关于MQ之kafka的深入研究
目录
1、MQ介绍
1.1、性能对比
1.2、分布式设计
1.3、ACK应答机制
2、Kafka的介绍
2.1、核心组件
2.2、核心特性
2.3、消费 Leader数据
2.4、如何找到 Leader 副本
2.5、消费者组与分区分配
2.6、消费者读取数据的流程
2.7、leader切换的流程
3、kafka架构设计
3.1、消费者组
3.2、消费者和broker联系
3.3、消费模型对比
3.4、消费同一partion原因
1. Offset 的独立性
2. 多订阅场景的需求
3. Partition 的 Leader 机制
4、常见问题
前言
Apache Kafka 是一个 分布式流处理平台,最初由 LinkedIn 开发,后成为 Apache 软件基金会的顶级开源项目。
Kafka 的核心目标是 构建实时数据管道和流式应用,支持高吞吐量、持久化、水平扩展和容错能力。它广泛应用于日志聚合、消息队列、事件溯源、流式处理等领域。
更多关于队列MQ的介绍,可参考:MQ消息队列的深入研究-CSDN博客
1、MQ介绍
1.1、性能对比
Kafka、RabbitMQ、RocketMQ 和 ActiveMQ 是流行的消息队列解决方案,它们在架构设计、性能、特性和适用场景上各有不同。
如下图所示:
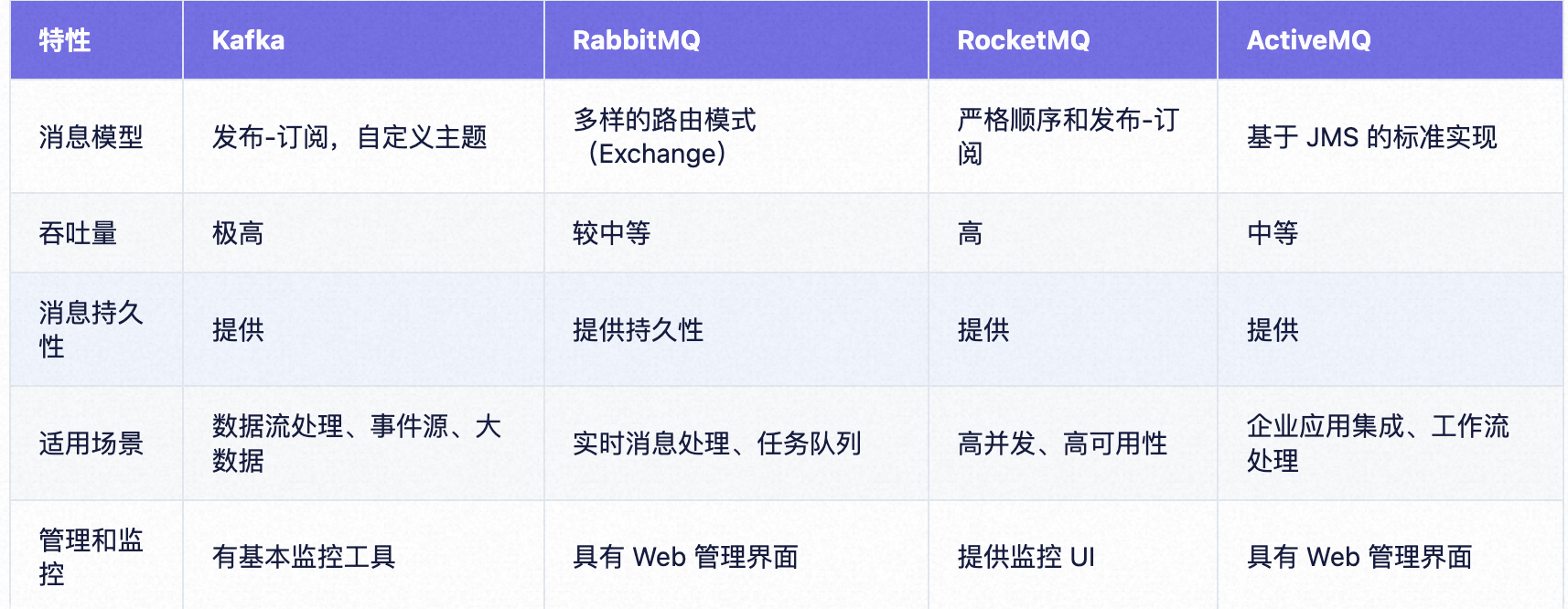
Kafka 适合高吞吐量和流式数据处理,RabbitMQ 适合需要复杂路由和灵活性场景,RocketMQ 适用于高并发的应用场景,而 ActiveMQ 则适合企业级 Java 应用集成。
1.2、分布式设计
对于kafka来讲:
Kafka是分布式的:其所有的构件borker(服务端集群)、producer(消息生产)、consumer(消息消费者)都可以是分布式的。
可以进行分区:每一个分区Partion都是一个顺序的、不可变的消息队列, 并且可以持续的添加。
1.3、ACK应答机制
本设计为面试重点提问:
producer在向kafka写入消息的时候,可以设置参数来确定是否确认kafka接收到数据,这个参数可设置 的值为 0,1,all。
0:
代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效 率最高。
1:
代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
all:
代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保 leader发送成功和所有的副本都完成备份。安全性最⾼高,但是效率最低。
⚠️注意:
如果往不存在的topic写数据,kafka会⾃动创建topic,partition和replication的数量 默认配置都是1。
