北大开源音频编辑模型PlayDiffusion,可实现音频局部编辑,比传统 AR 模型的效率高出 50 倍!
北大开源了一个音频编辑模型PlayDiffusion,可以实现类似图片修复(inpaint)的局部编辑功能 - 只需修改音频中的特定片段,而无需重新生成整段音频。此外,它还是一个高性能的 TTS 系统,比传统 AR 模型的效率高出 50 倍。
自回归 Transformer 模型已被证明能够高效地从文本合成语音。然而,它们面临着一个显著的局限性:修改生成音频的某些部分(称为修复)或移除它们而不留下不连续的伪影,这超出了它们的标准能力。因此,需要开发更通用的语音编辑工具,并采用不同的方法。请考虑以下句子:
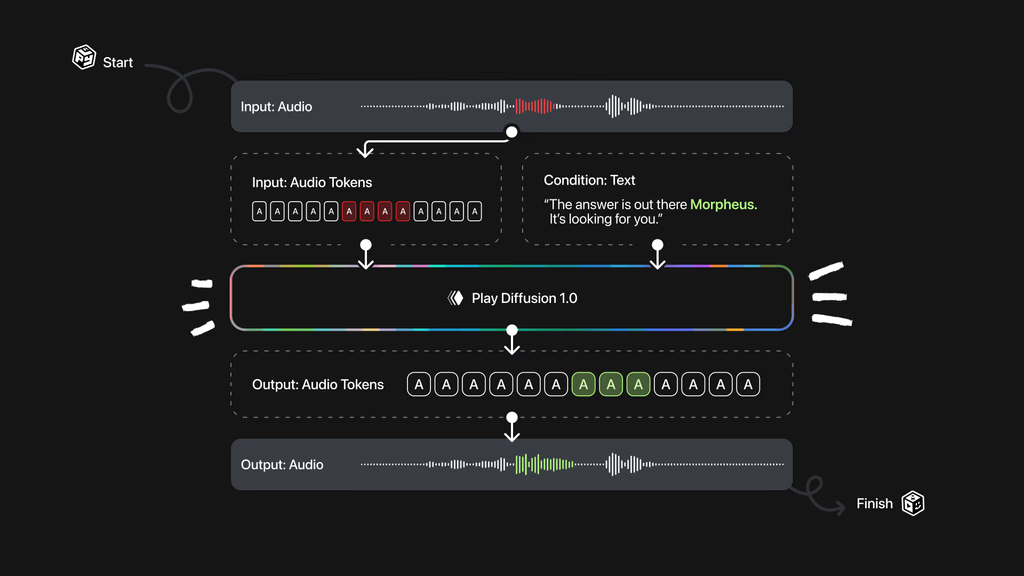
“The answer is out there, Neo. It's looking for you.”
现在假设你想在生成后将“Neo”更改为“Morpheus”。使用传统的 AR 模型,你的选择有限:
重新生成整个句子,这在计算上很昂贵,并且经常导致韵律或语音节奏的变化。
仅替换单词“Neo”,会导致单词边界处出现明显的伪影或不匹配。
从中间点重新生成,例如从“Morpheus。它在寻找你。”,但这可能会改变未编辑部分的韵律(“它在寻找你。”),从而产生不必要的语音节奏变化。
所有这些方法都会损害音频的连贯性和自然性。
相关链接
-
项目: https://github.com/playht/PlayDiffusion
-
试用: https://huggingface.co/spaces/PlayHT/PlayDiffusion
PlayDiffusion 简介
在 PlayAI,我们用一种新颖的基于扩散的音频语音编辑方法解决了这个问题。它的工作原理如下:
首先,我们将音频序列编码到离散空间中,将波形转换为更紧凑的表示形式。此表示中的每个单元称为一个标记 (token)。此过程适用于真实语音和文本转语音 (TTS) 模型生成的音频。
当需要修改某个片段时,我们会屏蔽该部分音频。
