《PyTorch深度学习入门》
参考小土堆up主
1. dir和help
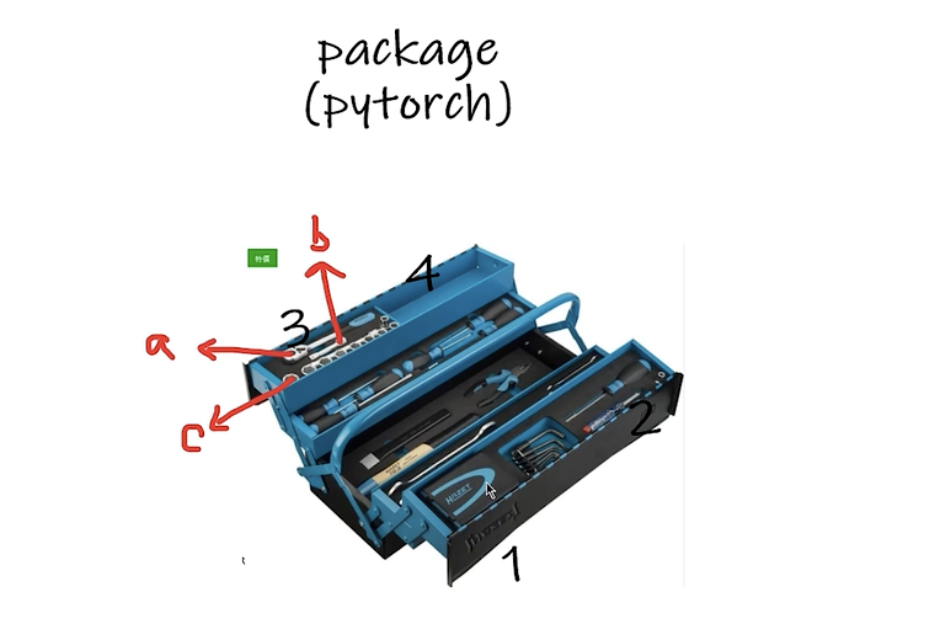
| 函数 | 作用 | 输出形式 | 典型使用场景 |
|---|---|---|---|
dir() | 列出所有属性和方法 | 字符串列表 | 快速探索对象结构 |
help() | 显示详细文档说明 | 格式化文本 | 理解参数用法和功能细节 |
加载数据:
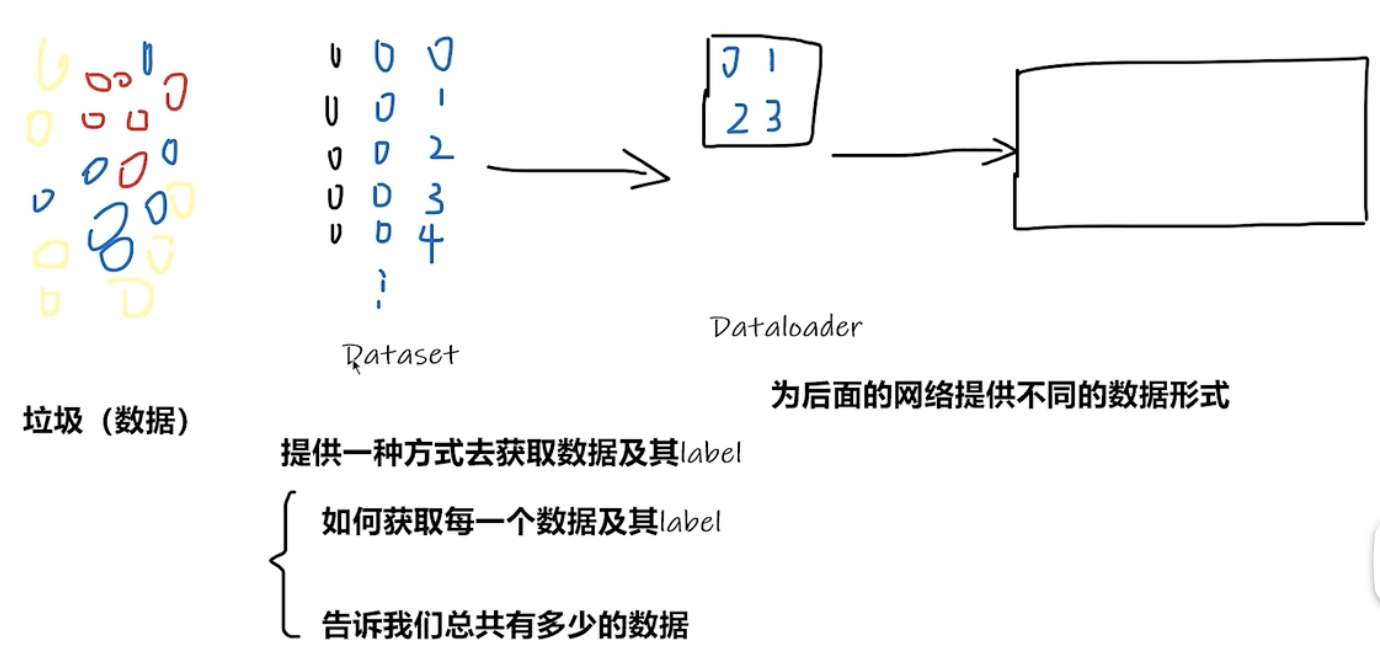
from torch.utils.data import Dataset
from PIL import Image
import osclass MyData(Dataset):def __init__(self, root_dir, label_dir):super().__init__()self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir, self.label_dir)self.img_path = os.listdir(self.path)def __getitem__(self, index):img_name = self.img_path[index]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)root_dir = "/Users/hailie/Desktop/小兰/hailie/study/AI/DL/PyTorch/TorchStudy1/data/hymenoptera_data/train/"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)2. TensorBoard
TensorBoard 是 一个强大的、基于 Web 的可视化工具包。它的核心目的是帮助开发者理解、调试和优化机器学习模型的训练过程以及模型本身的结构。
简单来说,TensorBoard 就像一个“仪表盘”或“监控中心”,让你能直观地看到模型训练时内部发生的各种事情,而不仅仅是盯着命令行输出的数字。
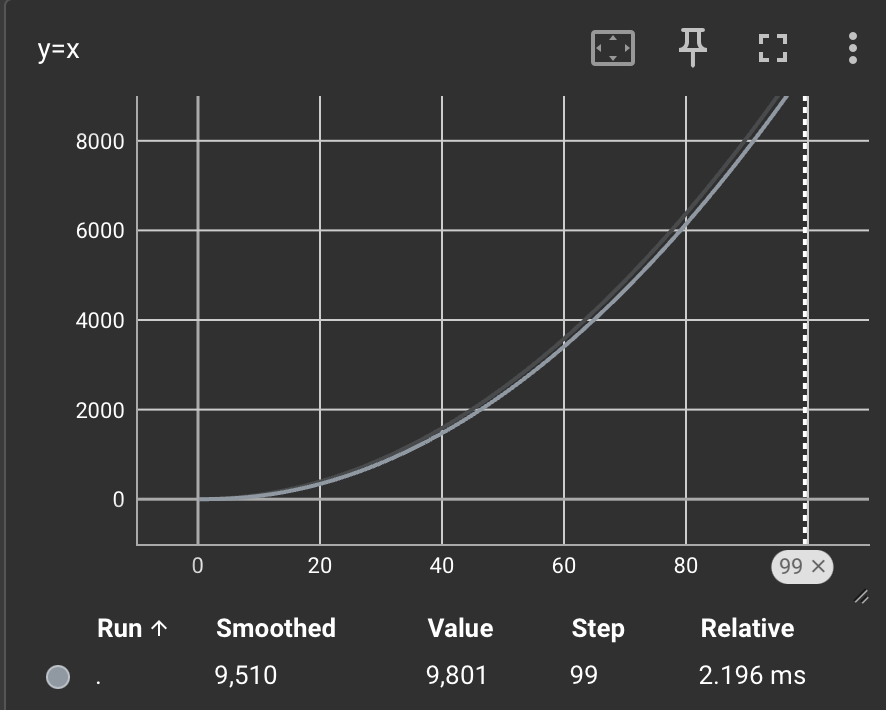
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# writer.add_image()
#y=x
for i in range(100): writer.add_scalar("y=x",i**2, i) writer.close()
TensorBoard 的主要功能和它能可视化的内容
-
标量可视化:
-
看什么: 训练损失、验证损失、准确率、精确率、召回率、学习率、自定义指标等随时间(迭代步数或epoch)的变化趋势。
-
有什么用: 判断模型是否在学习(损失是否下降)、是否过拟合/欠拟合(训练损失和验证损失的关系)、学习率设置是否合适、模型性能何时趋于稳定或开始下降。是最常用、最核心的功能。
-
-
计算图可视化:
-
看什么: 模型的计算图结构。TensorFlow 模型是由一系列操作(Ops)组成的计算图。
-
有什么用: 理解模型的架构、数据流向、检查操作之间的依赖关系、诊断图构建错误。对于理解复杂模型的结构非常有帮助。
-
-
直方图和分布:
-
看什么: 模型权重(Weights)、偏置(Biases)、激活值(Activations)、梯度(Gradients)等张量在训练过程中的分布变化。用直方图或分位数图表示。
-
有什么用: 监控权重初始化是否合适、激活函数是否饱和(如出现大量0或1)、梯度是否消失或爆炸(梯度值过大或过小)、参数分布是否发生不期望的偏移(如权重变得非常大)。是调试模型内部行为的关键工具。
-
-
图像可视化:
-
看什么: 训练/验证数据集中的样本图像、模型生成的图像(如 GAN)、特征图(卷积层的输出)、图像上的注意力图等。
-
有什么用: 检查输入数据是否正常、理解卷积网络不同层学习到了什么特征、可视化模型的预测结果或生成效果、调试图像相关的任务。
-
-
音频可视化:
-
看什么: 训练/验证数据集中的音频样本、模型生成的音频波形等。
-
有什么用: 检查音频数据、调试音频生成或语音识别模型。
-
-
文本可视化:
-