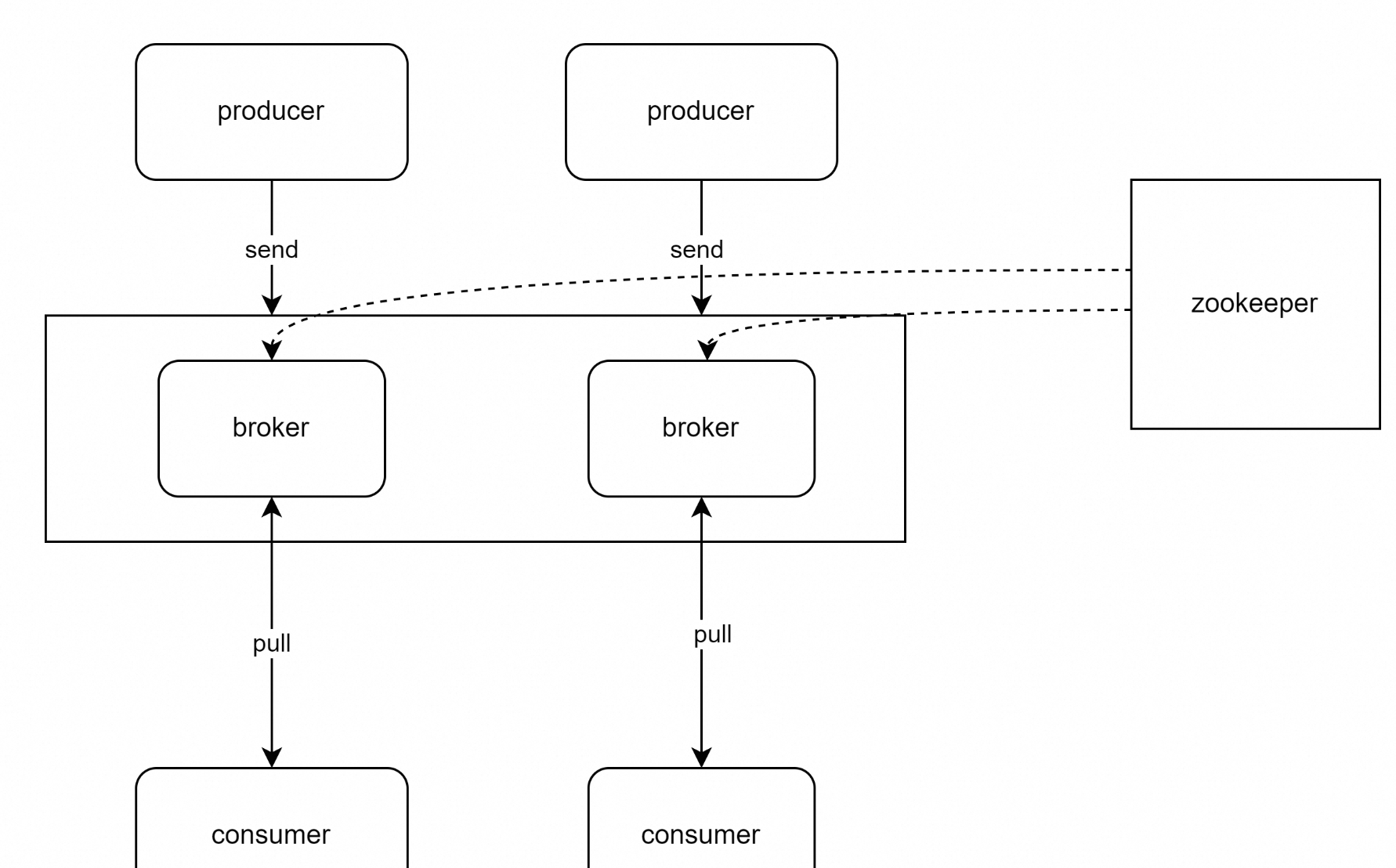
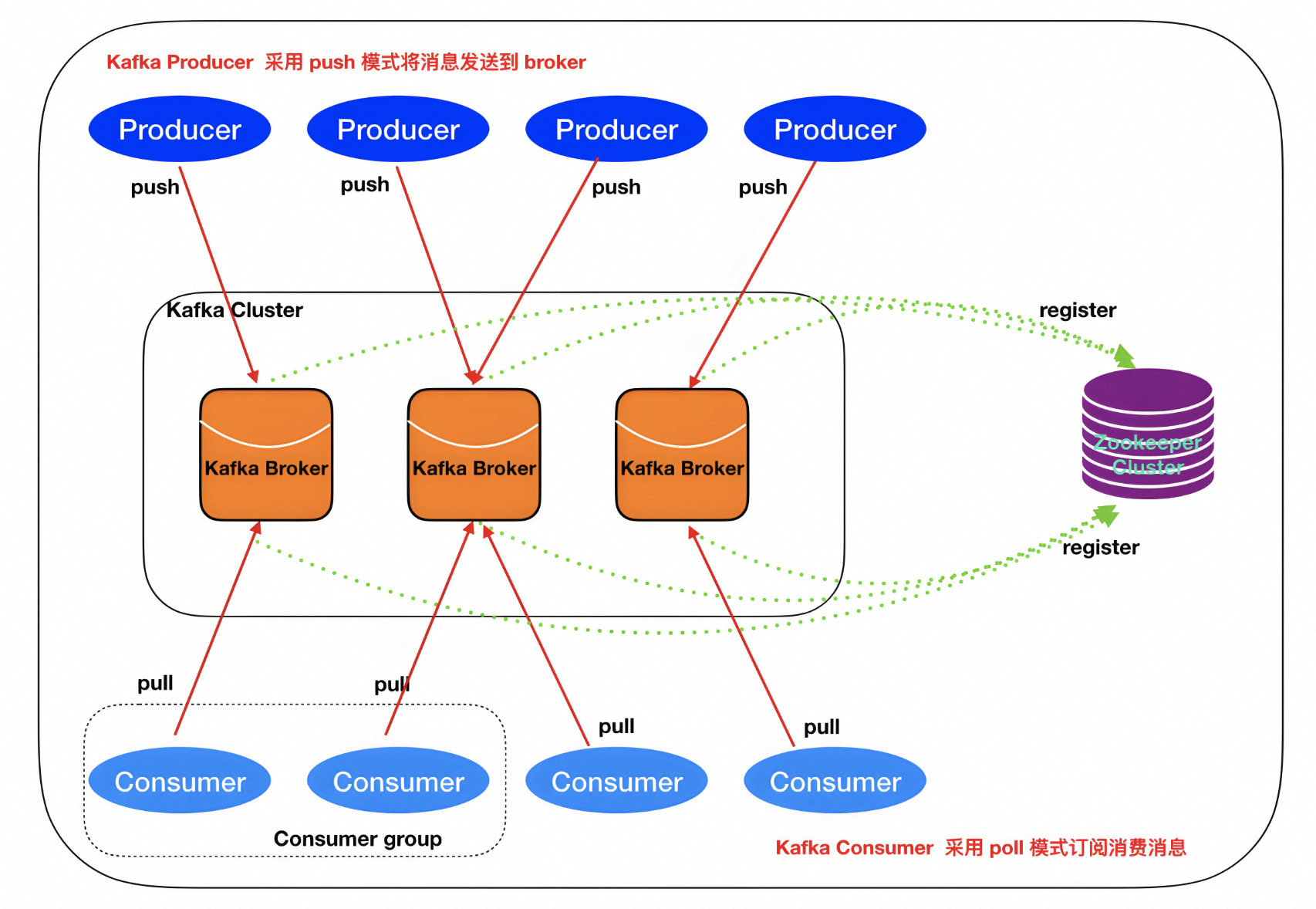
2、Kafka的介绍
如下图所示:
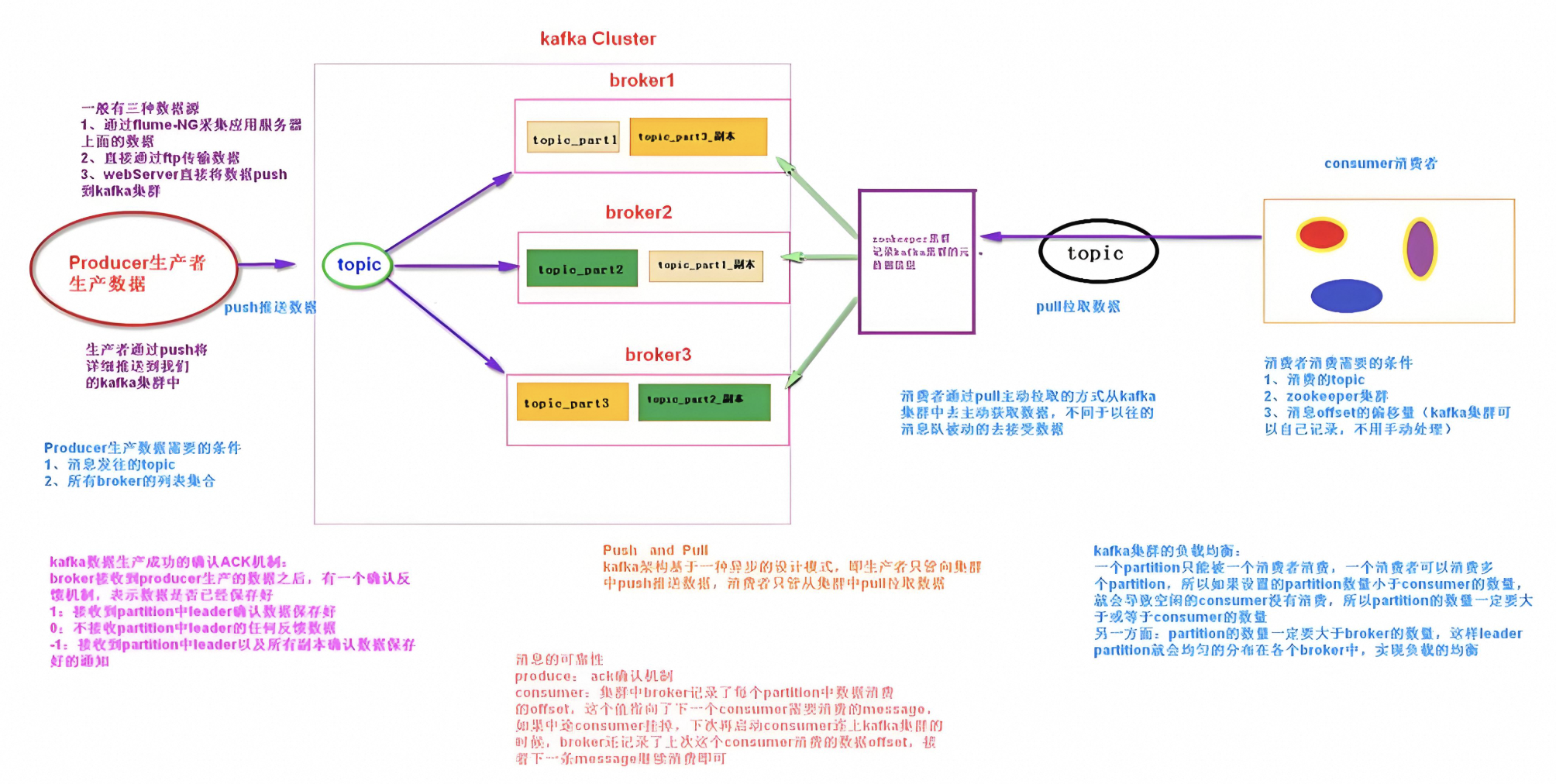
2.1、核心组件
当消息从producer推送给broker,消费者会从broker的leader节点去读取数据。每个broker对应的不同的节点。
1. Producer(生产者)
- 作用:将数据写入 Kafka 集群。
- 特性:
- 支持异步发送和同步发送。
- 可以指定消息的 Key 和 Value,用于分区策略。
- 消息会被发送到指定的 Topic 和 Partition。
具体写入的流程,如下:
消息发送:
当生产者发送消息时,首先计算消息的哈希值,以决定将消息发送到哪个分区。默认情况下,Kafka 使用轮询策略和关键字哈希来分配消息。
异步发送:生产者可以选择异步发送消息,这样可以提升发送效率。Kafka 会在后台处理消息的生产,在网络性能允许的情况下,可以并行发送。
确认机制:生产者可以配置确认等级(acks),如:
acks=0:不要求确认,速度最快。
acks=1:主 Broker 确认(数据成功写入到领导者)。
acks=all(或 acks=-1):所有副本都成功确认,最高的可靠性。
2. Consumer(消费者)
如下图所示:
- 作用:从 Kafka 集群读取数据。
- 特性:
- 消费者属于一个 Consumer Group(消费者组),组内消费者共同消费 Topic 的 Partition。
- 支持 offset 管理(记录消费位置),可通过自动提交或手动提交。
- 提供 拉取模型(Pull Model),消费者主动从 Broker 拉取数据。
消费的流程,如下:
消息读取:
消费者可以通过订阅主题来接收消息。消费者可以设置其消费者组,这样同一组内的多个消费者可以共享处理主题topic的负载。
消费位移:每个消费者在 Kafka 中维护自己的消费位移(offset),用于记录它已经消费到的位置。Kafka 允许消费者能够记录和管理自己的消费进度。
组管理:在消费者组内,Kafka 会将各个分区的消息分配给不同的消费者。确保每个分区只能被组内一个消费者处理,避免重复消费。
3. Topic(主题)
- 作用:逻辑上的数据分类,类似数据库中的表。
- 特性:
- 每个 Topic 被划分为多个 Partition(分区),实现水平扩展。
- 消息按顺序存储在 Partition 中(每个 Partition 内有序,跨 Partition 无序)。
4. Partition(分区)
如下图所示:
- 作用:Topic 的物理分片,用于并行处理和水平扩展。
