论文调研_BCSD综述论文调研
| 论文名称 | 发表期刊 | 发表时间 | 发表单位 |
| A Survey of Binary Code Similarity | ACM Computing Surveys | 2022年 | IMDEA |
1. BCSD基础
引入二进制代码基本概念、描述编译流程的扩展性以及现实中的多样性变换,明确二进制代码相似性检测(BCSD)定义。
1.1 基础概念引入:二进制代码的生成
二进制代码是指通过编译过程生成、可由CPU直接执行的机器码。标准的编译流程以程序的源代码文件为输入,结合所选的编译器、优化级别及特定平台(由架构、字长和操作系统定义),生成目标文件。这些目标文件随后会被链接为一个二进制程序,即独立的可执行文件或库文件。一般编译流程
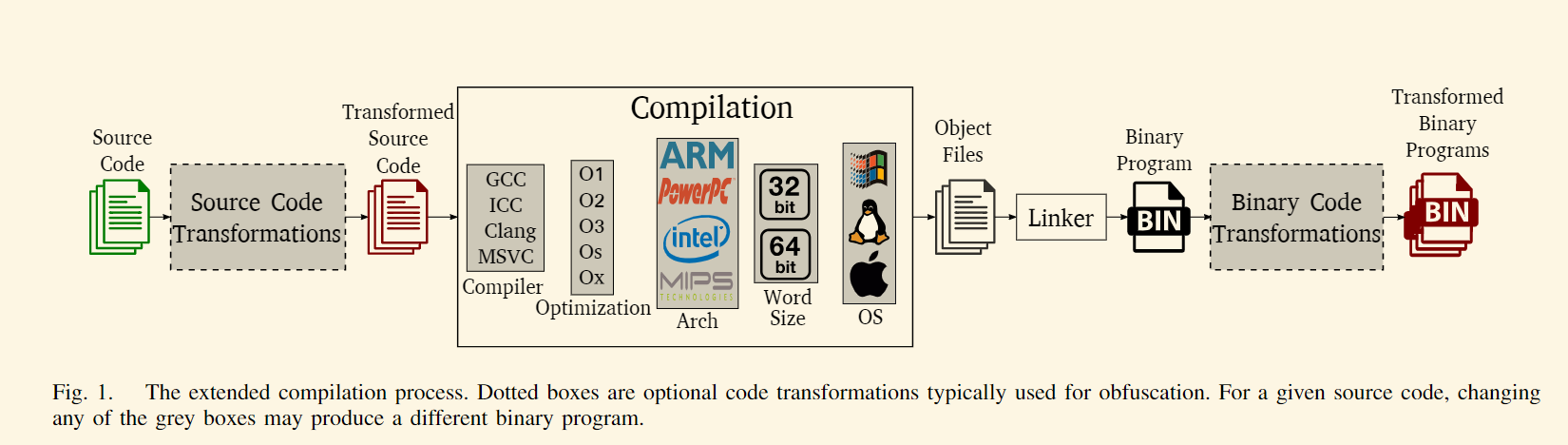
1.2 扩展编译流程:现实世界中的二进制代码
二进制代码相似性检测方法通常涉及一个扩展的编译流程,如上图所示,在标准编译流程的基础上增加了两个可选步骤:源代码变换和二进制代码变换。这两类变换通常是语义保持的,即不会改变程序的功能,最常用于代码混淆,以阻碍对分发的二进制程序的逆向工程。扩展编译流程
1.3 BCSD定义:同源二进制代码相似性捕获
同一份源代码在不同编译配置下可能生成不同的二进制表示。如上图所示,开发人员可以修改任意灰色模块,从而在不改变程序语义的前提下,生成多种不同的二进制程序。(1)这些差异可能源于标准编译过程中的变动,例如为了提高程序性能,开发人员可能调整编译器的优化级别,或更换不同的编译器,尽管源代码未变,但生成的二进制代码将随之变化。此外,开发人员也可能更换目标平台以适配不同的硬件架构,而若新平台使用不同的指令集,则生成的二进制代码可能差异巨大。(2)开发人员还可以主动应用混淆技术,使相同源代码生成多种语义等价但结构多样的变体。理想情况下,二进制代码相似性检测方法应能识别这些因变换而产生的不同二进制代码之间的相似性,其鲁棒性正体现为其应对各类编译和混淆变换的能力,即在这些变换存在的情况下依然能够准确检测代码相似性。
1.4 BCSD应用
补丁检测:补丁生成与分析是最早期且最常见的二进制代码相似性应用之一,其核心是对比同一程序的两个连续或相近版本,识别新版本中所做的补丁修改。这类应用在厂商未公开补丁细节的专有软件中尤为重要。通过差异分析生成的二进制补丁通常体积较小,可用于高效分发和程序更新。此外,该技术还可用于自动识别修复漏洞的安全补丁、对这些补丁进行深入分析,甚至可辅助生成适用于旧版本中未修复漏洞的利用代码。
漏洞检测:二进制代码相似性最广泛的应用之一是漏洞搜索,即在大型二进制代码库中查找已知漏洞对应的相似代码。由于代码重用现象普遍,存在缺陷的代码片段可能出现在多个程序中,甚至在同一个程序的不同位置重复出现。因此,在发现某个漏洞后,识别可能重用该缺陷代码的相似片段,对于漏洞扩散分析与补丁生成具有重要意义。漏洞搜索方法通常以存在缺陷的二进制代码片段作为查询输入,在目标代码库中寻找功能相似的片段。该问题的一个变体是跨平台漏洞搜索,目标代码可能针对不同平台(如 x86、ARM、MIPS)编译,从而对相似性检测方法的跨平台鲁棒性提出更高要求。
恶意软件分析:在二进制代码相似性检测中,恶意软件分析是一个重要的应用方向,主要包括以下三类:恶意软件检测:通过将待检测的可执行文件与已知恶意软件样本进行比对,若相似度较高,则该样本很可能是某一已知恶意家族的变体。相比于依赖系统或API调用行为的传统方法,BCSD更关注从代码层面识别语义相似性;恶意软件聚类:进一步将多个已知恶意样本按照二进制代码相似性划分为不同家族,每个家族通常包含同一恶意程序的不同版本及其多态变体(如加壳版本);恶意软件演化追踪:在已知属于同一恶意程序的样本集上构建版本演化图,图中每个节点代表一个程序版本,边表示其演化关系。由于恶意软件通常缺乏明确版本标识,演化追踪对于揭示其变种结构和传播路径具有重要意义,且通常依赖聚类结果作为前置步骤以确保分析的准确性。
许可证合规性分析:二进制代码相似性可用于识别对原告程序的未授权代码重用,例如源代码被窃取、二进制代码被直接复用、专利算法在未授权情况下被重新实现,或违反开源许可证(如将GPL代码用于商业软件)等情形。早期用于检测此类侵权行为的方法主要依赖软件指纹(birthmark),即提取程序固有功能特征的签名。然而,如第三节所述,本文不讨论基于签名的方法,而聚焦于基于二进制代码相似性的检测技术。
1.5 BCSD演进
| 论文名称 | 发表期刊 | 发表时间 | 发表单位 |
| How Machine Learning Is Solving the Binary Function Similarity Problem | USENIX | 2022年 | Cisco |
| 论文名称 | 发表期刊 | 发表时间 | 发表单位 |
| How Far Have We Gone in Binary Code Understanding Using Large Language Models | 2024 IEEE International Conference on Software Maintenance and Evolution | 2024年 | 中国科学院大学 |