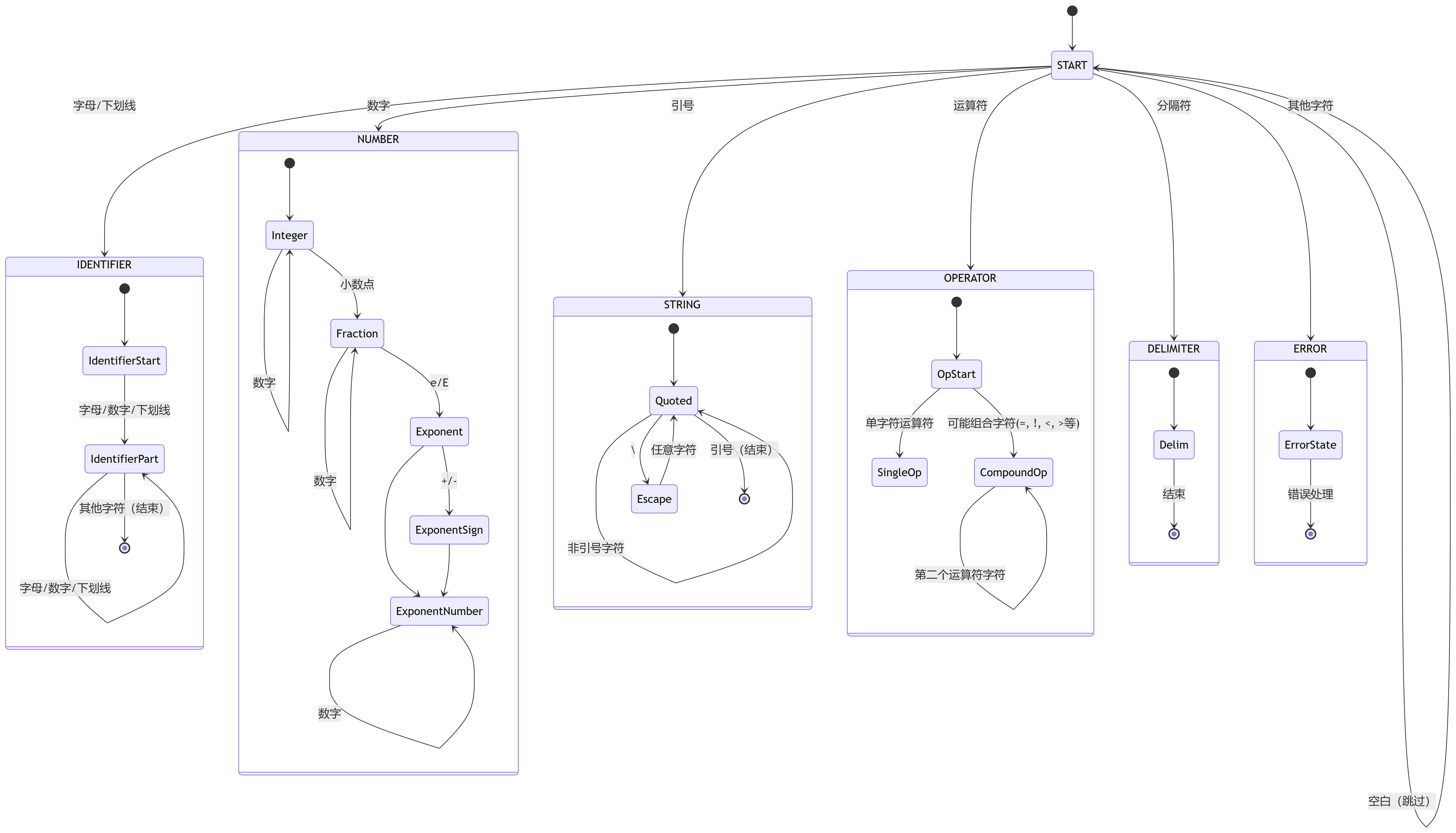
```python
def tokenize_algorithm():"""词法分析算法伪代码"""tokens = []position = 0while position < len(source_code):# 1. 跳过空白字符skip_whitespace()# 2. 记录当前位置start_position = current_position# 3. 根据当前字符确定token类型if is_letter_or_underscore(current_char):token = read_identifier_or_keyword()elif is_digit(current_char):token = read_number()elif is_quote(current_char):token = read_string()elif is_operator(current_char):token = read_operator()elif is_delimiter(current_char):token = read_delimiter()else:token = create_error_token()# 4. 添加到token列表tokens.append(token)# 5. 移动到下一个位置advance_position()return tokens
```4.2 数字识别算法
```python
def read_number(self) -> str:"""读取数字(支持整数和浮点数)状态机:START → [数字] → INTEGER → [.] → DECIMAL → [数字] → DECIMAL"""result = ''has_dot = Falsewhile (self.current_char is not None and (self.current_char.isdigit() or (self.current_char == '.' and not has_dot))):if self.current_char == '.':has_dot = Trueresult += self.current_charself.advance()return result
```4.3 字符串识别算法
```python
def read_string(self, quote_char: str) -> str:"""读取字符串字面量Args:quote_char: 引号字符(' 或 ")支持转义序列:\n, \t, \r, \\, \", \'"""result = quote_charself.advance() # 跳过开始引号while self.current_char is not None and self.current_char != quote_char:if self.current_char == '\\':# 处理转义字符result += self.current_charself.advance()if self.current_char is not None:result += self.current_charself.advance()else:result += self.current_charself.advance()if self.current_char == quote_char:result += self.current_charself.advance()return result
```4.4 标识符识别算法
```python