看什么: 训练/验证数据集中的文本样本、嵌入向量(通过投影)、模型生成的文本等。
-
有什么用: 检查文本数据、可视化词嵌入在低维空间的关系(如使用 PCA, t-SNE)、调试 NLP 模型。
-
-
PR 曲线和 ROC 曲线:
-
看什么: 在不同分类阈值下的精确率-召回率关系曲线或真正类率-假正类率关系曲线。
-
有什么用: 评估分类模型在不同阈值下的性能,选择最佳阈值,比较不同模型的分类能力,尤其是在数据不平衡时比单一准确率更有意义。
-
-
嵌入投影器:
-
看什么: 将高维嵌入向量投影到 2D 或 3D 空间(使用 PCA, t-SNE, UMAP 等方法)。
-
有什么用: 直观理解词嵌入、句子嵌入或其他潜在空间表示中点与点之间的关系、聚类情况,例如查看语义相似的词是否聚在一起。
-
-
Profiler:
-
看什么: 模型在硬件(CPU, GPU, TPU)上运行的性能剖析信息,包括各操作的执行时间、内存消耗、设备利用率等。
-
有什么用: 识别训练瓶颈(是数据加载慢?计算慢?通信慢?)、优化代码性能、提高硬件资源利用率。
-
-
HParams:
-
看什么: 系统地比较不同超参数组合(如学习率、批大小、层数、优化器等)对模型性能指标(如验证准确率、损失)的影响。
-
有什么用: 高效地进行超参数调优,直观地找出效果最好的超参数设置。
-
如何使用 TensorBoard
-
代码中插入日志记录:
-
在你的 TensorFlow (或 PyTorch + torch.utils.tensorboard / PyTorch Lightning 等) 训练代码中,使用特定的 API (
tf.summary,SummaryWriter等) 将你想要可视化的数据(标量、图像、直方图、计算图等)写入日志目录。
-
-
启动 TensorBoard 服务器:
-
在命令行运行:
tensorboard --logdir=path_to_your_log_dir -
这会启动一个本地 Web 服务器。
-
-
在浏览器中查看:
-
打开浏览器,访问 TensorBoard 提供的地址(通常是
http://localhost:6006)。 -
在 Web 界面上选择不同的标签页查看对应的可视化内容。
-
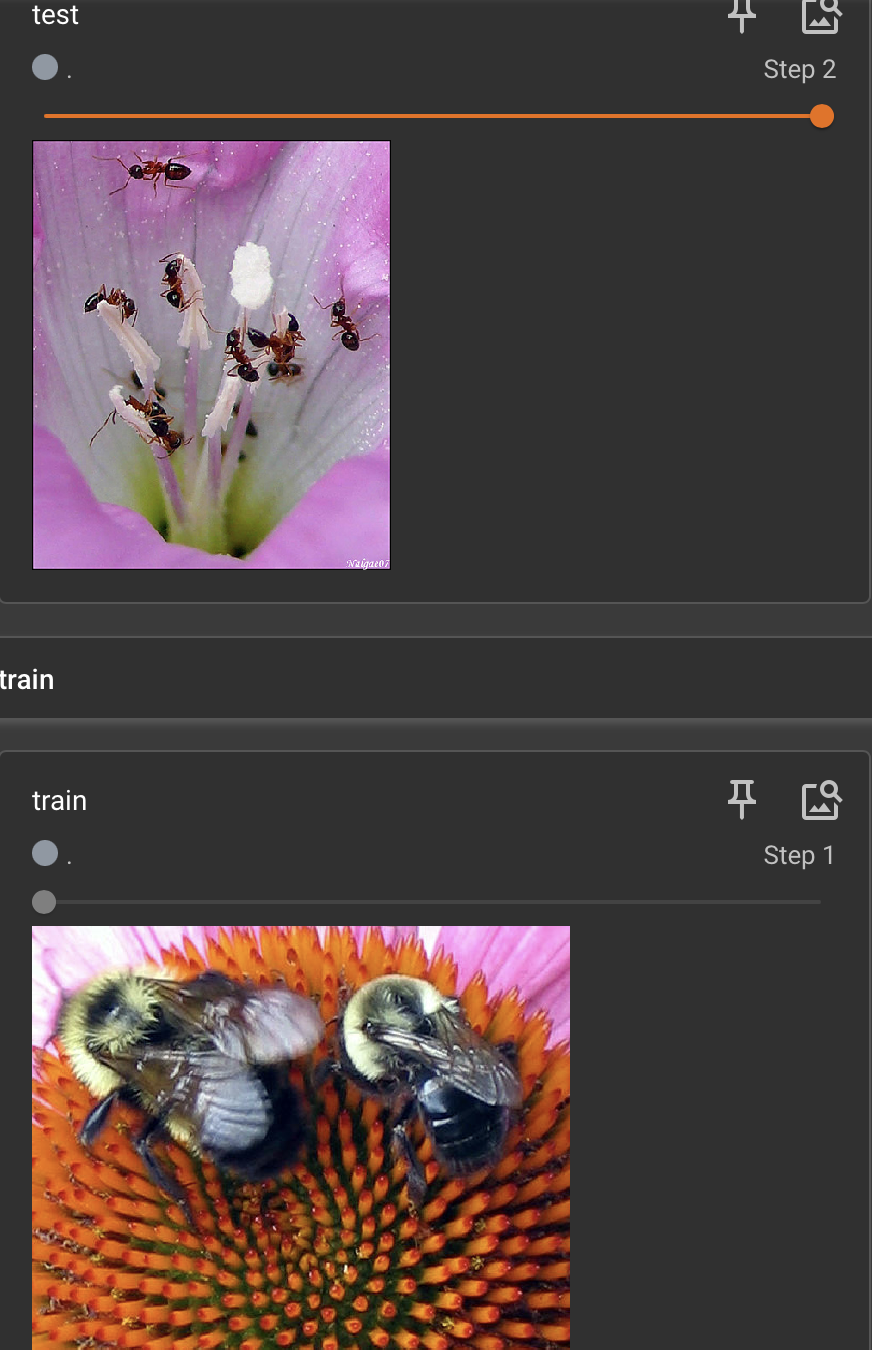
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as npwriter = SummaryWriter("logs")
image_path = "/Users/hailie/Desktop/小兰/hailie/study/AI/DL/PyTorch/TorchStudy1/data/dataset/train/ants_image/0013035.jpg"
image_PIL = Image.open(image_path)
img_array = np.array(image_PIL)
writer.add_image("test", img_array, 1,dataformats='HWC')image_path = "/Users/hailie/Desktop/小兰/hailie/study/AI/DL/PyTorch/TorchStudy1/data/dataset/train/ants_image/531979952_bde12b3bc0.jpg"
image_PIL = Image.open(image_path)
img_array = np.array(image_PIL)
writer.add_image("test", img_array, 2,dataformats='HWC')image_path = "/Users/hailie/Desktop/小兰/hailie/study/AI/DL/PyTorch/TorchStudy1/data/dataset/train/bees_image/29494643_e3410f0d37.jpg"
image_PIL = Image.open(image_path)
img_array = np.array(image_PIL)
writer.add_image("train", img_array, 1,dataformats='HWC')
3.transforms

