微服务架构的性能优化:链路追踪与可观测性建设

📋 目录
- 引言:微服务性能挑战
- 微服务架构性能瓶颈分析
- 可观测性体系概述
- 链路追踪技术深度解析
- 性能监控指标体系
- 日志聚合与分析
- 分布式追踪系统实现
- 性能优化策略与实践
- 自动化性能调优
- 故障诊断与根因分析
- 最佳实践与案例研究
- 未来发展趋势
引言
随着微服务架构的广泛采用,传统的单体应用被分解为多个独立的服务组件。这种架构模式带来了更好的可扩展性、技术栈多样性和团队独立性,但同时也引入了新的性能挑战。
在微服务环境中,一个用户请求可能需要经过多个服务的协同处理,形成复杂的调用链路。当系统出现性能问题时,定位问题根因变得异常困难。链路追踪(Distributed Tracing) 和 可观测性(Observability) 技术的出现,为解决这些挑战提供了有效的解决方案。
本文将深入探讨微服务架构下的性能优化策略,重点介绍如何构建完善的链路追踪和可观测性体系,帮助开发团队更好地理解、监控和优化分布式系统的性能表现。
微服务架构性能瓶颈分析
常见性能瓶颈类型
1. 网络延迟瓶颈 - 服务间通信开销 - 网络分区和抖动 - 负载均衡策略不当
2. 资源竞争瓶颈 - CPU资源争用 - 内存泄漏和GC压力 - I/O操作阻塞
3. 依赖链路瓶颈 - 关键路径上的慢服务 - 级联故障传播 - 超时配置不合理
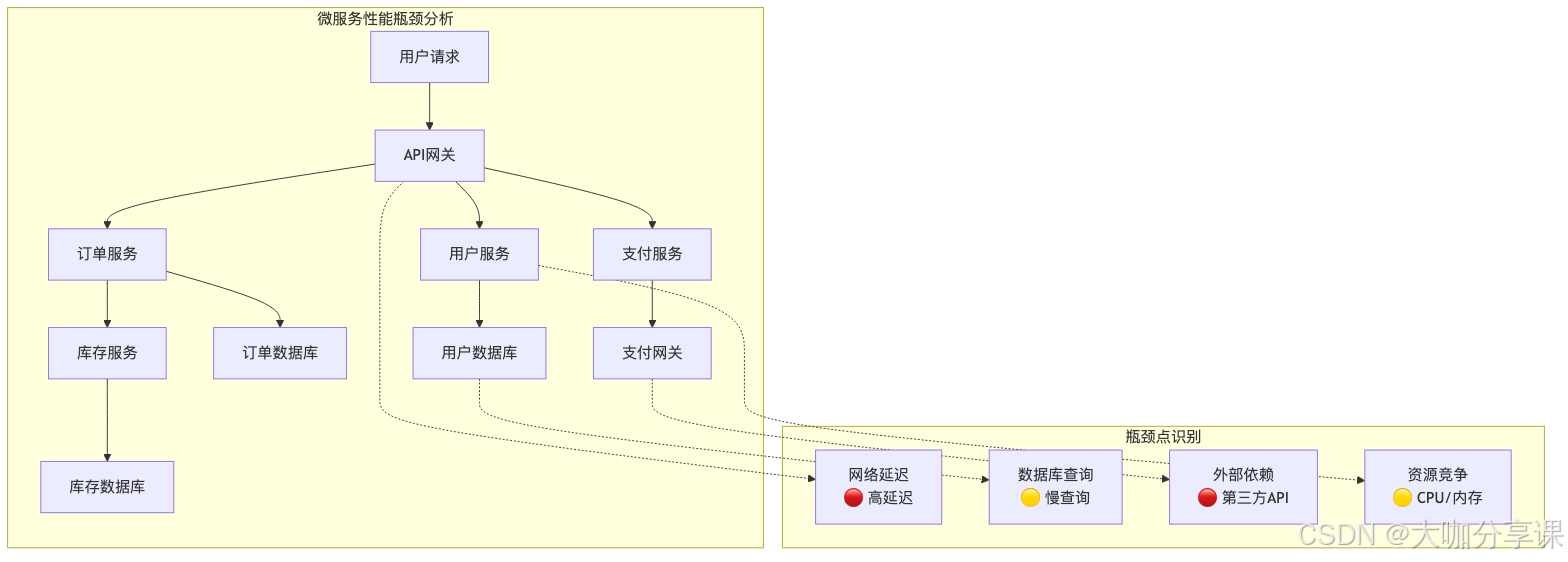
性能问题的挑战
1. 问题定位困难 - 调用链路复杂,难以追踪 - 异步处理增加排查复杂度 - 跨服务边界的性能损耗
2. 可见性不足 - 缺乏统一的监控视图 - 指标数据分散在各个服务 - 关联分析能力薄弱
3. 影响面广泛 - 单点故障影响整个系统 - 性能劣化的连锁反应 - 用户体验直接受损
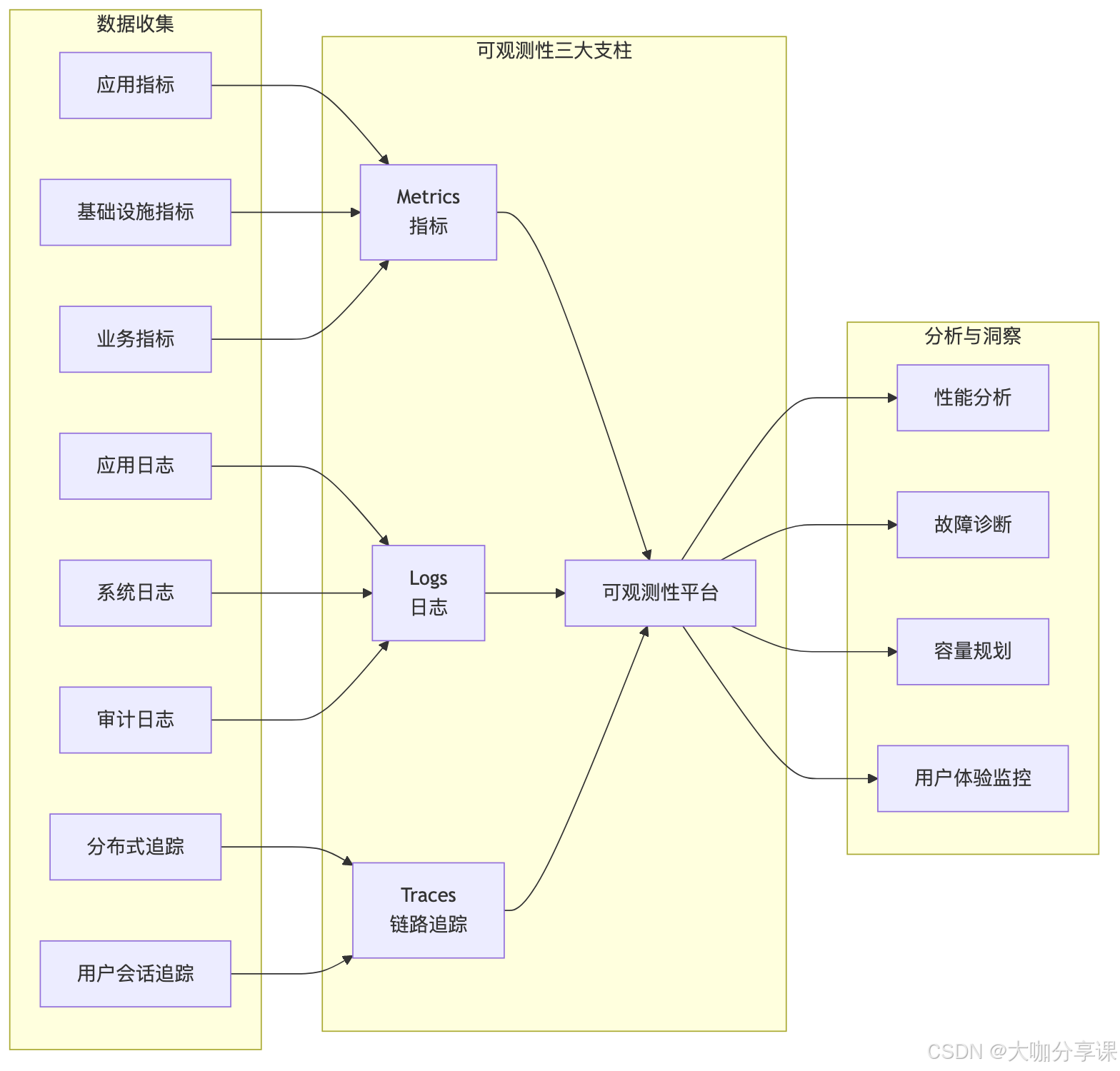
可观测性体系概述
可观测性三大支柱
可观测性(Observability)建立在三大支柱之上:
1. 指标(Metrics) - 系统性能的量化表示 - 时间序列数据 - 支持聚合和告警
2. 日志(Logs) - 离散的事件记录 - 详细的上下文信息 - 支持全文搜索和分析
3. 链路追踪(Traces) - 请求在系统中的完整路径 - 跨服务的调用关系 - 性能瓶颈的精确定位
可观测性成熟度模型
Level 0 - 基础监控 - 基本的系统指标收集 - 简单的日志记录 - 被动的故障响应
Level 1 - 结构化监控 - 标准化的指标体系 - 结构化日志格式 - 主动的告警机制
Level 2 - 关联分析 - 跨系统的指标关联 - 链路追踪的引入 - 根因分析能力
Level 3 - 智能运维 - AI驱动的异常检测 - 自动化的故障处理 - 预测性的容量管理
Level 4 - 自适应系统 - 自动调优算法 - 智能负载调度 - 自愈能力
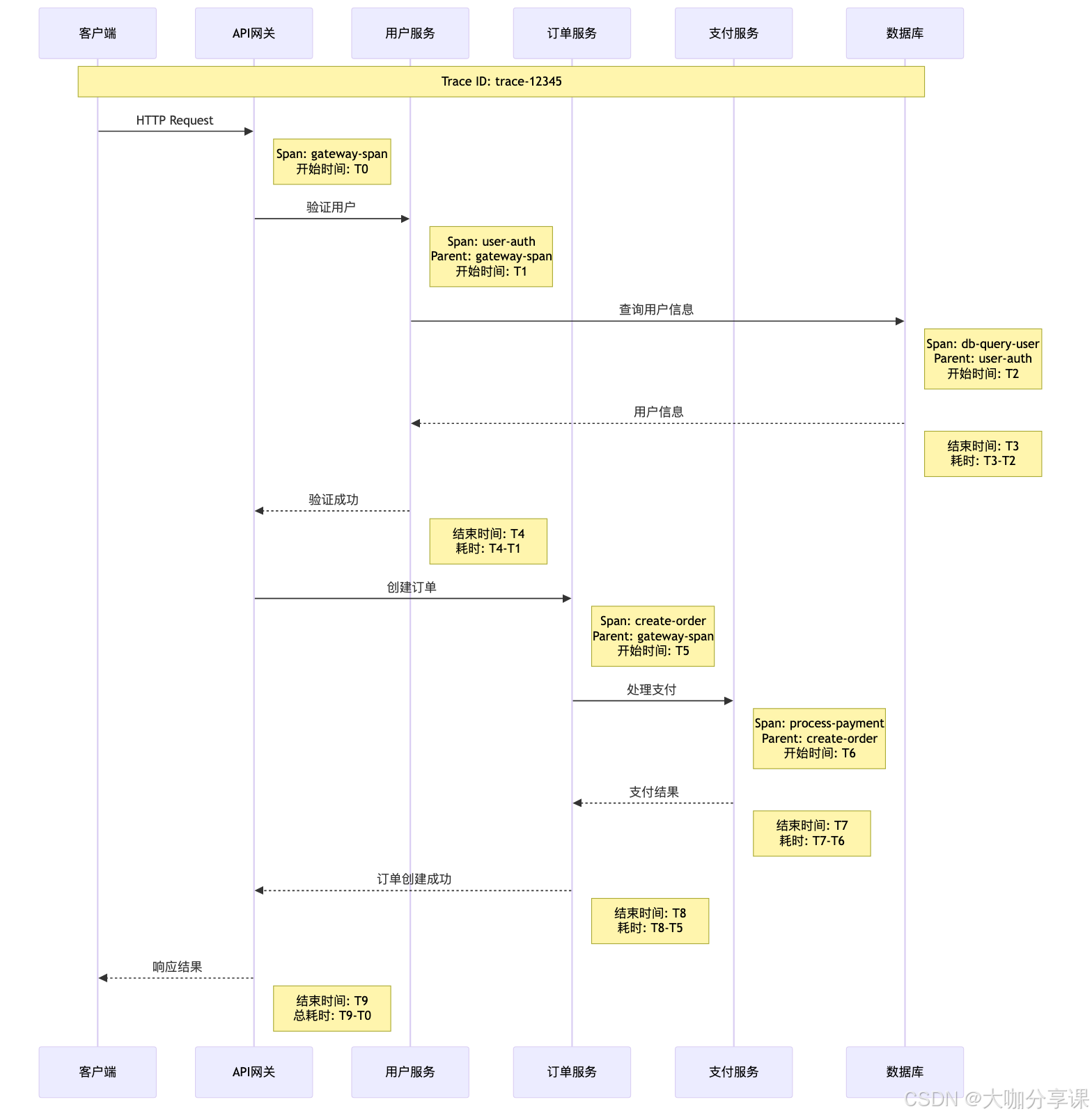
链路追踪技术深度解析
分布式追踪原理
分布式追踪通过在请求处理过程中注入追踪上下文,记录请求在各个服务中的执行路径和性能数据。
核心概念: - Trace(追踪):一个完整的请求处理过程 - Span(跨度):追踪中的一个操作单元 - Context(上下文):跨服务传递的追踪信息
主流追踪系统对比
| 特性 | Jaeger | Zipkin | SkyWalking | Datadog APM |
|---|---|---|---|---|
| 开源性 | ✅ Apache 2.0 | ✅ Apache 2.0 | ✅ Apache 2.0 | ❌ 商业产品 |
| 语言支持 | 多语言 | 多语言 | Java重点 | 多语言 |
| 存储后端 | 多种选择 | 多种选择 | 自带存储 | 托管服务 |
| UI界面 | 功能完善 | 基础功能 | 功能丰富 | 专业界面 |
| 性能开销 | 低 | 低 | 中等 | 低 |
| 学习曲线 | 中等 | 简单 | 中等 | 简单 |
OpenTelemetry标准
OpenTelemetry作为现代可观测性的标准,提供了统一的API、SDK和工具链。
核心组件:
# OpenTelemetry Collector配置示例
receivers:otlp:protocols:grpc:endpoint: 0.0.0.0:4317http:endpoint: 0.0.0.0:4318jaeger:protocols:grpc:endpoint: 0.0.0.0:14250processors:batch:timeout: 5ssend_batch_size: 1024resource:attributes:- key: environmentvalue: productionaction: upsertexporters:jaeger:endpoint: http://jaeger:14268/api/tracesprometheus:endpoint: "0.0.0.0:8889"elasticsearch:endpoints: [http://elasticsearch:9200]logs_index: otel-logsservice:pipelines:traces:receivers: [otlp, jaeger]processors: [batch, resource]exporters: [jaeger]metrics:receivers: [otlp]processors: [batch, resource]exporters: [prometheus]logs:receivers: [otlp]processors: [batch, resource]exporters: [elasticsearch]应用集成实践
Java应用集成示例:
// Spring Boot应用的OpenTelemetry配置
@Configuration
@EnableConfigurationProperties(TracingProperties.class)
public class TracingConfiguration {@Beanpublic OpenTelemetry openTelemetry(TracingProperties properties) {return OpenTelemetrySDK.builder().setTracerProvider(SdkTracerProvider.builder().addSpanProcessor(BatchSpanProcessor.builder(OtlpGrpcSpanExporter.builder().setEndpoint(properties.getEndpoint()).build()).build()).setResource(Resource.getDefault().merge(Resource.builder().put(ResourceAttributes.SERVICE_NAME, properties.getServiceName()).put(ResourceAttributes.SERVICE_VERSION, properties.getServiceVersion()).build())).build()).buildAndRegisterGlobal();}@Beanpublic Tracer tracer(OpenTelemetry openTelemetry) {return openTelemetry.getTracer("com.example.application");}
}// 业务代码中的手动追踪
@Service
public class OrderService {private final Tracer tracer;public OrderService(Tracer tracer) {this.tracer = tracer;}@Traced // 自动追踪注解public Order createOrder(CreateOrderRequest request) {Span span = tracer.spanBuilder("create-order").setSpanKind(SpanKind.SERVER).startSpan();try (Scope scope = span.makeCurrent()) {// 添加自定义属性span.setAttributes(Attributes.of(AttributeKey.stringKey("user.id"), request.getUserId(),AttributeKey.longKey("order.amount"), request.getAmount()));// 业务逻辑处理Order order = processOrder(request);// 记录业务事件span.addEvent("order-validated", Attributes.of(AttributeKey.stringKey("order.id"), order.getId()));return order;} catch (Exception e) {span.recordException(e);span.setStatus(StatusCode.ERROR, e.getMessage());throw e;} finally {span.end();}}
