[文献阅读] Emo-VITS - An Emotion Speech Synthesis Method Based on VITS
[文献阅读]:An Emotion Speech Synthesis Method Based on VITS 在VITS基础上通过参考音频机制,获取情感信息,从而实现的情感TTS方式。
摘要
VITS是一种基于变分自编码器(VAE)和对抗神经网络(GAN)的高质量语音生成模型。但合成语音的控制特征(仅文字)单调;加上包括情感在内的特征表达不足,导致情感语音合成成为一项具有挑战性的任务。
本文提出了一种基于高表现力语音合成模块VITS的emo -VITS系统来实现文本到语音合成的情感控制。设计了情感网络,提取参考音频的全局和局部特征,然后通过基于注意机制的情感特征融合模块将全局和局部特征融合,从而实现更准确、更全面的情感语音合成。
实验结果表明,与无情感网络相比,emo -VITS系统的错误率略有上升,但不影响语义理解。但是,这个系统在自然度、音质、情感相似度等方面都优于其他网络。
VITS
VITS是一种高性能的语音合成模型,它结合了变分推理增强、归一化流和对抗训练过程。VITS采用变分自动编码器(Variational AutoEncoder, VAE),将归一化流应用于条件先验分布和波形域上的对抗式训练,以提高语音波形的质量。