3.1 ToTensor
为什么我们需要Tensor数据类型:
因为包含了神经网络所需要的参数类型,特别是梯度和反向传播相关的
from PIL import Imagefrom torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("/Users/hailie/Desktop/小兰/hailie/study/AI/DL/PyTorch/TorchStudy1/logs")img_path = "/Users/hailie/Desktop/小兰/hailie/study/AI/DL/PyTorch/TorchStudy1/data/dataset/train/bees_image/29494643_e3410f0d37.jpg"
img = Image.open(img_path)# toTensor
tensor_transform = transforms.ToTensor()
tensor_img = tensor_transform(img)print(tensor_img)
writer.add_image("tensor_img", tensor_img)
#Normalize
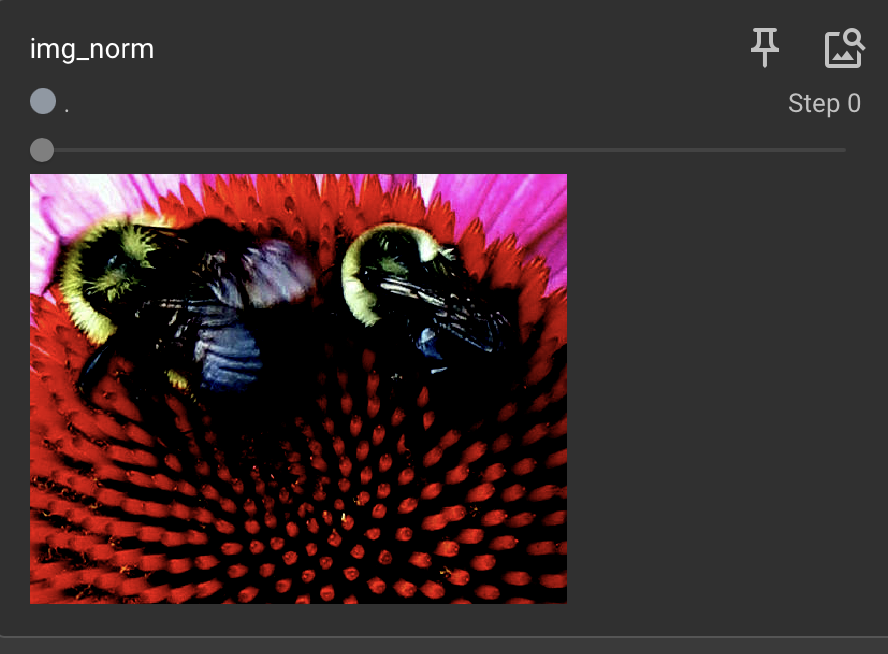
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(tensor_img)
writer.add_image("img_norm", img_norm)
writer.close()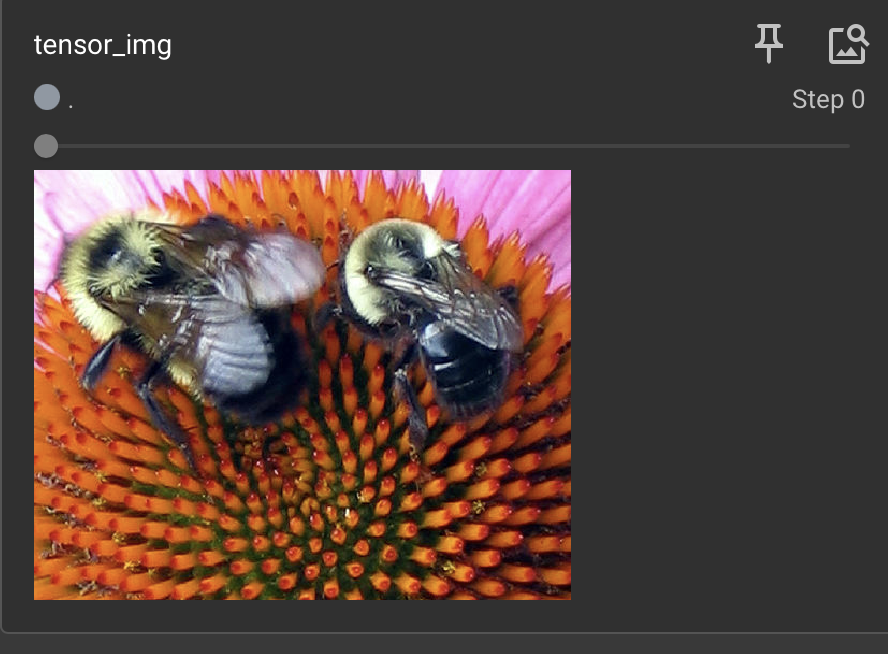
3.2 Normalize
transforms.Normalize 是 PyTorch 中 torchvision.transforms 模块提供的一个关键图像预处理操作。它的核心作用是对图像张量(Tensor)进行标准化(归一化)。
作用详解
-
标准化数据分布:
-
它执行的操作非常简单:对于图像张量中的每个通道,它都进行以下计算:
normalized_channel = (original_channel - mean[channel]) / std[channel] -
mean[channel]: 为该通道指定的均值。 -
std[channel]: 为该通道指定的标准差。 -
这个操作实质上是将每个通道的数据分布(像素值范围)从
[0, 1](或原始范围)平移并缩放到一个以0为中心、标准差为1的新分布(近似标准正态分布)。
-
-
为什么需要这样做?
-
加速模型收敛: 神经网络(尤其是深度网络)在训练时,如果输入数据的各个特征(在这里是各个通道的像素值)具有相似的尺度和分布,优化器(如 SGD、Adam)通常能更快、更稳定地找到最优解。标准化确保了不同通道、不同图像之间的数值范围一致,消除了因原始像素值绝对大小差异带来的影响。
-
提高模型稳定性: 当输入特征的尺度差异很大时,模型训练过程可能变得不稳定(如梯度爆炸或梯度消失)。标准化有助于保持梯度在一个更合理的范围内。
-
使模型更容易学习: 许多常用的激活函数(如 Tanh, Sigmoid)在输入值接近 0 时具有更大的梯度,学习效率更高。标准化将数据集中在 0 附近,使得这些激活函数能更有效地工作。
-
匹配预训练模型: 如果你在使用在大型数据集(如 ImageNet)上预训练的模型,这些模型在训练时使用了特定的均值和标准差进行标准化。为了正确利用这些预训练模型的特征提取能力或进行微调,你必须在你的数据上使用与预训练模型完全相同的均值和标准差进行标准化。否则,输入数据的分布与模型训练时看到的分布不一致,会导致性能显著下降。
-
3.3 Compose
-
transforms.Compose是 PyTorch 的torchvision.transforms模块中一个极其重要的工具,用于将多个图像预处理/变换操作组合成一个单一的、可调用的转换管道。它的主要作用是创建一系列有序的图像变换步骤,使数据预处理流程更加清晰、简洁和可维护。