- 特性:
- 每个 Partition 是一个 有序的、不可变的、顺序追加的日志文件。
- 消息在 Partition 中按顺序存储,并通过 Offset(偏移量)标识位置。
- 分区数决定了 Kafka 的并行能力(消费者数不能超过分区数)。
5. Broker(节点)
- 作用:Kafka 集群中的服务器节点,负责存储数据和处理请求。
- 特性:
- 每个 Broker 有唯一 ID。
- 支持水平扩展,新增节点可提升吞吐量和容错能力。
6. Replica(副本)
- 作用:为 Partition 提供冗余备份,确保高可用性。
- 特性:
- 每个 Partition 有多个副本(Leader + Follower)。
- Leader:负责处理读写请求。
- Follower:从 Leader 同步数据,故障时自动选举新 Leader。
7. ZooKeeper
如下图所示:
- 作用:Kafka 集群的协调服务,管理 Broker、Partition 和 Consumer Group 的元数据。
- 关键功能:
- 监控 Broker 状态。
- 管理 Partition 的 Leader 选举。
- 维护 Consumer Group 的消费进度。
2.2、核心特性
相比较于其他mq,kafka的最大特点:高吞吐量。
1. 高吞吐量
- 设计目标:每秒处理百万级消息。
- 优化手段:
- 批量发送:Producer 和 Consumer 支持批量操作,减少网络开销。
- 顺序写入:磁盘顺序写入(Append-Only),避免随机 I/O。
- 零拷贝(Zero-Copy):通过
sendfile系统调用直接从磁盘传输到网络。
2. 持久化与可靠性
- 消息持久化:消息写入磁盘并保留指定时间(如 7 天),避免数据丢失。
- 副本机制:每个 Partition 有多个副本,自动同步数据,确保高可用。
- 确认机制(acks):Producer 可配置
acks=1或acks=all,确保消息被多个副本接收。
3. 水平扩展
- 分区机制:Topic 的 Partition 可动态调整,支持水平扩展。
- 多 Broker 架构:增加 Broker 节点可提升吞吐量和存储容量。
4. 实时流处理
- 流处理 API:Kafka 提供 Kafka Streams 和 KSQL,支持实时计算。
- Exactly-Once 语义:通过事务机制(Transaction)保证消息的精准一次处理。
5. 灵活的消费模式
- 点对点模式:每个消息被一个 Consumer 消费(单播)。
- 发布-订阅模式:每个消息被所有 Consumer Group 消费(广播)。
2.3、消费 Leader数据
消费者在消费过程中,只会去请求leader数据,为什么会这样呢?