通过将TTS系统的两个模块与潜在变量连接起来,实现了完整的端到端学习,与目前的两阶段模型相比,可以产生更自然的声音音频。通过对隐变量进行随机建模,并使用随机时长预测器,提高了合成语音的多样性。同样的文本输入可以合成不同音调和韵律的语音。
先验编码器由两部分组成,文本编码器和归一化流fθ。文本编码器是一个Transformer编码器。归一化流可以提高先验分布的变化范围,从而提高最终的语音合成效果。
后验编码器使用了Glow-TTS中使用的非因果WaveNet残差块。解码器是一种改进的HIFI-GAN发生器,它由多个具有多接受场融合(MRF)的反置卷积组成。随机持续时间预测器根据条件输入估计音素持续时间的分布。鉴别器采用对抗性训练的方法,通过子鉴别器将一维序列重构为二维平面,并进行二维卷积运算来判断样本的真
实概率,从而实现了鉴别器的功能。
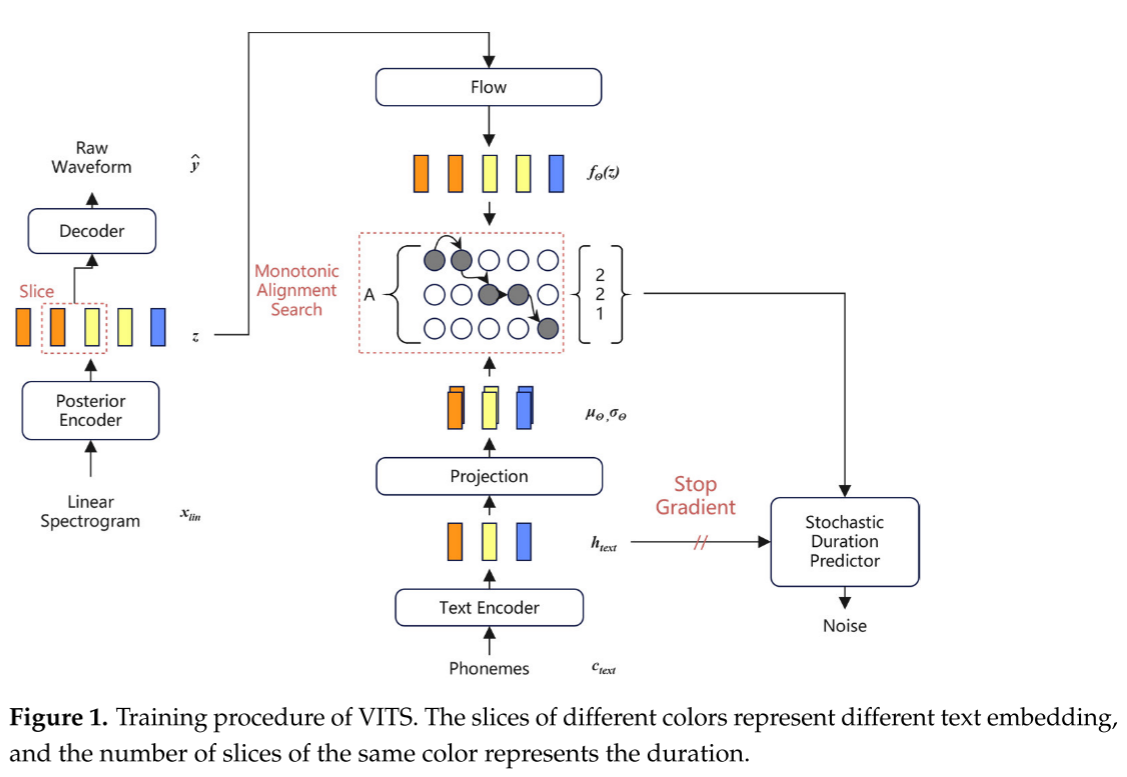
Emo-VITS
为了合成高自然度、兼顾不同信息粒度的情感语音,作者将情感网络引入到VITS中,提出了Emo-VITS系统。与其他声学模型相比,VITS具有非常高的合成自然度。Emo-VITS模型继承了VITS的高性能,并在此基础上进行了情感网络的设计,包括情感编码器网络和情感特征融合模块。情感网络的目标是从参考音频中提取不同感受野的情感特征,基于注意机制进行整合,并将其发送给VITS模块。