def read_identifier(self) -> str:"""读取标识符规则:- 首字符:字母或下划线- 后续字符:字母、数字或下划线"""result = ''while (self.current_char is not None and (self.current_char.isalnum() or self.current_char == '_')):result += self.current_charself.advance()return result
```5 性能分析
5.1 时间复杂度
整体算法: O(n),其中n是源代码的字符数
单字符处理: O(1)
数字识别: O(k),其中k是数字的位数
字符串识别: O(m),其中m是字符串的长度
标识符识别: O(l),其中l是标识符的长度
5.2 空间复杂度
输入存储: O(n),存储源代码文本
输出存储: O(t),其中t是token的数量
辅助空间: O(1),仅使用常量额外空间
6 图形界面设计
6.1 界面架构
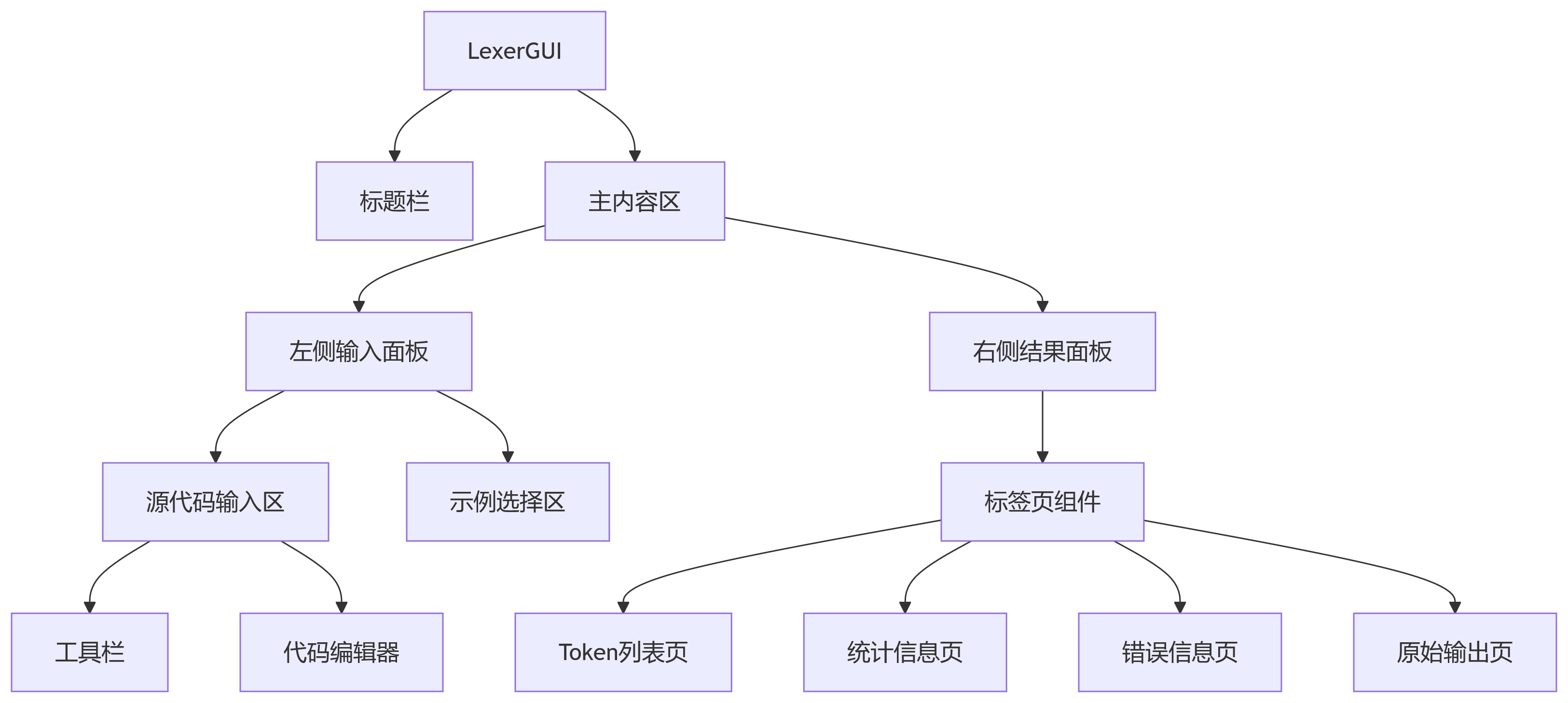
6.2 核心组件
目录
1 项目概述
2 整体架构
3 核心模块
3.1 TokenType枚举
3.2 Token数据类
3.3 Lexer核心类
3.4 核心属性
4 算法实现
4.1 词法分析算法
4.2 数字识别算法
4.3 字符串识别算法
4.4 标识符识别算法
5 性能分析
5.1 时间复杂度
5.2 空间复杂度
6 图形界面设计
6.1 界面架构
6.2 核心组件
7 API接口文档
7.1 Lexer类接口
7.2 使用示例
8 扩展指南
8.1 添加新的Token类型
8.2 支持新的数据类型
9 测试说明
9.1 单元测试
10 错误处理机制
10.1 错误类型
编辑
```python
self.code_text = scrolledtext.ScrolledText(input_frame, height=20, font=('Consolas', 11),wrap=tk.WORD
)
``````python
columns = ('序号', 'Token类型', 'Token值', '行号', '列号')
self.token_tree = ttk.Treeview(tokens_frame, columns=columns, show='headings', height=15
)
```7 API接口文档
7.1 Lexer类接口
```python
def __init__(self, text: str)
``````python
def tokenize(self) -> List[Token]
```7.2 使用示例
```python
from lexer import Lexer, TokenType# 创建词法分析器
source_code = """
x = 10 + 20;
if (x > 15) {print("大于15");
}
"""lexer = Lexer(source_code)
tokens = lexer.tokenize()# 处理结果
for token in tokens:if token.type != TokenType.EOF:print(f"类型: {token.type.value:15} "f"值: {token.value:10} "f"位置: ({token.line}, {token.column})")
```
8 扩展指南
8.1 添加新的Token类型
```python