使用以更新后的文本为条件的扩散模型来对掩蔽区域进行去噪。
周围环境被无缝保留,确保平滑过渡和一致的扬声器特性。
然后使用我们的 BigVGAN 解码器模型将生成的输出标记序列转换回语音波形。
通过使用非自回归扩散模型,我们可以更好地保持编辑边界处的语境,从而实现高质量、连贯的音频编辑。这标志着音频编辑能力的重大进步,并为动态、细粒度的语音修改铺平了道路。完整流程如图 1 所示。
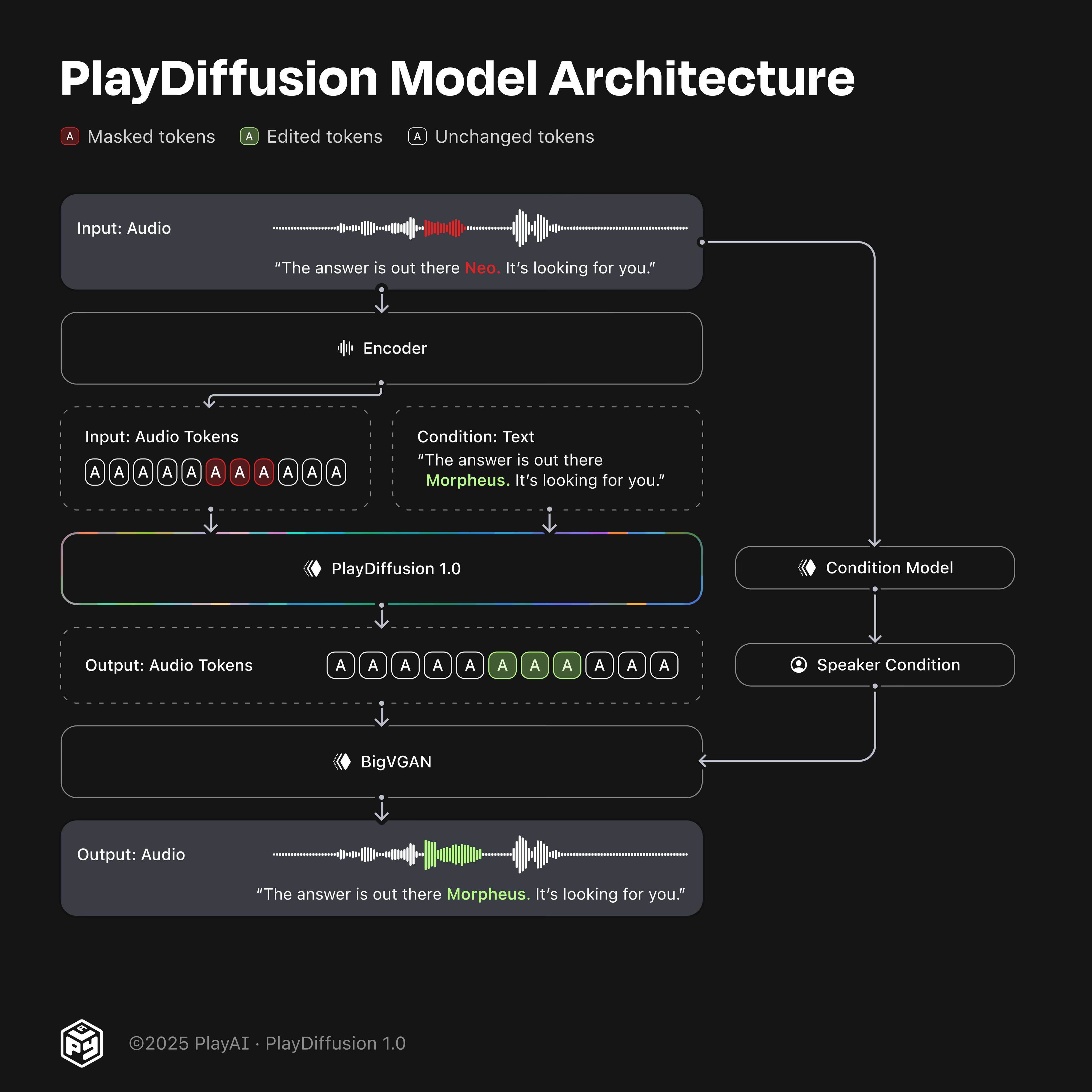
图 1. PlayDiffusion 1.0 模型。
-
包含语音“答案就在那儿,Neo。去抓住它!”的输入音频被编码为离散的音频标记。
-
与要编辑的语音对应的标记被屏蔽。这里我们屏蔽了“Neo”的标记。
-
给定更新后的文本和完整的输入标记序列(即屏蔽和未屏蔽的序列),PlayDiffusion 生成编辑后的输出序列。
-
该序列由我们的 BigVGAN 转换为波形,并以从原始片段中提取的说话人嵌入为条件。
离散扩散作为 TTS
在整个音频波形被掩盖的极端情况下,扩散模型可以作为高效的文本到语音 (TTS) 系统发挥作用。
虽然自回归 Transformer 模型在语音合成领域取得了令人瞩目的成果,但其逐个 token 的顺序生成方式本身就存在效率低下的问题。每个 token 都必须基于前一个 token 进行生成,这会导致巨大的计算开销。
相比之下,扩散模型采用非自回归方法——同时生成所有标记,并通过固定数量的去噪步骤对其进行细化。这种根本的架构差异带来了显著的性能优势。
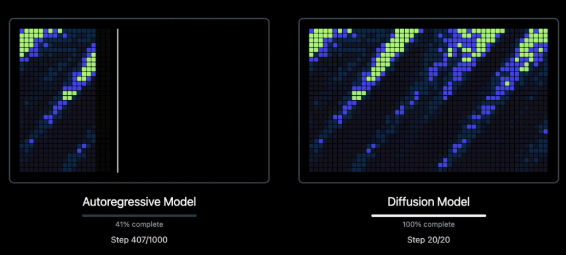
举例来说:对于运行频率为 50 Hz 的音频编解码器,在自回归模型中生成 20 秒的语音需要 1,000 个步骤。而扩散模型可以一次性生成全部 1,000 个 token,并仅需 20 个迭代步骤即可对其进行优化——这使得生成步骤的效率提高了 50 倍,同时又不影响输出的质量或清晰度。
训练