1、保证数据一致性:
如果消费者直接从 Follower 读取数据,可能会遇到数据不一致的问题。例如,Follower 可能尚未同步最新的消息,导致消费者读取到旧数据。Leader 是唯一负责写入和同步的副本,消费者直接从 Leader 读取可以确保读取到最新的、完整的数据。
2、简化系统设计:
所有读写操作集中到 Leader,避免了多副本间并发控制的复杂性。如果允许消费者直接读取 Follower,需要额外的协调机制来保证一致性,增加系统复杂度。
3、性能优化:
Follower 的主要职责是数据复制,而非处理读请求。若消费者直接读取 Follower,可能导致 Follower 资源被争用,影响同步效率。
2.4、如何找到 Leader 副本
1、ZooKeeper 的作用:
Kafka 使用 ZooKeeper 维护集群的元数据,包括每个分区的 Leader 和 Follower 信息。
消费者启动时会向 ZooKeeper 查询目标分区的 Leader 位置(Broker ID 和端口)。
2、动态感知 Leader 变更:
如果 Leader 副本故障,Kafka 会触发 Leader 选举,从 Follower 中选出新的 Leader消费者通过 ZooKeeper 监听分区的元数据变更,一旦发现 Leader 变更,会重新连接到新的 Leader。
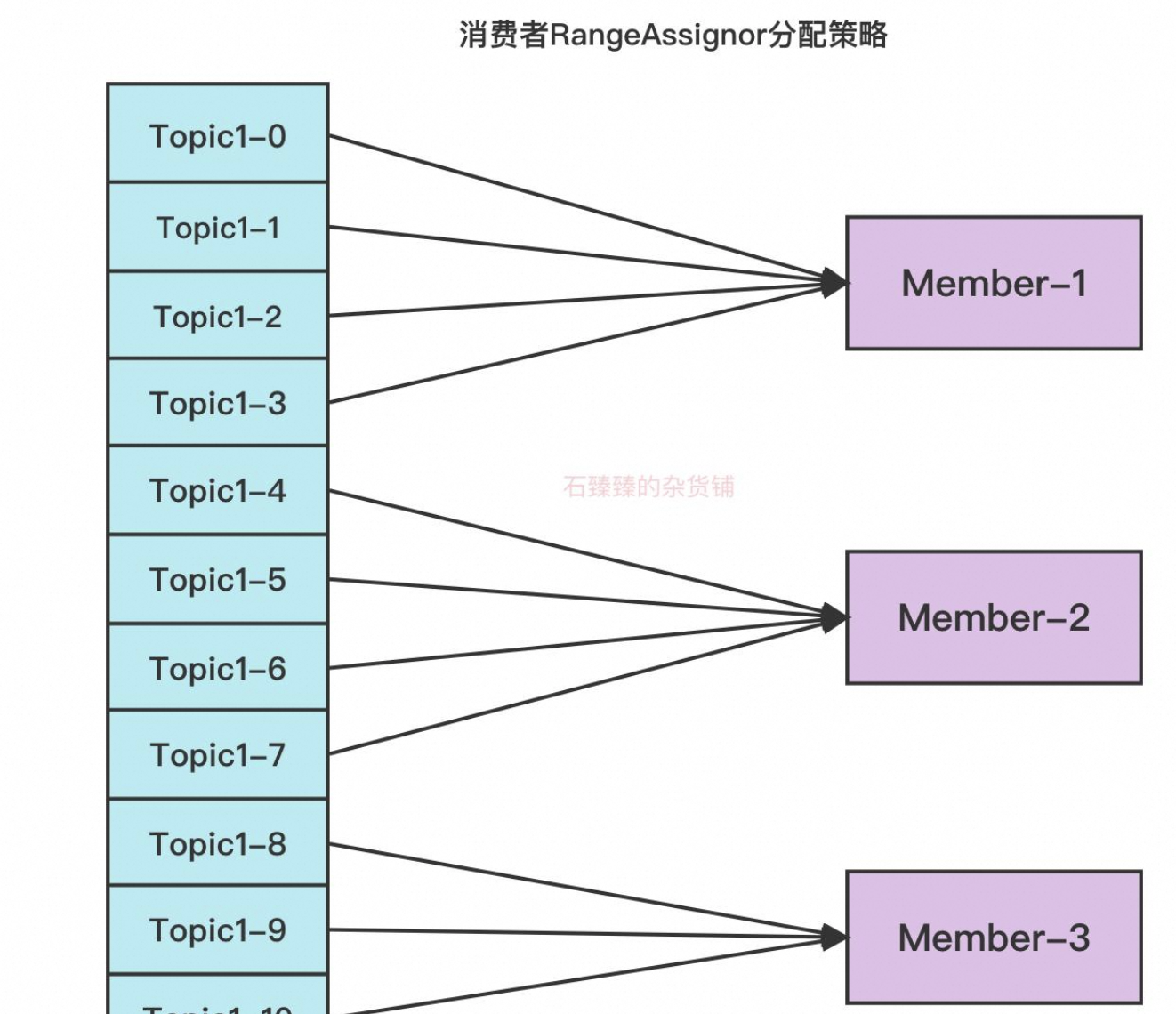