# 创建包含多个步骤的变换管道
transform = transforms.Compose([transforms.Resize(256), # 调整图像大小transforms.RandomCrop(224), # 随机裁剪transforms.RandomHorizontalFlip(),# 随机水平翻转transforms.ToTensor(), # 转换为PyTorch张量transforms.Normalize( # 标准化mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])3.4 RandomCrop
# RandomCrop
trans_random = transforms.RandomCrop(256)
trans_compose_2 = transforms.Compose([trans_random,tensor_transform])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("img_crop", img_crop,i)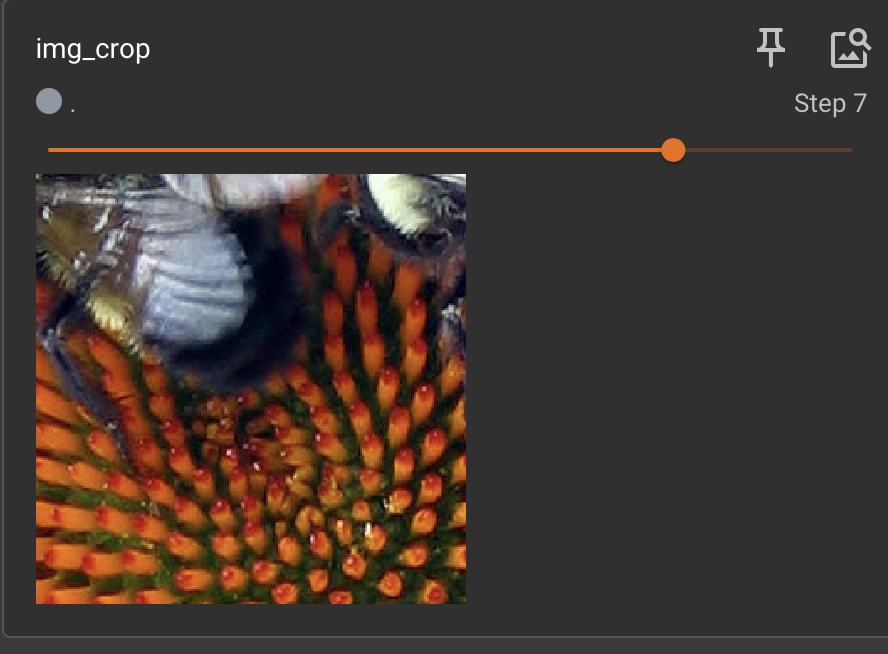
4. torchvision
import torchvision
from torchvision import transforms, datasetsfrom torch.utils.tensorboard import SummaryWriterdataset_transform = transforms.Compose([transforms.ToTensor()])train_set = datasets.CIFAR10(root='./data', train=True, download=True, transform=dataset_transform)
test_set = datasets.CIFAR10(root='./data', train=False, download=True, transform=dataset_transform)writer = SummaryWriter("p10")
for i in range(10):img, label = train_set[i]writer.add_image("torchvision_Image", img, i)5. dataLoader
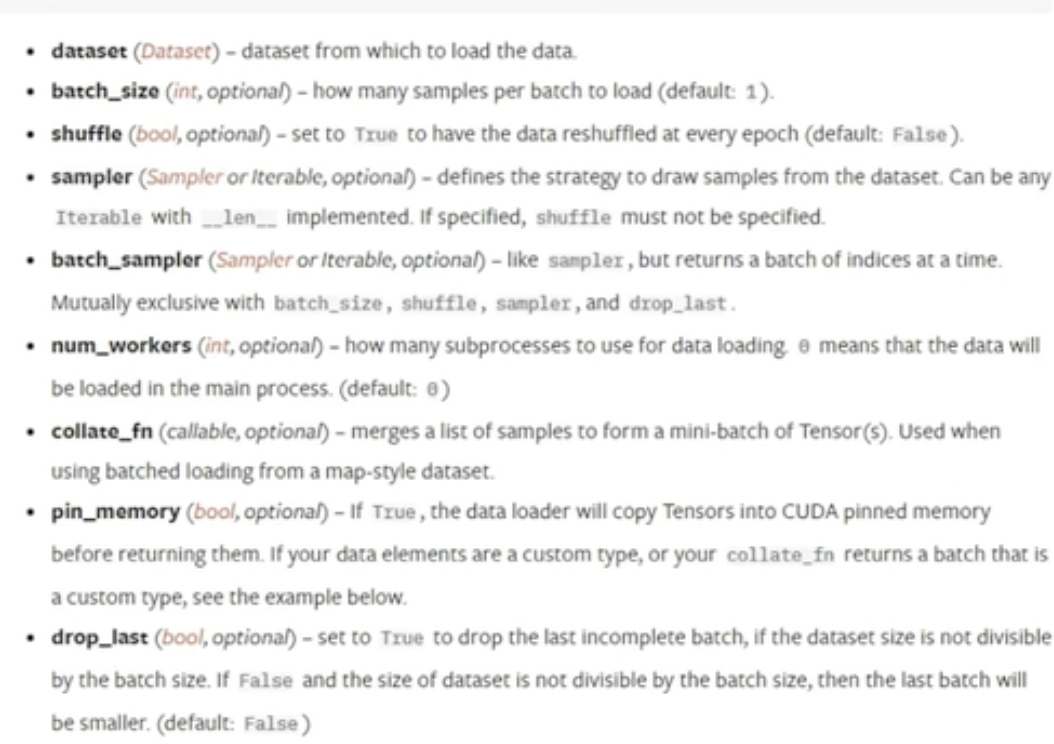
batch_size:2--每次抓牌抓两张
shuffle: 数据是否在每次epoch变换位置,类似洗牌之后第二局牌的顺序,true--打乱顺序
sampler:
num_workers:加载数据时候是否用多线程
drop_last: 如果100张牌,每次取3张,最后一张是否drop掉
epoch 抓几次牌
6. 神经网络
1) Model:
Base class for all neural network modules.
Your models should also subclass this class.
Modules can also contain other Modules, allowing them to be nested in a tree structure. You can assign the submodules as regular attributes:
import torch.nn as nn
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self) -> None:super().__init__()self.conv1 = nn.Conv2d(1, 20, 5)self.conv2 = nn.Conv2d(20, 20, 5)def forward(self, x):x = F.relu(self.conv1(x))return F.relu(self.conv2(x))2).conv2D
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Hailie(nn.Module):def __init__(self):super(Hailie, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return x
hailie = Hailie()
print(hailie)writer = SummaryWriter("logs")
step = 0