情感特征提取模块以Wav2Vec2.0为基础。使用Wav2Vec2.0进行特征提取,使用全局情感特征提取器和局部情感特征提取器进行不同粒度的特征提取,使用情感特征融合进行特征融合。
在训练阶段,使用作为原始音频的训练音频作为情感参考音频,提取全局和局部情感特征。将两个特征向量进行特征融合后,作为情感嵌入和文本嵌入加入到文本编码器中。
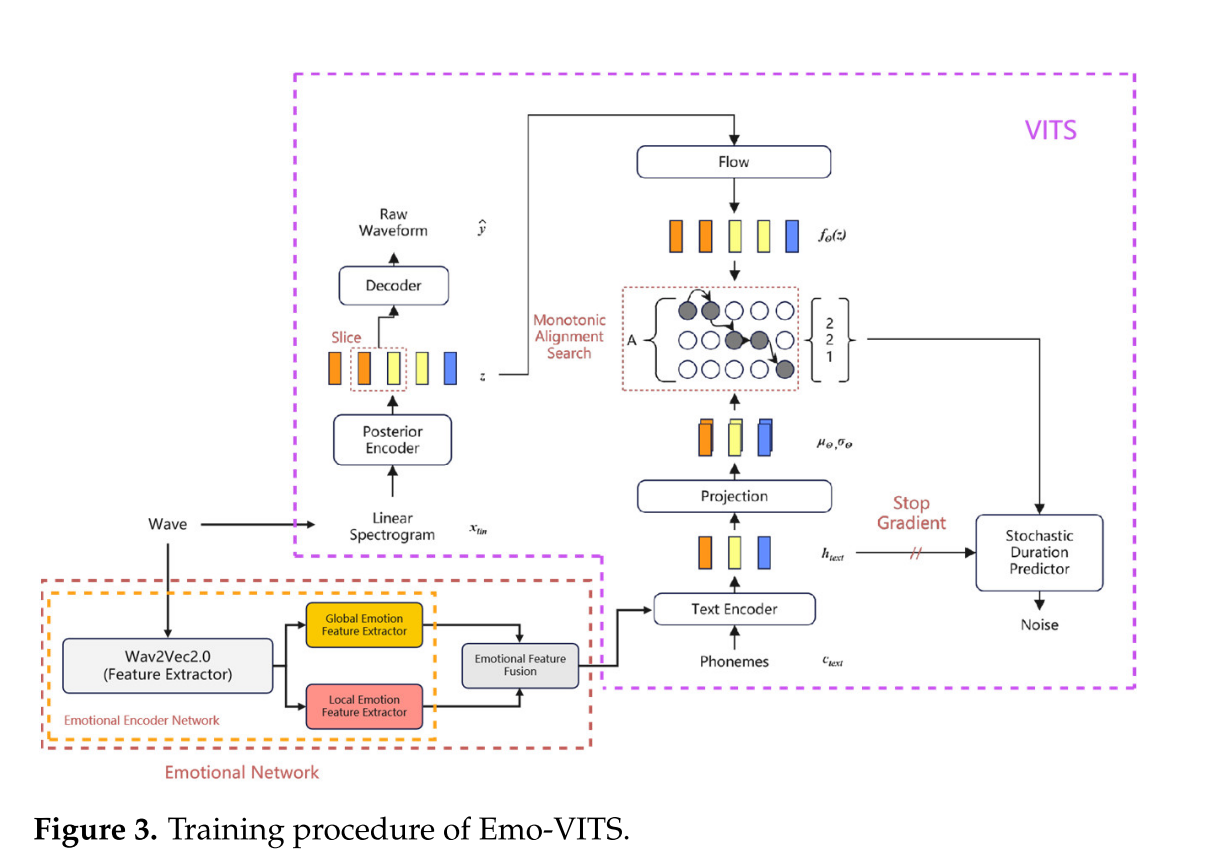
在推理阶段,根据给定的参考音频获得情感嵌入,并合成情感语音。
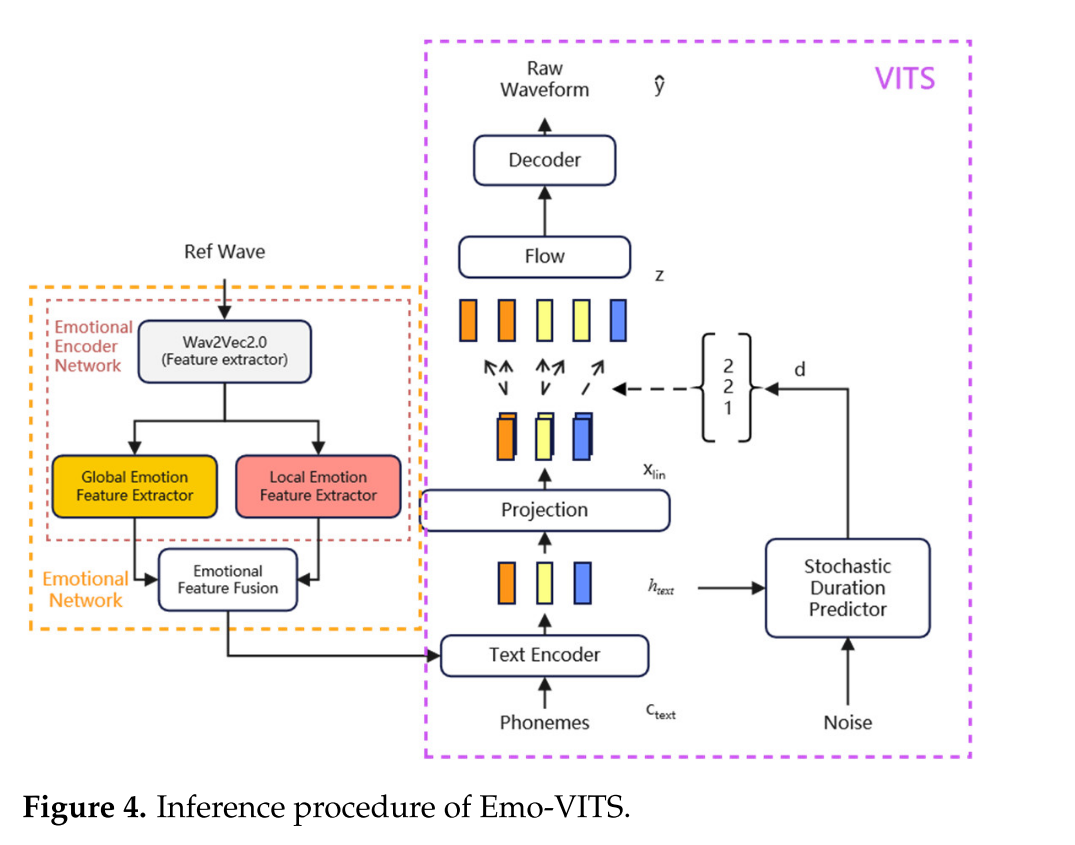
情感编码模块
全局情绪编码器网络通过一个具有ReLU激活的线性层处wav2vec 2.0的输出特征。然后,通过单层LSTM,进一步改进。最后,由MaskAvg模块经过一定步长后将特征序列聚合成均值向量表示,形成192维全局情感特征嵌入。
与全局情感编码器网络不同,局部情感编码器网络需要保留Wav2vec 2.0中特征提取的时间信息。具体来说,首先通过线性层改变wav2vec2.0的输出特征,然后使用平均池化对表示进行平滑处理。在扩展Kernel感知场的同时,有效地保留了局部显著特征。局部情感特征包含时间维度,因此最终提取的局部情感特征和全局情感特征将通过广播机制进行匹配和融合。