我们从预先训练的仅解码器文本转换器架构开始,并引入了专门针对音频生成定制的关键修改:
非因果掩蔽:
与 GPT 等采用因果掩蔽(允许标记仅关注先前的标记)的标准解码器专用 LLM 不同,我们改进的 LLM 实现使用非因果注意力头。这使得模型能够同时利用过去、现在和未来的标记。
自定义分词器和嵌入缩减:
为了优化效率,尤其是针对英语语音合成,我们使用了自定义字节对编码 (BPE) 分词器,该分词器仅包含 10,000 个文本分词。这大大减少了嵌入表的大小,从而显著提升了计算速度,同时又不影响音频质量。
说话人调节:
我们的模型融合了源自预训练嵌入模型 e(w): ℝᵗ → ℝᵏ 的说话人调节方法,该模型将不同长度 t 的波形映射到维度为 k 的固定大小向量。这能够捕捉说话人的基本特征,确保合成或编辑的音频片段之间语音身份的一致性。
在训练过程中,我们像 MaskGCT [1] 一样,随机屏蔽一定比例的音频 token。模型会根据说话人嵌入、文本输入以及剩余未屏蔽的音频 token 提供的上下文,学习准确预测这些被屏蔽的 token。这种方法可以有效地训练模型处理部分或完全音频屏蔽的场景。给定不同时间步长的文本样本 xₜ,文本条件 C,我们将损失建模为:

在推理过程中,解码会迭代进行,从完全掩码的 token 序列开始。解码过程包含多个步骤,记为 T:
逐步解码过程:
初步预测:在每次迭代中,模型根据当前的掩蔽音频和文本输入生成初始预测 X̂₀。
置信度评分:根据模型的预测,每个 token 都会获得一个置信度分数。新预测的(之前被屏蔽的)token 会被赋予与其预测概率相等的置信度,而之前确定的 token 则保持不变,置信度分数为 1。
自适应重掩码:我们利用一个逐步递减的方案 gamma,选择一定数量的置信度最低的 token,在后续迭代中进行重掩码。每次迭代后,需要重掩码的 token 数量都会逐渐减少,从而使模型的优化工作集中在不确定性最高的区域。更多详情,请参阅 MaskGCT [1]。
这个迭代解码过程持续进行,直到所有步骤完成,逐渐完善标记预测并产生连贯的高质量音频输出。