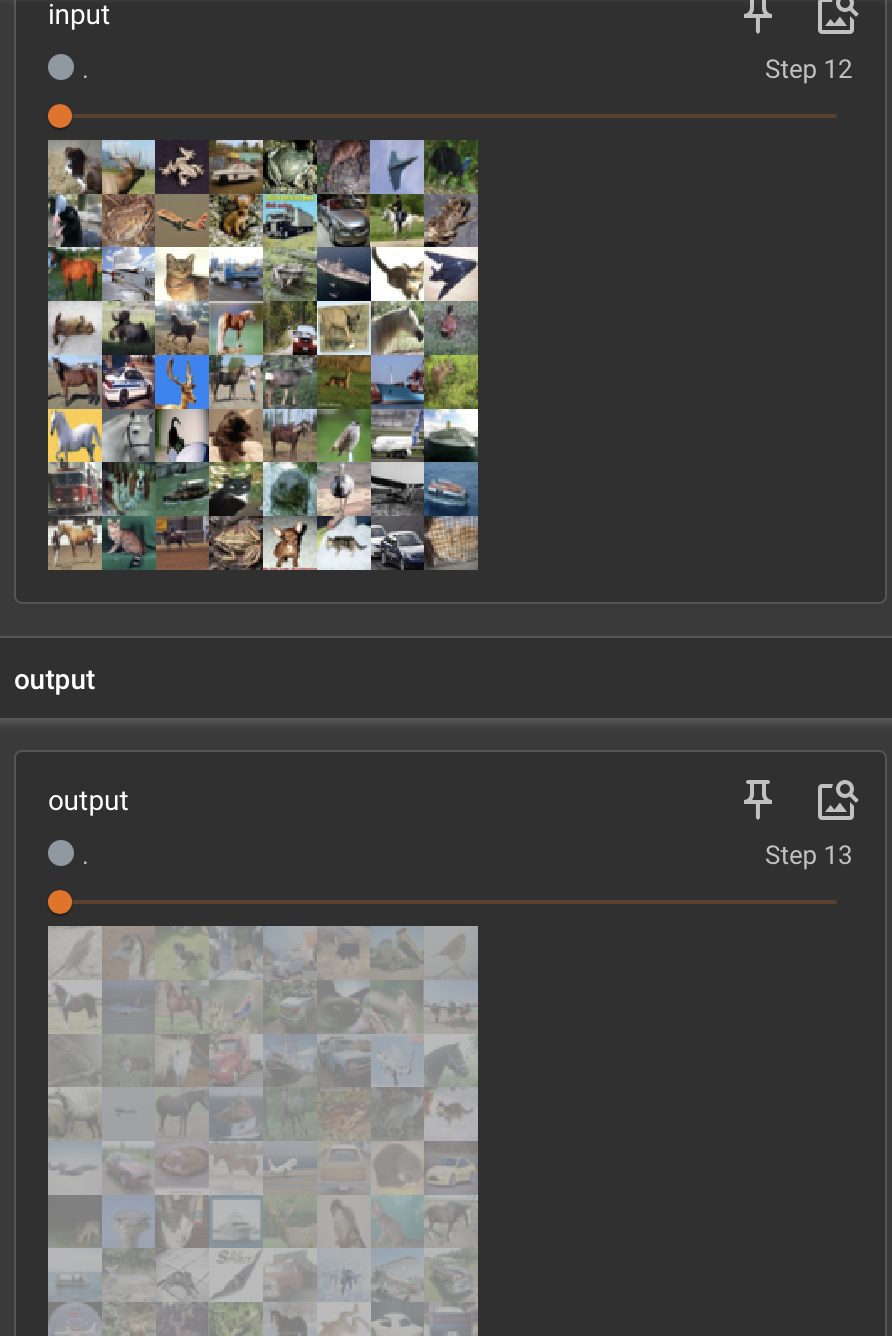
for data in dataloader:img, label = dataoutput = hailie(img)#input : torch.Size([64, 3, 32, 32])#output: torch.Size([64, 6, 30, 30])-> torch.Size([-1, 3, 30, 30])writer.add_images("input", img, step)output = torch.reshape(output, (-1, 3, 30, 30))writer.add_images("output", output, step)step += 1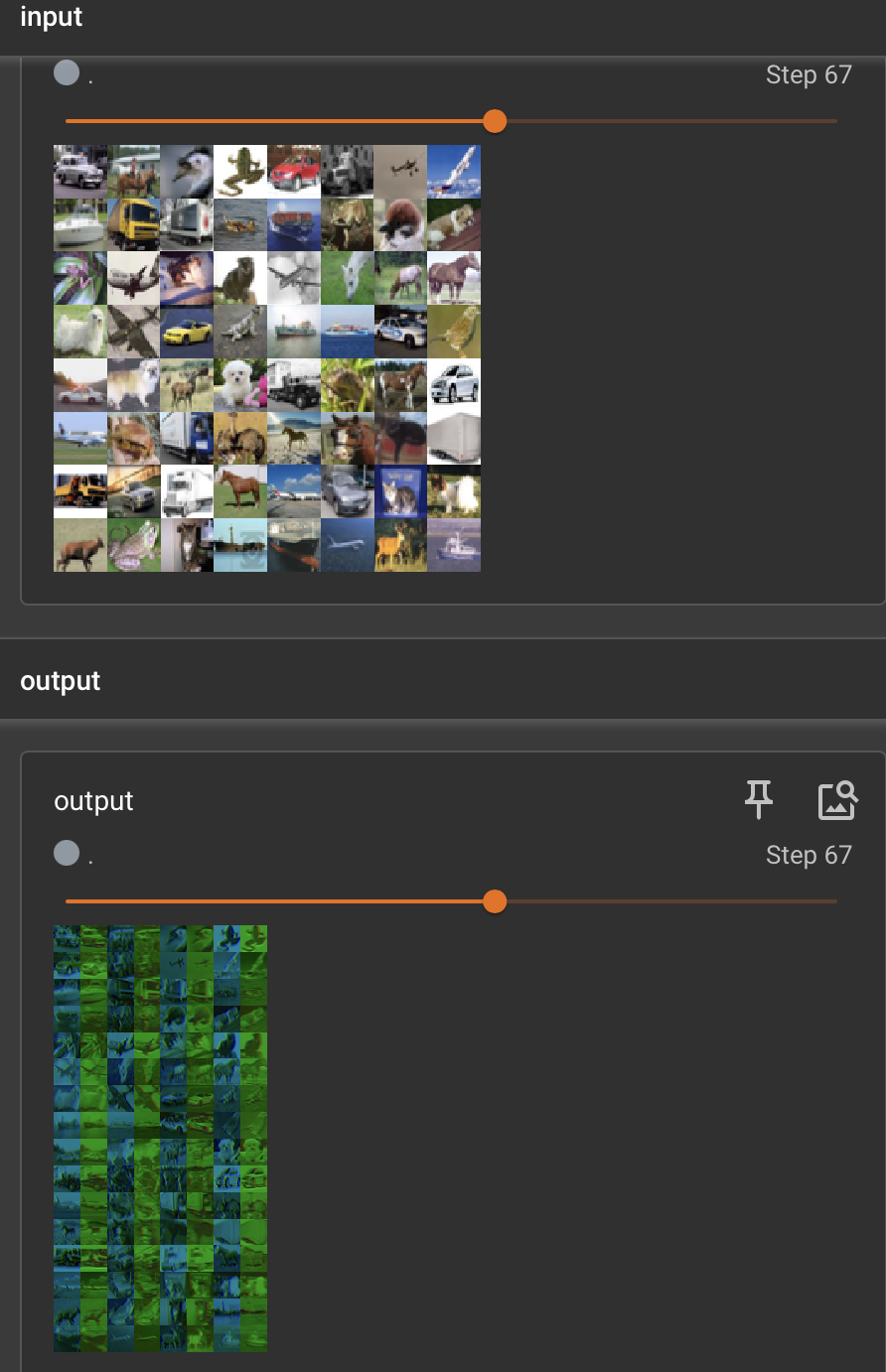
3). 池化
print(input.shape)
input = torch.reshape(input,(-1,1,5,5))
print(input.shape)class hailie(nn.Module):def __init__(self):super(hailie, self).__init__()self.maxpool1 = nn.MaxPool2d(kernel_size=3,ceil_mode=True)def forward(self, x):output = self.maxpool1(x)return output
hailie = hailie()
output = hailie(input)
print(output)torch.Size([5, 5])
torch.Size([1, 1, 5, 5])
tensor([[[[2, 3],
[5, 1]]]])
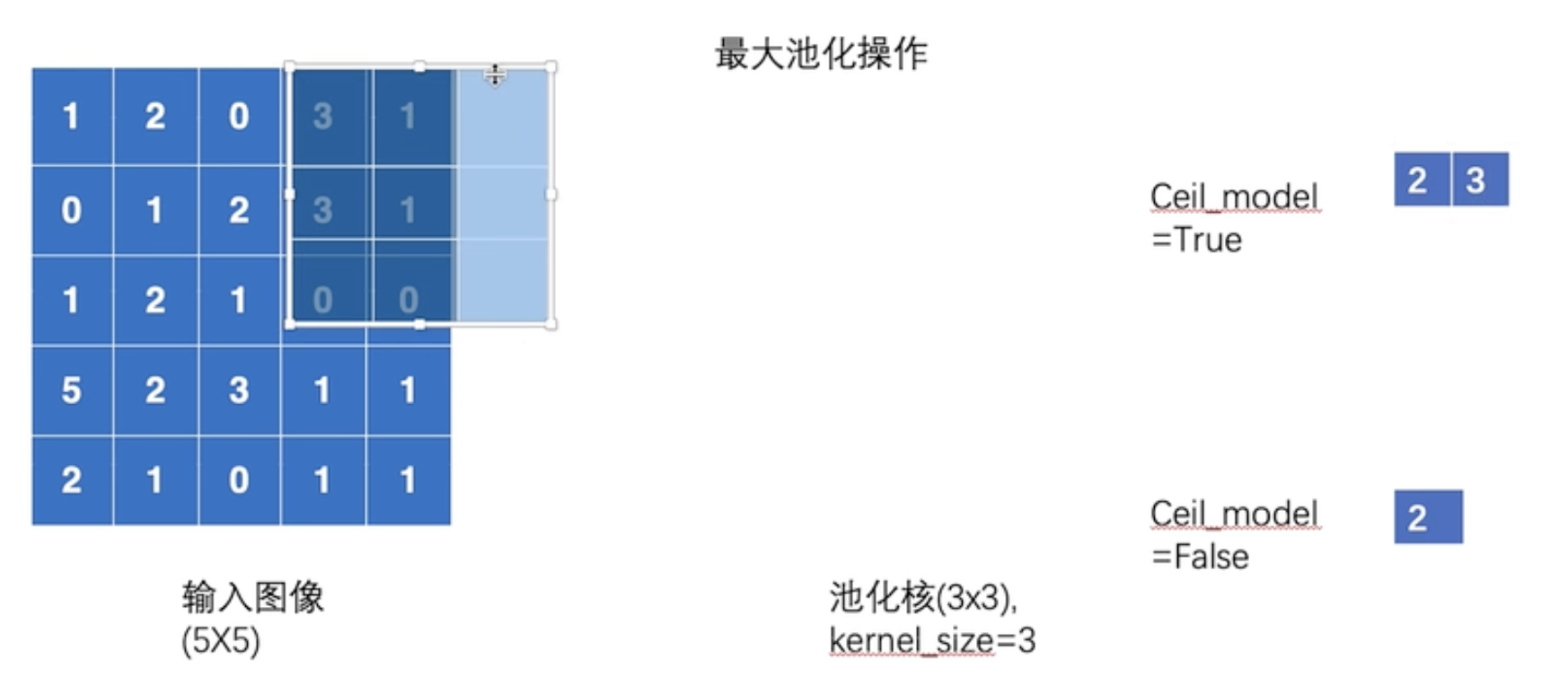
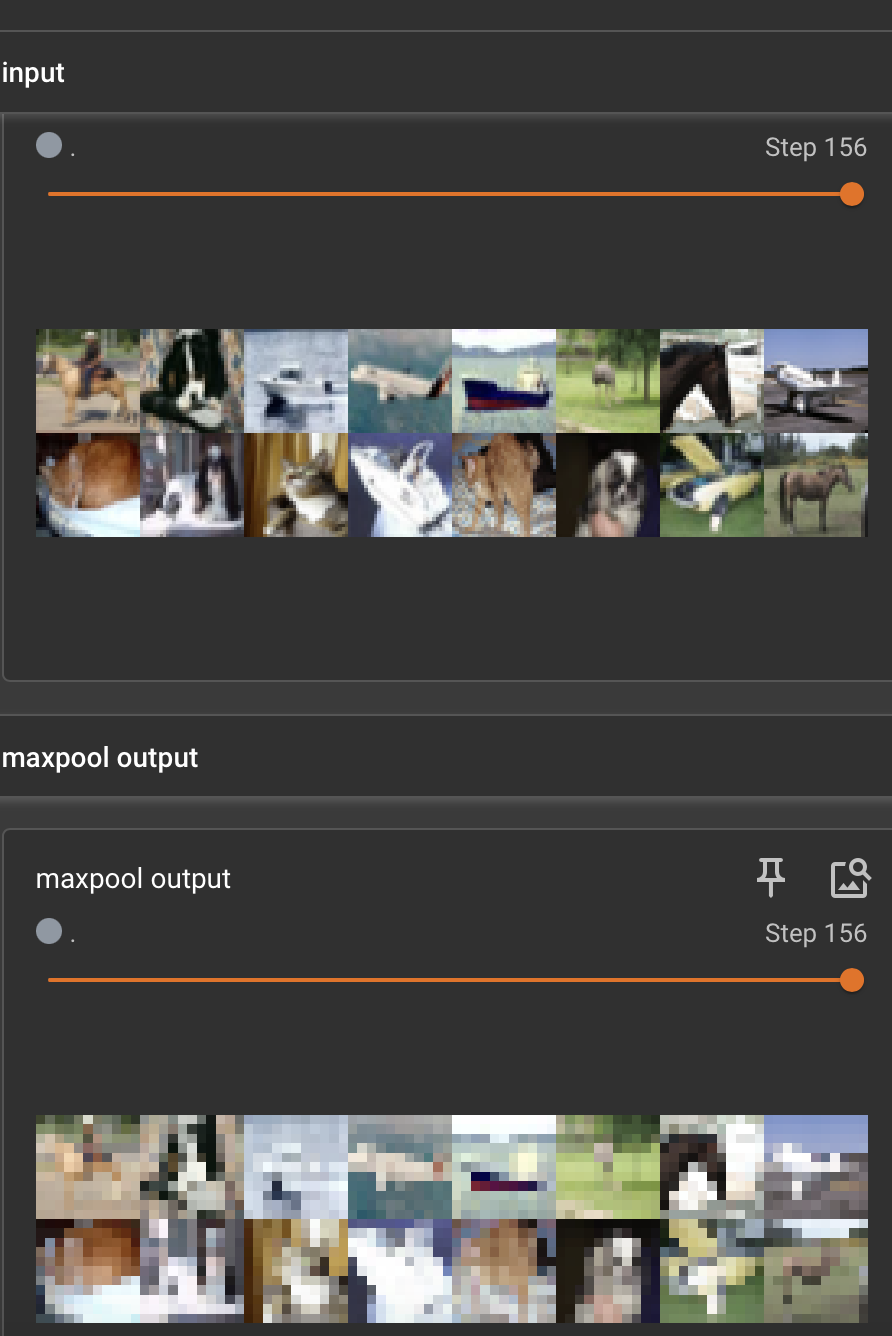
最大池化意义:
最大池化(Max Pooling)是卷积神经网络(CNN)中常用的一种下采样(Downsampling)操作,其核心意义在于提取局部最显著的特征并压缩特征图的空间尺寸
最大池化 vs. 平均池化:
-
最大池化: 强调最显著特征的存在性,更有利于识别物体关键部分(如边缘、角点、特定纹理)。它在图像识别任务中通常效果更好,因为它更关注最突出的激活。
-
平均池化: 取区域内所有值的平均值,保留该区域的整体平均响应。它平滑了特征,可能保留更多背景信息,但对噪声更敏感,有时会模糊关键特征。在需要平滑过渡或保留整体背景信息的任务中可能更合适。
池化效果:
4). 非线性激活
神经网络中的非线性变换(通常由激活函数实现,如 ReLU、Sigmoid、Tanh)是神经网络能够学习复杂模式、解决非线性问题的核心关键。如果没有非线性变换,无论神经网络有多少层,它本质上都等价于一个单层线性模型,表达能力极其有限,无法解决现实世界中的绝大多数复杂问题(如图像识别、自然语言处理等)
以下是其核心意义的详细解释:
-
打破线性限制,学习复杂函数:
-
线性模型的局限: 线性变换(矩阵乘法)的组合本质上仍然是线性变换。即使堆叠100层线性层,最终输出也只是输入数据的线性组合(
输出 = Wₙ(...(W₂(W₁*X + b₁) + b₂)...) + bₙ简化后仍是W'*X + b')。它只能学习直线(或超平面)来分割数据或拟合关系。 -
现实世界的非线性: 绝大多数真实世界的数据和问题(如图像中的物体边界、语音信号的频率变化、文本的语义关系)都具有高度非线性的特征。一个简单的例子:用一条直线(线性分类器)无法完美区分一个螺旋状分布的两类数据点。
-
激活函数的作用: 激活函数在每个神经元的输出上施加一个非线性函数(如 ReLU 的
max(0, x), Sigmoid 的1/(1+e⁻ˣ))。这使得神经元的输出不再是输入的简单线性加权和。 -
网络能力的质变: 通过在每个隐藏层后引入非线性激活函数,神经网络获得了组合这些非线性变换的能力。理论上,足够深和足够宽的网络配合非线性激活函数,可以以任意精度逼近任何复杂的连续函数(这是通用逼近定理的核心思想)。这使得网络能够学习极其复杂的决策边界和输入-输出映射关系。
-
-