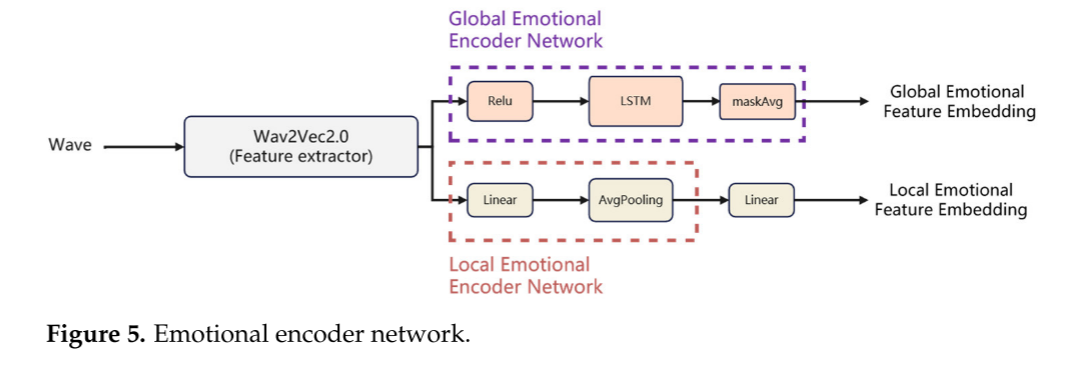
Wav2vec 2.0提取参考音频文件的情感特征向量,分别通过局部情感编码器和全局情感编码器生成相应的特征向量,然后进入下面的情感特征融合模块。
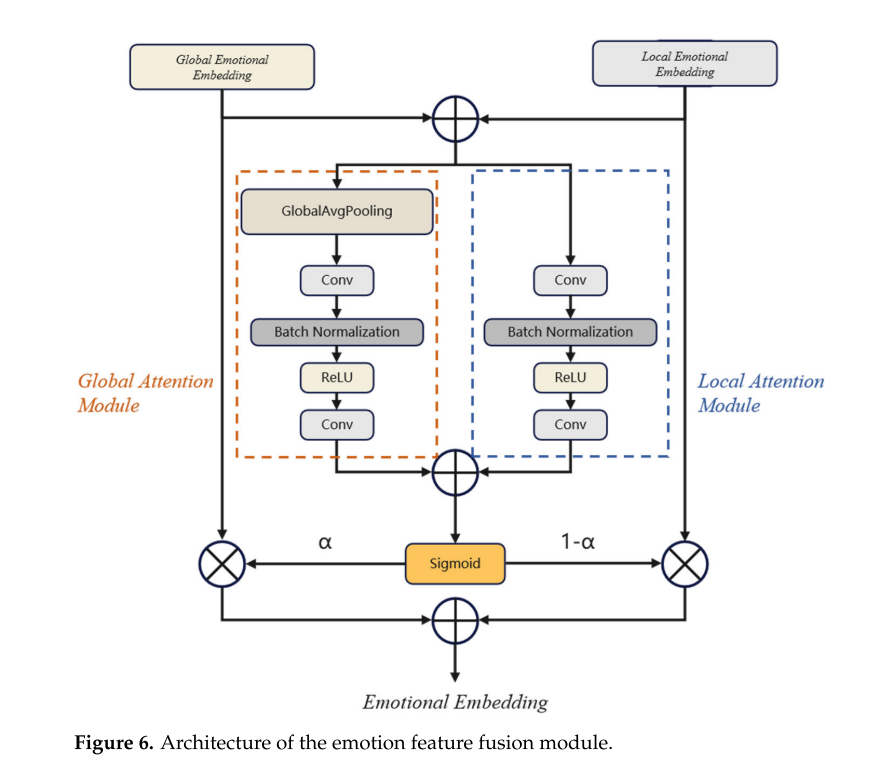
情感特征融合模块的目的是融合全局和局部情感特征,方便将情感特征引入到文本编码器中,特征融合的计算公式如下:
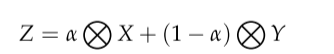
式中,X和Y分别为全局和局部情感特征向量。α为向量X和Y通过特征融合网络得到的新特征权重,其大小在0 ~ 1之间。它是X和Y的和,分别是全局关注模块和局部关注模块的输出和,然后用Sigmoid得到结果。
在训练过程中,将局部情感嵌入和全局情感嵌入相加,得到一个新的向量,然后分别进入局部注意力模块和全局注意力模块。局部注意模块首先经过卷积层,然后经过Batch Normolization层、Relu层,最后经过一个卷积层。全局注意模块比局部注意模块多了一个全局平均池化层,从而提取全局显著特征。两个模块得到的结果之和可以通过一个sigmoid激活函数得到,得到两部分特征重新分配的权重,然后进行特征重新加权求和。两部分网络将在训练中确定各自的网络权值。在预测过程中,可以选择单个参考音频的局部和全局情感特征。我们还使用不同的参考音频提供局部和全局情感特征,以获得更立体的效果。