}性能监控指标体系
分层监控模型
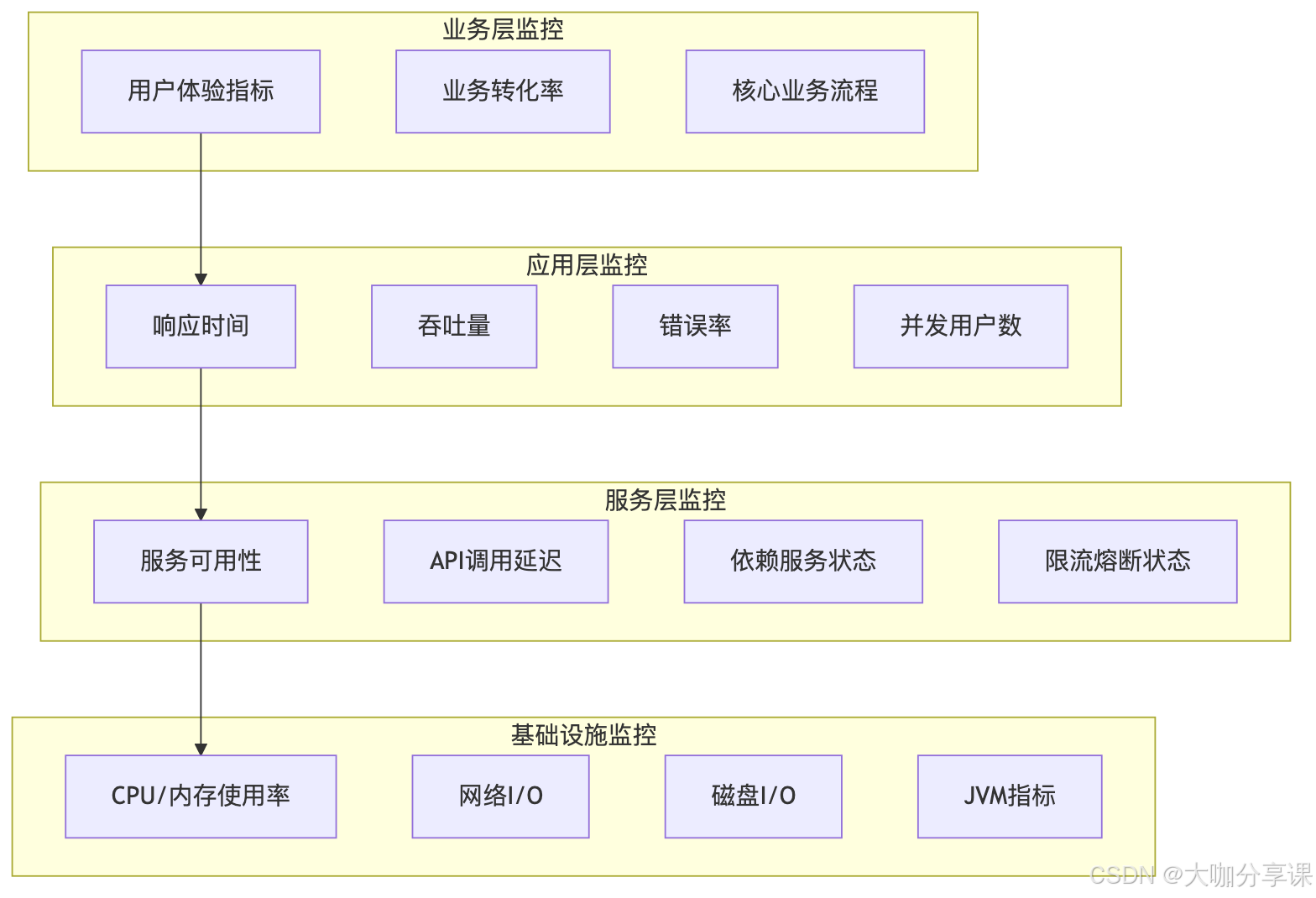
关键性能指标(KPI)
1. RED指标模型 - Rate(速率):请求处理速率 - Errors(错误):错误率统计 - Duration(持续时间):响应时间分布
2. USE指标模型 - Utilization(利用率):资源使用情况 - Saturation(饱和度):资源饱和程度 - Errors(错误):资源错误统计
3. 业务指标 - 用户体验指标:页面加载时间、交互响应时间 - 转化率指标:注册转化率、支付成功率 - 业务流程指标:订单处理时间、用户留存率
指标采集与存储
Prometheus配置示例:
# prometheus.yml
global:scrape_interval: 15sevaluation_interval: 15srule_files:- "performance_rules.yml"scrape_configs:- job_name: 'microservices'static_configs:- targets: - 'user-service:8080'- 'order-service:8080'- 'payment-service:8080'metrics_path: /actuator/prometheusscrape_interval: 10s- job_name: 'kubernetes-pods'kubernetes_sd_configs:- role: podrelabel_configs:- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)alerting:alertmanagers:- static_configs:- targets:- alertmanager:9093性能告警规则:
# performance_rules.yml
groups:- name: microservice.performancerules:# 高延迟告警- alert: HighLatencyexpr: histogram_quantile(0.95, http_request_duration_seconds_bucket) > 0.5for: 5mlabels:severity: warningannotations:summary: "服务 {{ $labels.service }} 延迟过高"description: "{{ $labels.service }} 的95%分位延迟超过500ms,当前值:{{ $value }}s"# 错误率告警- alert: HighErrorRateexpr: rate(http_requests_total{status=~"5.."}[5m]) / rate(http_requests_total[5m]) > 0.05for: 2mlabels:severity: criticalannotations:summary: "服务 {{ $labels.service }} 错误率过高"description: "{{ $labels.service }} 的错误率超过5%,当前值:{{ $value | humanizePercentage }}"# 内存使用率告警- alert: HighMemoryUsageexpr: process_resident_memory_bytes / 1024 / 1024 > 512for: 10mlabels:severity: warningannotations:summary: "服务 {{ $labels.service }} 内存使用过高"description: "{{ $labels.service }} 内存使用超过512MB,当前值:{{ $value }}MB"日志聚合与分析
结构化日志设计
日志标准格式:
{"timestamp": "2024-06-07T10:30:45.123Z","level": "INFO","service": "order-service","traceId": "abc123def456","spanId": "span789","userId": "user-12345","operation": "createOrder","message": "订单创建成功","duration": 245,"status": "success","metadata": {"orderId": "order-67890","amount": 99.99,"currency": "CNY"},"error": null
}Java应用日志配置:
<!-- logback-spring.xml -->
<configuration><include resource="org/springframework/boot/logging/logback/defaults.xml"/><springProfile name="!local"><appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp/><logLevel/><loggerName/><mdc/><arguments/><message/><stackTrace/></providers></encoder></appender></springProfile><!-- 性能日志专用appender --><appender name="PERFORMANCE" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>logs/performance.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>logs/performance.%d{yyyy-MM-dd}.%i.gz</fileNamePattern><maxFileSize>100MB</maxFileSize><maxHistory>30</maxHistory></rollingPolicy><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><timestamp/><mdc/><message/></providers></encoder></appender><logger name="PERFORMANCE" level="INFO" additivity="false"><appender-ref ref="PERFORMANCE"/></appender><root level="INFO"><appender-ref ref="STDOUT"/></root>
</configuration>ELK Stack集成
Elasticsearch映射配置:
{"mappings": {"properties": {"timestamp": {"type": "date","format": "strict_date_optional_time"},"level": {"type": "keyword"},"service": {"type": "keyword"},"traceId": {"type": "keyword"},"spanId": {"type": "keyword"},"userId": {"type": "keyword"},"operation": {"type": "keyword"},"message": {"type": "text","analyzer": "standard"},"duration": {"type": "long"},"status": {"type": "keyword"},"metadata": {"type": "object","dynamic": true}}}
}Logstash处理配置:
# logstash.conf
input {beats {port => 5044}
}filter {if [fields][service] {mutate {add_field => { "service_name" => "%{[fields][service]}" }}}# 解析JSON日志json {source => "message"}# 提取性能指标if [operation] and [duration] {mutate {add_field => { "metric_type" => "performance" }convert => { "duration" => "integer" }}}# 错误日志特殊处理if [level] == "ERROR" {mutate {add_field => { "alert_required" => "true" }}}# 添加地理位置信息(如果有IP)if [clientIp] {geoip {source => "clientIp"target => "geoip"}}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "microservice-logs-%{+YYYY.MM.dd}"template_name => "microservice-logs"}# 性能指标发送到专门的索引if [metric_type] == "performance" {elasticsearch {hosts => ["elasticsearch:9200"]index => "performance-metrics-%{+YYYY.MM.dd}"}}