2.5、消费者组与分区分配
如下图所示:
1、消费者组(Consumer Group):
同一消费者组内的消费者共同消费一个 Topic 的所有分区。Kafka 会将分区分配给消费者组中的消费者,确保每个分区仅被一个消费者消费。
2、分区分配策略:
Range 分配:按分区顺序依次分配给消费者。
Round-Robin 分配:轮询方式分配分区。
Sticky 分配:尽量保持分区分配的稳定性,减少再平衡开销。
3、再平衡(Rebalance):
当消费者加入/退出组,或分区 Leader 变更时,Kafka 会触发再平衡,重新分配分区给消费者。再平衡期间,消费者会短暂停止消费,直到分配完成。
2.6、消费者读取数据的流程
如下图所示:
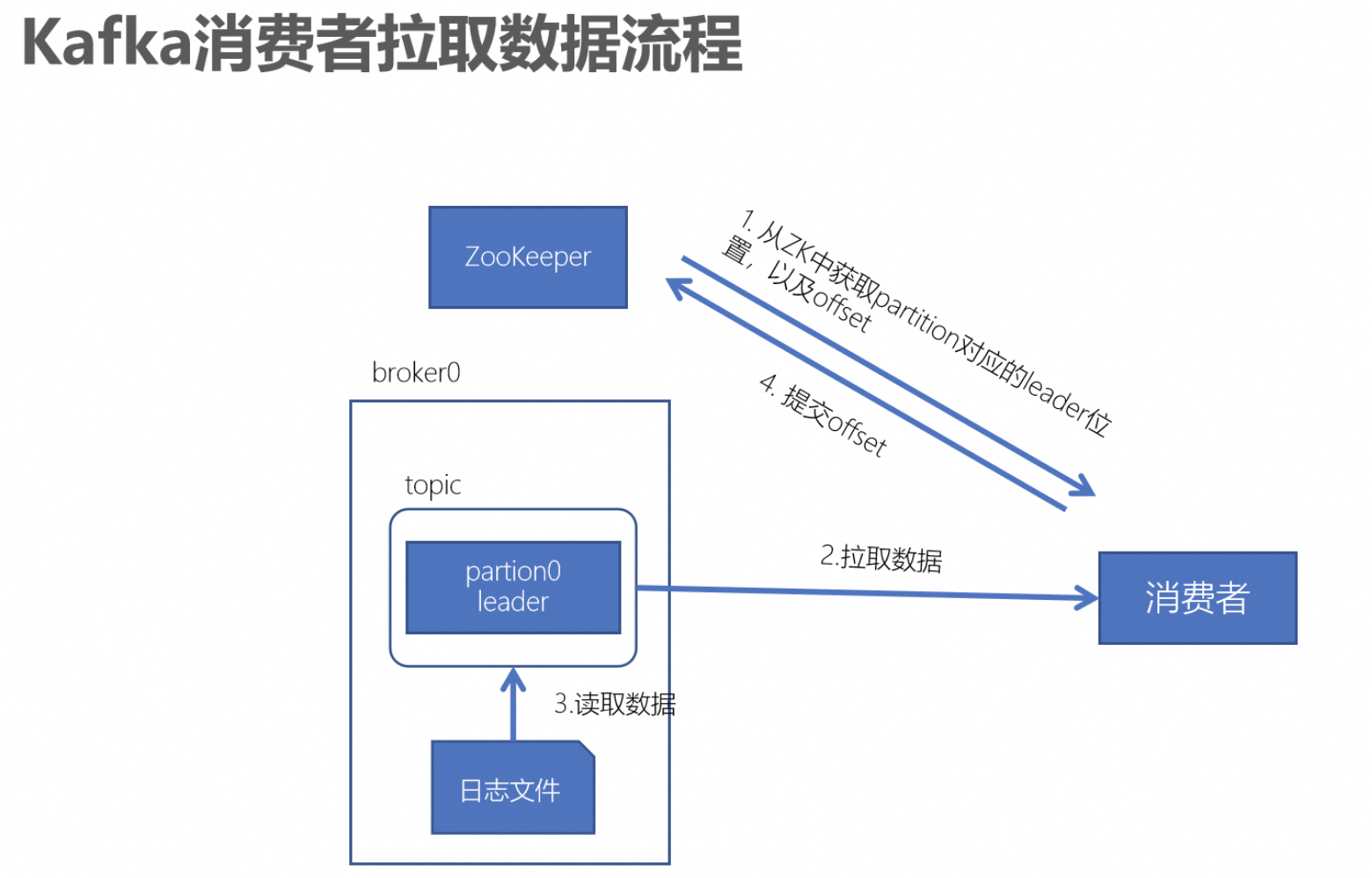
1、初始化阶段:
消费者向 ZooKeeper 查询目标分区的 Leader 信息。消费者连接到 Leader 所在的 Broker。
2、拉取数据(Fetch Request):
消费者向 Leader 发送 FetchRequest,请求指定 Offset 的消息。Leader 返回消息批次(Batch),消费者处理后更新消费 Offset。
3、Offset 管理:
自动提交:
消费者定期自动提交 Offset 到 Kafka 的 __consumer_offsets Topic。