class TokenType(Enum):# 现有类型...# 新增类型ARROW = "ARROW" # ->DOUBLE_COLON = "DOUBLE_COLON" # ::TRIPLE_EQUAL = "TRIPLE_EQUAL" # ===
``````python
def get_next_token(self):# 现有逻辑...# 添加新的识别逻辑if self.current_char == '-' and self.peek() == '>':self.advance()self.advance()return Token(TokenType.ARROW, '->', line, column)
```8.2 支持新的数据类型
```python
def read_hex_number(self) -> str:"""读取十六进制数字 (0x...或0X...)"""result = '0'self.advance() # 跳过'0'if self.current_char and self.current_char.lower() == 'x':result += self.current_charself.advance()while (self.current_char and self.current_char.lower() in '0123456789abcdef'):result += self.current_charself.advance()return result
```9 测试说明
9.1 单元测试
```python
import unittest
from lexer import Token, TokenTypeclass TestToken(unittest.TestCase):def test_token_creation(self):token = Token(TokenType.IDENTIFIER, "variable", 1, 5)self.assertEqual(token.type, TokenType.IDENTIFIER)self.assertEqual(token.value, "variable")self.assertEqual(token.line, 1)self.assertEqual(token.column, 5)
``````python
class TestLexer(unittest.TestCase):def test_simple_assignment(self):lexer = Lexer("x = 10")tokens = lexer.tokenize()expected_types = [TokenType.IDENTIFIER,TokenType.ASSIGN,TokenType.NUMBER,TokenType.EOF]for token, expected_type in zip(tokens, expected_types):self.assertEqual(token.type, expected_type)
```
10 错误处理机制
10.1 错误类型
未知字符错误: 遇到无法识别的字符
字符串未闭合错误: 字符串缺少结束引号
数字格式错误: 不合法的数字格式
```python
def handle_lexical_error(self, char: str) -> Token:"""处理词法错误Args:char: 引起错误的字符Returns:错误Token"""error_token = Token(TokenType.ERROR, char, self.line, self.column)# 错误恢复:跳过错误字符self.advance()return error_token
```