}分布式追踪系统实现
Jaeger部署架构
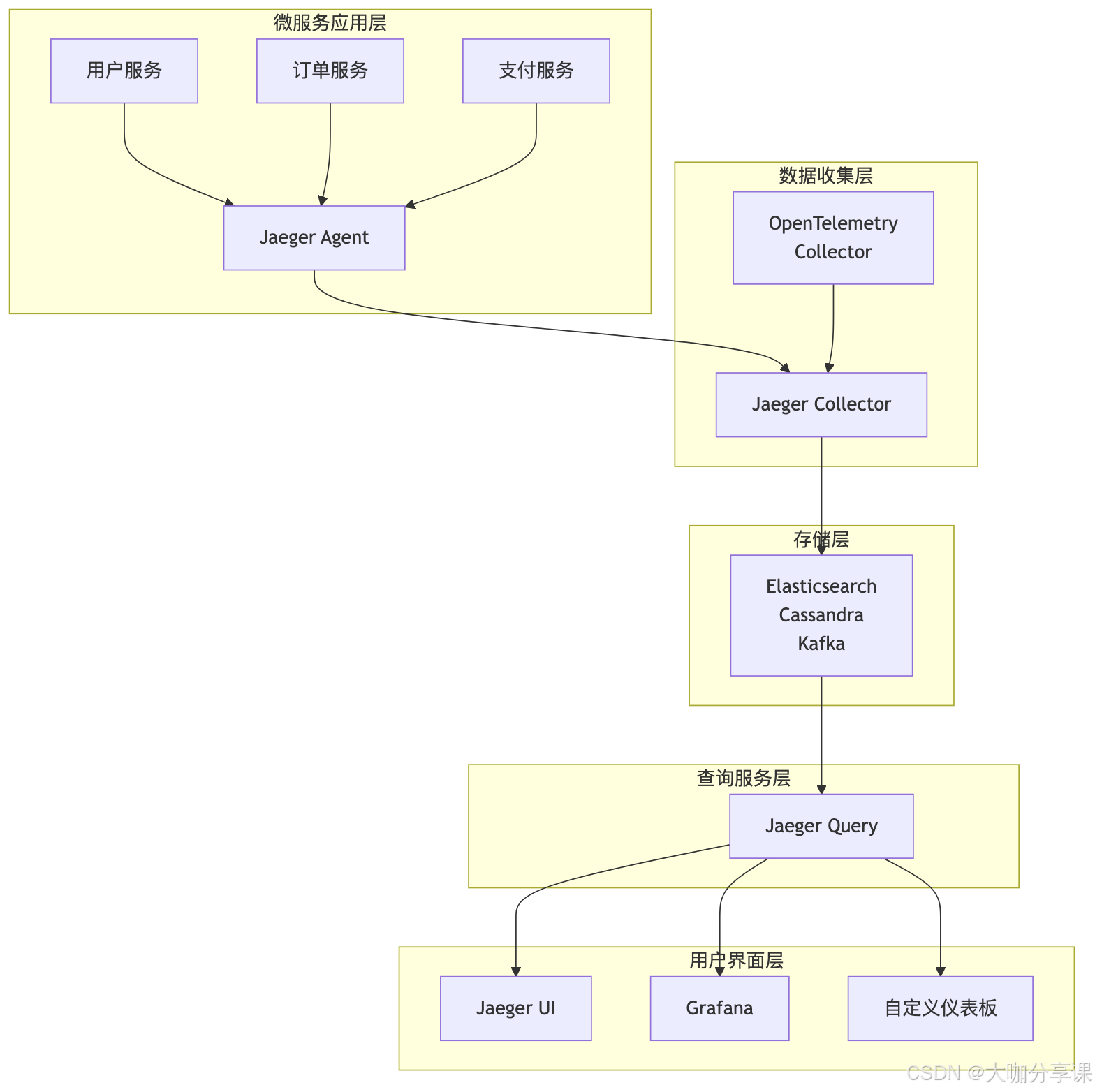
Kubernetes部署配置:
# jaeger-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: jaeger-all-in-onelabels:app: jaeger
spec:replicas: 1selector:matchLabels:app: jaegertemplate:metadata:labels:app: jaegerspec:containers:- name: jaegerimage: jaegertracing/all-in-one:1.41ports:- containerPort: 16686name: jaeger-ui- containerPort: 14268name: jaeger-http- containerPort: 14250name: jaeger-grpc- containerPort: 6831name: jaeger-udpenv:- name: COLLECTOR_ZIPKIN_HTTP_PORTvalue: "9411"- name: SPAN_STORAGE_TYPEvalue: "elasticsearch"- name: ES_SERVER_URLSvalue: "http://elasticsearch:9200"- name: ES_USERNAMEvalue: "elastic"- name: ES_PASSWORDvalueFrom:secretKeyRef:name: elasticsearch-secretkey: passwordresources:limits:memory: "512Mi"cpu: "500m"requests:memory: "256Mi"cpu: "250m"---
apiVersion: v1
kind: Service
metadata:name: jaeger-service
spec:selector:app: jaegerports:- name: jaeger-uiport: 16686targetPort: 16686- name: jaeger-httpport: 14268targetPort: 14268- name: jaeger-grpcport: 14250targetPort: 14250- name: jaeger-udpport: 6831targetPort: 6831protocol: UDP自定义追踪数据分析
性能分析查询示例:
# 使用Jaeger Python客户端进行性能分析
from jaeger_client import Config
import requests
import pandas as pd
import matplotlib.pyplot as pltclass PerformanceAnalyzer:def __init__(self, jaeger_endpoint):self.jaeger_endpoint = jaeger_endpointdef get_trace_data(self, service_name, start_time, end_time):"""从Jaeger获取追踪数据"""url = f"{self.jaeger_endpoint}/api/traces"params = {'service': service_name,'start': start_time,'end': end_time,'limit': 1000}response = requests.get(url, params=params)return response.json()def analyze_performance_trends(self, traces_data):"""分析性能趋势"""performance_data = []for trace in traces_data['data']:for span in trace['spans']:performance_data.append({'service': span['process']['serviceName'],'operation': span['operationName'],'duration': span['duration'],'start_time': span['startTime'],'tags': {tag['key']: tag['value'] for tag in span['tags']}})df = pd.DataFrame(performance_data)return self.generate_performance_report(df)def generate_performance_report(self, df):"""生成性能报告"""report = {'avg_response_time': df.groupby('service')['duration'].mean(),'p95_response_time': df.groupby('service')['duration'].quantile(0.95),'error_rate': df[df['tags'].str.contains('error', na=False)].groupby('service').size() / df.groupby('service').size(),'throughput': df.groupby('service').size() / (df['start_time'].max() - df['start_time'].min())}return report# 使用示例
analyzer = PerformanceAnalyzer('http://jaeger-query:16686')
traces = analyzer.get_trace_data('order-service', '1h', 'now')
report = analyzer.analyze_performance_trends(traces)实时性能监控
Grafana仪表板配置:
{"dashboard": {"title": "微服务性能监控","panels": [{"title": "服务响应时间趋势","type": "graph","targets": [{"expr": "histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))","legendFormat": "{{service}} - P95"},{"expr": "histogram_quantile(0.50, rate(http_request_duration_seconds_bucket[5m]))","legendFormat": "{{service}} - P50"}],"yAxes": [{"label": "响应时间 (秒)","min": 0}]},{"title": "服务吞吐量","type": "graph","targets": [{"expr": "rate(http_requests_total[5m])","legendFormat": "{{service}} - RPS"}]},{"title": "错误率","type": "singlestat","targets": [{"expr": "rate(http_requests_total{status=~\"5..\"}[5m]) / rate(http_requests_total[5m]) * 100","legendFormat": "错误率 %"}],"thresholds": "5,10","colorBackground": true}]}
}性能优化策略与实践
应用层优化
1. 缓存策略优化
@Service
public class ProductService {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;@Autowiredprivate ProductRepository productRepository;// 多级缓存策略@Cacheable(value = "products", key = "#id", condition = "#id != null")public Product getProduct(Long id) {// L1缓存:本地缓存(Caffeine)Product product = localCache.get(id);if (product != null) {return product;}// L2缓存:分布式缓存(Redis)product = (Product) redisTemplate.opsForValue().get("product:" + id);if (product != null) {localCache.put(id, product);return product;}// L3:数据库查询product = productRepository.findById(id).orElse(null);if (product != null) {// 写回缓存redisTemplate.opsForValue().set("product:" + id, product, Duration.ofMinutes(30));localCache.put(id, product);}return product;}// 缓存预热@EventListener(ApplicationReadyEvent.class)public void warmUpCache() {CompletableFuture.runAsync(() -> {List<Long> hotProductIds = getHotProductIds();hotProductIds.parallelStream().forEach(this::getProduct);});}