手动提交:
消费者通过 API 显式提交 Offset,确保消息处理完成后才提交。
2.7、leader切换的流程
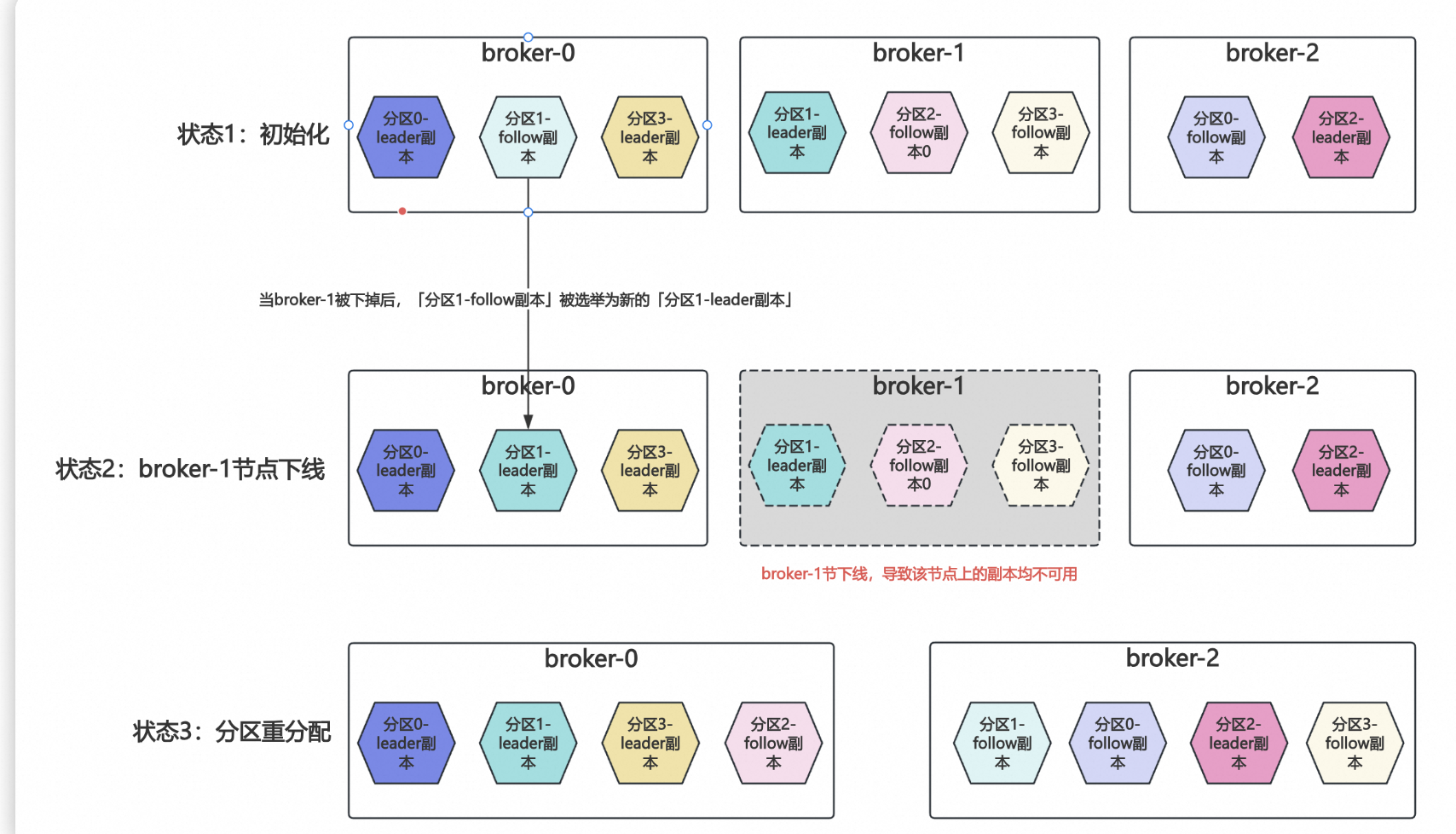
1. 消费者组启动时:
- 消费者 A 被分配到 Partition 0(Leader 在 Broker 1)。
- 消费者 B 被分配到 Partition 1(Leader 在 Broker 2)。
2. Broker 1 故障:
- Kafka 选举 Partition 0 的 Follower(假设在 Broker 3)为新 Leader。
- 消费者 A 通过 ZooKeeper 检测到变更,重新连接到 Broker 3。
- 消费者 A 继续从新的 Leader 读取数据,无需中断消费流程。
3、kafka架构设计
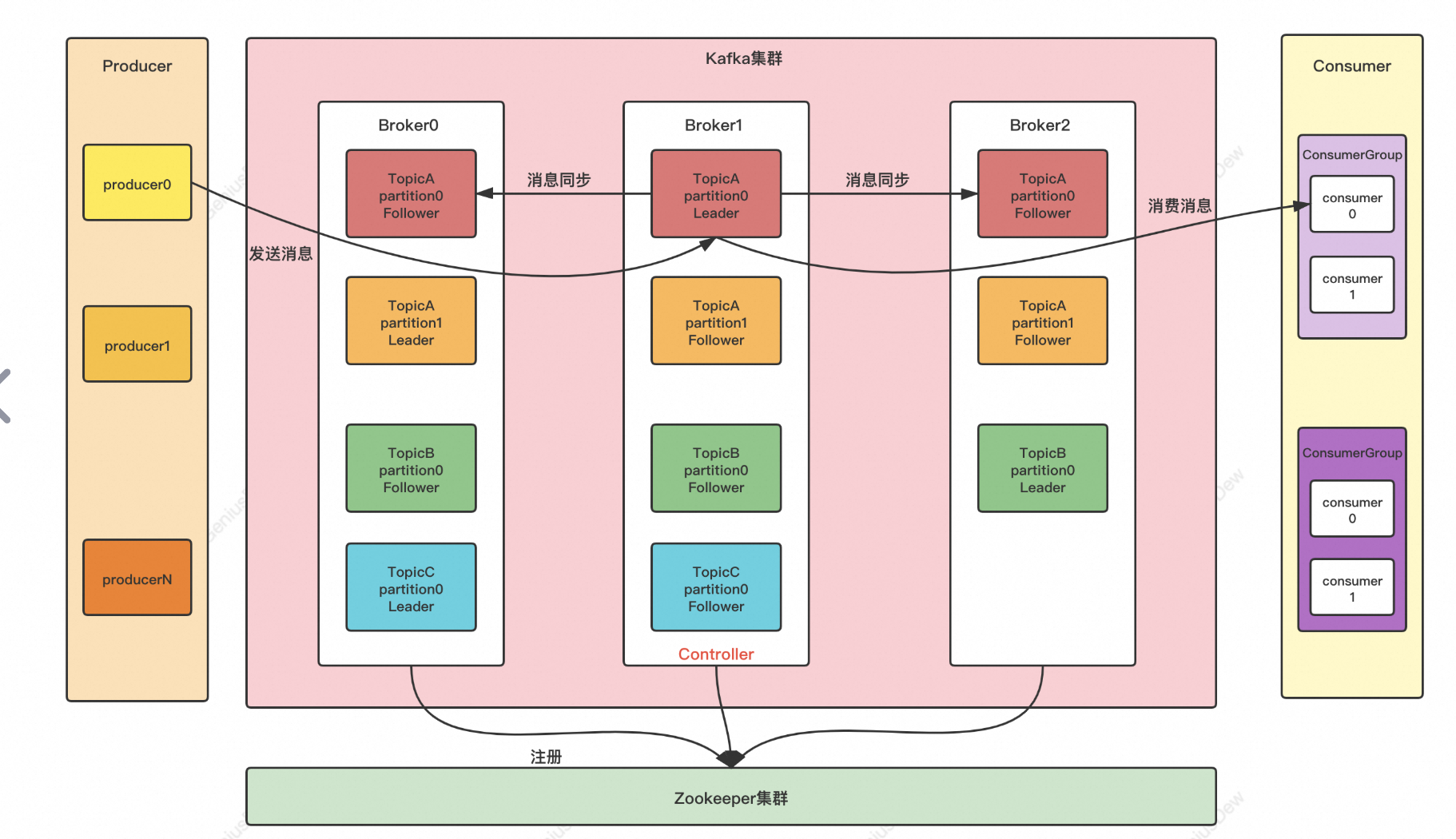
kafka的消息模型为发布-订阅方式。kafka的架构设计如下图所示:
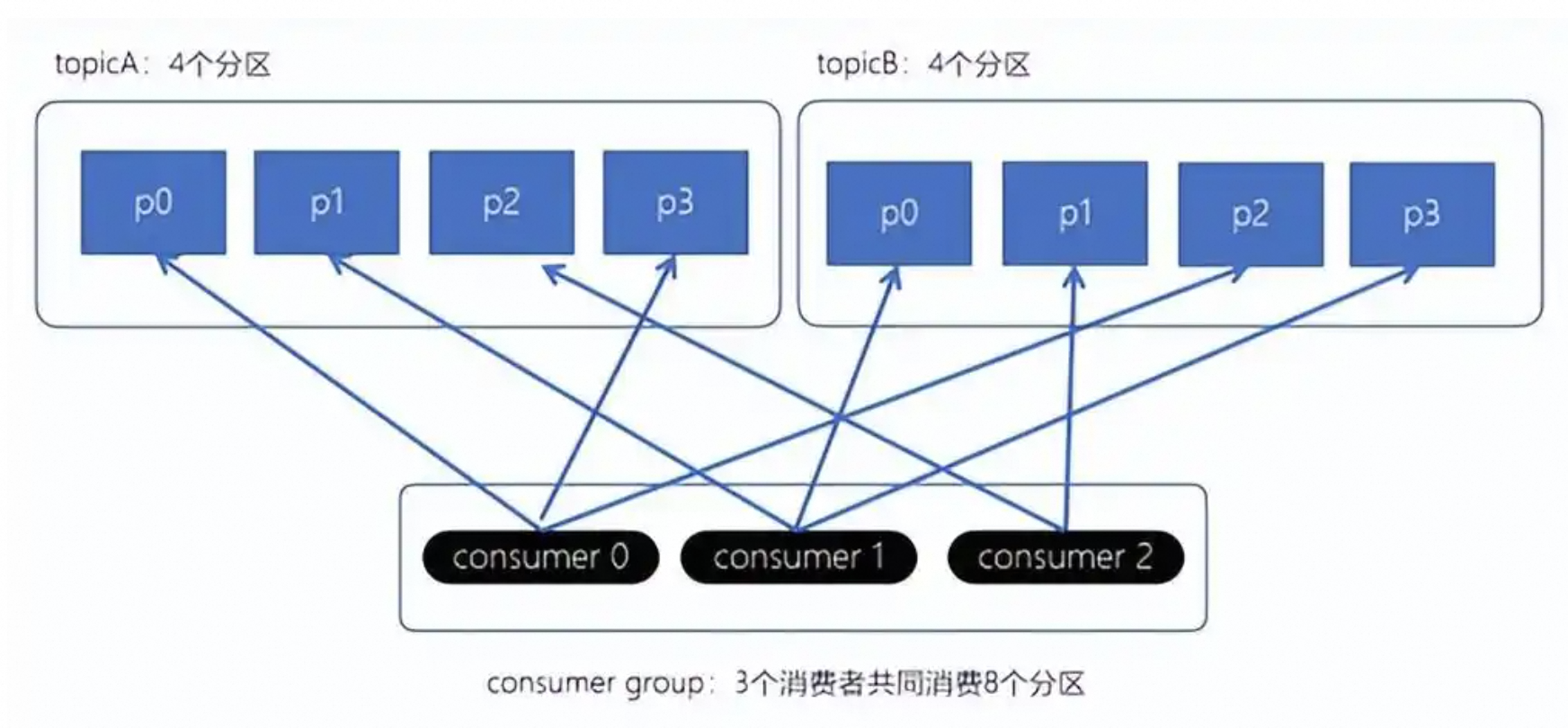
3.1、消费者组
如下图所示:
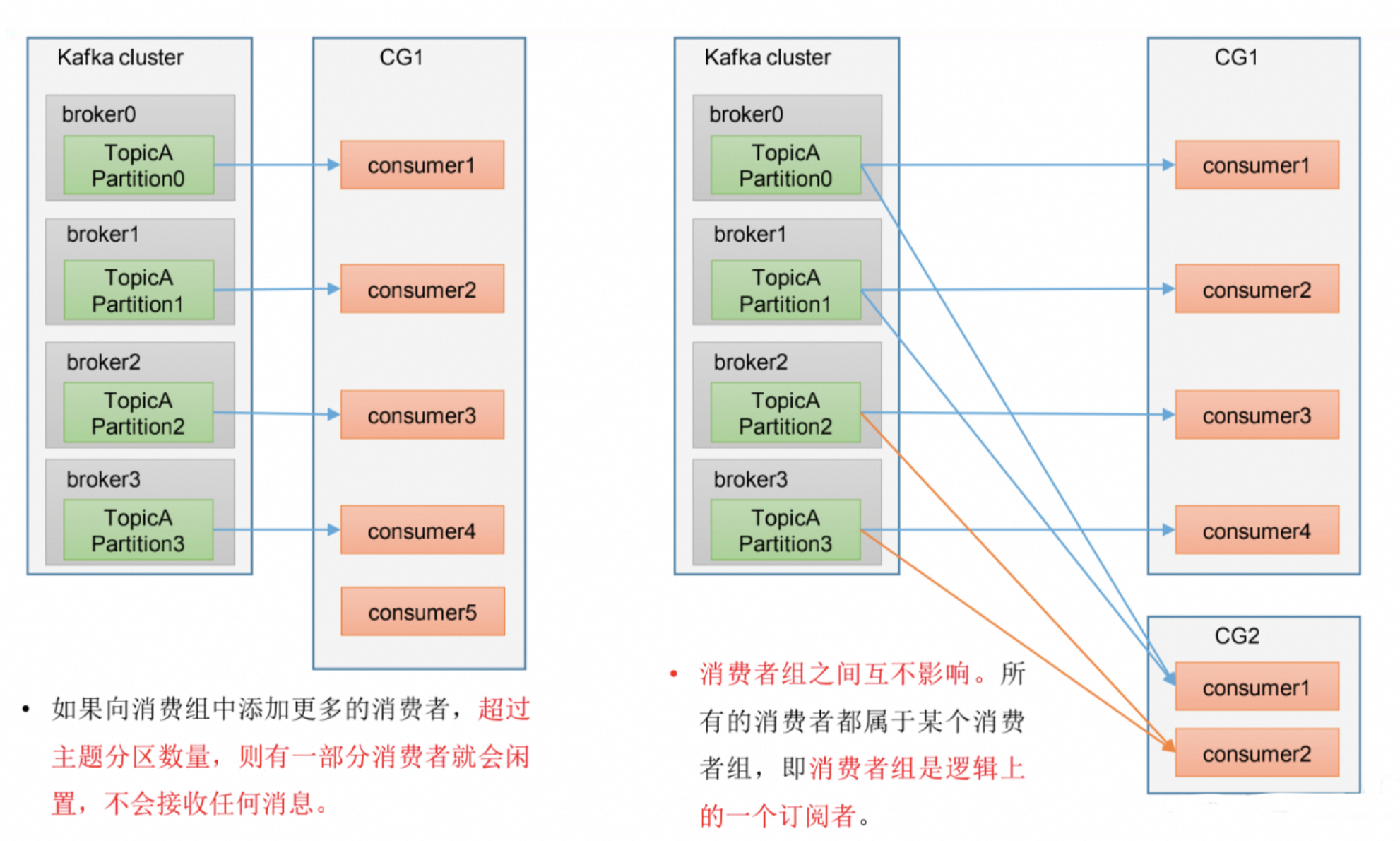
在 Kafka 中,不同消费者组的消费者可以同时消费同一个 Partition 的数据,而 同一消费者组内的消费者不能同时消费同一个 Partition。