import torch import torchvision from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriterinput = torch.tensor([[1, -0.5],[-1, 3]])input = torch.reshape(input, (1, 1, 2, 2))dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=64) class Hailie(nn.Module):def __init__(self):super(Hailie, self).__init__()self.sigmoid1 = nn.Sigmoid()def forward(self, x):output = self.sigmoid1(x)return output hailie = Hailie() writer = SummaryWriter("nn") step = 0for data in dataloader:img, label = datawriter.add_images("input", img, step)output = hailie(img)writer.add_images("output", output, step)step += 1
5) sequential
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
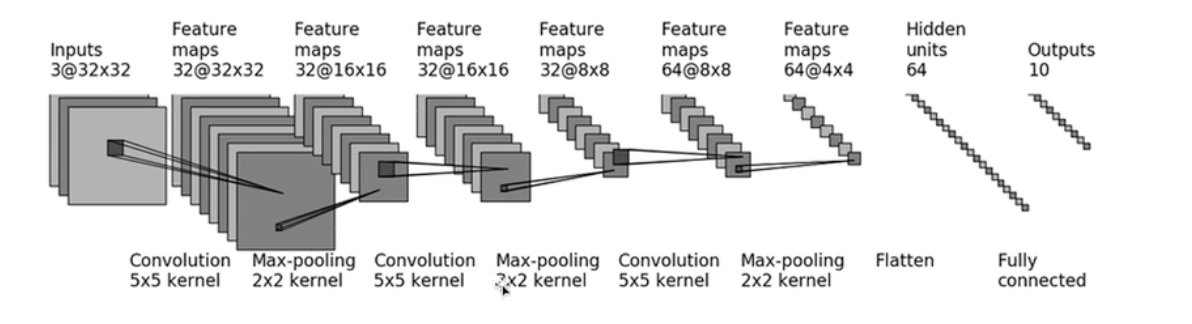
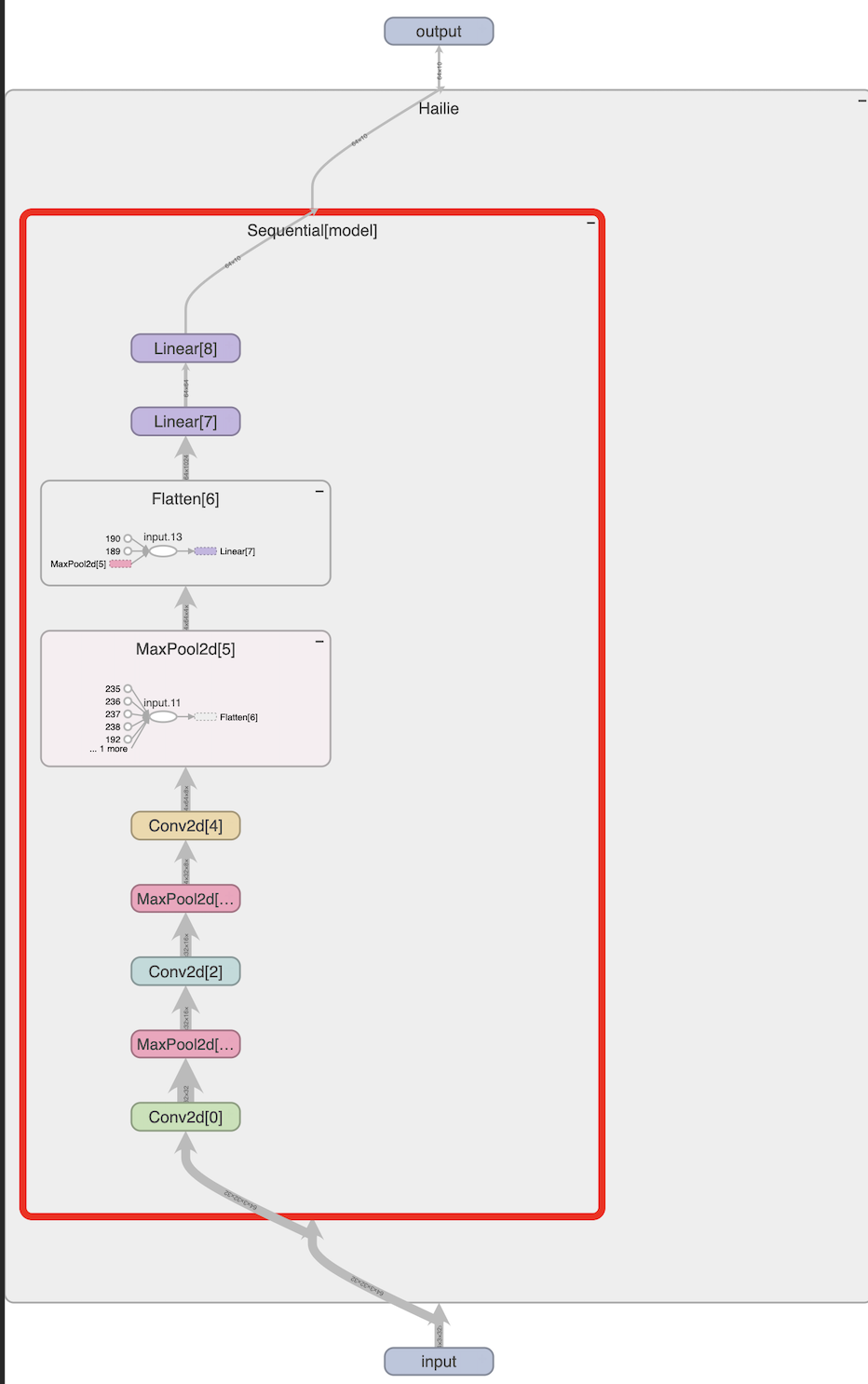
from torch.utils.tensorboard import SummaryWriterclass Hailie(nn.Module):def __init__(self):super(Hailie, self).__init__()'''self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2)self.maxpool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2)self.maxpool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2)self.maxpool3 = nn.MaxPool2d(2)self.flatten = nn.Flatten()self.linear1 = nn.Linear(in_features=1024, out_features=64)self.linear2 = nn.Linear(in_features=64, out_features=10)'''self.model = nn.Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Flatten(),Linear(in_features=1024, out_features=64),Linear(in_features=64, out_features=10))def forward(self, x):'''x = self.conv1(x)x = self.maxpool1(x)x = self.conv2(x)x = self.maxpool2(x)x = self.conv3(x)x = self.maxpool3(x)x = self.flatten(x)x = self.linear1(x)x = self.linear2(x)'''x = self.model(x)return x
hailie = Hailie()
print(hailie)input = torch.ones(64, 3, 32, 32)
output = hailie(input)
#print(output.shape)writer = SummaryWriter("nn")
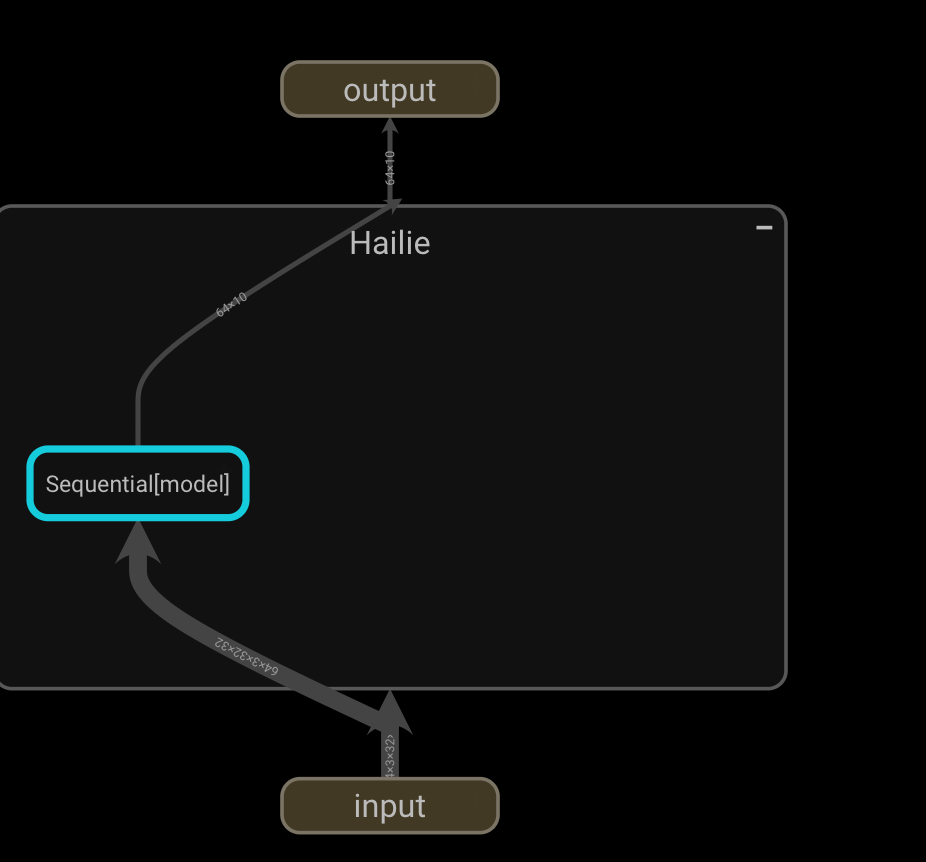
writer.add_graph(hailie, input)
writer.close()
7. 损失函数与反向传播

1)L1Loss

2)MSELoss

3)CrossEntropyLoss
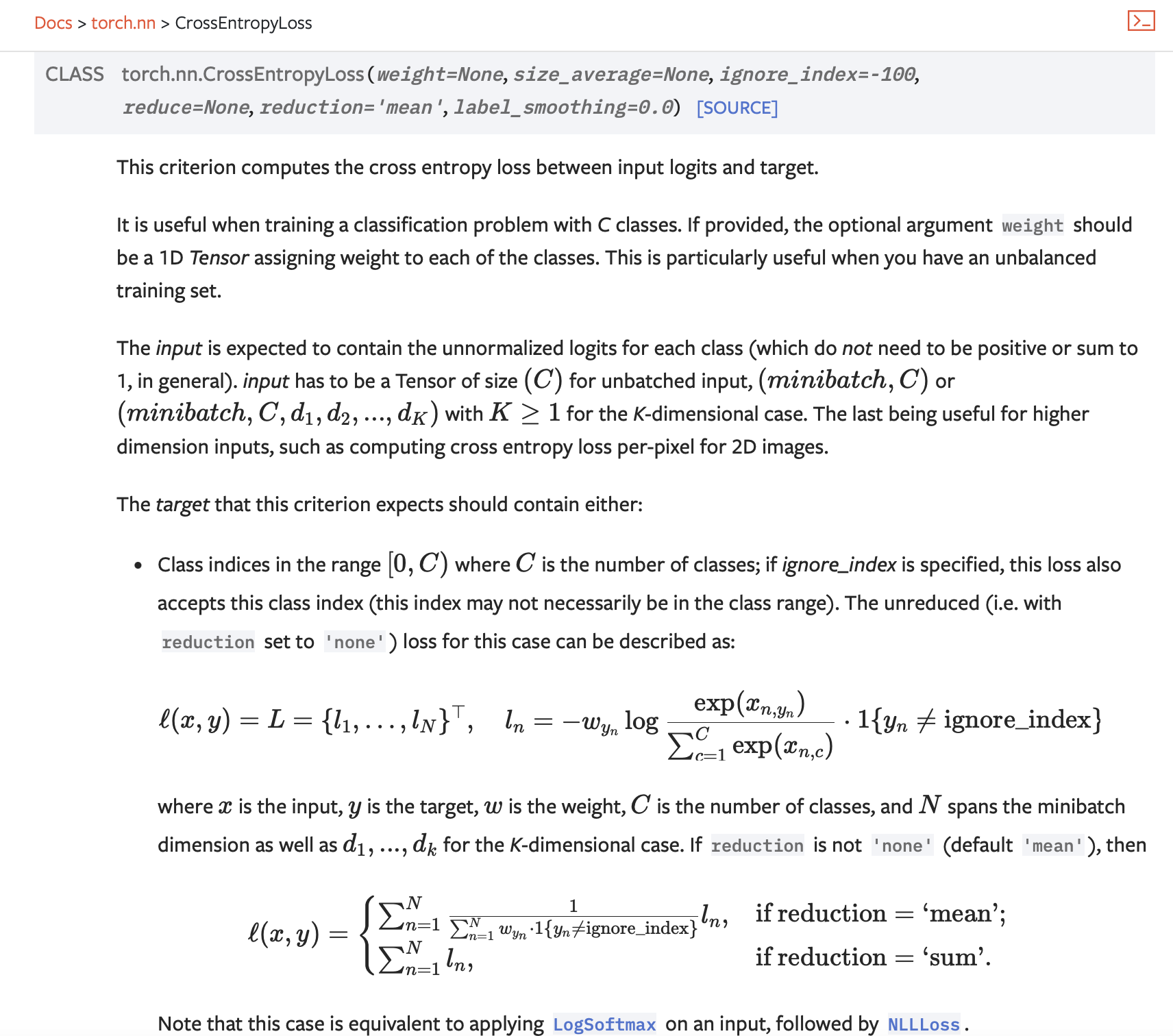