}2. 异步处理优化
@Service
public class OrderProcessingService {@Async("orderProcessingExecutor")@Tracedpublic CompletableFuture<Void> processOrderAsync(Order order) {try {// 异步处理订单validateOrder(order);reserveInventory(order);processPayment(order);sendConfirmationEmail(order);return CompletableFuture.completedFuture(null);} catch (Exception e) {return CompletableFuture.failedFuture(e);}}// 批量处理优化@Scheduled(fixedDelay = 5000)public void processPendingOrders() {List<Order> pendingOrders = orderRepository.findPendingOrders(PageRequest.of(0, 100));// 并行处理,但控制并发度pendingOrders.parallelStream().limit(20) // 限制并发处理数量.forEach(order -> {try {processOrderAsync(order).get(30, TimeUnit.SECONDS);} catch (Exception e) {handleProcessingError(order, e);}});}
}// 线程池配置
@Configuration
@EnableAsync
public class AsyncConfiguration {@Bean("orderProcessingExecutor")public TaskExecutor orderProcessingExecutor() {ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();executor.setCorePoolSize(10);executor.setMaxPoolSize(50);executor.setQueueCapacity(200);executor.setThreadNamePrefix("order-processing-");executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());executor.initialize();return executor;}
}数据库性能优化
1. 连接池优化
# application.yml
spring:datasource:hikari:maximum-pool-size: 20minimum-idle: 5connection-timeout: 30000idle-timeout: 600000max-lifetime: 1800000leak-detection-threshold: 60000jpa:properties:hibernate:jdbc:batch_size: 50order_inserts: trueorder_updates: truebatch_versioned_data: trueshow-sql: falseopen-in-view: false2. 查询优化
@Repository
public class OrderRepository {@EntityManagerprivate EntityManager entityManager;// 批量查询优化@Query("SELECT o FROM Order o JOIN FETCH o.items WHERE o.status = :status")List<Order> findOrdersWithItems(@Param("status") OrderStatus status);// 分页查询优化@Query(value = "SELECT * FROM orders WHERE created_at >= :startDate " +"ORDER BY created_at DESC LIMIT :limit OFFSET :offset",nativeQuery = true)List<Order> findRecentOrders(@Param("startDate") LocalDateTime startDate,@Param("limit") int limit,@Param("offset") int offset);// 使用索引提示优化@Query(value = "SELECT /*+ USE_INDEX(orders, idx_status_created) */ * " +"FROM orders WHERE status = :status AND created_at >= :date",nativeQuery = true)List<Order> findOrdersOptimized(@Param("status") String status,@Param("date") LocalDateTime date);
}网络层优化
1. HTTP/2和连接复用
@Configuration
public class HttpClientConfiguration {@Beanpublic ReactorClientHttpConnector httpConnector() {HttpClient httpClient = HttpClient.create().protocol(HttpProtocol.H2C, HttpProtocol.HTTP11) // 支持HTTP/2.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 5000).option(ChannelOption.SO_KEEPALIVE, true).option(ChannelOption.TCP_NODELAY, true).responseTimeout(Duration.ofSeconds(30)).compress(true);return new ReactorClientHttpConnector(httpClient);}@Beanpublic WebClient webClient(ReactorClientHttpConnector connector) {return WebClient.builder().clientConnector(connector).codecs(configurer -> {configurer.defaultCodecs().maxInMemorySize(10 * 1024 * 1024); // 10MB}).build();}
}2. 负载均衡优化
@Component
public class SmartLoadBalancer {private final Map<String, ServiceMetrics> serviceMetrics = new ConcurrentHashMap<>();public ServiceInstance choose(List<ServiceInstance> instances) {if (instances.isEmpty()) {return null;}// 基于响应时间和成功率的智能负载均衡return instances.stream().min(Comparator.comparingDouble(this::calculateScore)).orElse(instances.get(0));}private double calculateScore(ServiceInstance instance) {ServiceMetrics metrics = serviceMetrics.get(instance.getInstanceId());if (metrics == null) {return 1.0; // 新实例给予中等权重}double responseTimeScore = metrics.getAvgResponseTime() / 1000.0; // 响应时间权重double errorRateScore = metrics.getErrorRate() * 10; // 错误率权重double activeRequestsScore = metrics.getActiveRequests() / 100.0; // 并发请求权重return responseTimeScore + errorRateScore + activeRequestsScore;}@EventListenerpublic void handleMetricsUpdate(ServiceMetricsEvent event) {serviceMetrics.put(event.getInstanceId(), event.getMetrics());}