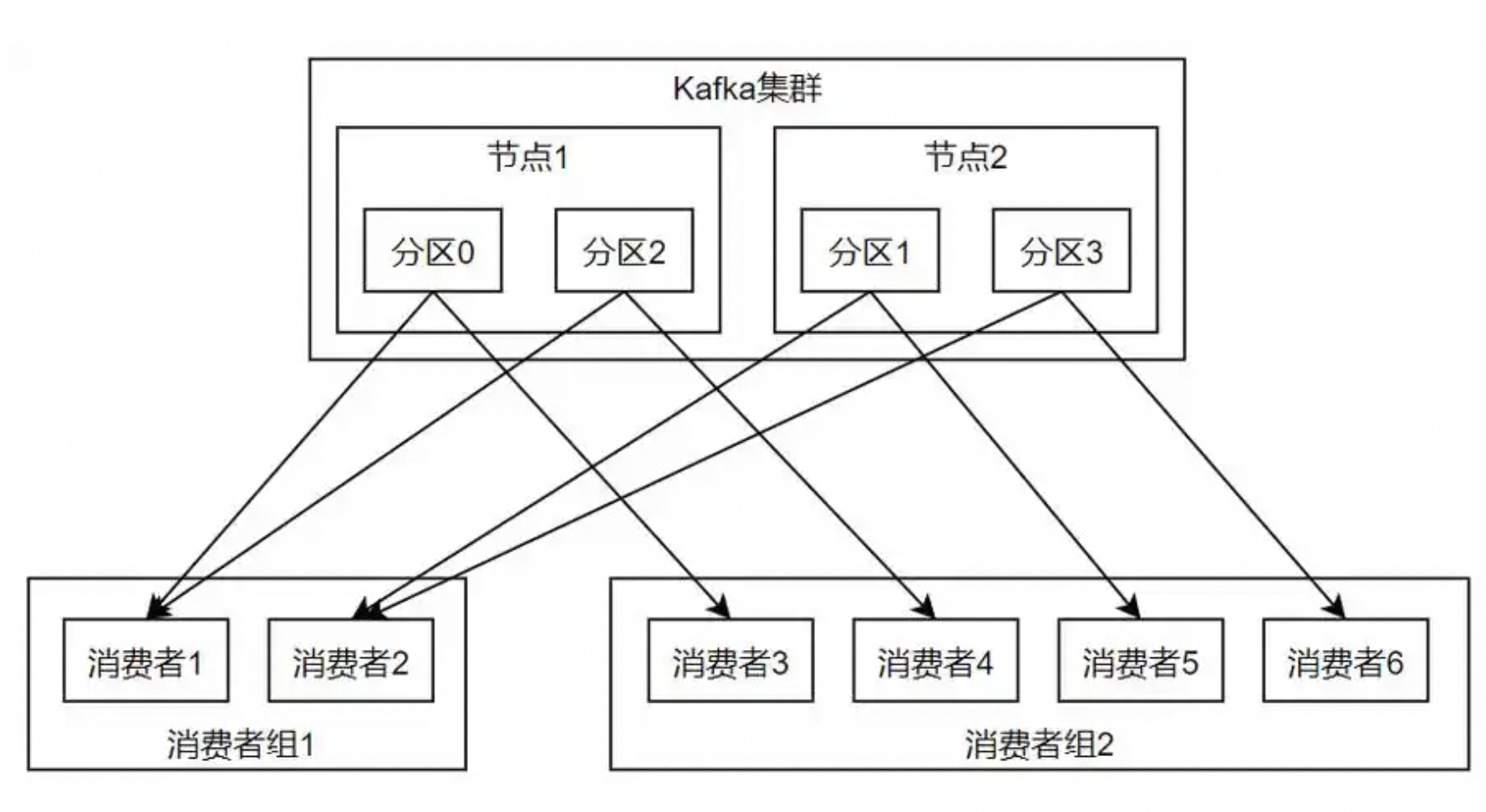
3.2、消费者和broker联系
1、消费者
同一组内的不同消费者可以消费不同的broker。
如下图所示:
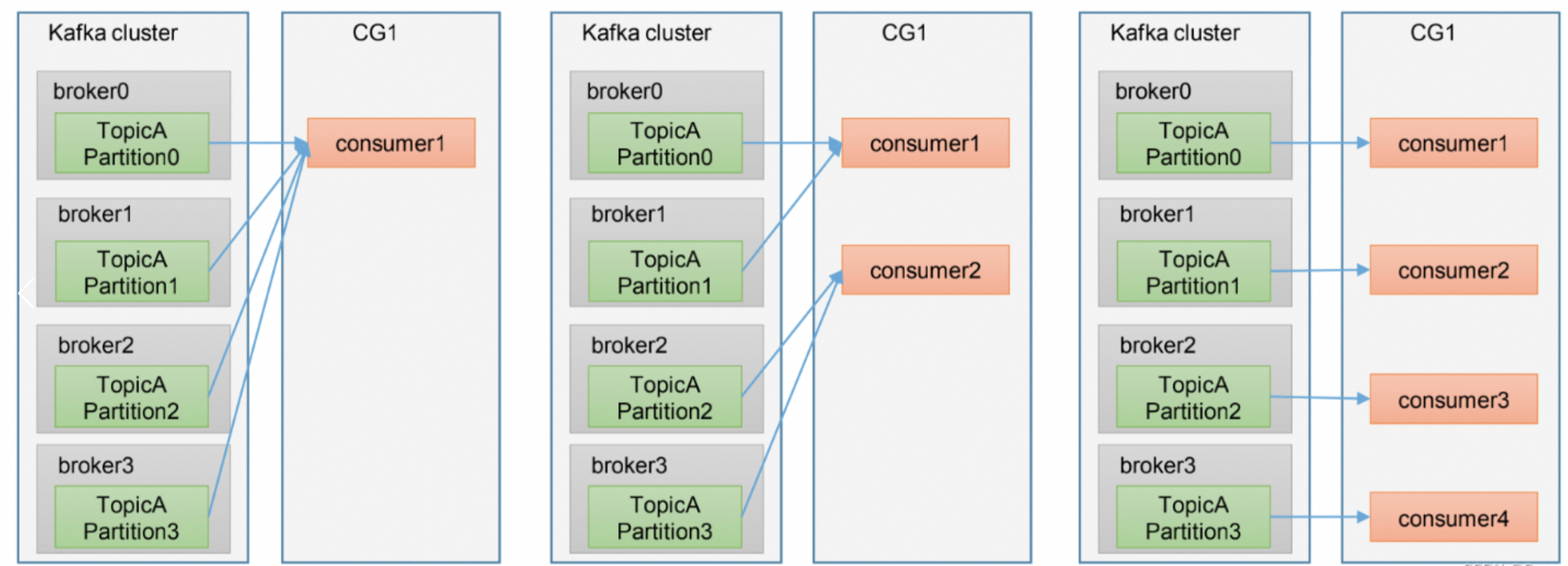
这是 Kafka 保证消息消费的灵活性和可靠性的核心机制之一。
同一组内的消费者:
共享一个组 ID(group.id),共同消费一个 Topic 的所有 Partition,每个 Partition 只能被组内 一个消费者 消费。
不同组的消费者:
彼此独立,可以同时消费同一个 Topic 的所有 Partition,包括同一 Partition。
3.3、消费模型对比

示例:
- 不同消费者组的消费者可以同时消费同一个 Partition。
- 每个消费者组会独立维护自己的消费偏移量(Offset),互不干扰。
- 示例:
- 假设 Topic
my-topic有 3 个 Partition(P0, P1, P2)。 - 消费者组 A:包含两个消费者 C1 和 C2,分别消费 P0 和 P1。
- 消费者组 B:包含两个消费者 C3 和 C4,分别消费 P0 和 P2。
- 此时,C1(组 A)和 C3(组 B)可以同时消费 P0,互不影响。
- 假设 Topic
3.4、消费同一partion原因
为什么不同消费者组可以消费同一 Partition?