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom myenv.nn_conv import dataloader
dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=torchvision.transforms.ToTensor())dataloader = DataLoader(dataset, batch_size=64)class Hailie(nn.Module):def __init__(self):super(Hailie, self).__init__()self.model = nn.Sequential(Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Conv2d(in_channels=32, out_channels=32, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Conv2d(in_channels=32, out_channels=64, kernel_size=5, stride=1, padding=2),MaxPool2d(2),Flatten(),Linear(in_features=1024, out_features=64),Linear(in_features=64, out_features=10))def forward(self, x):x = self.model(x)return xloss = nn.CrossEntropyLoss()
hailie = Hailie()
print(hailie)for data in dataloader:imgs, labels = dataoutputs = hailie(imgs)result_loss = loss(outputs, labels)result_loss.backward()执行backward之后,grad有更新
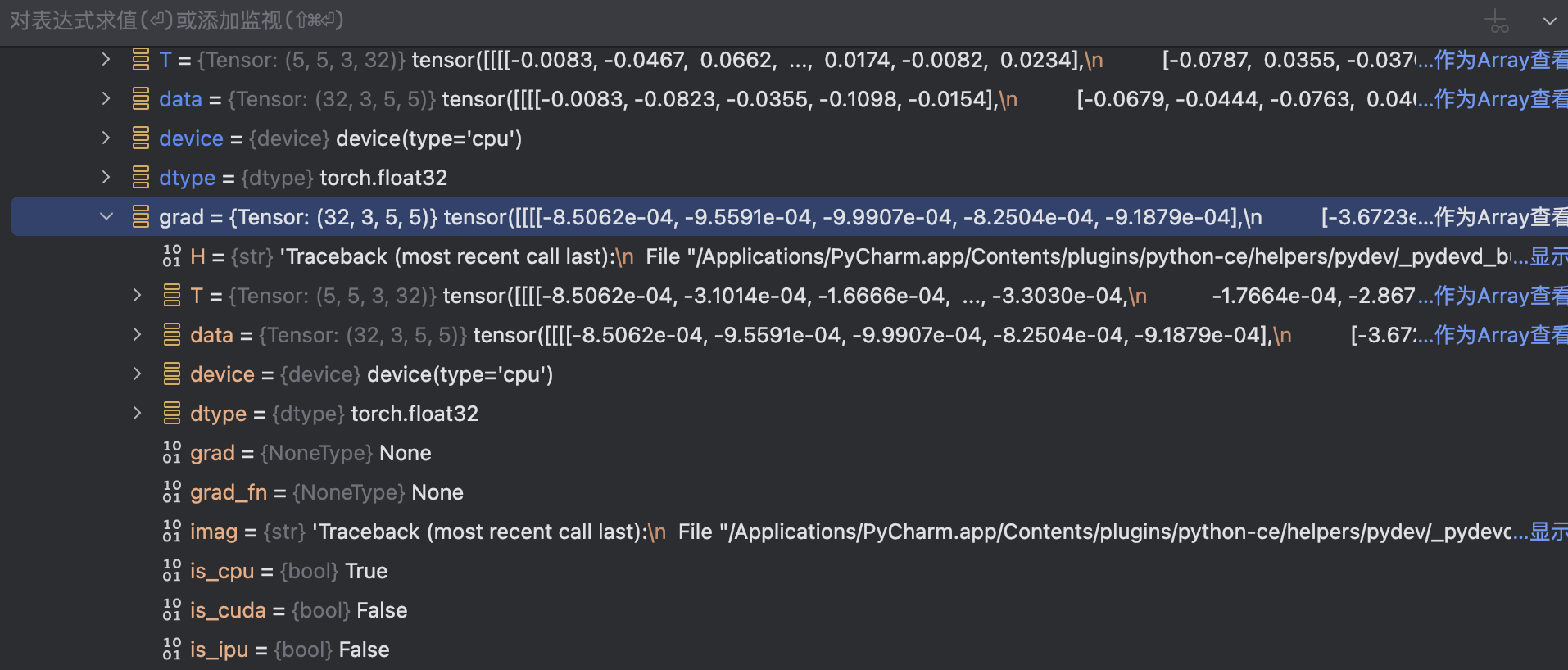
8. 优化器

使用场景
-
推荐 SGD 的情况:
-
需要极致模型性能(如训练ResNet等经典模型)。
-
数据噪声大,希望更好的泛化能力。
-
配合学习率调度器(如
StepLR)精细调参。 -
示例:训练CNN、Transformer等大型模型(常配合动量)。
-
-
推荐 Adam 的情况:
-
快速原型开发,减少调参负担。
-
稀疏梯度问题(如NLP任务)。
-
训练深度生成模型(如GAN)、RNN等。
-
默认学习率(
lr=0.001)通常表现良好。
-
9.现有网络模型的使用
VGG16 是由牛津大学视觉几何组(Visual Geometry Group)提出的经典卷积神经网络(CNN)模型,主要用于图像分类和目标识别任务。以下是其核心功能与特点详解:
核心功能
-
图像分类:
对输入图像进行 1000 类别分类(基于 ImageNet 数据集),如识别动物、物体、场景等。
输出:每个类别的概率分布(通过 Softmax 层生成)。 -
特征提取:
可作为强大的 预训练特征提取器,用于迁移学习(如目标检测、图像分割等下游任务)。
-
import torchvision.models as models# 加载预训练模型 vgg16 = models.vgg16(pretrained=True) # 迁移学习(修改分类头) vgg16.classifier[6] = torch.nn.Linear(4096, 10) # 改为10分类任务# 冻结卷积层(仅训练全连接层) for param in vgg16.features.parameters():param.requires_grad = False保存方法:
-
vgg16 = torchvision.model.vgg16(pretrained = False) #save1 模型的结构和模型的参数torch.save(vgg16,"vgg16_method1.pth")#save2 保存网络模型的参数(官网推荐)torch.save(vgg16.state_dict(),"vgg16_method2_pth")#加载模型1 model = torch.load("vgg16_method1.pth") #加载模型2 vgg16 = torchvision.model.vgg16(pretrained = False) vgg16.load_state_dict(torch.load(vgg16_method2.pth))10. 完整的模型训练