}自动化性能调优
基于机器学习的性能预测
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.preprocessing import StandardScaler
import joblibclass PerformancePredictor:def __init__(self):self.model = RandomForestRegressor(n_estimators=100, random_state=42)self.scaler = StandardScaler()self.feature_columns = ['cpu_usage', 'memory_usage', 'active_connections','request_rate', 'db_connections', 'cache_hit_rate']def prepare_features(self, metrics_data):"""准备特征数据"""df = pd.DataFrame(metrics_data)# 添加时间特征df['hour'] = pd.to_datetime(df['timestamp']).dt.hourdf['day_of_week'] = pd.to_datetime(df['timestamp']).dt.dayofweek# 添加滚动统计特征df['cpu_usage_ma5'] = df['cpu_usage'].rolling(window=5).mean()df['memory_usage_trend'] = df['memory_usage'].diff()# 添加交互特征df['cpu_memory_ratio'] = df['cpu_usage'] / (df['memory_usage'] + 1e-6)df['load_factor'] = df['request_rate'] * df['avg_response_time']return df[self.feature_columns].fillna(0)def train_model(self, historical_data):"""训练性能预测模型"""features = self.prepare_features(historical_data)targets = historical_data['response_time']# 标准化特征features_scaled = self.scaler.fit_transform(features)# 训练模型self.model.fit(features_scaled, targets)# 保存模型joblib.dump(self.model, 'performance_model.pkl')joblib.dump(self.scaler, 'feature_scaler.pkl')def predict_performance(self, current_metrics):"""预测性能指标"""features = self.prepare_features([current_metrics])features_scaled = self.scaler.transform(features)prediction = self.model.predict(features_scaled)[0]confidence = self.model.predict_proba(features_scaled)[0] if hasattr(self.model, 'predict_proba') else 0.8return {'predicted_response_time': prediction,'confidence': confidence,'feature_importance': dict(zip(self.feature_columns, self.model.feature_importances_))}def generate_optimization_suggestions(self, prediction_result):"""生成优化建议"""suggestions = []importance = prediction_result['feature_importance']# 基于特征重要性生成建议if importance['cpu_usage'] > 0.3:suggestions.append({'type': 'scaling','action': 'increase_cpu_resources','priority': 'high'})if importance['memory_usage'] > 0.25:suggestions.append({'type': 'optimization','action': 'optimize_memory_usage','priority': 'medium'})if importance['cache_hit_rate'] > 0.2:suggestions.append({'type': 'caching','action': 'improve_cache_strategy','priority': 'medium'})return suggestions自适应资源调整
# Kubernetes HPA配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: adaptive-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: order-serviceminReplicas: 2maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70- type: Resourceresource:name: memorytarget:type: UtilizationaverageUtilization: 80- type: Objectobject:metric:name: response_time_p95target:type: Valuevalue: "500m"behavior:scaleDown:stabilizationWindowSeconds: 300policies:- type: Percentvalue: 10periodSeconds: 60scaleUp:stabilizationWindowSeconds: 60policies:- type: Percentvalue: 50periodSeconds: 30- type: Podsvalue: 2periodSeconds: 30智能告警系统
class IntelligentAlertSystem:def __init__(self):self.anomaly_detector = IsolationForest(contamination=0.1)self.alert_history = []self.suppression_rules = {}def detect_anomalies(self, metrics_data):"""检测性能异常"""features = self.extract_features(metrics_data)anomaly_score = self.anomaly_detector.decision_function([features])[0]is_anomaly = self.anomaly_detector.predict([features])[0] == -1return {'is_anomaly': is_anomaly,'anomaly_score': anomaly_score,'severity': self.calculate_severity(anomaly_score, features)}def should_trigger_alert(self, anomaly_result, service_name):"""智能告警触发判断"""# 检查告警抑制规则if self.is_suppressed(service_name, anomaly_result):return False# 检查告警频率限制if self.is_rate_limited(service_name):return False# 基于历史数据的动态阈值dynamic_threshold = self.calculate_dynamic_threshold(service_name)return abs(anomaly_result['anomaly_score']) > dynamic_thresholddef generate_alert(self, anomaly_result, service_name, metrics_data):"""生成智能告警"""alert = {'id': f"alert-{int(time.time())}",'service': service_name,'severity': anomaly_result['severity'],'title': f"{service_name} 性能异常",'description': self.generate_alert_description(anomaly_result, metrics_data),'suggestions': self.generate_remediation_suggestions(anomaly_result, metrics_data),'timestamp': datetime.now().isoformat(),'auto_resolve_enabled': True}self.send_alert(alert)self.alert_history.append(alert)return alertdef generate_remediation_suggestions(self, anomaly_result, metrics_data):"""生成修复建议"""suggestions = []if metrics_data.get('cpu_usage', 0) > 80:suggestions.append({'action': '增加CPU资源或优化CPU密集型操作','impact': '高','estimated_time': '5-10分钟'})if metrics_data.get('memory_usage', 0) > 85:suggestions.append({'action': '检查内存泄漏或增加内存限制','impact': '高','estimated_time': '10-30分钟'})if metrics_data.get('response_time', 0) > 1000:suggestions.append({'action': '检查数据库查询性能或网络延迟','impact': '中','estimated_time': '15-45分钟'})return suggestions故障诊断与根因分析
故障诊断流程
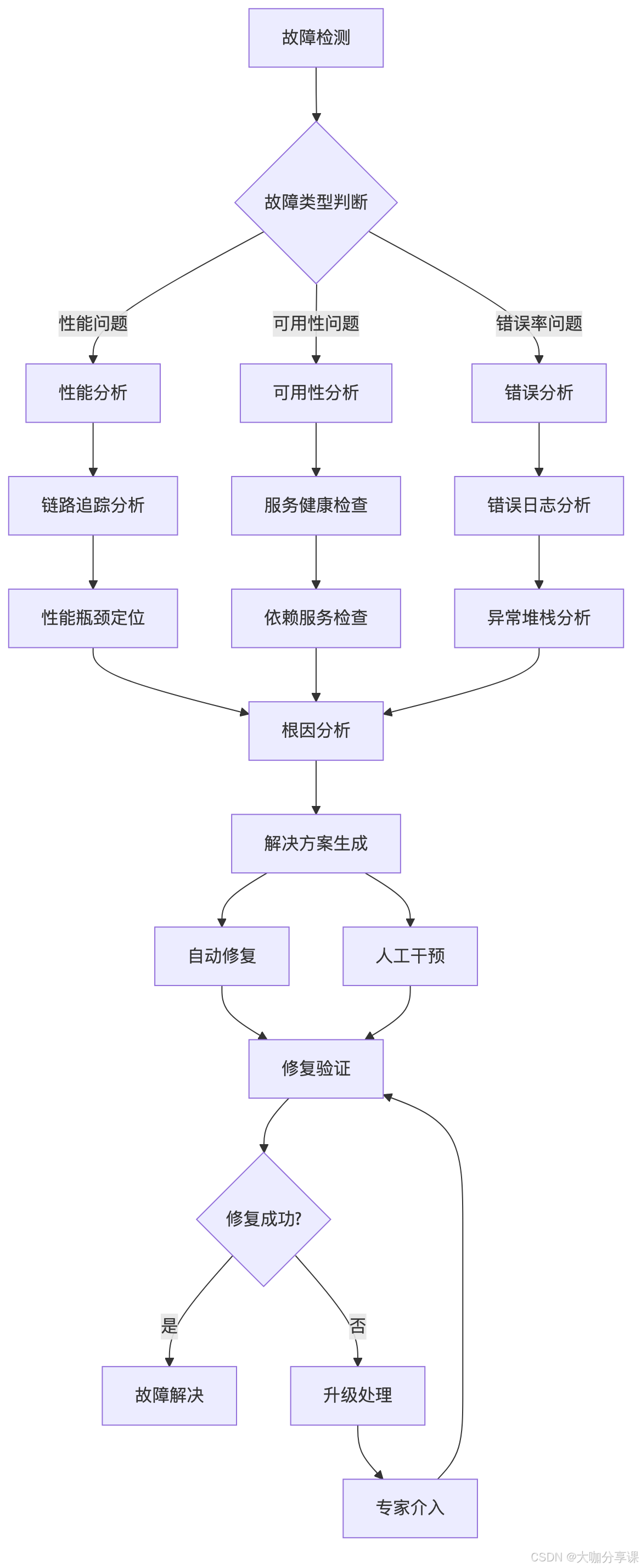
根因分析算法
class RootCauseAnalyzer:def __init__(self):self.dependency_graph = self.build_dependency_graph()self.correlation_analyzer = CorrelationAnalyzer()def analyze_failure(self, incident_data):"""分析故障根因"""affected_services = incident_data['affected_services']timeline = incident_data['timeline']symptoms = incident_data['symptoms']# 1. 构建故障传播图propagation_graph = self.build_propagation_graph(affected_services, timeline)# 2. 分析时间序列相关性correlations = self.correlation_analyzer.analyze(symptoms, timeline)# 3. 依赖关系分析dependency_impact = self.analyze_dependency_impact(affected_services)# 4. 综合分析得出根因root_causes = self.identify_root_causes(propagation_graph, correlations, dependency_impact)return {'root_causes': root_causes,'confidence_score': self.calculate_confidence(root_causes),'impact_analysis': self.analyze_impact(root_causes),'remediation_steps': self.generate_remediation_steps(root_causes)}def build_propagation_graph(self, affected_services, timeline):"""构建故障传播图"""graph = nx.DiGraph()# 按时间顺序添加故障事件for event in sorted(timeline, key=lambda x: x['timestamp']):service = event['service']graph.add_node(service, **event)# 找出可能的故障传播路径for upstream in self.get_upstream_services(service):if upstream in affected_services:graph.add_edge(upstream, service, weight=self.calculate_propagation_probability(upstream, service))return graphdef identify_root_causes(self, propagation_graph, correlations, dependency_impact):"""识别根本原因"""candidates = []# 查找故障起源点(入度为0的节点)origins = [node for node in propagation_graph.nodes() if propagation_graph.in_degree(node) == 0]for origin in origins:score = self.calculate_root_cause_score(origin, propagation_graph, correlations, dependency_impact)candidates.append({'service': origin,'type': 'origin','score': score,'evidence': self.collect_evidence(origin, propagation_graph)})# 查找关键节点(移除后大幅减少故障传播的节点)for node in propagation_graph.nodes():impact_score = self.calculate_removal_impact(node, propagation_graph)if impact_score > 0.7: # 高影响阈值candidates.append({'service': node,'type': 'critical_node','score': impact_score,'evidence': self.collect_evidence(node, propagation_graph)})# 按得分排序返回top候选return sorted(candidates, key=lambda x: x['score'], reverse=True)[:3]自动化故障修复
@Component
public class AutoHealer {@EventListenerpublic void handlePerformanceAnomaly(PerformanceAnomalyEvent event) {HealingStrategy strategy = determineHealingStrategy(event);executeHealing(strategy, event);}private HealingStrategy determineHealingStrategy(PerformanceAnomalyEvent event) {AnomalyType type = event.getAnomalyType();Severity severity = event.getSeverity();return switch (type) {case HIGH_RESPONSE_TIME -> severity == Severity.CRITICAL ? HealingStrategy.IMMEDIATE_SCALE_OUT : HealingStrategy.GRADUAL_OPTIMIZATION;case HIGH_ERROR_RATE -> HealingStrategy.CIRCUIT_BREAKER_ACTIVATION;case MEMORY_LEAK -> HealingStrategy.RESTART_PROBLEMATIC_INSTANCES;case DATABASE_SLOW -> HealingStrategy.QUERY_OPTIMIZATION;default -> HealingStrategy.MONITORING_ENHANCEMENT;};}private void executeHealing(HealingStrategy strategy, PerformanceAnomalyEvent event) {switch (strategy) {case