如下图所示:
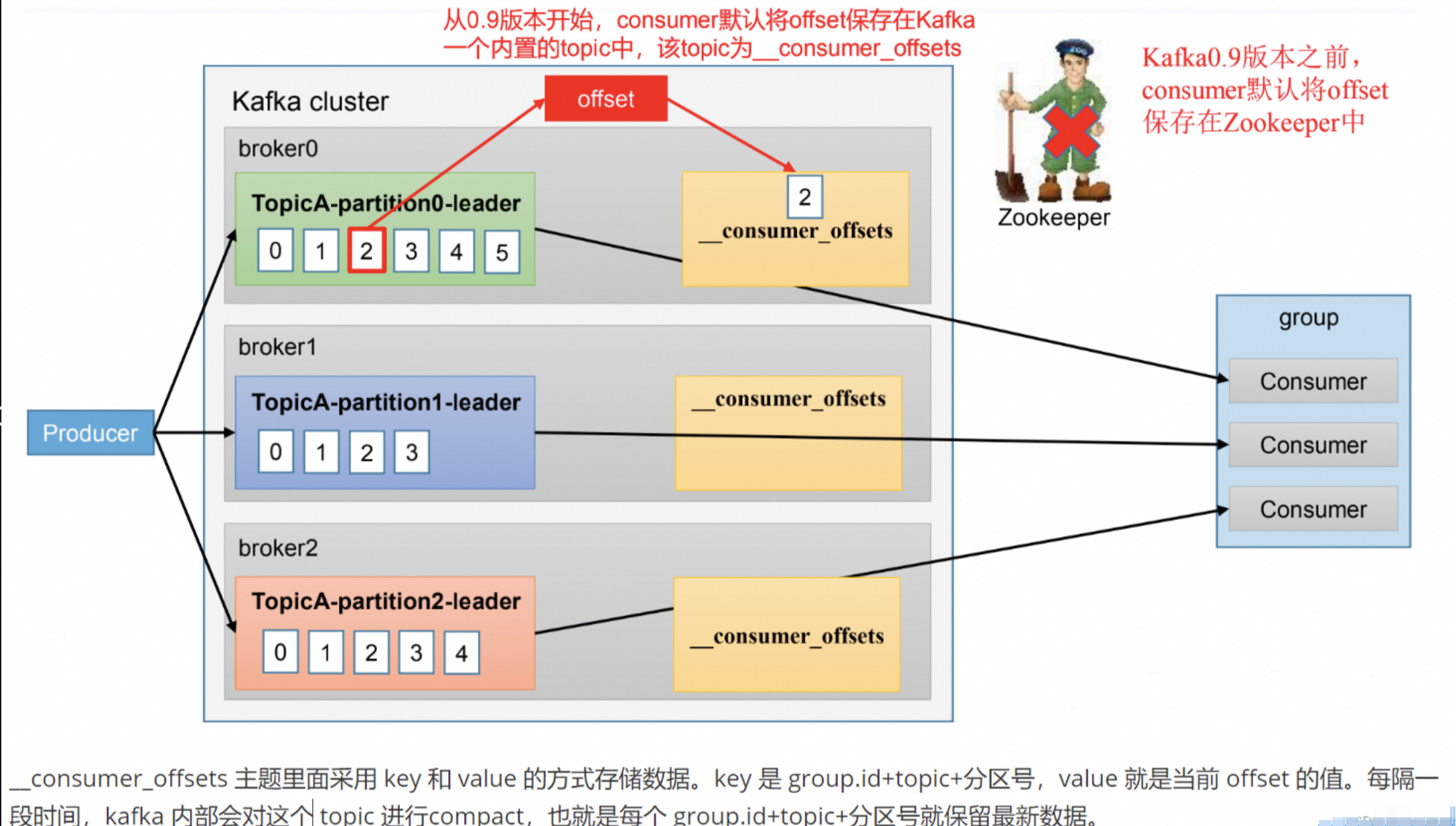
1. Offset 的独立性
每个消费者组会将消费进度(Offset)保存在 Kafka 的内部 Topic
__consumer_offsets 中。
不同组的 Offset 是独立存储的,因此它们可以独立地从 Partition 的任意位置(如起始位置或某个特定 Offset)开始消费。
2. 多订阅场景的需求
Kafka 的设计目标是支持 多订阅者(Multi-subscriber) 模型,即多个消费者组可以同时消费同一个 Topic 的数据。
例如:
一个消费者组用于实时数据分析。
另一个消费者组用于历史数据归档。
第三个消费者组用于监控告警。
3. Partition 的 Leader 机制
所有消费者(无论属于哪个组)都必须从 Partition 的 Leader 副本 读取数据。
Kafka 通过 ZooKeeper 维护 Partition 的 Leader 信息,不同组的消费者会同时向 Leader 发送请求,但 Kafka 允许多个客户端并发读取。
4、常见问题
1: 如果两个消费者组都消费同一个 Partition,会不会导致消息丢失?
不会。只要 Kafka 的副本机制正常运行,消息会被持久化到磁盘,并且每个消费者组会独立维护自己的 Offset。即使一个组消费失败,另一个组仍能正常消费。
2: 如何控制不同组的消费进度?
如下图所示:
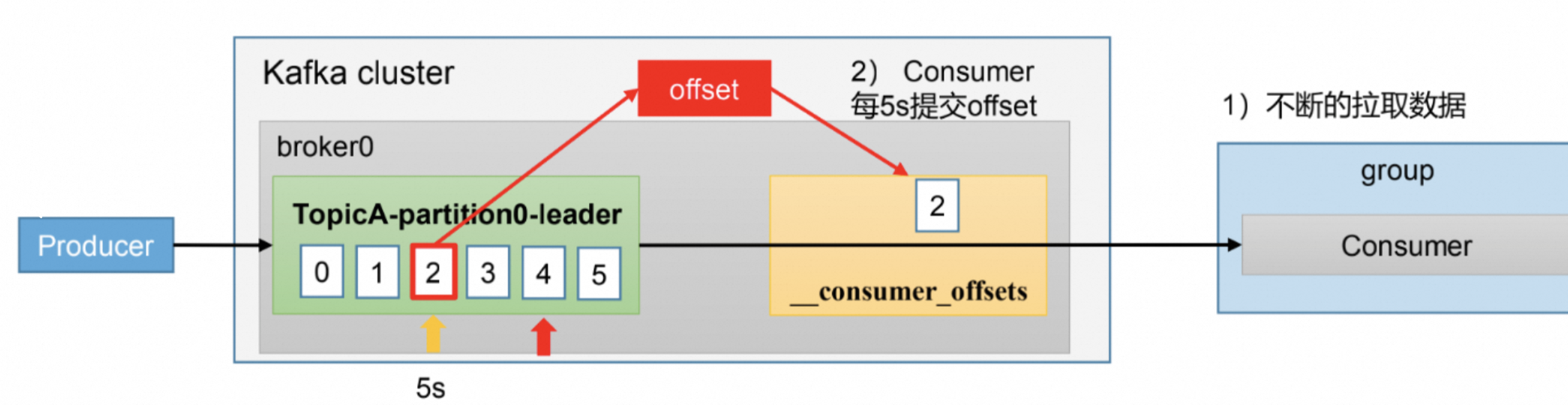
手动提交 Offset:
通过 consumer.commitSync() 或 consumer.commitAsync() 显式控制每个组的消费进度。
自动提交 Offset:
通过 enable.auto.commit=true 配置,Kafka 会定期自动提交 Offset。
3: 如果 Partition 的 Leader 故障,不同组的消费者会如何反应?
Kafka 会选举新的 Leader,所有消费者(无论属于哪个组)会重新连接到新的 Leader,并继续消费。
总结
Kafka 是一个强大的分布式流处理平台,凭借其 高吞吐量、持久化、水平扩展 和 实时处理能力,成为大数据和实时系统的核心组件。
尽管其配置和调优较为复杂,但在日志聚合、消息队列、流式处理等场景中表现优异。
参考文章:
1、kafka全解-CSDN博客