在深度学习中,
train和eval()是模型在不同阶段(训练和评估)的模式设置方法,主要影响模型特定层的行为(如 Dropout 和 Batch Normalization)
1. model.train():训练模式
-
作用:
将模型设置为训练模式,启用以下功能:-
Dropout 层:按设定概率随机丢弃神经元,防止过拟合。
-
Batch Normalization 层:使用当前批次的均值和方差进行归一化,并更新全局统计量(移动平均)。
-
-
使用场景:
在训练循环开始时调用:python
model.train() # 切换到训练模式 for data, labels in train_loader:outputs = model(data)loss = criterion(outputs, labels)loss.backward()optimizer.step()
2. model.eval():评估模式
-
作用:
将模型设置为评估模式,关闭训练特定行为:-
Dropout 层:停止随机丢弃,使用所有神经元(相当于概率为 0)。
-
Batch Normalization 层:使用训练阶段累积的全局均值和方差,而非当前批次的统计量。
-
-
额外优化:
通常与torch.no_grad()结合使用,禁用梯度计算以节省内存/算力:python
model.eval() # 切换到评估模式 with torch.no_grad(): # 不计算梯度for data, labels in test_loader:outputs = model(data)accuracy = calculate_accuracy(outputs, labels)
# -*- coding: utf-8 -*-
# 作者:小土堆
# 公众号:土堆碎念import torchvision
from torch.utils.tensorboard import SummaryWriterfrom model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoadertrain_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),download=True)# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建网络模型
tudui = Tudui()# 损失函数
loss_fn = nn.CrossEntropyLoss()# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10# 添加tensorboard
writer = SummaryWriter("../logs_train")for i in range(epoch):print("-------第 {} 轮训练开始-------".format(i+1))# 训练步骤开始tudui.train()for data in train_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始tudui.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = dataoutputs = tudui(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss: {}".format(total_test_loss))print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)total_test_step = total_test_step + 1torch.save(tudui, "tudui_{}.pth".format(i))print("模型已保存")writer.close()