IMMEDIATE_SCALE_OUT:scaleOutService(event.getServiceName(), event.getMetrics());break;case CIRCUIT_BREAKER_ACTIVATION:activateCircuitBreaker(event.getServiceName());break;case RESTART_PROBLEMATIC_INSTANCES:restartUnhealthyInstances(event.getServiceName());break;case QUERY_OPTIMIZATION:optimizeDatabaseQueries(event.getServiceName());break;default:enhanceMonitoring(event.getServiceName());}// 记录自愈操作recordHealingAction(strategy, event);// 验证修复效果scheduleHealingVerification(event.getServiceName(), Duration.ofMinutes(5));}@Asyncpublic void scaleOutService(String serviceName, MetricsSnapshot metrics) {try {// 计算所需实例数int currentInstances = kubernetesClient.getCurrentReplicas(serviceName);int targetInstances = calculateTargetReplicas(metrics, currentInstances);// 执行扩容kubernetesClient.scaleDeployment(serviceName, targetInstances);// 监控扩容效果monitorScalingEffect(serviceName, targetInstances);} catch (Exception e) {logger.error("自动扩容失败: {}", serviceName, e);alertManager.sendAlert(AlertType.AUTO_HEALING_FAILED, serviceName, e.getMessage());}}
}最佳实践与案例研究
电商平台案例研究
背景介绍:某大型电商平台拥有200+微服务,日均处理订单量超过100万笔,需要保证99.9%的可用性。
面临挑战: - 复杂的服务依赖关系 - 高并发场景下的性能瓶颈 - 故障定位困难,平均修复时间(MTTR)过长 - 缺乏统一的性能监控视图
解决方案实施:
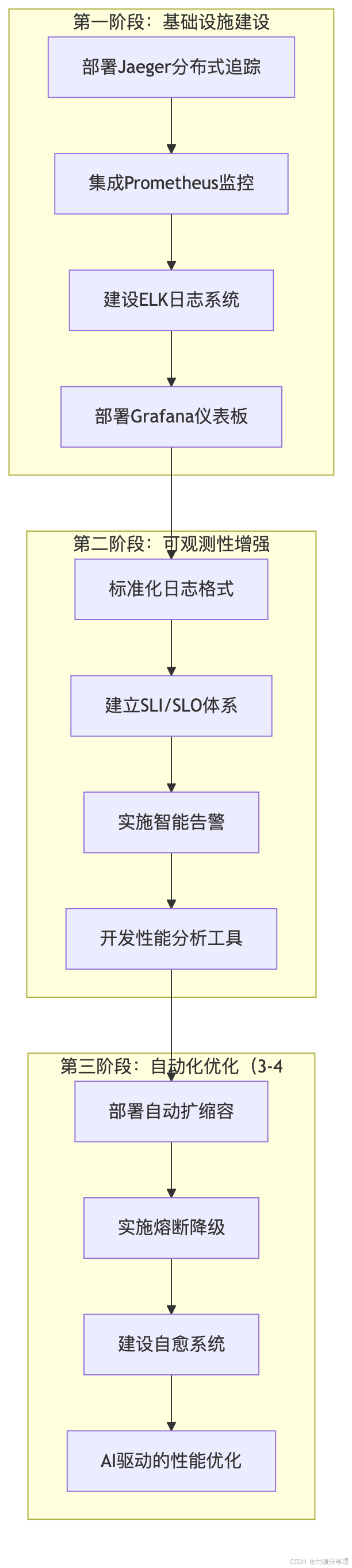
关键成果:
| 指标 | 优化前 | 优化后 | 改善幅度 |
|---|---|---|---|
| 平均响应时间 | 800ms | 350ms | ↓ 56% |
| P95响应时间 | 2.1s | 800ms | ↓ 62% |
| 故障检测时间 | 15分钟 | 2分钟 | ↓ 87% |
| 故障修复时间 | 45分钟 | 12分钟 | ↓ 73% |
| 可用性 | 99.5% | 99.92% | ↑ 0.42% |
金融科技平台案例
特殊要求: - 严格的监管合规要求 - 低延迟交易处理 - 高安全性要求 - 完整的审计追踪
关键实践:
// 金融级链路追踪增强
@Component
public class FinancialTracingEnhancer {@EventListenerpublic void enhanceFinancialTrace(SpanStartEvent event) {Span span = event.getSpan();// 添加监管合规标签span.setTag("compliance.regulation", "PCI-DSS");span.setTag("data.classification", determineDataClassification(span));// 记录审计信息if (isFinancialTransaction(span)) {span.setTag("audit.required", "true");span.setTag("retention.period", "7years");// 加密敏感信息encryptSensitiveSpanData(span);}// 性能SLA监控String slaLevel = determineSLALevel(span.getOperationName());span.setTag("sla.level", slaLevel);span.setTag("sla.threshold", getSLAThreshold(slaLevel));}private void encryptSensitiveSpanData(Span span) {// 加密账户号码、交易金额等敏感信息Map<String, Object> tags = span.getTags();for (Map.Entry<String, Object> entry : tags.entrySet()) {if (isSensitiveField(entry.getKey())) {String encryptedValue = encryptionService.encrypt(entry.getValue().toString());span.setTag(entry.getKey() + ".encrypted", encryptedValue);span.setTag(entry.getKey(), "[ENCRYPTED]");}}}
}实施最佳实践总结
1. 渐进式实施策略 - 从核心服务开始,逐步扩展到全系统 - 建立试点项目验证方案可行性 - 制定详细的实施计划和回滚方案
2. 团队协作与培训 - 建立跨职能的可观测性团队 - 定期进行技术培训和知识分享 - 建立最佳实践文档和操作手册
3. 工具选型原则 - 优先选择开源和标准化解决方案 - 考虑与现有技术栈的兼容性 - 评估长期维护成本和学习曲线
4. 性能基准建立 - 建立详细的性能基准线 - 定期进行性能回归测试 - 持续优化和改进监控指标
未来发展趋势
技术发展方向
1. eBPF技术在可观测性中的应用
// eBPF程序示例:监控HTTP请求延迟
#include <linux/bpf.h>
#include <linux/ptrace.h>
#include <linux/tcp.h>struct http_event {u64 timestamp;u32 pid;u32 duration;char method[8];char url[128];u16 status_code;
};BPF_PERF_OUTPUT(http_events);
BPF_HASH(start_times, u32, u64);// HTTP请求开始时记录时间戳
int trace_http_start(struct pt_regs *ctx) {u32 pid = bpf_get_current_pid_tgid();u64 ts = bpf_ktime_get_ns();start_times.update(&pid, &ts);return 0;
}// HTTP请求结束时计算延迟并发送事件
int trace_http_end(struct pt_regs *ctx) {u32 pid = bpf_get_current_pid_tgid();u64 *start_ts = start_times.lookup(&pid);if (start_ts) {u64 end_ts = bpf_ktime_get_ns();u32 duration = (end_ts - *start_ts) / 1000000; // 转换为毫秒struct http_event event = {};event.timestamp = end_ts;event.pid = pid;event.duration = duration;// 提取HTTP方法和URL(简化示例)bpf_probe_read_str(event.method, sizeof(event.method), (void*)PT_REGS_PARM1(ctx));bpf_probe_read_str(event.url, sizeof(event.url), (void*)PT_REGS_PARM2(ctx));http_events.perf_submit(ctx, &event, sizeof(event));start_times.delete(&pid);}return 0;
}2. AI驱动的智能运维