结果

从表中可以看出,在声学模型VITS中加入情感网络后,WER增加,但增加幅度是可以接受的。
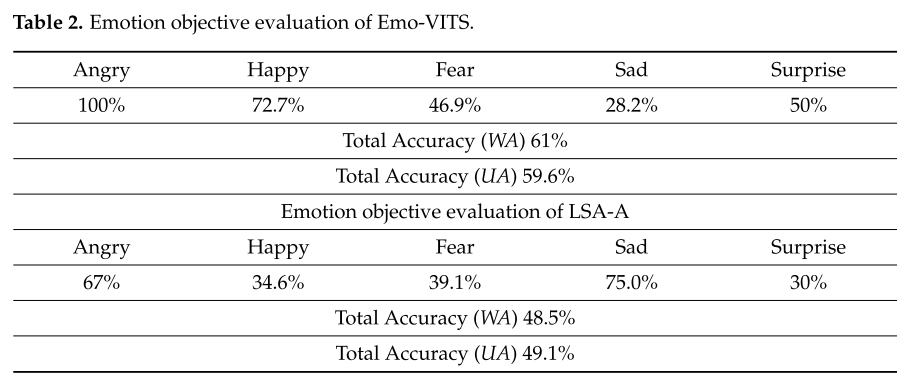
可以看出,在五种情绪的分类测试下,本文模型最终可以达到61%的情绪合成准确率。也就是说,在一半以上的音频被用作参考音频后,输出音频仍然保留了原有的情感特征,在情感分类中被归为同一类别。有趣的是,本文的模型对Angry和Happy的准确率很高,但对Sad合成的准确率却不高。我们认为这可能是因为Sad作为参考音频情绪时,其合成的音频因为声音起伏明显而被区分为Fear类,导致准确率下降。至于LSA-A模型,似乎Happy和surprise的合成效果都不太好。
总结
Emo-VITS是基于vits的情感语音合成模型,中充分利用了VITS结构。通过设计情感编码器网络,分别提取参考音频的全局情感特征嵌入和局部情感特征嵌入,利用情感编码器网络更好地表达参考音频中的情感因素。
。通过设计情感编码器网络,分别提取参考音频的全局情感特征嵌入和局部情感特征嵌入,利用情感编码器网络更好地表达参考音频中的情感因素。
在未来根据具体应用场景,可以继续改进情感特征提取和融合的方法。