class AIPerformanceOptimizer:def __init__(self):self.reinforcement_agent = self.build_rl_agent()self.performance_predictor = self.build_predictor_model()self.action_space = self.define_action_space()def build_rl_agent(self):"""构建强化学习智能体"""from stable_baselines3 import PPOfrom gym import spaces# 定义状态空间(系统指标)observation_space = spaces.Box(low=0, high=1, shape=(20,), # CPU、内存、延迟等20个指标dtype=np.float32)# 定义动作空间(优化操作)action_space = spaces.Discrete(10) # 10种优化动作return PPO('MlpPolicy', observation_space=observation_space,action_space=action_space,learning_rate=0.0003)def optimize_performance(self, current_metrics):"""AI驱动的性能优化"""# 1. 预测未来性能趋势future_metrics = self.performance_predictor.predict(current_metrics)# 2. 强化学习智能体决策state = self.normalize_metrics(current_metrics)action = self.reinforcement_agent.predict(state)[0]# 3. 执行优化动作optimization_result = self.execute_optimization_action(action, current_metrics)# 4. 收集反馈并学习reward = self.calculate_reward(current_metrics, optimization_result)self.reinforcement_agent.learn(state, action, reward)return optimization_resultdef execute_optimization_action(self, action, metrics):"""执行优化动作"""actions = {0: self.scale_up_replicas,1: self.scale_down_replicas,2: self.adjust_cache_size,3: self.tune_connection_pool,4: self.optimize_gc_parameters,5: self.adjust_thread_pool,6: self.update_load_balancer_weights,7: self.enable_circuit_breaker,8: self.optimize_database_queries,9: self.no_action}return actions[action](metrics)3. 混沌工程与可观测性结合
class ChaosObservabilityFramework:def __init__(self):self.chaos_experiments = []self.observability_stack = ObservabilityStack()self.experiment_analyzer = ExperimentAnalyzer()def run_chaos_experiment(self, experiment_config):"""运行混沌实验并收集可观测性数据"""# 1. 建立基线指标baseline_metrics = self.collect_baseline_metrics(experiment_config['duration'])# 2. 开始监控增强enhanced_monitoring = self.enable_enhanced_monitoring(experiment_config['target_services'])# 3. 执行混沌实验experiment_result = self.execute_chaos_experiment(experiment_config)# 4. 收集实验期间的可观测性数据experiment_metrics = self.collect_experiment_metrics(experiment_config['duration'], experiment_config['target_services'])# 5. 分析系统韧性resilience_analysis = self.analyze_system_resilience(baseline_metrics, experiment_metrics, experiment_result)# 6. 生成改进建议improvement_suggestions = self.generate_improvements(resilience_analysis)return {'experiment_id': experiment_result['id'],'resilience_score': resilience_analysis['score'],'weak_points': resilience_analysis['weak_points'],'improvements': improvement_suggestions,'observability_insights': self.extract_observability_insights(experiment_metrics)}def analyze_system_resilience(self, baseline, experiment_data, chaos_result):"""分析系统韧性"""resilience_metrics = {}# 计算恢复时间resilience_metrics['recovery_time'] = self.calculate_recovery_time(baseline, experiment_data, chaos_result['injection_time'])# 计算影响范围resilience_metrics['blast_radius'] = self.calculate_blast_radius(experiment_data, chaos_result['target_services'])# 计算服务降级程度resilience_metrics['degradation_level'] = self.calculate_degradation_level(baseline, experiment_data)# 综合韧性得分resilience_score = self.calculate_resilience_score(resilience_metrics)return {'score': resilience_score,'metrics': resilience_metrics,'weak_points': self.identify_weak_points(resilience_metrics)}标准化发展
1. OpenTelemetry生态成熟 - 更完善的自动instrumentation - 标准化的语义约定 - 云原生平台的深度集成
2. 可观测性即代码 - 基础设施即代码的扩展 - 版本控制的监控配置 - GitOps工作流程集成
3. 隐私保护与合规 - 端到端的数据加密 - 细粒度的访问控制 - 自动化的合规检查
新兴技术趋势
1. 边缘计算可观测性 - 边缘节点的性能监控 - 边云协同的链路追踪 - 分布式可观测性架构
2. 量子计算影响 - 量子安全的追踪协议 - 量子算法优化的性能分析 - 量子网络的监控需求
3. 绿色可观测性 - 低碳排放的监控方案 - 能耗优化的性能调优 - 可持续发展的运维实践
总结
微服务架构的性能优化是一个持续演进的过程,链路追踪与可观测性建设为解决复杂分布式系统的性能挑战提供了强有力的技术支撑。通过本文的深入分析,我们可以得出以下核心结论:
关键价值
1. 端到端可见性 - 完整的请求处理路径追踪 - 跨服务的性能瓶颈定位 - 实时的系统健康状态监控
2. 数据驱动决策 - 基于真实数据的性能优化 - 科学的容量规划和扩容策略 - 精确的故障根因分析
3. 自动化运维 - 智能的异常检测和告警 - 自适应的性能调优 - 快速的故障恢复机制
实施要点
1. 统一标准 - 采用OpenTelemetry等行业标准 - 建立一致的监控指标体系 - 制定标准化的操作规范
2. 分层建设 - 从基础设施到业务层的全栈监控 - 逐步完善可观测性能力 - 持续优化和改进监控策略
3. 智能化发展 - 引入AI/ML技术提升自动化水平 - 建设预测性的运维能力 - 实现自愈的系统架构
未来展望
随着云原生技术的不断发展和AI技术的深度融合,微服务性能优化将朝着更加智能化、自动化的方向发展。eBPF等新兴技术将提供更高效的数据收集能力,而强化学习等AI技术将实现更智能的优化决策。
企业在建设可观测性体系时,应该:
- 制定长远规划:考虑技术演进趋势,选择可扩展的技术方案
- 重视团队建设:培养具备可观测性技能的人才队伍
- 持续实践改进:在实践中不断完善和优化监控体系
- 关注标准发展:跟踪行业标准和最佳实践的发展
通过系统性的可观测性建设,企业能够更好地应对微服务架构带来的复杂性挑战,实现高性能、高可用的分布式系统,为业务发展提供坚实的技术保障。
关键词:微服务, 性能优化, 链路追踪, 可观测性, 分布式系统, Jaeger, OpenTelemetry, 监控告警